一、位图(Bitmap)
?1、什么是比特(bit)
? ? ? 1)它是英文 binary digit 的缩写
? ? ? 2)它是计算机内部存储的最小单位,用二进制的0或者1来表示?
? ? ? 3)1 Byte = 8 bit;1024 Byte = 1 Kb;1024 Kb = 1 Mb;1024 Mb = 1 Gb;1024 Gb = 1 Tb
2、引子
给出40亿个连续不重复且无序的无符号int型整数,目前条件是只有一个2G内存的PC,需要判断出某个数字是否在给出的这40亿个数字里面
分析:int占4个Byte,40亿 * 4 / 1024 / 1024 / 1024 ≈ 14.9 Gb,目前内存只有2G根本不满足要求(需要注意的是 int 无符号最大值是 4294967295,二进制的最高位为符号位),此时就需要位图(Bitmap)来处理了
? ?1)什么是位图(Bitmap)
? ? ? ? a)位图(Bitmap)就是用一个bit位表示数字。从0开始,第N位的bit位表示整数N。bit位为1表示该整数存在,bit位为0表示整数不存在

? ? ? ? b)位图本质上就是一个数组
? ? ? ? c)位图采用的空间换时间的方式来提高计算的效率
? ?2)通过位图(Bitmap)解决后:40亿个数字如果我们用40亿个bit来表示,则需要占据的空间为 40亿 / 8 / 1024 / 1024 ≈ 476.83 Mb,大大降低了内存的消耗?
3、缺点:以上是在数据连续的情况下占用了476.83Mb,假如现在只存第40亿一个数那仍然会占476.83Mb的内存。也就是说在数据密集的时候使用位图是很划算的,如果数据稀疏那就不划算了
二、压缩位图(RoaringBitmap)
1、实现原理
? ? ?1)压缩位图(RoaringBitmap,以下简称RBM)处理的是无符号int类型的整数
? ? ?2)RBM将一个32位的int拆分为高16位与低16位分开去处理,其中高16位作为索引,低16位作为实际存储数据
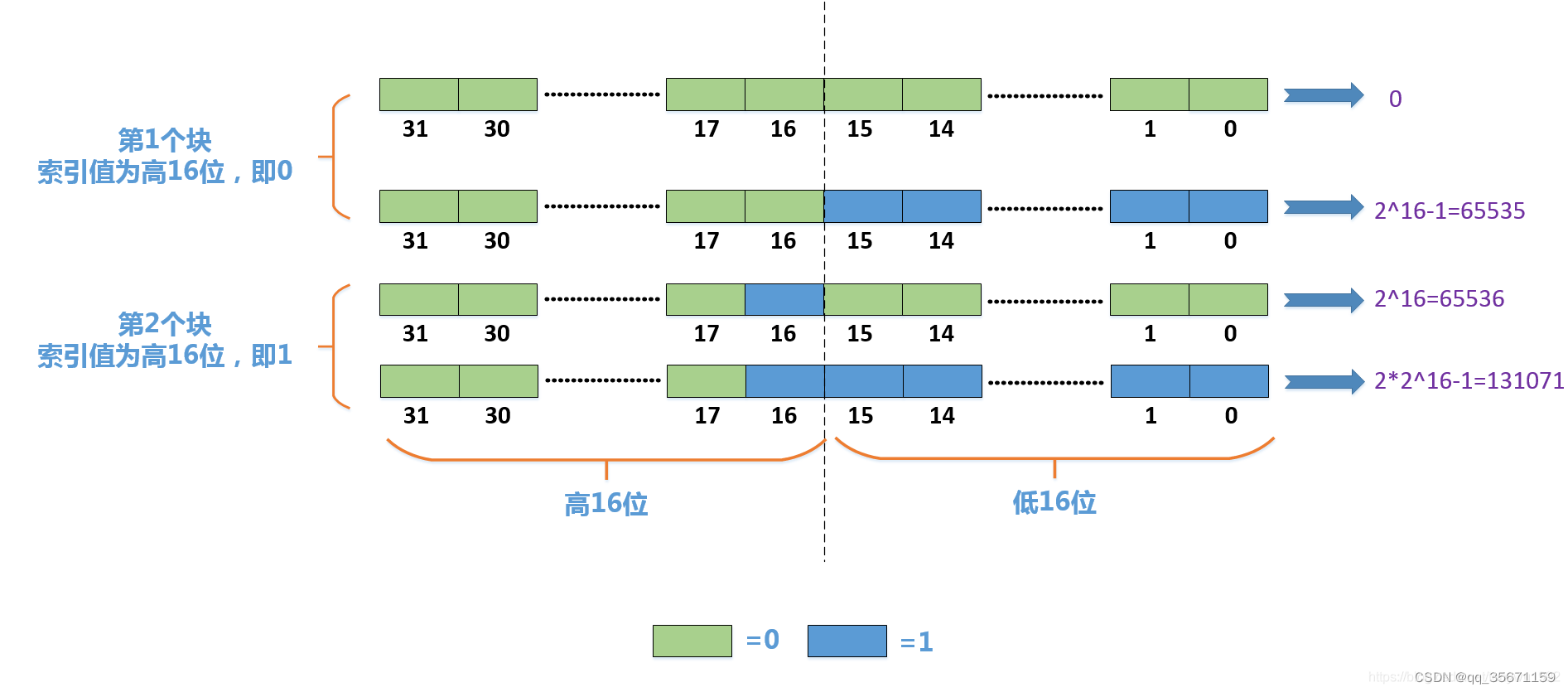
2、数据结构
? ? ?1)RoaringBitmap
RoaringArray highLowContainer = null;
/**
* Create an empty bitmap
*/
public RoaringBitmap() {
highLowContainer = new RoaringArray();
}
? ? ?2)RoaringArray
static final int INITIAL_CAPACITY = 4;
// short占2个字节,16位,一个short正好可以表示int高16位的所有数值
short[] keys = null;
// Container用来存储int低16位的2^16个int类型的整数
Container[] values = null;
protected RoaringArray() {
this.keys = new short[INITIAL_CAPACITY];
this.values = new Container[INITIAL_CAPACITY];
}
? ? ?3)Container
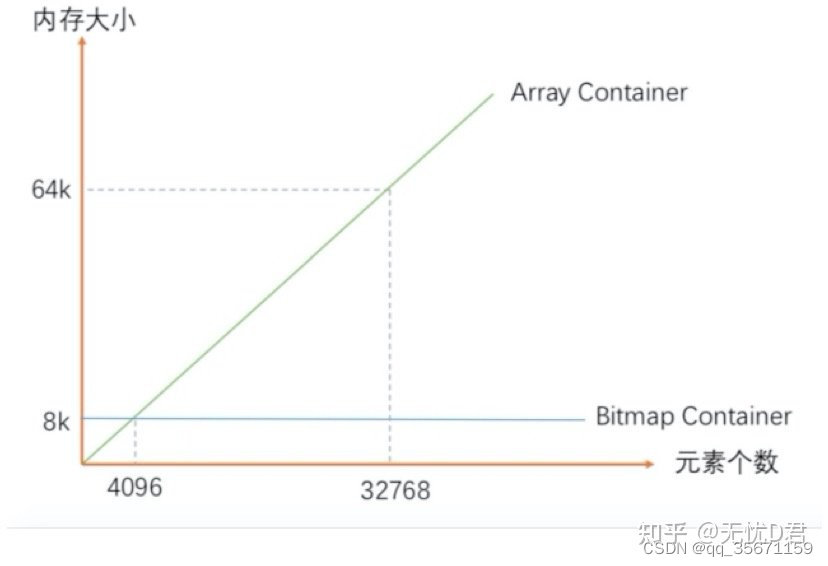
? ? ? ? a)ArrayContainer
// ArrayContainer中允许的最大数据量
// 4096 * 2Byte / 1024 = 8k 也就是说ArrayContainer最大容量时所占的内存为8k
static final int DEFAULT_MAX_SIZE = 4096;// containers with DEFAULT_MAX_SIZE or less integers should be ArrayContainers
// 基数(元素个数)
protected int cardinality = 0;
// 用来存储int类型低16位的整数,也就是说ArrayContainer中存储的数字来自0~65535(2^16-1),且只能存这个范围内的4096个数
short[] content;? ? ? ? b)BitmapContainer
// 最大可以存储2^16个比特位(每个bit对应一个数值, 最大可以表示2^16个int类型的整数)
protected static final int MAX_CAPACITY = 1 << 16;
long[] bitmap;
int cardinality;
public BitmapContainer() {
this.cardinality = 0;
// long占8Byte(64bit)
// 2^16bit / 64bit = 1024 也就是说需要1024个long, 所以此处new一个长度为1024长度的long数组
// 2^16bit / 8 / 1024 = 8Kb (1024个long * 8Byte / 1024 = 8Kb), 所以BitmapContainer始终占据内存空间为8Kb
this.bitmap = new long[MAX_CAPACITY / 64];
}
ArrayContainer 与 BitmapContainer 随着存储的数据量增多时所占内存空间对比图
? ? ? ? c)RunContainer
private short[] valueslength;// we interleave values and lengths, so
// that if you have the values 11,12,13,14,15, you store that as 11,4 where 4 means that beyond 11 itself, there are
// 4 contiguous values that follows.
// Other example: e.g., 1, 10, 20,0, 31,2 would be a concise representation of 1, 2, ..., 11, 20, 31, 32, 33
int nbrruns = 0;// how many runs, this number should fit in 16 bits.
private RunContainer(int nbrruns, short[] valueslength) {
this.nbrruns = nbrruns;
this.valueslength = Arrays.copyOf(valueslength, valueslength.length);
}
有关RunContainer的注意事项:
在RBM创立初期只有以上两种容器,RunContainer其实是在后期加入的。RunContainer是基于之前提到的RLE算法进行压缩的,主要解决了大量连续数据的问题。
举例说明:3,4,5,10,20,21,22,23这样一组数据会被优化成3,2,10,0,20,3,原理很简单,就是记录初始数字以及连续的数量,并把压缩后的数据记录在short数组中
显而易见,这种压缩方式对于数据的疏密程度非常敏感,举两个最极端的例子:如果这个Container中所有数据都是连续的,也就是[0,1,2.....65535],压缩后为0,65535,即2个short,4字节。若这个Container中所有数据都是间断的(都是偶数或奇数),也就是[0,2,4,6....65532,65534],压缩后为0,0,2,0.....65534,0,这不仅没有压缩反而膨胀了一倍,65536个short,即128kb
因此是否选择RunContainer是需要判断的,RBM提供了一个转化方法runOptimize()用于对比和其他两种Container的空间大小,若占据优势则会进行转化
3、数据存储使用示例
?????1)代码
RoaringBitmap rbm = new RoaringBitmap();
// 从 0 到 2^16-1, 这个范围内的高位索引为0, 此处取了 5 个数
rbm.add(0);
rbm.add(1);
rbm.add(10);
rbm.add(10000);
rbm.add(65335);
// 从 2^16 到 2^17-1, 这个范围内的高位索引是1, 此处取了 2^15 个偶数
for (int i = 65536; i < 65536 * 2; i+=2) {
rbm.add(i);
}
// 其实就是从 2^17+2^16 到 2^17+2^17-1 这个范围内的高位索引为3, 此处取了 2^16 个数
for (int i = 3 * 65536; i < 4 * 65536; i++) {
rbm.add(i);
}
// 用来优化BitmapContainer, 优化为RunContainer
rbm.runOptimize();
? ? ? 2)分析
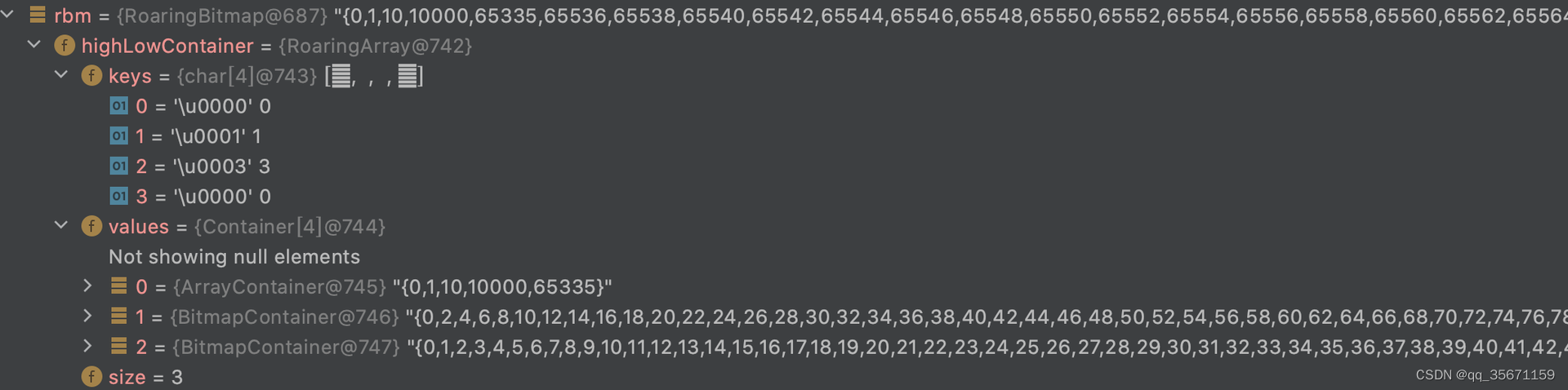
? ? ? ? ? ?a)优化前
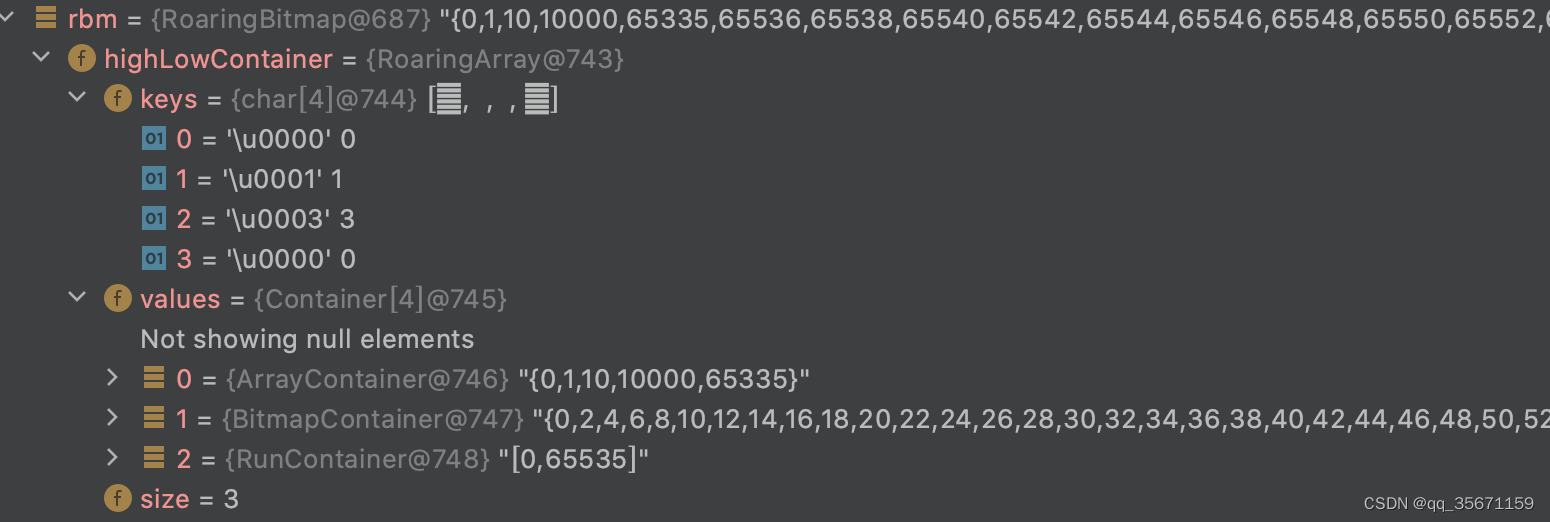
? ? ? ? ? ?b)优化后
? ? ? ? ? ?c)注释
????????????????第一组由于数据最大为 2^16-1 所以最高位的索引为0,且个数没有超过4096,所以直接存到ArrayContainer中
????????????????第二组数据的范围是 2^16 到 2^17-1 所以最高位索引为1,此时需要用BitmapContainer来存储低16位的数字
????????????????第三组如果没有优化的话是BitmapContainer存储从 0 ~ 65535 的所有数据,如果优化以后则会用RunContainer存储,且只会存一个开始值0,还有一个步长65535,中间所有的值连续
需要注意的是第二组在调用优化方法以后并没有被优化成RunContainer
4、常用API
// and取交集
RoaringBitmap roaringBitmapAnd1 = RoaringBitmap.bitmapOf(1, 2, 3);
RoaringBitmap roaringBitmapAnd2 = RoaringBitmap.bitmapOf(3, 6, 4);
RoaringBitmap and = RoaringBitmap.and(roaringBitmapAnd1, roaringBitmapAnd2);
print(and, "and取交集后bitmap的值: ");
System.out.println("统计基数: " + and.getCardinality());
System.out.println("判断bitmap是否为空: " + and.isEmpty());
System.out.println("判断1与2是否相等: " + roaringBitmapAnd1.equals(roaringBitmapAnd2));
System.out.println("判断1与2是否相交: " + RoaringBitmap.intersects(roaringBitmapAnd1, roaringBitmapAnd2));
System.out.println("AND计算并返回基数: " + RoaringBitmap.andCardinality(roaringBitmapAnd1, roaringBitmapAnd2));
roaringBitmapAnd1.remove(2);// 这里是数值, 不是索引
print(roaringBitmapAnd1, "1中移除数字2: ");
// roaringBitmapAnd2.flip(4L, 5L);// ??????
// print(roaringBitmapAnd2, "2中翻转数字3: ");
System.out.println("bitmap1小于等于3的整数数目: " + roaringBitmapAnd1.rank(3));
System.out.println("bitmap2中是否包含10: " + roaringBitmapAnd2.contains(10));
// System.out.println("bitmap1中是否有值在给出的范围: " + roaringBitmapAnd1.contains(2, 3));// ???
System.out.println("bitmap1中是否包含bitmapand: " + roaringBitmapAnd1.contains(and));
roaringBitmapAnd2.add(10);
print(roaringBitmapAnd2, "bitmap2中添加元素10: ");
System.out.println("bitmap1中添加元素6到8: " + RoaringBitmap.add(roaringBitmapAnd1, 6L, 11L));
System.out.println("添加完元素以后bitmap1的值: " + roaringBitmapAnd1);
System.out.println("======================");
?
// or取并集
RoaringBitmap roaringBitmapOr1 = RoaringBitmap.bitmapOf(1, 2, 3);
RoaringBitmap roaringBitmapOr2 = RoaringBitmap.bitmapOf(3, 4, 5);
RoaringBitmap or = RoaringBitmap.or(roaringBitmapOr1, roaringBitmapOr2);
print(or, "or取并集后bitmap的值: ");
System.out.println("统计基数: " + or.getCardinality());
System.out.println("判断bitmap是否为空: " + or.isEmpty());
System.out.println("判断1与2是否相等: " + roaringBitmapOr1.equals(roaringBitmapOr2));
System.out.println("判断1与2是否相交: " + RoaringBitmap.intersects(roaringBitmapOr1, roaringBitmapOr2));
System.out.println("or计算并返回基数: " + RoaringBitmap.orCardinality(roaringBitmapOr1, roaringBitmapOr2));
System.out.println("======================");
// xor取异或: 相同的都是0, 不同的为1
RoaringBitmap roaringBitmapXor1 = RoaringBitmap.bitmapOf(1, 2, 3);
RoaringBitmap roaringBitmapXor2 = RoaringBitmap.bitmapOf(3, 2, 5);
RoaringBitmap xor = RoaringBitmap.xor(roaringBitmapXor1, roaringBitmapXor2);
print(xor, "xor异或后取bitmap的值: ");
System.out.println("统计基数: " + xor.getCardinality());
System.out.println("判断bitmap是否为空: " + xor.isEmpty());
System.out.println("判断1与2是否相等: " + roaringBitmapXor1.equals(roaringBitmapXor2));
System.out.println("判断1与2是否相交: " + RoaringBitmap.intersects(roaringBitmapXor1, roaringBitmapXor2));
System.out.println("xor计算并返回基数: " + RoaringBitmap.xorCardinality(roaringBitmapXor1, roaringBitmapXor2));
System.out.println("======================");
// andNot取差集
RoaringBitmap roaringBitmapAndNot1 = RoaringBitmap.bitmapOf(1, 2, 3);
RoaringBitmap roaringBitmapAndNot2 = RoaringBitmap.bitmapOf(3, 4, 5);
RoaringBitmap andNot1 = RoaringBitmap.andNot(roaringBitmapAndNot1, roaringBitmapAndNot2);
RoaringBitmap andNot2 = RoaringBitmap.andNot(roaringBitmapAndNot2, roaringBitmapAndNot1);
print(andNot1, "andNot计算bitmap1与bitmap2的差集: ");
System.out.println("统计基数: " + andNot1.getCardinality());
System.out.println("判断bitmap是否为空: " + andNot1.isEmpty());
System.out.println("判断1与2是否相等: " + roaringBitmapAndNot1.equals(roaringBitmapAndNot2));
System.out.println("判断1与2是否相交: " + RoaringBitmap.intersects(roaringBitmapAndNot1, roaringBitmapAndNot2));
System.out.println("andNot1计算并返回基数: " + RoaringBitmap.andNotCardinality(roaringBitmapAndNot1, roaringBitmapAndNot2));
System.out.println("---");
print(andNot2, "计算bitmap2与bitmap1的差集: ");
System.out.println("统计基数: " + andNot2.getCardinality());
System.out.println("判断bitmap是否为空: " + andNot2.isEmpty());
System.out.println("判断1与2是否相等: " + roaringBitmapAndNot2.equals(roaringBitmapAndNot1));
System.out.println("判断1与2是否相交: " + RoaringBitmap.intersects(roaringBitmapAndNot2, roaringBitmapAndNot1));
System.out.println("andNot2计算并返回基数: " + RoaringBitmap.andNotCardinality(roaringBitmapAndNot2, roaringBitmapAndNot1));
System.out.println("======================");
private static void print(RoaringBitmap roaringBitmap, String message) {
System.out.print(message);
roaringBitmap.forEach((Consumer<? super Integer>) i -> System.out.print(i + " "));
System.out.println();
}
## result
and取交集后bitmap的值: 3
统计基数: 1
判断bitmap是否为空: false
判断1与2是否相等: false
判断1与2是否相交: true
AND计算并返回基数: 1
1中移除数字2: 1 3
bitmap1小于等于3的整数数目: 2
bitmap2中是否包含10: false
bitmap1中是否包含bitmapand: true
bitmap2中添加元素10: 3 4 6 10
bitmap1中添加元素6到8: {1,3,6,7,8,9,10}
添加完元素以后bitmap1的值: {1,3}
======================
or取并集后bitmap的值: 1 2 3 4 5
统计基数: 5
判断bitmap是否为空: false
判断1与2是否相等: false
判断1与2是否相交: true
or计算并返回基数: 5
======================
xor异或后取bitmap的值: 1 5
统计基数: 2
判断bitmap是否为空: false
判断1与2是否相等: false
判断1与2是否相交: true
xor计算并返回基数: 2
======================
andNot计算bitmap1与bitmap2的差集: 1 2
统计基数: 2
判断bitmap是否为空: false
判断1与2是否相等: false
判断1与2是否相交: true
andNot1计算并返回基数: 2
---
计算bitmap2与bitmap1的差集: 4 5
统计基数: 2
判断bitmap是否为空: false
判断1与2是否相等: false
判断1与2是否相交: true
andNot2计算并返回基数: 2
三、压缩位图精确去重UDAF实现
1、构造表以及数据
? ?1)构造的表名称:mart_grocery_crm.bitmap_count_distinct_test_spark
? ?2)mart_grocery_crm.bitmap_count_distinct_test_spark 表中的数据(user_id为int类型)
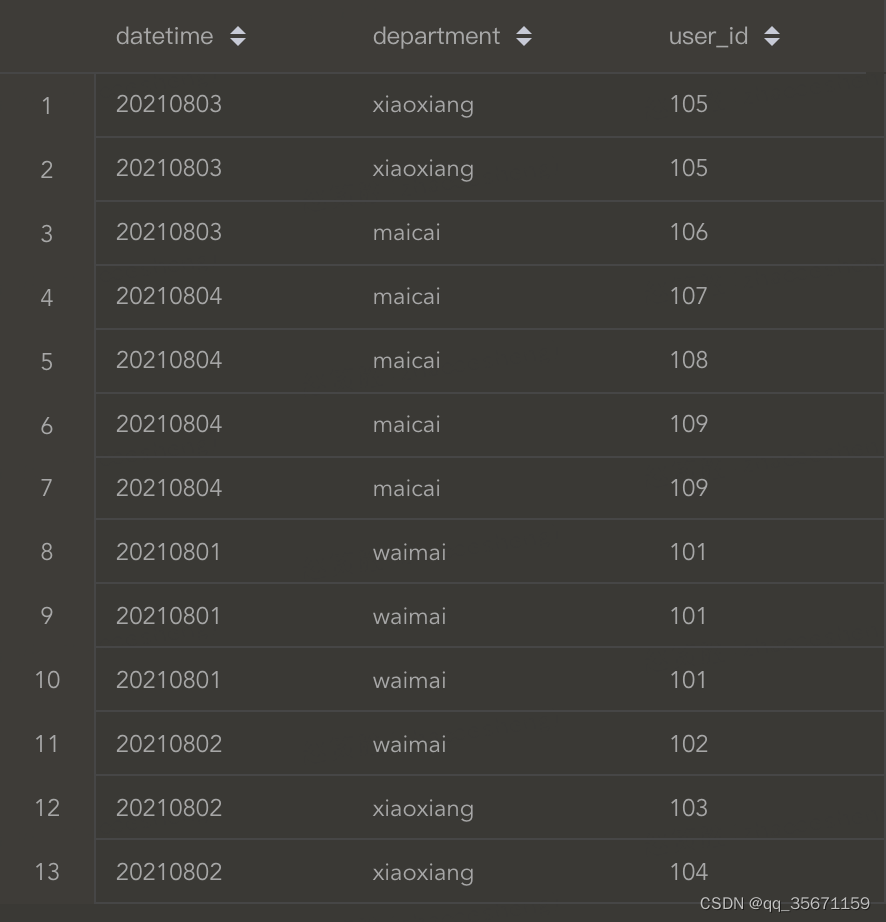
? ?3)通过SQL查看分组去重后的结果?
SELECT department, count(distinct user_id) FROM mart_grocery_crm.bitmap_count_distinct_test_spark GROUP BY department
--根据部门分组去重后的结果
――――――――――――――――――――――――――――――――――――――――――――――――
| department | `count`(DISTINCT `user_id`) |
|――――――――――――――――――――――――――――――――――――――――――――――|
| waimai | 2 |
|――――――――――――――――――――――――――――――――――――――――――――――|
| xiaoxiang | 3 |
|――――――――――――――――――――――――――――――――――――――――――――――|
| maicai | 4 |
|――――――――――――――――――――――――――――――――――――――――――――――| 2、编写UDAF
? ? ?1)继承 AbstractGenericUDAFResolver 抽象类,重写 getEvaluator 方法
/**
* @author zhaocesheng
* @since 2021/08/04
* 通过RoaringBitmap实现CountDistinct测试类
*/
public class RBMCountTestUDAF extends AbstractGenericUDAFResolver {
?
/**
* @param info UDAF方法入参
* @return 该方法可以实现不同的入参走不同的实现类里面的实现逻辑
* @throws SemanticException 可能会抛出语义异常错误
*/
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
// 校验长度
if (info.length > 1) {
throw new UDFArgumentTypeException(info.length - 1, "Exactly one argument is expected.");
}
// 校验类型
switch (((PrimitiveTypeInfo) info[0]).getPrimitiveCategory()) {
case INT:
break;
case BYTE:
case SHORT:
case LONG:
case FLOAT:
case DOUBLE:
case TIMESTAMP:
case DECIMAL:
case STRING:
case BOOLEAN:
case DATE:
default:
throw new UDFArgumentTypeException(0,"Only numeric type arguments are accepted but "
+ info[0].getTypeName() + " was passed as parameter 1.");
}
// 只有一个实现逻辑就是Count Distinct
return new RoaringBitmapCountEvaluator();
}
getEvaluator 方法的目的感觉有两个:
一个是校验函数入参的个数以及入参的类型
一个是根据不同的入参判断走哪个子类,不同的子类对应着不同的实现逻辑(本例中的子类只有一个,也就是实现逻辑只有一个)? ? ?2)实现类以及init方法
public static class RoaringBitmapCountEvaluator extends GenericUDAFEvaluator {
?
PrimitiveObjectInspector inputOI;
?
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
assert (parameters.length == 1);
super.init(m, parameters);
inputOI = (PrimitiveObjectInspector) parameters[0];
// map和combine阶段返回RoaringBitmap的二进制数组
if (m == Mode.PARTIAL1 || m == Mode.PARTIAL2) {
return PrimitiveObjectInspectorFactory.javaByteArrayObjectInspector;
}
// 只有map和reduce的情况返回一个Count Distinct之后的数值
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
1 实现类需要继承GenericUDAFEvaluator
2 Hive的执行过程其实是mapreduce的过程,可以分为四种情况
1)多个节点的map阶段收集数据 (对应着Mode.PARTIAL1)
2)combine阶段部分聚合每个节点中map阶段的数据(对应着Mode.PARTIAL2)
3)reduce阶段合并各个节点的数据(对应着Mode.FINAL)
4)有些情况map阶段之后直接输出结果(对应着Mode.COMPLETE)
在本例中map阶段和combine阶段输出的结果为RoaringBitmap的字节数组byte[],只有map阶段以及reduce阶段返回最终结果(int类型)
3 PrimitiveObjectInspector是全局输入输出数据类型的OI实例,用于解析输入输出数据(后续的方法中会用到)? ? 3)构建中间结果缓存Buffer
/**
* 构建自己的缓冲Buffer
*/
static class RoaringBitmapAgg implements AggregationBuffer {
RoaringBitmap rbm;
?
public byte[] serializeToByte() {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(bos);
try {
assert (rbm != null);
rbm.serialize(dos);
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
return bos.toByteArray();
}
?
public RoaringBitmap deSerializeFromByte(byte[] bytes) {
RoaringBitmap rbm = new RoaringBitmap();
DataInputStream dis = new DataInputStream(new ByteArrayInputStream(bytes));
try {
rbm.deserialize(dis);
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
return rbm;
}
?
}
?
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
RoaringBitmapAgg rbmBuffer = new RoaringBitmapAgg();
if (rbmBuffer.rbm == null) {
rbmBuffer.rbm = new RoaringBitmap();
} else {
reset(rbmBuffer);
}
return rbmBuffer;
}
?
@Override
public void reset(AggregationBuffer agg) throws HiveException {
RoaringBitmapAgg rbmBuffer = (RoaringBitmapAgg) agg;
if (rbmBuffer != null && rbmBuffer.rbm != null) {
rbmBuffer.rbm.clear();
}
}
1 RoaringBitmapAgg 类的目的是为了缓存 RoaringBitmap 聚集或者取并集后的部分结果
2 RoaringBitmapAgg 中的 serializeToByte 方法目的是为了将 RoaringBitmap 序列化成二进制流,在 map 或者 combine 阶段作为输出的结果使用
3 RoaringBitmapAgg 中的 deSerializeFromByte 方法目的是为了将二进制流反序列化成 RoaringBitmap,在 combine 或者 reduce 阶段将入参反序列化成 RoaringBitmap 后做合并计算时使用
4 getNewAggregationBuffer 方法在map阶段执行一次,目的是获取中间结果缓存对象
5 reset 方法mapreduce支持mapper和reducer的重用,所以为了兼容,也需要做内存的重用(不是很明白???)? ? ? 4)map阶段的iterate方法
/**
* map阶段各个节点将数据写入RoaringBitmap, 需要注意的是需要把参数转换成int类型
*
* @param agg buffer
* @param parameters 列值
* @throws HiveException UDF异常
*/
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
assert (parameters.length == 1);
RoaringBitmapAgg rbmBuffer = (RoaringBitmapAgg) agg;
if (rbmBuffer != null && rbmBuffer.rbm != null && parameters[0] != null) {
rbmBuffer.rbm.add(PrimitiveObjectInspectorUtils.getInt(parameters[0], inputOI));
}
}
1 该方法只会发生在 map 阶段
2 该方法的目的是为了聚集map阶段所在节点的有效数据
3 此处需要通过 PrimitiveObjectInspector 以及入参得到int类型的列值,然后将列值写入 RoaringBitmap
? ? ? 5)terminatePartial方法
/**
* map和combine阶段返回部分聚集结果
*
* @param agg buffer
* @return byte[]
* @throws HiveException UDF异常
*/
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
RoaringBitmapAgg rbmBuffer = (RoaringBitmapAgg) agg;
if (rbmBuffer != null) {
return rbmBuffer.serializeToByte();
}
return new Byte[0];
}
map 阶段或者 combine 阶段结束以后将结果序列化
? ? ?6)merge方法
/**
* combine和reducer阶段聚合数据
*
* @param agg buffer
* @param partial 部分聚集数据
* @throws HiveException UDF异常
*/
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
RoaringBitmapAgg rbmBuffer = (RoaringBitmapAgg) agg;
if (rbmBuffer != null && rbmBuffer.rbm != null) {
rbmBuffer.rbm.or(rbmBuffer.deSerializeFromByte((byte[]) partial));
}
}
combine 阶段或者 reduce 阶段将结果聚合在一起,本例中是将各个节点的 Roaringbitmap 取并集
? ? ? 7)terminate方法
/**
* 得到reduce后的最终结果
*
* @param agg buffer
* @return 取并集后的最终结果
* @throws HiveException UDF异常
*/
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
RoaringBitmapAgg rbmBuffer = (RoaringBitmapAgg) agg;
if (rbmBuffer.rbm != null) {
return rbmBuffer.rbm.getCardinality();
}
return -1;
}
输出 reduce 后的最终结果,该结果的类型与init方法中的定义的返回类型前后呼应3、UDAF的工作流程总览
? ? 1)方法执行流程
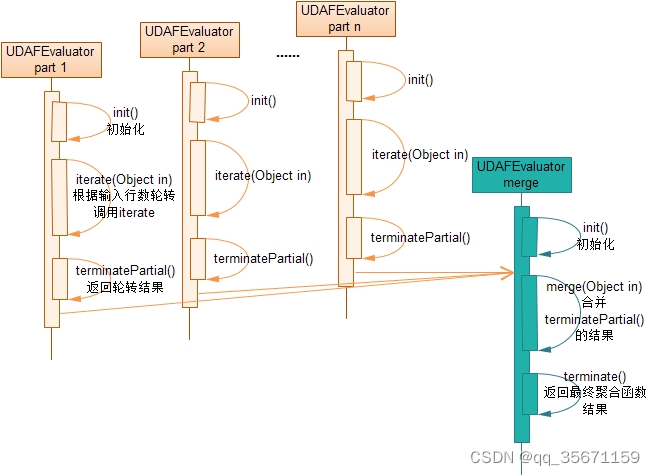
?
? ? 2)MR中数据流转流程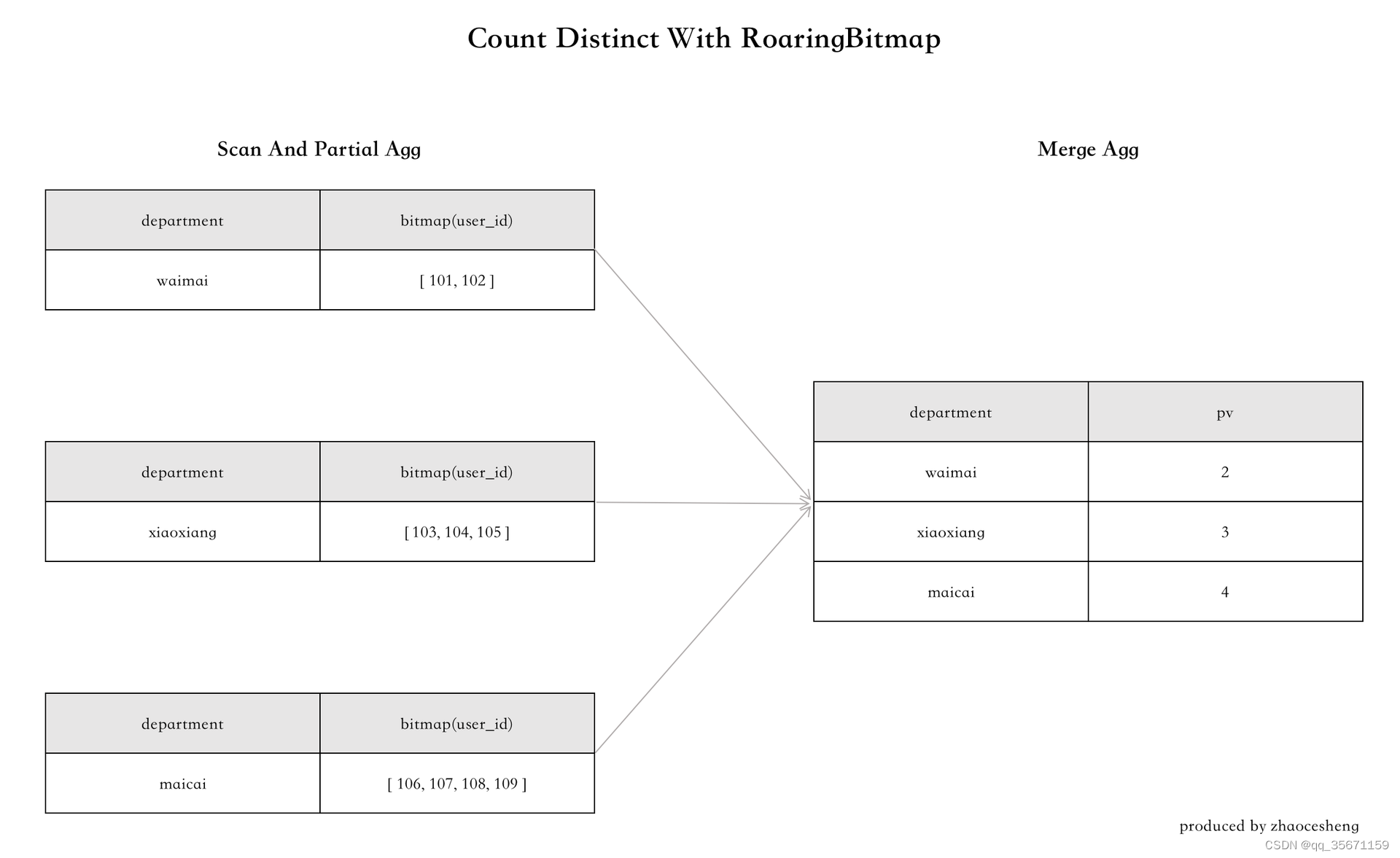
? ??? ?

