ађбд:
дкЗчПиФЃаЭПЊСїГЬжа,ЪЙгУЕФГЁОАЗжБ№гаAПЈЁЂBПЈЁЂCПЈЕШФЃаЭ,ГЃЙцЪЙгУзюЖрЕФОЭЪЧТпМЛиЙщЫуЗЈЁЃЪЙгУТпМЛиЙщЫуЗЈ80%ЛсЪЙгУЕФБрТыЗНЪНОЭЪЧWOEБрТы,ЯраХзіФЃаЭЕФЭЌбЇЖдетжжБрТыЗНЪНЗЧГЃЪьЯЄЁЃ
зіWOEЕФБрТыЕФКУДІ,ЮоашЖрбд,БШШчПЩНтЪЭадЧП,ЖдгкМЋЖЫжЕЛЙВЛашзіДІРэ,ЕЋдкГ§ТпМЛиЙщЕФЦфЫќГЁОАжаЪЧЗёвВФмЪЙгУетжжБрТыЗНЪН?СэЭтФЃаЭГЁОАжаЛЙгаФФаЉЦфЫќЕФБрТыЗНЪН?ЛЙгаWOEЪЧЗёПЩвдЬсЩ§МЏГЩЫуЗЈЕФаЇЙћ?ЙигкетаЉЮЪЬт,БОЮФ,ЗЌЧбЗчПиИјИїЮЛЖСепДјРДФЃаЭЕФБрТыЗНЪНЛузм,ЧвдкМЏГЩЫуЗЈжадЫгУwoeБрТыПЩвдНјвЛВНЬсЩ§ФЃаЭЕФзМШЗадЁЃ
БОДЮећЬхЕФФкШнНЯЖр,Г§СЫЙЋжкКХЩЯЕФФкШнИќЛсдкжЊЪЖаЧЧђЩЯЮЊДѓМвЬсЙЉБОДЮФкШнЫљЩцМАЕФЪЕВйЪ§ОнгыДњТы,ЪжАбЪжЪЕВйДјСьДѓМвСьТдећИіФЃаЭБрТыЗНЪНЕФФкШн,БОДЮећЬхФПТМШчЯТ:
PART 1.ЬиеїЗжРрКЭГЃМћЕФБрТыЗНЪН
1.1.ЬиеїНщЩм
1.2.ГЃМћЕФБрТыЗНЗЈНщЩм
PART 2.ЬиеїБрТыЕФгІгУГЁОА1ЈCLRЦРЗжПЈ
PART 3.ЬиеїБрТыЕФгІгУГЁОА2ЈCМЏГЩФЃаЭ
PART 4.ЪЕВйЈCСЌајаЭЬиеїКЭИпЛљЪ§ЬиеїЕФWOEБрТы(Ъ§ОнМЏ+ДњТыФкШн)
дкЗчПиФЃаЭПЊЗЂжа,ЬиеїБрТыЪЧЗЧГЃживЊЕФвЛИіВНжш,БОЮФНЋвРЭаТпМЛиЙщ,МЏГЩФЃаЭЕФСНИіЫуЗЈГЁОА,НщЩмЬиеїБрТыЕФЪЕМЪгІгУЗНЗЈЁЃ
Part1.ЬиеїЗжРрКЭГЃМћЕФБрТыЗНЪН
1.ЬиеїНщЩм
вЛАуЬиеїПЩЗжЮЊСЌајаЭЬиеїКЭРыЩЂаЭЬиеї,СЌајаЭжИдквЛЖЈЧјМфФкПЩвдШЮвтШЁжЕ,ЯрСкЕФСНИіЪ§жЕПЩзїЮоЯоЗжИю,Р§ШчЩэИпПЩвдЪЧ185,вВПЩвдЪЧ185.3,ЖјРыЩЂаЭЕФШЁжЕжЎМфВЛПЩзіЗжИю,жЛФмгУећЪ§,зжЗћЕШРДБэЪОРрБ№ЁЃДѓЖрЪ§ЕФБрТыЗНЗЈЖМЪЧеыЖдРыЩЂаЭЬиеїЕФ,РыЩЂаЭЬиеїгжПЩЗжЮЊ:
- АДееЪЧЗёЮЊЪ§жЕ:Ъ§жЕаЭКЭзжЗћаЭ
- АДееЪЧЗёгаЫГађЙиЯЕ:гаађКЭЮоађаЭ
- АДееРрБ№ЕФЪ§СП:ИпЛљРрКЭЕЭЛљРр,ИпЛљЪ§ЬиеїЕФРрБ№Ъ§вЛАудкМИАйЩѕжСМИЧЇИівдЩЯ,Р§ШчГЧЪаУћ,IPЕижЗ,ЕЭЛљЪ§ЬиеїЕФРрБ№Ъ§ОЭБШНЯЩй,жЛгаМИИіЛђМИЪЎИі,Р§ШчбЇРњ,ЪЁЗнЁЃ
УПжжЬиеїЪЪгУЕФБрТыЗНЗЈЪЧВЛвЛбљЕФ,ЯТУцЛсОпЬхНщЩмЕНЁЃ
2.ГЃМћЕФБрТыЗНЗЈНщЩм:
1)ЖРШШБрТы:жївЊеыЖдЮоађЕЭЛљЪ§РрЕФРыЩЂЬиеї,Р§ШчадБ№[Фа,ХЎ],ЭЈЙ§ЖРШШБрТыБфГЩЪЧЗёФа,ЪЧЗёХЎЕФ0,1Ьиеї,зЊЛЛКѓЕФЬиеїгжГЦЮЊбЦБфСПЁЃЖРШШБрТыНтОіСЫЫуЗЈВЛФмДІРэЪєадЪ§ОнЕФЮЪЬт,вВЦ№ЕНСЫРЉГфЬиеїЕФзїгУ,ЕЋШБЕуЪЧВЛЪЪКЯДІРэИпЛљЪ§Ьиеї,ЛљЪ§Й§ДѓЛсДјРДЙ§КмЖрСаЕФЯЁЪшЬиеї,ЯћКФФкДцКЭбЕСЗЪБМфЁЃ
2)БъЧЉБрТы:ЪЪгУгкгаађзжЗћаЭЕФРыЩЂЬиеї,Р§ШчбЇРњ,ДгИпжаЕНВЉЪПгаЫГађЙиЯЕ,БъЧЉБрТыжБНгНЋЦфРрБ№гГЩфГЩЪ§зж1,2,3Ё,ЪЕЯжаЮЪНМђЕЅЧвЖдгкЕЭЛљЪ§ЬиеївВКмгааЇ,ЕЋВЛНЈвщгУдкИпЛљЪ§ЕФЬиеїЩЯЁЃ
3)woeБрТы:woeДњБэСЫЬиеїЖдгкYБъЧЉЕФдЄВтФмСІ,ЭЈГЃБЛУшЪіЮЊЧјЗжКУПЭЛЇКЭЛЕПЭЛЇЕФКтСПБъзМ,ЪЧЗчПиНЈФЃжагІгУзюЙуЗКЕФБрТыЗНЗЈ,ВЛЙмЪЧСЌајаЭЛЙЪЧРыЩЂаЭ,РрБ№Ъ§ЖрЛЙЪЧЩй,woeБрТыЖМФмЪЪгУ,БОЮФвВЛсзХжиНВЫќЕФгІгУЗНЗЈЁЃ
4)ЦНОљЪ§БрТы:ЖдгкИпЛљЪ§РрЬиеї,ЦНОљЪ§БрТыЪЧвЛжжИпаЇЕФБрТыЗНЗЈ,НќМИФъвВдкИїРрОКШќжаБЛгІгУ,дкКѓУцМЏГЩФЃаЭЕФГЁОАжаЛсОпЬхНщЩмЕНЁЃ
5)ФЃаЭБрТы:ФПЧАЕФМЏГЩЫуЗЈжа,жЛгаlightgbmКЭcatboostжЇГжДІРэРрБ№аЭЕФЬиеї,lightgbmВЩгУЕФЪЧGSБрТы,НЋРрБ№ЬиеїзЊЮЊРлЛ§жЕ (вЛНзЦЋЕМЪ§жЎКЭ/ЖўНзЦЋЕМЪ§жЎКЭ)дйНјаажБЗНЭМЬиеїХХађ,ЖјcatboostЪЙгУOrdered TSБрТы,МШРћгУСЫTSЪЁПеМфКЭЫйЖШЕФгХЪЦ,вВЪЙгУOrderedЕФЗНЪНЛКНтдЄВтЦЋвЦЮЪЬт,ашвЊзЂвтЕФЪЧ,дкЫуЗЈбЕСЗЧА,ашвЊНЋзжЗћаЭЕФЬиеїгГЩфГЩЪ§жЕЁЃ
Part2.ЬиеїБрТыЕФгІгУГЁОА1ЈCLRЦРЗжПЈ
1.woeЕФМЦЫуЙ§ГЬ
WOE = ln (ЕкiИіЗжЯфЕФЛЕШЫЪ§ / змЛЕШЫЪ§) - ln (ЕкiИіЗжЯфЕФКУШЫЪ§ / змКУШЫЪ§)
етИіЙЋЪНПЩвдРэНтЮЊУПИіЯфЬхЛЕШЫЗжВМЯрБШгкКУШЫЗжВМЕФВювьад
НЋетИіЙЋЪНБфЛЛвЛЯТ:
WOE = ln (ЕкiИіЗжЯфЕФЛЕШЫЪ§ / ЕкiИіЗжЯфЕФКУШЫЪ§) - ln (змЛЕШЫЪ§ / змКУШЫЪ§)
ДЫЪБПЩвдРэНтЮЊУПИіЯфЬхЕФКУЛЕБШ(bin_odds)ИњзмЬхЕФКУЛЕБШ(all_odds)ЕФВювьад,woeПЩБэЪОЯфЬхЖдгкYБъЧЉЕФдЄВтФмСІ,ШчЙћwoeЮЊе§ЧвжЕдНДѓ,дђЯфЬхЕФЛЕгУЛЇИХТЪдНИп,woeЮЊИКжЕдНДѓдђЯфЬхЕФКУгУЛЇИХТЪдНИп,ЫљвдЫЕwoeгаКмКУЕФвЕЮёНтЪЭадЁЃдкwoeЕФМЦЫуЛљДЁЩЯ,ЛЙФмМЦЫуГіIV:
IV=sum([(ЕкiИіЗжЯфЕФЛЕШЫЪ§ / змЛЕШЫЪ§) - (ЕкiИіЗжЯфЕФКУШЫЪ§ / змКУШЫЪ§)]*woe),IVЬхЯжСЫећИіЬиеїЖдгкYБъЧЉЕФдЄВтФмСІЁЃ
вдФъСфетИіЬиеїЮЊР§,еЙЪОЯТwoeЕФМЦЫуЙ§ГЬ:
ЕквЛВН:ЖдФъСфНјааЗжЯф,МЦЫуУПИіЯфЬхЕФЛЕгУЛЇЪ§КЭКУгУЛЇЪ§
?
ЕкЖўВН:МЦЫуИїИіЯфЬхЕФКУЛЕБШ
?
ЕкШ§ВН:ЭЈЙ§КУЛЕБШМЦЫуУПИіЯфЬхЕФwoeКЭУПИіЯфЕФIV,зюКѓНЋУПИіЯфЕФIVМгзмОЭЪЧетИіЬиеїЕФIV
?
2.LRжазіwoeБрТыЕФКУДІ
1)woeБрТывЊзіЖдЬиеїЗжЯфРыЩЂЛЏ,ЖјЬиеїРыЩЂЛЏжЎКѓ,Ц№ЕНСЫМђЛЏФЃаЭЕФзїгУ,ЪЙФЃаЭБфЕУИќЮШЖЈ,НЕЕЭСЫФЃаЭЙ§ФтКЯЕФЗчЯе,ВЂЧвРыЩЂЛЏжЎКѓЕФЬиеїЖдвьГЃЪ§ОнгаКмЧПЕФТГАєадЁЃ
2)woeПЩДњБэЗжЯфИњзмЬхЕФКУЛЕБШВювь,гаКмКУЕФНтЪЭад,СэЭтдкЗчПиНЈФЃжа,ЮвУЧЯАЙпгкгУЯпадХаЖЯЬиеїЕФзїгУ,Р§ШчЕБЬиеїXдНДѓ,YдНаЁ,ЕЋОГЃXгыYДцдкзХЗЧЯпаЮЙиЯЕ,ДЫЪБwoeБрТыОЭФмДІРэетИіЮЪЬтЁЃ
3)woeФмДІРэШБЪЇжЕ,гЩгкLRВЛФмжБНгДІРэШБЪЇ,woeПЩвдАбШБЪЇЕЅЖРЗжЮЊвЛЯф,ЬсИпСЫЪ§ОнЕФРћгУТЪЁЃ
4)гЩгкБрТыКѓЬиеїЕФШЁжЕБфЩй,дкбЕСЗФЃаЭЪБФмИќПьЕФЪеСВ,ЬсИпСЫбЕСЗЫйЖШЁЃ
5)woeЛЏжЎКѓПЩвдМЦЫуУПИіЬиеїЕФIVжЕ,гУРДЩИбЁЬиеїЁЃ
3.woeдкЗжЯфЪБашвЊзЂвтЕФЕиЗН
1)ЗжЯфЪБбљБОСПвЊГфзу,БЃжЄЦфЭГМЦвтвхЁЃ
2)вЊГЏзХIVзюДѓЛЏЕФФПБъНјааЗжЯф,ЗжЯфЗНЗЈгазюгХЗжЯф,ПЈЗНЗжЯф,ОіВпЪїЗжЯф,ЕШЦЕКЭЕШОрВЛЬЋЪЪгУЁЃ
3)ЗжЯфЕФИіЪ§ВЛвЊЬЋЖрвВВЛвЊЬЋЩй,вЛАуПижЦдк4-8Иі,ЧвУПЯфЕФбљБОВЛФмЬЋЩй,жСЩйеМзмСПЕФ5%ЁЃ
4)ЯрСкЕФЯфЬхШчЙћwoeЯрЭЌ,ЛђепФГИіЯфЬхжЛгаЛЕгУЛЇЛђКУгУЛЇ,дђашвЊзіКЯВЂВ№ЗжЕФДІРэЁЃ
5)ЯфЬхжЎМфwoeБфЛЏвЊЗћКЯвЕЮёНтЪЭ,Р§ШчгтЦкДЮЪ§дНЖр,ЛЕЕФИХТЪдНДѓ,ФЧЗжЯфЕФwoeвВвЊБЃГжетИіТпМ,вЛАузюКѓЕФЗжЯфТпМЖМвЊЪжЖЏЕїећЙ§ЁЃ
6)ашвЊбщжЄПчЪБМфЩЯЗжЯфЕФКЯРэад,ШчЙћдкбЕСЗМЏЩЯwoeЪЧЕЅЕїЕФ,ЕЋдкOOTЩЯВЛЕЅЕї,ЫЕУїЗжЯфВЛКЯРэ,ашвЊзіЕїећЁЃ
4.woeвЛЖЈвЊЕЅЕїТ№?
woeВЛвЛЖЈвЊЕЅЕї,жЛвЊдквЕЮёЩЯНтЪЭЕФЭЈОЭааЁЃОйИіР§зг,ФъСфетИіЬиеї,ФъЧсШЫКЭРЯФъШЫЕФЛЙПюФмСІЛсБШжаФъШЫЕФвЊЕЭ,ЗчЯевВвђДЫИќИп,ВЛЪЧГЪЕЅЕїЕФЙиЯЕЁЃСэЭтгааЉЮвУЧШЯЮЊгІИУЕЅЕїЕФЬиеїЪЕМЪБэЯжШДВЛЕЅЕї,Р§ШчЖрЭЗЬиеї,вЛАуШЯЮЊЪЧЖрЭЗдНЖрдНЛЕ,ЕЋНсКЯФПЧАЕФаХДћЛЗОГ,ЖрЭЗДЮЪ§ЖрПЩФмЪЧвђЮЊгУЛЇзЪжЪКУВХФмНшЕНИќЖрЕФЛњЙЙ,ЫљвдЪЕМЪЕФwoeБэЯжвВФмДјИјЮвУЧаТЕФЫМПМ,ДђЦЦжЎЧАЕФЙЬгаЫМЮЌЁЃ
5.woeЪЧЗёДцдкЙ§ФтКЯЕФЮЪЬт
ЛсШнвздьГЩЙ§ФтКЯ,ЕЋВЛЪЧwoeБрТыЕФЮЪЬт,ЖјЪЧЗжЯфМАгУЕНСЫYБъЧЉЕМжТЁЃШчЙћЮвУЧгУЕШЦЕ/ЕШОретжжЮоМрЖНЗжЯф,Й§ФтКЯЕФЗчЯеЛсДѓДѓНЕЕЭ,ЕЋЕШОрЪмЗжВМгАЯь,ЕШЦЕЖдРыЩЂжЕВЛгбКУ,ВЂЧвЧАЮФЬсЕНвЊГЏзХIVзюДѓЛЏЕФФПБъ,ЫљвдЛсгУПЈЗН,ОіВпЪїетжжв§ШыYБъЧЉЕФЫуЗЈРДжИЕМЗжЯфЁЃwoeБрТы+LRЦфЪЕРрЫЦМЏГЩбЇЯАЕФдРэ,МЏГЩбЇЯАОЭЪЧАбЕквЛВуФЃаЭЕФНсЙћзіЮЊЕкЖўВуФЃаЭЕФЪфШы,СНВуФЃаЭЖМЪЧвдYБъЧЉЮЊФПБъЕФ,LRжаЕФЕквЛВуФЃаЭОЭЪЧwoeЗжЯфБрТы,ЫљвдвВИњМЏГЩЫуЗЈвЛбљШнвзЙ§ФтКЯЁЃЪЕМЪПЊЗЂLRЪБ,ЮвУЧВЛЛсжБНггУПЈЗН/ОіВпЪїЕФЗжЯфНсЙћ,ЖјЛсЪжЖЏЖдЗжЯфзіЕїећ,вЛЗНУцЮЊСЫНтЪЭад,СэвЛЗНУцОЭЪЧдМЪјЗжЯфЕФЬѕМўРДНЕЕЭЙ§ФтКЯЗчЯеЁЃ
Part3.ЬиеїБрТыЕФгІгУГЁОА2ЈCМЏГЩФЃаЭ
1.МЏГЩФЃаЭжагІгУЖРШШБрТыЕФзЂвтЕу
ЧАЮФЬсЕН,ЖРШШБрТы(one-hot)ЕФзюДѓШБЕудкгк,ЖдгкРрБ№Ъ§КмЖрЕФЬиеї,жБНгonehotЛсЩњГЩИпЮЌЕФЯЁЪшЬиеї,ЖјМЏГЩФЃаЭУцЖдИпЮЌЯЁЪшЬиеї,ЛЎЗжДЮЪ§ШнвздіЖр,ЪїЕФВуМЖШнвзМгЩю,етбљЛсЕМжТЙ§ФтКЯ,ЫљвдЖРШШБрТыдкМЏГЩФЃаЭРяЪЪгУгкРрБ№Ъ§ЩйЕФЬиеї,вЛАуРрБ№Ъ§вЊдк5вдЯТЁЃСэЭтЛЙЛсУцСйСНжжЧщПі:
1)ВтЪдМЏГіЯжбЕСЗМЏжаУЛгаЕФаТРрБ№,ФЧаТРрБ№ЕФonehotЬиеїЪЧУЛгадкШыФЃзжЖЮРяЕФ,ПЩвдКіТдЕє
2)бЕСЗМЏжаЕФРрБ№УЛгадкВтЪдМЏжаГіЯж,ФЧетИіРрБ№ЕФonehotЬиеїдкВтЪдМЏРяЕФжЕЖМЩшЮЊ0ДІРэ
2.lightgbmздЩэДІРэРрБ№аЭЬиеїЕФТпМ
ЮЊСЫНтОіЩЯЪіЖРШШБрТыЕФЮЪЬт,lgbВЩгУGSБрТы,МДMany vs ManyЕФЧаЗжЗНЪН,МђЕЅРДЫЕ,ЪЧЭЈЙ§ЖдУПИіРрБ№ШЁжЕНјааЪ§жЕБрТы,ИљОнБрТыЕФЪ§жЕбАевНЯгХЧаЗжЕу,ЪЕЯжСЫРрБ№ЬиеїМЏКЯЕФНЯгХЧаЗж,ОпЬхЕФЪЕЯжТпМЮЊ:
1)ЕБЬиеїЕФРрБ№Ъ§<=4(ВЮЪ§max_cat_to_onehot),ЛсжБНгonehotБрТы,ж№ИіЩЈУшУПвЛИіbinШнЦї,евГізюМбЗжСбЕуЁЃ
2)ЕБЬиеїЕФРрБ№Ъ§>4,ЛсЭГМЦИїИіРрБ№ЖдгІбљБОЕФвЛНзКЭЖўНзЬнЖШжЎКЭ,вдвЛНзЬнЖШжЎКЭ / (ЖўНзЬнЖШжЎКЭ + е§дђЛЏЯЕЪ§)зїЮЊИУЬиеїШЁжЕЕФБрТыЁЃНЋРрБ№зЊЛЏЮЊЪ§жЕБрТыКѓ,ДгДѓЕНаЁХХађ,БщРњжБЗНЭМбАевзюгХЕФЧаЗжЕу,Р§ШчЖдгкРрБ№ЮЊA-EЕФЬиеї,ШЁжЕЮЊA,CЕФЬнЖШНЯДѓ(ЗжРрФбЖШИп),дђзюгХЕФЗжИюЕуЮЊ[A,C] vs [B,D,E]ЁЃ
дкгУlgbздДјЕФБрТыЪБ,ШчЙћЬиеїЮЊзжЗћаЭ,ашвЊЯШНЋзжЗћгГЩфЮЊЗЧИКећЪ§жЕ(БъЧЉБрТы)дйДјЕНФЃаЭРябЕСЗ,НЋРрБ№аЭЬиеїlistЗХдкfitВЮЪ§жаЕФcategorical_featureМДПЩЁЃ
?
3.МЏГЩФЃаЭЪЧЗёгаБивЊЖдСЌајаЭЬиеїБрТы
ЪЧУЛгаБивЊЕФ,ВЛЭЌгкLR,МЏГЩФЃаЭЕзВуЫуЗЈЪЧОіВпЪї,ОіВпЪїБОЩэОЭЪЧбАевзюгХЗжИюЕуРДЛЎЗжбљБО,ЯрЕБгкзіСЫЗжЯфВйзї,ШчЙћЬсЧАЖдСЌајаЭЬиеїзіСЫЗжЯф,ФЧПЩФмОЭевВЛЕНзюгХЗжИюЕуСЫ,ЧвЬиеїШЁжЕБфЩйМЏГЩФЃаЭЕФЬнЖШЬсЩ§гХЪЦЛсМѕШѕ,ЕМжТФЃаЭаЇЙћЕФЯТНЕЁЃВЛЙ§ЮвУЧПЩвдЛЛвЛжжЫМТЗ,ЭЈЙ§СЌајЬиеїРыЩЂЛЏЙЙНЈзщКЯНЛВцЕФаТЬиеї,в§ШыИќЖрЕФЗЧЯпад,ЫЕВЛЖЈФмЬсЩ§ФЃаЭЕФаЇЙћЁЃ
4.ИпЛљЪ§ЬиеїдѕУДДІРэБШНЯКУ
ИпЛљЪ§ЬиеїЕФР§зг:IPЕижЗ,ГЧЪаУћ,МвЭЅзЁжЗ,ЩшБИidЕШ,етРрЬиеїЕФРрБ№Ъ§жСЩйЪЧГЩАйЩЯЧЇЕФ,гУЖРШШКЭБъЧЉБрТыЖМВЛЬЋаа,етРяЬсЙЉШ§жжНтОіЗНЗЈ:
1)жБНггУlightgbm,catboostздДјЕФБрТыЗНЗЈ,гХЕуЪЧВйзїМђЕЅ,ШБЕуЪЧЬиеїЛљЪ§ЬЋЖрШнвзЙ§ФтКЯ,ЧвЛсЯћКФдЫЫуЪБМф,зюКУЪЧЯШзівЛЯТОбщЕФКЯВЂМѕЩйРрБ№Ъ§,ФЃаЭаЇЙћПЩФмЛсИќКУЁЃ
2)гУwoeБрТыРДзіКЯВЂ,МѕЩйРрБ№Ъ§ЁЃЯШЯожЦКУКЯВЂКѓЕФРрБ№Ъ§КЭРрБ№ЕФзюаЁеМБШ,ШЛКѓМЦЫуУПИіРрБ№ЕФbadrateВЂХХађ,ИљОнbadrateзщФкВювьаЁ,зщМфВювьДѓЕФддђНјааРрБ№жЎМфЕФКЯВЂ,жБЕНТњзуЯоЖЈЬѕМўЭЃжЙКЯВЂ,ШЛКѓНЋКЯВЂКѓЕФаТРрБ№гГЩфЮЊwoeжЕ,етбљзіЯрЕБгкЖдИпЛљЪ§ЬиеїзіСЫЗжЯфДІРэ,ОпЬхЕФДњТыЪЕЯжЙ§ГЬдкЪЕВйpartжаЛсНВЕНЁЃЮвУЧЪЕбщБШНЯЙ§woeБрТыКЭФЃаЭБрТыЖдгкИпЛљЪ§ЬиеїЕФДІРэаЇЙћ,woeБрТыЛсИќКУвЛЕуЁЃ
3)гУЦНОљЪ§БрТы,ЦНОљЪ§БрТыИњwoeвЛбљвВЪЧгаМрЖНЕФБрТыЗНЗЈ,ЫќгУЕНСЫЯШбщКЭКѓбщИХТЪЕФЫМЯы,МйЩшФГИіИпЛљЪ§ЬиеїAгаNИіРрБ№,ОпЬхФГИіРрБ№гУnБэЪО:
ЯШбщИХТЪ:P(Y=1) = YЮЊ1ЕФЪ§СП / бљБОСП
КѓбщИХТЪ:ЬиеїЪєгкФГвЛРрБ№ЪБЕФИХТЪP(y=1|A=n) = YЮЊ1ЧвAЮЊnЕФЪ§СП / AЮЊnЕФЪ§СП
ЦНОљБрТыЕФЫМЯыОЭЪЧНЋЬиеїAжаУПИіРрБ№n,ЖМБэЪОЮЊЙРЫуЕФyЕФИХТЪp(ЙРЫуЕФгУаЁаДPБэЪО),НЋnгГЩфЮЊpЭъГЩБрТыЁЃЙРЫуЕФpгІЕБЪЧЯШбщИХТЪгыКѓбщИХТЪЕФвЛИіЭЙзщКЯ,гЩДЫЮвУЧв§ШыЯШбщИХТЪЕФШЈжиtРДМЦЫуpЁЃ
p(A=n) = t*P(Y=1) + (1-t)*P(y=1|A=n)
ШЈжиtгавдЯТЕФЬиад:
- ШчЙћВтЪдМЏжаГіЯжСЫаТЕФРрБ№(ЮДдкбЕСЗМЏжаГіЯж),ФЧУДt=1ЁЃ
- РрБ№дкбЕСЗМЏФкГіЯжЕФДЮЪ§дНЖр,КѓбщИХТЪЕФПЩаХЖШдНИп,ЦфШЈжиtвВдНДѓ
ЦНОљЪ§БрТыЛЙгУСЫНЛВцбщжЄЕФЗНЗЈРДНЕЕЭЙ§ФтКЯ,ФПЧАБЛШЯЮЊЪЧДІРэИпЛљЪ§ЕФвЛжжгааЇЪжЖЮ,ОпЬхЕФДњТыЪЕЯжДѓМвПЩвддкЭјЩЯевевзЪСЯ,етРяВЛзізИЪіЁЃ
зюКѓзівЛЯТаЁНс:
1/2/3/4/5Ё
(ПЩвдгХЯШвЦВНжЊЪЖаЧЧђ,ВЮМћЯъЯИФкШн)
СэЭтдкЕкЫФВПЗж,ЮвУЧЛЙЛсИњДѓМвДјРДЙигкБОДЮЕФЪЕВйФкШн(ВЮМћЪ§ОнМЏгыДњТы),вЛВНВННјааФкШнЪЕВйЁЃжївЊЕФФкШнАќРЈ:
1.ОіВпЪїМЦЫуwoeЕФБрТы
2.ИпЛљЪ§МЦЫуwoeБрТы
3.ФЃаЭжаЕФwoeБрТыЕФЬсЩ§аЇЙћЖдБШ
ВПЗжФкШнВЮПМШчЯТ:
Part4.ЪЕВйЈCСЌајаЭЬиеїКЭИпЛљЪ§ЬиеїЕФWOEБрТы
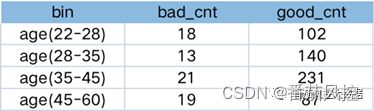
ЕМШыЪ§Он(woe_data.csv),бљБОСПЮЊ10000,АќКЌidзжЖЮ,y_label(YБъЧЉ),score(ЗчЯеЦРЗж,СЌајаЭЬиеї),city(гУЛЇЖЈЮЛГЧЪа,ИпЛљЪ§РрБ№Ьиеї),КЭЦфЫћФфУћЬиеї,ЖдscoreЮвУЧВЩгУЛљгкОіВпЪїЗжЯфЕФwoeБрТы,ЖдcityЭЈЙ§ЛљгкКЯВЂЕФЗНЗЈНјааwoeБрТыЁЃ
вЛ.ОіВпЪїЗжЯфЕФwoeБрТы
1.ЯШЖЈвхЩњГЩОіВпЪїЗжЯфТпМЁ
2.ЖЈвхЗжЯфМЦЫуwoeЕФКЏЪ§Ё
3.ЕїгУКЏЪ§ЪфГіЁ
(ЯъМћжЊЪЖаЧЧђФкШн)
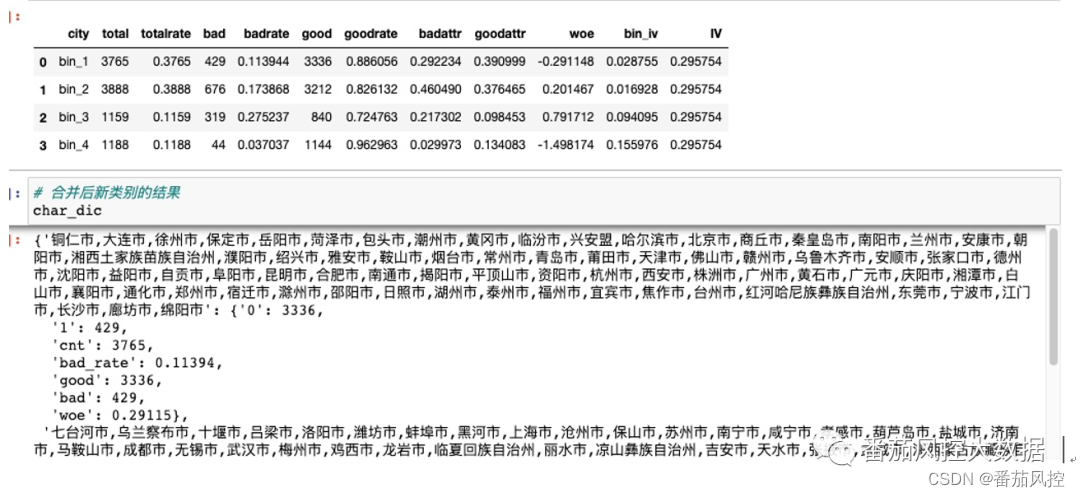
Жў.ИпЛљЪ§ЬиеїЕФwoeБрТы
1.ЖЈвхКЯВЂРрБ№ЕФКЏЪ§Ё
2.ЖЈвхКЯВЂРрБ№КѓМЦЫуwoeЕФКЏЪ§Ё
3Ё (ЯъМћжЊЪЖаЧЧђФкШн)
?
Ш§.woeБрТыКЭФЃаЭБрТыдкМЏГЩФЃаЭжаЕФаЇЙћЖдБШ
1/2/3Ё,ЪЕВйВПЗжЯъМћжЊЪЖаЧЧђФкШн
ЁЪЃЯТЕкЕкЫФВПЗж,вђЦЊЗљЙиЯЕ,ЯъЧщПЩвдвЦВНжЊЪЖаЧЧђВЮПМЭъећЯъАцФкШн~
?
СэЭт,ЙигкНќЦкЗЌЧбЗчПиЙигкФЃаЭЯрЙиЕФЪЕВйФкШн,ИќПЩвдЭЌВНжСжЊЪЖаЧЧђКѓЬЈ,ВщПДЭъећАцБОЪ§ОнМЏ+ДњТыФкШн,ЛЖгаЧЧђЭЌбЇвЦВНЕНжЊЪЖаЧЧђВщЪеЭъећФкШн:
?
Ё
~дДДЮФеТ

