----------------��Ŀ-------------------
��ӰʦС��������Ӱ,��������Ƭ(��ͬ��ʽ,��ͬ�ֱ���),�е����Լ������,�е������ѵ������æ�ĵ��ġ�
�����ܿ���,��Ϊ�кܶ���Ƭ�����Ƶ�(����,��ƫ��һ��Ƕ�),���ó�����������Ƶ�ͼƬ��ѡ������
1.������(����ĩβ������)
����120��ͼƬ,��ʽ��png,jpg��ռһ��,�������ִ�С1:1,4:3,full ���֡�
2.ʵ�����˼·
(1)ͳһͼƬ��ʽ,������һ���ıȽϡ���300300��png��ʽ��
(2)��������ͼƬ֮��ľ���,�ж�ͼƬ���Ƶ����ƶ���ֵ
����ͼƬ֮��ľ����кܶ��ַ���,��ѡ���˼���ͼƬ֮����������ƶȡ�
���ƶ���ֵ��ȷ��:����һ�����Ƶ���Ƭ�ɶԳ��ֵ�����,ͨ������ÿһ�Ե����ƶ�ֵ,ѡȡ��С�Һ�����ֵΪ��ֵ(0.86),����Ϊ�����ƶȴ������ֵʱ,��ɾȥ����һ�š�
3.ͼƬȥ��
����ɸѡ�����Ľ��,�������ǵ���ֵ(0.87),�ٽ�һ���õ����õĽ����
4.ʵ�����
����ʵ��������,����ʱ�����(6Сʱ),Ч�����Ǻܺõ�,���õ���36����ͬͼƬ��������취����һ��ʱ��,���ֿ���ͨ������ͼƬ�ı����ʹ�С,������4������,�ó�����������ٶ�ͼ(ֻ����4�����ǿɿ���)��
����,��������ʹ��100100��ͼƬ����ʵ��ͼƬȥ��,���õ�35��ͼƬ,ֻ�����˰��Сʱ,����˵�Ƿdz�ֵ����,������ͨ��������ֵ(0.88)���ֲ���
3.����ʵ��
(1)������
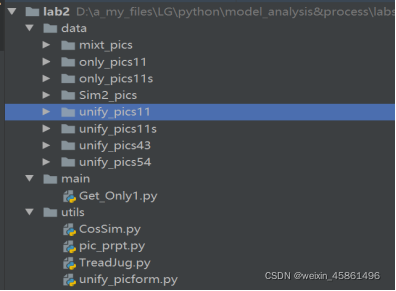 data�ļ���:
data�ļ���:
mixt_pics�CԭʼͼƬ,����Ų�ͬ��ʽ�ʹ�С��120��ͼƬ;
Sim2_pics�C����ijɶ�����ͼƬ�ļ�;
unify_picsxx:��ԭʼͼƬͳһ��ʽΪ.png,xx��ȡ��������4��ֵ,��ͬ;
only_picsxx:ȥ�غ�õ���ͼƬ��,xx��ζ���Ƕ��������͵�ȥ�ء�
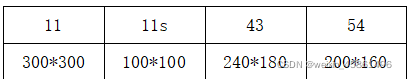
utils�ļ���:
CosSim.py�C��������ͼƬ���������ƶ�;
pic_prpt.py�C�����Բ�ͬ�����Ĵ����ٶ�����;
TreadJug.py�C�ҵ�����ͼƬ�ĺ��������ƶȷֽ�� threadholdjudge(���������ָ����ֻƫ��һ��Ƕ�);
unify_picform.py�CͳһͼƬ�Ĵ�С��ʽ��
(2)��Ҫ����
unify_picform.py
#ʹ������Ƭ�Ĵ�С��ͳһΪ300*300,��ʽͳһΪ.png unify_pics11
#ʹ������Ƭ�Ĵ�С��ͳһΪ240*180,��ʽͳһΪ.png unify_pics43
#ʹ������Ƭ�Ĵ�С��ͳһΪ200*160,��ʽͳһΪ.png unify_pics54
#ʹ������Ƭ�Ĵ�С��ͳһΪ100*100,��ʽͳһΪ.png unify_pics11s
import cv2
import os
outtype = '.png' # <---------- �����ͳһ��ʽ
image_size_w = 200 # <---------- �趨��
image_size_h =160 # <---------- �趨��
source_path = "../data/mixt_pics/" # <---------- Դ�ļ�·��
target_path = "../data/unify_pics54/" # <---------- ���Ŀ���ļ�·��
if not os.path.exists(target_path):
os.makedirs(target_path)
image_list = os.listdir(source_path)
# ����ļ���,����ط���˳������,���ô������ݼ�,���±��
#list(120)[''0.jpg'',''1.jpg'',....����]
i = 0
for file in image_list:
image_source = cv2.imread(source_path + file) # ��ȡͼƬd
print("������-->",file)
image = cv2.resize(image_source, (image_size_w, image_size_h), 0, 0, cv2.INTER_LINEAR)
# �ijߴ�
cv2.imwrite(target_path + str(i) + outtype, image)
# ���������ұ��� (ͳһͼƬ��ʽ)
i = i + 1
print("�����������")
CosSim.py
# ��������ͼƬ���������ƶ�
from numpy import average, linalg, dot
def CosSim(image1, image2):
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
res = dot(a / a_norm, b / b_norm)
return res
TreadJug.py
#�ҵ�����ͼƬ�ĺ��������ƶȷֽ�� threadholdjudge(���������ָ����ֻƫ��һ��Ƕ�)
#�Ƚ�unify_pics�����е�ͼƬ���ļ��и��Ƶ�Sim2_pics�ļ�����,�˹�ɸѡ���ɶԵ����Ƶ�ͼƬ
import datetime
import time
import os
from PIL import Image
from utils.CosSim import CosSim
#��������������������������������������������������������������������������������������������������������������������������������������������#
start_dt = datetime.datetime.now()
print("start_datetime:", start_dt)
time.sleep(2)
for i in range(10000):
i += 1
#��������������������������������������������������������������������������������������������������������������������������������������������#
Sim2_pics_path = "../data/Sim2_pics/"
Sim2_image_list = os.listdir(Sim2_pics_path)
Sim2_image_list.sort(key=lambda x:int(x[:-4]))
#��Sim2_pics�����ͼƬ�ź���
Sims = []
for i in range(0,len(Sim2_image_list),2):
img0 = Image.open(Sim2_pics_path+Sim2_image_list[i])
img1 = Image.open(Sim2_pics_path+Sim2_image_list[i+1])
sim = CosSim(img0,img1)
Sims.append(sim)
print(Sims)
#��������ᷢ����һЩ������������,�ۻ�������,����ֱ�ӳɶ�ɾ������
#[0.9619623054567803, 0.9616339735852711, 0.9096149655317833, 0.9668034186000998, 0.9763342316609243, 0.8898721390144304, 0.9794886082631756, 0.8855574201574012, 0.8608441002718709, 0.9635481853715363, 0.903659455613319, 0.9006432345661939, 0.8732949568357835, 0.9629020059033538, 0.9170403900886609, 0.8702003480765763, 0.874373609783053, 0.9537583041067714, 0.8669105262204524, 0.9890501169546155, 0.9603054463979213, 0.9010165189044402, 0.9164895782283211, 0.951835633174128, 0.928385154992327, 0.9794886082631756]
print(min(Sims))
#0.8608441002718709
#�����������Ϊ���ƶȵ���0.86���Dz����Ƶ�����ͼƬ
#��������������������������������������������������������������������������������������������������������������������������������������������#
end_dt = datetime.datetime.now()
print("end_datetime:", end_dt)
print("time cost:", (end_dt - start_dt).seconds, "s")
#��������������������������������������������������������������������������������������������������������������������������������������������#
pic_prpt.py
#�����Բ�ͬ�����Ĵ����ٶ�����
import datetime
import time
import matplotlib.pyplot as plt
from PIL import Image
import os
from utils.CosSim import CosSim
pics_path11 = "../data/unify_pics11/"
pics_list11 = os.listdir(pics_path11)
pics_path11s = "../data/unify_pics11s/"
pics_list11s = os.listdir(pics_path11s)
pics_path43 = "../data/unify_pics43/"
pics_list43 = os.listdir(pics_path43)
pics_path54 = "../data/unify_pics54/"
pics_list54 = os.listdir(pics_path54)
Pro_time = []
paths = [pics_path11,pics_path11s,pics_path43,pics_path54]
lists = [pics_list11,pics_list11s,pics_list43,pics_list54]
for i in range(len(paths)):
start_t = datetime.datetime.now()
#ͨ������20�� CosSim(img0,img1) ����,�Ƚ϶Բ�ͬ������ͼƬ�Ĵ���Ч��
for j in range(0,40,2):
img0 = Image.open(paths[i]+lists[i][j])
img1 = Image.open(paths[i]+lists[i][j+1])
similar = CosSim(img0,img1)
end_t = datetime.datetime.now()
Pro_time.append((end_t - start_t).seconds)
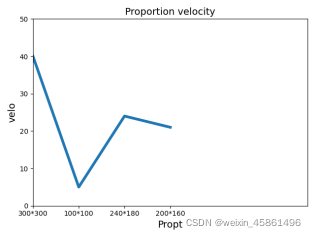
print(Pro_time)
x_name = ['300*300','100*100','240*180','200*160']
plt.plot(x_name, Pro_time, linewidth=4)
plt.title("Proportion velocity",fontsize=14)
plt.xlabel("Propt", fontsize=14)
plt.ylabel("velo", fontsize=14)
#���ÿ̶ȱ��
plt.tick_params(axis='both', labelsize=10)
plt.axis([0, 6, 0, 50])
plt.show()
Get_Only1.py
# ���Ƚ���һ��ͼƬ���only1�ļ���,Ȼ��ÿһ��һ��ͼƬ�ʹ����һ�ſ�ʼ�Ƚ�,����������е�ͼƬ�ʹ������
import datetime
import time
#��������������������������������������������������������������������������������������������������������������������������������������������#
start_dt = datetime.datetime.now()
print("start_datetime:", start_dt)
time.sleep(2)
for i in range(10000):
i += 1
#��������������������������������������������������������������������������������������������������������������������������������������������#
from PIL import Image
import os
from utils.CosSim import CosSim
import cv2
from tqdm import tqdm
import shutil
# pics_path = "../data/unify_pics11/".
# picsonly_path = "../data/only_pics11/"
pics_path = "../data/unify_pics11s/"
picsonly_path = "../data/only_pics11s/"
pics_list = os.listdir(pics_path)
pics_list.sort(key=lambda x:int(x[:-4]))
#�������ư�ͼƬ˳���ź�
threshold = 0.87 #Ϊ0.86ʱ,Ч��������,������һЩ�������Ƶ�ͼƬ���ж�Ϊ����,����������ƶ�
piconly_names = [pics_list[0]]
outtype = ".png"
if not os.path.exists(picsonly_path):
os.makedirs(picsonly_path)
shutil.rmtree(picsonly_path)
os.mkdir(picsonly_path)
##ע��ʹ��CosSim����ʱ������
for i in tqdm(range(1,len(pics_list))):
img0 = Image.open(pics_path+pics_list[i])
flag = 1
for j in range(len(piconly_names)-1,-1,-1):
img1 = Image.open(pics_path+piconly_names[j])
print("\n���ڱȽ�ԭʼ��{}��ͼƬ��ȥ�غ�ĵ�{}��ͼƬ".format(i,j))
similar = CosSim(img0,img1)
if CosSim(img0,img1) >= threshold:
flag = 0
break
if flag:
piconly_names.append(pics_list[i])
for _ in range(len(piconly_names)):
pico = cv2.imread(pics_path + piconly_names[_])
cv2.imwrite(picsonly_path + str(_) + outtype, pico)
#��������������������������������������������������������������������������������������������������������������������������������������������#
end_dt = datetime.datetime.now()
print("end_datetime:", end_dt)
print("time cost:", (end_dt - start_dt).seconds, "s")
#��������������������������������������������������������������������������������������������������������������������������������������������#
4.ʵ��Ч��
(1)ԭʼ���ݼ�(�鿴����)
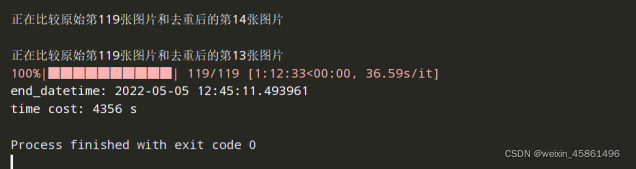
(2)����ʱ��Ա�
����300300ʱ,������4356s��
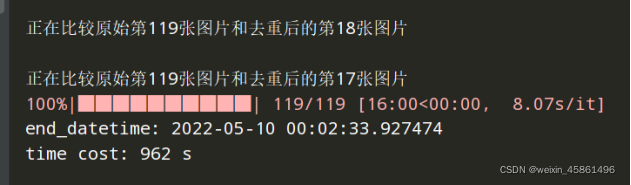
����100100ʱ,������962s��
(3)ȥ�غ�ͼƬ��(ǰ����ͨ��300300�õ���36��,������ͨ��100100�õ���35��)
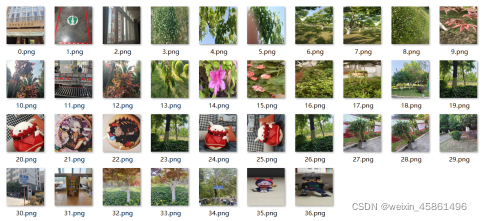
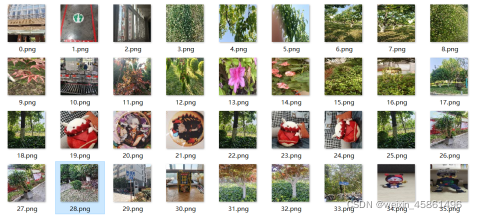
�����յĽ����,���ǻ����ϴﵽ��ȥ��(ȥ��ֻƫ��һЩ�Ƕȵ�ͼƬ)��Ŀ��,�����Կ�����һЩ��ת�ǶȽϴ��ͼƬ(24.png,25.png)û�б�ȥ��,��ʶ��һ�ַ����CSIFT�㷨�����ҵ���ת�Լ��߶Ȳ����������,�ҳ�����һ��,����Ч������(������main��debig_shift.py):

# ����Щ��ת�ϴ�Ƕȵ�ͼƬȥ��
import cv2
import numpy as np
#��ȡͼƬ�ؼ������������
def detectAndDescribe(image):
# ����ɫͼƬת�ɻҶ�ͼ
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# SIFT������
destriptor = cv2.SIFT_create()
kps, features = destriptor.detectAndCompute(gray, None)
# ���ת��numpy����
kps = np.float32([kp.pt for kp in kps])
return (kps, features)
#����ƥ��
def matchKeyPoints(kpsA, kpsB, featuresA, featuresB, ratio=0.75, reprojThresh=4.0):
# ��������ƥ����
matcher = cv2.BFMatcher()
# KNN�����������ͼƬ��SIFT����ƥ���
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
#Ԫ������,924��
matches = []
for m in rawMatches:
# �����������ν�����ı�ֵС��ratioʱ,���������
# (<DMatch 000001B1D6B605F0>, <DMatch 000001B1D6B60950>) ��ʾ����featuresA��ÿ���۲��,�õ������������B�е������ؼ�������
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# �洢��������featuresA, featuresB�е�����ֵ
matches.append([m[0].trainIdx, m[0].queryIdx])
# ������ô�о�ֻ����m[0]Ҳ����������Ǹ�������,Ӧ��û�õ�������
# ���m[0].trainIdx��ʾ��ʱ��������B�е�����λ��, m[0].queryIdx��ʾ��ʱA�еĵ�ǰ�ؼ������������
# ��ɸѡ���ƥ��Դ���4ʱ,�������������ӽDZ任����
if len(matches) > 4:
# ��ȡƥ��Եĵ�����
#��Ҫ���Ǵ�ͼƬB�и�ͼƬA�еĹؼ����������K��ƥ������,Ȼ����ڹ���ɸѡ,
# �����ƥ��õĹؼ������������ֵ,ͨ������ֵȡ��ƥ��������ֵ,
# ���˶���4�Ե�����ֵ,���ܵõ��ӱ任���� ���ﷵ�ص���Ҫ�����Ǹ��任����
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# �����ӽDZ任���� ������Dz���,Ȼ��ⷽ�̵õ��任����Ĺ���
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
return (matches, H, status)
# ƥ����С��4ʱ,����None
return None
def drawMatches(imageA, imageB, kpsA, kpsB, matches, status):
# ��ʼ�����ӻ�ͼƬ,��A��Bͼ�������ӵ�һ��
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# ���ϱ���,����ƥ���
for ((trainIdx, queryIdx), s) in zip(matches, status):
# �����ƥ��ɹ�ʱ,�������ӻ�ͼ��
if s == 1:
# ����ƥ���
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# ���ؿ��ӻ����
return vis
#��ȡ�����кܴ���ת������ͼƬ
image1 = cv2.imread('../data/only_pics11/24.png')
image2 = cv2.imread('../data/only_pics11/25.png')
# ���A, BͼƬ��SIFT�����ؼ���,�õ��ؼ���ı�ʾ����
(kps_img1, features_img1) = detectAndDescribe(image1)
# kpsA (�ؼ������, ����) features(�ؼ������,����)
#kps_img1 (924, 2) features_img1 (924, 128)
(kps_img2, features_img2) = detectAndDescribe(image2)
# ƥ������ͼƬ������������,����ƥ���� ע��,�����DZ任right����ͼ��,����Ӧ���Ǵ�left����right��ƥ��ĵ�,Ȼ��ȥ����right�ı任����
M = matchKeyPoints(kps_img1, kps_img2, features_img1, features_img2)
if M:
# ��ȡƥ����
(matches, H, status) = M
print('888888')
vis = drawMatches(image1, image2, kps_img1, kps_img2, matches, status)
cv2.imshow("vis",vis)
cv2.waitKey()
cv2.destroyAllWindows()

