基础提升1--哈希函数与哈希表
1. 哈希函数的特征
1)一把情况下,输入无穷
2)相同的输入必然有相同的输出
3)但是不同的输入也有可能出相同的输出,这叫哈希碰撞;
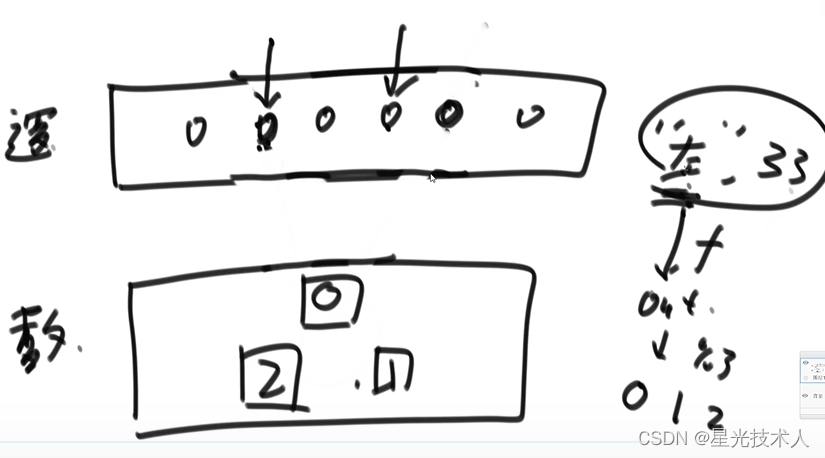
4)均匀性和离散性,给一组输入,无论输入是否有规律,经过哈希函数计算的一组输出可以均匀的离散分布在值域上,假如值域是个圆,每个哈希函数值是一个点;当使用一个大小一样的小圆去包括点时,每一次包括住的点个数 都很均匀;描述的也不是很清楚
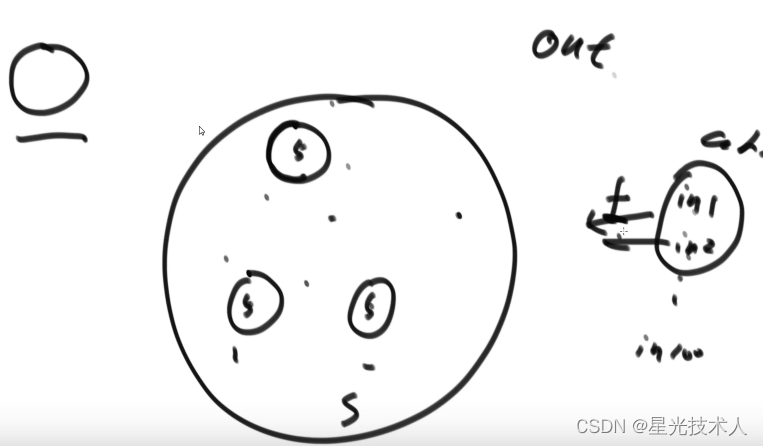
哈希函数越均匀,表示这个哈希函数越优秀;哈希函数有多种
- 域均匀性的传递
如果值域范围太大,将输入经过哈希函数得到的一组输出除于m求模,那么得到的新值域也是均匀的;
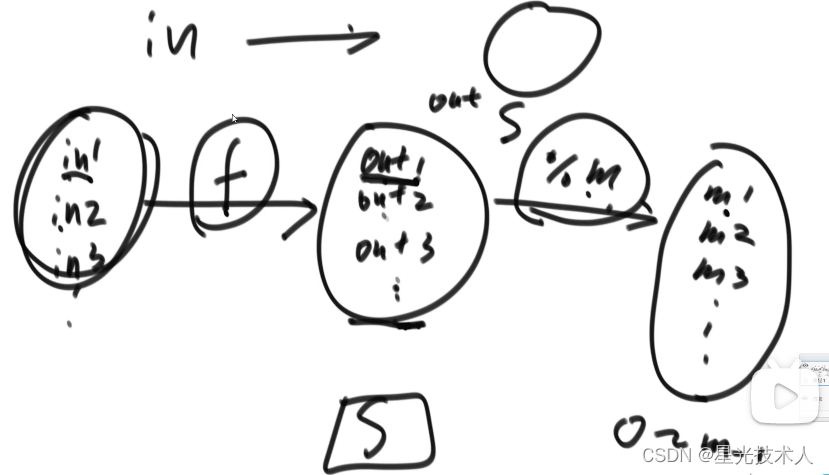
性质5的应用
给定1G的内存;统计40亿的数字中的最高频数字,传统的做法做法是一个哈希表(key,value);key代表数字,value代表出现的次数;但是如果说40亿个数字都不同,那么哈希表就需要40亿个键值对;经过粗略计算,1G内存最多可以容纳1亿个不同的数来计算词频;
所以可以在输入经过哈希函数以后,取模m=100;那么每一个输入最后都会得到一个0-99之间的数字,将相同的输出对应的输入放进同一个文件,根据哈希函数的均匀分布性,每个文件储存的数字都是输入数据量的百分之一;这时候用1G的内存来遍历计算每个文件的最高词频,1G内存对于每个文件的数据量是戳戳有余的;
2 哈希表的实现原理和扩容
??定义一个哈希表的时候,刚开始会分配一个默认大小的空间;假设说每一个i个哈希值对应的键是一个链表;那么如果在增删改查某个数的时候会很麻烦,因为最差的情况就是完全遍历一个链表;
??所以为了省事,就可以设定每一个链表的最大长度,当某个哈希值对应的链表的长度到达阈值的时候(根据哈希函数的均匀分布性,表明所有的key对应的链表几乎都达到了阈值),哈希表空间就会进行扩容;然后重新计算原来已经放进老哈希表中的输入对应的新哈希值;这里就是扩容代价:包括哈希表扩大和重复计算的代价;
??哈希表扩大空间的次数O(logN);假如有1000个输入,那么假如原始的哈希表的空间为2,随着输入的增加,哈希表空间扩大到1000,扩容次数就是O(log100);每一次扩容以后重复计算的时间时间复杂度为O(N);所以总的时间复杂度就为O(NlogN),所以N个输入,扩容代价最多是O(NlogN),单次扩容代价就为O(logN);这是在哈希表的值对应的链表长度阈值为2时得出的结果;
??所以如果把链表的长度定位10,那么每次扩容的时间就是O(lg10)的级别。所以在使用的时候,哈希表扩容的时间复杂度可以看做O(1);
3 设计randompool结构

#include<iostream>
#include<map>
#include<string>
using namespace std;
class Randompool
{
public:
int size = 0;//哈希表长度
int k = -1;//哈希值从1出发
void insert(map<int, string>& m1, map<string, int>& m2, string cur)
{
if (m2.find(cur) == m2.end())
{
m2[cur] = ++k;
m1[k] = cur;
size++;
}
}
void delete_s(map<int, string>& m1, map<string, int>& m2, string cur)
{
//将待删除的字符与最后一个哈希值对应的字符互换
if (m2.find(cur) != m2.end())
{
int idx = m2[cur];//待删除的字符对用的哈希值
m1[idx] = m1[size - 1];//
//m1[size - 1] = cur;
m2[cur] = size;
m2[m1[idx]] = idx;
size--;
}
};
string rand_num(map<int, string>& m1)
{
int idx = rand() % size;//[0,size-1]范围的随机数
return m1[idx];
}
};
int main()
{
map<int, string> M1;
map<string, int> M2;
Randompool RP;
RP.insert(M1,M2,"feng");
RP.insert(M1,M2,"zhang");
RP.insert(M1, M2, "su");
RP.delete_s(M1, M2, "feng");
cout << M2["su"] << endl;
return 0;
}
源码地址:https://github.com/hjfenghj/randpooling
4 布隆过滤器
布隆过滤器用途:假如设计一个服务器,其中国需要过滤点100亿个url网址;假如一个url网址需要64个字节来表示,那么100亿个URL网址就需要6400亿字节,也就是640G;需要640G个内存来储存需要过滤的网址,这显然时不现实的,所以就使用哈希函数和位图来处理
位图
一个储存int型变量,长度为10的数组;int型变量为4字节,也就是32个bit;这个数组也就代表320bit的位置;假如说使用一个bit位来代表一个URL网址;那么那可以降低内存的使用;
怎么取出某位的状态呐
vector<int> Arr;//假设长度为10
int n_bit= 180;
int numindex = 180/32;
int bitindex = 180%32;
int flag = (Arr[numindex]>>bitindex) & 1;//1代表第180bit的位置是1
//0代表第180 bit位置上是0;
URL使用bit表示的流程
a) 每一个由64个字节表示的URL网址,经过哈希函数和求bit位的运算后得到数组的第numindex位置的第bitindex位置,然后将该bit位置写为1;
b) 设置k个哈希函数,然后接受一个URL网址,就更新K个bit位的状态;如果已经位1,就不变;如果该比特位状态位0,就改为1;
c) 遍历所有的URL,最后就得到代表过滤器的数组
d) 输入一个新的URL网址,计算13个bit位,如果着13个bit位置上的状态都为1,那么就过滤掉这个URL网址;但凡出现了一个0,就说明这个网址不在我们的带过滤网址集合范围内;
布隆过滤器的失误类型
??失误类型有两种,不该过滤的被过滤掉,该过滤掉的没有被过滤掉;
??这里只存在第一种失效类型;因为如果某URL在该过滤URL集合中,在遍历待过滤网址集合的时候,对应位置上就会记为1;
但是如果是不该过滤的URL;因为哈希碰撞的存在,不同的URL经过哈希函数得到的哈希值在求bit位的时候,可能出现重合,所以本不应该过滤掉的网址对应的13个位置都为1;
通过位图设计,原本需要640G的内存,降低为 26个G;
5 一致性哈希