目录
insert_Leaf_Item(ptr, pos, kx, rec);
设计一个节点结构
原理及解释
先可以看看别的地方给出的B+树定义,B+树点击即可;
对于B+树节点结构的思路如下:
现在设计的节点框架如下,看看都要设计什么变量;
typedef struct BNode
{
//B+树的变量
}BNode;(1)每个节点必须有存放自己双亲节点指针;
(2)对于关键码来说,必须要知道关键码的个数,后面操作都能用上;
(3)对于B+树来说,叶子节点和分支节点结构不一样吧;所以得区分一下吧;
(4)关键码不可少吧;
(5)记录集指针不可少,我们就是通过关键码找记录集的吧;
(6)对于一个树来说,孩子指针不能少吧;
(7)对于B+树的叶子结点来说,是通过链表连接的,所以链表所用的直接前驱指针和直接后继指针不能不有吧;
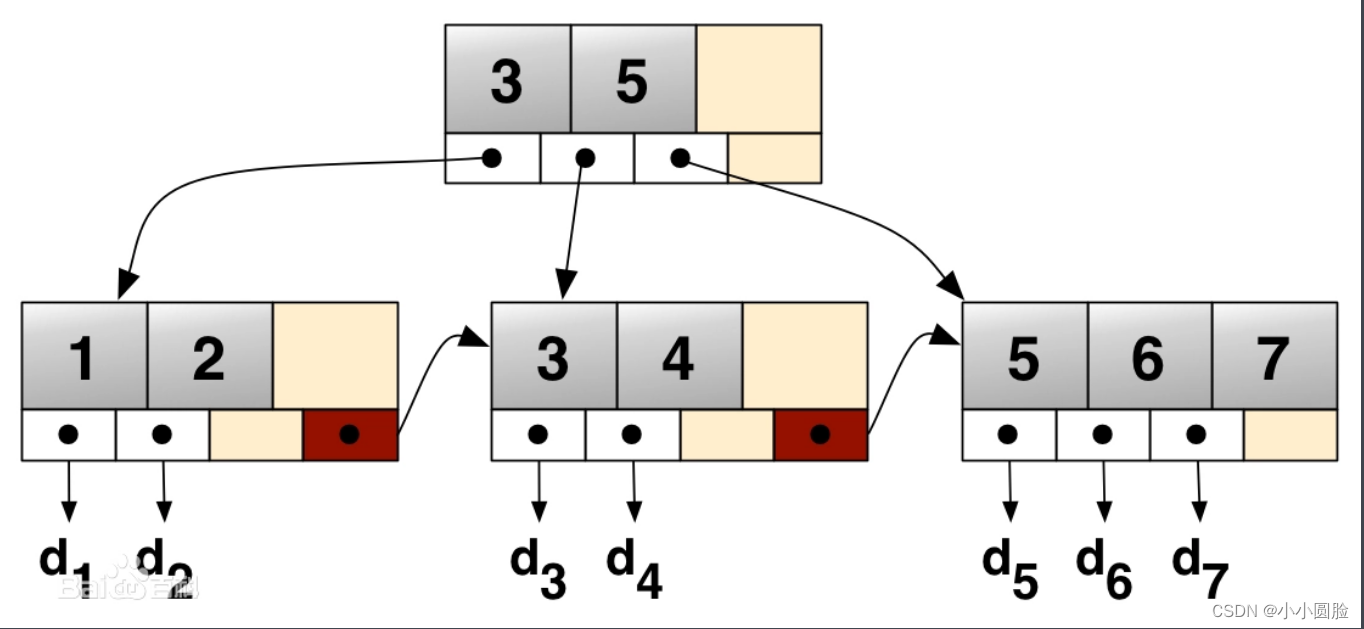
到现在基本就结束了;以上述给出个设计思路,给出一张我理解的图,拿图好说话(以五阶B+树为例);
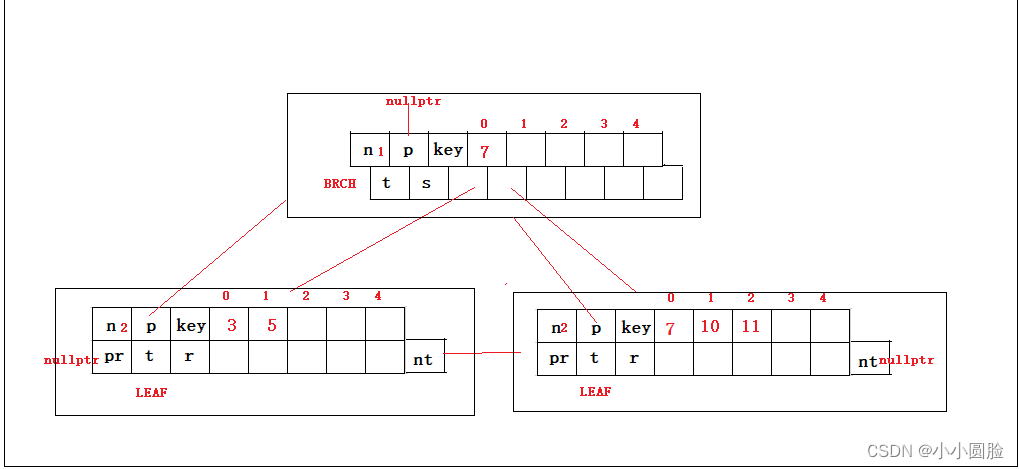
?图中字母意思:
- n代表 num(关键码个数)?
- p 代表Parent指针(指向双亲结点)
- key代表关键码数组(不占位只是为好理解)
- t代表节点是分支还是叶子;
- r代表记录集指针数组(r字符不占位置)
- pr代表链表的前驱指针?
- nt代表链表后继指针
对于一个节点结构来说,它只能为分支或者是叶子结点,只能是一个,所以设计结构体如下:
typedef struct BNode
{
int num; //关键码数量
BNode* parent;//双亲指针
NodeType utype; // LEAF , BRCH; 结构体类型
KeyType key[M + 1];//关键码数组
union
{
struct // LEAF 叶子结点
{
Record* recptr[M + 1];
BNode* prev, * next;
};
// BRCH; 分支节点
BNode* sub[M + 1];
};
}BNode;对于B+树来说,我们可以怎样去设计它的结构,为了查找方便设计如下:
typedef struct
{
struct BNode* root;//指向根节点
struct BNode* first;//指向叶子结点第一个节点
int cursize;//结构体数量
}BTree;最后一步,设计一结构体,用于查询,插入,如下;
typedef struct
{
struct BNode* pnode; // 节点指针
int index; //节点某一关键码位置
bool tag; //是否存在该值
}Result;代码块
对于五阶B+树来说,整体代码块如下:
#define M 5 // M 奇数 //
#define BRCHMAX (M-1) // // SUB M
#define BRCHMIN (M/2); // SUB M/2+1
#define LEAFMAX (M) // MAX ELEM 5
#define LEAFMIN (M/2+1) // MIN ELEM; 3
typedef int KeyType;
typedef struct {}Record;
typedef enum { BRCH = 1, LEAF = 2 } NodeType;
typedef struct BNode
{
int num; //关键码数量
BNode* parent;//双亲指针
NodeType utype; // LEAF , BRCH; 结构体类型
KeyType key[M + 1];//关键码数组
union
{
struct // LEAF 叶子结点
{
Record* recptr[M + 1];
BNode* prev, * next;
};
// BRCH; 分支节点
BNode* sub[M + 1];
};
}BNode;
typedef struct
{
struct BNode* root;//指向根
struct BNode* first;//指向叶子结点第一个结构
int cursize;
}BTree;
typedef struct
{
struct BNode* pnode; // 保存节点
int index; //保存关键码位置
bool tag; //是否有该值
}Result;算法设计
插入算法
首先我们知道插入一个值得插入关键码和记录集吧;设计插入函数如
bool Insert(BTree& tree, KeyType kx, Record* rec)
{
、、、、、、
}我们对于刚刚定义的结构进行插入演示;示例{55 35 25 10 8 60 59 17 85 105 37 44 65};
(1)首先插入的是55,因为B+树的插入只在叶子上进行,所以对于第一个值来说,此时我们先判断根节点是否为空,如果为空,我们得建立一个叶子结点,所以55一定会给叶子结点插入;
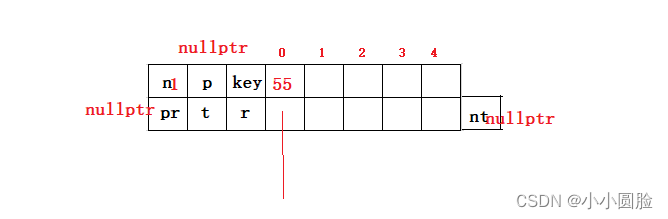
if (tree.root == nullptr)
{
BNode* s = BuyLeaf();//购买叶子结点
s->key[0] = kx;
s->recptr[0] = rec;
s->num = 1;
tree.root = tree.first = s;
return true;
}(2)如果root不为空,我们就得查找kx应该插入的位置吧;对于查找位置分为两种情况,从根节点查找,和从叶子结点,还记得我们定义的最后一个结构体没;
从叶子结点查找的方式
需要注意的是,我们每次最好给一个节点的最后插入数据,如果找到的位置是节点的第一个值之前,如果该节点的前驱结点不空,我们就让其指向前驱结点的最后一个值;
Result FindLeaf(BNode* ptr, KeyType kx)
{
Result res = { nullptr,-1,false };//初始化查找结构体
BNode* p = ptr;
while (p != nullptr && p->next != nullptr && kx > p->key[p->num - 1])//防止p等于NULLptr
{
p = p->next;
}
if (p == nullptr) return res;//如果为nullptr,则直接返回
int pos = p->num - 1;//从0开始,所以走实际位置
while (pos >= 0 && kx < p->key[pos])
{
--pos;
}
res.pnode = p;//记录找到的节点
res.index = pos;//记录找到的位置
if (pos < 0 && p->prev != nullptr)//如果是负数,则将其移动到前一个叶子结点,给前一个结点最后
{
res.pnode = p->prev;
res.index = p->prev->num - 1;
}
else if (pos >= 0 && kx == p->key[pos])
{
res.tag = true;
}
return res;
}
从根节点查找的方式
思路:从根节点出发,一直找到叶子结点的第一个结构,再使用叶子查找方式;
Result FindRoot(BNode* ptr, KeyType kx)
{
Result res = { nullptr,-1,false };
BNode* p = ptr;
while (p != nullptr && p->utype == BRCH)//找到第一个叶子结点;
{
p->key[0] = kx;
int i = p->num;
while (kx < p->key[i]) --i;
p = p->sub[i];
}
res = FindLeaf(p, kx);//进行叶子方式查找
return res;
}我们现在知道两种方式的查找方式;那就根节点不为空,那就找位置呗;
Result resr = FindRoot(tree.root, kx);//从根节点查找
Result resf = FindLeaf(tree.first, kx);//从叶子结点查找
if (resf.pnode == nullptr)//如果返回值为nullptr
{
cout << "Btree struct error " << endl;
return false;
}
if (resf.tag)//如果tag==true则表明有该值
{
cout << "已经有该值了" << endl;
return false;
}
BNode* ptr = resf.pnode;
int pos = resf.index;
Insert_Leaf_Item(ptr, pos, kx, rec);//进行插入insert_Leaf_Item(ptr, pos, kx, rec);
那就开始写Insert_Leaf_Item(ptr, pos, kx, rec);代码吧;
void Insert_Leaf_Item(BNode* ptr, int pos, KeyType kx, Record* rec)
{
for (int i = ptr->num - 1; i > pos; --i)//吧该位置的值依次往后移动,留下位置
{
ptr->key[i + 1] = ptr->key[i];
ptr->recptr[i + 1] = ptr->recptr[i];
}
ptr->key[pos + 1] = kx;
ptr->recptr[pos + 1] = rec;
ptr->num += 1;//num++
}现在给叶子节点已经插入完成了,但是新的问题出来了,会不会产生分裂?对于五阶B+树来说,每个节点最多四个关键码,第五个进入的时候就要进行分裂;先看图:
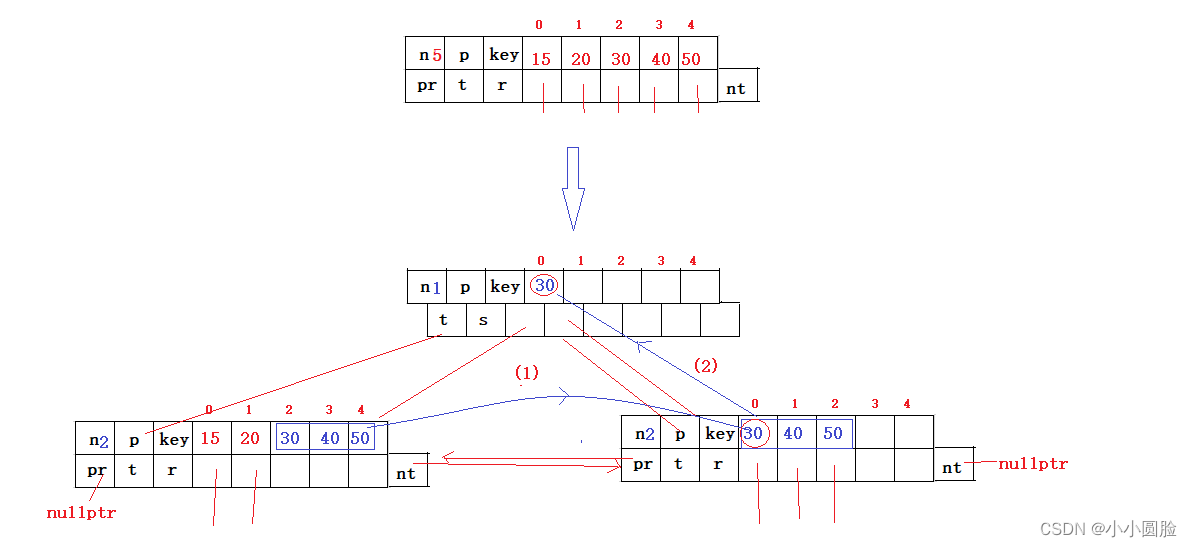
假设插入的节点指针是ptr吧;
首先判断ptr->num是否等于5,如果是,也就是关键码满了需要进行分裂;如图,
(1)将LEAFMIN后的值依次赋值给新建的叶子结构体的关键码0 1 2 位置;
(2)把ptr的前驱和后继改一下吧,右兄弟节点了;
(3)判断ptr->parent是否存在,如果不存在,也就是说没有双亲结点吧,那就建造一个分支节点,将ptr->next的0位置的值赋给新建的节点,并且改一下双亲指针,毕竟现在拥有双亲了;在改双亲的sub指针;
(4)如果ptr有双亲指针,也就是人家有爸爸,咋办,再判断,也许爸爸节点的关键码key达到五个了,也许要分裂,所以说慢慢来;
思路出来了 ,那就代码吧,首先判断一下:
if (ptr->num > LEAFMAX)
{
BNode* newroot = Splice_Leaf(ptr);
if (newroot != nullptr)
{
tree.root = newroot;
}
}如果分裂之后产生的节
现在开始写分裂代码BNode* Splice_Leaf(BNode* ptr);
首先我们已经确定ptr节点已经满了,需要分裂,那就先买一个叶子结点;
BNode* s = BuyLeaf();创建叶子结点的
创建叶子结点的代码简单,我直接给出
BNode* Buynode()
{
BNode* s = (BNode*)malloc(sizeof(BNode));
if (nullptr == s) exit(1);
memset(s, 0, sizeof(BNode));
return s;
}
BNode* BuyLeaf()
{
BNode* s = Buynode();
s->parent = nullptr;
s->utype = LEAF;
return s;
}创建好叶子结点后,我们就要开始上图中的第一步,将ptr的关键码转移到性节点s上去:
KeyType kx = Move_Leaf_Item(s, ptr);叶子节点分裂转移代码
开始写转移代码,将ptr从num到LEAFMIN的值转移到分裂的新节点s
KeyType Move_Leaf_Item(BNode* s, BNode* ptr)
{
for (int i = 0, j = LEAFMIN; j < ptr->num; ++i, ++j)//循环给s节点赋值
{
s->key[i] = ptr->key[j];
s->recptr[i] = ptr->recptr[j];
}
s->num = LEAFMIN;//配置s->num
ptr->num = LEAFMIN;//更新ptr->num
s->parent = ptr->parent;//两个节点的双亲指针是相同的,直接赋值
s->next = ptr->next;//更新兄弟指针(next和prev)
s->prev = ptr;
ptr->next = s;
if (s->next != nullptr)//如果原ptr有后继节点,也就是s是插入新节点,更新s->next
{
s->next->prev = s;
}
return s->key[0];
}现在新节点s已经被设置好了,但是新的问题又来了,如图
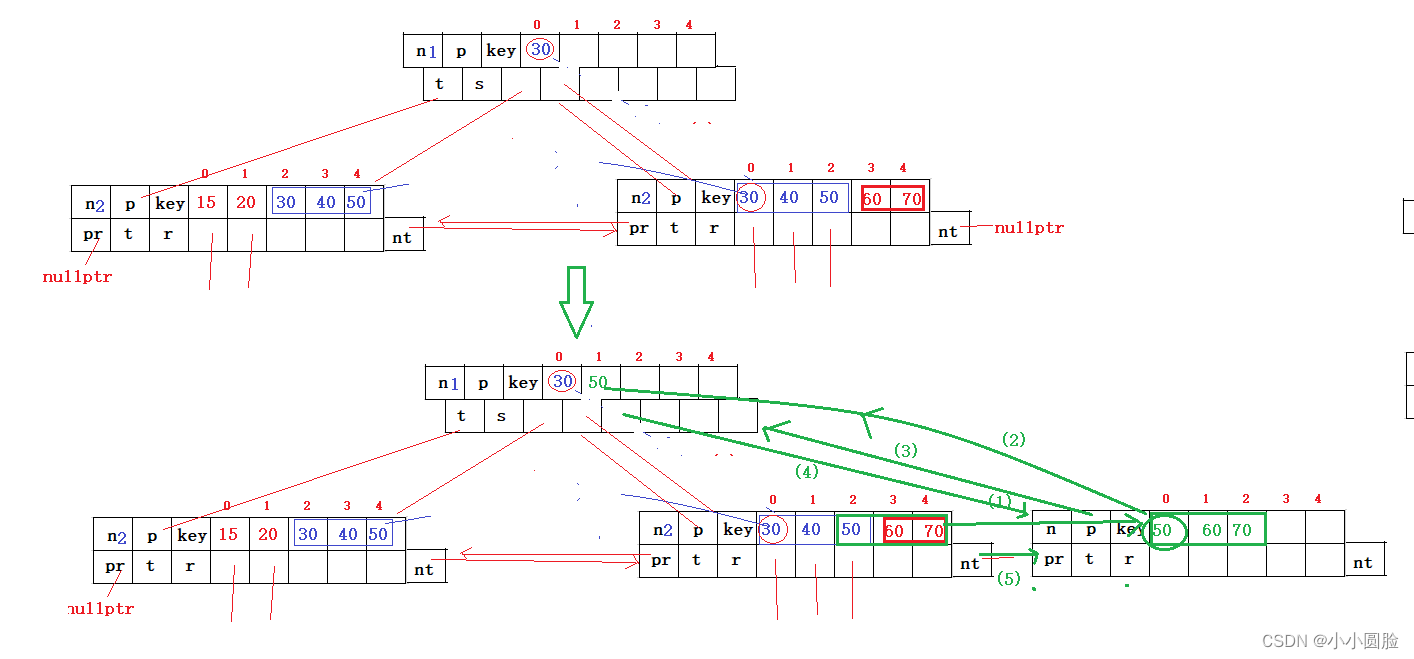
?当加入60,70时,ptr满了,需要分裂,和上面一样首先创建新的叶子节点,然后看看双亲指针,发现人家不为空,那就不用创建新的了,直接添加就行了吧;
所以我们还得判断,如下
如果prt->parent==nullptr时,我们就去创建新的,如上上图一样;
如果ptr->parent!=nullptr时,我们该怎么办?直接插入,那分支节点也满了呢?
那就先说没满的情况吧;
BNode* pa = ptr->parent;
int pos = pa->num;
pa->key[0] = kx; //
while (pos > 0 && kx < pa->key[pos]) { --pos; }//找到对应的插入分支节点的位置
Insert_Brch_Item(pa, pos, kx, s);分支节点插入
开始分支节点插入的代码吧,很简单:
void Insert_Brch_Item(BNode* ptr, int pos, KeyType kx, BNode* right)
{
for (int i = ptr->num; i > pos; --i)
{
ptr->key[i + 1] = ptr->key[i];
ptr->sub[i + 1] = ptr->sub[i];
}
ptr->key[pos + 1] = kx;
ptr->sub[pos + 1] = right; // right->parent;
ptr->num += 1;
}好了,快结束了。那如果我们给分支节点插入了一个值之后,pa->num=5了,是不是分支需要分裂了;看图:

??如图当ptr节点分裂时会产生新的节点qtr,和新的分支关键码,但是对于分支pa来说,已经达到5个值,需要分裂;
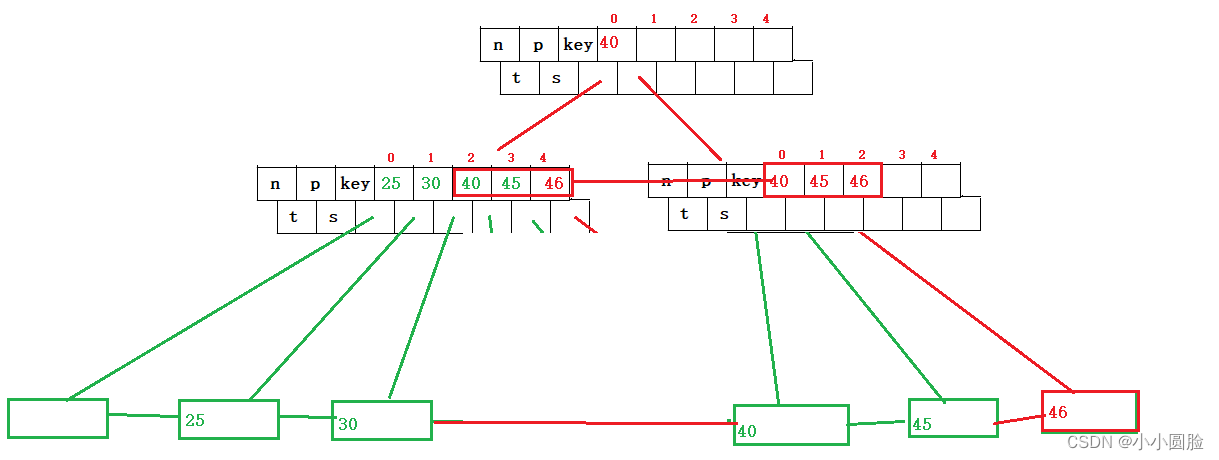
?如上图,pa分支节点,分裂为两个分支节点,如图
那代码还需要判断一下
if (pa->num > BRCHMAX)
{
return Splice_Brch(pa);
}
else
{
return nullptr;
}现在开始写BNode* Splice_Brch(BNode* ptr);
首先注意后面为递归形式,可以这样想,分裂之后是不是有两种情况
- (1)ptr->parent==nullptr要么产生一个一个新的分支节点,
- (2)ptr->parent!=nullptr,需要给ptr的双亲结点增加一个关键码,又有新的问题,如果增加的关键码导致该分支结构满了,又要分裂吧;所以用递归
BNode* Splice_Brch(BNode* ptr)
{
BNode* s = BuyBrchnode();//创建一个分支节点
KeyType kx = Move_Brch_Item(s, ptr);//移动分支节点的值
if (ptr->parent == nullptr)
{
return MakeRoot(kx, ptr, s);//如果分支ptr->parent==nullptr得创建吧
}
BNode* pa = ptr->parent;
int pos = pa->num;
pa->key[0] = kx; //
while (pos > 0 && kx < pa->key[pos]) { --pos; }
Insert_Brch_Item(pa, pos, kx, s);
if (pa->num > LEAFMAX)
{
return Splice_Brch(pa);
}
else
{
return nullptr;
}
}创建一个分支节点
BNode* BuyBrchnode()
{
BNode* s = Buynode();
s->parent = nullptr;
s->utype = BRCH;
return s;
}移动分支节点的值
void Insert_Brch_Item(BNode* ptr, int pos, KeyType kx, BNode* right)
{
for (int i = ptr->num; i > pos; --i)
{
ptr->key[i + 1] = ptr->key[i];
ptr->sub[i + 1] = ptr->sub[i];
}
ptr->key[pos + 1] = kx;
ptr->sub[pos + 1] = right; // right->parent;
ptr->num += 1;
}好了,插入代码到此结束了;
测试一下子23,33,12,10,48,50 如图所示,我们去看看编译器;
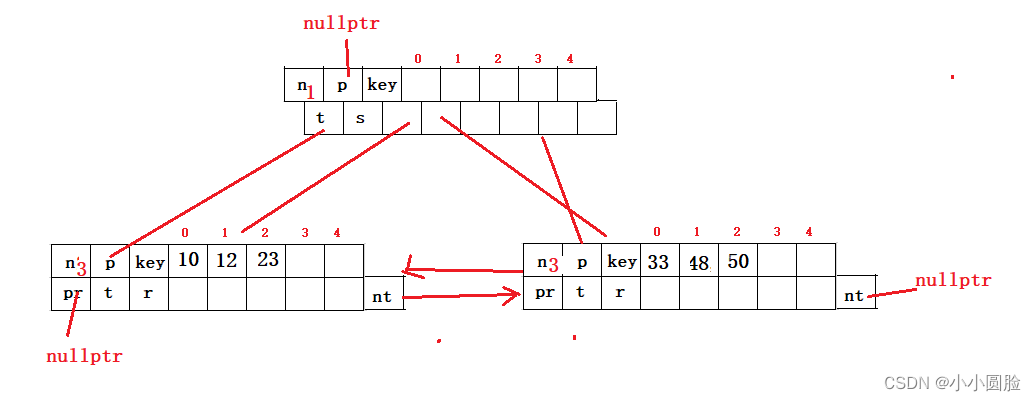
?测试如图


