�ж�·���Ƿ��ཻ
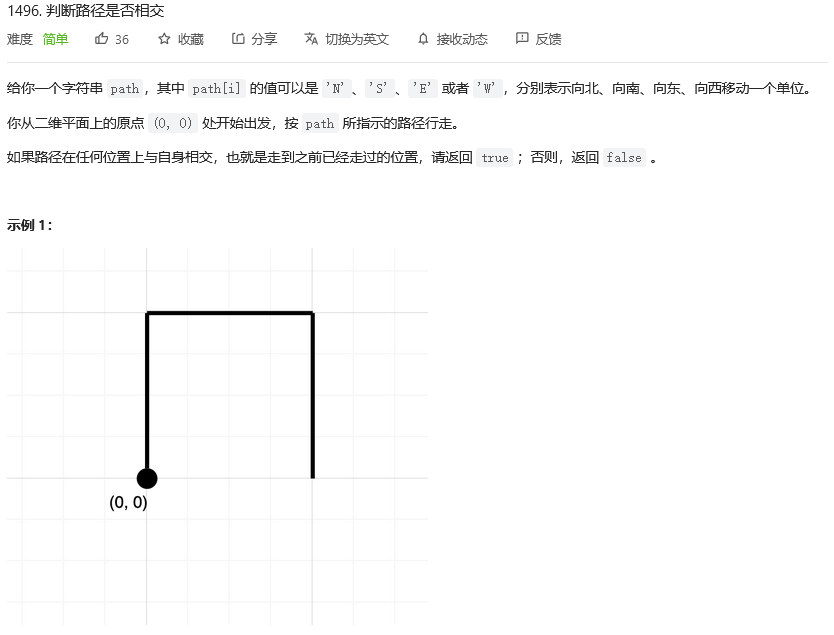
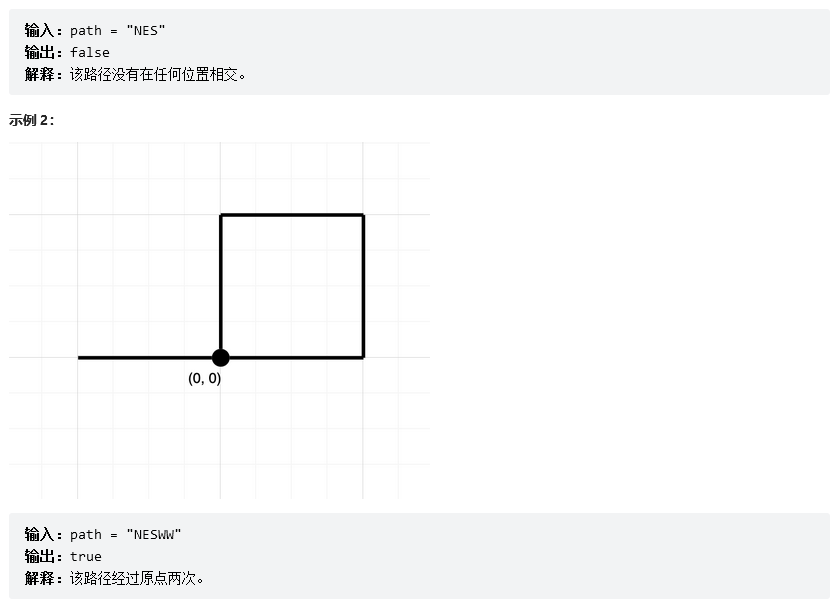

һ��ʼԭ����һ��С��,�����С��һ��ָ��,��Щָ��ֱ�Ϊ 'N'��'S'��'D'��'W'(���������ĸ�����),����ÿ��ָ��ᳯ���ĸ������е�ijһ���� 1 ����λ�ij���(�������һ�������ν,�����ǶԳƵ�,����һ����)
ʾ�� 1:
���ǿ��Ը��ݸ�����ָ���߳�һ��·��,��:���ߵĹ�����,��û�г����ظ��ĵ�
����ߵĹ��������ظ��ĵ����� True,���û���ظ��ĵ����� False
���ݷ�Χ:10^4,ʱ�临�Ӷ�Ҫ������ O( n�� n ) ���� O(nlogn)
ÿ��ֻ��һ��λ�ľ���,�����Ǻ�ƽ��ֱ�ķ�ʽ��,ÿ������֮���߹������е㶼һ����������(�������궼һ��������),����߹��ظ��ĵ�һ����ijһ���߶ε�����,�������ߵ�������֮���е��λ��,ֻ��Ҫ�����������߹��Ķ˵���û���ظ��ĵ㼴��(�����ù�ϣ���ж�һ�ѵ�������û���ظ��ĵ�)
�ù�ϣ���������߹��ĵ㶼�洢����,ÿ���ߵ�һ���µĵ�֮��,������Ƿ�������µĵ�֮ǰ�߹�,�ͷ��� True,���� False
ע���ϣ��ֻ�ܹ�ϣһ���ֵı�������,����:��ϣ�����Թ�ϣ string,���Dz��ܹ�ϣ pair,������һ������(x,y),��Ҫ������ɹ�ϣ���ܹ���ϣ������(һ�ֱȽϼķ�ʽ�ǰ� x��y ƴ�ӳ�һ���ַ���)
![]()
ʱ�临�Ӷ����߹��ĵ���������,ʱ�临�Ӷ�Ϊ O( n )
class Solution {
public:
bool isPathCrossing(string path) {
//����һ����ϣ��
unordered_set<string> hash;
//�Ȱ����(0,0)�ӵ���ϣ����
hash.insert("0 0");
//���(0,0)
int x = 0, y = 0;
//ö��ÿһ��ָ��
for(auto c: path) {
//���ָ��Ϊ'N' ��ʾ����Ӧ��������
if(c == 'N') x --;
else if(c == 'S') x ++;
//������
else if(c == 'W') y --;
else y++;
//�ѵ�ǰ������һ���ַ���
string s = to_string(x) + ' ' + to_string(y);
//���s��֮ǰ���ֹ�-> ˵�����ظ��ĵ�
if(hash.count(s)) return true;
//����ѵ�ǰ����ӵ���ϣ����
hash.insert(s);
}
//�����������û�з����ظ��ĵ� ����false
return false;
}
};���������Ƿ���Ա� k ����

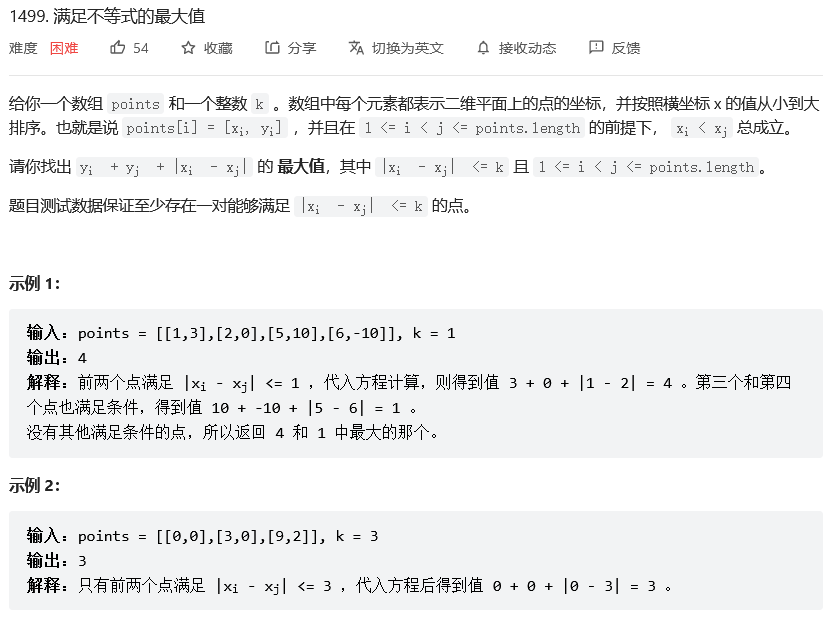
����һ������,�ٸ�һ�� k,���鳤����ż��,ϣ���������е��������ֳ�����һ�����,ʹ��ÿһ�Ե�����֮�Ͷ�ǡ���ܹ��� k ����,����������㷵�� True,����,���� False
���ݷ�Χ:10^5,ʱ�临�Ӷ�Ҫ������ O(nlogn)
��Եķ�ʽ�кܶ���,������������ָ������Ҫ��ÿһ�Ե����ĺ��ܹ��� k ����,���ǹ���Ӧ�ò��� a��b �ľ���ֵ,Ӧ���� a �� b ���� k ������:��� a? + b �ܹ��� k ����,��ζ�� k / (a + b) �������� 0,Ӧ�ù���ÿһ����������ÿһ�����������Ƕ���
�Ƚ�����������������ֳ� k ��(���������� k �������ֳ� k ��)
������ 0 ~ k - 1,һ���� k ��
����ԵĹ�����:
�����ǰ��������� k �������� 0,���������һ�����ĺͳ��� k ������Ҳ�� 0,����Ҫ��������Ե���������� k ������Ҳ�� 0,������ 0 ����ֻ�ܺ� 0 ���,������ 1 ����ֻ���������� k - 1 �������,������ 2 ����ֻ���������� k - 2 �������. . .�Դ�����,���Է�����Ȼ�����ܶ�,������ȷ���Ե����,����ֻ��Ҫ���һ��:����������Է�ʽ,�ܲ���ǡ�÷ֳ� k �鼴��(ÿһ�������ҵ�����Ե���)
��ͳ��һ��ÿһ������ĸ���,���ж������� 0 ��һ��ĸ����Dz���ż��( 0 ֻ�ܺ� 0 ���),���ж������� 1 ��һ��ĸ����������� k - 1 ��һ��ĸ����Dz���һ����. . .�Դ�����
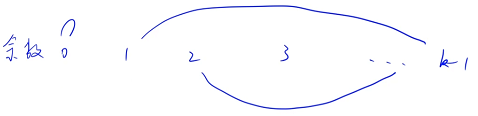
ֱ��ģ��,һ���������:���� 0 Ҫ�� 0 ���,���� 1 Ҫ�� k - 1 ���,ÿ��һ�� 1 ��Ҫ��һ�� k - 1 �������,����һ�� 1 ����û�� k - 1 ��ì����,�� 1 �������ٿ� 2,�Դ�����. . .���ÿһ�������������,���� True;������������,���� False
���ڸ���������жϲο����: leetcode1497_Jackybored�IJ���-CSDN����_����1497
��ϸ����ɷ���ͻ�Ƶ�,����ÿ������,�Ƿ����˵��������Ҫ�������鲢�Ҽ�¼�����ֵ�ijЩ��Ϣ,������������֮��Ĵ��ڲ��Ҳ�����ƥ�������DZ�k�������뵽ʹ��ȡģ��������ʱ��ƥ������ת����ȡģ�����Ϳɽ��������������������k�ı���,��ô��������ȡģ����Ӻͱ�Ϊk������������������:
1.һ����������,һ�����Ǹ���,����������Ϊ 0,���Ա� k ����,��ô���Ǹ����ƥ������������,Ӧ�����²���,���ڸ��� num,���� (num%k) + k ����,�� num = -1,k = 3,��ô (-1%3) + 3 = 2,�� -1 ƥ������� 1,���������� num%k ����,1%3 = 1�����Է�������������֮��������Ϊ 3,��2 +1 = 3,��˿�ת��Ϊ�������������������Ϊ k,����������֮�͵�ƥ�����⡣
2.��������������,��Ϊk�ı���,�� num1 = 4,num2 = 5,k = 3,��ô���� num%k �����ɵõ� 4%3 = 1,5%3 = 2,1+2=3,ƥ��������������ͬ��
3.�����������������k�ı���,��num1 = 3,num2 = 3,k = 3,��ô 3%3 = 0,��ʱ������Ҫ��¼ȡ�����Ϊ 0 �ĸ���,���������������,�ض���һ������ƥ�䡣
��ʵ����ȡ�������˵,���ж��ȡ������Խ����û��Ӱ���,�� 5%3 = 2,5%3%3 = 2,��������������������Ժϲ���һ��,��((num%k)+k)%k,�������ǾͿ���д������,��һ����Ҫʹ��hash_map��¼,���������ݽṹ vector �Ⱦ��ɼ�¼
class Solution {
public:
bool canArrange(vector<int>& arr, int k) {
//��һ����ϣ����¼ÿһ�����ĸ���
unordered_map<int,int> cnt;
//ͳ��ÿһ����
//ȡģ��������Ϊ������Ҫ������-> ��Ҫ�����е�������ɷǸ���
for(auto x : arr) cnt[(x % k + k) % k] ++;
//���жϵ� 0 ���Dz�������Ҫ��-> cnt[0] %2 ?= 1 ż����������������������
if(cnt[0] % 2) return false;
//�ӵ� 1 �ʼһֱ���� k - 1 ��
for(int i = 1;i < k;i++) {
//�����ǰ������
while(cnt[i]) {
//��ǰ��--
cnt[i] --;
//���� k - i ����û�ж�Ӧ��һ���� ����� k - i ���Ѿ�С�ڵ��� 0,˵����ǰ�� i ������������
if(cnt[k - i] <= 0) return false;
//��ȥ�뵱ǰ����Ե���
cnt[k - i] --;
}
}
//ÿһ�������������
return true;
}
};������������������Ŀ

����һ������ nums ��һ��Ŀ��ֵ target,ͳ���������ж��ٸ��ǿ�������,ʹ���������е���СԪ�������Ԫ�صĺ�С�ڵ��� target,��������Ŀ
���ݷ�Χ:10^5,ʱ�临�Ӷ�Ҫ������ O(nlogn)
��һ�����е������еȼ����������Ӽ�:�κ�һ�������ж���һ������,�κ�һ�����ϰ����±�������һ��������
��������һ����,Ҫ��һ�����������,�ж��ٸ��ǿ��Ӽ�,ʹ�÷ǿ��Ӽ������������С��С�ڵ���Ŀ��ֵ target,Ҫ����һ�����ϵ����Ԫ�غ���СԪ��,Ϊ�˷����ҵ����ϵ����Ԫ�غ���СԪ��,�����Ƚ����������С��������,�ǰ�ľ�����Сֵ,���ľ������ֵ
![]()
ͳ���ж��ٸ��Ӽ�,ʹ����С����������ĺ���С�ڵ���Ŀ��ֵ target
���������Ӽ��ļ���������ʾ:

Ϊ�˷���ͳ���Ӽ�������,���������Ӽ�����,�����Ԫ�ط���(���߰�����СԪ�ط���),������СԪ���ǵ� 0 �������Ӽ��ǵ� 1 ��,������СԪ���ǵ� 1 �������Ӽ��ǵ� 2 ��,�Դ�����һֱ���� n - 1 ��,ֻ��ֱ����ÿһ����Ӽ�����,����һ��,������������Ҫ��ķǿ��Ӽ�������
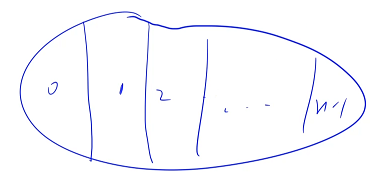
���ǵ�ǰ�� i ��,������СԪ���� ai(���� ai ����Сֵ,���� ai ��ߵ���������ѡ����û����ߵ���),���� ai ����СԪ��,������ѡ��Ԫ�ص�ʱ��,ֻ���� ai ���ұ�ѡ,Ҫ�����Ԫ�ؼ���СԪ��ҪС��Ŀ��ֵ:�� i ��ʼ,���ұ������Ԫ������Ƕ��ٵ�ʱ���������Ҫ��
������� ai ��˵,�����ҵ�һ������ aj,ai + aj ��С�ڵ���Ŀ��ֵ target,���� aj ���ٽ��(aj ��������������Ҫ�����,aj �ұ����е���������ѡ)
��СԪ���� ai ��,��������Ҫ��ķǿ��Ӽ��ж��ٸ�?��ô����?
ֻ�ܴ� ai �� aj ֮�����Щ������ѡ��,�����ǵ� i ��,���ȱ������ ai

ʣ�µ� ai-1 ~ aj-i ֮��� j - i ����ѡ���߲�ѡ��������Ҫ���,ÿ������������ѡ��

�� i ���ܹ��ķ������� 2^j-i ��
?
ֻҪ����ÿһ�� ai ,�ҵ�һ������ aj,�Ϳ���ͳ�Ƴ��� i ������Ҫ����Ӽ�����
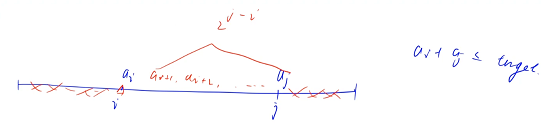
��ô����ÿһ�� ai �� aj?�����������е���,������˫ָ��
�����ǰ����ö�� ai ��ֵ,ai �Dz��ϱ���,��֮��Ӧ�� aj �Dz��ϱ�С��
һ��ʼ i �ڵ� 0 ��λ��,i ����������,j �����һ��λ��,����������,i Խ��,j ԽС
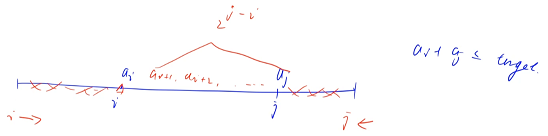
˫ָ���ܹ�ʹ�õ�ǰ��:�е�����,�� i ��ǰ�����ߵ�ʱ��,j һ����Ӻ���ǰ��,j ������������,j ���߷��ǵ�����
�� i �� i �ߵ� i ' ��ʱ��,�� i ' ���Ӧ�� j ' �������� j �ĺ���,��� i ' + j ' ��������С�ڵ���Ŀ��ֵ,��ô i? + j ' ��������Ҳһ��С�ڵ���Ŀ��ֵ,(��Ϊ i ��С��),��ζ�ŵ� i ������Ӧ�� j �Ͳ������� j,�ͻ����ì��,���� j ���߷����е�����,������˫ָ��
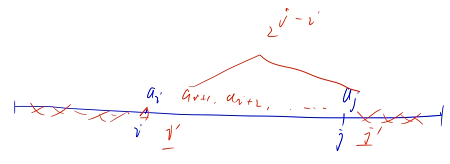
Ҫ�����ظ�����������,��Ŀ��û�и����������е����Dz��ظ���,����������ͬ�����ݵ�ʱ����ô����?
��ijһ�������а������� 5 ��ʱ��,��СֵӦ��ȡ�ĸ� 5?(ȡ�� 1 �� 5��ȡ�� 2 �� 5��������ȡ)�������ظ�����?��ᵼ������Ӽ���ö��һ�� 5 ��ʱ��¼һ��,��ö�ٵ� 2 �� 5 ��ʱ��,�ֱ���¼һ�δӶ������ظ�����?

���ǿ϶���,�������ǿ��������:��Ȼ������ 5 ����ֵ��һ����,����,������Ϊ�涨���ǵ��Ⱥ�˳��:�涨�����ǰ�� 5 �ȿ���� 5 ҪС,�����Ͳ�������ظ�����������
�Ӷ���֤ÿһ�����ϵ���Сֵ�����ֵ����Ψһ��,ÿ�������ڼ�����ʱ��,ֻ�ᱻ����Ψһ��Сֵ��¼һ��,�Ӷ���������ظ�����
�����㷨��ʱ�临�Ӷ�Ϊ O(nlogn) (����)
˫ָ��ʱ�临�Ӷ�:O(n)
��Ҫ���� 2^j-i,2^j-i ���ܴܺ�,��Ҫ��Ԥ����
leetcode1498. ������������������Ŀ(Python3)_AndyLiu1997�IJ���-CSDN����
�������Ƿ���,�ǿ������в���Ҫ��������,Ҳ����˵,������ԭ��˳���ء������������������������ֵ����Сֵ�ĺ�С�ڵ���target��������ǿ���ֱ�Ӷ������������,�������ǾͿ��Ի�����Χ,��ijһ��������,����ߵ�ֵһ�������������Сֵ,���ұߵ�ֵһ�������ֵ��
�������ǿ��������������,�������һ��������,ʹ��˫ָ��,left��ʾ���������߽�,right��ʾ�����ұ߽�,�����
left+right <= target,��ô������������ж�����������������?����2 ^ (right-left)��
���������ǵ����б������nums[left],��������[2,3,4,6],target=9Ϊ��:
���DZ��뺬��2,��ô���з�������������Ϊ[2]��[2,3]��[2,4]��[2,6]��[2,3,4]��[2,3,6]��[2,4,6]��[2,3,4,6]��һ��2 ^ 3=8����
������������,�ڱ������2�Ļ�����,�����3��������ѡ0����ѡ1����ѡ2����ѡ3������Cn0 + Cn1 + �� + Cnn = 2 ^ n��
��ô����Ϊʲô�������2��,Ϊʲô������[3]��[4]�ȵ���?
ԭ������Щ����֮���ѭ���лᱻ�ҵ���
��������ÿ�μ��������leftλ��Ϊ��ֹ��,�����������������С�
�������Ƚ�����ָ����Ϊ�����������������;�����ʱ����������,����ָ��right�C,ֱ���ҵ����ʱ��left����������right��������ָ��ĺ���������(С�ڵ���target),��ô�����ʱ��leftΪ��ʼ������������;Ȼ��left++,�������㡣
��C++ ȡģmod�״��㡿���ڴ𰸿��ܻ�ܴ�,���㽫�����1e9+7ȡģ���ٷ���_�������������IJ���-CSDN����_c++ mod
ȡģ����(C++)_��û���~�IJ���-CSDN����_c++��������?
class Solution {
public:
int numSubseq(vector<int>& nums, int target) {
int n = nums.size(),mod = 1e9 + 7;
vector<int> p(n);
//Ԥ���� 2 �����д���
//p[0]Ϊ2^0
p[0] = 1;
for(int i = 1;i < n; i++ ) p[i] = p[i - 1] * 2 % mod;
//����������
sort(nums.begin(),nums.end());
int res = 0;
//��ǰ������˫ָ���㷨ö��
for(int i = 0,j = n - 1;i < n;i++ ) {
//j������i��ǰ��-> i����Сֵ ����ѡiǰ�����
while(j >= i && nums[i] + nums[j] > target) j--;
if(j >= i && nums[i] + nums[j] <= target) {
//����Ҫ���¼�� res����2^j-i
res = (res + p[j - i]) % mod;
}
}
return res;
}
};���㲻��ʽ�����ֵ