��:���
HashMap���ڹ�ϣ����Map�ӿ�ʵ��,����key-value�洢��ʽ����,����Ҫ������ż�ֵ�ԡ�HashMap��ʵ�ֲ���ͬ����,����ζ���������̰߳�ȫ�ġ�����key��value������Ϊnull������,HashMap�е�ӳ�䲻������ġ�
JDK1.8֮ǰHashMap������+������ɵ�,������HashMap������,����������ҪΪ�˽����ϣ��ͻ (����������õ�hashCode��������Ĺ�ϣ��ֵһ�µ��¼������������ֵ��ͬ) �����ڵ�("������"�����ͻ) ��JDK1.8�Ժ��ڽ����ϣ��ͻʱ���˽ϴ�ı仯,���������ȴ�����ֵ(���ߺ�����ı߽�ֵ,Ĭ��Ϊ8)���ҵ�ǰ����ij��ȴ���64ʱ,��ʱ������λ���ϵ��������ݸ�Ϊʹ�ú�����洢��
����:������ת���ɺ����ǰ���ж�,��ʹ��ֵ����8,�������鳤��С��64,��ʱ�����Ὣ������Ϊ�����������ѡ������������ݡ�
��������Ŀ������Ϊ����Ƚ�С,�����ܿ�������ṹ,��������±�Ϊ������ṹ,�����ή��Ч��,��Ϊ�������Ҫ��������,����,��ɫ��Щ����������ƽ�⡣ͬʱ���鳤��С��64ʱ,����ʱ�����Ҫ��Щ��������������Ϊ��������ܺͼ�������ʱ��,�ײ�����ֵ����8�������鳤�ȴ���64ʱ,������ת��Ϊ�������������Բο�treeifyBin������
��Ȼ��Ȼ���˺������Ϊ�ײ����ݽṹ,�ṹ��ø�����,������ֵ����8�������鳤�ȴ���64ʱ,����ת��Ϊ�����ʱ,Ч��Ҳ��ĸ���Ч��
�ܽ������ص����:
- ��ȡ�������
- ����ֵλ�ö�������null,��һ��map��ֻ����һ������null
- ��λ����Ψһ��,�ײ�����ݽṹ���Ƽ���
- jdk1.8ǰ���ݽṹ��:����+����jdk1.8֮����:����+����+�����
- ��ֵ(�߽�ֵ)>8�������鳤�ȴ���64,�Ž�����ת��Ϊ�����,��Ϊ�������Ŀ����Ϊ�˸�Ч�IJ�ѯ��
һ:�洢����
������HashMap���϶����ʱ��,��jdk8ǰ,���췽���д���һ��һ��������16��Entry[] table�����洢��ֵ�����ݵġ���jdk8�Ժ�����HashMap�Ĺ��췽���ײ㴴��������,���ڵ�һ�ε���put����ʱ����������,Node[] table�����洢��ֵ�����ݵġ�
�����´���:
HashMap<String, Integer> hm = new HashMap<>();
hm.put("����", 18);
hm.put("����", 28);
hm.put("���»�", 40);
hm.put("����", 20);
System.out.println(hm);
�������ϣ���д洢(�����ҡ�, 18)����,�������ҵ���String������д֮���hashCode()���������ֵ,Ȼ�������鳤�Ȳ���ij���㷨�������Node�����д洢���ݵĿռ������ֵ�����������������ռ�û������,��ֱ�ӽ�(�����ҡ�, 18)�洢�������С�
�ײ����hashֵ�����㷨:
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
�������ϣ���д洢����(�����»���, 40),�������Һ����»��������hashCode����������鳤�ȼ����������ֵ����3,��ô��ʱ����ռ䲻��null,��ʱ�ײ��Ƚ����Һ����»���hashֵ�Ƿ�һ��,�����һ��,���ڴ˿ռ��ϻ���һ���ڵ����洢��ֵ���������»�-40���ַ�ʽ��Ϊ������
�������ϣ���д洢����(�����ҡ�, 20),��ô���ȸ������ҵ���hashCode����������鳤�ȼ���������϶�3,��ʱ�ȽϺ�洢���������Һ��Ѿ����ڵ����ݵ�hashֵ�Ƿ����,���hashֵ���,��ʱ������ϣ��ײ����ô�ײ���������������String�е�equals�����Ƚ����������Ƿ����,��������ӵ����ݵ�value����֮ǰ��value,�������ô�������º����������ݵ�key���бȽ�,����������,��һ���ڵ�洢����
����ڵ㳤�ȼ��������ȴ�����ֵ8�������鳤�ȴ���64����н�������Ϊ�����
���ڴ洢���̵�������:
��ϣ���ײ����hashֵ���㷨:
����key��hashcode��hash����,��������16λȻ����������㡣
�����������hashCode���ʱ����ô��?
�������ϣ��ײ,��keyֵ������ͬ���滻�ɵ�value
��Ȼ���ӵ���������,�������ȳ�����ֵ8��ת��Ϊ������洢��
ʲô�ǹ�ϣ��ײ�Լ���ʱ������ϣ��ײ,��ν����ϣ��ײ?
������ͬ��ֵ(����������)����hash�����,�õ���hashֵ��ͬ,����������Ҫ�ŵ�ԭ����������λ��,
���������λ���Ѿ�������ռ��,���³�ͻ��
ֻҪ����Ԫ�ص�key����Ĺ�ϣ��ֵ��ͬ�ͻᷢ����ϣ��ײ��
jdk8ǰʹ�����������ϣ��ײ��jdk8֮��ʹ������+����������ϣ��ײ��
�����������hashcode��ͬ,��δ洢��ֵ��?
hashcode��ͬ,ͨ��equals�Ƚ������Ƿ���ͬ��
��ͬ:���µ�value����֮ǰ��value
����ͬ:���µļ�ֵ�����ӵ���ϣ����
�ڲ��ϵ��������ݵĹ�����,���漰����������,�������ٽ�ֵ(��Ҫ��ŵ�λ�÷ǿ�)ʱ,���ݡ�Ĭ�ϵ����ݷ�ʽ:����Ϊԭ��������2��,����ԭ�е����ݸ��ƹ�����
ͨ����������,��λ��һ�������е�Ԫ�ؽ϶�,��hashֵ��ȵ������ݲ���ȵ�Ԫ�ؽ϶�ʱ,ͨ��keyֵ���β��ҵ�Ч�ʽϵ͡���JDK1.8��,��ϣ���洢��������+����+�����ʵ��,����������(��ֵ)����8ʱ�ҵ�ǰ����ij���>64ʱ,������ת��Ϊ�����,�����������˲���ʱ�䡣jdk8�ڹ�ϣ��������������ԭ��ֻ��Ϊ�˲���Ч�ʸ��ߡ�

���������Ļ���������,��ͳhashMap��ȱ��,1.8Ϊʲô��������?�����ṹ�Ļ����Ǹ��鷳����,Ϊ�η�ֵ����8���ɺ����?
JDK 1.8��ǰHashMap ��ʵ��������+����,��ʹ��ϣ����ȡ���ٺ�,Ҳ���ѴﵽԪ�ذٷְپ��ȷֲ�����HashMap���д��ǵ�Ԫ�ض���ŵ�ͬһ��Ͱ��ʱ,���Ͱ����һ������������,���ʱ��HashMap���൱��һ��������,���絥������n��Ԫ��,������ʱ�临�ӶȾ���Q(n),��ȫʧȥ���������ơ�����������,JDK1.8�������˺����(����ʱ�临�Ӷ�ΪO(logn))���Ż�������⡣���������Ⱥ�С��ʱ��,��ʹ����,�ٶ�Ҳ�dz���,���ǵ��������Ȳ��ϱ䳤,�϶���Բ�ѯ������һ����Ӱ�졣���Բ���Ҫת������
��:�̳й�ϵ
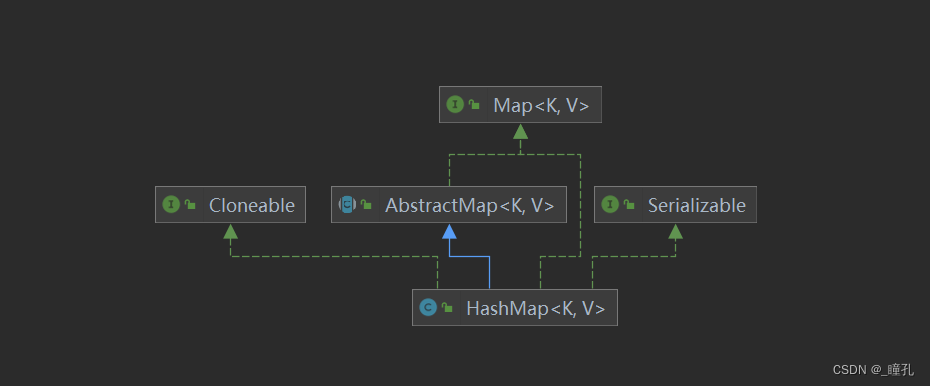
��ͼ��HashMap����ͼ:
- Cloneable�սӿ�,��ʾ���Կ�¡������������HashMap�����һ��������
- Serializable ���л��ӿڡ����ڱ���Խӿڡ�HashMap������Ա����л��ͷ����л���
- AbstractMap �����ṩ��Mapʵ�ֽӿڡ�������ȵؼ���ʵ�ִ˽ӿ�����Ĺ�����
ͨ�������̳й�ϵ���Ƿ���һ������ֵ�����,����HashMap�Ѿ��̳���AbstractMap��AbstractMap��ʵ����Map�ӿ�,��ΪʲôHashMap��Ҫ��ʵ��Map�ӿ���?ͬ����ArrayList��LinkedList�ж������ֽṹ��
��java���Ͽ�ܵĴ�ʼ��Josh Bloch����,������д����һ��ʧ����java���Ͽ����,����������д���ܶ�,�ʼдjava���Ͽ�ܵ�ʱ��,����Ϊ����д,��ijЩ�ط��������м�ֵ��,ֱ������ʶ�����ˡ���Ȼ��,JDK��ά����,��������Ϊ���СС��ʧ��ֵ��ȥ��,���Ծ��������������ˡ�
��:��Ա����
3.1:���л��汾��
private static final long serialVersionUID = 362498820763181265L;
3.2:���ϳ�ʼ������
Ĭ�ϵij�ʼ������16 �C 1<<4�൱��1*2��4�η���1*16
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
����:Ϊʲô������ 2 �� n ����?�������ֵ���� 2 ���ݱ��� 10 ����ô��?
���� HashMap ������һ��Ԫ�ص�ʱ��,��Ҫ���� key �� hash ֵ,ȥȷ�����������еľ���λ�á�HashMap Ϊ�˴�ȡ��Ч,������ײ,����Ҫ���������ݷ������,ÿ���������ȴ�����ͬ,���ʵ�ֵĹؼ����ڰ����ݴ浽�ĸ������е��㷨��
����㷨ʵ�ʾ���ȡģ,hash % length,�������ֱ������Ч�ʲ���λ�����㡣����Դ���������Ż�,ʹ�� hash & (length - 1),��ʵ���� hash % length ���� hash & ( length - 1) ��ǰ���� length �� 2 �� n ���ݡ�
Ϊʲô�����ܾ��ȷֲ�������ײ��?2��n�η�ʵ�ʾ���1����n��0,2��n�η�-1ʵ�ʾ���n��1;
�ܽ�:
- ��������Կ���,�����Ǹ���key��hashȷ�����������λ��ʱ,���nΪ2���ݴη�,���Ա�֤���ݵľ��Ȳ���,���n����2���ݴη�,���������һЩλ����Զ�����������,�˷�����Ŀռ�,�Ӵ�hash��ͻ��
- ��һ����,һ�����ǿ��ܻ���ͨ��%������ȷ��λ��,����Ҳ����,ֻ�������ܲ���&���㡣���ҵ�n��2���ݴη�ʱ: hash & (length - 1) == hash % length
- HashMap����Ϊ2���ݵ�ԭ��,����Ϊ�����ݵĵľ��ȷֲ�,����hash��ͻ,�Ͼ�hash��ͻԽ��,����������һ�����ij���Խ��,�����Ļ��ή��hashmap������
ֵ��ע�����,�������HashMap����ʱ,��������鳤����10,����2����,HashMapͨ��һͨλ������ͻ�����õ��Ŀ϶���2���ݴ���,���������Ǹ�����������֡�
hashmap���ù��캯���Զ����ʼ����:
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
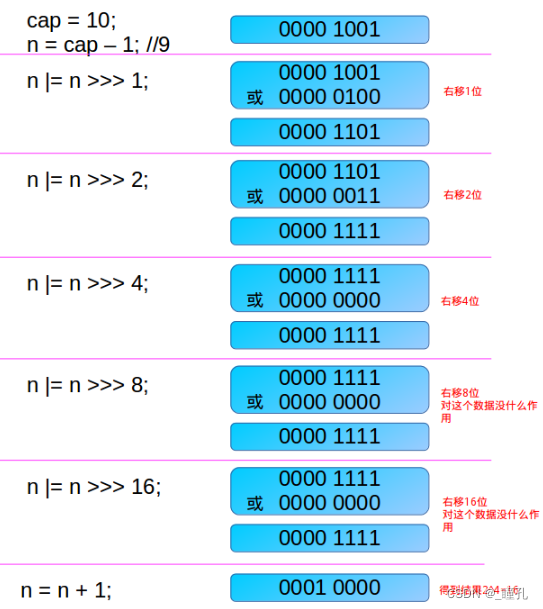
ת��Ϊ2���ݵĺ���:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
����ʵ���� HashMap ʵ��ʱ,��������� initialCapacity,���� HashMap �� capacity ���붼�� 2 ����,���������������ҵ����ڵ��� initialCapacity ����С�� 2 ���ݡ�
-
int n = cap - 1;
��ֹ cap �Ѿ��� 2 ���ݡ���� cap �Ѿ��� 2 ����,��û������� 1 ����,��ִ�������ļ������Ų���֮��,���ص� capacity ������� cap �� 2 ���� -
��� n ��ʱΪ 0 ��(������cap - 1��),������ļ�������������Ȼ�� 0,��ص� capacity ��1(����и� n + 1 �IJ���)��
-
ע��:�������Ҳ���� 32bit ������,������ n |= n >>> 16; ���Ҳ�� 32 �� 1(�������Ѿ��Ǹ�����,��ִ�� tableSizeFor ֮ǰ,�� initialCapacity �����ж�,�������MAXIMUM_CAPACITY(2 ^ 30),��ȡ MAXIMUM_CAPACITY���������MAXIMUM_CAPACITY,��ִ��λ�Ʋ����������������λ�Ʋ���֮��,��� 30 �� 1,������ڵ��� MAXIMUM_CAPACITY��30 �� 1,�� 1 ��� 2 ^ 30)��
3.3: ��������
Ĭ��ֵ��0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
3.4:�����������
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
3.5:�����ٽ�ֵ
Ĭ����8,���������ȳ���8��ת�ɺ�����ṹ
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
Ϊʲô Map Ͱ�н��������� 8 ��תΪ�����?8�����ֵ������HashMap��,��������Ա����,��Դ���ע����ֻ˵���� 8 �� bin(bin���� bucket Ͱ)������ת��������ֵ,���Dz�û��˵��Ϊʲô�� 8��
�� HashMap ����һ��ע��˵��:
/*
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*/
����:��Ϊ�����Ĵ�С��Լ����ͨ��������,��������ֻ�����Ӱ����㹻�Ľ��ʱ��ʹ������㡣�����DZ��̫С(����ɾ���������С)ʱ,�ͻᱻת������ͨ��Ͱ����ʹ�÷ֲ����õ��û� hashCode ʱ,����ʹ�����䡣���������,�������ϣ����,�����н���Ƶ�ʷ��Ӳ��ɷֲ�,Ĭ�ϵ�����ֵΪ0.75,ƽ������ԼΪ0.5,�������ڵ������ȵIJ���ܴ��Է���,�б���Сk��Ԥ�ʳ��ִ�����(exp(-0.5) * pow(0.5, k) / factorial(k))��
TreeNodes ռ�ÿռ�����ͨ Nodes ������,����ֻ�е� bin �����㹻��Ľ��ʱ�Ż�ת��TreeNodes,���Ƿ��㹻������� TREEIFY_THRESHOLD ��ֵ�����ġ��� bin �н��������ʱ,�ֻ�ת����ͨ�� bin���������Dz鿴Դ���ʱ����,�������ȴﵽ 8 ��ת�ɺ����,�����Ƚ��� 6 ��ת����ͨ bin��
�����ͽ�����Ϊʲô����һ��ʼ�ͽ���ת��Ϊ TreeNodes,������Ҫһ���������תΪ TreeNodes,˵���˾���Ȩ��ռ��ʱ�䡣
������ݻ�˵��:�� hashCode ��ɢ�Ժܺõ�ʱ��,���� bin �õ��ĸ��ʷdz�С,��Ϊ���ݾ��ȷֲ���ÿ�� bin ��,���������� bin ���������Ȼ�ﵽ��ֵ����������� hashCode ��,��ɢ�Կ��ܻ���,Ȼ�� jdk �ֲ�����ֹ�û�ʵ�����ֲ��õ� hash �㷨,��˾Ϳ��ܵ��²����ȵ����ݷֲ����������������� hashCode �㷨������ bin �н��ķֲ�Ƶ�ʻ���ѭ���ɷֲ�,���ǿ��Կ���,һ�� bin ���������ȴﵽ 8 ��Ԫ�صĘ���Ϊ 0.00000006,�����Dz������¼�������,֮����ѡ�� 8,�������Q����,�����̾ݸ���ͳ�ƾ����ġ��i�˿ɼ�,��չ����30��� Java ÿһ��Ķ����Ż����Ƿdz��Ͻ��Ϳ�ѧ�ġ�
Ҳ����˵:ѡ�� 8 ��Ϊ���ϲ��ɷֲ�,���� 8 ��ʱ��,�����Ѿ��dz�С��,��������ѡ�� 8��
3.6: ���������ٽ�ֵ
��bin�к����ڵ�С�ڸ�ֵʱ,�ɺ�����˻�Ϊ����,Ĭ��Ϊ6
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
3.7:����������
�� Map ����������������ֵʱ,���е�Ͱ���ܽ������λ�,����Ͱ��Ԫ��̫��ʱ������,���������λ�Ϊ�˱���������ݡ����λ�ѡ��ij�ͻ,���ֵ����С��4*TREEIFY_THRESHOLD
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
3.8:table
�� jdk1.8 �������˽ HashMap ��������������Ӻ��������ɵĽṹ,���� table ���� HashMap �е�����
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
jdk8 ֮ǰ���������� Entry<K,V> ���͡��� jdk1.8 ֮���� Node<K,V> ���͡�ֻ�ǻ��˸�����,��ʵ����һ���Ľӿ�:Map.Entry<K,V>������洢��ֵ�����ݵġ�

3.9:entrySet
���ڴ�Ż���:
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
3.10:size
��¼Ԫ�ظ���
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
3.11:modCount
��¼hashmap���Ĵ���
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
3.12:threshold
�ٽ�ֵ,��ʵ�ʴ�С(����*��������)�����ٽ�ֵʱ,���������
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
3.13:loadFactor
hash���ĸ�������:
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
-
loadFactor ���������� HashMap ���ij̶�,��ʾHashMap�����̶ܳ�,Ӱ�� hash ������ͬһ������λ�õĸ���,���� HashMap ��ʵʱ�������ӵķ���Ϊ:size/capacity,������ռ��Ͱ������ȥ���� capacity��capacity ��Ͱ������,Ҳ���� table �ij��� length��
-
loadFactor ̫���²���Ԫ��Ч�ʵ�,̫С��������������ʵ�,��ŵ����ݻ�ܷ�ɢ��loadFactor ��Ĭ��ֵΪ 0.75f �ǹٷ�������һ���ȽϺõ��ٽ�ֵ��
-
�� HashMap �������ɵ�Ԫ���Ѿ��ﵽ HashMap ���鳤�ȵ� 75% ʱ,��ʾ HashMap ̫����,��Ҫ����,��������������漰�� rehash���������ݵȲ���,�dz��������ܡ����Կ����о����������ݵĴ���,����ͨ������ HashMap ���϶���ʱָ����ʼ�������������⡣
��:���췽��
4.1:���
��ʱ��ʼ����ΪĬ�ϵ�16,��������ҲΪĬ�ϵ�0.75f
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
4.2:�вι���(��ʼ����)
��ʱ����ָ����ʼ����,�����ʼ������Ϊ2����,��ô���Զ������ɴ��ڴ���ֵ����ӽ�����ֵ��2����,��ʱ����������ȻΪĬ�ϵ�0.75f
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
4.3:�вι���(��ʼ����,��������)
����һ������ָ���ij�ʼ�����������ӵ� HashMap��
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
����this.threshold = tableSizeFor(initialCapacity);������:
tableSizeFor(initialCapacity)�ж�ָ���ij�ʼ�������Ƿ���2��n����,���������ô���Ϊ��ָ����ʼ�����������С��2��n���ݡ�
����ע��,��tableSizeFor�������ڲ������������ݷ��ظ�����������,����ֱ�Ӹ�ֵ��threshold�߽�ֵ�ˡ���Щ�˻����������һ��bug,Ӧ��������д:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;
�����ŷ���threshold����˼(��HashMap��size����threshold�����ֵʱ������)��
������ע��,��jdk8�Ժ�Ĺ��췽����,��û�ж�table�����Ա�������г�ʼ��,table�ij�ʼ�����Ƴٵ���put������,��put�����л��threshold���¼��㡣
4.4:�вι���(map)
����һ��ӳ���ϵ��ָ��map��ͬ���µ�HashMap
/**
* Constructs a new <tt>HashMap</tt> with the same mappings as the
* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified <tt>Map</tt>.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
// δ��ʼ��,sΪm��ʵ��Ԫ�ظ���
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// ����õ���t������ֵ,���ʼ����ֵ
if (t > threshold)
threshold = tableSizeFor(t);
}
// �ѳ�ʼ��,����mԪ�ظ���������ֵ,�������ݴ���
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
float ft = ((float)s / loadFactor) + 1.0F; ��һ�д�����ΪʲôҪ�� 1.0F ?
s/loadFactor �Ľ����С��,�� 1.0F �� (int)ft �൱���Ƕ�С����һ������ȡ���Ծ����ܵı�֤��������,����������ܹ����� resize �ĵ��ô��������� + 1.0F ��Ϊ�˻�ȡ�����������
����:ԭ�����ϵ�Ԫ�ظ����� 6 ��,��ô 6/0.75 ��8,�� 2 ��n����,��ô�µ������С���� 8 �ˡ�Ȼ��ԭ����������ݾͻ�洢�������� 8 ���µ���������,�����ᵼ���ڴ洢Ԫ�ص�ʱ��,��������,���ü�������,��ô���ܽ�����,����� +1 ��,���鳤��ֱ�ӱ�Ϊ16��,�������Լ�����������ݡ�
��:��Ա����
5.1:put()
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1)transient Node<K,V>[] table; ��ʾ�洢Map������Ԫ�ص����顣
2)(tab = table) == null ��ʾ���յ�table��ֵ��tab,Ȼ���ж�tab�Ƿ����null,��һ�ο϶���null��
3)(n = tab.length) == 0 ��ʾ������ij���0��ֵ��n,Ȼ���ж�n�Ƿ����0,n����0,����if�ж�ʹ��˫��,����һ������,��ִ�д��� n = (tab = resize()).length; ���������ʼ��,������ʼ���õ����鳤�ȸ�ֵ��n��
4)ִ����n = (tab = resize()).length,����tabÿ���ռ䶼��null��
*/
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*
1)i = (n - 1) & hash ��ʾ���������������ֵ��i,��ȷ��Ԫ�ش�����ĸ�Ͱ�С�
2)p = tab[i = (n - 1) & hash]��ʾ��ȡ�������λ�õ����ݸ�ֵ�����p��
3) (p = tab[i = (n - 1) & hash]) == null �жϽ��λ���Ƿ����null,���Ϊnull,��ִ�д���:tab[i] = newNode(hash, key, value, null);���ݼ�ֵ�Դ����µĽ������λ�õ�Ͱ�С�
С��:�����ǰͰû�й�ϣ��ײ��ͻ,��ֱ�ӰѼ�ֵ�Բ���ռ�λ�á�
*/
if ((p = tab[i = (n - 1) & hash]) == null)
// ����һ���µĽ����뵽Ͱ��
tab[i] = newNode(hash, key, value, null);
else {
// ִ��else˵��tab[i]������null,��ʾ���λ���Ѿ���ֵ��
Node<K,V> e; K k;
/*
�Ƚ�Ͱ�е�һ��Ԫ��(�����еĽ��)��hashֵ��key�Ƿ����
1)p.hash == hash :p.hash��ʾԭ���������ݵ�hashֵ hash��ʾ���������ݵ�hashֵ �Ƚ�����hashֵ�Ƿ���ȡ�
˵��:p��ʾtab[i],�� newNode(hash, key, value, null)�������ص�Node����
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
����Node���о��г�Ա����hash������¼��֮ǰ���ݵ�hashֵ�ġ�
2)(k = p.key) == key :p.key��ȡԭ�����ݵ�key��ֵ��k key ��ʾ���������ݵ�key�Ƚ�����key�ĵ�ֵַ�Ƿ���ȡ�
3)key != null && key.equals(k):�ܹ�ִ�е�����˵������key�ĵ�ֵַ�����,��ô���жϺ����ӵ�key�Ƿ����null,���������null�ٵ���equals�����ж�����key�������Ƿ���ȡ�
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
/*
˵��:����Ԫ�ع�ϣֵ���,����key��ֵҲ���,���ɵ�Ԫ���������ֵ��e,��e����¼
*/
e = p;
// hashֵ����Ȼ���key�����;�ж�p�Ƿ�Ϊ��������
else if (p instanceof TreeNode)
// ��������
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// ˵�����������
else {
/*
1)����������Ļ���Ҫ�����������Ȼ�����
2)����ѭ�������ķ�ʽ,�ж��������Ƿ����ظ���key
*/
for (int binCount = 0; ; ++binCount) {
/*
1)e = p.next ��ȡp����һ��Ԫ�ظ�ֵ��e��
2)(e = p.next) == null �ж�p.next�Ƿ����null,����null,˵��pû����һ��Ԫ��,��ô��ʱ������������β��,��û���ҵ��ظ���key,��˵��HashMapû�а����ü�,���ü�ֵ�Բ��������С�
*/
if ((e = p.next) == null) {
/*
1)����һ���µĽ����뵽β��
p.next = newNode(hash, key, value, null);
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
ע����ĸ�����next��null,��Ϊ��ǰԪ�ز��뵽����ĩβ��,��ô��һ�����϶���null��
2)�������ӷ�ʽҲ�����������ݽṹ���ص�,ÿ����������µ�Ԫ�ء�
*/
p.next = newNode(hash, key, value, null);
/*
1)����������֮���жϴ�ʱ�������Ƿ����TREEIFY_THRESHOLD�ٽ�ֵ8,�������������ת��Ϊ�������
2)int binCount = 0 :��ʾforѭ���ij�ʼ��ֵ����0��ʼ��������¼�ű������ĸ�����ֵ��0��ʾ��һ�����,1��ʾ�ڶ�����㡣������7��ʾ�ڰ˸����,���������еĵ�һ��Ԫ��,Ԫ�ظ�����9��
TREEIFY_THRESHOLD - 1 --��8 - 1 ---��7
���binCount��ֵ��7(���������еĵ�һ��Ԫ��,Ԫ�ظ�����9)
TREEIFY_THRESHOLD - 1Ҳ��7,��ʱת���������
*/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// ת��Ϊ�����
treeifyBin(tab, hash);
// ����ѭ��
break;
}
/*
ִ�е�����˵��e = p.next ����null,�������һ��Ԫ�ء������ж������н���keyֵ������Ԫ�ص�keyֵ�Ƿ���ȡ�
*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// ���,����ѭ��
/*
Ҫ���ӵ�Ԫ�غ������еĴ��ڵ�Ԫ�ص�key�����,������forѭ���������ټ����Ƚ���
ֱ��ִ�������if���ȥ�滻ȥ if (e != null)
*/
break;
/*
˵�������ӵ�Ԫ�غ͵�ǰ��㲻���,����������һ����㡣
���ڱ���Ͱ�е�����,��ǰ���e = p.next���,���Ա�������
*/
p = e;
}
}
/*
��ʾ��Ͱ���ҵ�keyֵ��hashֵ�����Ԫ����ȵĽ��
Ҳ����˵ͨ������IJ����ҵ����ظ��ļ�,����������ǰѸü���ֵ��Ϊ�µ�ֵ,�����ؾ�ֵ
���������put����������
*/
if (e != null) {
// ��¼e��value
V oldValue = e.value;
// onlyIfAbsentΪfalse���߾�ֵΪnull
if (!onlyIfAbsent || oldValue == null)
// ����ֵ�滻��ֵ
// e.value ��ʾ��ֵ value��ʾ��ֵ
e.value = value;
// ���ʺ�ص�
afterNodeAccess(e);
// ���ؾ�ֵ
return oldValue;
}
}
// �ļ�¼����
++modCount;
// �ж�ʵ�ʴ�С�Ƿ����threshold��ֵ,�������������
if (++size > threshold)
resize();
// �����ص�
afterNodeInsertion(evict);
return null;
}
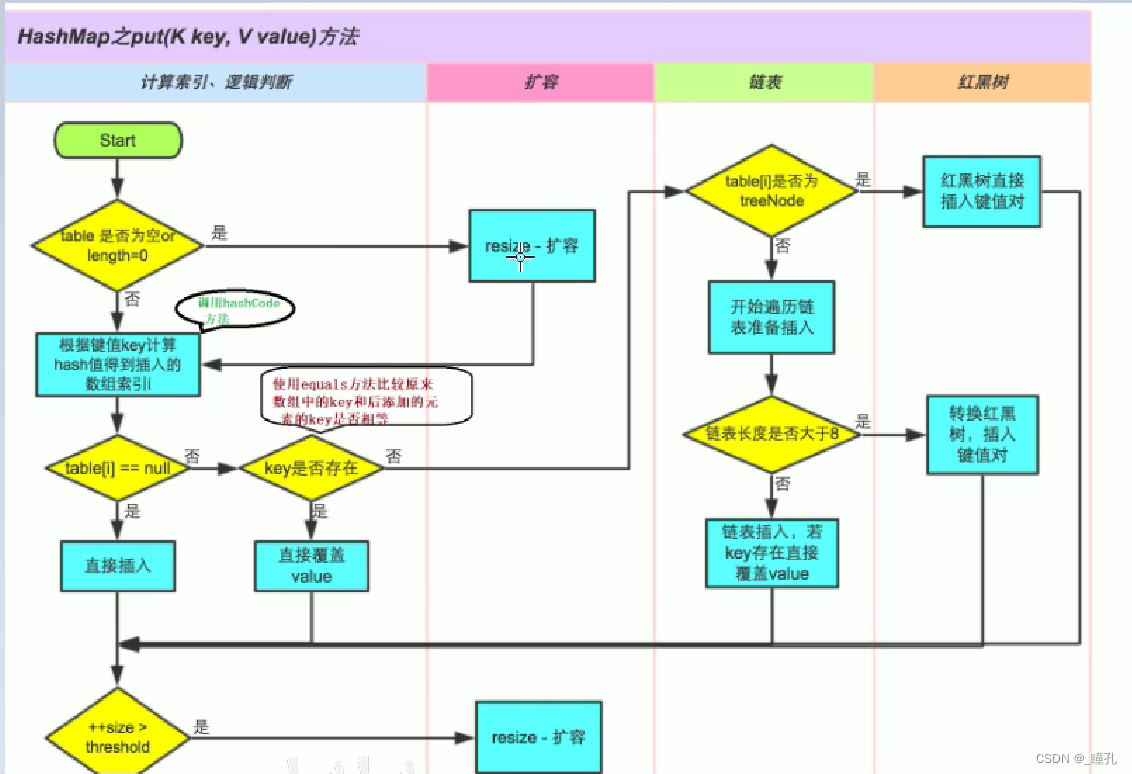
put�����DZȽϸ��ӵ�,ʵ�ֲ����������:
- ��ͨ�� hash ֵ����� key ӳ�䵽�ĸ�Ͱ;
- ���Ͱ��û����ײ��ͻ,��ֱ�Ӳ���;
- ���������ײ��ͻ��,����Ҫ������ͻ:
- �����Ͱʹ�ú����������ͻ,����ú�����ķ�����������;
- ������ô�ͳ����ʽ�������롣������ij��ȴﵽ�ٽ�ֵ,�����ת��Ϊ�����;
- ���Ͱ�д����ظ��ļ�,��Ϊ�ü��滻��ֵ value;
- ��� size ������ֵ threshold,���������;
�������о��� key �Ĺ�ϣֵ����μ�������ġ�key �Ĺ�ϣֵ��ͨ������������������ġ������ϣ�������ȼ���� key �� hashCode ��ֵ�� h,Ȼ���� h �������� 16 λ��Ķ����ƽ��а�λ���õ����� hash ֵ���������������ʾ:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- key.hashCode();����ɢ��ֵҲ���� hashcode,����������ɵ�һ��ֵ��
- n ��ʾ�����ʼ���ij����� 16��
- &(��λ������):�������:��ͬ�Ķ�������λ��,���� 1 ��ʱ��,���Ϊ 1,����Ϊ0��
- ^(��λ�������):�������:��ͬ�Ķ�������λ��,������ͬ,���Ϊ 0,��ͬΪ 1��

����˵����:
�� 16bit ����,�� 16bit �� 16bit ����һ�����(�õ��� hashCode ת��Ϊ 32 λ������,ǰ 16 λ�ͺ� 16 λ�� 16bit �� 16bit ����һ�����)��
����:ΪʲôҪ����������?
����� n �����鳤�Ⱥ�С,������ 16 �Ļ�,��ô n - 1 ��Ϊ 1111 ,������ֵ�� hashCode ֱ������λ�����,ʵ����ֻʹ���˹�ϣֵ�ĺ� 4 λ���������ϣֵ�ĸ�λ�仯�ܴ�,��λ�仯��С,�����ͺ�������ɹ�ϣ��ͻ��,��������Ѹߵ�λ����������,�Ӷ������������⡣
5.2:treeifyBin()
����������֮���жϴ�ʱ�������Ƿ���� TREEIFY_THRESHOLD �ٽ�ֵ 8,�������������ת��Ϊ�����,ת��������ķ��� treeifyBin,�����������:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
/*
�����ǰ����Ϊ�ջ�������ij���С�ڽ������λ�����ֵ(MIN_TREEIFY_CAPACITY = 64),��ȥ���ݡ������ǽ�����Ϊ�������
Ŀ��:��������С,��ôת�������,Ȼ�����Ч��Ҫ��һЩ����ʱ��������,��ô���¼����ϣֵ,���������п��ܾͱ����,���ݻ�ŵ�������,���������˵Ч�ʸ�һЩ��
*/
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//���ݷ���
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
/*
1)ִ�е�����˵����ϣ���е����鳤�ȴ�����ֵ64,��ʼ�������λ�
2)e = tab[index = (n - 1) & hash]��ʾ�������е�Ԫ��ȡ����ֵ��e,e�ǹ�ϣ����ָ��λ��Ͱ����������,�ӵ�һ����ʼ
*/
// hd:�������ͷ��� tl:�������β���
TreeNode<K,V> hd = null, tl = null;
do {
// �´���һ�����Ľ��,���ݺ͵�ǰ�������eһ��
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p; // ���´�����p��㸳ֵ���������ͷ���
else {
p.prev = tl; // ����һ�����p��ֵ�����ڵ�p��ǰһ�����
tl.next = p; // �����ڽ��p��Ϊ����β������һ�����
}
tl = p;
/*
e = e.next ����ǰ������һ����㸳ֵ��e,�����һ����㲻����null
��ص��������ȡ�������н��ת��Ϊ�����
*/
} while ((e = e.next) != null);
/*
��Ͱ�еĵ�һ��Ԫ�ؼ������е�Ԫ��ָ���½��ĺ�����Ľ��,�Ժ����Ͱ���Ԫ�ؾ��Ǻ����
�������������ݽṹ��
*/
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
��������һ���������¼�����:
- ���ݹ�ϣ����Ԫ�ظ���ȷ�������ݻ������λ���
- ��������λ�����Ͱ�е�Ԫ��,������ͬ���������ν��,��������,��������ϵ��
- Ȼ����Ͱ�еĵ�һ��Ԫ��ָ���´������������,�滻Ͱ����������Ϊ���λ����ݡ�
5.3:resize()
final Node<K,V>[] resize() {
// �õ���ǰ����
Node<K,V>[] oldTab = table;
// �����ǰ�������null���ȷ���0,���ص�ǰ����ij���
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//��ǰ��ֵ�� Ĭ����12(16*0.75)
int oldThr = threshold;
int newCap, newThr = 0;
// ����ϵ����鳤�ȴ���0
// ��ʼ�������ݺ�Ĵ�С
if (oldCap > 0) {
// �������ֵ�Ͳ���������,��ֻ��������ײȥ��
if (oldCap >= MAXIMUM_CAPACITY) {
// ����ֵΪint�����ֵ
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*
û�������ֵ,������Ϊԭ����2��
1) (newCap = oldCap << 1) < MAXIMUM_CAPACITY ����2��֮������ҪС���������
2)oldCap >= DEFAULT_INITIAL_CAPACITY ԭ���鳤�ȴ��ڵ��������ʼ������16
*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// ��ֵ����һ��
newThr = oldThr << 1; // double threshold
}
// ����ֵ�����0 ֱ�Ӹ�ֵ
else if (oldThr > 0) // ����ֵ��ֵ���µ����鳤��
newCap = oldThr;
else { // ֱ��ʹ��Ĭ��ֵ
newCap = DEFAULT_INITIAL_CAPACITY;//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// �����µ�resize�������
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// �µķ�ֵ Ĭ��ԭ����12 ����2֮���Ϊ24
threshold = newThr;
// �����µĹ�ϣ��
@SuppressWarnings({"rawtypes","unchecked"})
//newCap���µ����鳤��--��32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// �жϾ������Ƿ���ڿ�
if (oldTab != null) {
// ��ÿ��bucket���ƶ����µ�buckets��
// �����ɵĹ�ϣ����ÿ��Ͱ,���¼���Ͱ��Ԫ�ص���λ��
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// ԭ�������ݸ�ֵΪnull ����GC����
oldTab[j] = null;
// �ж������Ƿ�����һ������
if (e.next == null)
// û����һ������,˵����������,��ǰͰ��ֻ��һ����ֵ��,ֱ�Ӳ���
newTab[e.hash & (newCap - 1)] = e;
//�ж��Ƿ��Ǻ����
else if (e instanceof TreeNode)
// ˵���Ǻ������������ͻ��,�������ط��������ֿ�
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // ��������������ͻ
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// ͨ�����������ԭ�������������λ��
do {
// ԭ����
next = e.next;
// �������ж��������true e��������resize֮����Ҫ�ƶ�λ��
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// ԭ����+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// ԭ�����ŵ�bucket��
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// ԭ����+oldCap�ŵ�bucket��
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
ʲôʱ�����Ҫ����:�� HashMap �е�Ԫ�ظ������������С(���鳤��)*loadFactor(��������)ʱ,�ͻ������������,loadFactor ��Ĭ��ֵ�� 0.75��
HashMap ��������ʲô:��������,�������һ������ hash ����,���һ���� hash �������е�Ԫ��,�Ƿdz���ʱ�ġ��ڱ�д������,Ҫ�������� resize��
HashMap �ڽ�������ʱ,ʹ�õ� rehash ��ʽ�dz�����,��Ϊÿ�����ݶ��Ƿ���,��ԭ������� (n - 1) & hash �Ľ�����,ֻ�Ƕ���һ�� bit λ,���Խ��Ҫô����ԭ����λ��,Ҫô�ͱ����䵽 ��ԭλ�� + �������� ���λ�á��������Ǵ� 16 ��չΪ 32 ʱ,����ı仯������ʾ:

���Ԫ�������¼��� hash ֮��,��Ϊ n ��Ϊ 2 ��,��ô n - 1 �ı�Ƿ�Χ�ڸ�λ�� 1bit(��ɫ),����µ� index �ͻᷢ�������ı仯:

5 �Ǽ�����������ԭ������������������֤��������������:����֮�����Խ��Ҫô����ԭ����λ��,Ҫô�ͱ����䵽 ��ԭλ�� + �������� ���λ�á�
���,���������� HashMap ��ʱ��,����Ҫ���¼��� hash,ֻ��Ҫ����ԭ���� hash ֵ�������Ǹ� bit �� 1 ���� 0 �Ϳ�����,�� 0 �Ļ�����û��,�� 1 �Ļ�������� ��ԭλ�� + �������� �����Կ�����ͼΪ 16 ����Ϊ 32 �� resize ʾ��ͼ:
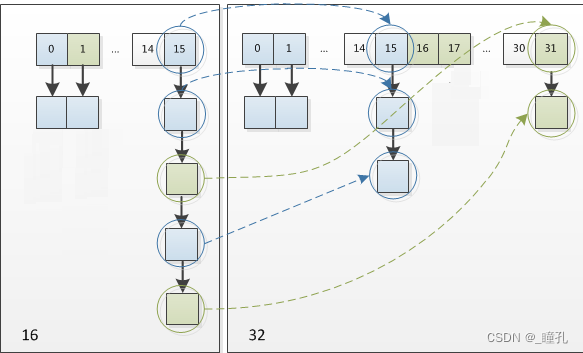
������Ϊ��������� rehash ��ʽ,��ʡȥ�����¼��� hash ֵ��ʱ��,����ͬʱ,���������� 1bit �� 0 ���� 1 ������Ϊ�������,�� resize �Ĺ����б�֤�� rehash ֮��ÿ��Ͱ�ϵĽ����һ��С�ڵ���ԭ��Ͱ�ϵĽ����,��֤�� rehash ֮����ָ����ص� hash ��ͻ,���ȵİ�֮ǰ�ij�ͻ�Ľ���ɢ���µ�Ͱ���ˡ�
5.4:remove()
ɾ�����������������ҵ�Ԫ�ص�λ��,����������ͱ��������ҵ�Ԫ��֮��ɾ����������ú�����ͱ�����Ȼ���ҵ�֮����ɾ��,��С�� 6 ��ʱ��Ҫת������
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// ����hash�ҵ�λ��
// �����ǰkeyӳ�䵽��Ͱ��Ϊ��
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// ���Ͱ�ϵĽ�����Ҫ�ҵ�key,��nodeָ��ý��
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// ˵����������һ�����
if (p instanceof TreeNode)
// ˵�����Ժ�����������ij�ͻ,���ȡ�����Ҫɾ���Ľ��
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// �ж��Ƿ���������ʽ����hash��ͻ,�ǵĻ���ͨ������������Ѱ��Ҫɾ���Ľ��
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// �Ƚ��ҵ���key��value��Ҫɾ�����Ƿ�ƥ��
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// ͨ�����ú�����ķ�����ɾ�����
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
// ����ɾ��
tab[index] = node.next;
else
p.next = node.next;
// ��¼�Ĵ���
++modCount;
// �䶯������
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
5.5:get()
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// �����ϣ����Ϊ�ղ���key��Ӧ��Ͱ�ϲ�Ϊ��
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
/*
�ж�����Ԫ���Ƿ����
����������λ�ü���һ��Ԫ��
ע��:���Ǽ���һ��Ԫ��
*/
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// ������ǵ�һ��Ԫ��,�ж��Ƿ��к������
if ((e = first.next) != null) {
// �ж��Ƿ��Ǻ����,�ǵĻ����ú�����е�getTreeNode������ȡ���
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// ���Ǻ�����Ļ�,�Ǿ��������ṹ��,ͨ��ѭ���ķ����ж��������Ƿ���ڸ�key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
get ����ʵ�ֵIJ���:
- ͨ�� hash ֵ��ȡ�� key ӳ�䵽��Ͱ
- Ͱ�ϵ� key ����Ҫ���ҵ� key,��ֱ���ҵ�������
- Ͱ�ϵ� key ����Ҫ�ҵ� key,��鿴�����Ľ��:
- �����������Ǻ�������,ͨ�����ú�����ķ������� key ��ȡ value
- �������������������,��ͨ��ѭ�������������� key ��ȡ value
��������������õ��� getTreeNode ����ͨ�����ν��� find �������в���:
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p; // �ҵ�֮��ֱ�ӷ���
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
// �ݹ����
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
- ���Һ����,����֮ǰ����ʱ�Ѿ���֤��������������,��˲���ʱ���������۰����,Ч�ʸ��ߡ�
- ����Ͳ���ʱһ��,����ԱȽ��Ĺ�ϣֵ��Ҫ���ҵĹ�ϣֵ���,�ͻ��ж�key�Ƿ����,��Ⱦ�ֱ�ӷ��ء�����Ⱦʹ������еݹ���ҡ�
- ��Ϊ��,��������ͨ��key.equals(k)����,O(logn)����Ϊ����,����������ͨ��key.equals(k)����,O(n)��
5.6:���� HashMap ����
����һ:�ֱ���� Key �� Values
for (String key : map.keySet()) {
System.out.println(key);
}
for (Object vlaue : map.values() {
System.out.println(value);
}
������:ʹ�� Iterator ����������
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> mapEntry = iterator.next();
System.out.println(mapEntry.getKey() + "---" + mapEntry.getValue());
}
������:ͨ�� get ��ʽ(������ʹ��)
Set<String> keySet = map.keySet();
for (String str : keySet) {
System.out.println(str + "---" + map.get(str));
}
�������Ȥ�˽�����������,��ӭ���ҵĸ�����վ����:ͫ�ĸ��˿ռ�

