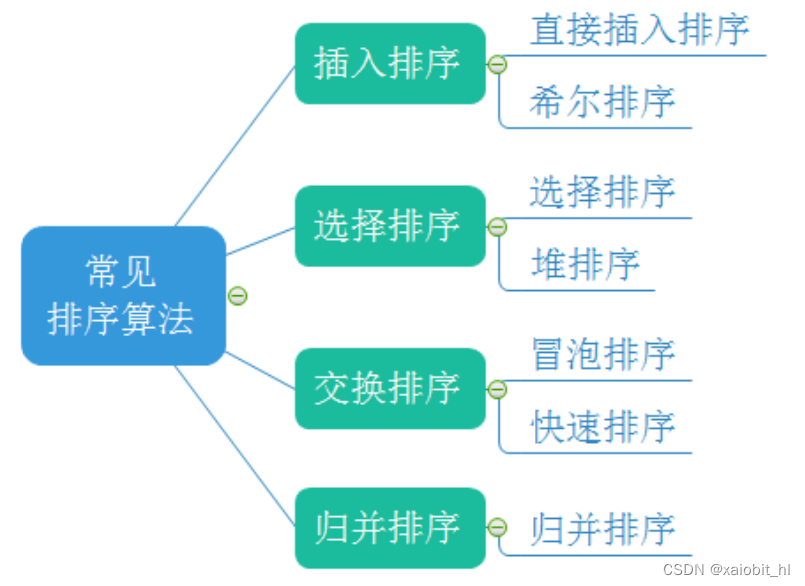
目录
1.直接插入排序
2.希尔排序
3.直接选择排序
4.堆排序
5.冒泡排序
6.快速排序
? ? ? ? 6.1.Hoare法
? ? ? ? 6.2.挖坑法
? ? ? ? 6.3.前后指针法
? ? ? ? 6.4.快排的优化
? ? ? ? ? ? ? ? 6.4.1.区间内进行插排优化
? ? ? ? ? ? ? ? 6.4.2.三数取中法
? ? ? ? ? ? ? ? 6.4.3.聚焦与基准相同的值
? ? ? ? 6.5.非递归实现快排
7.归并排序
? ? ? ? 7.1.非递归实现归并排序
? ? ? ? 7.2.归并排序的应用
8.计数排序
9.八大排序之间的性能评估
1.直接插入排序
基本思想
把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到 一个新的有序序列。我们平时玩的扑克牌用到的就是这个思想。
代码实现
public static void insertSort(int[] array) {
//外层循环控制待插入的数据
for (int i = 1; i < array.length; i++) {
int tmp = array[i];
int j = i - 1;
//内层循环控制已排好序的数据
for (; j >= 0; j--) {
if(tmp < array[j]) {
array[j + 1] = array[j];
} else {
break;
}
}
array[j + 1] = tmp;
}
}画图分析

特性总结
1.元素集合越接近有序,直接插入排序算法的时间效率越高。
2. 时间复杂度(对数据敏感):【直接插入排序的应用场景是:当数据量小,并且已经趋于有序的时候,使用直接插入排序】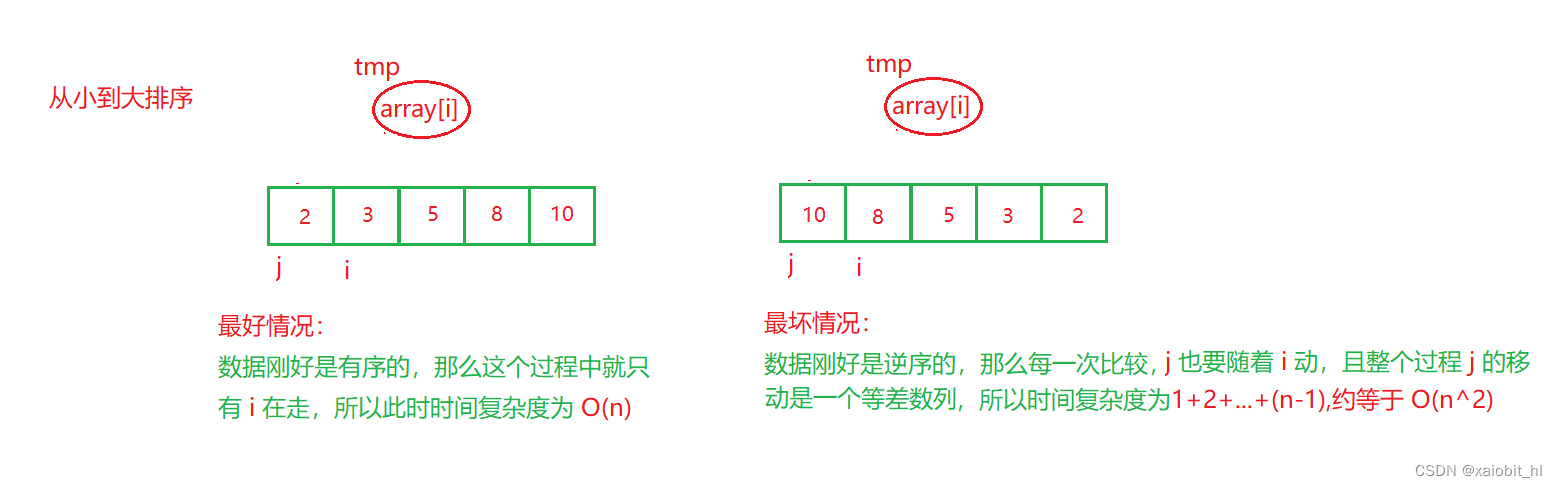
3.?空间复杂度:O(1)
4.稳定性:稳定(补充):
a.判断稳定性,一般如果有跳跃式的交换,一般来说是不稳定的;
b.如果本身是一个稳定的排序,我们可以实现为不稳定的;如果本身是一个不稳定的排序,那么就不可能变成一个稳定的排序。
?2.希尔排序(缩小增量排序)
基本思想
先选定一个整数gap,把待排序文件中所有记录分成gap组,所 有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后,不断缩小gap,重复上述分组和排序的工作。当到达gap =1 时,所有记录已经排好序 。
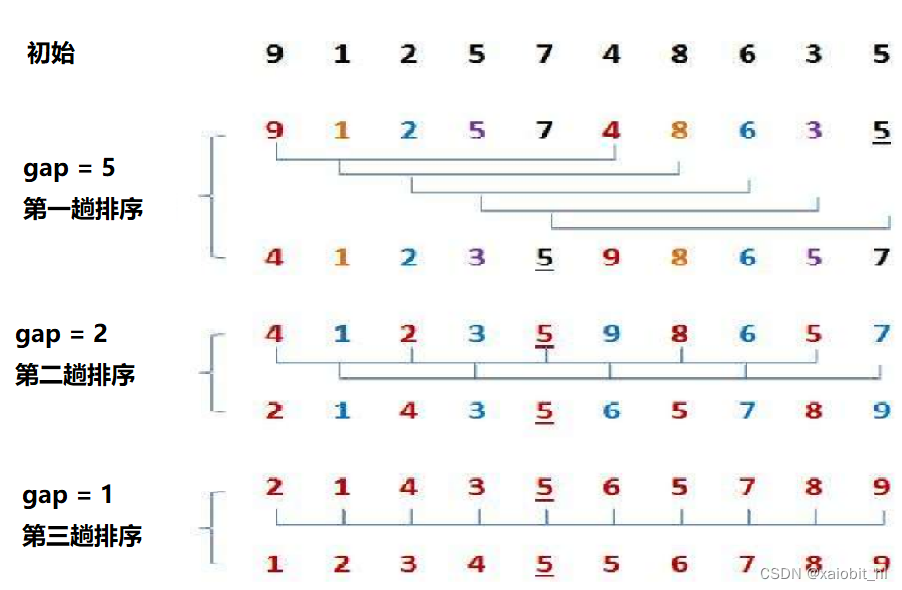
?代码实现
private void shell(int[] array, int gap) {
//这里的for循环的 i++ 可不能写成 i += gap
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i - gap;
for (; j >= 0 ; j -= gap) {
if(tmp < array[j]) {
array[j + gap] = array[j];
} else {
break;
}
}
array[j + gap] = tmp;
}
}
public void shellSort(int[] array) {
int gap = array.length / 2;
while(gap > 1) {
shell(array,gap);
gap /= 2;
}
shell(array, 1);
}?特性总结
1. 希尔排序是对直接插入排序的优化;
2.当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,再进行一次排序,此时数据已经有序了,这样整体而言可以达到优化的效果,例如:
3.?希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,而且很多书中给出的时间复杂度都不固定,可以按照《数据结构(C语言版)》--- 严蔚敏?给出的 n^1.3~n^1.5?来记

3.直接选择排序
基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
代码实现?
public void selectSort(int[] array) {
for (int i = 0; i < array.length; i++) {
int minIndex = i;
for (int j = i + 1; j < array.length; j++) {
if(array[j] < array[minIndex]) {
minIndex = j;//记录最小数据的下标
}
}
swap(array, i, minIndex);
}
}
private void swap(int[] array, int i, int minIndex) {
int tmp = array[i];
array[i] = array[minIndex];
array[minIndex] = tmp;
}画图分析

??特性总结
1. 时间复杂度(不管有序无序):O(N^2)2. 空间复杂度:O(1)3. 稳定性:不稳定
4.堆排序
基本思想
1.从小到大排序:需要建立一个大根堆? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 2.从大到小排序:需要建立一个小根堆
这样做的原因???
因为我们排序是要对数组本身进行排序,比如从小到大排序的话,
如果建小根堆,每次弹出堆顶元素存在一个数组中,这不叫堆排序。
代码实现
private void swap(int[] array, int child, int root) {
int tmp = array[child];
array[child] = array[root];
array[root] = tmp;
}
private void shiftDown(int[] array, int root, int len) {
int child = 2 * root + 1;
while(child < len) {
if(child + 1 < len && array[child] < array[child + 1]) {
child++;
}
if(array[child] > array[root]) {
swap(array, child, root);
root = child;
child = 2 * root + 1;
} else {
break;
}
}
}
//建大根堆 O(n)
private void createHeap(int[] array) {
for (int p = (array.length-1-1)/2; p >= 0 ; p--) {
shiftDown(array, p, array.length);
}
}
public void heapSort(int[] array) {
createHeap(array);//O(n)
int end = array.length - 1;
//O(n*log2^n)
while(end > 0) {
swap(array, 0, end);
shiftDown(array, 0, end);
end--;
}
}?具体步骤
1.建立大根堆;
2. 每次0下标和end下标交换;
3.向下调整0下标这棵树;
4.end--
- ?特性总结
1. 时间复杂度:O(N*logN)?建堆时间复杂度(JAVA实现优先级队列这一篇博客有详细讲到):O(n)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?每次向下调整的时间:O(log2^n) --也就是完全二叉树的高度? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?所以堆排序的时间复杂度为:O(n * log2^n) ?
2. 空间复杂度:O(1)3. 稳定性:不稳定
5.冒泡排序
代码实现
public void bubbleSort(int[] array) {
for (int i = 0; i < array.length - 1; i++) {
boolean flg = false;
for (int j = 0; j < array.length - 1 - i; j++) {
if(array[j] > array[j + 1]) {
swap(array, j, j + 1);
flg = true;
}
}
if(!flg) {
break;
}
}
}特性总结
1. 冒泡排序是一种非常容易理解的排序2. 时间复杂度:O(N^2)3. 空间复杂度:O(1)4. 稳定性:稳定
6.快速排序
基本思想
任取待排序元素序列中的某元 素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有 元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止 。
6.1.方法一:Hoare法
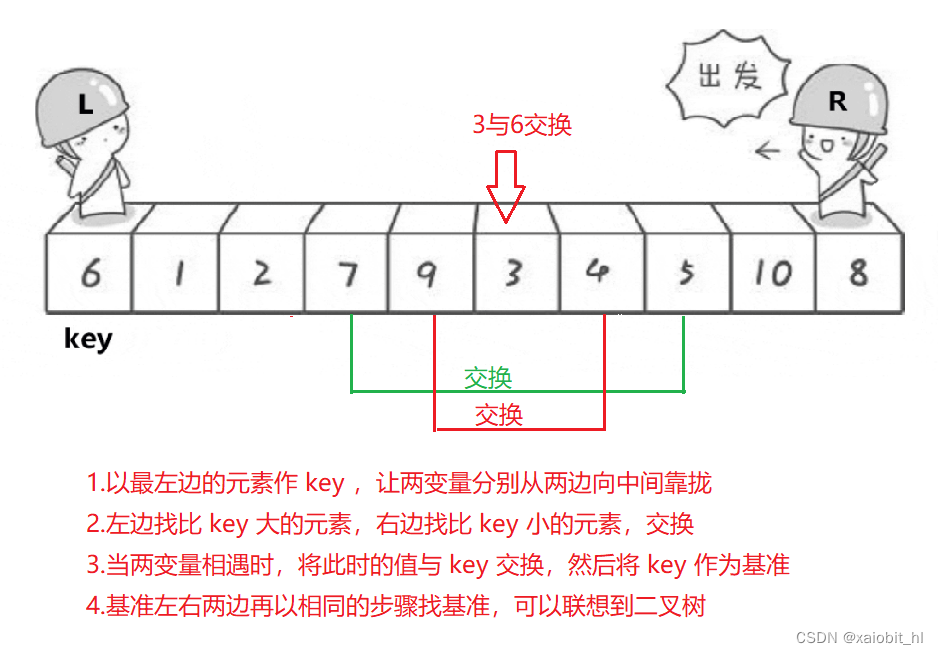
?代码实现
public int partitionHoare(int[] array, int low, int high) {
int key = low;//记录 key 的下标,交换要用到
int tmp = array[low];//记录 key 的值,比较大小时用到
while(low < high) {
//左边做 key ,右边先走
//从右往左找比 key 小的值
while(low < high && array[high] >= tmp) {
high--;
}
//从左往右找比 key 大的值
while(low < high && array[low] <= tmp) {
low++;
}
swap(array, low, high);
}
swap(array, low, key);
return low;
}
public void quick(int[] array, int left, int right) {
if(left >= right) return;//可能右边没数据
int pivot = partitionHoare(array, left, right);
quick(array, left, pivot - 1);
quick(array, pivot + 1, right);
}
public void quickSort(int[] array) {
quick(array,0,array.length - 1);
}画图分析(三个重要注意点)
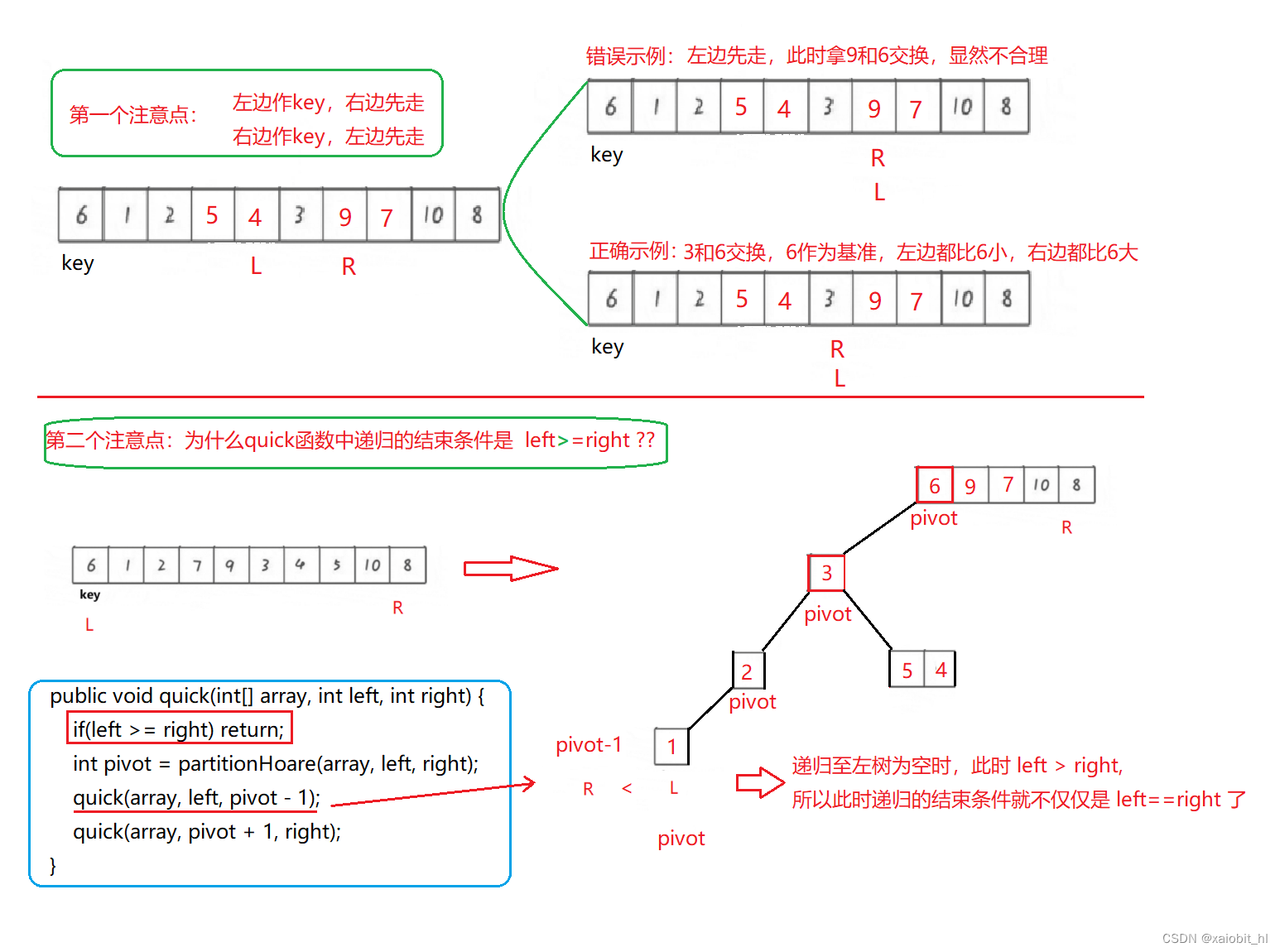
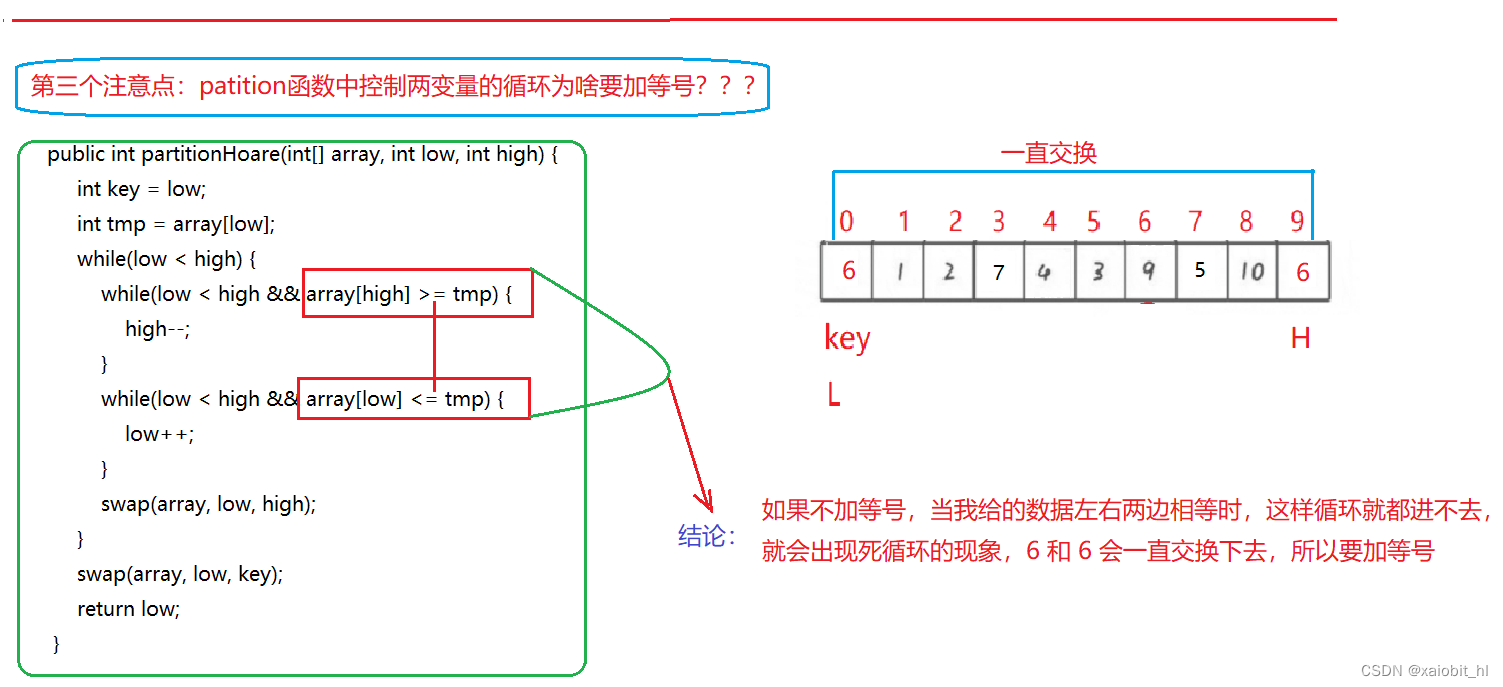
?时间复杂度
好的情况 O(n*log2^n)? : 此时是一棵完全二叉树,树的高度为 log2^n,每一层左右两边递归的区间是 O(n),所以时间复杂度为 O(n*log2^n).
?坏的情况 O(n^2) :此时是棵只有左树或右树的二叉树,此时树的高度就是节点个数,又每一层的递归区间为 O(n),所以时间复杂度为 O(n^2).
空间复杂度
空间复杂度同理,每一层只用到了一个变量,所以好的情况下是 O(log2^n),坏的情况下是 O(n)
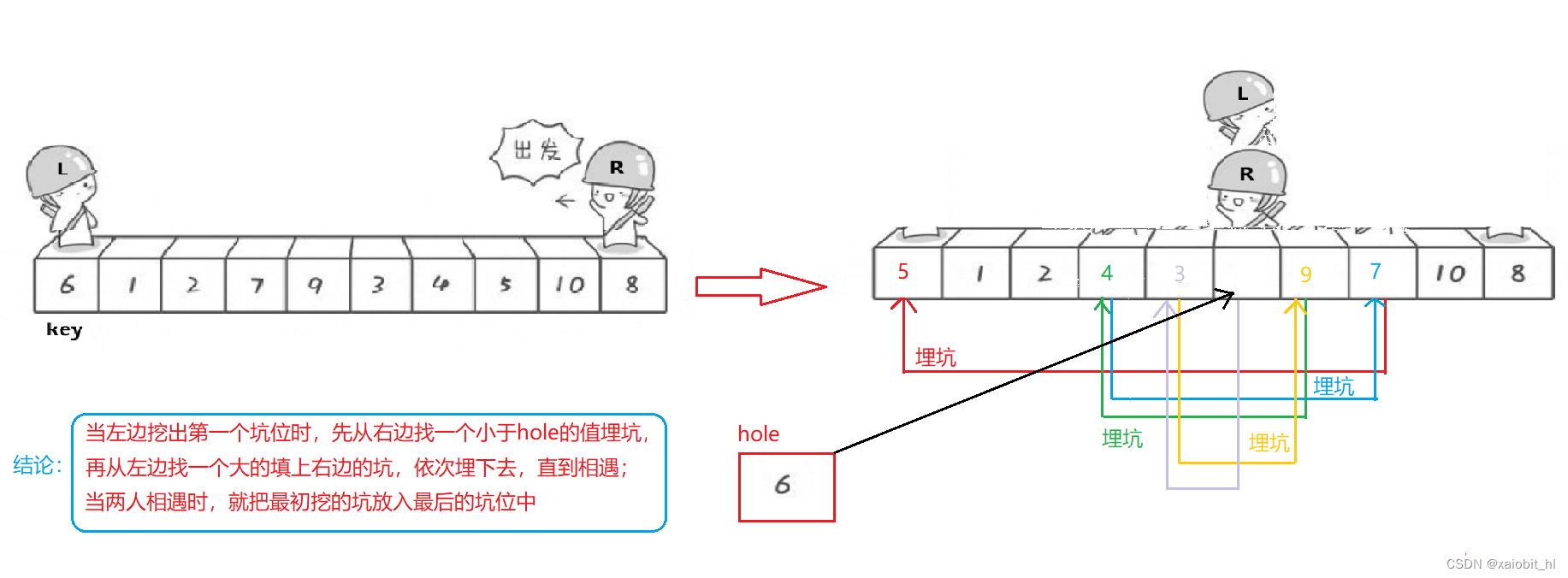
6.2.方法二:挖坑法
基本步骤
1.把最左边的 key 挖出来存放在一个单独的空间 hole 中;
2.先从右边找一个比 key 小的埋坑,再从左边找一个比 key 大的埋进右边的坑,依次埋坑直? ? ?到相遇;
3.相遇时,将最初的存在 hole 中的数据埋进相遇时的坑位
代码实现
public int partitionHole(int[] array, int low, int high) {
int hole = array[low];
while(low < high) {
while(low < high && array[high] >= hole) {
high--;
}
//埋坑
array[low] = array[high];
while(low < high && array[low] <= hole) {
low++;
}
//埋坑
array[high] = array[low];
}
//把第一个挖出来的元素埋进相遇点的坑位
array[low] = hole;
return low;
}画图分析
时间复杂度?
挖坑法的patition单独的时间复杂度为 O(n);? 整个排序的时间复杂度还是 O(n*log2^n);
6.3.方法三:前后指针法
基本思想
1.两个"指针"控制除 key 之外的所有数据,一个找大于 key 的,一个找小于 key 的;
2.交换:在没有出现大于 key 之前的交换,都是自己跟自己交换,出现后才是真正的调整;
3.将 key 的值和 prev - 1的值进行交换(因为prev保存的值都是大于key的值)
代码实现
public int partition(int[] array, int low, int high) {
int prev = low + 1;//存下标,方便交换
int key = array[low];//存值,方便比较
for (int i = low + 1; i <= high; i++) {
if(array[i] < key) {
swap(array, prev, i);
prev++;//当 prev 保存大于 key 值的下标时,此时才不会自己和自己交换
}
}
swap(array, low, prev - 1);
return prev - 1;
}画图分析
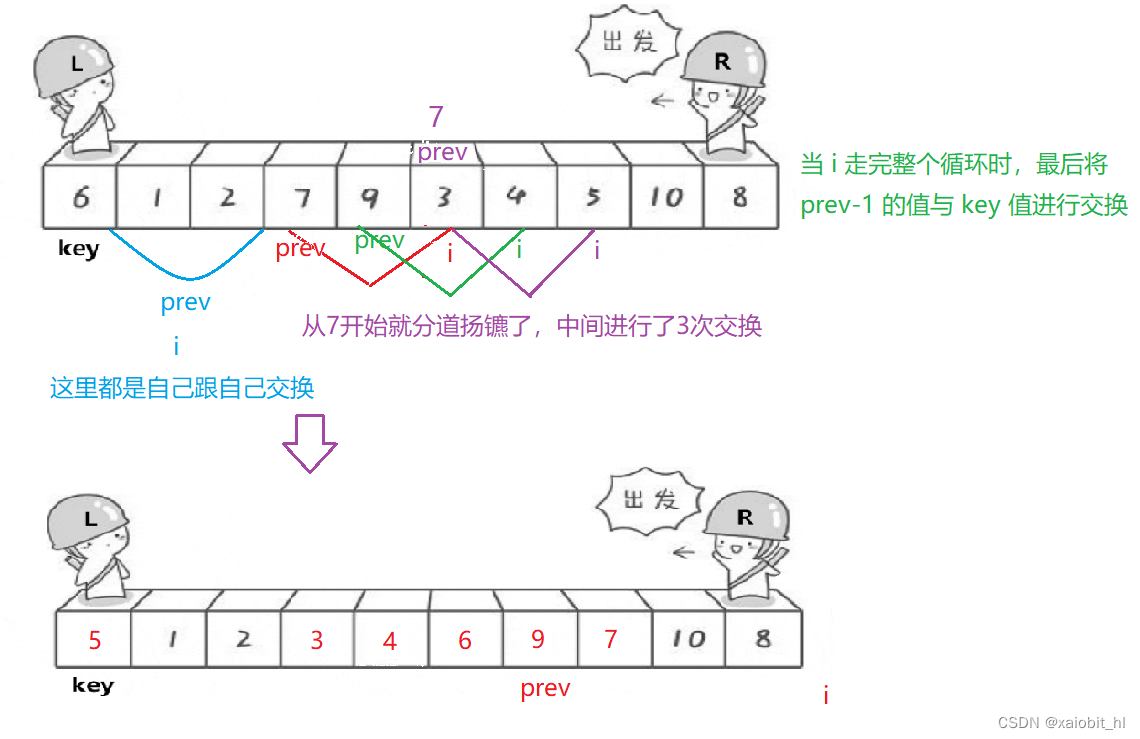
时间复杂度
O(n*log2^n)
6.4.快排的优化(三种优化)
为什么要对快排进行优化???

三数取中法(优化一)(对排序本身分割数据的一种优化)
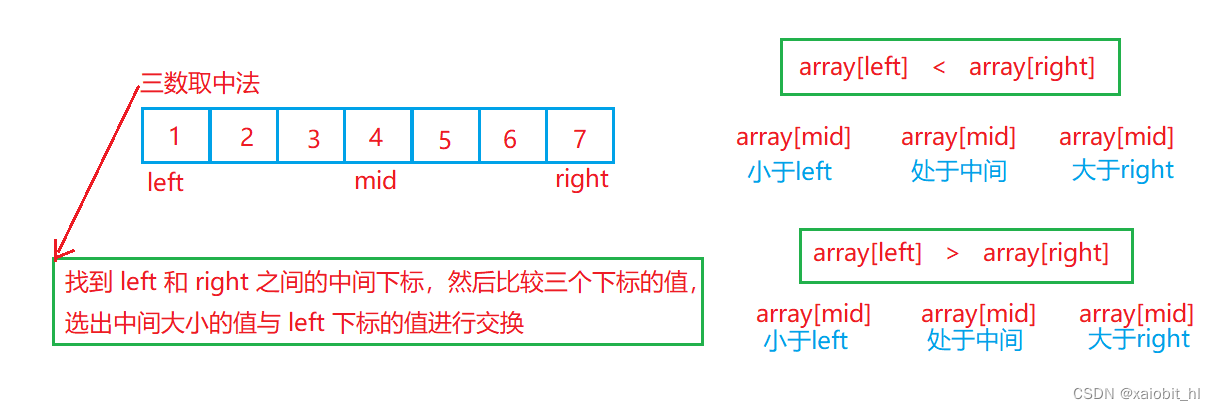
代码实现
private int medianOfThreeIndex(int[] array, int left, int right) {
int mid = left + (right - left) >>> 1;
if(array[left] < array[right]) {
if(array[mid] < array[left]) {
return left;
} else if(array[mid] > array[right]) {
return right;
} else {
return mid;
}
} else {
if(array[mid] > array[left]) {
return left;
} else if(array[mid] < array[right]) {
return right;
} else {
return mid;
}
}
}
public void quick(int[] array, int left, int right) {
if(left >= right) return;
//在找基准之前先调整数据是数据尽量对半分
int index = medianOfThreeIndex(array, left, right);
swap(array, left, index);
int pivot = partitionHole(array, left, right);
quick(array, left, pivot - 1);
quick(array, pivot + 1, right);
}区间内的比较的优化(优化二)
private void insertSortRange(int[] array, int left, int right) {
for (int i = left + 1; i <= right; i++) {
int tmp = array[i];
int j = i - 1;
for (; j >= 0; j--) {
if(tmp < array[j]) {
array[j + 1] = array[j];
} else {
break;
}
}
array[j + 1] = tmp;
}
}
public void quick(int[] array, int left, int right) {
if(left >= right) return;
//对区间内的比较的优化
if(right - left + 1 <= 200) {
insertSortRange(array, left, right);
return;
}
int index = medianOfThreeIndex(array, left, right);
swap(array, left, index);
int pivot = partitionHole(array, left, right);
quick(array, left, pivot - 1);
quick(array, pivot + 1, right);
}聚焦与基准相等元素(优化三)
public static int[] focusSameNum(int[] array,int left,int right,int pivot,int low,int high){
int pLeft = pivot-1;//左子序列的右端点
int pRight = pivot+1;//右子序列的左端点
//聚焦左边
for(int i = left;i < pivot - 1;i++){
if(array[pivot] == array[i]){
//交换之前判断一下 pLeft 位置的值是否等于基准的值
if(array[pLeft] != array[pivot]) {
//不等就交换
swap(array, pLeft, i);
pLeft--;
} else {
//相等就与前一个交换,继续判断
pLeft--;
}
}
}
low = pLeft;//聚焦后下一次待分割的左子序列的右端点
//聚焦右边
for(int i = right;i > pivot + 1;i--){
if(array[pivot] == array[i]){
//交换之前判断一下 pRight 位置的值是否等于基准的值
if(array[pRight] != array[pivot]) {
//不等就交换
swap(array, pRight, i);
pRight++;
} else {
//相等就与后一个交换,继续判断
pRight++;
}
}
}
high = pRight;//聚焦后下一次待分割的左子序列的右端点
//将这两个端点用数组带回,为下一次分割做准备
int[] b = new int[2];
b[0] = left;
b[1] = right;
return b;
}画图分析优化三:
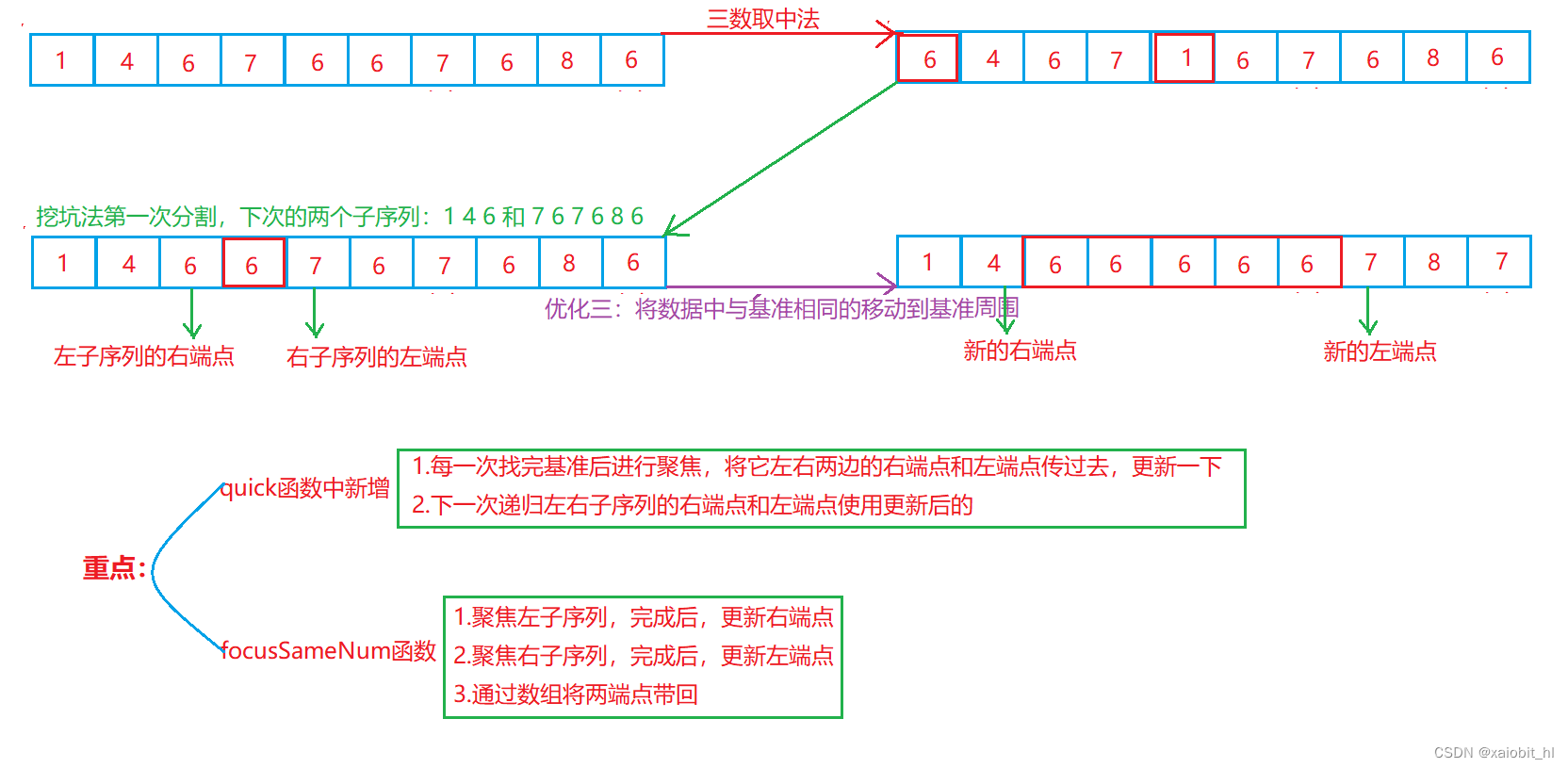
总结:优化一才是真正意义上的优化,真正解决了递归深度太深导致栈溢出的问题,优化二只是对区间内的比较的一种优化,而优化三可以缩小递归的区间,也可以有效的提高效率,相比优化二来说,优化一和优化三提高效率更明显。
6.5.非递归实现快速排序
基本思想
非递归我们需要借用栈,并且要借助在第一次划分的基础上实现,第一次划分后,将两段数据的左和右入栈,然后开始循环控制出栈入栈,弹出两元素,继续重复第一次的操作,直到栈为空。
代码实现
public void quickSortNor(int[] array) {
Stack<Integer> stack = new Stack<>();
int left = 0;
int right = array.length - 1;
//第一次划分
int pivot = partitionHole(array, left, right);
//把两段数据的左和右入栈
if(pivot > left + 1) {
stack.push(left);
stack.push(pivot - 1);
}
if(pivot < right - 1) {
stack.push(pivot + 1);
stack.push(right);
}
//弹出两元素,重复第一次的操作
while(!stack.empty()) {
right = stack.pop();
left = stack.pop();
pivot = partitionHole(array, left, right);
if(pivot > left + 1) {
stack.push(left);
stack.push(pivot - 1);
}
if(pivot < right - 1) {
stack.push(pivot + 1);
stack.push(right);
}
}
}画图分析
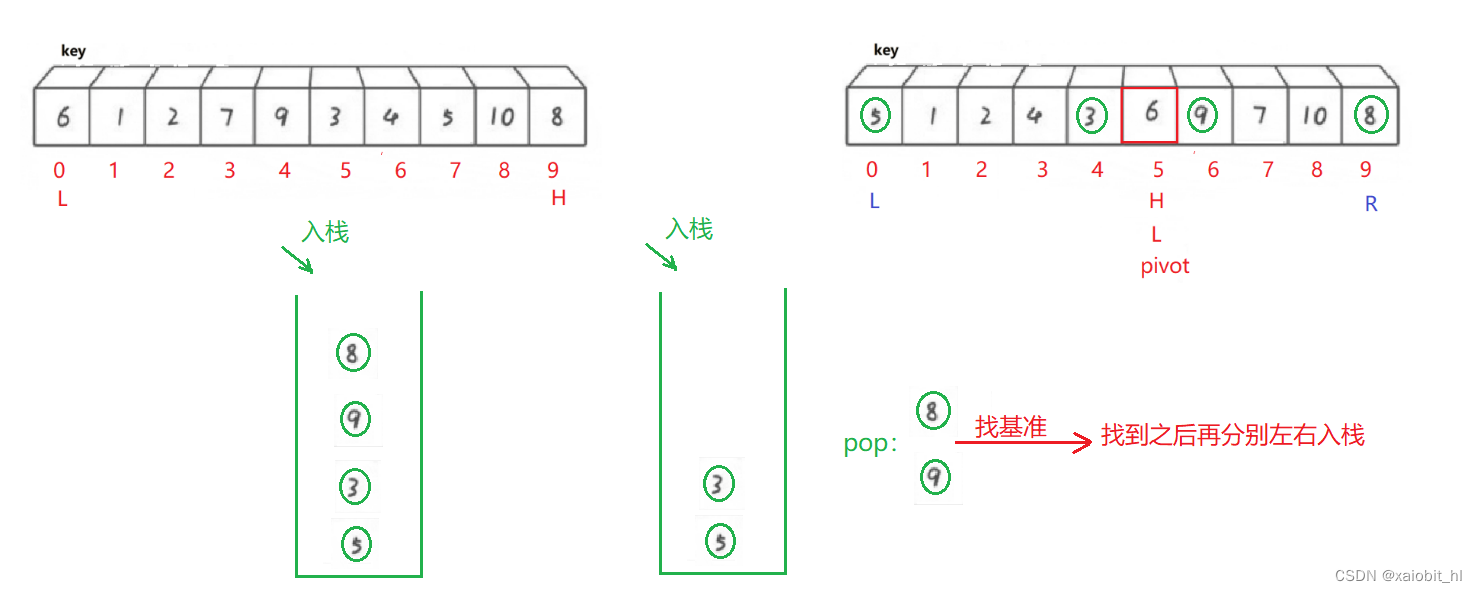
时间复杂度
O(n log2^n)
?7.归并排序
基本思想
归并排序是一种分治思想的排序,简单来说,就是先把一堆数据分成一个一个有序,然后将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
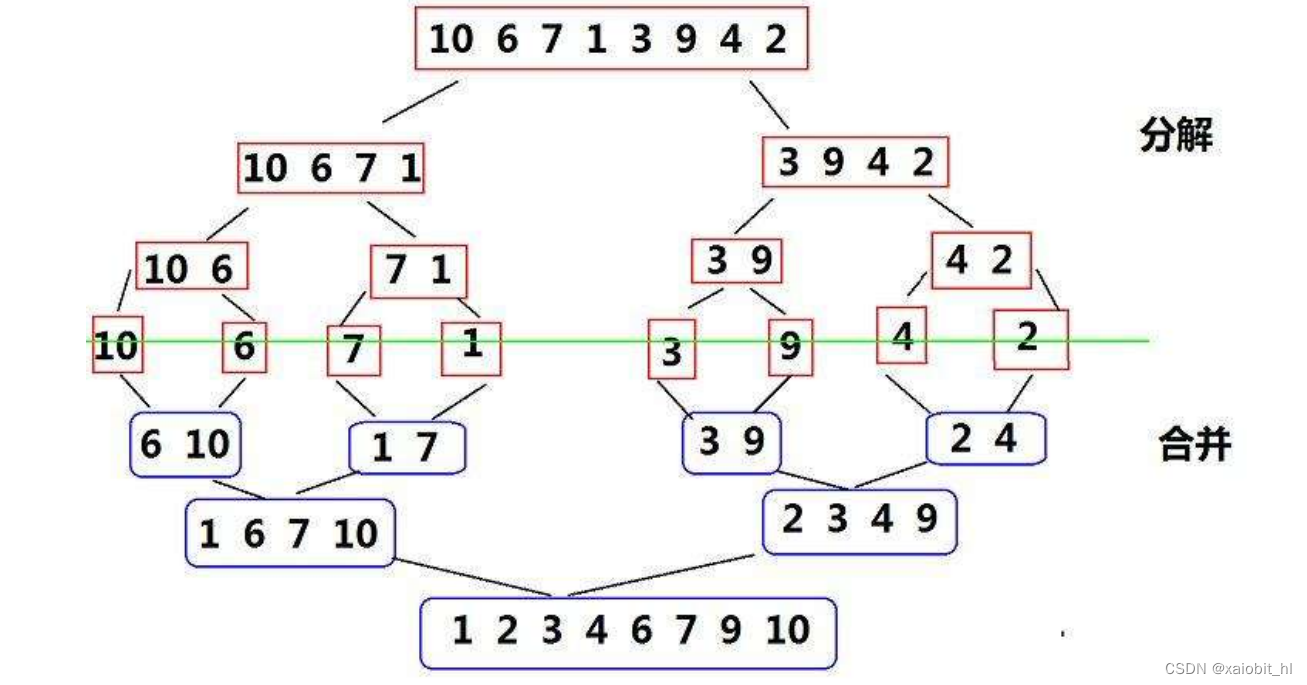
?代码实现(递归版本)
private void merge(int[] array, int left, int mid, int right) {
int s1 = left;
int s2 = mid + 1;
int[] tmpArr = new int[right - left + 1];
int k = 0;
//两段数据都不为空
while(s1 <= mid && s2 <= right) {
// <= 说明归并排序是稳定的
if(array[s1] <= array[s2]) {
tmpArr[k++] = array[s1++];
} else {
tmpArr[k++] = array[s2++];
}
}
//将剩余子序列中的元素挪到新数组中
while(s1 <= mid) {
tmpArr[k++] = array[s1++];
}
while(s2 <= right) {
tmpArr[k++] = array[s2++];
}
//拷贝到原数组中
for (int i = 0; i < tmpArr.length; i++) {
//i + left 是防止拷贝第二段子序列时,覆盖第一段,且达不到想到的效果
array[i + left] = tmpArr[i];
}
}
private void mergeSortInternal(int[] array, int left, int right) {
if(left >= right) return;
int mid = left + ((right - left)>>>1);
mergeSortInternal(array, left, mid);
mergeSortInternal(array, mid + 1, right);
//边分解边合并
merge(array, left, mid, right);
}
public void mergeSort(int[] array) {
mergeSortInternal(array, 0, array.length - 1);
}画图分析
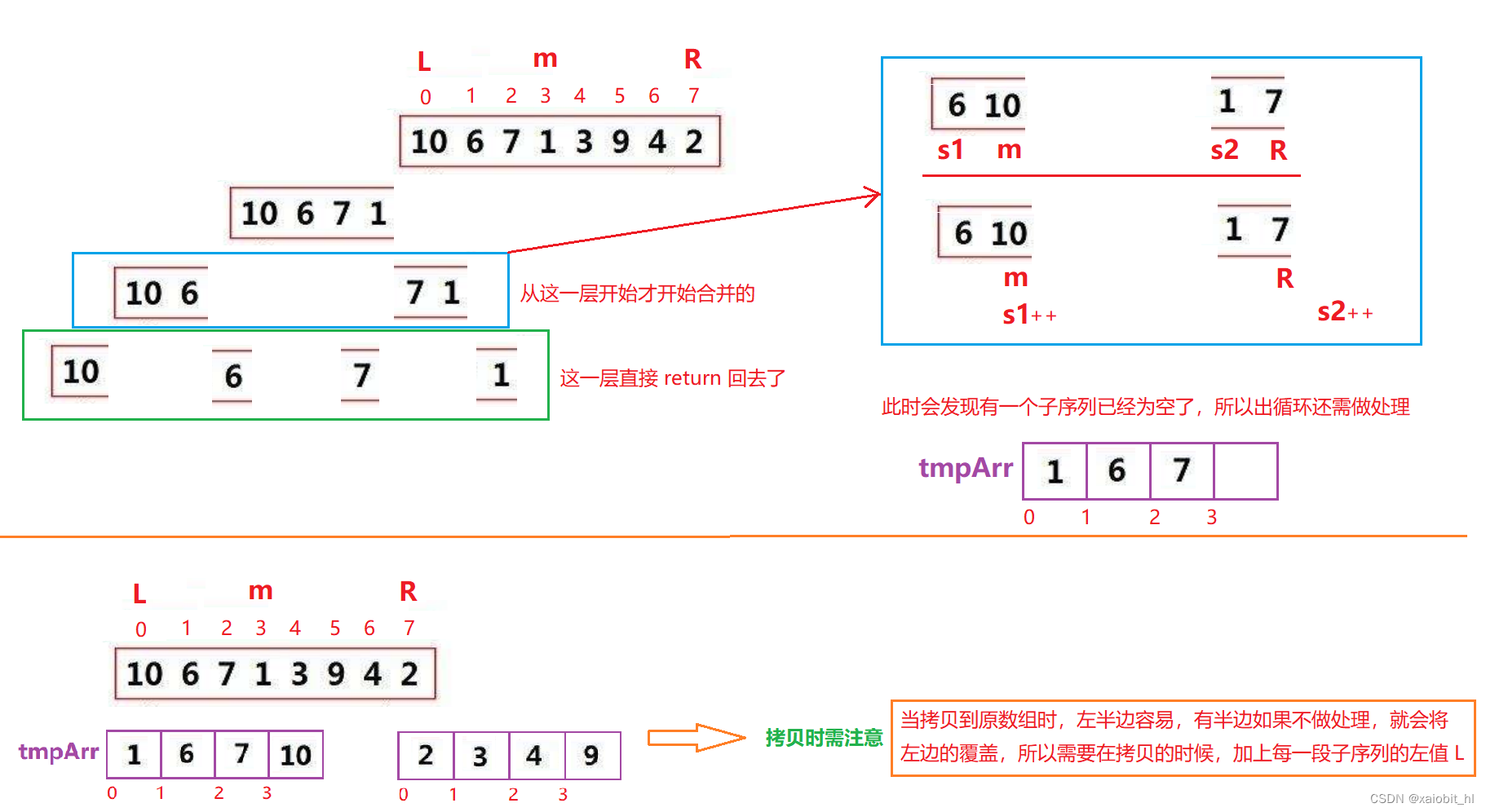
时间复杂度:O(n log2^n )? 和数据有序无序没有关系,因为每一层都是对半分,所以递归的高度就是完全二叉树的高度,且每一层的归并都是 n。
空间复杂度:O(n)? 从最后一次归并能知道,临时数组的大小就等于原始数组的大小。
稳定性:稳定(两组数据在归并的时候,1<=2就把1放入数组,所以是稳定的)
7.1.非递归实现归并排序
基本思想
我们用两层循环来代替递归,外层循环控制层数的变化,内层循环控制每一层的合并。
代码实现
public void mergeSortNor(int[] array) {
int gap = 1;
//控制层数
while(gap < array.length) {
//控制一层
for (int i = 0; i < array.length; i += 2 * gap) {
int left = i;
int mid = left + gap - 1;
//能进循环,left一定不会越界,而 mid 和 right 可能会越界
if(mid >= array.length) {
//修正 mid
mid = array.length - 1;
}
int right = mid + gap;
if(right >= array.length) {
//修正 right
right = array.length - 1;
}
//合并--核心代码
merge(array, left, mid, right);
}
gap *= 2;
}
}时间复杂度
O(n log2^n)
7.2.归并排序的应用场景
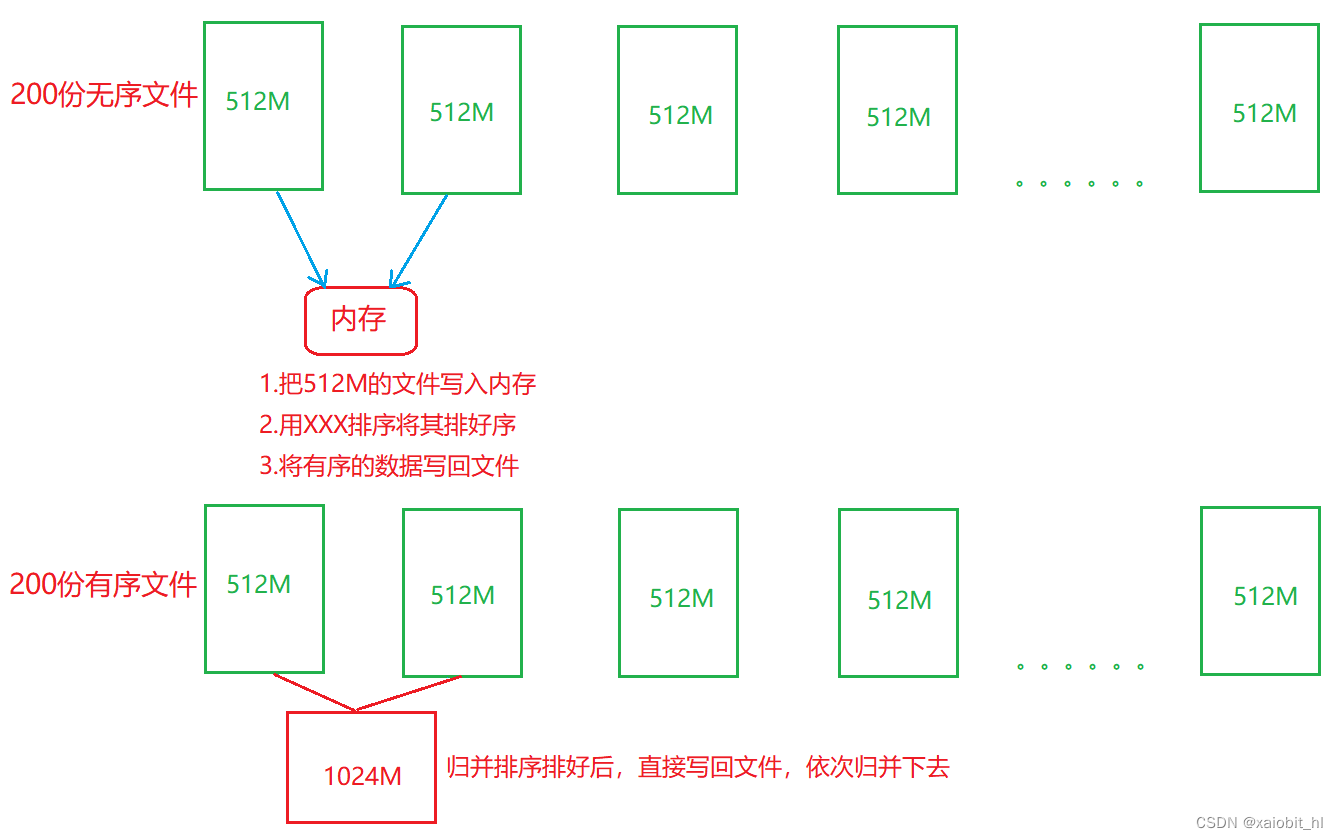
海量数据的排序问题:我们有100G的数据待排序,内存只有一个G,我们应该怎么办???
1. 先把文件切分成 200 份,每份?512 M2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以3. 进行 2路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
?8.计数排序
基本思想
1. 统计相同元素出现次数;2. 根据统计的结果将序列回收到原来的序列中。
public void countSort(int[] array) {
//1.找到数据中的最大值和最小值
int maxVal = array[0];
int minVal = array[0];
for (int i = 1; i < array.length; i++) {
if(array[i] < minVal) {
minVal = array[i];
}
if(array[i] > maxVal) {
maxVal = array[i];
}
}
int range = maxVal - minVal + 1;
int[] count = new int[range];
//2.计数,count数组中是次数,下标是数据
for (int i = 0; i < array.length; i++) {
count[array[i] - minVal]++;
}
//3.回收到原数组
int index = 0;
for (int j = 0; j < count.length; j++) {
//单个数据出现几次就回收几次
while(count[j] > 0) {
array[index++] = j + minVal;
count[j]--;
}
}
}画图分析?

?时间复杂度
O(数据范围+N) --- 跟给定的数据范围有关系
解释:回收的过程中两个循环不是相乘的关系,而是相加的关系,因为不可能每一个数据都出现了 N 次,比如极端情况下,一个数,它出现了N次,那么第一个循环就可以没有,所以是相加的关系。
空间复杂度
O(数据范围)
9.八大排序之间的性能评估
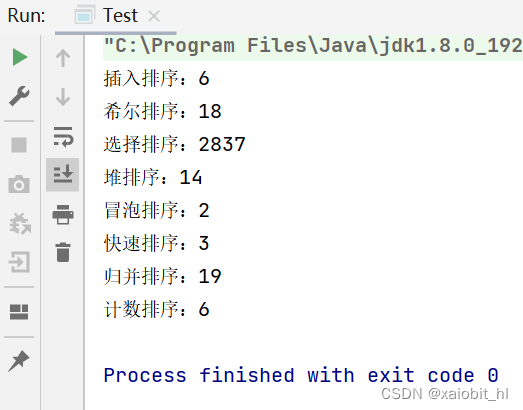
9.1.对十万个有序数据进行排序
public class Test {
public static void testInsertSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.insertSort(array);
long endTime = System.currentTimeMillis();
System.out.println("插入排序:"+ (endTime-startTime));
}
public static void testShellSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.shellSort(array);
long endTime = System.currentTimeMillis();
System.out.println("希尔排序:"+ (endTime-startTime));
}
public static void testSelectSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.selectSort(array);
long endTime = System.currentTimeMillis();
System.out.println("选择排序:"+ (endTime-startTime));
}
public static void testHeapSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.heapSort(array);
long endTime = System.currentTimeMillis();
System.out.println("堆排序:"+ (endTime-startTime));
}
public static void testBubbleSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.bubbleSort2(array);
long endTime = System.currentTimeMillis();
System.out.println("冒泡排序:"+ (endTime-startTime));
}
public static void testQuickSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.quickSort(array);
//TestSort.quickSortNor(array);
long endTime = System.currentTimeMillis();
System.out.println("快速排序:"+ (endTime-startTime));
}
public static void testMergeSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.mergeSort(array);
long endTime = System.currentTimeMillis();
System.out.println("归并排序:"+ (endTime-startTime));
}
public static void testCountSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
TestSort.countSort(array);
long endTime = System.currentTimeMillis();
System.out.println("计数排序:"+ (endTime-startTime));
}
public static void main(String[] args) {
int[] array = new int[10_0000];
Random random = new Random();
for (int i = 0; i < array.length; i++) {
array[i] = i;
//array[i] = random.nextInt(10_0000);//-Xss2m
}
testInsertSort(array);
testShellSort(array);
testSelectSort(array);
testHeapSort(array);
testBubbleSort(array);
testQuickSort(array);
testMergeSort(array);
testCountSort(array);
}
}运行结果
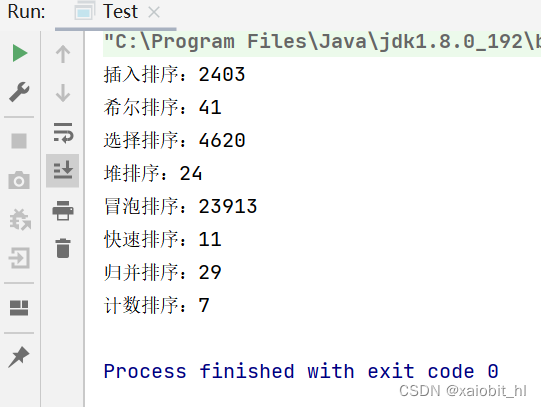
9.2.对十万个随机数进行排序
还是上面那个代码,把 for 循环的第一行注释,第二行打开,运行结果如下:
9.3.八大排序的时空复杂度
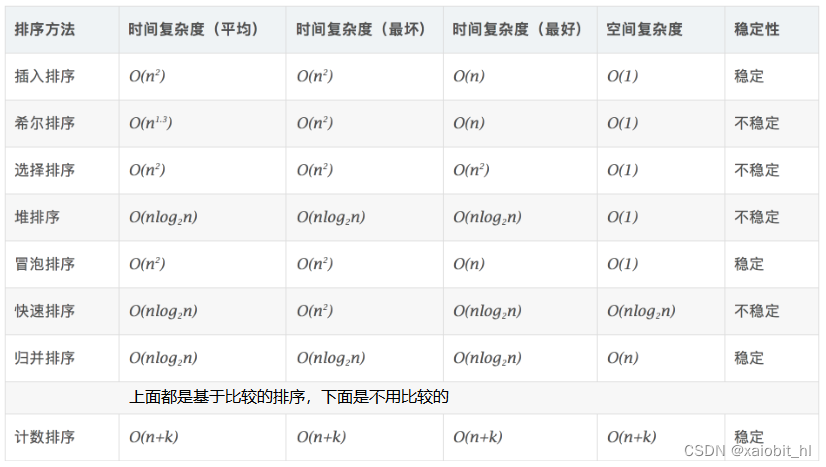
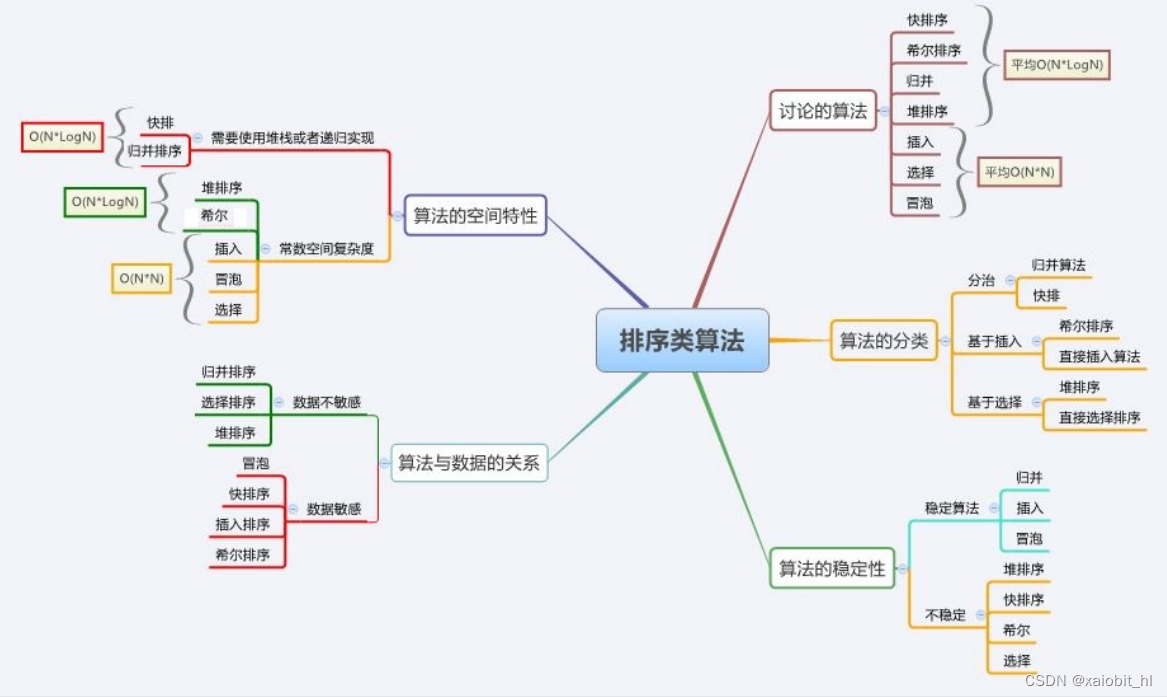
9.4.八大排序的总结
本篇文章就写到这里了,希望能帮助到大家,喜欢的话就点个赞呗~~?