ǰ��
��������Сʱ,ΪOI����(���Ա����ò��ֵַ�)��һ��������Ŀ
A.��������
����ʱ��:2.0 sec
�ڴ�����:512MB
����
�������ɸ�int��������,����������λ���ɴ�С����,���λ����ͬ,��������������С������������,
����:10 -3 1 23 89 100 9 -123
���:-123 100 10 23 89 -3 1 9
������������������� 1 0 6 10^6 106����
�����ʽ
��һ�����������ɸ�����,����֮����һ���ո�ָ���
�����ʽ
��һ�����������õ�����,����֮����һ���ո�ָ���
����
input
10 -3 1 23 89 100 9 -123
ouput
-123 100 10 23 89 -3 1 9
input
1 -2 12
ouput
12 -2 1
˼·
? 1.����һ�ྭ���������������,���������������С���Ρ�������Ŀ˵�������鳤�� n = 1 0 6 n = 10^6 n=106�����ԾͲ�Ҫ�Լ�дð������ȱȽ����������ˡ���C++��ֱ��ʹ��STL�е�����������:sort()��
? 2.�����������д����,Ҳ��������ô������Ϊһ�����DZ�����ʱ���˷�ʱ��,��һ������STL�е�sort���˺ܶ��Ż�,��������д�Ŀ��Ż�����졣
ʹ�÷���
// 1.��Ҫ��ͷ�ļ�
#include <algorithm>
// ����������ô��ӵ�ͷ�ļ�,����Զ��������<����ͷ�ļ�>,������������,���ٸ��ֱ���,�����ǹ��õġ�
#include <bits/stdc++.h>
// 2.sort��ʹ�÷���
sort (��ʼ��ַ,������ַ����һλ,�Զ����������ĺ�����)
// ��ʼ/������ַ:�����Ӧ��ָ��,һ��Ҫע���ǽ����ĵ�ַ����һλ!
// �Զ���������:����sort��������αȽ�������,˭����ǰ��,˭���ں��档������ʱĬ������������
// 3.���尸��1:����һ����������a,����ϣ�������±�Ϊ[l,r]������<����>����
sort(a + l , a + r + 1)
�ص������,���Ĺؼ���ʵ���ǹ����Զ�����������������չ����һ����һ�㡣
//���尸��2:����һ����������a,����ϣ�������±�Ϊ[l,r]������<����>����
//��ʱ���ǿ����Լ�����һ���Զ�������ĺ���cmp(��������������),Ȼ�������������������(�������Ͻ�����������,�����Ǵ��ݺ���ָ��)
sort(a + l , a + r + 1 , cmp);
// ����ֵΪbool��,������������a , b
// ��������������Ǹ���sort��������αȽ���������������true��ʱ��a����b֮ǰ,����false��ʱ��b����a֮ǰ
bool cmp (const int& a , const int& b){
//if (a > b) return true;
//else return false;
//���������,ֱ�ӷ���������ʽ
return a > b;
}
// �������:1.�������ñ�����Ϊ�˼ӿ��ٶ�,���ٿ���ʱ�䡣2.ʹ��const������Ϊ�˷�ֹ����������ݡ�
//�����㲻��������,ֱ��дint a , int b Ҳ����������,ֻ�Dz��淶���ˡ�
��������Ĺؼ����ǹ����Զ���������cmp����������:
#include <bits/stdc++.h>
using namespace std;
struct Val{
int dig; // �����
int val; // ����
};
Val a[1000006];
// ��������
int getDig (int val){
val = abs(val);
int ans = 0;
while (val){
ans ++;
val /= 10;
}
return ans;
}
int cmp (const Val & a , const Val& b){
if (a.dig != b.dig)
return a.dig > b.dig;
return a.val < b.val;
}
int main() {
int x , n = 0;
while (cin >> x) {
a[++n].val = x;
a[n].dig = getDig(a[n].val);
}
sort(a + 1 , a + n + 1 , cmp);
for (int i = 1 ; i <= n ; i++){
cout << a[i].val;
if (i == n) cout << endl;
else cout << " ";
}
return 0;
}
�ܽ�
����
���ǻ��Ե�һ��,�ѶȱȽ�С�����ƽʱ����ˢ��Ӧ����������ġ�
�ؼ�
��������
B.���
����ʱ��:2.0 sec
�ڴ�����:512MB
����
����һ��int������ x x x,�� x x x�Ķ����Ʊ�ʾ�е�iλ�͵�jλ��ֵ������ 0 �� i , j �� 31 0 \leq i,j \leq 31 0��i,j��31
ע��: x x x�Ķ����Ʊ�ʾ�����ұ�Ϊ��0λ��
�����ʽ
��һ����������������, x , i , j x,i,j x,i,j, ����֮����һ���ո�ָ���
�����ʽ
��һ�������������Ľ��
����
input
38 2 4
ouput
50
input
1 0 2
ouput
4
˼·
˼·����Ȼ:��ȡ x x x�����Ʊ�ʾ�еĵ� i i iλ��� j j jλ��֮�����ǻ������ɡ�
��������:ʵ�ַ����ܶ�
1.����ת���ɶ���������a,Ȼ��ģ��swap(a[i] , a[j])����ת����ʮ������
2.����λ����ļ���ȥ��
��һ��:��ö����Ƶ� i , j i,j i,jλ���ϵ�ֵ��
�����:���� x x x���� i / j i/j i/jλȻ��������1��
a = ( x > > i ) & 1 a=(x >> i)\&1 a=(x>>i)&1
b = ( x > > j ) & 1 b=(x >> j)\&1 b=(x>>j)&1
�ڶ���:����,�����, x i = b x_i=b xi?=b, x j = a x_j=a xj?=a
ֻ�е� a �� b a \neq b a��?=b ʱ����Ҫ�������������Ľ������ȡ�����ɡ���ȡ�����ǿ�������<���1>����ɡ�
if (a != b){
x ^= (1 << i);
x ^= (1 << j);
}
ʵ��
#include <bits/stdc++.h>
using namespace std;
int main() {
int x , i , j;
cin >> x >> i >> j;
int a = (x >> i) & 1;
int b = (x >> j) & 1;
// �����ı�ʾ����,��������ʡȥ�ж�
x ^= ((a ^ b) << i);
x ^= ((a ^ b) << j);
cout << x << endl;
return 0;
}
�ܽ�
??����:λ����ļ���,Ӧ��Ҫ�����֡�
C.��ּ���
����ʱ��:0.5 sec
�ڴ�����:512MB
����
���� n n n������ a 1 , . . . , a n a_1,...,a_n a1?,...,an?��һ������ x x x�����ж�������� ( i , j (i,j (i,j)���� a i ? a j = x a_i-a_j= x ai??aj?=x��
�����ʽ
��һ���������� n ( 1 �� n �� 2 �� 1 0 6 ) , x ( ? 2 �� 1 0 6 �� x �� 2 �� 1 0 6 ) n(1 \leq n \leq 2 \times 10^6),x(-2 \times 10^6 \leq x \leq 2 \times 10^6) n(1��n��2��106),x(?2��106��x��2��106),�ֱ���������ĸ�������Ŀ�е� x x x��
�ڶ��� n n n���ÿո����������,�� i i i������ ? 2 �� 1 0 6 �� a i �� 2 �� 1 0 6 -2 \times 10^6 \leq a_i \leq 2 \times 10^6 ?2��106��ai?��2��106
�����ʽ
һ��һ������,�������� a i ? a j = x a_i-a_j=x ai??aj?=x������� ( i , j ) (i,j) (i,j)������
����
input
5 1
1 1 5 4 2
ouput
3
����˵��
( 1 ( 1 ) , 2 ( 5 ) ) , ( 1 ( 2 ) , 2 ( 5 ) ) , ( 5 ( 3 ) , 4 ( 4 ) ) (1(1),2(5)),(1(2),2(5)),(5(3),4(4)) (1(1),2(5)),(1(2),2(5)),(5(3),4(4)) ����������ԡ�
˼·
1.��Ȼ�����ⷨ
??˫��ѭ��ö�� i , j i,j i,j ����������,���Ӷ��� O ( n 2 ) O(n^2) O(n2)���������õ����֡� ������һ��һ���� 1 e 8 1e8 1e8 �Ρ��� n n n ����ȥ���� ( 2 ? 1 0 6 ) 2 = 4 ? 1 0 12 Զ �� �� 1 e 8 (2 * 10^6)^2=4 * 10^{12} Զ���� 1e8 (2?106)2=4?1012Զ����1e8
2.ǰ������(��ȷ�㷨�ı����汾)
??����ö��ÿһ��
a
j
a_j
aj?(����Եĺ����Ǹ���), �۲���Ŀ������ʽ
a
i
?
a
j
=
x
a_i-a_j=x
ai??aj?=x
??��ʱ
a
j
a_j
aj?�Ѿ����̶�,������
x
x
xһ����һ������,����������һ��,���Եõ�
a
i
=
x
+
a
j
a_i=x+a_j
ai?=x+aj?
??��ʱҲ������
i
��
[
1
,
j
?
1
]
i \in [1,j-1]
i��[1,j?1] �ڵ������ж��ٸ���Ϊ
x
+
a
j
x+a_j
x+aj?��
??���ѷ���,����
j
j
jȡʲôֵ,��������������һ��ǰ,���ǿ��Խ�ǰ:
i
��
[
1
,
j
?
1
]
i \in [1,j-1]
i��[1,j?1]������
a
i
a_i
ai? ���뵽һ����ϣ��
H
H
H ����,Ȼ��ֱ�Ӳ�ѯ
H
[
x
+
a
j
]
H[x+a_j]
H[x+aj?] ���ɡ���������������ʾ,��������Ŀ����Ϊ���ӷ���:
1
?
1
?
5
?
4
?
2
1\ 1\ 5\ 4\ 2
1?1?5?4?2
| λ�� j j j | a j a_j aj? | ǰ | x + a j x+a_j x+aj? | �𰸹��� |
|---|---|---|---|---|
| 1 | 1 1 1 | ? \empty ? | 2 2 2 | 0 0 0 |
| 2 | 1 1 1 | { 1 } \{1\} {1} | 2 2 2 | 0 0 0 |
| 3 | 5 5 5 | { 1 , 1 } \{1,1\} {1,1} | 6 6 6 | 0 0 0 |
| 4 | 4 4 4 | { 1 , 1 , 5 } \{1,1,5\} {1,1,5} | 5 5 5 | 1 1 1 |
| 5 | 2 2 2 | { 1 , 1 , 5 , 4 } \{1,1,5,4\} {1,1,5,4} | 2 2 2 | 2 2 2 |
| �ܴ� | 1 + 2 = 3 1+2=3 1+2=3 |
3.ά��ǰ��
??��ʵ���ǽ�����������ܹ����Ͽ�������,��ʶ��һ������:ǰ�ı仯��������,Ҳ����˵:�� k k k��ǰ��� k ? 1 k-1 k?1��ǰ���ֻ�Ƕ���һ�� a k a_k ak?.����������ȫ��û��Ҫÿ�ζ��ѹ�ϣ�����Ȼ�����¹���ǰ�Ĺ�ϣ��,��ֻ����Ҫÿ������ϣ��������µ�ֵ���ɡ���ô������ʵ�ͺ���Ȼ��~
??��Ȼ�������ĸ��ӶȾ��� O ( n ) O(n) O(n)��
ʵ��
? ע��,��ʵ�ֵĹ����л�����Ҫע��ܶ�ϸ�����⡣
#include <bits/stdc++.h>
using namespace std;
const int maxn = 2e6 + 5;
int a[maxn];
int b[maxn * 2]; // ע��:b���±������ֵ��Χ,�������鳤��,������Ҫ������
// �±�任
int idTrans (int x){
// ��ʱ�±��[-2e6,2e6]ӳ�䵽[0,4e6]
return x + 2e6;
}
int main() {
int n , x;
cin >> n >> x;
for (int i = 1 ; i <= n ; i++)
cin >> a[i];
// �𰸿��ܴܺ�:����aiȫ����x=0,��ô��������i,j����һ���𰸡���ô�𰸻���n^2�ġ�
// ���Խ������ȥ�ᷢ������int��,����ֻ����long long �洢
long long ans = 0;
// hash��������STL�е�unordered_map,�������Ƿ����±���ʵû��ô��
// ����Ϊ�˸���������ٶ����ǿ��Կ�һ��Ͱ����b��
// ����ֵ���漰������,������Ҫ��һ���±��ӳ��.
for (int j = 2 ; j <= n ; j++){
ans += b[idTrans(a[j] + x)];
b[idTrans(a[j])]++;
}
cout << ans << endl;
return 0;
}
�ܽ�
����
??������ʽ�漰���㷨˼��,����Ϊ���������Ѷȡ�
�ؼ�
??�������Ż��ؼ�����ǰ�������仯�ԡ��������ù�ϣ��
��չ
??1.����Ŀ�е� a i ? a j = x a_i-a_j= x ai??aj?=x �ij� a i ? a j = i ? j a_i-a_j= i-j ai??aj?=i?j
??2.�������ж��ٸ��Ӷεĺ�ǡ��Ϊ
x
x
x,������������(
i
,
j
i,j
i,j)����
��
k
=
i
j
a
k
=
x
\sum_{k=i}^{j}a_k=x
k=i��j?ak?=x
??3.�������ж��ٸ��Ӷεĺ�Ϊ
x
x
x�ı���,�����ж��������
(
i
,
j
(i,j
(i,j)����
��
k
=
i
j
a
k
��
0
?
(
m
o
d
?
x
)
\sum_{k=i}^{j} a_k \equiv 0 \ (mod\ x)
k=i��j?ak?��0?(mod?x)
??4.�������ж��ٸ��Ӷε�ƽ��ֵǡ��Ϊ
x
x
x,������������
(
i
,
j
(i,j
(i,j)����
��
k
=
i
j
a
k
j
?
i
+
1
=
x
\frac{\sum_{k=i}^{j} a_k}{j-i+1}=x
j?i+1��k=ij?ak??=x
D.��������
����ʱ��:2 sec
�ڴ�����:512MB
����
���������ǹ�����ʹ�õļ���ϵͳ,�ֽ��Ժܳ�����
�����������߸���������: I,V,X,L,C,D,M��
| �������� | I | V | X | L | C | D | M |
|---|---|---|---|---|---|---|---|
| ��Ӧ�İ��������� | 1 1 1 | 5 5 5 | 10 10 10 | 50 50 50 | 100 100 100 | 500 500 500 | 1000 1000 1000 |
��Ҫע���������������ʮ��λ���ֵ����岻ͬ,��û�б�ʾ�������,���λ���ء����������Ĺ�����Ա�ʾ��������
����
��������ʽ
�ظ�����:һ�����������ظ�����,�ͱ�ʾ������ļ�����
����Ҽ�:
- 1.�ڽϴ���������ֵ��ұ��Ͻ�С����������,��ʾ�����ּ�С���֡�
- 2.�ڽϴ���������ֵ�����Ͻ�С����������,��ʾ�����ּ�С���֡�
- 3.���������������,������I,X,C.���� 45 45 45��ʾXLV,������VL
- 4.���ʱ���ɿ�Խһ��λֵ������, 99 99 99��XCIX$ ([100- 10]+ [10- 1])$,������IC ( [ 100 ? 1 ] ) ([100 - 1]) ([100?1])����ͬ�ڰ���������ÿλ���ֱַ��ʾ��
- 5.������ֱ���Ϊһλ,���� 8 8 8��VIII,������IIX
- 6.��������V,L,D�е��κ�һ�����ڽϴ�����������ұ�ֻ��ʹ��һ����
- 7.�Ҽ�������ͬ���ֲ�������λ,���� 14 14 14��XIV,������XIIII
���ڸ���һ�����������ֱ�ʾ��ʮ����������,������Ӧ���������֡�
�����ʽ
һ��ʮ��������
�����ʽ
һ���ַ���,��ʾ��Ӧ����������
����
input
3
output
III
˼·
??��������Ҫ���ѵ�����������������������ʽ��,�Ȱ� 1 ? 10 1-10 1?10 ����ʾ����!
| ʮ���� | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| �������� | I | II | III | IV | V | VI | VII | VIII | IX | X |
��������7, 1 , 2 , 3 1,2,3 1,2,3 һ���� I,II,III
����4,��������7,������IIII,���Ը�������2�õ�:IV. ����9��ͬ����
??���Ƿ��������Ĺ��ɺ������ƹ㵽10,20,��,100 �� 100 , 200 , 300 , �� , 1000
| ʮ���� | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
|---|---|---|---|---|---|---|---|---|---|---|
| �������� | X | XX | XXX | XL | L | LX | LXX | LXXX | XC | C |
| ʮ���� | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| �������� | C | CC | CCC | CD | D | DC | DCC | DCCC | CM | M |
??���������ű�,���ǾͿ��Ա�ʾ�� [ 1 , 1000 ] [1,1000] [1,1000] �ڵ��κ�һ������ֻ��Ҫ���ʮ����λ���ɡ�
??����: 338 = 300 + 30 + 8 338=300+30+8 338=300+30+8�������� C C C X X X V I I I CCCXXXVIII CCCXXXVIII
ʵ��
1.���
2.���������ʮ���Ʋ��
3.������
����:��
�ܽ�
����
??һ����ģ���⡣
E.�˷�
����ʱ��:1.0 sec
�ڴ�����:256MB
����
����һ������Ϊ n n n�����к�һһ������Ϊ m m m������,���Թ���õ�һ�� n �� m n\times m n��m�ľ���C,���� C i , j = A i �� B j C_{i,j}= A_i \times B_j Ci,j?=Ai?��Bj?��
�������� K K K,����Ҫ��� C C C�еĵ� k k k�������ֵ��
�����ʽ
��һ�������������� n , m , K n, m,K n,m,K( 1 �� n , m �� 1 0 5 , 1 �� K �� n �� m 1 \leq n,m��10^5,1\leq K \leq n \times m 1��n,m��105,1��K��n��m)��
�ڶ������� n n n���ո���������� A 1 , A 2 , . . . , A n ( ? 1 0 6 �� A i �� 1 0 6 ) A_1, A_2,...,A_n(-10^6��A_i��10^6) A1?,A2?,...,An?(?106��Ai?��106)
���������� m m m���ո���������� B 1 , B 2 , . . . , B m ( ? 1 0 6 �� B i �� 1 0 6 ) B_1, B_2,...,B_ m(-10^6��B_i��10^6) B1?,B2?,...,Bm?(?106��Bi?��106)
�����ʽ
���һ��һ ������,��ʾ�����еĵ� K K K�������ֵ��
����
input
3 3 3
2 3 4
4 5 6
output
18
˼·
1.����
?? ����ѭ���õ� C C C�е�����ֵ,֮����������ʵ� K K K�������ɡ� O ( n 2 ) O(n^2) O(n2)����ͨ��ȫ�����ݡ�
2.��չ��
?? ��ΪҪ֪���� k k k�������������Ȼ��ϣ���Ƚ� A , B A,B A,B���齵�������������֪�� A 1 �� B 1 A_1 \times B_1 A1?��B1? һ�������ֵ���������ڴδ�ֵ��˭?
A 1 �� B 2 ? �� ? A 2 �� B 1 A_1 \times B_2\ �� \ A_2 \times B_1 A1?��B2??��?A2?��B1? �����,����
A = [ 6 ? 5 ] A = [6\ 5] A=[6?5]
B = [ 6 ? 1 ] B = [6\ 1] B=[6?1]
����
A = [ 6 ? 1 ] A = [6\ 1] A=[6?1]
B = [ 6 ? 5 ] B = [6\ 5] B=[6?5]
??������������֪�������������������û���������ܵ�λ�����γɴδ�ֵ�ˡ��������ǰ��������������������IJ�����֮Ϊ��չ
���¹��̾���Ϊ A , B A,B A,B�����ѱ���������
??������ˢ�����������֪���������������ά��,ÿ��ɾ�����,Ȼ��������չ�����ش���ѡ��������� k ? 1 k-1 k?1��,�Ѷ����ǵ� k k k�������(�����ϵij���II�ǵ���Ҳ����������)
??�������㷨���о������ǶԵ�,�����߳���˵��һ���㷨����ȷ��
"���"֤��
??������һ������Ȼ�Ľ���:����֪ǰ k ? 1 k-1 k?1��ij˻��������ǵķ����������(��֪�� k ? 1 k-1 k?1����Ԫ�� < A i �� B j , i , j > <A_i \times B_j , i,j> <Ai?��Bj?,i,j>)����ô�� k k k��ij˻�һ�������� k ? 1 k-1 k?1��������ijһ������չ�Ľ����
??������ۺ���Ȼ,��Ϊ����� k k k�����Ϊ A i �� B j A_i \times B_j Ai?��Bj? ,��ô�����Կ�������$A_{i-1} \times B_j $ ��չ����������Ȼ A i ? 1 �� B j > A i �� B j A_{i-1} \times B_j > A_i \times B_j Ai?1?��Bj?>Ai?��Bj?,���� A i ? 1 �� B j A_{i-1} \times B_j Ai?1?��Bj? һ����ǰ k ? 1 k-1 k?1���ijһ����
1.����������˻ᷢ��: i = 1 i=1 i=1������ۻ���ô?
??���ǶԵ�,��ΪҲ���Կ����� A i �� B j ? 1 A_{i}\times B_{j-1} Ai?��Bj?1?��չ ��
2.��һ����:Ҫ�����ʱ�� j = 1 j=1 j=1 ��??
??����������� A 1 �� B 1 A_1 \times B_1 A1?��B1? , �������������,��һ���ǵ� 1 1 1��~
??���Ը���������������������һ���������㷨
??��һ������
S
S
Sά��ǰ
k
?
1
k-1
k?1��ķ�����Ȼ��ͨ����չ�����õ�
2
��
(
k
?
1
)
2 \times (k-1)
2��(k?1) �����ܵĽ��,����ѡһ��������û���ֹ������ֵ,���뵽����
S
S
S�С���������ù��̼���,����ͼ��ʾ
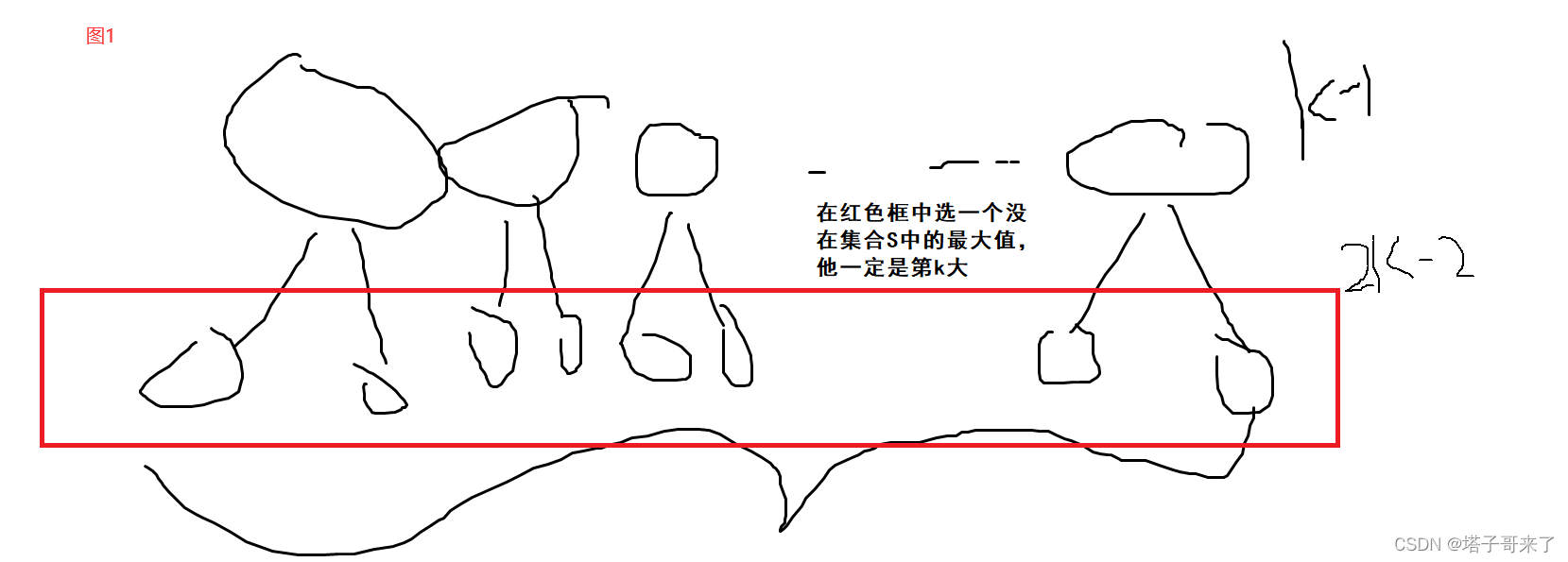
??���������ĸ��Ӷ��� O ( k 2 ) O(k^2) O(k2) �ġ��������ڼ��� S S S�е�ÿ��Ԫ��ֻ�п��ܱ���չ������Ԫ��,����k�Ƕ���ء�
??����:��1����� < A 1 �� B 1 , 1 , 1 > <A_1 \times B_1,1,1> <A1?��B1?,1,1> �����ǻᱻ��չ�� < A 1 �� B 2 , 1 , 2 > �� < A 2 �� B 1 , 2 , 1 > <A_1 \times B_2,1,2>��<A_2 \times B_1,2,1> <A1?��B2?,1,2>��<A2?��B1?,2,1>,�������ڵڼ���
??���Խ�����
S
S
S�е�
<
A
1
��
B
1
,
1
,
1
>
<A_1 \times B_1,1,1>
<A1?��B1?,1,1> �滻��
<
A
1
��
B
2
,
1
,
2
>
��
<
A
2
��
B
1
,
2
,
1
>
<A_1 \times B_2,1,2>��<A_2 \times B_1,2,1>
<A1?��B2?,1,2>��<A2?��B1?,2,1> ��һ���ȼ۲���,���ı��㷨��ȷ�ԡ����Ҷ��ڵ�
i
,
i
��
[
1
,
k
]
i,i \in [1,k]
i,i��[1,k]���Ԫ��������ʶ��������������ǿ��Ը�����Ԫ�ؽ�����չ�滻�����Բ��ѷ���,������ȫ���Բ�ȥά������
S
S
S,����ֱ��ά������չ����
T
T
T,����ͼ��ʾ
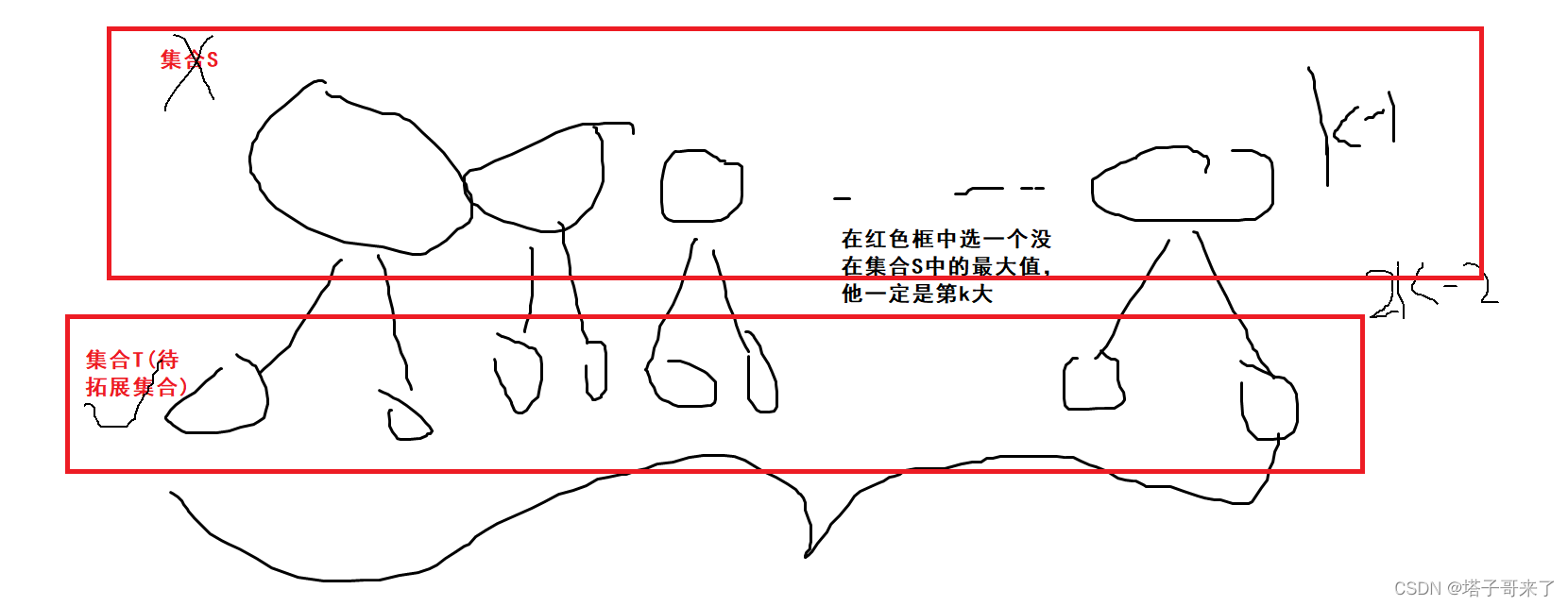
??����,���Ǿ��Ƿ����ĴӼ���
T
T
T���ó����ֵ,ɾ����,Ȼ�����������չ��
k
?
1
k-1
k?1��֮�ϵ����ֵ���ǵ�
k
k
k��Ľ����
??��ǡǡ��Ӧ��������㷨�����Ǵ�ſ�����������㷨�ǶԵ��ˡ���Ϊ���������Ż���ÿһ�����ǵȼ۲���������ֻҪ�����㷨�ǶԵ�,���յ��Ż��㷨���ǶԵġ�
��������в��ֶ��߾���֤����Ҫ�Ͻ�,�����������Ż�,̫����ˡ���������Ϊ֤��һ�������Ͻ�,�Ƕ���С�������ѶȾͳɱ����ӡ����Ի���ֱ�Ľ��ͺ�Щ��
ʵ��
��
�ܽ�
F.Minimum_Sum
����ʱ��:2.0 sec
�ڴ�����:256MB
����
����һ������
a
1
,
a
2
,
.
.
.
,
a
n
a_1,a_2,...,a_n
a1?,a2?,...,an?,Ȼ�����һЩ����
[
l
,
r
]
[l,r]
[l,r].����ÿһ������,����Ҫ�ҵ���ʽ����Сֵ,�������п��ܵ�
x
x
x
��
i
=
l
r
�O
x
?
a
i
�O
\sum_{i=l}^{r}|x-a_i|
i=l��r?�Ox?ai?�O
�����ʽ
��һ��һ������ N N N �������г��ȡ�
������һ���� N N N�������� a i ( 1 �� a i �� 1 0 9 ) a_i(1 \leq a_i \leq 10^9) ai?(1��ai?��109),�ÿո������
������һ��һ������ Q ( 1 �� Q �� 1 0 5 ) Q(1 \leq Q \leq 10^5) Q(1��Q��105),����ѯ�ʵ����������
������ Q Q Q��,ÿ��һ������ l , r ( 1 �� l �� r �� N ) l,r(1 \leq l \leq r \leq N) l,r(1��l��r��N)
�����ʽ
��� Q Q Q�С�ÿ�д�����Ӧ������Ľ����
˼·
��С�������پ���
??1.���ڸ���������
[
l
,
r
]
[l,r]
[l,r]���������ȷ�����
x
x
x��?��
a
r
g
m
i
n
x
?
��
i
=
l
r
�O
x
?
a
i
�O
\Large \underset{x}{argmin}\ \sum_{i=l}^{r}|x-a_i|
xargmin??i=l��r?�Ox?ai?�O
����ʵ���ʾ�����С�������پ����������ȿ��Ƕ����������е����:
���Ľ�����: ������ a a a�����
1.�� n n n������ʱ, x ? = a n / 2 + 1 x^*=a_{n / 2 +1} x?=an/2+1? , Ҳ�������е���λ����
2.�� n n n��ż����ʱ�� x ? �� [ a n / 2 , a n / 2 + 1 ] x^* \in[a_{n / 2},a_{n / 2 + 1}] x?��[an/2?,an/2+1?]
??ֱ�۵�����:��
x
x
x ����λ����λ��ʱ,���������������ƶ����������ƶ�,�����г���
n
/
2
n / 2
n/2 ������Զ��������ô���һ����������ͼ��ʾ
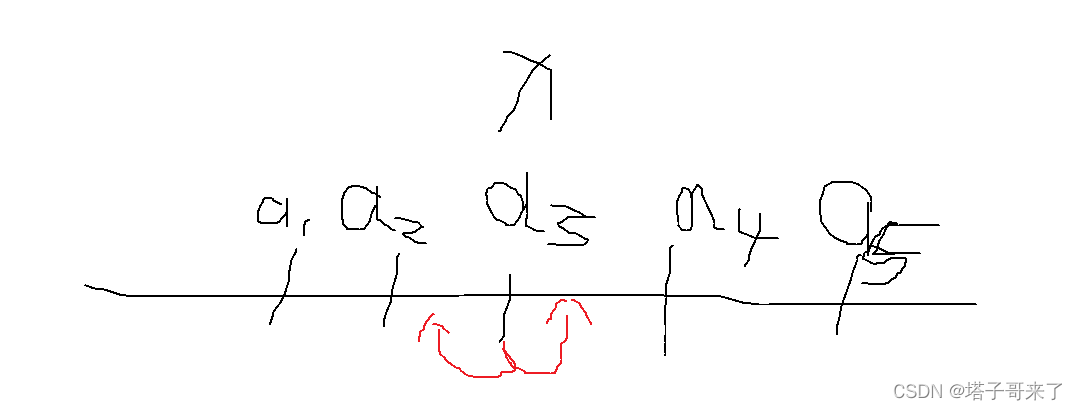
��������ƶ�һ����λ,����3������Զ��,2�����ڿ���
ͬ����,��������ƶ�һ����λ,����3������Զ��,2�����ڿ���.�����м��λ����С��
��Ȼ�ϸ����ѧ֤���ڴ�:����,������߲�չ����
�����ⷨ
??������������һ������������:����ѯ�ʵ�����
[
l
,
r
]
[l,r]
[l,r],����һ�ݳ�����������,Ȼ����ݽ��۵õ���λ�����ټ���ֵ�������������������������֡����Ȿ�ʱ�Ϊ1.���������λ�� 2.����������ijһֵ��ĺͼ�
��
��
��
��
��
��
[
l
,
r
]
��
ֵ
��
Ϊ
[
x
,
y
]
��
��
��
��
������������[l,r]��ֵ��Ϊ[x,y]�����ĺ�
������������[l,r]��ֵ��Ϊ[x,y]��������
�����ݽṹ�Ż�
??����,������һ���ɳ־û�ֵ���߶���(��ϯ��)��ģ���⡣�ڽ����ά��Ҷ�ڵ�����Լ�Ҷ�ڵ��Ȩֵ�ͼ��ɡ�
��Ȼ���DZ��߿ں�������,û��ʵ��ȥʵ�֡�����и��õ�������ӭ������������!
����
??�����ѶȲ���,���Ƿdz������Ļ����⡣��ʱ�����Ϸ��������� [ 200 , 300 ] [200,300] [200,300]֮�䡣