1.������
1.0.���
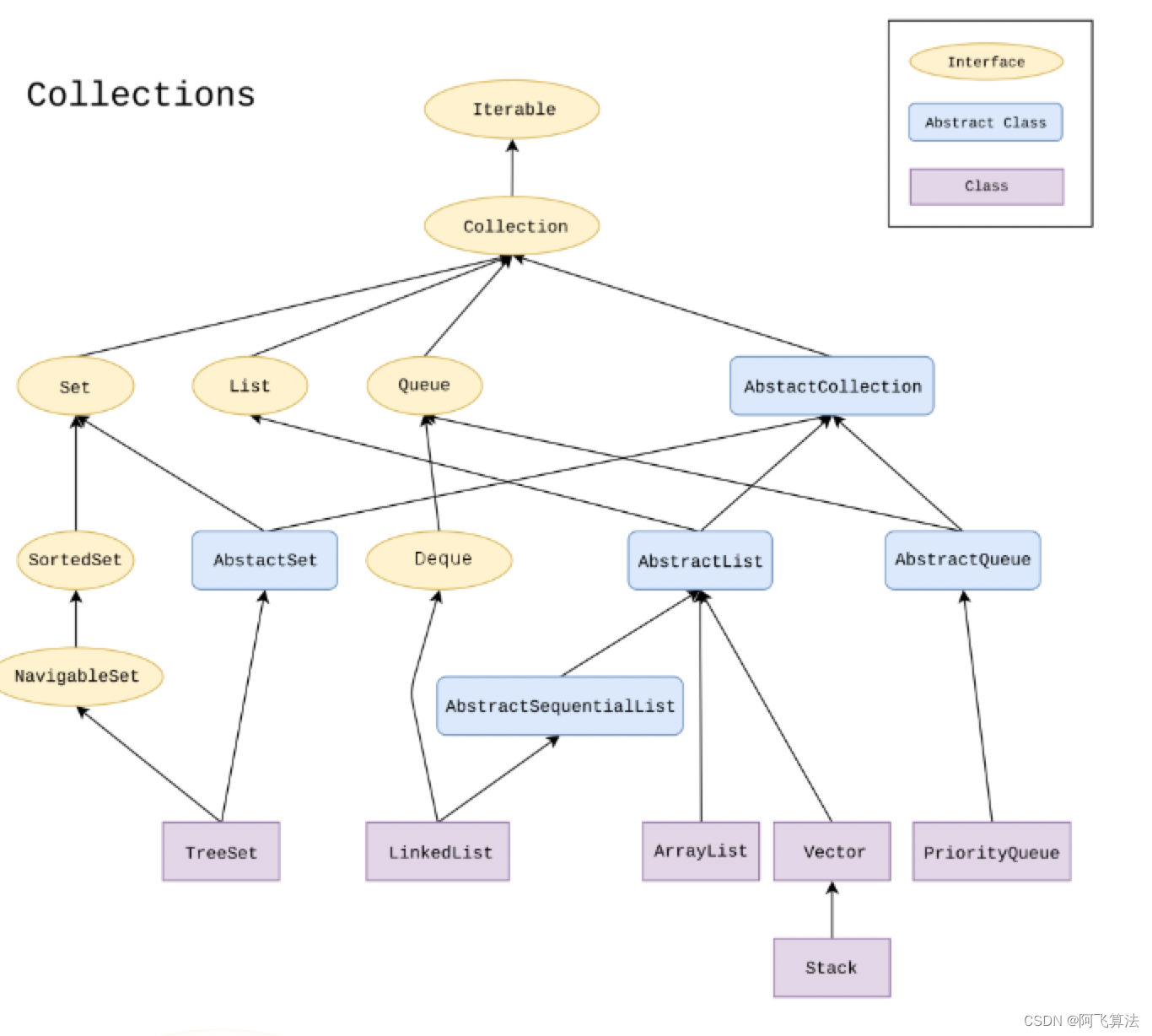
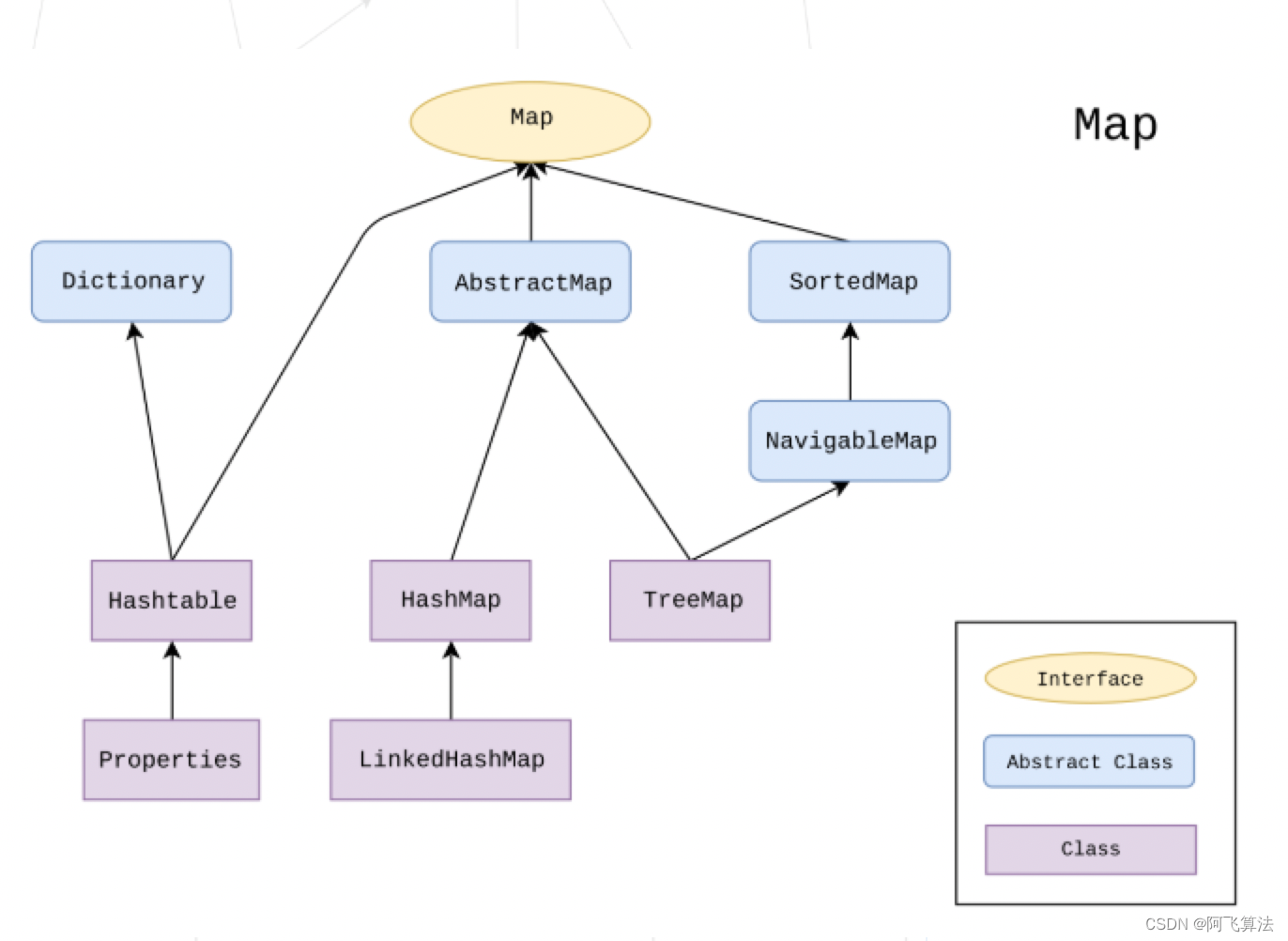
��Щ������Ϊ���������˺ܶ��:
- HashSet:ʵ�� Set �ӿ�,�������ظ���Ԫ��,�ײ����ݽṹ hash table
- LinkedHashSet:ʵ�� Set �ӿ�,�������ظ���Ԫ��,�ײ����ݽṹ hash table ��˫����
- TreeSet:ʵ�� NavigableSet �ӿ�,�������ظ���Ԫ��,�ײ����ݽṹ�����
- ArrayList:ʵ�� List �ӿ�,�����ظ�Ԫ��,�ײ����ݽṹ�ɱ�����
- LinkedList:ʵ�� List �ӿ�,�����ظ�Ԫ��,�ײ����ݽṹ˫����
- Vector:ʵ�� List �ӿ�,�����ظ�Ԫ��,�ײ����ݽṹ�ɱ�����
- HashMap:ʵ�� Map �ӿ�,�������ظ��� key,�ײ����ݽṹ hash table
- LinkedHashMap:ʵ�� Map �ӿ�,�������ظ��� key,�ײ����ݽṹ hash table ��˫����
- HashTable:ʵ�� Map �ӿ�,�������ظ��� key,�ײ����ݽṹ hash table
- TreeMap:ʵ�� SortedMap �ӿ�,�������ظ��� key,�ײ����ݽṹ�����
Java�г������ݽṹ:list��map -�ײ����ʵ��
1.1.HashMap����
Java����(��)��ConcurrentHashMap���ݽ���Java���̺߳��ļ���
1.1.0.HashMap��ʼ����Ϊʲô��2��n���ݼ�����Ϊʲô��2������ʽ
��HashMap��������2��n����ʱ,(n-1)��2����Ҳ����1111111***111������ʽ��,����������Ԫ�ص�hashֵ����λ����ʱ,�ܹ���ֵ�ɢ��,ʹ�����ӵ�Ԫ�ؾ��ȷֲ���HashMap��ÿ��λ����,����hash��ײ
1.1.1.HashMap �Dz��������?���������
��û�������Mapʵ������? TreeMap �� LinkedHashMap
TreeMap �� LinkedHashMap ����α�֤����˳���? TreeMap ��ͨ��ʵ�� SortMap �ӿ�,�ܹ���������ļ�ֵ�Ը��� key ����,���ں����,�Ӷ���֤ TreeMap �����м�ֵ�Դ�������״̬��LinkedHashMap ����ͨ����������(������ put ��ʱ���˳����ʲô,ȡ������ʱ�����ʲô����)�ͷ�������(�ı�����ѷ��ʹ��ķŵ��ײ�)�ü�ֵ����
1.1.2.Ϊʲô��HashMap?
HashMap ��һ��ɢ��Ͱ(���������),���洢�������Ǽ�ֵ�� key-value ӳ��
HashMap ��������������������ݽṹ,���ڲ�ѯ���ķ���̳�����������Բ��Һ�������Ѱַ��
HashMap �Ƿ� synchronized,���� HashMap �ܿ�
HashMap ���Խ��� null ����ֵ,�� Hashtable ����(ԭ����� equlas() ������Ҫ����,��Ϊ HashMap �Ǻ���� API ���������ſ���)
1.1.3.HashMap �Ĺ���ԭ����ʲô?
HashMap �ǻ��� hashing ��ԭ��
����ʹ�� put(key, value) �洢���� HashMap ��,ʹ�� get(key) �� HashMap �л�ȡ�������Ǹ� put() �������ݼ���ֵʱ,�����ȶԼ����� hashCode() ����,���㲢���ص� hashCode �������ҵ� Map ����� bucket λ�������� Node ����
����ؼ�������ָ��,HashMap ���� bucket �д���������ֵ����,��ΪMap.Node ��

�����Ǿ���� put ����(JDK1.8)
- 1.�� Key �� Hash ֵ,Ȼ���ټ����±�
- 2.���û����ײ,ֱ�ӷ���Ͱ��(��ײ����˼�Ǽ���õ��� Hash ֵ��ͬ,��Ҫ�ŵ�ͬһ�� bucket ��)
- 3.�����ײ��,�������ķ�ʽ���ӵ�����
- 4.����������ȳ�����ֵ(TREEIFY THRESHOLD==8),�Ͱ�����ת�ɺ����,�������ȵ���6,�ͰѺ����ת������
- 5.����ڵ��Ѿ����ھ��滻��ֵ
- 6.���Ͱ����(����16*��������0.75),����Ҫ resize(����2��������)
�����Ǿ��� get ����
�����������:����������� hashcode ��ͬ,����λ�ȡֵ����?
�����ǵ��� get() ����,HashMap ��ʹ�ü������ hashcode �ҵ� bucket λ��,�ҵ� bucket λ��֮��,����� keys.equals() ����ȥ�ҵ���������ȷ�Ľڵ�,�����ҵ�Ҫ�ҵ�ֵ����
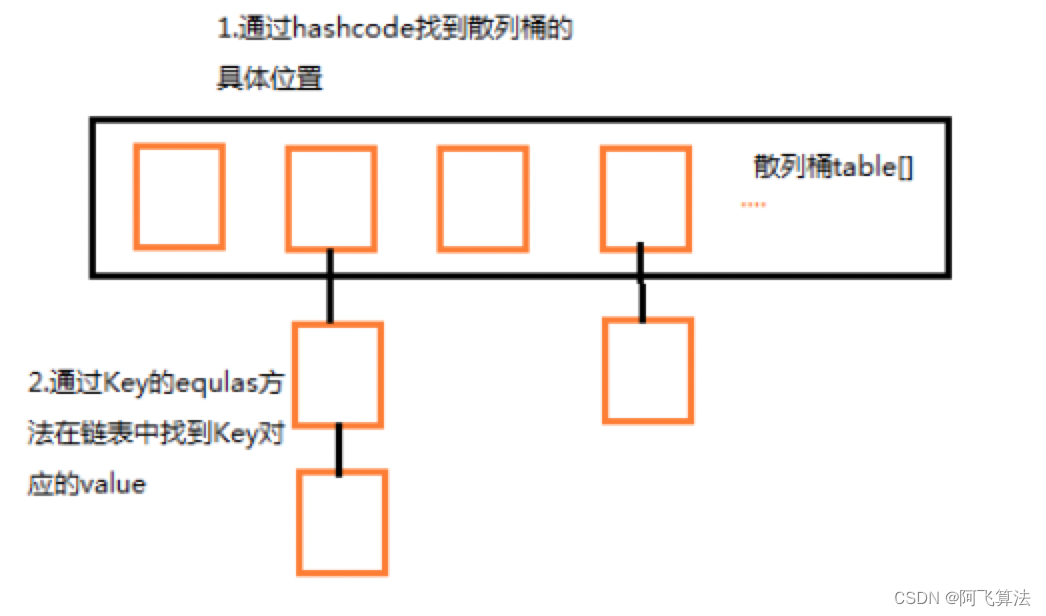
1.1.4.��ʲô�������Լ�����ײ?
�Ŷ��������Լ�����ײ
ԭ���������������ȵĶ��ز�ͬ�� hashcode �Ļ�,��ô��ײ�ļ��ʾͻ�СЩ�������ζ�Ŵ������ṹ��С,����ȡֵ�Ļ��Ͳ���Ƶ������ equal ����,�Ӷ���� HashMap ������(�Ŷ��� Hash �����ڲ����㷨ʵ��,Ŀ�����ò�ͬ���ز�ͬhashcode)��
ʹ�ò��ɱ�ġ������� final ����,���Ҳ��ú��ʵ� equals() �� hashCode() ����,���������ײ�ķ���
���ɱ���ʹ���ܹ����治ͬ���� hashcode,�⽫���������ȡ������ٶ�,ʹ�� String��Integer ������ wrapper ����Ϊ���Ƿdz��õ�ѡ��
Ϊʲô String��Integer ������ wrapper ���ʺ���Ϊ��?
��Ϊ String �� final,�����Ѿ���д�� equals() �� hashCode() �����ˡ����ɱ����DZ�Ҫ��,��ΪΪ��Ҫ���� hashCode(),��Ҫ��ֹ��ֵ�ı�,�����ֵ�ڷ���ʱ�ͻ�ȡʱ���ز�ͬ�� hashcode �Ļ�,��ô�Ͳ��ܴ� HashMap ���ҵ�����Ҫ�Ķ���
1.1.5.HashMap �� hash ������ô��ʵ�ֵ�?
���ǿ��Կ���,�� hashmap ��Ҫ�ҵ�ij��Ԫ��,��Ҫ���� key �� hash ֵ����ö�Ӧ�����е�λ�á���μ������λ�þ��� hash �㷨��
ǰ��˵��,hashmap �����ݽṹ������������Ľ��,�������ǵ�Ȼϣ����� hashmap �����Ԫ��λ�þ����ķֲ�����Щ,����ʹ��ÿ��λ���ϵ�Ԫ������ֻ��һ������ô�������� hash �㷨������λ�õ�ʱ��,���ϾͿ���֪����Ӧλ�õ�Ԫ�ؾ�������Ҫ��,��������ȥ���������� ����,���������뵽�ľ��ǰ� hashcode �����鳤��ȡģ���㡣����һ��,Ԫ�صķֲ������˵�DZȽϾ��ȵġ�
���ǡ�ģ����������Ļ��DZȽϴ��,�ܲ�����һ�ָ����١����ĸ�С�ķ�ʽ?���������� JDK1.8 Դ������ô����(��¥��������һ��)
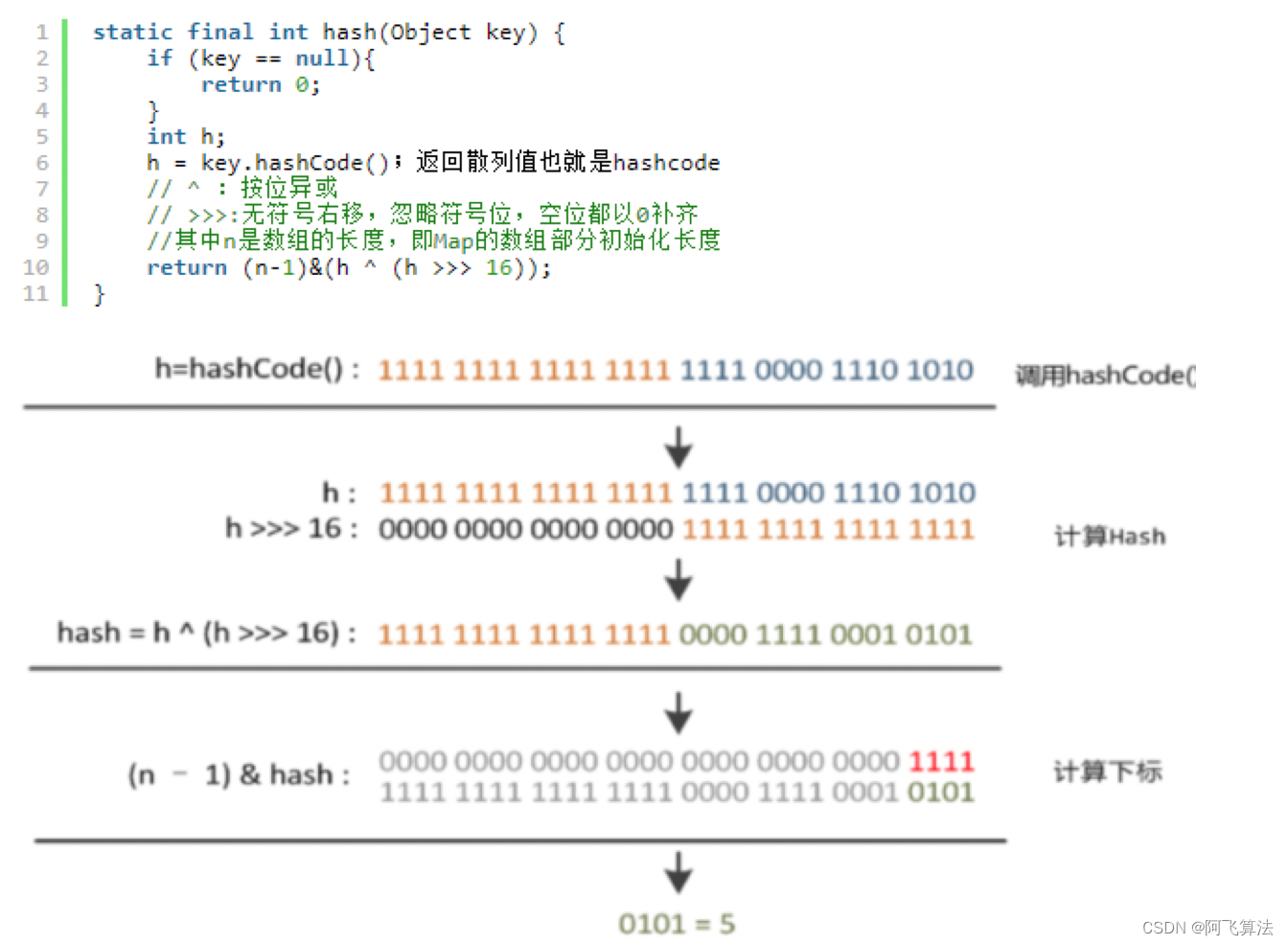
����˵����:
��16 bit ����,��16 bit ��16 bit ����һ�����(�õ��� hashcode ת��Ϊ32λ������,ǰ16λ�ͺ�16λ��16 bit��16 bit����һ�����)
(n��1) & hash = -> �õ��±�
1.1.6.���������µ���������,Ϊʲô���ö�������������ѡ������?Ϊʲô��һֱʹ�ú����?
֮����ѡ��������Ϊ�˽�������������ȱ��:�������������������»���һ�����Խṹ(���ԭ��ʹ�������ṹһ����,��ɲ�κ��������),�������һ�dz�������������ڲ��������ݺ������Ҫͨ����������������ɫ��Щ����������ƽ�⡣������������Ϊ�˲������ݿ�,���������ѯ��ȵ����⡣����֪�����������ƽ�������,Ϊ�˱��֡�ƽ�⡱����Ҫ�������۵�,���Ǹô�������ĵ���ԴҪ�ȱ�����������Ҫ�١����Ե����ȴ���8��ʱ��,��ʹ�ú����;����������Ⱥ̵ܶĻ�,��������Ҫ��������,���뷴��������
1.1.7.˵˵��Ժ�����ļ���?
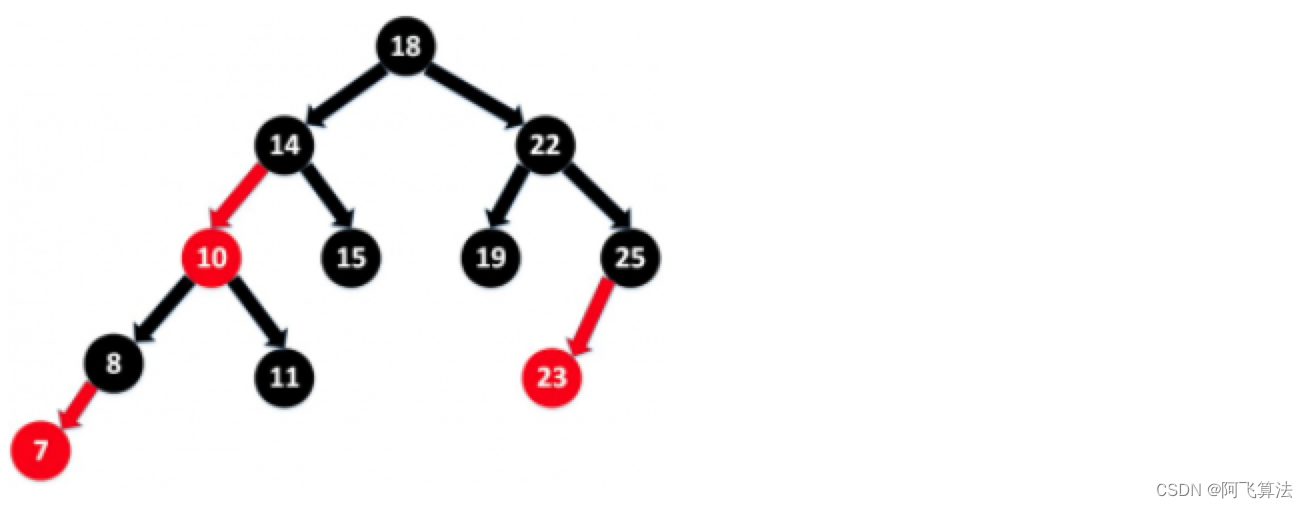
- ÿ���ڵ�Ǻ켴��
- ���ڵ����Ǻ�ɫ��
- ����ڵ��Ǻ�ɫ��,�������ӽڵ�����Ǻ�ɫ��(��֮��һ��)
- ÿ��Ҷ�ӽڵ㶼�Ǻ�ɫ�Ŀսڵ�(NIL�ڵ�)
- �Ӹ��ڵ㵽Ҷ�ڵ����ӽڵ��ÿ��·��,���������ͬ��Ŀ�ĺ�ɫ�ڵ�(����ͬ�ĺ�ɫ�߶�)
1.1.8.��� hash ��ײ������Щ�취?
���Ŷ�ַ��
����ͻ����ʱ,ʹ��ij��̽�鼼����ɢ�б����γ�һ��̽��(��)���С��ش����������Ԫ�ز���,ֱ���ҵ������ĵ�ַ�������γ�̽�����еķ�����ͬ,�ɽ����Ŷ�ַ������Ϊ����̽�鷨������̽�鷨��˫��ɢ�з��ȡ�
�����һ������̽�鷨������:
����:��֪һ��ؼ���Ϊ (26,36,41,38,44,15,68,12,06,51),�ó��෨����ɢ�к���,������̽�鷨�����ͻ��������ؼ��ֵ�ɢ�б���
���:Ϊ�˼��ٳ�ͻ,ͨ����װ������ �� �ɳ��෨������13��ɢ�к���������������ؼ������е�ɢ�е�ַΪ (0,10,2,12,5,2,3,12,6,12)��
ǰ5���ؼ��ֲ���ʱ,����Ӧ�ĵ�ַ��Ϊ���ŵ�ַ,�ʽ�����ֱ�Ӳ��� T[0]��T[10)��T[2]��T[12] �� T[5] �С�
�������6���ؼ���15ʱ,��ɢ�е�ַ2(�� h(15)=15%13=2)�ѱ��ؼ��� 41(15��41��Ϊͬ���)ռ�á���̽�� h1=(2+1)%13=3,�˵�ַ����,���Խ� 15 ���� T[3] �С�
�������7���ؼ���68ʱ,��ɢ�е�ַ3�ѱ���ͬ���15��ռ��,�ʽ�����뵽T[4]�С�
�������8���ؼ���12ʱ,ɢ�е�ַ12�ѱ�ͬ���38ռ��,��̽�� hl=(12+1)%13=0,�� T[0] �౻26ռ��,��̽�� h2=(12+2)%13=1,�˵�ַ����,�ɽ�12�������С�
���Ƶ�,��9���ؼ���06ֱ�Ӳ��� T[6] ��;�����һ���ؼ���51����ʱ,��̽��ĵ�ַ 12,0,1,��,6 ���ǿ�,��51���� T[7] �С�
ɢ�б�Ҫ�����һ���������ɢ��ֵ�ij�ͻ����,ͨ�������ַ���:�������Ϳ��ŵ�ַ�������������ǽ���ͬhashֵ�Ķ�����֯��һ����������hashֵ��Ӧ�IJ�λ;���ŵ�ַ����ͨ��һ��̽���㷨,��ij����λ�Ѿ���ռ�ݵ�����¼���������һ������ʹ�õIJ�λ��
1.1.9.��� HashMap �Ĵ�С�����˸�������(load factor)�����������ô��?
HashMap Ĭ�ϵĸ������Ӵ�СΪ0.75��Ҳ����˵,��һ�� Map ������75%�� bucket ʱ��,������������һ��(�� ArrayList ��),���ᴴ��ԭ�� HashMap ��С�������� bucket ���������µ��� Map ��С,����ԭ���Ķ�������µ� bucket �����С�������̽��� rehashing��
��Ϊ������ hash �����ҵ��µ� bucket λ�á����ֵֻ�����������ط�,һ����ԭ�±��λ��,��һ�������±�Ϊ <ԭ�±�+ԭ����> ��λ�á�
1.1.10.���µ��� HashMap ��С����ʲô������?
���µ��� HashMap ��С��ʱ��,ȷʵ��������������
��Ϊ��������̶߳����� HashMap ��Ҫ���µ�����С��,���ǻ�ͬʱ���ŵ�����С���ڵ�����С�Ĺ�����,�洢�������е�Ԫ�صĴ���ᷴ��������Ϊ�ƶ����µ� bucket λ�õ�ʱ��,HashMap �����ὫԪ�ط���������β��,���Ƿ���ͷ��������Ϊ�˱���β������(tail traversing)�������������������,��ô����ѭ���ˡ����̵߳Ļ����²�ʹ�� HashMap��
Ϊʲô���̻߳ᵼ����ѭ��,������ô������?
HashMap �����������ġ����������Ԫ�ز���,ʹ�� HashMap �ﵽһ�����Ͷ�ʱ,Key ӳ��λ�÷�����ͻ�ļ��ʻ�����ߡ���ʱ��, HashMap ��Ҫ��չ���ij���,Ҳ���ǽ���Resize��
����:����һ���µ� Entry ������,������ԭ�����2��
rehash:����ԭ Entry ����,�����е� Entry ���� Hash ��������
����ͼ:https://www.cnblogs.com/zhuoqingsen/p/8577646.html
1.1.11.HashTable
- ���� + ������ʽ�洢
- Ĭ������:11(����Ϊ��)
- put����:���Ƚ����������� (key.hashCode() & 0x7FFFFFFF)% table.length;�����������ҵ���,���滻��ֵ,��δ�ҵ������;����Ԫ�ظ������� ���� * �������� ʱ,����Ϊԭ�� 2 ��������ɢ��;����Ԫ�ؼӵ�����ͷ��
- ���� Hashtable �ڲ��������ݵķ��������� synchronized,��֤�̰߳�ȫ
1.1.12.HashMap �� HashTable ����
- Ĭ��������ͬ,���ݲ�ͬ
- �̰߳�ȫ��:HashTable ��ȫ
- Ч�ʲ�ͬ:HashTable Ҫ��,��Ϊ����
1.1.13.����ʹ�� CocurrentHashMap ������ Hashtable ��?
- ����֪�� Hashtable �� synchronized ��,���� ConcurrentHashMap ͬ�����ܸ���,��Ϊ����������ͬ������� map ��һ���ֽ�������
- ConcurrentHashMap ��Ȼ���Դ��� HashTable,���� HashTable �ṩ��ǿ���̰߳�ȫ��
- ���Ƕ��������ڶ��̵߳Ļ���,���ǵ� Hashtable �Ĵ�С���ӵ�һ����ʱ��,���ܻἱ���½�,��Ϊ����ʱ��Ҫ�������ܳ���ʱ�䡣���� ConcurrentHashMap �����˷ָ�(segmentation),��������ö�ô��,������Ҫ���� Map ��ij������,�������̲߳���Ҫ�ȵ�������ɲ��ܷ��� Map�������֮,�ڵ����Ĺ�����,ConcurrentHashMap �������� Map ��ij������,�� Hashtable ����������� Map
1.1.14.CocurrentHashMap(JDK 1.7)
- CocurrentHashMap ���� Segment ����� HashEntry ������������
- Segment �ǻ���������(ReentrantLock):һ�����ݶξ�������ÿ�� HashEntry һ�������ṹ��Ԫ��,���� Hash �㷨�õ�����ȷ�����������ݶ�,Ҳ���Ƕ�Ӧ������ʱ��Ҫ������ȡ������ConcurrentHashMap ֧�� CurrencyLevel(Segment ��������)���̲߳�����ÿ��һ���߳�ռ��������һ�� Segment ʱ,����Ӱ�쵽������ Segment
- ���������� value,�Լ��������� volatile ���ε�,��֤�˻�ȡʱ�Ŀɼ���
- ������ͨ�� key ��λ�� Segment,֮���ڶ�Ӧ�� Segment �н��о���� put ��������:
- ����ǰ Segment �е� table ͨ�� key �� hashcode ��λ�� HashEntry��
- ������ HashEntry,�����Ϊ�����жϴ���� key �͵�ǰ������ key �Ƿ����,����Ǿɵ� value
- ��Ϊ������Ҫ�½�һ�� HashEntry �����뵽 Segment ��,ͬʱ�����ж��Ƿ���Ҫ����
- �������� 1 ������ȡ��ǰ Segment ������
- ��Ȼ HashEntry �е� value ���� volatile �ؼ������ε�,���Dz����ܱ�֤������ԭ����,���� put ����ʱ��Ȼ��Ҫ��������
���ȵ�һ����ʱ��᳢�Ի�ȡ��,�����ȡʧ�ܿ϶����������̴߳��ھ���,������ scanAndLockForPut() ������ȡ���� - ����������ȡ��
- ������ԵĴ����ﵽ�� MAX_SCAN_RETRIES ���Ϊ��������ȡ,��֤�ܻ�ȡ�ɹ����������ǰ Segment ����
1.2.ʲô�ǿ���ʧ��(fail-fast)���ܾٸ�������?ʲô�ǰ�ȫʧ��(fail-safe)��?
����ʧ��(fail-fast)
����ʧ��(fail-fast)�� Java ���ϵ�һ�ִ�������ơ���ʹ�õ������Լ��Ͻ��б�����ʱ��,�����ڶ��߳��²����ǰ�ȫʧ��(fail-safe)�ļ�������ܾͻᴥ�� fail-fast ����,�����׳�ConcurrentModificationException �쳣������,�ڵ��߳���,����ڱ��������жԼ��϶�������ݽ������ĵĻ�Ҳ�ᴥ�� fail-fast ���ơ�
�ٸ�����:���߳���,����߳� 1 ���ڶԼ��Ͻ��б���,��ʱ�߳� 2 �Լ��Ͻ�����(���ӡ�ɾ������),�����߳� 1 �ڱ��������жԼ��Ͻ�����,���ᵼ���߳� 1 �׳��쳣��
��ȫʧ��(fail-safe)
���ð�ȫʧ�ܻ��Ƶļ�������,�ڱ���ʱ����ֱ���ڼ��������Ϸ��ʵ�,�����ȸ���ԭ�м� ������,�ڿ����ļ����Ͻ��б���������,�ڱ��������ж�ԭ�����������IJ����ܱ���������,�ʲ����� ConcurrentModificationException
1.3.��һ�� CopyOnWriteArrayList �� CopyOnWriteArraySet?
CopyOnWrite ����:
дʱ���Ƶ���������������һ����������Ԫ�ص�ʱ��,��ֱ������ǰ�� ������,�����Ƚ���ǰ�������� Copy,���Ƴ�һ���µ�����,Ȼ���µ�����������Ԫ��,�� ����Ԫ��֮��,�ٽ�ԭ����������ָ���µ��������������ĺô������ǿ��Զ� CopyOnWrite �������в����Ķ�,������Ҫ����,��Ϊ��ǰ�������������κ�Ԫ�ء����� CopyOnWrite ����Ҳ��һ�ֶ�д�����˼��,����д��ͬ�����������´������� ArrayList ������Ԫ��,���Է��������ӵ�ʱ������Ҫ������,������߳�д��ʱ��� Copy ��N������������
public boolean add(T e) {
final ReentrantLock lock = this.lock; lock.lock();
try {
Object[] elements = getArray(); int len = elements.length;// ���Ƴ�������
Object[] newElements = Arrays.copyOf(elements, len + 1); //����Ԫ�����ӵ���������
newElements[len] = e; // ��ԭ��������ָ��������
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
����ʱ����Ҫ����,�������ʱ���ж���߳������� ArrayList ��������,�����ǻ�����ɵ�����,��Ϊд��ʱ����ס�ɵ� ArrayList��
public E get(int index) {
return get(getArray(), index);
}
CopyOnWrite �����������ڶ���д�ٵIJ���������
CopyOnWrite ��ȱ��
CopyOnWrite�� ���кܶ��ŵ�,����ͬʱҲ������������,�� �ڴ�ռ������ �� ����һ�������⡣�����ڿ�����ʱ����Ҫע�⡣
�ڴ�ռ�����⡣��Ϊ CopyOnWrite ��дʱ���ƻ���,�����ڽ���д������ʱ��,�ڴ����ͬʱפ������������ڴ�,�ɵĶ������д��Ķ���(ע��:�ڸ��Ƶ�ʱ��ֻ�Ǹ������������ ��,ֻ����д��ʱ��ᴴ���¶������ӵ���������,���������Ķ�����ʹ��,���������� �����ڴ�)�������Щ����ռ�õ��ڴ�Ƚϴ�,����˵ 200M ����,��ô��д�� 100M ���ݽ�ȥ,�ڴ�ͻ�ռ�� 300M,��ô���ʱ����п������Ƶ���� Yong GC �� Full GC������ڴ�ռ������,����ͨ��ѹ�������е�Ԫ�صķ��������ٴ������ڴ�����,����,�� ��Ԫ��ȫ��10���Ƶ�����,���Կ��ǰ���ѹ����36���ƻ�64���ơ����߲�ʹ�� CopyOnWrite ����,��ʹ�������IJ�������,�� ConcurrentHashMap��
14��CocurrentHashMap(JDK 1.8)
CocurrentHashMap ������ԭ�е� Segment �ֶ���,������ CAS + synchronized ����֤������ȫ�ԡ����е� val next ������ volatile ����,��֤�˿ɼ��ԡ�
����ص��������� CAS
���� Unsafe ��ʵ�� native code��CAS��3��������,�ڴ�ֵ V���ɵ�Ԥ��ֵ A��Ҫ�ĵ���ֵ B�����ҽ���Ԥ��ֵ A ���ڴ�ֵ V ��ͬʱ,���ڴ�ֵV��Ϊ B,����ʲô��������Unsafe ���� CPU ָ�� cmpxchg ��ʵ�֡�
CAS ʹ��ʵ��
�� sizeCtl �Ŀ��ƶ����� CAS ��ʵ�ֵ�:
- -1 ���� table ���ڳ�ʼ��
- N ��ʾ�� -N-1 ���߳����ڽ������ݲ���
- ��� table δ��ʼ��,��ʾtable��Ҫ��ʼ���Ĵ�С
- ��� table ��ʼ�����,��ʾtable������,Ĭ����table��С��0.75��,�������ʽ�� 0.75(n �C (n >>> 2))
CAS ����ֵ�����:ABA
���:�Ա�������һ���汾��,ÿ����,�汾�ż� 1,�Ƚϵ�ʱ��Ƚϰ汾�š�
put ����- ���� key ����� hashcode
- �ж��Ƿ���Ҫ���г�ʼ��
- ͨ�� key ��λ���� Node,���Ϊ�ձ�ʾ��ǰλ�ÿ��� д������,���� CAS ����д��,ʧ����������֤�ɹ�
- �����ǰλ�õ� hashcode == MOVED == -1,����Ҫ��������
- �����������,������ synchronized �������
- ����������� TREEIFY_THRESHOLD ��Ҫת��Ϊ�����
get ���� - ���ݼ�������� hashcode Ѱַ,�������Ͱ����ôֱ�ӷ���ֵ
- ����Ǻ�����ǾͰ������ķ�ʽ��ȡֵ
- �Ͳ������ǾͰ��������ķ�ʽ������ȡֵ

15.hashmap�̲߳���ȫ,����Ϊʲô�̲߳���ȫ?
���γ�ѭ������
https://blog.csdn.net/chisunhuang/article/details/79041656
16.ʹ�ú����Ϊʲô����߲�ѯ������?
�����(red-black tree) ��һ�������������ʵĶ��������:
- ÿһ�����Ҫô�Ǻ�ɫ,Ҫô�Ǻ�ɫ��
- ������Ǻ�ɫ�ġ�
- ����Ҷ�ӽ�㶼�Ǻ�ɫ��(ʵ���϶���Nullָ��,��ͼ��NIL��ʾ)��Ҷ�ӽ�㲻�����κιؼ�����Ϣ,���в�ѯ�ؼ��ֶ��ڷ��ս���ϡ�
- ÿ����ɫ���������ӽڵ�����Ǻ�ɫ�ġ����仰˵:��ÿ��Ҷ�ӵ���������·���ϲ��������������ĺ�ɫ���
- ����һ��㵽��ÿ��Ҷ�ӵ�����·����������ͬ��Ŀ�ĺ�ɫ���
�������ض���
-
�Ӹ���Ҷ�ӵ���Ŀ���·����������̵Ŀ���·������������
�������������5����֪����ͼ�ĺ����ÿ��·���϶���3���ڽ�㡣������·������Ϊ2(û�к����·��)���ٸ�������4(�������㲻������)������1,2(Ҷ�Ӻ������Ǻڽ��)����ô���ǿ��Եó�:һ������3���ڽ���·�������ֻ����2������(��ڼ������)��Ҳ����˵�����Ϊ2(�����Ҳ�Ǻ�ɫ)�ĺ�����·��Ϊ4,���·��Ϊ2������һ�����ǿ��Կ���������� ����ƽ��ġ� (��Ȼ��ƽ�������Ҫ��һЩ,AVL��ƽ���������Ϊ1) -
�����������(h)������������������(bd),��h<=2bd
���ݶ���1,���Dz���˵����һ�㡣bd�Ǻ���������·�����ȡ������ܵ��·������(���ߵ����ֵ)���Ǻ������·��,����2bd�����h<=2bd�� -
һ��ӵ��n���ڲ����(������Ҷ�ӽ��)�ĺ����������h<=2log(n+1)
������������֤��һ����n���ڲ����ĺ��������n>=2bd-1�����������ѧ���ɷ�֤��,ʩ����������h����h=0ʱ,���൱����һ��Ҷ���,�ڸ߶�bdΪ0,���ڲ��������nΪ0,��ʱ0>=20-1��������������h<=tʱ,n>=2^bd-1����,���Ǽ�һ������ Ϊt+1�ĺ�����ĸ��������������ڲ��������Ϊnl,���������ڲ��������Ϊnr,�������������ĺڸ߶�Ϊbd��(ע�������������ĺڸ߶ȱ�Ȼһ ��),��Ȼ����������������<=t,������nl>=2bd��-1�Լ�nr>=2bd��-1,������������ʽ�����nl+nr>=2(bd��+1)-2,���ò���ʽ���Ҽ�1,�õ�n>=2(bd��+1)-1,����Ȼbd��+1>=bd,����ǰ��IJ���ʽ���� ��Ϊn>=2bd-1,������֤����һ����n���ڲ����ĺ��������n>=2bd-1��
�ڸ��ݶ���2,h<=2bd����n>=2^(h/2)-1,��ôh<=2log(n+1)
�����������ܹ�����,������IJ��ҳ���������2log(n+1),��������ʱ�临�Ӷ�Ҳ��O(log N)����ġ�
������IJ���
��Ϊÿһ�������Ҳ��һ���ػ��Ķ��������,��˺�����ϵIJ��Ҳ�������ͨ����������ϵIJ��Ҳ�����ͬ��Ȼ��,�ں�����Ͻ��в��������ɾ�������ᵼ�²� �ٷ��Ϻ���������ʡ��ָ��������������Ҫ����(O(log n))����ɫ���(ʵ���Ƿdz����ٵ�)�Ͳ�������������ת(���ڲ������������)�� ��Ȼ�����ɾ���ܸ���,������ʱ���Կ��Ա���Ϊ O(log n) �� ��
������ܹ���O(log2(N))��ʱ�临�ӶȽ������������롢ɾ������������,�κβ�ƽ�ⶼ����3����ת֮�ڽ������һ����AVL�����߱��ġ�
����ʵ��Ӧ����,�ܶ����Զ�ʵ���˺���������ݽṹ������ TreeMap, TreeSet(Java )�� STL(C++)�ȡ�
17.HashMap�����Dz�������ͷ������β��
��jdk1.8֮ǰ�Dz���ͷ����,��jdk1.8���Dz���β���ġ�
1.2.List����
1.2.1.ArrayList ����ȱ��
ArrayList���ŵ�����:
ArrayList �ײ�������ʵ��,��һ���������ģʽ��- ArrayList ʵ���� RandomAccess �ӿ�,��˲��ҵ�ʱ��dz��졣
ArrayList ��˳������һ��Ԫ�ص�ʱ��dz����㡣
ArrayList ��ȱ������:
ɾ��Ԫ�ص�ʱ��,��Ҫ��һ��Ԫ�ظ��Ʋ��������Ҫ���Ƶ�Ԫ�غܶ�,��ô�ͻ�ȽϺķ����ܡ�
����Ԫ�ص�ʱ��,Ҳ��Ҫ��һ��Ԫ�ظ��Ʋ���,ȱ��ͬ�ϡ�
ArrayList �Ƚ��ʺ�˳�����ӡ�������ʵij�����
1.2.2.��������ʱ,ArrayList��LinkedList��Vector˭�ٶȽϿ�?
ArrayList��Vector �ײ��ʵ�ֶ���ʹ�����鷽ʽ�洢���ݡ�����Ԫ��������ʵ�ʴ洢�������Ա����ӺͲ���Ԫ��,���Ƕ�����ֱ�Ӱ��������Ԫ��,���Dz���Ԫ��Ҫ�漰����Ԫ���ƶ����ڴ����,�����������ݿ��������������
Vector �еķ������ڼ��� synchronized ����,��� Vector ���̰߳�ȫ����,�������Ͻ�ArrayList�
LinkedList ʹ��˫������ʵ�ִ洢,���������������Ҫ����ǰ���������,����������ʱֻ��Ҫ��¼��ǰ���ǰ�����,���� LinkedList �����ٶȽϿ�
2.��ƪ
2.1.IO/NIO
ͬ�����첽
ͬ��: ͬ�����Ƿ���һ�����ú�,��������δ����������֮ǰ,���ò����ء�
�첽: �첽���Ƿ���һ�����ú�,���̵õ��������ߵĻ�Ӧ��ʾ�ѽ��յ�����,���DZ������߲�û�з��ؽ��,��ʱ���ǿ��Դ�������������,��������ͨ�������¼�,�ص��Ȼ�����֪ͨ�������䷵�ؽ����
ͬ�����첽��������������첽�Ļ������߲���Ҫ�ȴ��������,��������ͨ���ص��Ȼ�����֪ͨ�������䷵�ؽ����
�����ͷ�����
����: �������Ƿ���һ������,������һֱ�ȴ�����������,Ҳ���ǵ�ǰ�̻߳ᱻ����,��������������,ֻ�е������������ܼ�����
������: ���������Ƿ���һ������,�����߲���һֱ���Ž������,������ȥ���������顣
�ٸ������м�����,������������ˮ,Сʱ����Ƚϱ���,������ɵ����ˮ��(ͬ������)���������ٳ���һ��,��֪��ÿ����ˮ�Ŀ�϶����ȥ�ɵ�������,Ȼ��ֻ��Ҫʱ��ʱ������ˮ����û��(ͬ��������)������,���Ǽ�������ˮ���˻ᷢ�������ĺ�,�������ֻ��Ҫ�����������֪��ˮ����,�����ڼ�����������Լ�������,����Ҫȥ��ˮ��(�첽������)��
2.1.1.IO/NIO����
1.NIO������/NIO��IO����
1)Non-blocking IO(������IO)
IO����������,NIO���Dz������ġ�
Java NIOʹ���ǿ��Խ��з�����IO����������˵,���߳��д�ͨ����ȡ���ݵ�buffer,ͬʱ���Լ������������,�����ݶ�ȡ��buffer�к�,�߳��ټ����������ݡ�д����Ҳ��һ���ġ�����,������дҲ����ˡ�һ���߳�����д��һЩ���ݵ�ijͨ��,������Ҫ�ȴ�����ȫд��,����߳�ͬʱ����ȥ��������顣
Java IO�ĸ������������ġ�����ζ��,��һ���̵߳���read()��write()ʱ,���̱߳�����,ֱ����һЩ���ݱ���ȡ,��������ȫд�롣���߳��ڴ��ڼ䲻���ٸ��κ�������
2)Buffer(������)
IO ������(Stream oriented),�� NIO ������(Buffer oriented)��
Buffer��һ������,������һЩҪд�����Ҫ���������ݡ���NIO����м���Buffer����,�������¿���ԭI/O��һ����Ҫ��������������I/O�С����Խ�����ֱ��д����߽�����ֱ�Ӷ��� Stream �����С���Ȼ Stream ��Ҳ�� Buffer ��ͷ����չ��,��ֻ�����İ�װ��,���Ǵ�������������,�� NIO ȴ��ֱ�Ӷ��� Buffer �н��в�����
��NIO����,�������ݶ����û����������ġ��ڶ�ȡ����ʱ,����ֱ�Ӷ����������е�; ��д������ʱ,д�뵽�������С��κ�ʱ�����NIO�е�����,����ͨ�����������в�����
��õĻ������� ByteBuffer,һ�� ByteBuffer �ṩ��һ�鹦�����ڲ��� byte ���顣����ByteBuffer,����������һЩ������,��ʵ��,ÿһ��Java��������(����Boolean����)����Ӧ��һ�ֻ�������
3)Channel (ͨ��)
NIO ͨ��Channel(ͨ��) ���ж�д��
ͨ����˫���,�ɶ�Ҳ��д,�����Ķ�д�ǵ���ġ����۶�д,ͨ��ֻ�ܺ�Buffer��������Ϊ Buffer,ͨ�������첽�ض�д��
4)Selectors(ѡ����)
NIO��ѡ����,��IOû�С�
ѡ��������ʹ�õ����̴߳������ͨ�������,����Ҫ���ٵ��߳���������Щͨ�����߳�֮����л����ڲ���ϵͳ��˵�ǰ���ġ� ���,Ϊ�����ϵͳЧ��ѡ���������õġ�
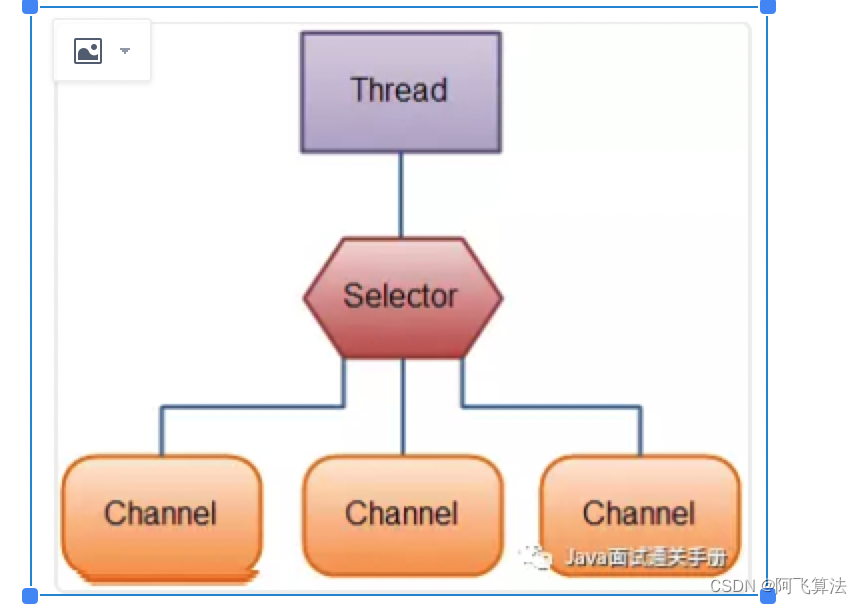
2.NIO �����ݺ�д���ݷ�ʽ
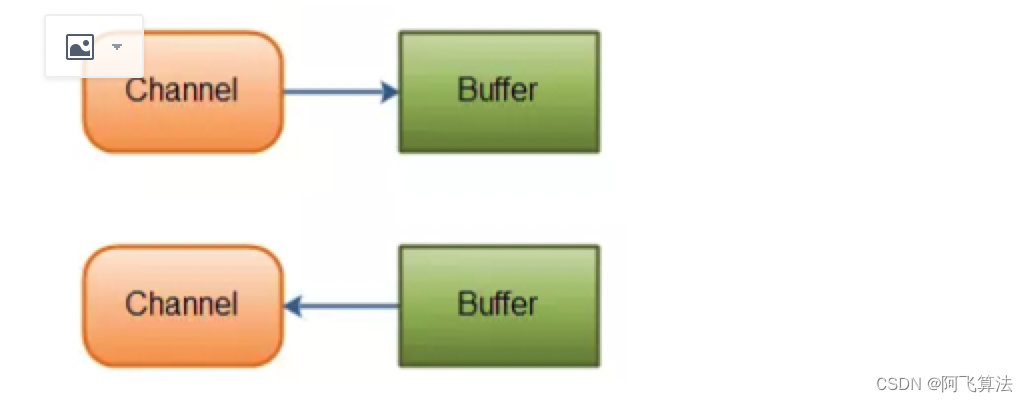
ͨ����˵NIO�е�����IO���Ǵ� Channel(ͨ��) ��ʼ�ġ�
��ͨ���������ݶ�ȡ :����һ��������,Ȼ������ͨ����ȡ���ݡ�
��ͨ����������д�� :����һ��������,�������,��Ҫ��ͨ��д�����ݡ�
���ݶ�ȡ��д�����ͼʾ:
3.AIO (Asynchronous I/O)
AIO Ҳ���� NIO 2���� Java 7 �������� NIO �ĸĽ��� NIO 2,�����첽��������IOģ�͡��첽 IO �ǻ����¼��ͻص�����ʵ�ֵ�,Ҳ����Ӧ�ò���֮���ֱ�ӷ���,�������������,����̨�������,����ϵͳ��֪ͨ��Ӧ���߳̽��к����IJ�����
AIO ���첽IO����д,��Ȼ NIO �����������,�ṩ�˷������ķ���,���� NIO �� IO ��Ϊ����ͬ���ġ����� NIO ��˵,���ǵ�ҵ���߳����� IO ��������ʱ,�õ�֪ͨ,���ž�������߳����н��� IO ����,IO����������ͬ���ġ�
������:��θ�Ů���ѽ���ʲô��Linux������IOģ��?��
https://github.com/Snailclimb/JavaGuide/blob/master/Java%E7%9B%B8%E5%85%B3/Java%20IO%E4%B8%8ENIO.md
BIO��NIO��AIO
BIO (Blocking I/O):
ͬ������ I/O ģʽ,���ݵĶ�ȡд�����������һ���߳��ڵȴ�����ɡ�
NIO (Non-blocking/New I/O):
NIO ��һ��ͬ���������� I/O ģ��,��Ӧ java.nio ��,�ṩ�� Channel , Selector,Buffer �ȳ���Java NIOʹ���ǿ��Խ��з�����IO����������˵, ���߳��д�ͨ����ȡ���ݵ�buffer,ͬʱ���Լ������������,�����ݶ�ȡ��buffer�к�, �߳��ټ����������ݡ�д����Ҳ��һ���ġ�����,������дҲ����ˡ�һ���߳�����д��һ Щ���ݵ�ijͨ��,������Ҫ�ȴ�����ȫд��,����߳�ͬʱ����ȥ��������顣JDK �� NIO �ײ��� epoll ʵ�֡�
ͨ����˵ NIO �е����� IO ���Ǵ� Channel(ͨ��) ��ʼ�ġ�
��ͨ���������ݶ�ȡ :����һ��������,Ȼ������ͨ����ȡ���ݡ�
��ͨ����������д�� :����һ��������,�������,��Ҫ��ͨ��д�����ݡ�
AIO (Asynchronous I/O):�첽������IOģ��,�첽 IO �ǻ����¼��ͻص�����ʵ�ֵ�,Ҳ����Ӧ�ò���֮���ֱ�ӷ���,�������������,����̨�������,����ϵͳ��֪ͨ��Ӧ�� �߳̽��к����IJ�����AIO ��Ӧ�û����Ǻܹ㷺��
2.2.java1.8��������
java8Stream map��flatmap������:
https://www.cnblogs.com/wangjing666/p/9999666.html
https://www.jianshu.com/p/a5950652ac39
2.3.ǿ���á������á������á�������
ǿ����:��ǿ���ù����Ķ��ᱻ���ա�ʹ�� new һ���¶���ķ�ʽ������ǿ���á�
Object obj = new Object();
������:�������ù����Ķ���ֻ�����ڴ治��������²Żᱻ���ա�ʹ�� SoftReference �������������á�
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null; // ʹ����ֻ�������ù���
������:�������ù����Ķ���һ���ᱻ����,Ҳ����˵��ֻ�ܴ���һ���������շ� ��֮ǰ��ʹ�� WeakReference �������������á�
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;
2.10.һЩ����
1.����˳��:
��̬�����;�̬����������ʵ����������ͨ����,��̬�����;�̬����ij�ʼ��˳��ȡ���������ڴ����е�˳��
���ڼ̳е������,��ʼ��˳��Ϊ:
����(��̬��������̬����)
����(��̬��������̬����)
����(ʵ����������ͨ����)
����(���캯��)
����(ʵ����������ͨ����)
����(���캯��)
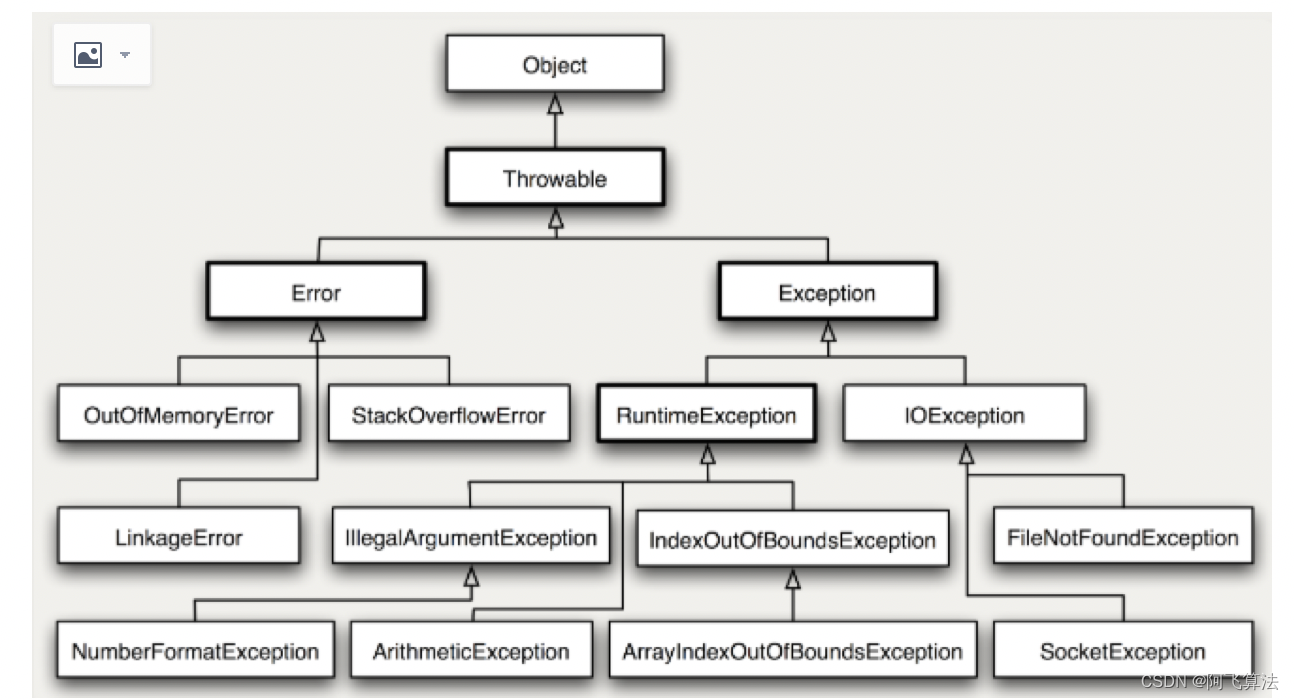
2.�쳣
Throwable ����������ʾ�κο�����Ϊ�쳣�׳�����,��Ϊ����: Error �� Exception������ Error ������ʾ JVM �������Ĵ���,Exception ��Ϊ����:
�ܼ��쳣 :��Ҫ�� try��catch�� ��䲶���д���,���ҿ��Դ��쳣�лָ�;
���ܼ��쳣 :�dz�������ʱ����,����� 0 ������ Arithmetic Exception,��ʱ��������������ָ���
3.����
Java �������
10 �� Java ����������
�������������,���ǿ����ܽ��һ������,��Producer Extends, Consumer Super��:
��Producer Extends�� �C �������Ҫһ��ֻ��List,������produce T,��ôʹ��? extends T��
��Consumer Super�� �C �������Ҫһ��ֻдList,������consume T,��ôʹ��? super T��
�����Ҫͬʱ��ȡ�Լ�д��,��ô���ǾͲ���ʹ��ͨ����ˡ�
����Ķ���һЩJava�������Դ��,���Է���ͨ�����ǻὫ���߽������һ����,��������������:
public class Collections {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++)
dest.set(i, src.get(i));
}
}
4.String��StringBuffer��Stringbuild�������ܱȽ�
https://blog.csdn.net/shenhonglei1234/article/details/54908934