目录
💟作者简介:大家好呀!我是路遥叶子,大家可以叫我叶子哦!???? ?
📝个人主页:【路遥叶子的博客】
🏆博主信息:四季轮换叶,一路招摇胜!?????????????? 专栏
??????? 【安利Java基础】
??????? 【数据结构-Java语言描述】
🐋希望大家多多支持😘一起进步呀!~??
🌈若有帮助,还请【关注?点赞?收藏】,不行的话我再努力努力呀!💪
――――――――――――――――
🍁想寻找共同成长的小伙伴,请点击【Java全栈社区】
前言
由于图的结构比较复杂,任意两个顶点之间都可能存在关系(边),无法通过存储位置表示这种任意的逻辑关系,所以,图无法采用顺序存储结构。这一点同其他数据结构(如线性表、树)不同。
因为图中的顶点具有相对概念,没有固定的位置,且顶点和顶点之间通过添加和删除边,维持着不同的关系。考虑图的定义,图是由顶点和边组成的。所以,分别考虑如何存储顶点和边。图常用的存储结构有邻接矩阵、邻接表、十字链表和邻接多重表。那么对于一般情况下该怎么存储图的数据结构呢?这里我们主要分两个章节详细介绍两种常用的图存储结构 ― 邻接矩阵、邻接表

什么是邻接表?
在图论和计算机科学中,邻接表【Adjacency List】是用来表示有限图的无序表的集合。每个列表描述图中一个顶点的邻域集。这是计算机程序中常用的几种图形表示法之一。
1. 邻接表,存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
2. 实际上就是一种由链表组成的图形数据结构,对其每一个顶点,都用链表来记录它的出边。 ??
3. 对于无向图来说,使用邻接表进行存储也会出现数据冗余,表头结点A所指链表中存在一个指向C的表结点的同时,表头结点C所指链表也会存在一个指向A的表点。???
邻接表:定义
对于无向图,n个顶点e条边的无向图的邻接表表示中,有n个顶点表结点和2e个边表结点。
对于有向图,vi的邻接表中每个表结点都对应于以vi为始点射出的一条边。因此,将有向图的邻接表称为出边表。
1、邻接表是图的一种链式存储方法
2、邻接表由一个顺序存储的顶点表和n个链式存储的边表组成。
-
顶点表由顶点结点组成
-
边表:
?无向图:由?边?结点组成的一个单链表,表示所有依附于顶点vi的边。
有向图:由?弧?结点组成的一个单链表,表示所有以顶点vi为始点的弧。
-
链式存储结点:
-
图结点由2部分组成:第一个邻接点、下一个邻接点
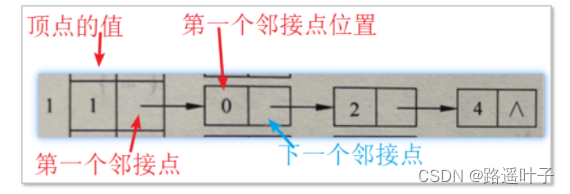
-
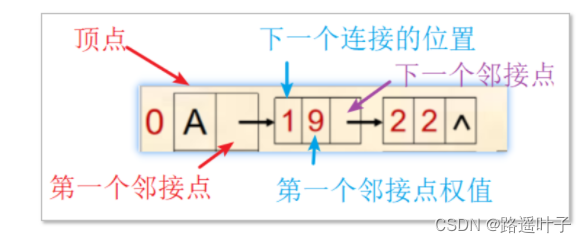
网结点有3部分组成:第一个邻接点、权值、下一个邻接点
-
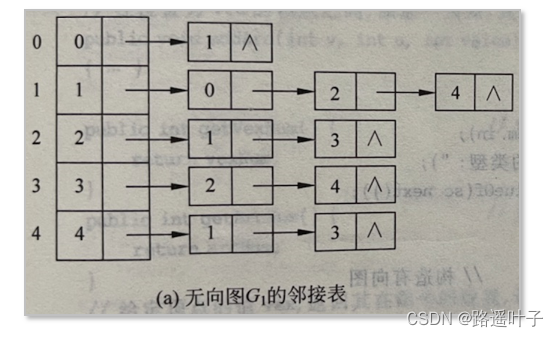
无向图:对应的邻接表某行上边结点个数为该行表示结点的度。
-
如果无向图(网)中有e条边,则对应邻接表有2e个边结点。
-
无向网邻接表
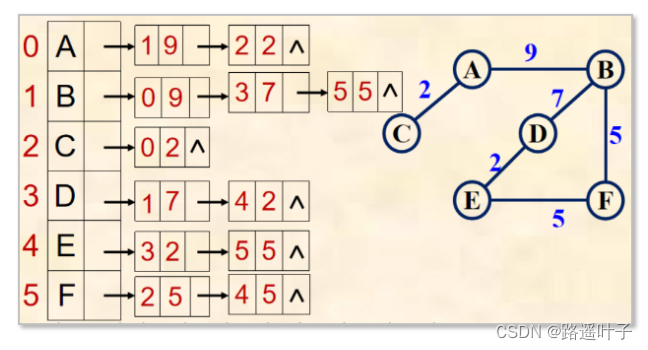
有向图:
-
邻接表:边表表示所有以vi为始点的弧。
-
对应的邻接表某行上边结点个数为该结点的出度。
-
在有向图的邻接表中不易找到指向该顶点的弧。
-
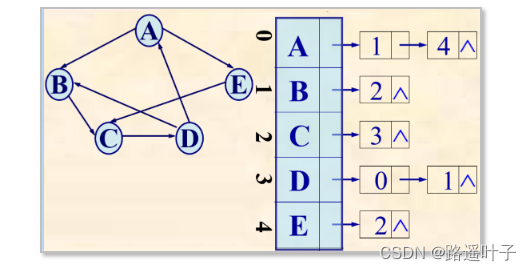
逆邻接表:边表表示所有以vi为终点的弧。
-
对应的逆邻接表某行上边结点个数为该结点的入度。
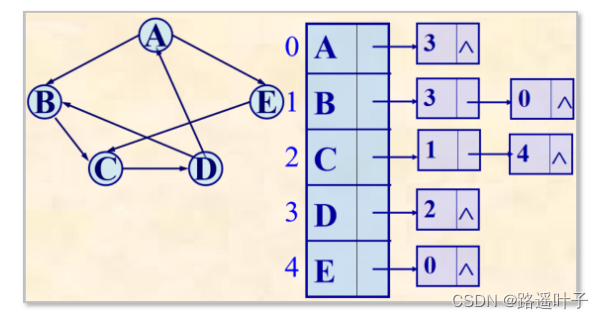
- ?如果有向图(网)中有e条边,则对应邻接表有e个边结点。
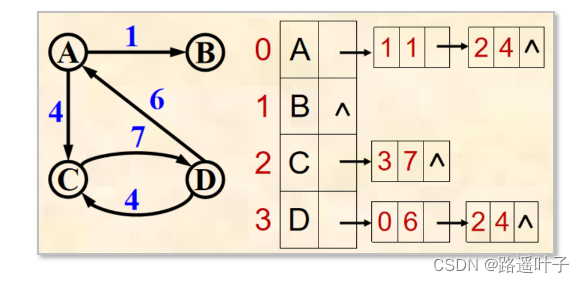
邻接表:相关类
- 顶点结点类:

//图的邻接表存储表示中的顶点结点类
public class VNode {
public Object data; //顶点信息
public ArcNode firstArc; //指向第一个依附于该顶点的弧
}- 边(弧)结点类:

//图的邻接表存储表示中的边(弧)结点类
public class ArcNode {
public int adjVex; //该弧所指向的顶点位置
public int value; //边(或弧)的权值
public ArcNode nextArc; //指向下一条弧
}- 邻接表类
//创建邻接表
public class ALGraph implements IGraph {
private GraphKind kind; //图的种类标志
private int vexNum, arcNum; //图的当前顶点数和边数
private VNode[] vexs; //顶点
private void createUDN() { //创建无向网
}
private void createDN() { //创建有向网
}
// 给定顶点的值vex,返回其在图中的位置,若图中不包含该顶点的,则返回-1
public int locateVex(Object vex) {}
// 在图中插入边结点
public void addArc(int v, int u, int value) {}
// 返回v的第一个邻接点,若v没有邻接点则返回-1。其中 0 <= v <= vexNum
public int firstAdjVex(int v) throws Exception {}
// 返回v相对于w的下一个邻接点,若w是v的最后一个邻接点,则返回-1。其中 0 <= v,w <= vexNum
public int nextAdjVex(int v, int w) throws Exception {}
}邻接表:基本操作
1)创建无向网
-
步骤:
-
输入顶点数和边数
-
构建顶点向量
-
根据图的边数,确定输入边的数目
-
根据输入的每条边生成结点,并在相应位置插入边结点
-
-
代码
// 无向网的创建算法
private void createUDN() {
//初始化变量
Scanner sc = new Scanner(System.in);
System.out.println("请分别输入图的顶点数、图的边数:");
vexNum = sc.nextInt(); //顶点数n
arcNum = sc.nextInt(); //边数e
//输入图中各顶点
vexs = new VNode[vexNum];
System.out.println("请分别输入图的各顶点:");
// 构造顶点向量
for (int v = 0; v < vexNum; v++)
vexs[v] = new VNode(sc.next());
//输入图中各边信息
System.out.println("请输入各边的顶点及其权值:");
for (int k = 0; k < arcNum; k++) {
int v = locateVex(sc.next()); // 弧尾
int u = locateVex(sc.next()); // 弧头
int value = sc.nextInt(); // 权值
addArc(v, u, value); //加入边
addArc(u, v, value); //加入边
}
}2)创建有向网
// 创建有向网
private void createDN() {
Scanner sc = new Scanner(System.in);
System.out.println("请分别输入图的顶点数、图的边数:");
vexNum = sc.nextInt();
arcNum = sc.nextInt();
vexs = new VNode[vexNum];
System.out.println("请分别输入图的各顶点:");
for (int v = 0; v < vexNum; v++)
// 构建顶点向量
vexs[v] = new VNode(sc.next());
System.out.println("请输入各边的顶点及其权值:");
for (int k = 0; k < arcNum; k++) {
int v = locateVex(sc.next());// 弧尾
int u = locateVex(sc.next());// 弧头
int value = sc.nextInt();
addArc(v, u, value); // 一个方向
}
}3)顶点定位
// 给定顶点的值vex,返回其在图中的位置,若图中不包含该顶点的,则返回-1
public int locateVex(Object vex) {
for (int v = 0; v < vexNum; v++)
if (vexs[v].data.equals(vex))
return v;
return -1;
}4)插入边
-
核心思想:往链式存储的边表头插入一个新结点。
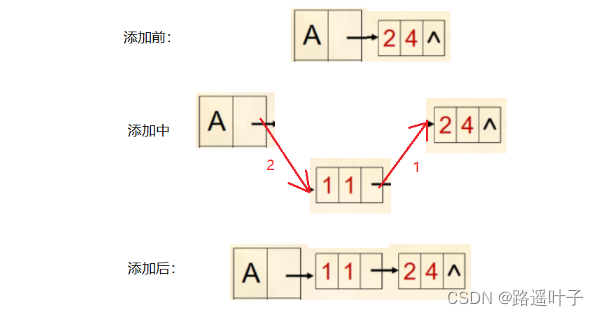
// 在图中插入边结点
public void addArc(int v, int u, int value) {
ArcNode arc = new ArcNode(u, value); //u为边的终点,生成边结点
arc.nextArc=vexs[v].firstArc; //v为边的起点,将边结点插入顶点v 的链表表头
vexs[v].firstArc=arc; //生成新表头
}5)第一个邻接点
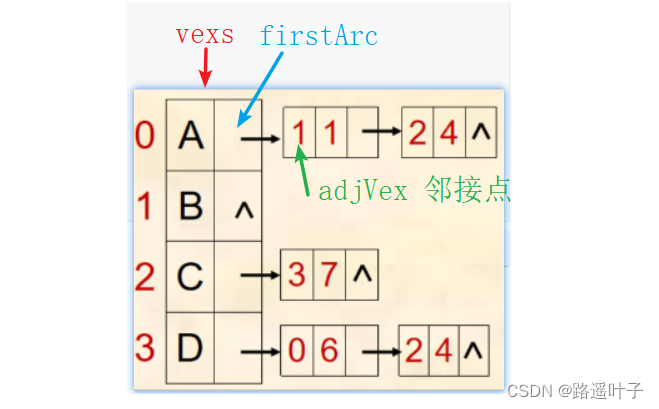
// 已知图中的一个顶点v,返回v的第一个邻接点,如果v没有连接点,则返回-1,其中0 <= v < vexNum
public int firstAdjVex(int v) throws Exception {
if (v < 0 || v >= vexNum)
throw new Exception("第" + v + "个顶点不存在!");
VNode vex = vexs[v];
if (vex.firstArc != null)
return vex.firstArc.adjVex;
else
return -1;
}6)查询下一个邻接点
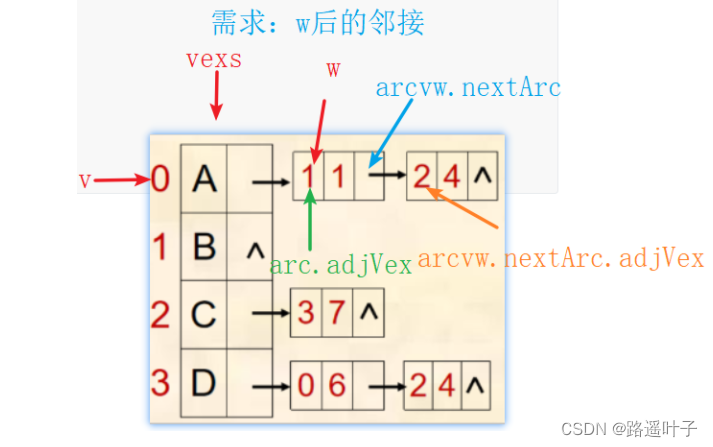
public int nextAdjVex(int v, int w) throws Exception {
if (v < 0 || v >= vexNum)
throw new Exception("第" + v + "个顶点不存在!");
VNode vex = vexs[v];
ArcNode arcvw = null;
// 获得w结点在链表中所在的位置
for (ArcNode arc = vex.firstArc; arc != null; arc = arc.nextArc)
if (arc.adjVex == w) {
arcvw = arc;
break;
}
// 返回w的下一个邻接点
if (arcvw != null && arcvw.nextArc != null)
return arcvw.nextArc.adjVex;
else
return -1;
}小试牛刀
回顾前一章节,我们一起学习了图的邻接矩阵和邻接表。下面我们来练习练习,给出下图,试着画出图对应的邻接表和邻接矩阵吧!检验一下学习成果。
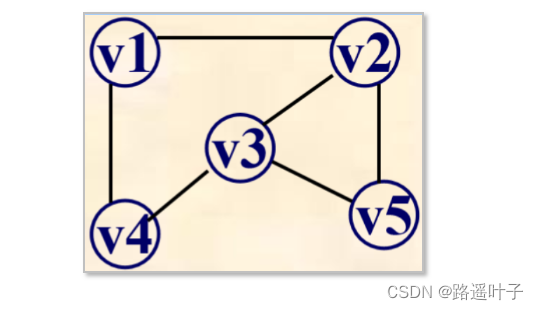
?你学会了吗?快来对对答案吧!
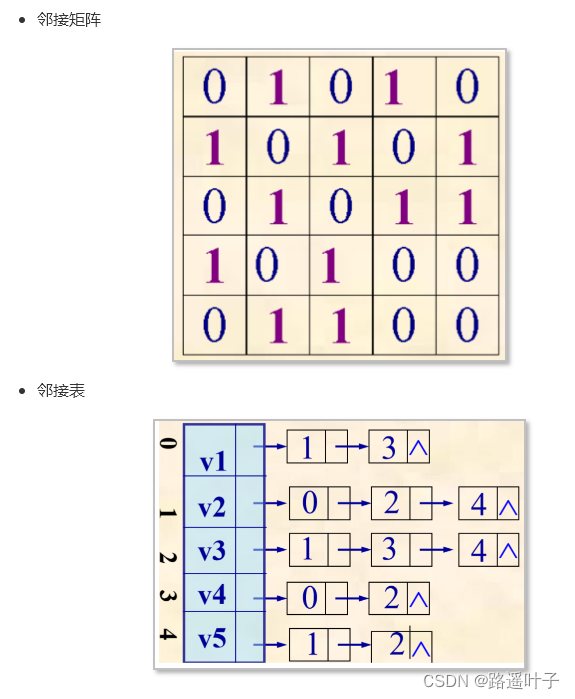
对比邻接表与邻接矩阵
1、对于稀疏图,邻接表比邻接矩阵更节省存储空间。
邻接表的空间使用与图中的边和顶点的数量成正比,而对于以这种方式存储的邻接矩阵,其空间与顶点数的平方成正比。然而,通过使用由顶点对索引的哈希表而不是数组,可以更有效地存储邻接矩阵的空间,从而匹配邻接表的线性空间使用。
2、邻接表上很容易找到任意一个顶点的邻接点和 ,但若要判定任意两个邻接点是否有边相连,则需遍历单链表,不如邻接矩阵方便。
3、邻接表和邻接矩阵之间的另一个显著区别是它们执行操作的效率。
在邻接表中,每个顶点的邻居可以有效地列出,在时间上与顶点的程度成正比。在邻接矩阵中,这个操作需要的时间与图中顶点的数量成正比,而顶点的数量可能明显高于度。此外,邻接矩阵允许测试两个顶点是否在固定的时间内彼此相邻;邻接表支持这一操作的速度较慢。
不同的数据结构也有着不同的操作。在邻接表中找到与给定顶点相邻的所有顶点就像读取邻接表一样简单。对于邻接矩阵,必须扫描整行,这就需要花费时间。
写到最后
四季轮换,已经数不清凋零了多少, 愿我们往后能向心而行,一路招摇胜!
🐋 你的支持认可是我创作的动力
💟 创作不易,不妨点赞💚评论??收藏💙一下
😘 感谢大佬们的支持,欢迎各位前来不吝赐教
想要了解更多吗?没时间解释了,快来点一点!
路遥叶子的博客_CSDN博客-数据结构,安利Java零基础,spring领域博主![]() https://blog.csdn.net/zsy3757486?spm=1010.2135.3001.5343
https://blog.csdn.net/zsy3757486?spm=1010.2135.3001.5343