ЧАЧщЬсвЊ:
? ?
innodbв§ЧцЖдгкДХХЬЖСаДЕФзюаЁЕЅЮЛЮЊвГ,УПвГЮЊ16kb(ЕЋЪЧЮФМўЯЕЭГЕФвЛвГЮЊ4kb,Ыљвдinnodbв§ЧцашвЊаД4ДЮЮФМўЯЕЭГ,ет4ДЮВйзїВЛЪЧдзгадЕФ)
вЛЁЂШЋОжНсЙЙЭМ
ЖўЁЂФкДцВПЗж
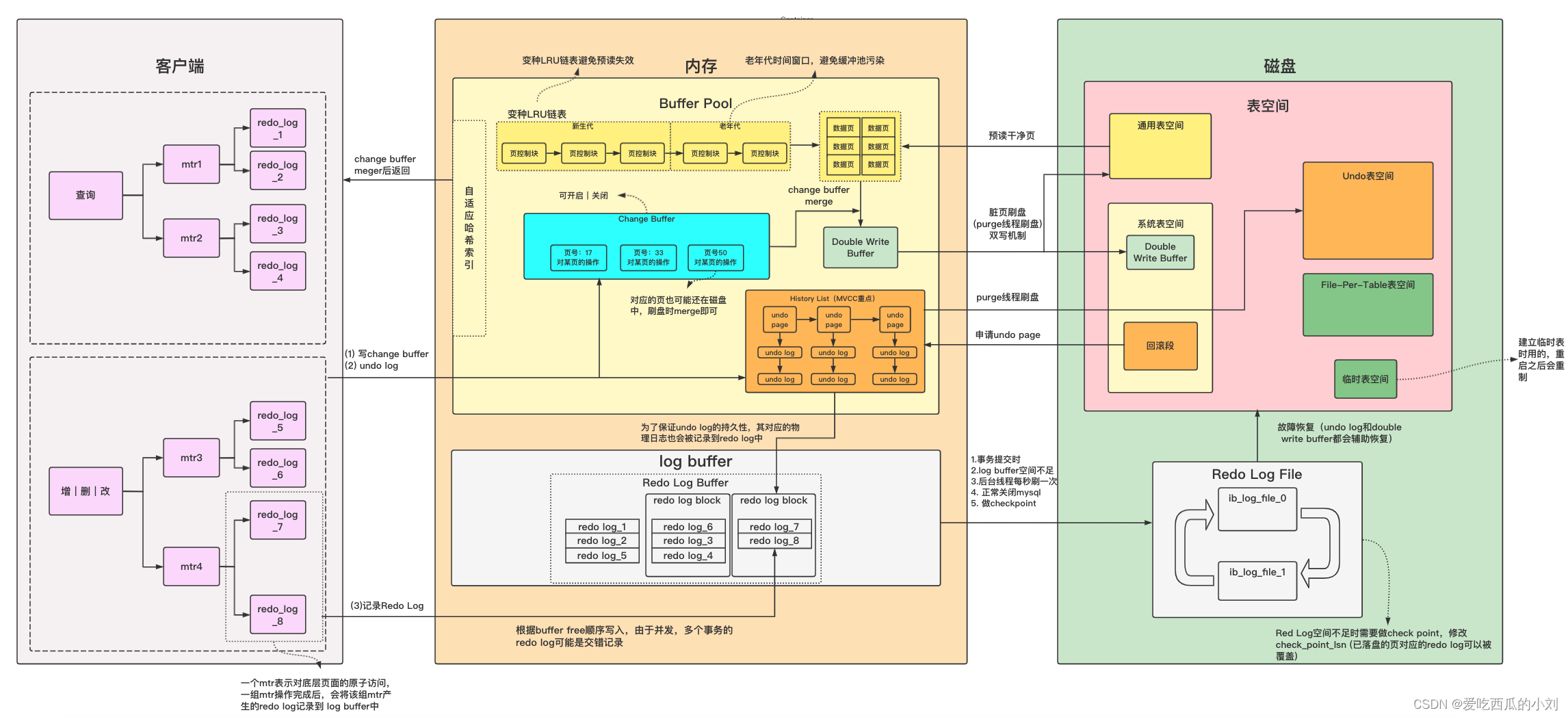
(1)Buffer Pool
(1)в§Шыдвђ
? ? ? ? ? ЖдгкInnodbРДЫЕ,длУЧНЈЕФБэвдМАРяУцДцДЂЕФМЧТМЕШЦфЫћЕФвЛаЉаХЯЂЖМЪЧГжОУЛЏДцДЂдкДХХЬЩЯУцЕФ,вВОЭЪЧЫЕдкЖСаДЕФЕФЙ§ГЬжаПЯЖЈЪЧШЦВЛЙ§ЖдДХХЬЕФЖСаДЕФ,ВЛЭЌБэжаЕФМЧТМПЩФмгжВЛЪЧДцДЂдкЭЌвЛПщЧјгђЕФ,ШчЙћЮвУЧвЊЖдЗжВМдкЖрИіДХХЬЧјгђЕФМЧТМНјааИќаТКЭВщбЏЪБ,ОЭЪєгкЪЧЫцЛњЖСаД,ДХХЬЕФЫцЛњЖСаДЯћКФЯрЖдРДЫЕЛЙЪЧЭІДѓЕФ,InnodbдкЩшМЦЕФЪБКђОЭПМТЧЕНСЫ,ЫљвдЫћдкФкДцжаЙЙНЈСЫвЛИіЛКГхЧј(Buffer Pool)РДЛКНтЫцЛњЖСаДДХХЬЕФбЙСІЁЃИФЖЏЕФЪБКђЯШАДвГЮЊЕЅЮЛ(16KB)НЋЪ§ОнМгдиЕНФкДцжа,БШШчФувЊВщбЏЕФМЧТМдквГКХЮЊ50ЕФЪ§ОнвГжа,ЮЊСЫБмУтКѓајВйзїПЩФмЛсгУЕНИУЪ§ОнвГИННќЕФЪ§ОнвГ,InnodbжБНгЭЈЙ§дЄЖС,НЋвГКХЮЊ50ЕФЪ§ОнвГжмЮЇЕФЪ§ОнвГЭЈЙ§вьВНЕФЗНЪНМгдиЕНbuffer poolжаЁЃКѓајжБНгдкФкДцжаНјааЖСШЁЛђепаДШыВйзї,ЕШЕНБивЊЕФЪБКђдйЫЂШыДХХЬМДПЩЁЃ
зЂ:innodbв§ШыСЫbuffer poolжЎЭтЛЙИуСЫКмЖрЖдДХХЬI/OЕФгХЛЏ,дЄЖСОЭЪЧЦфжаЕФвЛИі
??БфжжLRUСДБэ
в§Шыдвђ:
?? ? ? ЕБЧыЧѓБфЖрСЫжЎКѓ,МгдиЕНbuffer poolЕФЪ§ОнвГПЯЖЈЪЧдНРДдНЖрЕФ,innodbОЭЬсЙЉСЫвЛжжЬдЬЫуЗЈРДЬдЬЪ§ОнвГ,БЛЬдЬЕФЪ§ОнвГЛсБЛЫЂШыДХХЬжаЁЃетжжЫуЗЈКЭДЋЭГЕФLRUКмЯё
?ДЋЭГLRUЫуЗЈдРэ:
?? ? ? ? МйШчСДБэЙЬЖЈГЄЖШЮЊ3,ВЂЧвСДБэжаЕФдЊЫиЪЧЮЈвЛЕФ,ЕБСДБэдЊЫиИіЪ§ДяЕН3ЪБ(3->2->1),ДЫЪБЕкЫФИідЊЫиВхШы,ШчЙћСДБэжавбОДцдкИУдЊЫи,дђАбСДБэжаЕФИУдЊЫиЗХдкСДБэЭЗВП(1ВхШы3->2->1,БфГЩ1->3->2),ШчЙћСДБэжаВЛДцдкИУдЊЫи,дђзюКѓвЛИідЊЫиБЛЬоГ§СДБэ,аТдЊЫиВхШыЭЗВП(4ВхШы3->2->1,БфГЩ4->3->2,1БЛЬоГ§)
?ШчЙћНЋДЋЭГLRUЫуЗЈв§ШыЕНInnodbРяУцЛсВњЩњЪВУДЮЪЬтФи?
??дЄЖСЪЇаЇ:????????гЩгкдЄЖСЛсЬсЧААбвГЗХШыСЫЛКГхГи,ЕЋзюжеетаЉдЄЖСвГЖМУЛгаБЛВйзїОЭБЛЬдЬСЫ,ГЦЮЊдЄЖСЪЇаЇЁЃ
??ЛКГхГиЮлШО:
????????гЩгкдЄЖСашвЊМгдиКмЖрЪ§ОнвГЕНСДБэжа,ЖјетаЉаТНјРДЕФФЧаЉдЄЖСвГПЩФмИљБОгУВЛЩЯ,ВЂЧвСДБэжаОГЃЗУЮЪЕФШШЪ§ОнвГжБНгОЭБЛетаЉЮогУЕФдЄЖСвГЬцЛЛЕєСЫЁЃ
???НтОіАьЗЈ:
????????НЋLRUСДБэЗжЮЊСНЖЮ,вЛЖЮЮЊФъЧсДњ,вЛЖЮЮЊРЯФъДњ,ВЂЧвдкРЯФъДњЩшжУЪБМфДАПк,ЮвУЧжЎКѓОЭГЦжЎЮЊБфжжLRUЫуЗЈ(ЦфЪЕredisвВВЩгУСЫздМКЩшМЦЕФLRUЫуЗЈРДЬдЬkey,ИааЫШЄЕФПЩвдШЅСЫНтвЛЯТ)
БфжжLRUЫуЗЈдРэ:
НЋLRUСДБэАДБШР§ЗжЮЊ2ИіВПЗж,МйЩшАДШШЕуЪ§ОнвГвВОЭЪЧеце§БЛЗУЮЪЕФЪ§ОнвГеМ70%,дЄЖСвГеМ30%,вдетИіБШР§РДНЋСДБэЗжЮЊ2ИіВПЗжЁЃ
дрЪ§ОнШчКЮБЛЬдЬ?
етИіЕШЮвУЧНВЭъЯТУцЕФredo logдйвЛЦ№ЫЕ
ВЮПМСДНг:https://blog.csdn.net/shenjian58/article/details/93268633
??Change Buffer
?
ИќаТЪ§ОнЪБ,ЮвУЧФмЯыЕНЕФВйзївЛАуЪЧетбљЕФ:
??ЩцМАЕФЪ§ОнвГвбОБЛМгдиЕНBuffer Poolжа:
?? ? (1)дђжБНгдкBuffer PoolжаИќаТ(ФкДцВйзї)
? ? (2)ЯШМЧТМredo logдкФкДцжа,ЪТЮёЬсНЛКѓЫЂШыДХХЬ(вЛДЮФкДцаДШы+вЛДЮДХХЬЫГађаДШы,аДШыДХХЬЕФетДЮВйзїЪЧЫГађаДШы,КѓУцЛсЫЕ)
??ЩцМАЕФЪ§ОнвГУЛгаБЛМгдиЕНBuffer Poolжа:
?? ? (1)ШЅДХХЬжаАбИУЪ§ОнвГКЭдЄЖСвГМгдиЕНBuffer Poolжа
? ? (2)ШЛКѓдкBuffer PoolжаНјааИќаТВйзї,
? ? (3)МЧТМredo log(вЛДЮФкДцаДШы+вЛДЮДХХЬЫГађаДШы)
етбљПДЦ№РДЪЧУЛЪВУДЮЪЬт,ФузаЯИЯыЯыШчЙћЮвУЧИќаТСЫжЎКѓВЂУЛгаФЧУДМАЪБШЅЗУЮЪетИіЪ§ОнвГжаЕФЪ§Он(аДЖрЖСЩйЕФГЁОА),ФЧУДЮвУЧЪЧВЛЪЧПЩвдЯШМЧТМвЛЯТетДЮаоИФВйзї,ЕШЕНвЊЗУЮЪетИіЪ§ОнвГЕФЪБКђ,дйНЋетДЮаоИФВйзїКЭЪ§ОнвГКЯВЂ,етИіКЯВЂВйзїЮвУЧГЦжЎЮЊmergeЁЃгЩДЫв§ГіСЫChange Buffer(жЎЧАНаInsert Buffer),Change BufferжївЊЪЧЮЊСЫМѕЩйаДВйзїЕФДХХЬIO
??в§ШыChange BufferКѓ,ЩцМАЕФЪ§ОнвГУЛгаБЛМгдиЕНBuffer Poolжа:
?? ?? (1)ЯШНЋаоИФВйзїМЧТМдкChange Bufferжа
? ?? (2)МЧТМredo log
ВњЩњmergeЕФГЁОА:
?????????? ЖСШЁBuffer PoolжаВЛДцдкЕФЪ§ОнвГ,ЕЋЪЧChange BufferжаАќКЌИУЪ§ОнвГЕФаоИФМЧТМ
?????????? КѓЬЈЯпГЬ,ШЯЮЊЪ§ОнПтПеЯаЪБ
?????????? Buffer PoolВЛЙЛгУЪБ
?????????? Ъ§ОнПте§ГЃЙиБеЪБ
?????????? redo logаДТњЪБ
ЪЪКЯв§ШыChange BufferЕФГЁОА:
?????????? Ъ§ОнПтДѓВПЗжЪЧЗЧЮЈвЛЫїв§
?????????? вЕЮёЪЧаДЖрЖСЩй,ЛђепВЛЪЧаДКѓСЂПЬЖСШЁПЩвдЪЙгУаДЛКГх,НЋдБОУПДЮаДШыЖМашвЊНјааДХХЬIOЕФSQL,гХЛЏЖЈЦкХњСПаДДХХЬЁЃР§Шч,еЫЕЅСїЫЎвЕЮё
ВЛЪЪКЯв§ШыChange BufferЕФГЁОА:
??????????? Ъ§ОнПтДѓВПЗжЪБЮЈвЛЫїв§(ШчЙћаоИФЕФВПЗжЩцМАЕНЮЈвЛЫїв§,ашвЊШЅДХХЬжаНјаавЛаЉХаЖЯРДБЃжЄЫїв§ЕФЮЈвЛад)
?????????? аДШывЛИіЪ§ОнКѓ,ЛсСЂПЬЖСШЁЫќ(ЖСЖраДЩйЕФГЁОА)
ЯрЙиХфжУ:
innodb_change_buffer_max_size:
?? ? ? ? НщЩм:ХфжУаДЛКГхЕФДѓаЁ,еМећИіЛКГхГиЕФБШР§,ФЌШЯжЕЪЧ25%,зюДѓжЕЪЧ50%ЁЃ(аДЖрЖСЩйЕФвЕЮё,ВХашвЊЕїДѓетИіжЕ,ЖСЖраДЩйЕФвЕЮё,25%ЦфЪЕвВЖрСЫ)
innodb_change_buffering:
?? ? ?? НщЩм:ХфжУФФаЉаДВйзїЦєгУаДЛКГх,ПЩвдЩшжУГЩall/none/inserts/deletesЕШЁЃ(етИівВКУРэНт,ОЭЪЧМћУћжЊвт,ШчЙћжЛХфжУГЩinserts,ФЧОЭжЛЖдINSERTВйзїЩњаЇ,вдДЫРрЭЦ)
Change BufferВЛЛсВњЩњЪ§ОнЖЊЪЇЕФдвђ:
?????????? МЧТМChange BufferжЎЧАЛсМЧТМredo log
?????????? аДЛКГхВЛжЛЪЧвЛИіФкДцНсЙЙ,ЫќвВЛсБЛЖЈЦкЫЂХЬЕНаДЛКГхЯЕЭГБэПеМф
ВЮПМСДНг:https://blog.csdn.net/shenjian58/article/details/93691224
??Double Write Buffer
?
в§Шыдвђ
? ? ? ? ?Buffer PoolжаЕФЪ§ОнвГПЯЖЈВЛПЩФмвЛжБЗХдкФкДцжа,ЕБТњзувЛаЉДЅЗЂЬѕМўЪБ,етаЉЛКДцвГНЋЛсЫЂШыДХХЬжа,Р§Шче§ГЃЙиБеЗўЮёЕФЪБКђ,ЛђепLRUСДБэЬдЬЪ§ОнвГЕФЪБКђЁЃMySQLЕФBuffer PoolжавЛвГЕФДѓаЁЪЧ16K,ЮФМўЯЕЭГвЛвГЕФДѓаЁЪЧ4K,вВОЭЪЧЫЕ,MySQLНЋBuffer PoolжавЛвГЪ§ОнЫЂШыДХХЬ,вЊаД4ИіЮФМўЯЕЭГРяЕФвГ,ЕЋЪЧет4ВНВЂВЛЪЧдзгадЕФ,ПЩФмЫЂШыЦфжа2ИіОЭЪЇАмСЫ,ФЧетвГЪ§ОнВЛОЭВЛЭъећСЫ?ФуПЩФмЯыЕН,ВЛЪЧгаredo logТ№,жБНгДгredo logЛжИДВЛОЭКУСЫ,ЗЧГЃвХКЖ,redo logжаМЧТМЕФЪЧИУвГБЛаоИФЕФВПЗж,ВЂВЛЪЧвЛећвГЪ§ОнвГЕФИББО,ЫљвдЖдгкетжжШБЪЇвГ,redo logвВЮоФмЮЊСІ,ЮЊДЫInnoDBв§ШыСЫ ЫЋаДЛКДцЧј(Double Write Buffer)ЁЃ
Double Write BufferдѕУДНтОіШБЪЇвГЮЪЬтЕФ
Buffer PoolжаЕФЪ§ОнвГЫЂШыДХХЬЪБ,ВЛжБНгЫЂШыДХХЬ:
?(1)ЯШНЋЪ§ОнвГmemcopyНјФкДцжаЕФDouble Write Bufferжа
(2)ФкДцжаЕФDouble Write BufferНЋЪ§ОнвГЫЂЕНЯЕЭГБэПеМфжаЕФDouble Write BufferДХХЬЧјгђ
(3)ФкДцжаЕФDouble Write BufferНЋЪ§ОнвГЫЂЕНДцДЂИУвГЕФЭЈгУБэПеМфжа,вВОЭЪЧЦфдРДдкДХХЬжаДцДЂЕФЮЛжУ
зЂ:(2)(3)ВНЪЧДгФкДц"ЯШ"аДШыДХХЬжаЕФЯЕЭГБэПеМфжа,"Кѓ"аДШыЭЈгУБэПеМфжа,гЩДЫЕУГі"ЫЋаД",
? МйШч(1)ЙЪеЯ,ФЧУДДЫЪБДХХЬжаЕФЭЈгУБэПеМфРяУцЕФЪ§ОнвГЪЧЭъећЕФ,жБНггУredo logЛжИДМДПЩ
? МйШч(2)ЙЪеЯ,ДЫЪБДХХЬжаЕФЭЈгУБэПеМфРяУцЕФЪ§ОнвГвВЪЧЭъећЕФ,жБНггУredo logЛжИДМДПЩ
? МйШч(3)ЙЪеЯ,ДЫЪБДХХЬжаЕФЭЈгУБэПеМфРяУцЕФЪ§ОнвГВЛЭъећСЫ,redo logЮоЗЈжБНгЛжИД,ЕЋЪЧВНжш(2)вбОЭъГЩ,ЫљвдДЫЪБЯЕЭГБэПеМфжаЕФDouble Write BufferжагаЭъећЕФЪ§ОнвГ,жБНгДгЯЕЭГБэПеМфРяУцЛжИДМДПЩЁЃ
ЯрЙиУќСю
ВщПДDouble Write BufferЕФЪЙгУЧщПі:show global status like "%dblwr%"
змНс:
(1)ВЛЪЧвЛИіФкДцbuffer,ЪЧвЛИіФкДц/ДХХЬСНВуЕФНсЙЙ,ЪЧInnoDBРяOn-DiskМмЙЙРяКмживЊЕФвЛВПЗж;
(2)ЪЧвЛИіЭЈЙ§аДСНДЮ,БЃжЄвГЭъећадЕФЛњжЦ;
(3)дквьГЃБРРЃЪБ,ШчЙћВЛГіЯжЁАвГЪ§ОнЫ№ЛЕЁБ,ФмЙЛЭЈЙ§redoЛжИДЪ§Он;
(4)дкГіЯжЁАвГЪ§ОнЫ№ЛЕЁБЪБ,ФмЙЛЭЈЙ§double write bufferЛжИДвГЪ§Он;
ВЮПМСДНг:https://blog.csdn.net/liuxiao723846/article/details/103509226
??здЪЪгІЫїв§
?
в§Шыдвђ:
InnodbДцДЂв§ЧцЛсМрПиЖдБэЩЯЖўМЖЫїв§ЕФВщев,ШчЙћЗЂЯжФГЖўМЖЫїв§БЛЦЕЗБЗУЮЪ,ЖўМЖЫїв§ГЩЮЊШШЪ§Он,НЈСЂЙўЯЃЫїв§ПЩвдДјРДВщбЏЫйЖШЕФЬсЩ§,
зЂ:ЪщЩЯвВУЛЯъЯИЫЕ,СЫНтвЛЯТОЭКУ,ЪЧЗёНЈСЂетИіЫїв§ВЛЪЧЮвУЧФмПижЦЕФ,ЪЧinnodbздМКШЅМрПиЕФ,ВЛЙ§етИіКЭDouble Write BufferвдМАChange BufferЭГГЦЮЊInnodb Ш§ДѓЬиадЁЃ
??History List
?
в§Шыдвђ:
УПДЮИќаТЁЂЩОГ§ЁЂВхШыЕФundo logЖМЛсЯШаДШыЕНHistory ListжаЬсЙЉЪТЮёЕФMVCCЛњжЦ,етРяОЭВЛЯИЫЕСЫ,MVCCжаУПааЪ§ОнЕФРњЪЗАцБОЖМДцДЂдкетИіHistory Listжа,History ListжаЕФУПИіНкЕуЮЊundo page,undo pageПЩвдРэНтЮЊзАundo logЕФвГ,УПИіundo pageжаЕФundo logгжЭЈЙ§СДБэСЌНгЁЃетбљЕФЛА,ЛюдОЕФЪТЮёШчЙћвЊЛиЙідђжБНгПЩвдЭЈЙ§ВщбЏетИіHistory ListРДевЕНвЊЛиЭЫЕФundo log(ЛюдОЕФЪТЮёжИЕФЪЧЛЙЮДЬсНЛЕФЪТЮё,ВЛЛюдОЕФЪТЮёвВОЭЪЧвбОЬсНЛЕФЪТЮё)
History ListжаЕФundo logЖрОУЫЂШыДХХЬЁЊpurgeЛњжЦ:
ФкДцПеМфЪЧгаЯоЕФ,ПЯЖЈЕУгавЛЖЈЕФЙцдђРДЪЭЗХHistory ListжавбОЁАгУВЛЕНЁБЕФundo log,ЪВУДНазігУВЛЕНФи?вВОЭЪЧЕБЧАЛюдОЪТЮёжа,ВЛгУЬсЙЉMVCCЕФundo logЁЃInnodbЬсЙЉСЫpurgeЛњжЦРДНЋетаЉУЛгУЕФundo logЫЂЕНundo logБэПеМфжа,ЦфБОжЪОЭЪЧЦ№вЛИівьВНЯпГЬРДБщРњHistory List,ШЛКѓНЋУЛгУЕФundo logЫЂШыДХХЬЁЃ
ШЋОжЖЏЬЌВЮЪ§innodb_purge_batch_sizeгУРДЩшжУУПДЮpurgeВйзїашвЊЧхРэЕФundo pageЪ§СПЁЃФЌШЯжЕЮЊ300 ШЋОжЖЏЬЌВЮЪ§innodb_max_purge_lagгУРДПижЦhistory listЕФГЄЖШ,ШєДѓгкИУВЮЪ§ЪБ,ЦфЛсбгЛКDMLЕФВйзї ШЋОжЖЏЬЌВЮЪ§innodb_max_purge_lag_delay,гУРДПижЦDMLВйзїУПааЪ§ОнЕФзюДѓбгЛКЪБМф,ЕЅЮЛЮЊКСУыЁЃ
?History ListжаЕФundo logШчКЮБЃжЄЦфВЛЖЊЪЇ:
ДгpurgeЛњжЦЕУжЊ,undo logВЂВЛЪЧЪЕЪБЫЂШыДХХЬЕФ,ЖјЧвЬсЙЉMVCCЕФundo logвВЪЧУЛгаСЂМДБЛЫЂЕНДХХЬЩЯЕФ,ФЧУДШчЙћхДЛњСЫ,етаЉundo logВЛОЭЖЊЪЇСЫ?ЮЊДЫ,innodbдчОЭЯыЕНСЫ,ЫќдкBuffer PoolжаМЧТМundo logжЎЧАЛсЯШНЋundo logАДredo logЕФаЮЪНМЧТМГЩredo log,ВЂЧвЪТЮёЕФЛиЭЫВйзївВЛсМЧТМГЩredo log,ШЛКѓЫцзХredo logЕФЫЂХЬВпТдЫЂШыДХХЬжаЁЃетбљЪ§ОнЛжИДЕФЪБКђжБНггУredo logРДЛжИДМДПЩ,ЯШгУredo logЛжИД,ШЛКѓгУМЧТМСЫundo logЛиЭЫВйзїЕФredo logЛиЭЫЁЃ
undo logШчКЮЖдЪТЮёНјааЛиЙі
дкHistory ListжаевЕНашвЊЛиЙіЕФundo log,ШЛКѓЛжИДЕНетИіundo logМЧТМЕФжЕ,ВЂЧвНЋетИіundo logМЧТМЮЊПЩЩОГ§зДЬЌ,ЕШЕНHistory ListжаЕФundo logЫЂХЬЕФЪБКђОЭЛсНЋетаЉБЛБъМЧСЫПЩЩОГ§зДЬЌЕФundo logЮяРэЩОГ§ЕєЁЃ
зЂ:ЦфЪЕКмгаКмЖрЯИНкУЛНВ,БШШчundo logЕФЗжРр,undo pageЕФжигУ,ДѓРаУЧздааАйЖШвЛЯТ
(2)Log Buffer
??Redo Log Buffer
?
ЧАУцжЊЪЖЕуЕФДЎСЊ:
ЧАУцЮвУЧжЊЕР,ЕБвЛИіаДВйзїРДСЫжЎКѓ,ЛсдкBuffer PoolжаМЧТМЯргІЕФundo log,Change BufferвдМАаоИФЛКДцвГ,ШЛКѓЛЙвЊПДЪЧЗёашвЊдкLRUСДБэжаЬдЬЛКДцвГ,ашвЊЬдЬЕФЛАОЭЕУЯШАбЬдЬвГМЧТМЕНDouble Write Bufferжа,ШЛКѓЭЈЙ§purgeЯпГЬЫЋаДЕНДХХЬжаЕФЯЕЭГБэПеМфРяЕФDouble Write BufferЧјгђвдМАЭЈгУБэПеМфжа,ШЛКѓЛсгУpurgeЛњжЦЖЈЦкЧхРэУЛгаЬсЙЉMVCCЛњжЦЕФHistotyжаЕФundo log,InnodbЛсИљОнЖўМЖЫїв§ЛКДцвГЕФЗУЮЪЦЕТЪЕШвЛаЉвђЫиРДОіЖЈЪЧЗёдкBuffer PoolжаНЈСЂздЪЪгІЫїв§РДЬсИпШШЕуЖўМЖЫїв§ЛКДцвГЕФВщбЏаЇТЪ,вдЩЯетаЉЖМЪЧBuffer PoolжаЕФЙЄзї,дкФкДцжаЛЙгавЛИіБШНЯживЊЕФЧјгђ,ЫќВЛдкBuffer PoolжаЖјЪЧдкФкДцжаСэЭтЗжХфСЫПщПеМф,вВОЭЪЧRedo Log Buffer,ЦфЪЧгУРДМЧТМredo logЕФЁЃ
ЪВУДЪЧredo log?
вЛИіЪТЮёЛсАќКЌаэЖрSQL,ЖјвЛЬѕSQLаоИФгяОф,ЛсВњЩњ"КмЖрзщredo log"ОЭ,Жјет"вЛзщredo log"ГЦЮЊmtr(Mini-Transaction)ЪЧаДШыЕФзюаЁЕЅдЊ,БШШчupdate age = 5? from A where id > 10етЬѕsql,ШчЙћAБэжаДцдкТњзуid > 10ЕФЖрЬѕМЧТМ,ФЧаоИФвЛЬѕМЧТМОЭПЩвдПДГЩвЛЬѕredo log,ФуаоИФПЯЖЈЕУАбЫљгаТњзуid > 10етИіЬѕМўЕФМЧТМЖМаоИФСЫВХЪЧдзгадЕФ,етОЭЪЧвЛИіmtrЪЧвЛзщredo logЕФгЩРД,вЛИіredo logМЧТМЕФОЭЪЧдкДХХЬЕФФФИіЮЛжУ,аоИФСЫЪВУДЖЋЮїЁЃЖдгІЙиЯЕОЭЪЧ:
"вЛИіЪТЮё"ЁЊЁЊ>"ЖрЬѕsqlгяОф"
"вЛЬѕsqlгяОф"ЁЊЁЊ>"ЖрЬѕmtr"
"вЛЬѕmtr"ЁЊЁЊ>"ЖрИіredo log"
"вЛИіredo log" ЁЊЁЊ>"АбБэПеМфxЁЂвГКХyЁЂЦЋвЦСПЮЊzДІЕФжЕИќаТЮЊn"
redo logаДШыЕНredo log bufferЕФЙ§ГЬ
ЮЊСЫНтОіЪ§ОнЫцЛњЖСаДДХХЬЫйЖШЙ§Т§ЕФЮЪЬтЖјв§ШыСЫ Buffer Pool ЁЃЭЌРэ,аДШы redo logЪБвВВЛФмжБНгжБНгаДЕНДХХЬЩЯ,ЪЕМЪЩЯдкЗўЮёЦїЦєЖЏЪБОЭЯђВйзїЯЕЭГЩъЧыСЫвЛДѓЦЌГЦжЎЮЊ redo log buffer ЕФСЌајФкДцПеМф,ЗвыГЩжаЮФОЭЪЧ redoШежОЛКГхЧј ,ЮвУЧвВПЩвдМђГЦЮЊ log buffer ЁЃетЦЌФкДцПеМфБЛЛЎЗжГЩШєИЩИіСЌајЕФredo log block,ШЛКѓinnodbЮЌЛЄСЫИіШЋОжЦЋвЦСП,вВОЭЪЧbuffer free,БэЪОаТЕФredo logвЊаДШыredo log bufferжаФФПщredo log blockжаЕФФФИіЮЛжУ,УПИіmtrЕФжДааЙ§ГЬжа,ЯШНЋЦфЖдгІЕФЖрИіredo logаДШыЕНФкДцжаЕФФГИіЕиЗН,ШЛКѓЕБИУmtrжДааЭъГЩКѓдйвЛДЮадаДШыЕНredo log bufferжаЁЃгЩгкВЛвЛЖЈжЛгавЛИіЪТЮёдкжДаа,Ыљвдredo logЪЧВЂЗЂаДШыЕНredo log bufferжаЕФ,УПИіЪТЮёЖдгІЕФЖрИіredo logВЛвЛЖЈЪЧСЌајЕФ,ПЩФмЪЧНЛДэЕФЁЃ
redo logЫЂХЬЪБЛњ
(1)ЬсНЛЪТЮёКѓОЭЫЂХЬ,ЫЂШыЕФЮЛжУгЩinnodb_flush_log_at_trx_commitОіЖЈ:
??????????? innodb_flush_log_at_trx_commit=0 :
????????????????БэЪОУПДЮЪТЮёЬсНЛЪБЖМжЛЪЧАб redo log Сєдк redo log buffer жа ,ЕШД§вьВНЯпГЬШЅЫЂХЬ;
??????????? innodb_flush_log_at_trx_commit=1:
????????????????БэЪОУПДЮЪТЮёЬсНЛЪБЖМНЋ redo log жБНгГжОУЛЏЕНДХХЬ;
??????????? innodb_flush_log_at_trx_commit=2:
????????????????БэЪОУПДЮЪТЮёЬсНЛЪБЖМжЛЪЧАб redo log аДЕН page cache,page cacheЪЧДХХЬКЭФкДцжЎМфЕФвЛПщЛКГхЧј,ЫќВЂВЛЪЧГжОУЛЏЕФ,ЫцзХЯЕЭГвьГЃЙиБеЪБЦфЛсЖЊЪЇЁЃ
(2)ЖЈЪБДІРэ:
?????????innodb_flush_log_at_timeoutХфжУЖЈЪБЫЂХЬ,ХфжУжЎКѓгаЯпГЬЛсЖЈЪБ(ФЌШЯУПИє 1 Уы)Абredo log bufferжаЕФЪ§ОнЫЂХЬ,ВЂЧвашвЊзЂвт,ХфжУетИіЯюКѓ,ЪТЮёЬсНЛжЎКѓВЂВЛЛсТэЩЯДЅЗЂЫЂХЬ,ЖјЪЧашвЊЕШетИіЯпГЬШЅЫЂЁЃ
(3)ИљОнПеМфДІРэ:
?????????redo log buffer еМгУЕНСЫвЛЖЈГЬЖШ( innodb_log_buffer_size ЩшжУЕФжЕвЛАы)еМ,етИіЪБКђвВЛсАбredo log bufferжаЕФЪ§ОнЫЂХЬЁЃ
redo logЫЂХЬЙ§ГЬ:
?????????ИљОнЩЯУцЕФЫЂХЬЛњжЦ,redo log bufferжаЕФredo logзюжеЛсБЛЫЂШыЕНДХХЬжаInnodbЗжХфЕНЕФвЛПщНаRedo Log FileЕФЧјгђ,ШЛКѓФЌШЯЧщПіЯТ,ЛсгУ2ИіЮФМўРДзАетаЉredo log,вЛПЊЪМЛсЯШДгЕквЛИіЮФМў(ib_logfile_1)ПЊЪМаД,аДТњСЫОЭЛЛЕкЖўИіЮФМў(ib_logfile_2)РДаД,ЕкЖўИіЮФМўаДТњСЫОЭЧхРэвЛВПЗжЕквЛИіЮФМўЕФПеМф,ШЛКѓМЬајаДШыЕквЛИіЮФМў,етИіЧхРэЕФЛњжЦНазіcheckpoint ЁЃ
checkpointЛњжЦ:
?? ЮЊЪВУДашвЊcheckpoint:
Redo Log FileжаЕФПеМфВЂВЛЪЧЮоЯоЕФ,ЕБ2Иіib_logfileМЧТМТњСЫжЎКѓ,ашвЊЛиЕНЕквЛИіib_logfileПЊЪММЧТМ,ФЧУДib_logfile_1ОЭашвЊЬкГівЛВПЗжПеМфРДзАетаЉаТЕФredo log,ФЧУДФФаЉredo logПЩвдБЛ"ЬкГіРД"Фи,дкетжЎЧАЮвУЧашвЊжЊЕРredo logЪЧЮЊСЫБЃжЄbuffer poolжаЕФдрвГЕФГжОУадЖјДцдкЕФ,вВОЭЪЧЫЕbuffer poolЕФLRUСДБэжаЕФЪ§ОнвГЛЙУЛРДЕУМАБЛЫЂаТЕНДХХЬжаЪБ,ЛњЦїОЭхДЛњСЫ,ФЧУДетаЉЪ§ОнвГдкbuffer poolжаБЛаоИФЕФВПЗжОЭЖЊЪЇСЫ,ДЫЪБОЭашвЊгУredo logРДЛжИДЁЃДЫЪБЛиД№жЎЧАЕФФЧИіЮЪЬт,ЪВУДбљЕФredo logПЩвдБЛЬкГіРДФи,вВОЭЪЧBuffer PoolжавбОБЛЫЂЕНДХХЬЕФЪ§ОнвГЖдгІЕФredo logПЩвдБЛЬкГіРД,вђЮЊетаЉЪ§ОнвГвбОЫЂШыДХХЬСЫвбОЕУЕНСЫГжОУЛЏЕФБЃжЄ,ВЛашвЊдйгУredo logРДЛжИДСЫЁЃ
ЩЯУцПЩвдзмНсЮЊ:ЕБRedo Log FileжаЕФ2Иіib_logfileЖМаДТњКѓ,innodbЛсХаЖЯДЫЪБет2ИіЮФМўжаФФаЉredologЖдгІЕФдрвГвбОБЛЫЂШыЕНДХХЬжаСЫ,ШЛКѓОЭжБНгАбетВПЗжЕФredo logЬдЬЕє,ЬкГіРДЕФПеМфОЭПЩвдСєИјаТЕФredo logЁЃШчЙћПеМфашЧѓБШНЯДѓ,дђЛсДгbuffer poolжаЧПжЦЫЂаТвЛаЉдрвГЕНДХХЬжа,ШЛКѓНЋЖдгІЕФredo logОЭПЩвдБЛИВИЧЁЃ
?? ЪВУДЪБКђЛсДЅЗЂcheckpoint:
(1)Ъ§ОнПте§ГЃЙиБеЪБ,дрвГЪЧашвЊЫЂЕНДХХЬЕФ,ШЋВПЫЂШыДХХЬКѓ,ЫљгаЕФredo logОЭПЩвдБЛИВИЧСЫ,МДinnodb_fast_shutdown=0ЪБашвЊжДааsharp checkpoint
(2)redo logПьТњЕФЪБКђНјааfuzzy checkpoint ,вВОЭЪЧЮвУЧЧАУцЫЕЕФЧщПі
(3)master threadУПИє1УыЛђ10УыЖЈЦкНјааfuzzy checkpoint,ЫћЛсЫЂвЛаЉдрвГЕНДХХЬжаЁЃ
(4)innodbБЃжЄгазуЙЛЖрЕФПеЯаpage,ШчЙћЗЂЯжВЛзу,ашвЊвЦГ§LRUСДБэФЉЮВЕФpage,ШчЙћетаЉpageЪЧдрвГ,ФЧУДвВашвЊfuzzy checkpoint
(5)innodb buffer poolжадрвГБШГЌЙ§innodb_max_dirty_pages_pctЪБвВЛсДЅЗЂfuzzy checkpoint
??:вдЩЯвВПЩвдРэНтЮЊ,ЪВУДЪБКђLRUСДБэжаЕФдрвГЛсБЛЫЂШыДХХЬжа,етбљОЭЛиД№СЫжЎЧАLRUВПЗжЕФЮЪЬт(дрвГЪВУДЪБКђЫЂШыДХХЬ)
Redo LogКЭBinlogЕФСННзЖЮЬсНЛ:
ЮвУЧашвЊУїШЗвЛИіЪТЧщ,MysqlЕФserverВуЬсЙЉЕФbinlogЪЧгУРДБЃжЄЪ§ОнБИЗнКЭжїДгЭЌВНЪЙгУЕФЁЃвВОЭЪЧЫЕШчЙћЪ§ОнПтЫљдкЕФЛњЦїФФЬьЙЪеЯСЫ,ФуПЩвдФУЕНbinlogШЅСэЭтЬЈЛњЦїНјааЛиЕЕ,жїДгЭЌВНвВЪЧШчДЫ,ЁЎДгЪ§ОнПтЁЏжЛашвЊНтЮіЁЎжїЪ§ОнПтЁЏЕФbinlogЕУЕНsqlгяОф,ШЛКѓжДааКѓОЭПЩвдЕУЕНжїПтЕФЫљгаЪ§ОнЁЃ
ШЛКѓДцДЂв§ЧцВуinnodbЬсЙЉЕФredo logОЭзіВЛЕНетаЉ,вђЮЊЮвУЧжЎЧАЫЕЙ§ЕБПеМфВЛзуЪБЫћЪЧЛсБЛИВИЧЕФЁЃredo logжЛЪЧinnodbгУРДЬсЙЉcrash safeЕФ,МДШчЙћMysql НјГЬвьГЃжиЦєСЫ,ЯЕЭГЛсздЖЏШЅМьВщredo log,НЋжЎЧАbuffer poolжавђЮЊНјГЬвьГЃЕМжТЕФЮДаДШыЕНДХХЬЕФЪ§ОнДгredo logЛжИДЕНДХХЬШЅЁЃ
ЩЯУцетЖЮЛАЮвжЛЪЧЯыЫЕУї,redo logКЭbinlogЪЧдкзіВЛЭЌЕФЪТЧщ,ЕЋЪЧЫќСЉЖМЩцМАЕНЪ§ОнПтЪ§ОнЕФЭъећад,ЫљвдЫћСНБЃжЄЕФЪ§ОнНјЖШБиаывЛжТЁЃЫљвдmysqlВЩгУСЫСННзЖЮЬсНЛЗНЪНРДБЃжЄетИівЊЧѓЁЃ
МйЩшredo logКЭbinlogЗжБ№ЬсНЛ,ПЩФмЛсдьГЩгУШежОЛжИДГіРДЕФЪ§ОнКЭдРДЪ§ОнВЛвЛжТЕФЧщПіЁЃ
(1)МйЩшЯШаДredo logдйаДbinlog,МДredo logУЛгаprepareНзЖЮ,аДЭъжБНгжУЮЊcommitзДЬЌ,ШЛКѓдйаДbinlogЁЃФЧУДШчЙћаДЭъredo logКѓMysqlхДЛњСЫ,жиЦєКѓЯЕЭГздЖЏгУredo log ЛжИДГіРДЕФЪ§ОнОЭЛсБШbinlogМЧТМЕФЪ§ОнЖрГівЛаЉЪ§Он,етОЭЛсдьГЩДХХЬЩЯЪ§ОнПтЪ§ОнвГКЭbinlogЕФВЛвЛжТ,ЯТДЮашвЊгУЕНbinlogЛжИДЮѓЩОЕФЪ§ОнЪБ,ОЭЛсЗЂЯжЛжИДКѓЕФЪ§ОнКЭдРДЕФЪ§ОнВЛвЛжТЁЃ
(2)МйЩшЯШаДbinlogдйаДredologЁЃШчЙћаДЭъredo logКѓMysqlхДЛњСЫ,ФЧУДbinlogЩЯЕФМЧТМОЭЛсБШДХХЬЩЯЪ§ОнвГЕФМЧТМЖрГівЛаЉЪ§ОнГіРД,ЯТДЮгУbinlogЛжИДЪ§Он,ОЭЛсЗЂЯжЛжИДКѓЕФЪ§ОнКЭдРДЕФЪ§ОнВЛвЛжТЁЃ
гЩДЫПЩМћ,redo logКЭbinlogЕФСННзЖЮЬсНЛЪЧЗЧГЃБивЊЕФЁЃ
?Redo LogШчКЮНјааЪ§ОнЛжИД
ДХХЬжаЕФЪ§ОнвГЛсЮЌЛЄвЛИіLSN(ФуПЩвдРэНтЮЊЪ§ОнНјЖШ),ШЛКѓRedo LogжавВЛсЮЌЛЄвЛИіLSN,ШчЙћДХХЬжаЪ§ОнвГЕФLSNаЁгкRedo LogЕФLSN,дђЫЕУїашвЊЛжИДЪ§Он,ОЭАбДѓгкДХХЬLSNЕФredo logЖдДХХЬжаЕФЪ§ОнвГНјааЛжИДМДПЩ
WALЛњжЦ
InnodbЬсЙЉСЫWALЛњжЦ(write ahead? log)РДЬсИпЖСаДаЇТЪ,МђЕЅРДЫЕОЭЪЧАбЖдЪ§ОнаоИФЕФВПЗжЯШЗХШыФкДцжаЕФBuffer Poolжа,ВЛМБзХТэЩЯЫЂШыДХХЬ,вђЮЊДХХЬioЪЧБШНЯТ§ЕФТя,ЖјЧвШчЙћФуаоИФСЫжЎКѓТэЩЯгжвЊВщбЏетИіЪ§Он,ФЧЦёВЛЪЧгждіМгСЫвЛДЮДХХЬioЁЃетаЉдкФкДцжааоИФВйзїЮвУЧПЯЖЈЕУБЃжЄЫќЕФГжОУад,ЮвУЧОЭВЩгУ'ЯШ'аДШыredo logЕФЗНЪНРДБЃжЄЪ§ОнГжОУад,ШЛКѓЕШЕНКѓУцашвЊЕФЪБКђ"дй"НЋФкДцжаЕФдрЪ§ОнвГЫЂШыДХХЬжаЁЃ
Ш§ЁЂДХХЬВПЗж
(1)БэПеМф
?? ЭЈгУБэПеМф
ДцЪ§ОнвГЕФДХХЬЧјгђ
?? ЯЕЭГБэПеМф
double write bufferЁЂchange bufferЁЂundo ЛиЙіЖЮ....ЕФДХХЬЧјгђ
?? UndoБэПеМф
Дцundo logЕФДХХЬЧјгђ
(2)Redo Log File
?
етИіЧјгђЪЧredo logЕФДХХЬЧјгђ,ФкДцжаRedo Log BufferЕФredo logЛсБЛЫЂШыИУЧјгђ,ОпЬхЙцдђдкЧАУцЕФRedo Log BufferвбЫЕ,етРяОЭВЛдйзИЪі
ВЮПМзЪСЯ:
? ? ? ? ЁЖMysqlЪЧШчКЮдЫааЕФ?ДгИљЖљЩЯРэНтmysqlЁЗ
????????ЁЖMysqlММЪѕФкФЛ:InnodbДцДЂв§ЧцЁЗ
? ? ? ? ? https://blog.csdn.net/shenjian58/article/details/93268633
? ? ? ? ? https://blog.csdn.net/shenjian58/article/details/93691224
? ? ? ? ? https://blog.csdn.net/liuxiao723846/article/details/103509226