һ:�㷨˼��
- Ӳ����:��ͳK-��ֵ�㷨��,ÿ������ֻ�ܴ�������������е�һ��,��֮ΪӲ���ࡣ���־���������һ������:���еĶ�����ڼ���������ĵĹ�������ͬ��,Ҳ����˵,���ڴ�����һ���������Ԫ��,�㷨�����������ֿ����ġ����ַ��䷽ʽ�ڴ���һЩ�������ݼ���(�����������ص�)��������ָ�ɲ�����
- ������:һ��������������ڶ������ľ����
ģ��K-��ֵ�㷨(FCM�㷨):����ÿ�����,����Ӧһ��ȡֵ��Χ��[0,1]����ֵ,����ʾ�ö��������ijһ���Ŀ�������һ����������������Ķ�Ӧȡֵ��Ӧ��Ϊ1���ڸ��´����ĵ�Ĺ�����,����ֵ�ͷ�ӳ���ö��������һ��Ĺ��׳̶�,���ݹ��׳̶ȵIJ�ͬ,��ӳ������������ڷ��䵽�ĸ������
FCM�㷨��K-��ֵ�㷨��Ŀ�꺯������
J m = �� k = 1 N �� j = 1 u i j m �O �O x i ? c j �O �O 2 , 1 �� m < �� J_{m}=\sum_{k=1}^{N}\sum_{j=1}u_{ij}^{m}||x_{i}-c_{j}||^{2},1\leq m <\infty Jm?=k=1��N?j=1��?uijm?�O�Oxi??cj?�O�O2,1��m<��
����
- m ( > 1 ) m(>1) m(>1):ģ��ϵ��
- N N N:������
- C C C:����������
- c j c_{j} cj?:�� j j j����������
- x i x_{i} xi?:�� i i i������
- u i j u_{ij} uij?:���� x i x_{i} xi?�Ծ������� c j c_{j} cj?��������,Ҳ�� x i x_{i} xi?���� c j c_{j} cj?�ĸ��ʡ���Ȼ�� �� j = 1 C u i j \sum\limits_{j=1}^{C}u_{ij} j=1��C?uij?=1
FCM�㷨ͨ������ u i j u_{ij} uij?�� c j c_{j} cj?�������Ż�Ŀ�꺯��
u i j = 1 �� k = 1 C ( �O �O x i ? c j �O �O �O �O x i ? c k �O �O ) 2 m ? 1 u_{ij}=\frac{1}{\sum\limits_{k=1}^{C}(\frac{||x_{i}-c_{j}||}{||x_{i}-c_{k}||})^{\frac{2}{m-1}}} uij?=k=1��C?(�O�Oxi??ck?�O�O�O�Oxi??cj?�O�O?)m?12?1?
c j = �� i = 1 N u i j m x i �� i = 1 N u i j m c_{j}=\frac{\sum\limits_{i=1}^{N}u_{ij}^{m}x_{i}}{\sum\limits_{_{i=1}}^{N}u_{ij}^{m}} cj?=i=1?��N?uijm?i=1��N?uijm?xi??
FCM�㷨����������һ������Ϊ���ε��������м���� S S E SSE SSE��ֵ,���� �� \xi ����Ԥ���趨�õ��������,�����ε��������м���� S S E SSE SSE��ֵС�ڸ�Ԥ��ֵʱ,�ж��㷨����
E ( t ) = �O �O S S E t ? S S E t ? 1 �O �O < �� E(t)=||SSE^{t}-SSE^{t-1}||<\xi E(t)=�O�OSSEt?SSEt?1�O�O<��
��:�㷨����
- ��ʼ�������Ⱦ��� U 0 U^{0} U0:���� N N N������,ָ��������Ϊ C C C,�������Ⱦ���ӦΪ N N N�� C C C
- ���ݹ�ʽ���¾������� c j c_{j} cj?
- ���ݹ�ʽ���������Ⱦ���(ע�Ᵽ�����ǰ�������Ⱦ���)
- �ж��Ƿ�����,��������ֹͣ����,��֮���ز���2
��:Pythonʵ��
import numpy as np
import copy
# ŷ�Ͼ���
def distance(data, centroid):
return np.sqrt(np.sum(np.power(data-centroid, 2)))
def fcm(data_set, m, k, eps):
example_nums = np.shape(data_set)[0] # ��������
cluster = np.zeros(example_nums)
# ��ʼ�������Ⱦ���
random_mat = np.random.rand(example_nums, k) # �����������
random_mat_sum = 1 / np.sum(random_mat, axis=1) # ��ÿһ�еĺ�
membership_mat = np.multiply(random_mat.T, random_mat_sum) # ʹ�����Ⱦ���ÿһ�к�Ϊ1
membership_mat = membership_mat.T
membership_mat_old = np.zeros((example_nums, k)) # ���ڵ���
# ���е���,���������Ⱦ���;�������
while True:
centorids = np.empty((k, np.shape(data_set)[1]))
# �ɹ�ʽ���������
for j in range(k):
centorids[j] = np.dot(membership_mat[:, j]**m, data_set) / (np.sum(membership_mat[:, j]**m))
membership_mat_old = membership_mat.copy()
# ���ݹ�ʽ�����µ������Ⱦ���
for i in range(example_nums):
for j in range(k):
for z in range(k):
membership_mat[i, j] += ((distance(data_set[i], centorids[j])) / distance(data_set[i], centorids[z])) ** (2 / (m-1))
membership_mat = 1 / membership_mat
# �ж��Ƿ�����
if np.max(np.abs(membership_mat - membership_mat_old)) < eps:
cluster = np.argmax(membership_mat, axis=1)
return centorids, cluste
��:Ч��չʾ
import pandas as pd
import matplotlib.pyplot as plt
import FCM
import numpy as np
Iris_types = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'] # ������
Iris_data = pd.read_csv('dataSet/Iris.csv')
# x_axis = 'PetalLengthCm' # ���곤��
# y_axis = 'PetalWidthCm' # �������
x_axis = 'SepalLengthCm' # �����
y_axis = 'SepalWidthCm' # �������
examples_num = Iris_data.shape[0] # ��������
train_data = Iris_data[[x_axis, y_axis]].values.reshape(examples_num, 2) # ��������
# ��һ��
min_vals = train_data.min(0)
max_vals = train_data.max(0)
ranges = max_vals - min_vals
normal_data = np.zeros(np.shape(train_data))
nums = train_data.shape[0]
normal_data = train_data - np.tile(min_vals, (nums, 1))
normal_data = normal_data / np.tile(ranges, (nums, 1))
# ѵ������
k = 3 # ����
max_iterations = 50 # ����������
centroids, cluster = FCM.fcm(normal_data, 2, k, 1e-6)
plt.figure(figsize=(12, 5), dpi=80)
# ��һ��ͼ����֪��ǩ��ȫ������
plt.subplot(1, 2, 1)
for Iris_type in Iris_types:
plt.scatter(Iris_data[x_axis], Iris_data[y_axis], c='black')
plt.title('raw')
# �ڶ���ͼ�Ǿ�����
plt.subplot(1, 2, 2)
for centroid_id, centroid in enumerate(centroids): # �Ǿ�������
current_examples_index = (cluster == centroid_id).flatten()
plt.scatter(normal_data[current_examples_index, 0], normal_data[current_examples_index, 1])
for centroid_id, centroid in enumerate(centroids): # ��������
plt.scatter(centroid[0], centroid[1], c='red', marker='x')
plt.title('label kemans')
plt.show()
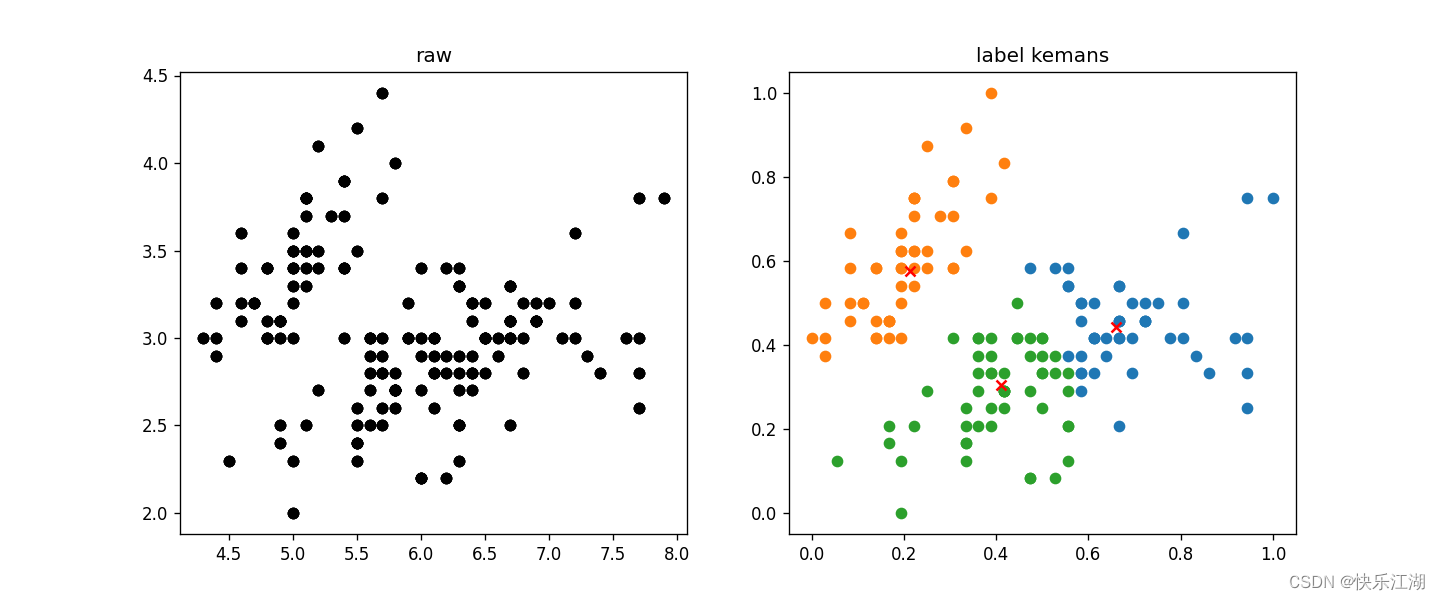
��:�㷨ȱ��
- ����Ⱥ��ʮ������
- �㷨�ܿ�����һ���ֲ����Ž�
- �㷨������ʮ�ִ�
- �㷨�����Բ�,���ʺϴ������ģ���ݼ���
- ģ��ϵ�� m m m�Ծ�����Ӱ��dz���