Ŀ¼
ǰ��:
?????????(�f��???) hi~ ��ӭ��ҵ㿪�ҵ�����~ �����һ���ܹ鲢���������ʵ�ַ���:�ݹ�ͷǵݹ���
? ? ? ? ע:�����㷨�Ҿ���ʹ�õ�����,����ֻ��Ҫ��ִ�������෴�ͺ���~<*))>>=<
�鲢����
????????�鲢�����ǽ������鲢�����ϵ�һ����Ч,�ȶ��������㷨,���㷨�Dz������η�(Divide and Conquer)��һ���dz����͵�Ӧ�á�����������������ϲ�,�õ���ȫ���������;����ʹÿ������������,��ʹ�����жμ�������������������ϲ���һ�������,��Ϊ��·�鲢��
�鲢:�鲢ʵ���Ͼ����Ƚ��������ֳ�������,Ȼ����������Ҫ������,�ͽ��й鲢����,��ϳ�һ�������������,����������Ӳ���û����ľͼ�����,�ֵ�������߲����ڵ�ʱ���������,Ȼ�������ݡ�
����:���ֶ���֮��,��˼���ǰ�һ�����ӵ�����ֳɼ���С����,Ȼ���ٷ�,�ֵ����Լ����,Ȼ��ԭ����Ľ�ʵ���Ͼ�����ЩС����Ľ�ĺϲ��������Ӧ�þ��ǽ���ֳ�С���������,����е�һ������һ�ξ�������ˡ�
1.�ݹ�汾?
��ʾ:
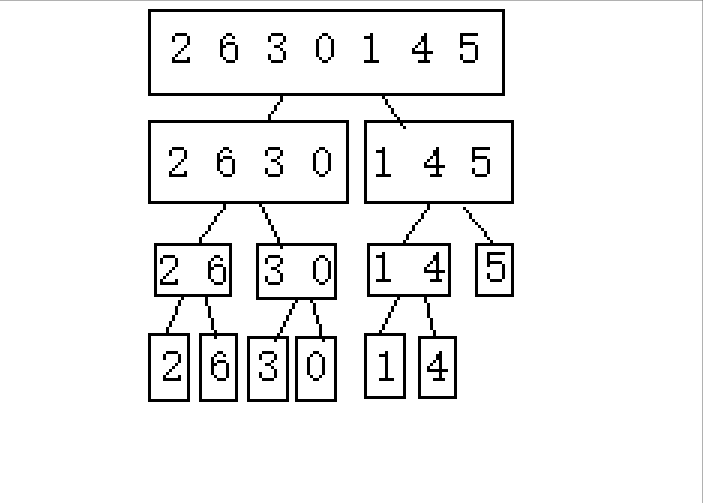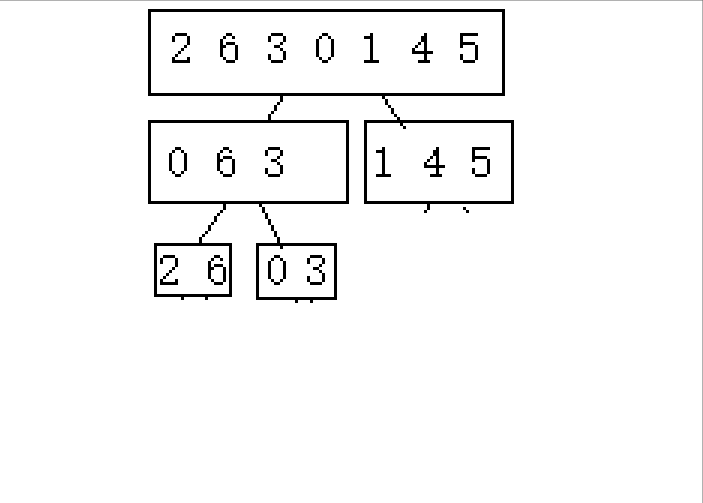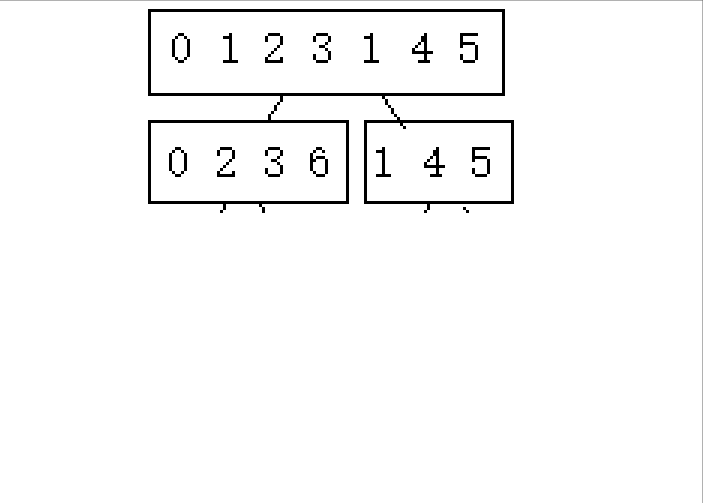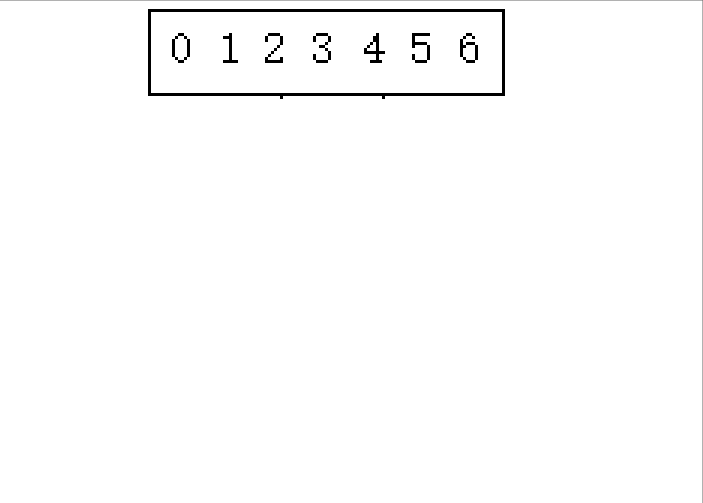
(������2 6 3 0 1 4 5����������������ʾ)
????????1.�ֳɿɽ������(�������߲����ڼ����������)
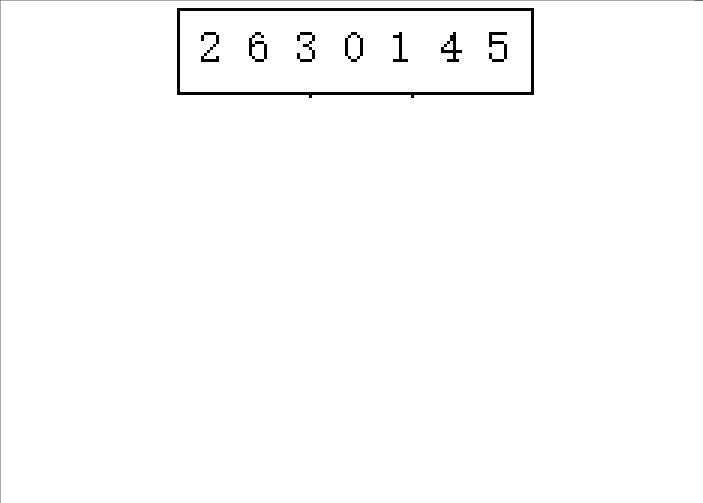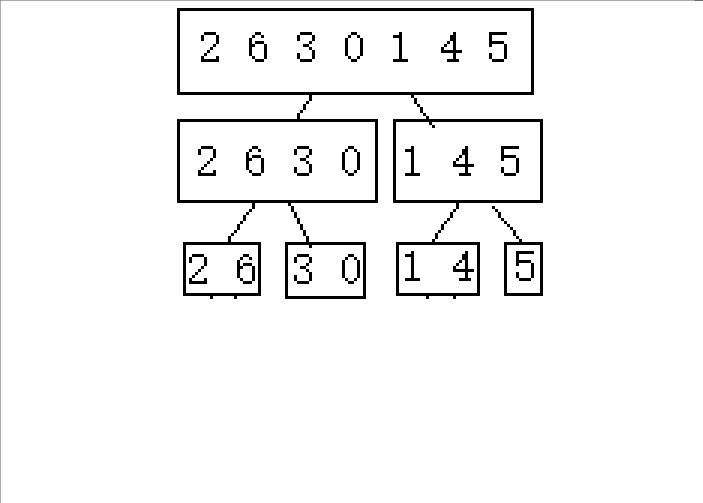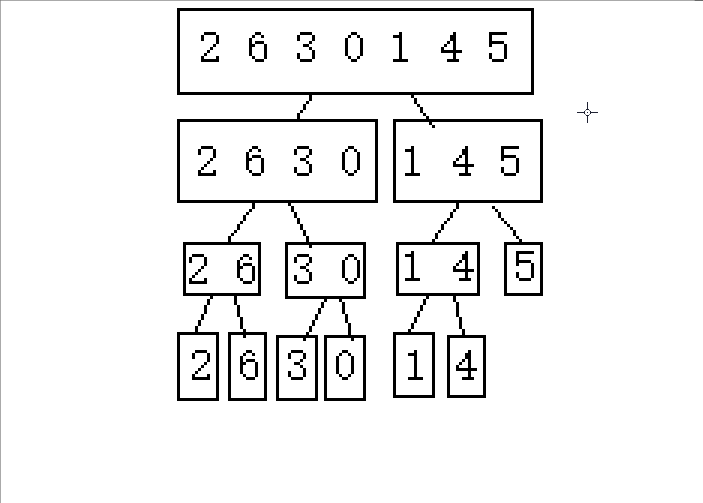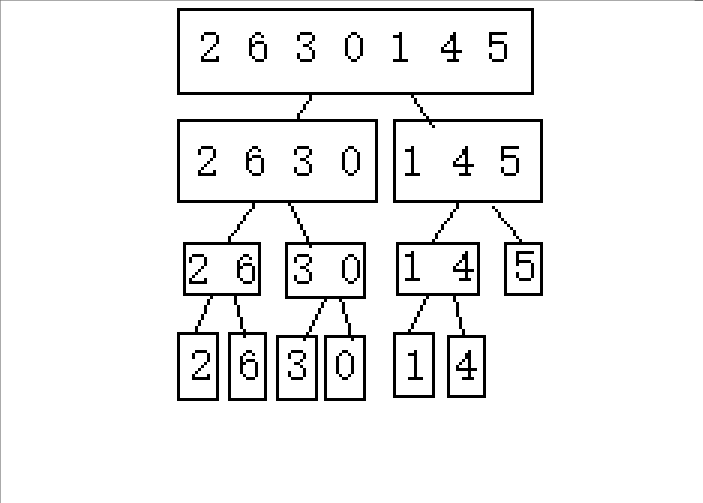
? ? ? ? ?2.�Ӻ���ǰ�鲢
?
ʵ��:
????????�����������ʾ,���Dz��ѷ���,������Ҫ���������������ֳ�С��,Ȼ����й鲢�������Ծ��е����������㷨,�����Ȱ��������ߴ�����,Ȼ�����ڽ����ҵĹ鲢��
????????������һ��,������ʵ��:
//�����鲢����ݹ���Ӻ���
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (begin >= end)
return;//�������߲�����������ͽ����ݹ�
//�����ں���:
int middle = (begin + end) / 2;
int begin1 = begin;
int end1 = middle;
int begin2 = middle + 1;
int end2 = end;
_MergeSort(a, tmp, begin1, end1);
_MergeSort(a, tmp, begin2, end2);
//��ʱ��Ϊ [begin1, end1] �� [begin2, end2]��������������
//�鲢�㷨
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));//�ڴ��������,���Խ���������������ƹ�ȥ
}
//�鲢���� �ݹ�汾
void MergeSort(int* a, int n)
{
//����mallocһ������
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("δ�����뵽�ڴ�\n");
exit(-1);
}
//��һ�δ��� 0 �� n - 1 ���������
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
}
tmp����:�����ڹ鲢ʱ,��Ҫһ��ý�����������ֵĽ������������ԭ�����Ͻ��в����Ļ�,�Ḳ�ǵ�ԭ��������,������ݶ�ʧ��
malloc:?void?*malloc(?size_t?size?); ����ڴ�����ָ���ֽڵ������ռ䡣
memcpy:void* memcpy(void* dest, const void* src, size_t count);��һ��ָ���ֽڵ������ռ�����ݸ��Ƶ�dest��
_MergeSort:���ڵݹ���Ӻ���,��ʵ�ֹ鲢��ǰ��,���Ƚ����ߵݹ��ȥ,ֱ����������begin >= end��ʱ��ͽ����ݹ�,������һ���ݹ�ĺ���������һ������,�������ܱ�֤�ڽ��й鲢ǰ,�������������
2.�ǵݹ�汾
? ? ? ? �ݹ�汾��������������Ļ�,��������,�ᵼ��ջ���,���������ʵ�ַǵݹ�汾,ʹ����ö��ڴ��������,���ڴ��ջ�ڴ�����,�Ͳ��õ�������������ˡ�
????????�ǵݹ�汾ʵ���е����⡣���Ŵ��Ҳ�˽����������ķǵݹ�汾,�Ǹ������õ�ջ���߶������ݽṹ���洢����Ӷ�ʵ�ֵġ������Ƿ�����������Ĺ鲢�����ء�
? ? ? ? ͨ��ǰ��ĵݹ�汾����֪��,�˹鲢������Ҫ��ǰ���źú�Ҳ���Ǻ������ʽ������������������й鲢���������ջ������Щ����,���ȴ洢0 ��n - 1,Ȼ��洢 0 ��middle,middle + 1�� end ,Ȼ��Ͳ���ֱ��ȡ��,��Ϊ����ȷ�������������Ƿ��������,������Ҫ�������ȥ����,����鷳��
? ? ? ? ��ô���ǻ���˼·,�������Եķǵݹ�ʵ����Ҫ����������ջ֮������ݿռ�İ�,����쳲��������еķǵݹ�ʵ��,��ô����ֱ��ʵ���Dz���Ҳ������?
��ʾ:
1.����2��n���������([0 7])

ע��,�ڴ���ʾ��,ÿ�ξ��DZ�����������,�������ݡ�Ϊ��ʵ�ִ����ȷ��,��ô��Ҫ���� ����2��n�η��������κ�ż���Ρ�
?2.������2��n�������������([0 6])

?����ͻᷢ��,��һ�ζ�����1����2��2�ݵķ������Ļ�3û������ֵ�,��ô3�ͱ��ֲ���,ֱ����2�ֵַ�����һ���ʱ��Ϳ������������ˡ�
3.������2��n�η���ż��������([0 9])

?����ͬ���Ŀ��Է���,��һ���Ǿ�����2�ֵ�,���Ǻ���Ͳ�����,�����ں�����ֺ��˺�,��Ӧ��û�����Ҳ���ֲ���,ֱ����Ӧ���顣
ʵ��:
? ? ? ? ֱ�ӽ��зֿ�,Ȼ����й鲢���˴��벢����д,��Ҫ������������ʾ�е����������
????????���ǿ��Զ���һ��gap������ȷ��ÿһ�ε����䳤��,��һ��1,�ڶ���2,������4,ֱ��<n�����,����������鳤�Ȳ���2��n�η��Ļ�,��Ҫ������д�����
? ? ? ? ����ij����������ִ�������,�������������ʾ�е��������������
//�鲢���� �ǵݹ�汾
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("����ռ�ʧ��\n");
exit(-1);
}
//���彻�� - 1
//int gap = 1;
//while (gap < n)
//{
// for (int i = 0; i < n; i += 2 * gap)//ÿ�ο�Խ����
// {
// int begin1 = i, end1 = i + gap - 1; // [0, 0] [2, 2] [4, 4] [6, 6]
// int begin2 = i + gap, end2 = i + 2 * gap - 1; // [1, 1] [3, 3] [5, 5] [7, 7]
// //�߽����:begin1�϶�����Խ��,��end1Խ���ʱ��
// if (end1 >= n)
// {
// end1 = n - 1;
// //��2ϵ�еIJ����ڼ���
// begin2 = 1;
// end2 = 0;
// }
// else if (begin2 >= n)
// {
// begin2 = 1;
// end2 = 0;
// }
// else if (end2 >= n)
// {
// end2 = n - 1;
// }
// //�鲢
// int j = begin1;
// while (begin1 <= end1 && begin2 <= end2)
// {
// if (a[begin1] <= a[begin2])
// {
// tmp[j++] = a[begin1++];
// }
// else
// {
// tmp[j++] = a[begin2++];
// }
// }
// while (begin1 <= end1)
// {
// tmp[j++] = a[begin1++];
// }
// while (begin2 <= end2)
// {
// tmp[j++] = a[begin2++];
// }
// }
// memcpy(a, tmp, sizeof(int) * n);//���帴��,��ô ����2�Ĵη�����n��Ҫ���б߽����
// gap *= 2;
//}
//ÿ�ν��� - 2
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)//ÿ�ο�Խ����
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (end1 >= n || begin2 >= n)
{
break;
}
else if (end2 >= n)
{
end2 = n - 1;
}
//�鲢
int j = begin1;
int m = end2 - begin1 + 1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * m);//�ֲ�����,end2 - begin1 + 1
}
gap *= 2;
}
free(tmp);
}
gap:gap�������ÿ�λ��ֵ����䳤��,��һ�ξ�����һ����������ϲ�һ�������,����gapÿ��ѭ��*2���ɡ�
begin:begin1��2�ֱ����������俪ʼ���±ꡣ����i������,i��һ����0,��ô����gap������,begin1��Ȼ��i,begin2�����Ѿ������һ��������,������i+gap
end:end1��2����������������±�,end1�ǵ�һ�����������±�,��Ȼ�ǵڶ�������Ŀ�ʼ��һ,������i+gap - 1.end2�ǵڶ������������±�,������Ȼ�ǵ���������Ŀ�ʼ��һ,��i+gap*2-1��
���������������,�����ִ����취,ʵ����Ҳ����һ��,ֻ���������memcpy��һ��һ�θ��ƻ������帴���������֡�һ���Dz����д�������һ��,һ����Ҫ���д���,�Ա߽�����Ż����ɡ�