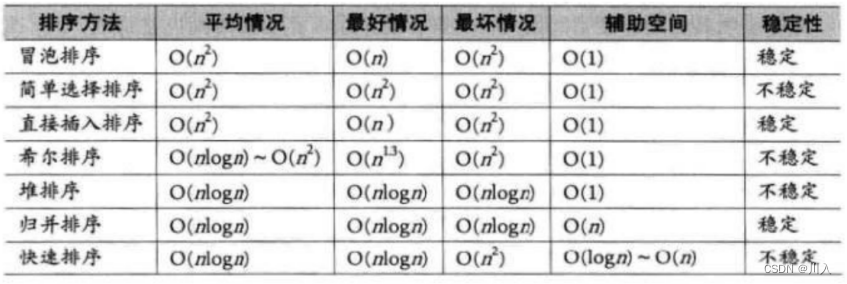
��������:
- ����:��ν����,����ʹһ����¼,�������е�ij����ijЩ�ؼ��ֵĴ�С,������ݼ������������IJ�����
- �ȶ���:�ٶ��ڴ�����ļ�¼������,���ڶ��������ͬ�Ĺؼ��ֵļ�¼,����������,��Щ��¼����Դ��ֲ���,����ԭ������,r[i] = r[j]?,��?r[i]?��?r[j]?֮ǰ,����������������,r[i]?����?r[j]?֮ǰ,������������㷨���ȶ���;�����Ϊ���ȶ��ġ�
- �ڲ�����:����Ԫ��ȫ�������ڴ��е�����
- �ⲿ����:����Ԫ��̫���ͬʱ�����ڴ���,����������̵�Ҫ�����������֮���ƶ����ݵ�����

Ŀ¼
? ? ? ? ? ? 2. ѡ��keyѡ������ߺ�,ѡ���ұ����ߵ�����:
1.1 ����Ǹ����������ַ����Ͳ���������
1.2?������ݷ�Χ�ܴ�,�ռ临�ӶȾͻ�ܸ�,��Բ��ʺ�
һ ������������:
? ? ? ? ����,���˿���ʱ,ͨ������˿���Ȼ���ƶ��ٲ���IJ������Ǵ�����2��,3��,4�š���һ����

1��?ֱ�Ӳ�������:
//ֱ�Ӳ�������
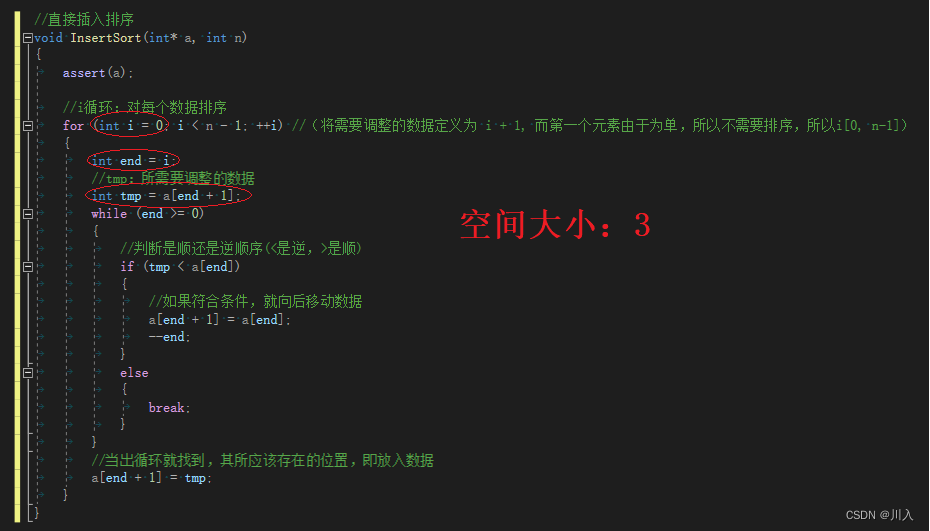
void InsertSort(int* a, int n)
{
assert(a);
//iѭ��:��ÿ����������
for (int i = 0; i < n - 1; ++i) //(����Ҫ���������ݶ���Ϊ i + 1, ����һ��Ԫ������Ϊ��,���Բ���Ҫ����,����i[0, n-1])
{
int end = i;
//tmp:����Ҫ����������
int tmp = a[end + 1];
while (end >= 0)
{
//<������,>�ǽ���
if (tmp < a[end])
{
//�����������,������ƶ�����
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
//����ѭ�����ҵ�,����Ӧ�ô��ڵ�λ��,����������
a[end + 1] = tmp;
}
}1. 1 ֱ�Ӳ������������:
-
Ԫ�ؼ���Խ�ӽ�����,ֱ�Ӳ��������㷨��ʱ��Ч��Խ��
-
ʱ�临�Ӷ�:O(N^2)(���ΪO(N) ~ ���ΪO(N^2))
-
?�ռ临�Ӷ�:O(1)
-
?�ȶ���:�ȶ�
1.1.1 ʱ�临�Ӷ�:
????????????????���O(N)�����:
? ? ? ? ? ? ? ? ? ? ? ??(����Ϊ���)ֻ�д�����ֵ��ǰֵ����������,������Ҫ�ƶ�,������ֻ��Ҫ�жϸ�ֵ��ǰֵһ��,����ÿ��Ԫ�ض�һ��,��ֻ��Ҫÿ��Ԫ�ص�һ���ж�,��O(N)��
????????????????���O(N^2)�����:
? ? ? ? ? ? ? ? ? ? ? ??(����Ϊ���)ֻ�д�����ֵ��ǰֵ���뷴��,��ǰ���ж������ݾ���Ҫ�ƶ�����,����������һ���Ȳ�����:1 + 2 + 3 + �� + N-1,����:n (1+n-1)/2 ��~O(n^2)?������Ҫÿ��Ԫ�ص�һ���ж�,���ƶ��Ĵ���Ϊ���,��O(N^2)��
1.1.2?�ռ临�Ӷ�:
? ? ? ? ? ?��:�ռ临�Ӷ�ΪO(1)
1.1.3 �ȶ���:

? 2�� ϣ������:
? ? ? ? ϣ������Ļ���˼��:��ѡ��һ������,�Ѵ������ļ������м�¼�ֳɸ���,���о���Ϊ�ļ�¼����ͬһ����,����ÿһ���ڵļ�¼��������Ȼ��,ȡ�ظ��������������Ĺ�����������=1ʱ,���м�¼��ͳһ�������������
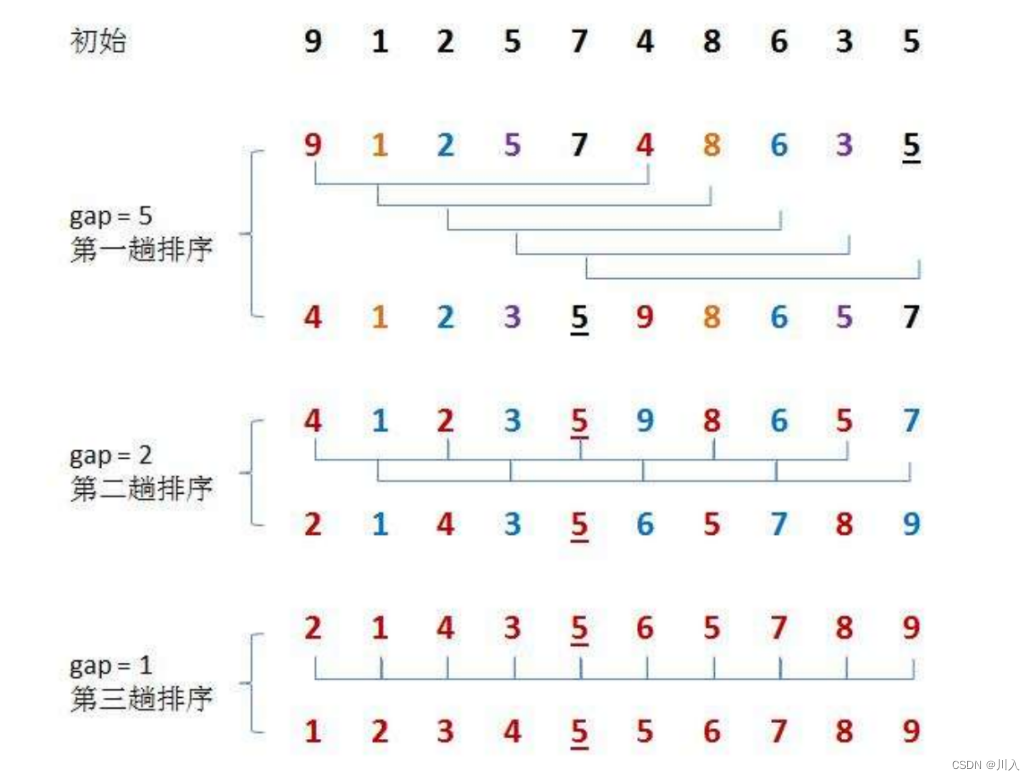
????????��gap = 2��:
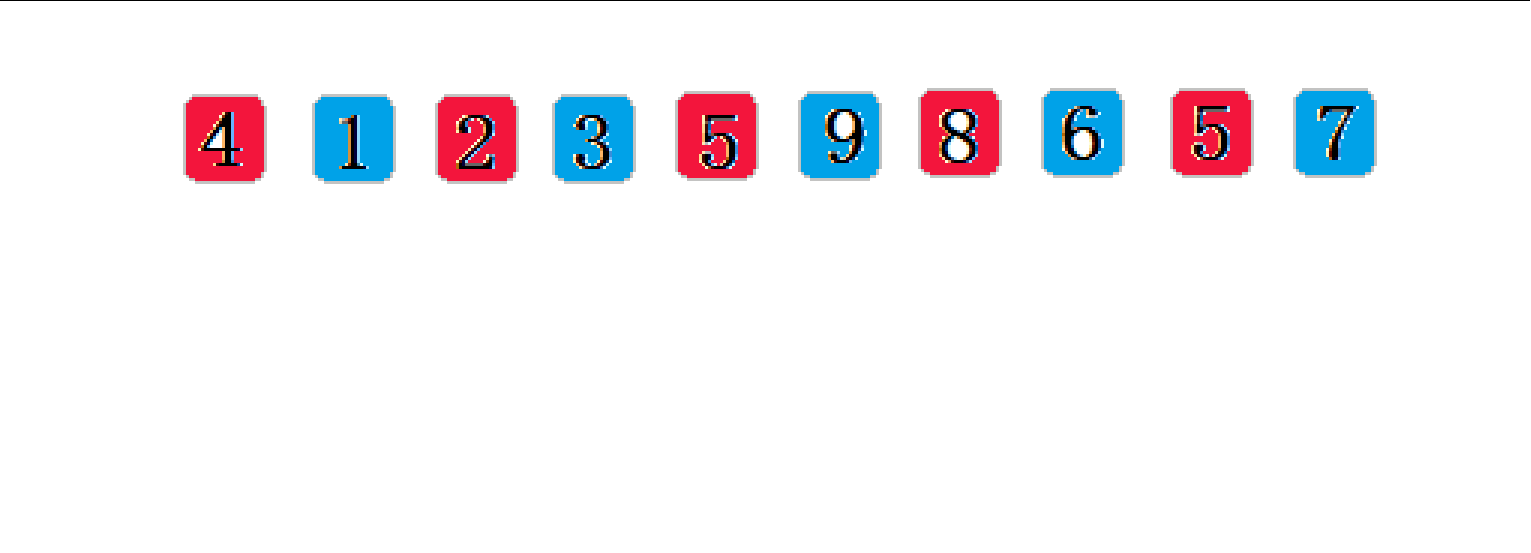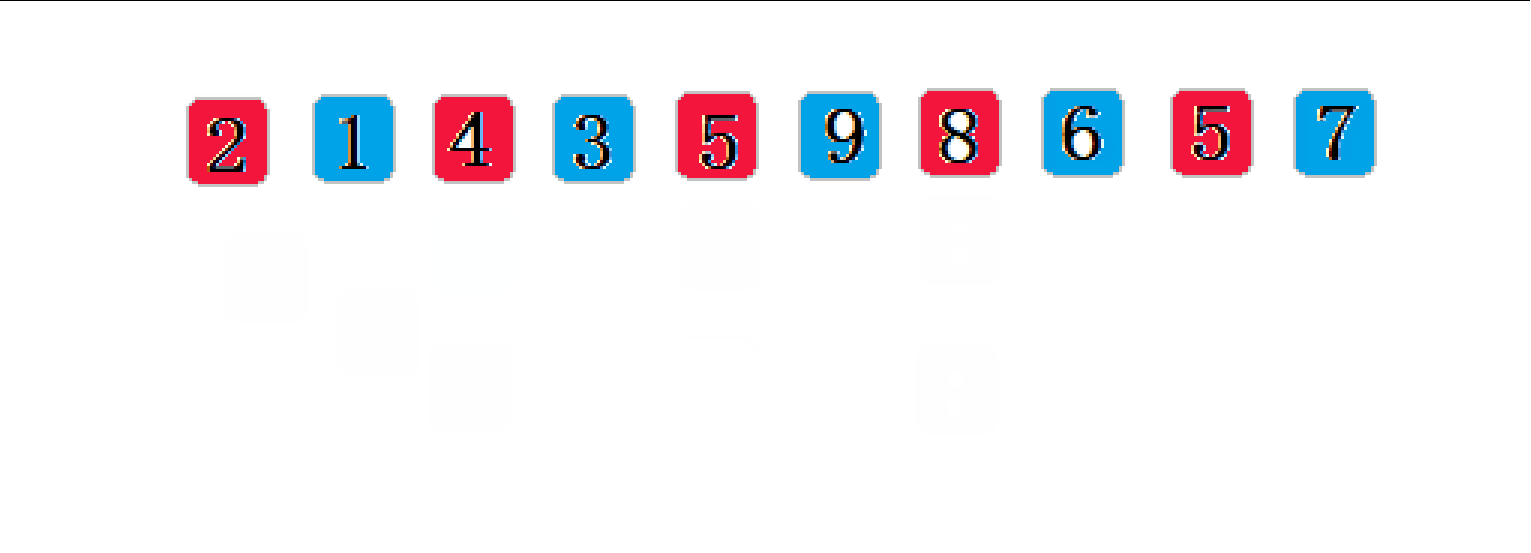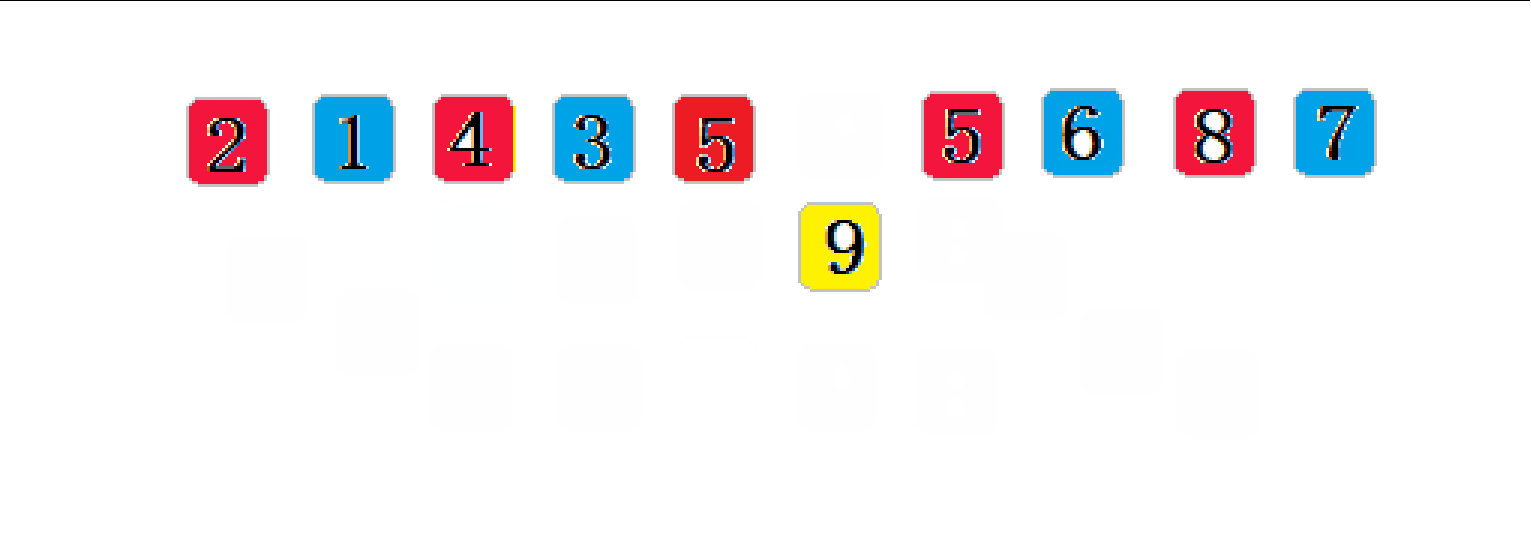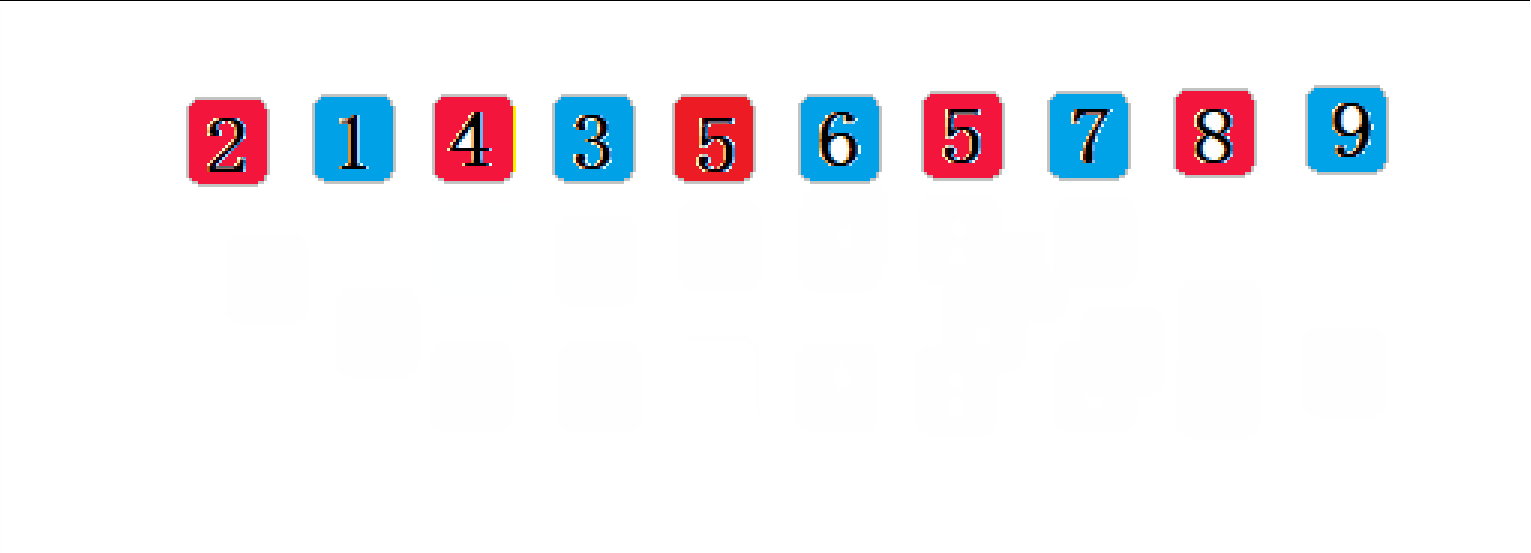
//ϣ������
/* ����,�±� 0~n ������,�������±�Ϊ X ������ʱ,0~X-1 �������Ѿ�������� */
/* ƽ������: ������(С��),��Ԫ����������*/
void ShellSort(int* a, int n)
{
assert(a);
int gap = n;
while (gap > 1)
{
// +1��ֹgap����1,��֮ǰgap = 2ʱ,��Ϊ3 / 2 = 0,(����2����Ϊ��0)
gap = gap / 3 + 1;
/*gap = gap / 2*/
//j:������iͬһ��(����gap����)������Ԫ���±�
//i:��������������Ԫ���±�,��Ϊÿһ��Ƚ����ݵ����һ��Ԫ���±�
for (int j = 0; j < gap; j++)
{
for (int i = j; i < n - gap; i += gap)
{
int end = i;
//tmp:����������
int tmp = a[end + gap];
while (end >= 0)
{
//<������,>�ǽ���
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
}?ϣ�����������һ��д��:
????????��gap = 2��:

//ϣ������
void ShellSort(int* a, int n)
{
assert(a);
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
/*gap = gap / 2*/
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
//<������,>�ǽ���
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}2.1?ϣ������������ܽ�:
- ϣ�������Ƕ�ֱ�Ӳ���������Ż���
- ?��gap > 1ʱ����Ԥ����,Ŀ������������ӽ�������gap == 1ʱ,�����Ѿ��ӽ��������,�����ͻ�ܿ졣�����������,���Դﵽ�Ż���Ч��������ʵ�ֺ���Խ������ܲ��ԵĶԱȡ�
- ϣ�������ʱ�临�ӶȲ��ü���,��Ϊgap��ȡֵ�����ܶ�,���º���ȥ����,����ں�Щ���и�����ϣ�������ʱ�临�Ӷȶ����̶�:
? ? ?�����ݽṹ(C����)��--- ��ε��


- �ȶ���:���ȶ�
- �ռ临�Ӷ�:O(1)
2.1.1 �ռ临�Ӷ�:

? ? ? ? ? ?��:�ռ临�Ӷ�ΪO(1)
2.1.2 �ȶ���:
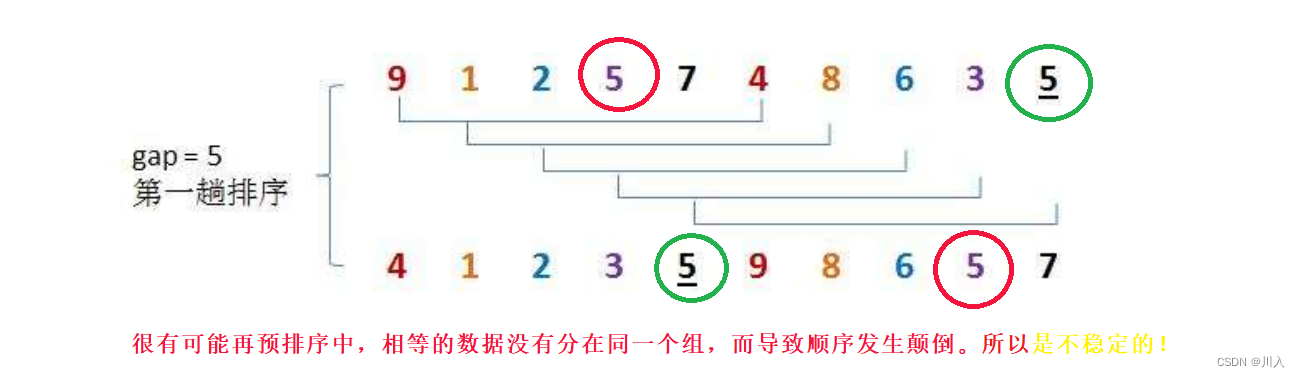
?��������������
? 1������
? ? ? ? ð������Ļ���˼��:�Ƚ����ڵ�Ԫ�ء��������ߴ�(С),�ͽ������ߡ���ÿһ������Ԫ����ͬ���Ĺ���,�ӿ�ʼ��һ�Ե���β�����һ�ԡ������һ��Ԫ����������������ֵ��(��������ֱ�����)
//���ݽ���
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//����
void BubbleSort(int* a, int n)
{
assert(a);
//�����ж��Ƿ�
int compare = 0;
//jѭ��: ���е�����j��λ��,������Ҫ��Ԫ�����λ��,���ڵ�һ��Ԫ�����Ϊ��,����j < n
//iѭ��:������δ���������(��Χ[0 , n - j])���бȽ�����
int j = 0;
for (j = 1; j < n; j++)
{
int i = 0;
for (i = 0; i < n - j; i++)
{
//>������,<�ǽ���
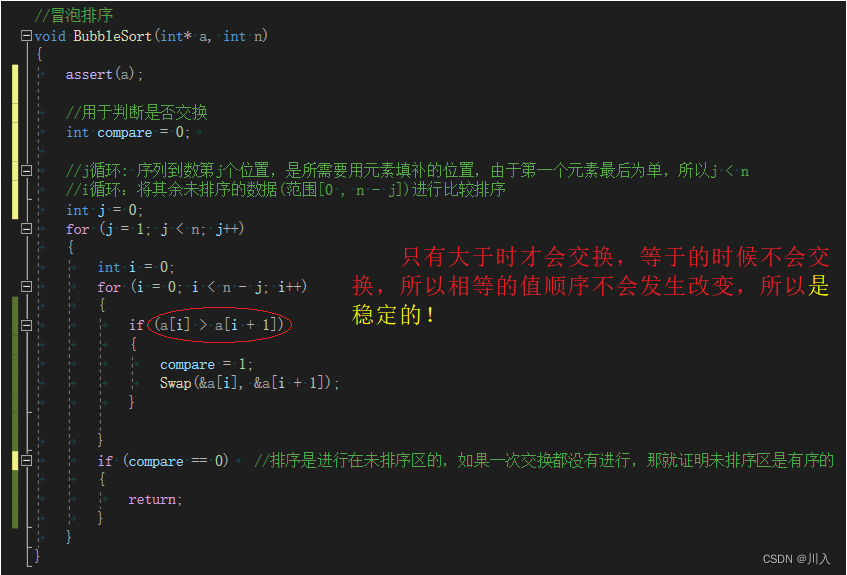
if (a[i] > a[i + 1])
{
compare = 1;
Swap(&a[i], &a[i + 1]);
}
}
if (compare == 0) //�����ǽ�����δ��������,���һ�ν�����û�н���,�Ǿ�֤��δ�������������
{
return;
}
}
}1.1?ð������������ܽ�:
- ð��������һ�ַdz��������������
- ʱ�临�Ӷ�:O(N^2)(���ΪO(N) ~ ���ΪO(N^2))
- �ռ临�Ӷ�:O(1)
- �ȶ���:�ȶ�
1.1.1 ʱ�临�Ӷ�:
????????????????���O(N)�����:
? ? ? ? ? ? ? ? ? ? ? ??(����Ϊ���)ֻ�д�����ֵ��ǰֵ����������,ȫ�̲���Ҫ����,��ô�Ϳ���ֱ���˳�,����ֻ��Ҫ�Ƚ�һ��,��ֻ��Ҫ�ж�,��O(N)��
?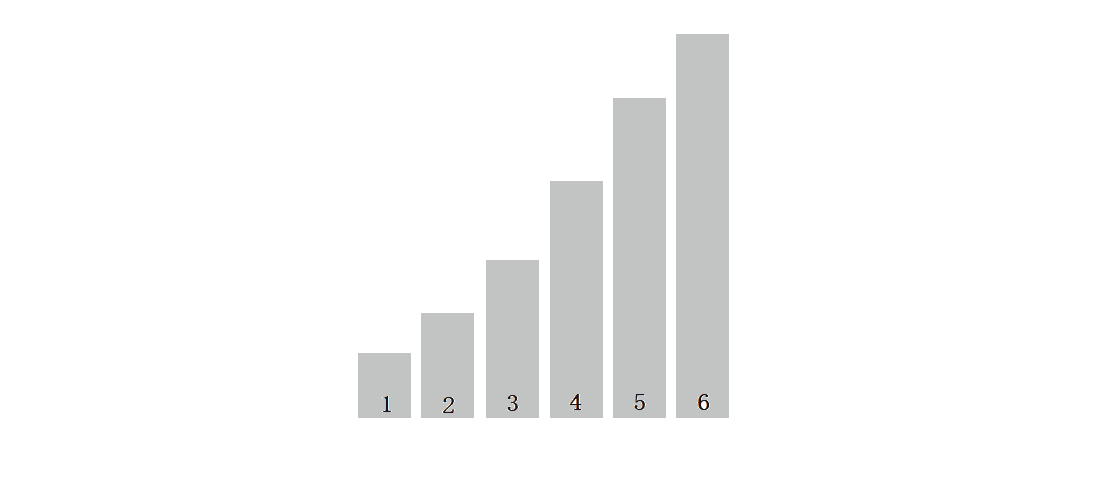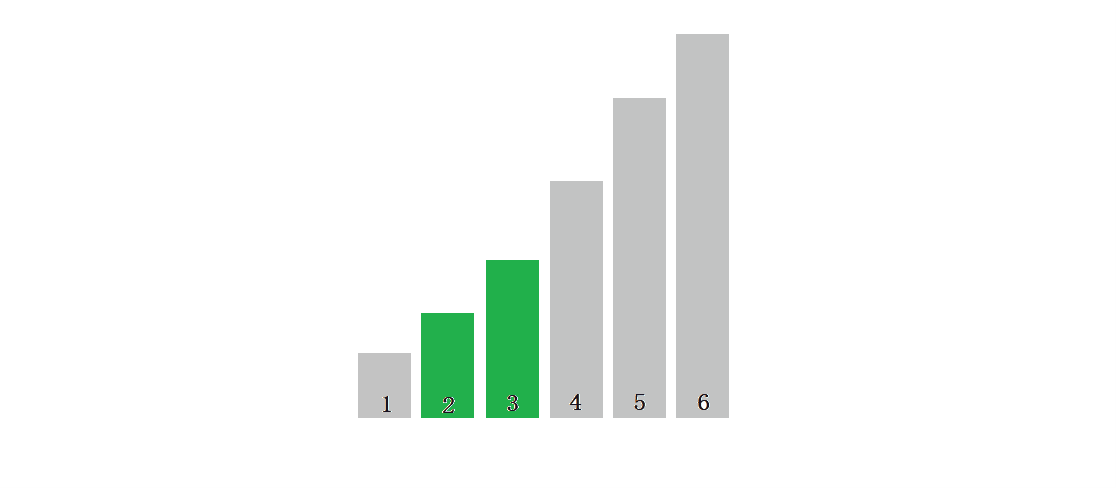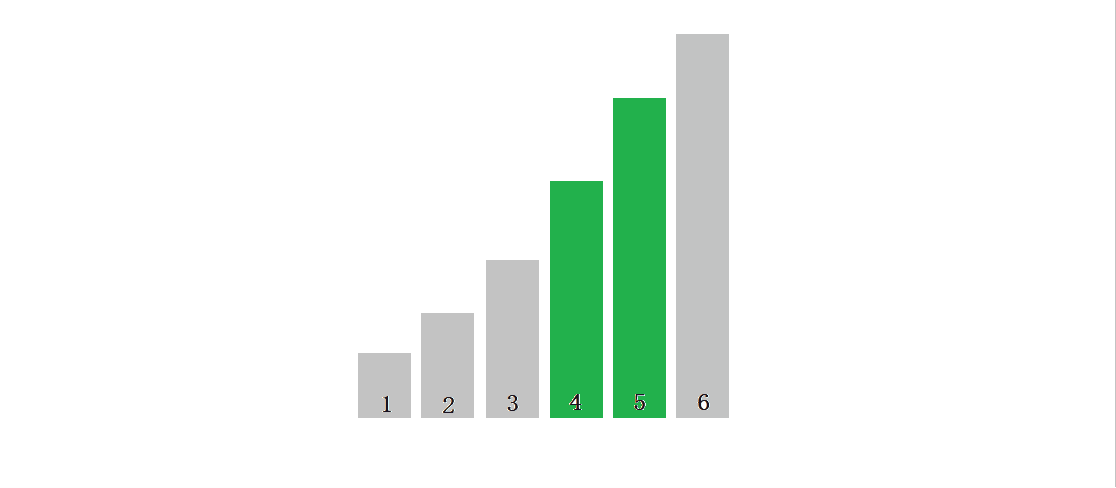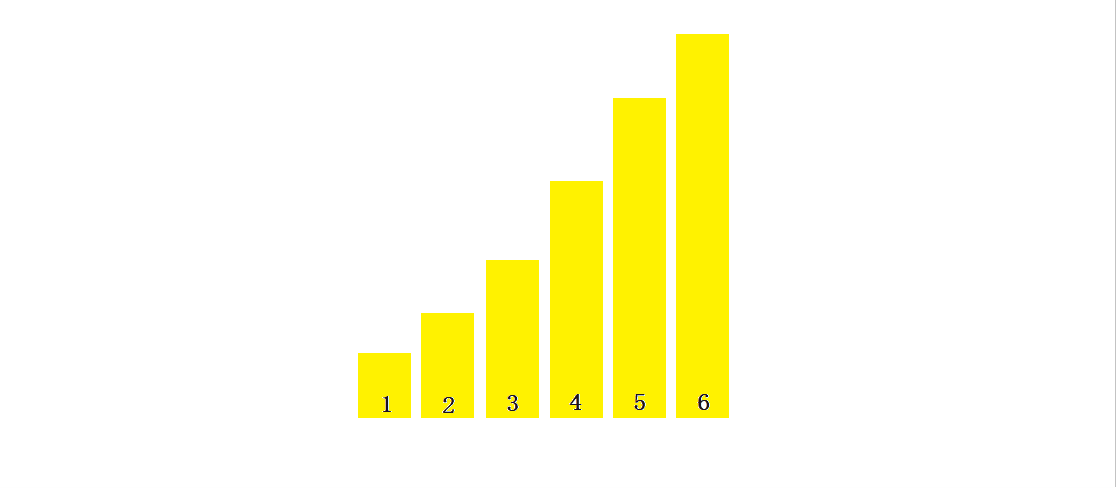
????????????????���O(N^2)�����:
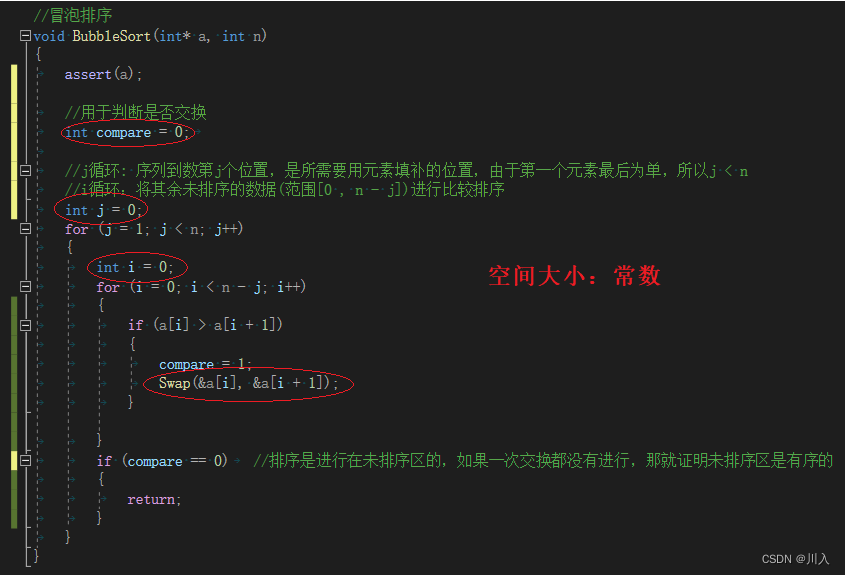
? ? ? ? ? ? ? ? ? ? ? ??(����Ϊ���)ÿ�ֱȽ϶���Ҫ�ƶ�,����������һ���Ȳ�����:N-1 +? �� + 3 + 2 + 1,����:n (n-1+1)/2 ��~O(n^2)?������Ҫÿ��Ԫ�ص�һ���ж�,���ƶ��Ĵ���Ϊ���,��O(N^2)��?
1.1.2 �ռ临�Ӷ�:?
?? ? ? ? ? ?��:�ռ临�Ӷ�ΪO(1)
2.1.2 �ȶ���:
??2����������:
?????????����������Hoare��1962�������һ�ֶ������ṹ�Ľ�������,�����˼��Ϊ:��ȡ������Ԫ�������е�ijԪ����Ϊ��ֵ,���ո������뽫�����Ϸָ����������,��������������Ԫ�ؾ�С�ڻ�ֵ,��������������Ԫ�ؾ����ڻ�ֵ,Ȼ���������������ظ��ù���,ֱ������Ԫ�ض���������Ӧλ����Ϊֹ��
�����õ���Ҫ����(Ϊ��������ݹ�ʵ�ֵ������):

������,�����䰴�ջ�ֵ����Ϊ�������벿�ֵij�����ʽ��:
- hoare�汾
-
�ڿӰ汾
-
ǰ��ָ��汾
- ������ִ�з�ʽ��ͬ,���Ǻ���˼���Dz����,�汾�ĸ���ֻ��Ϊ�˸��ӱ������⡣
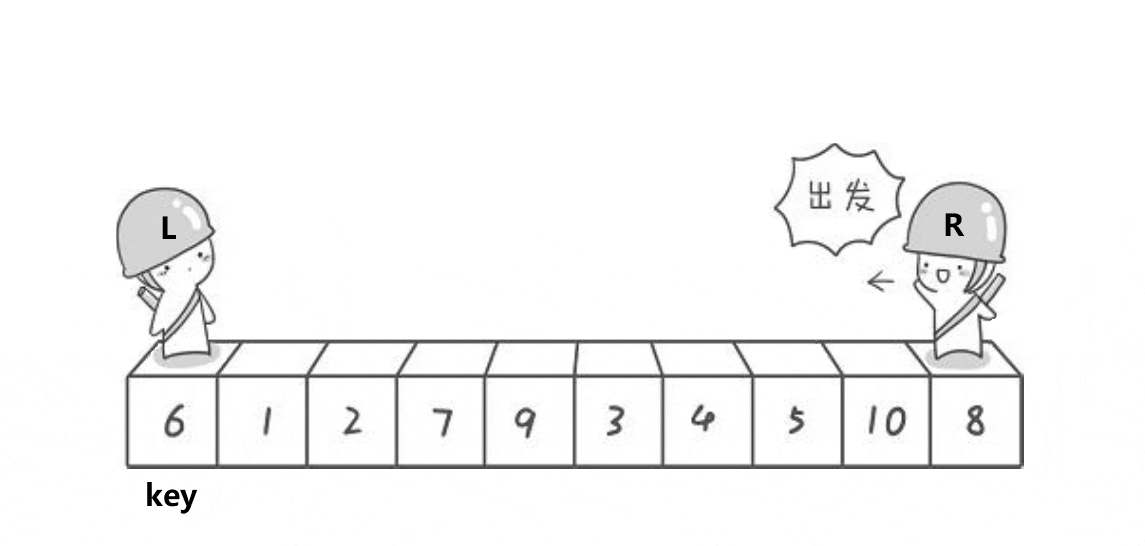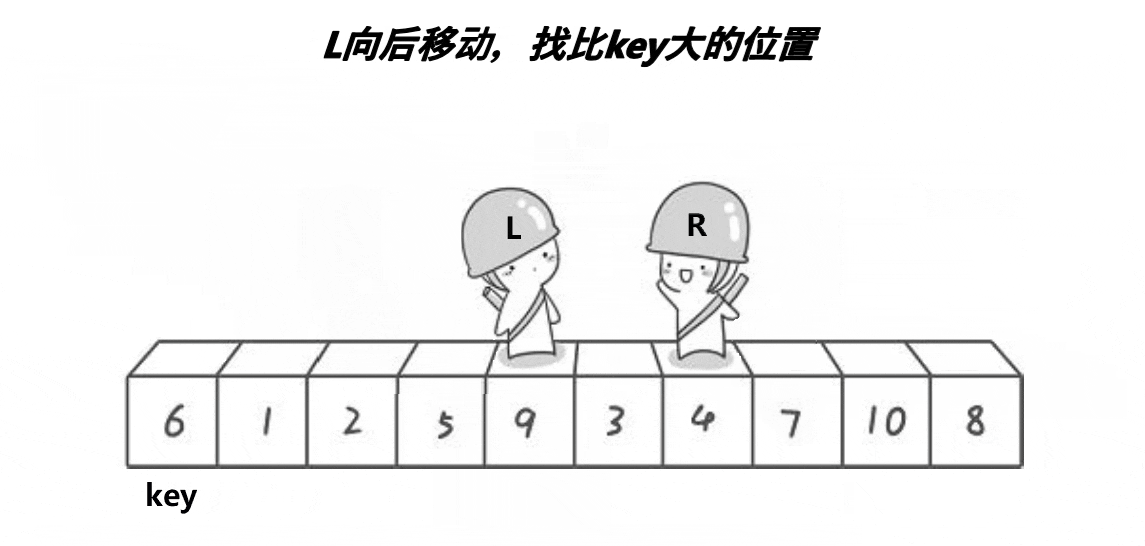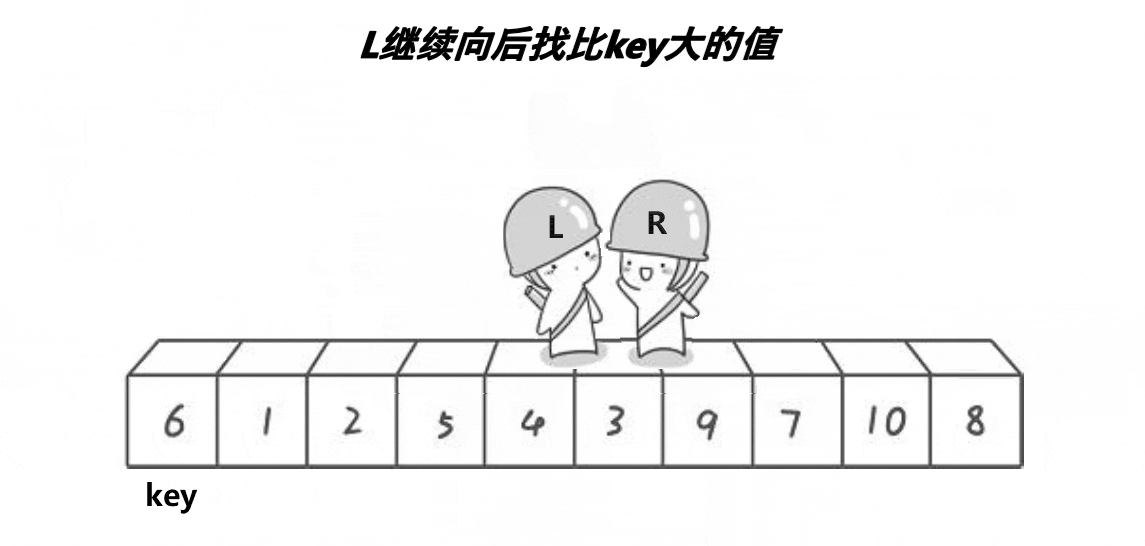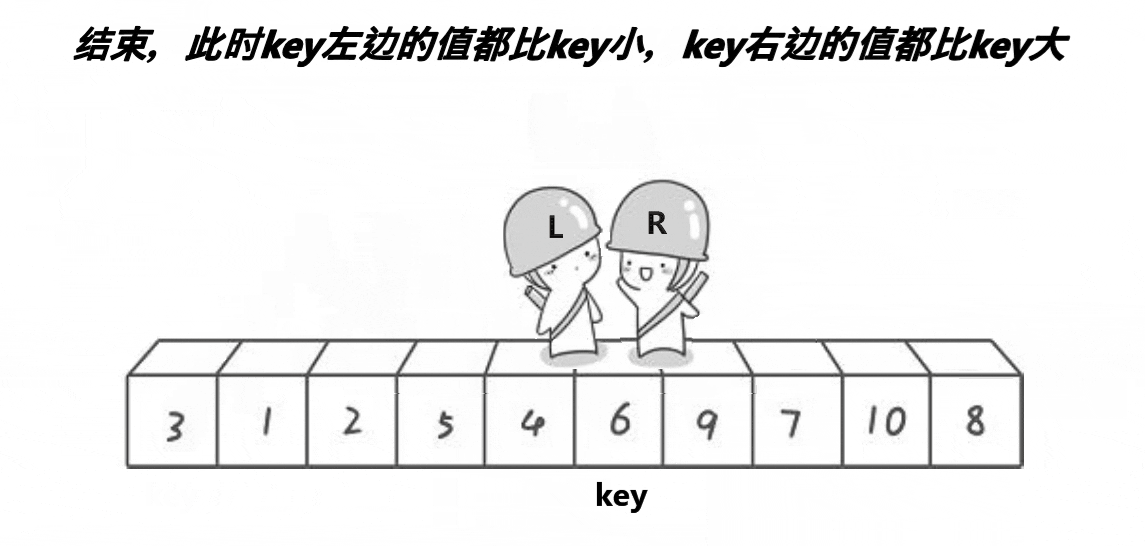
? 1.??hoare�汾:
//���ݽ���
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//hoare�汾(���η�)
//��right�ߵ����ݵ�������С�ڻ����������������,left��ͬ����֮��������
void QuickSort1(int* a, int begin, int end)
{
assert(a);
if (begin >= end)
return;
//keyi:����Ҫ�����������±�
int right, left, keyi;
left = begin, right = end;
keyi = begin;
//���ݴ�С������Ԫ�ؽ���
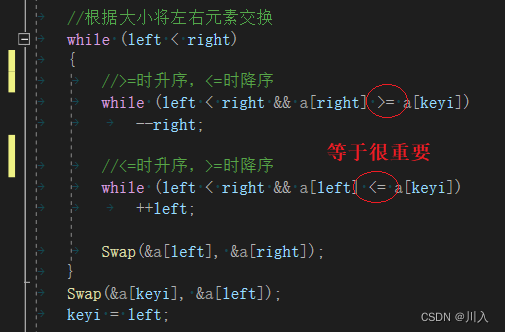
while (left < right)
{
//>=ʱ����,<=ʱ����
while (left < right && a[right] >= a[keyi])
--right;
//<=ʱ����,>=ʱ����
while (left < right && a[left] <= a[keyi])
++left;
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
keyi = left;
//�������������
//[begin, keyi - 1] keyi [keyi + 1, end]
QuickSort1(a, begin, keyi - 1);
QuickSort1(a, keyi + 1, end);
}
hoare�汾�״���:
????????(ͬ���ĺ�����ڿӰ�,Ҳ��ͬ�������� )
? ? ????????1.���ڱȽ�ʱ:
??????????????����,û�е���:
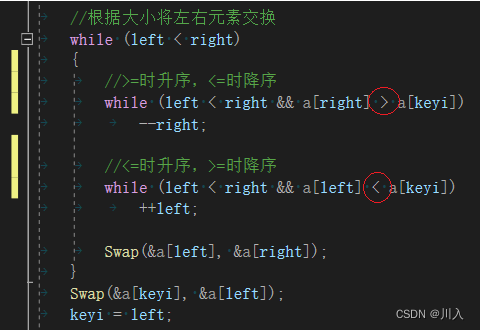
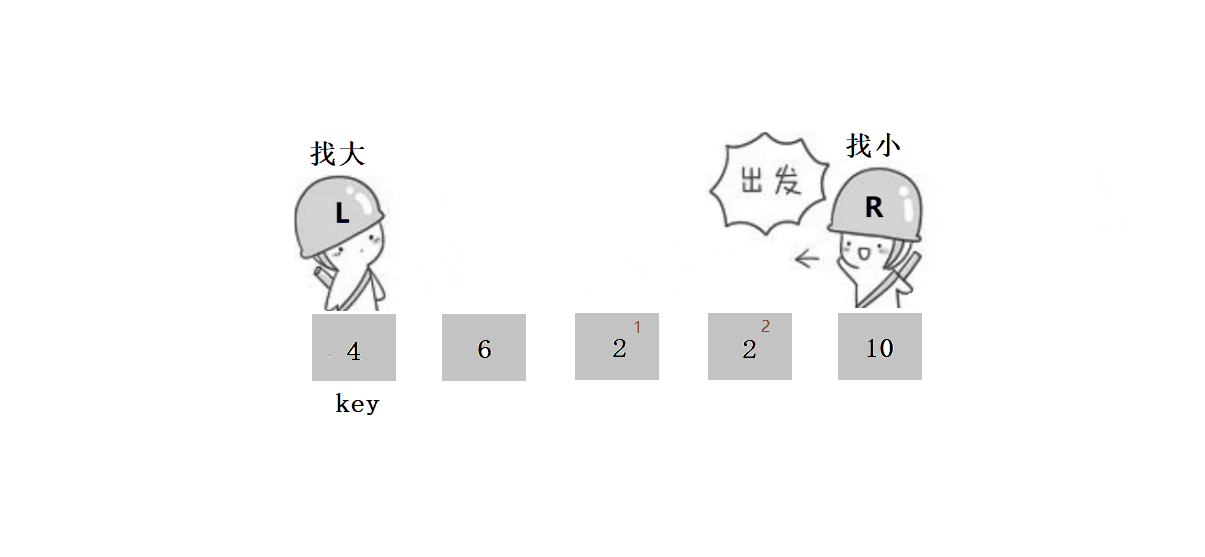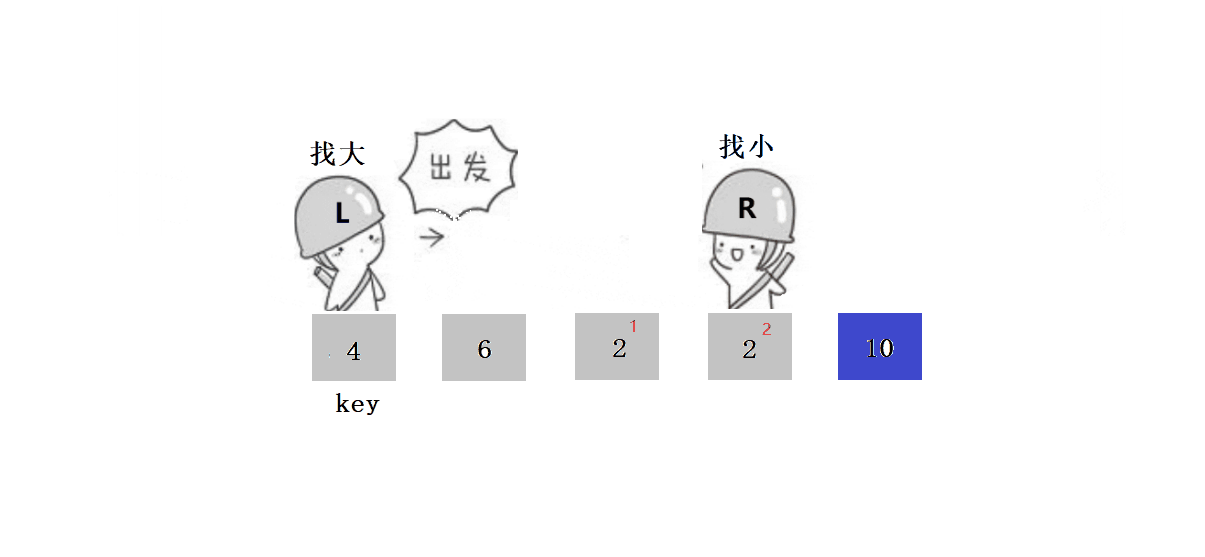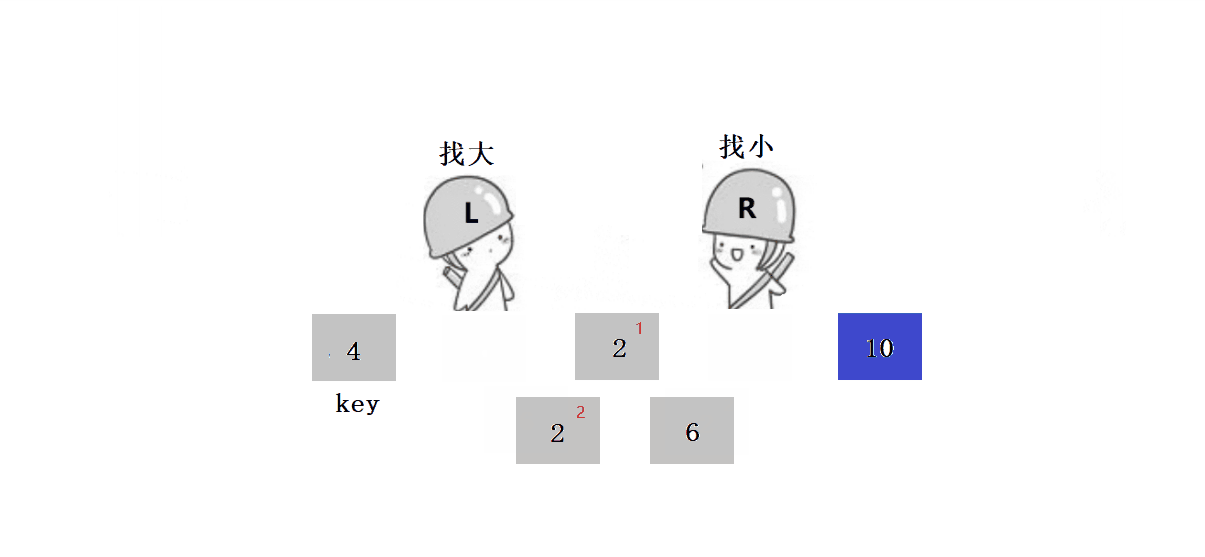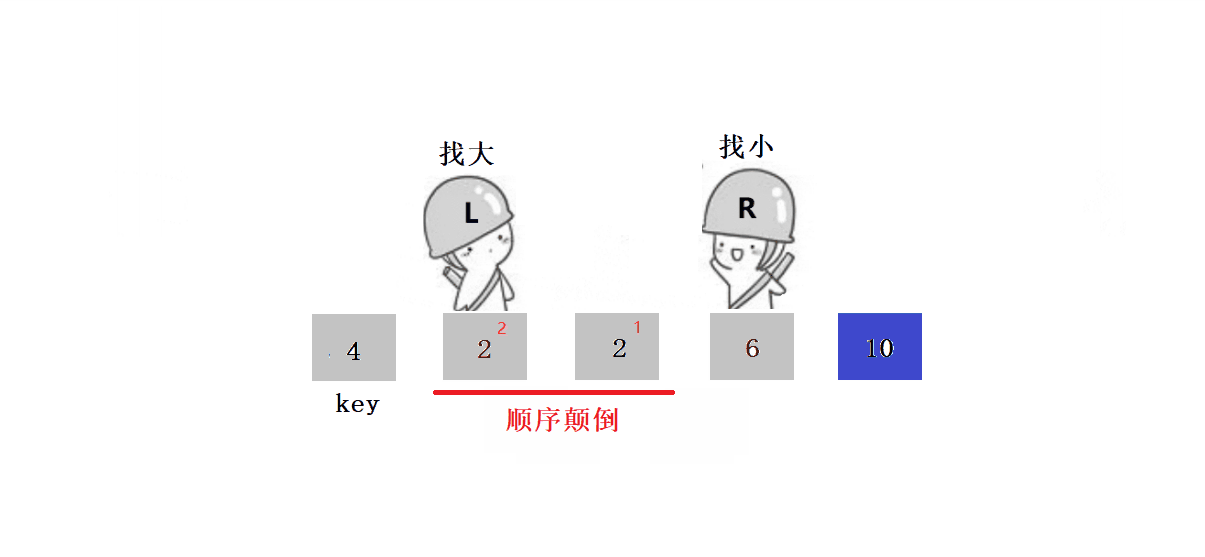
? ? ? ? ? ? 2. ѡ��keyѡ������ߺ�,ѡ���ұ����ߵ�����:
????????ԭ��:��ΪҪȷ������λ�õ�ֵ,��keyС���߾���key��λ�á�
????????������������:
? ? ? ? ? ? ? ? 1.?L����,Lͣ����,Rȥ����L��
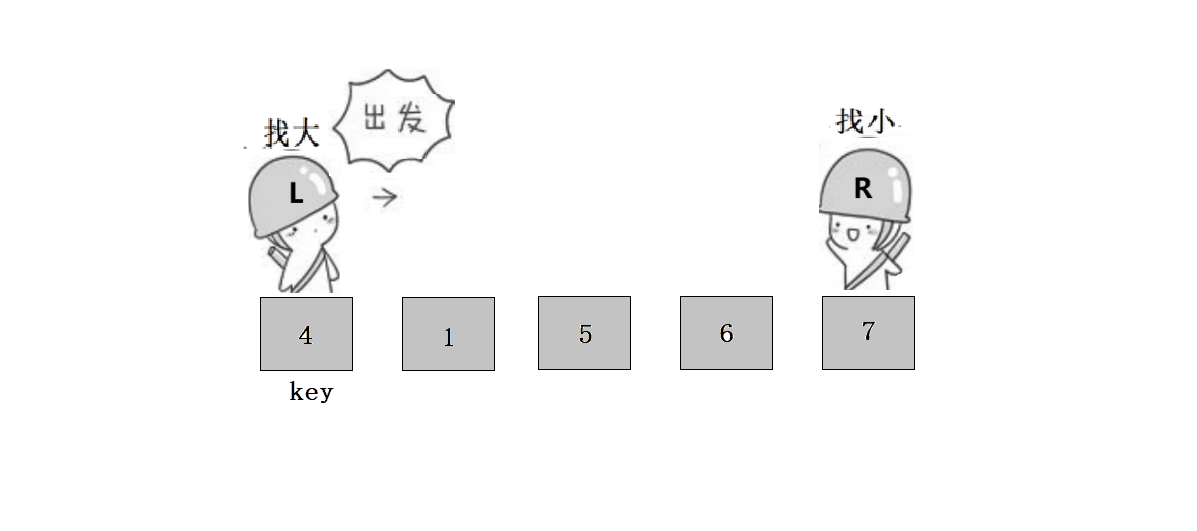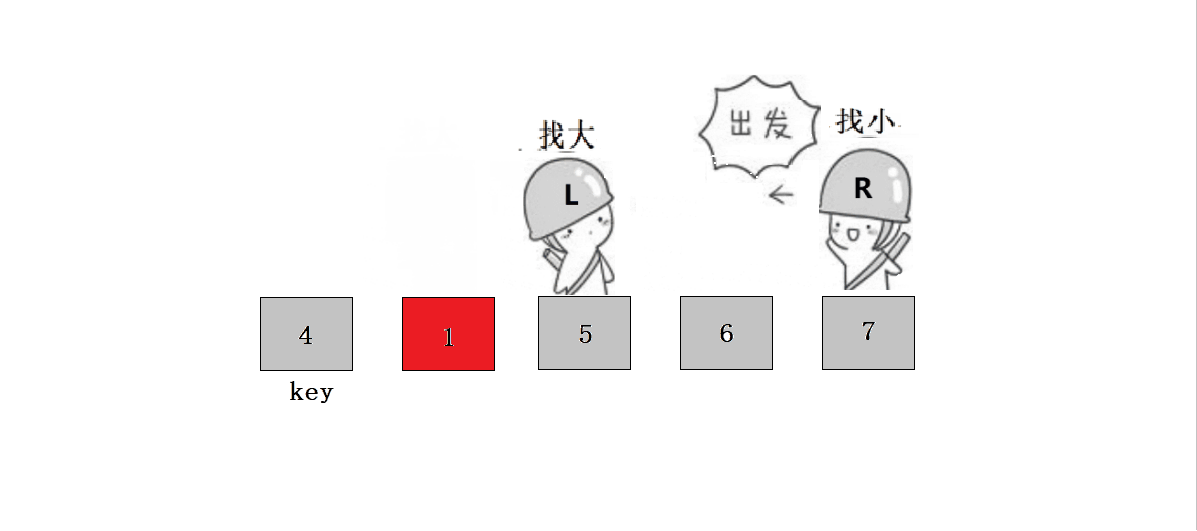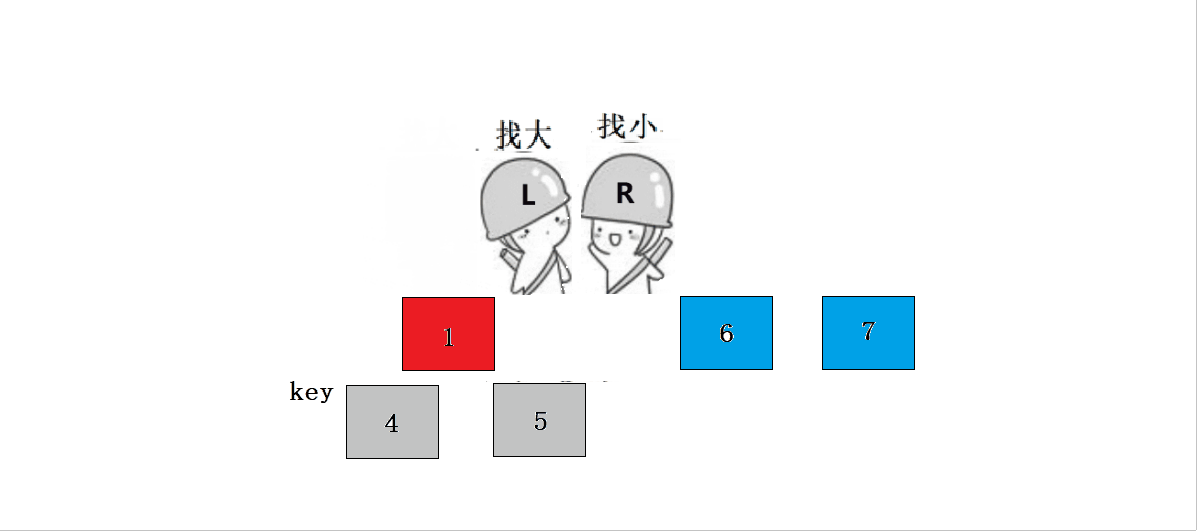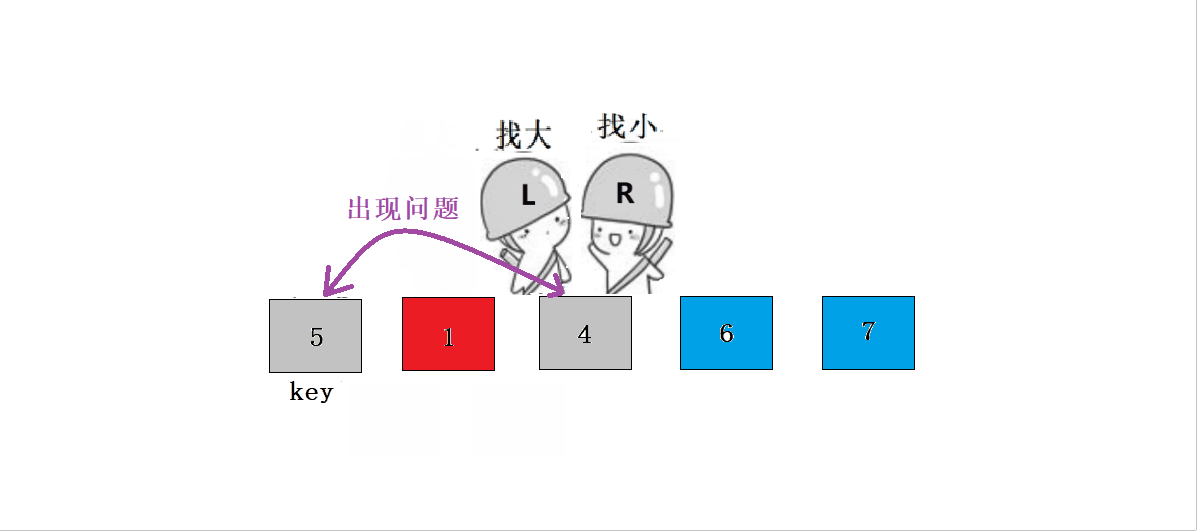
? ? ? ? ? ? ? ??2.?L����,ֱ����R����
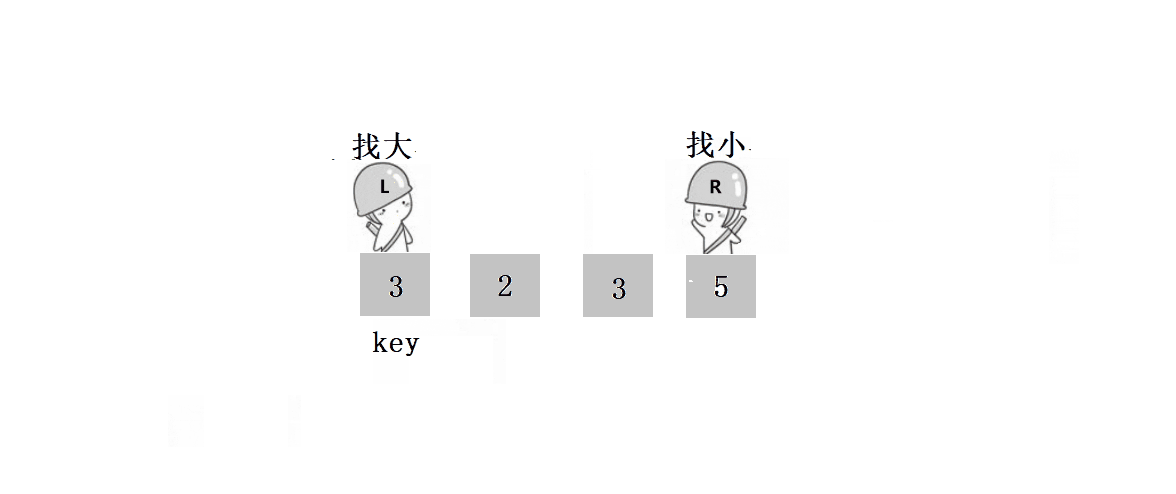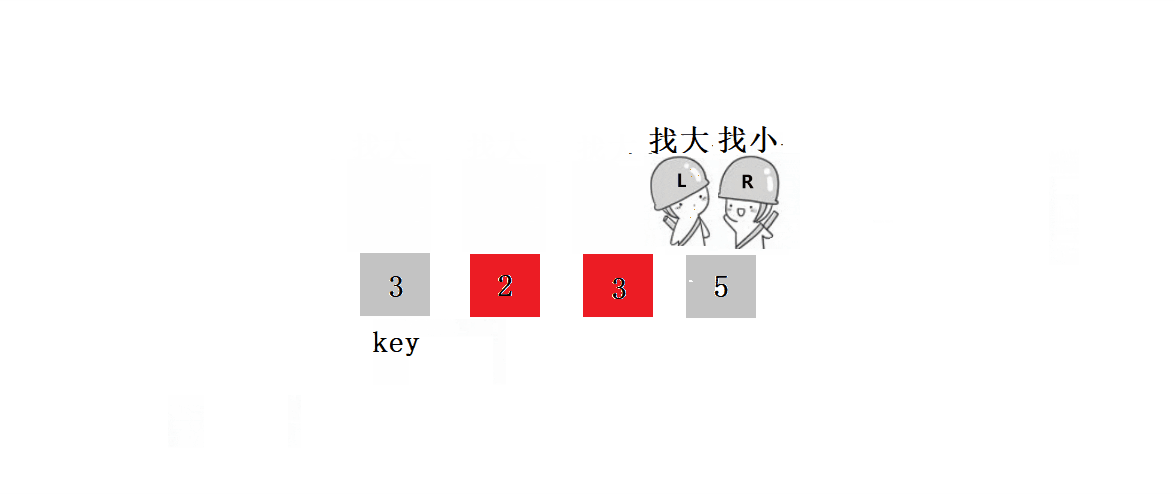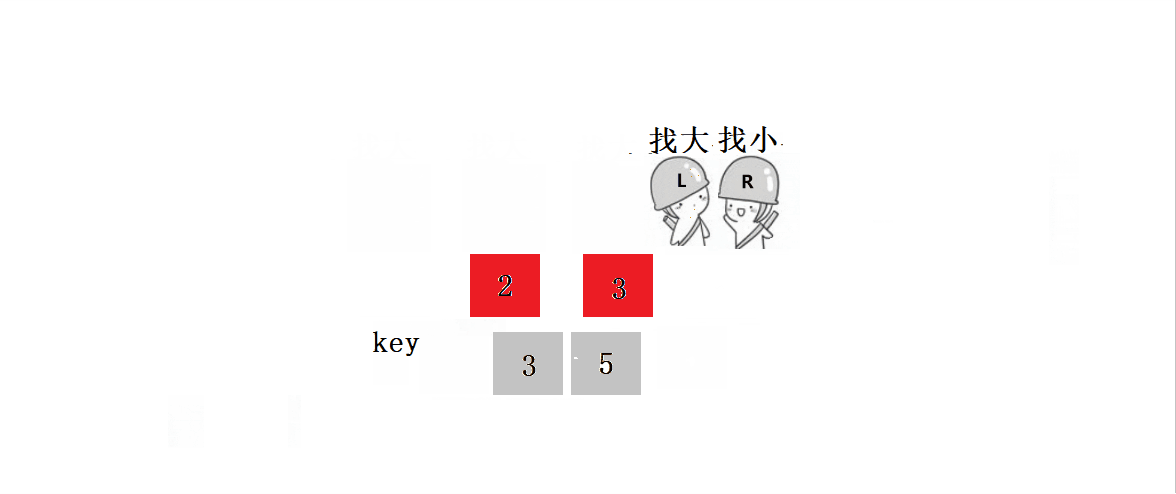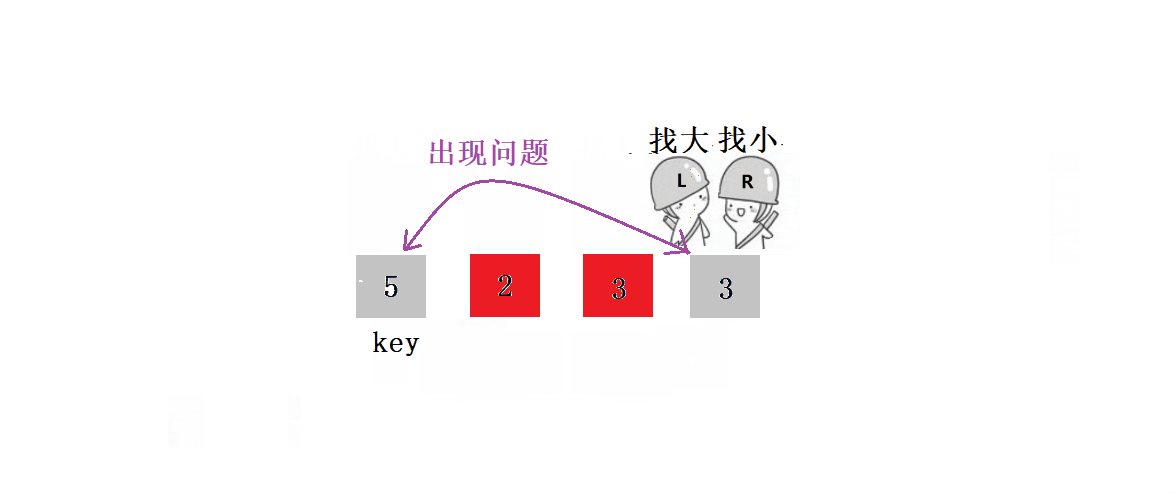
? 2.??�ڿӰ汾:
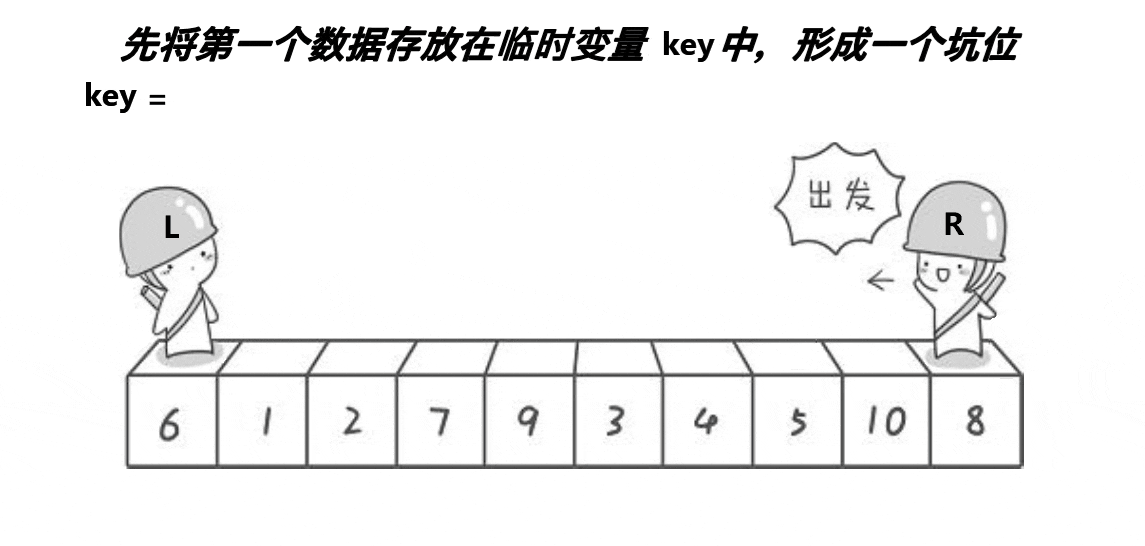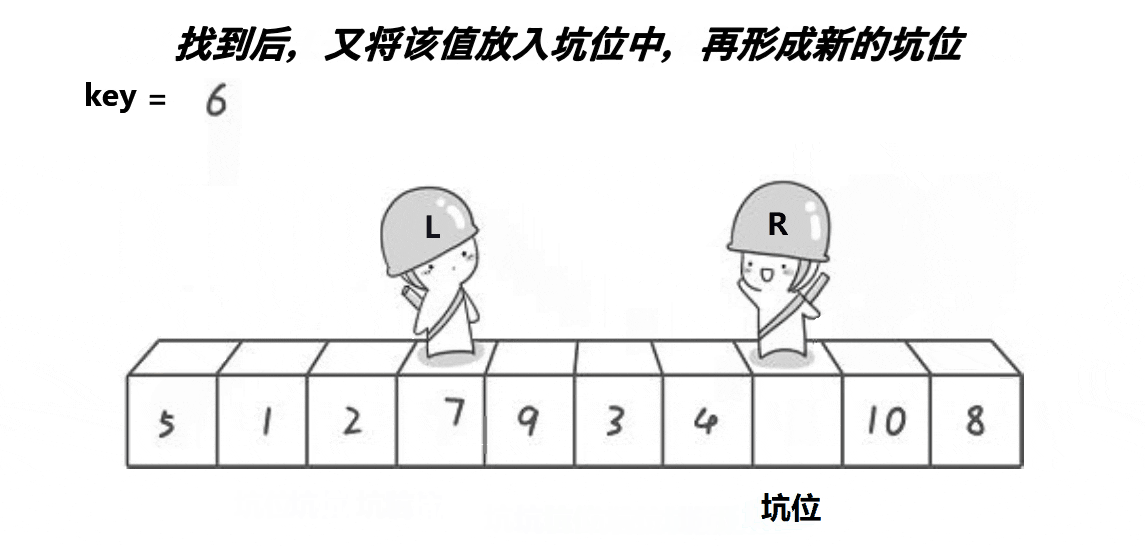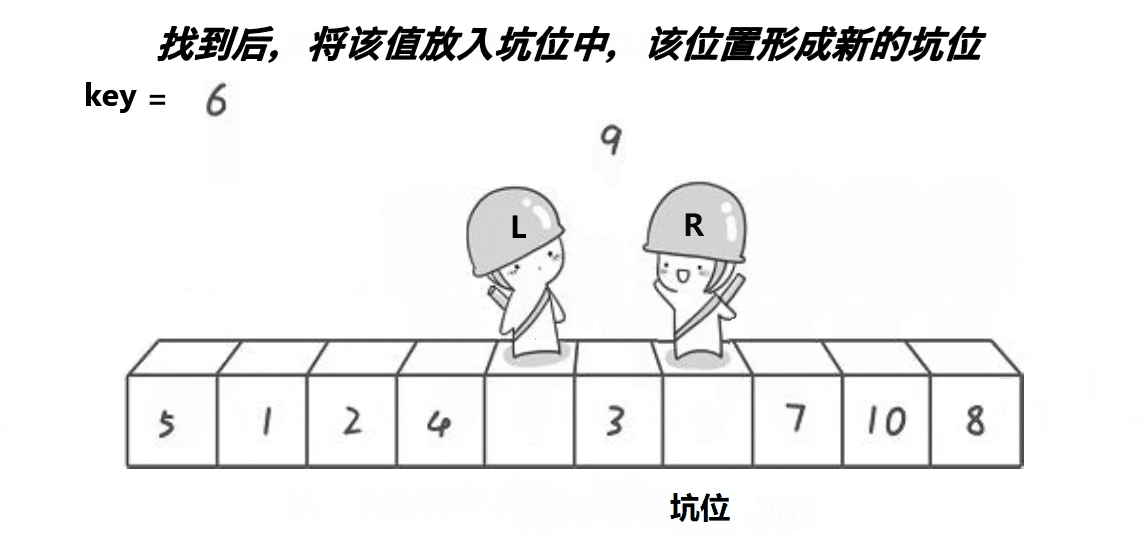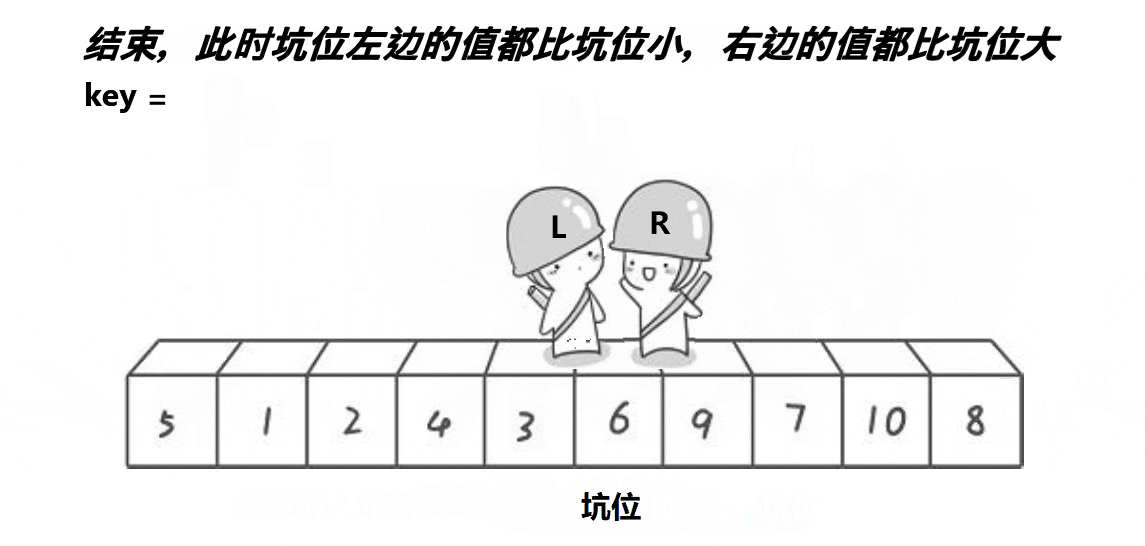
//���ݽ���
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//�ڿӰ汾
//��right�ߵ����ݵ�������С�ڻ����������������,left��ͬ����֮��������
void QuickSort2(int* a, int begin, int end)
{
assert(a);
if (begin >= end)
return;
//keyi:�ӵ��±�
//key: ����Ҫ����������
int right, left, keyi, key;
keyi = left = begin;
right = end;
key = a[keyi];
//���ݴ�С���ӽ����
while (left < right)
{
while (left < right && a[right] >= key) //>=������,<=�ǽ���
--right;
Swap(&a[keyi], &a[right]);
keyi = right;
while (left < right && a[left] <= key) //<=������,>=�ǽ���
++left;
Swap(&a[keyi], &a[left]);
keyi = left;
}
a[left] = key;
keyi = left;//��ʱkeyiΪ�Ѿ������õ�����
//[begin, keyi - 1] keyi [keyi + 1, end]
QuickSort2(a, begin, keyi - 1);
QuickSort2(a, keyi + 1, end);
}�ڿӰ汾�״���
(��ǰ�������:hoare���״���,��ͬС��)
? 3.?ǰ��ָ��汾:
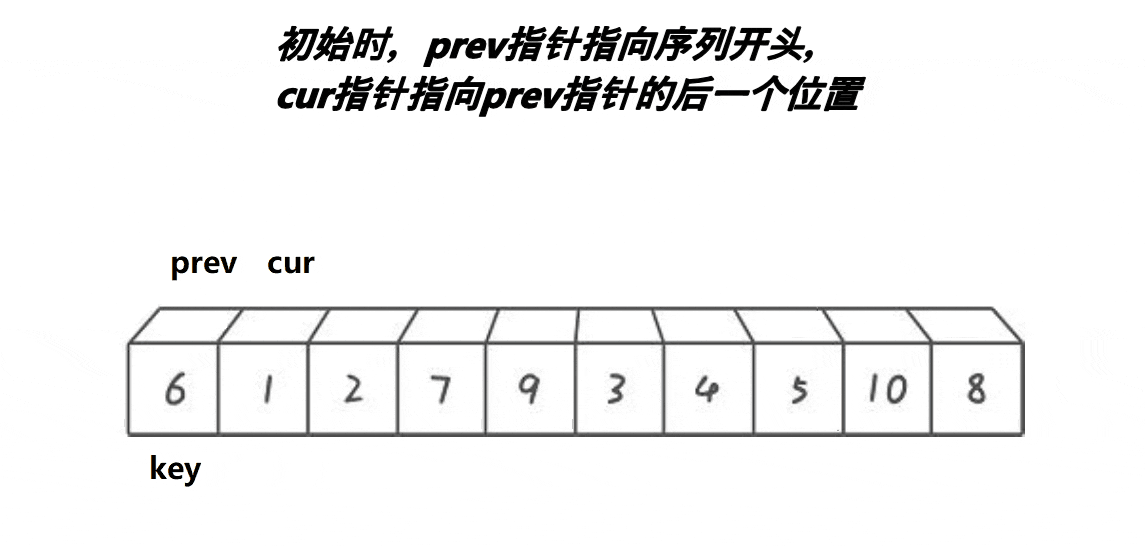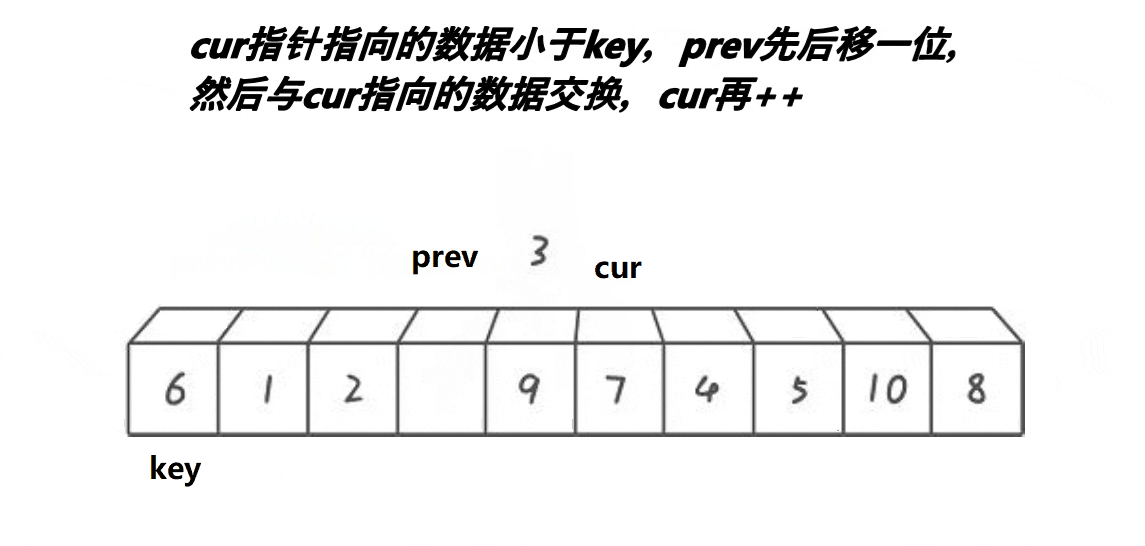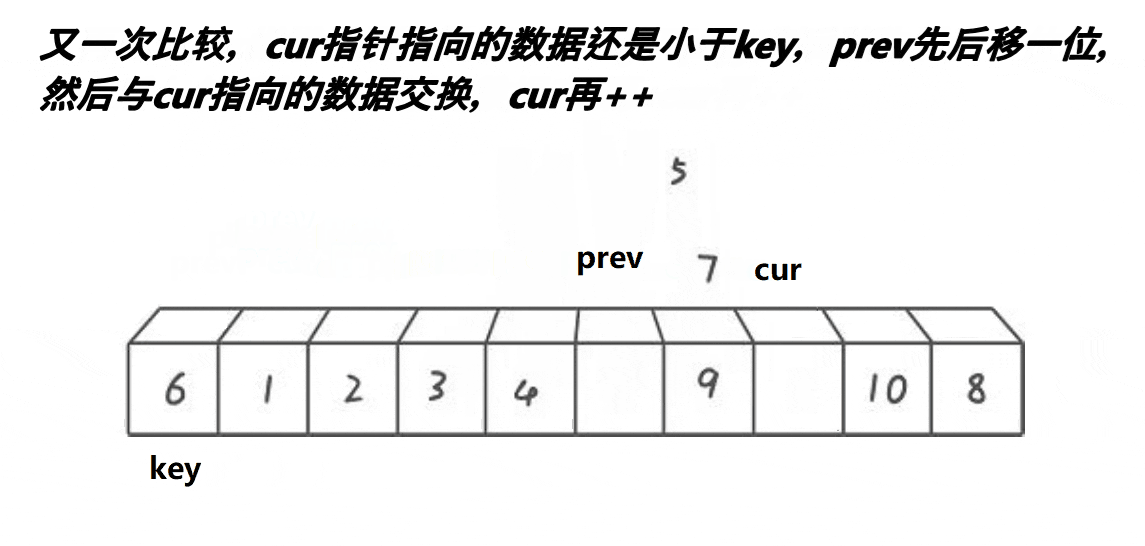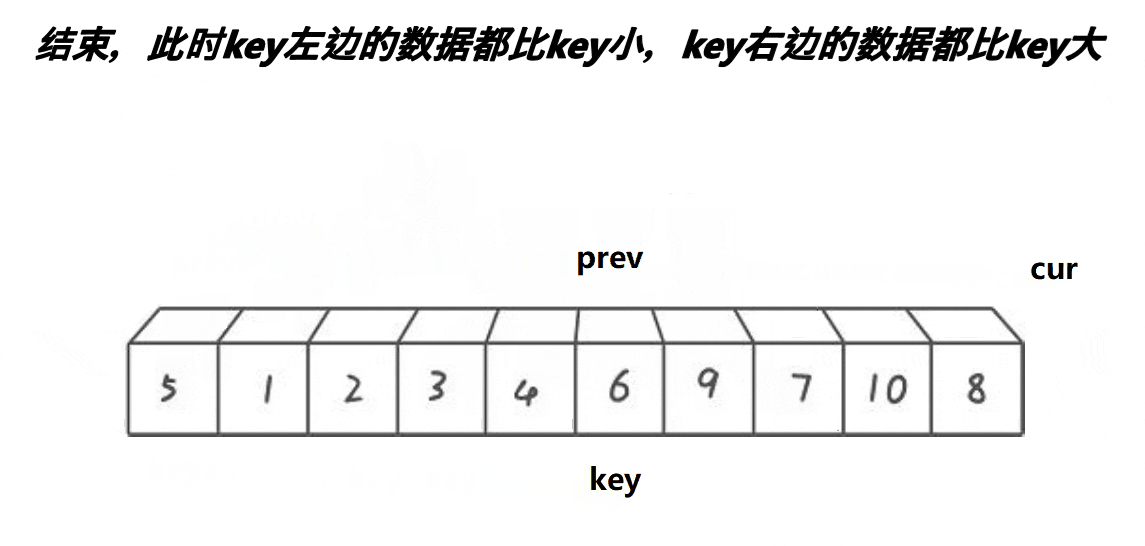
//���ݽ���
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//Ϊ�±�Ϊkeyi��key����
int Pointer_QSort(int* a, int begin, int end)
{
assert(a);
//keyi:����Ҫ�����������±�
int keyi = begin;
int prev, cur;
prev = begin, cur = begin + 1;
while (cur <= end)
{
// curλ�õ�֮С��keyiλ��ֵ
//<������,>�ǽ���
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[prev], &a[cur]);
++cur;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
//ǰ��ָ��汾
void QuickSort3(int* a, int begin, int end)
{
assert(a);
if (begin >= end)
return;
int keyi = Pointer_QSort(a, begin, end);
//[begin, keyi - 1] keyi [keyi + 1, end]
QuickSort3(a, begin, keyi - 1);
QuickSort3(a, keyi + 1, end);
}2.1. ��������������ܽ�:
- ��������������ۺ����ܺ�ʹ�ó������DZȽϺõ�,���ԲŸҽ���������
- ʱ�临�Ӷ�:O(N*logN)(���ΪO(N*logN) ~ ���ΪO(N^2))
- �ռ临�Ӷ�:O(logN)(���ΪO(logN) ~ ���ΪO(N))
- �ȶ���:���ȶ�
2.1.1 ʱ�临�Ӷ�:
????????????????���O(N*logN)�����:
? ? ? ? ? ? ? ? ? ? ? ?���������Ƿ��η�ʵ�ֵ�,��ô��������ʱ�����,�δ���������,ֱ���������

? ? ? ? ? ? ? ? ? ? ? ?��:O(N*logN)
????????????????���O(N^2)�����:?
? ? ? ? ? ? ? ? ? ? ? ?���������Ƿ��η�ʵ�ֵ�,�������������:
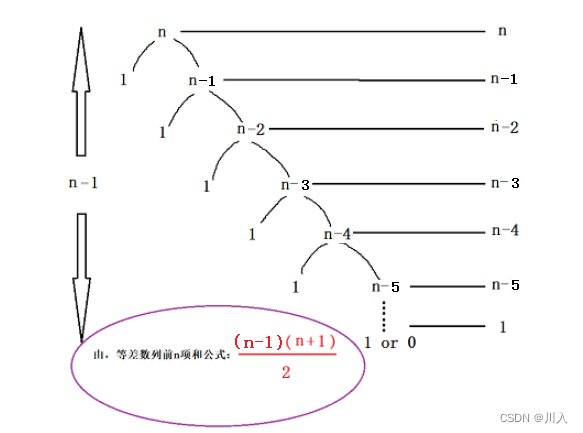
? ? ? ? ? ? ? ? ? ? ? ?��:O(N^2)
2.1.2 �ռ临�Ӷ�:
????????????????��Ҫ�ǵݹ���ɵ�ջ�ռ��ʹ�á�
????????????????���O(logN)�����:
? ? ? ? ? ? ? ? ? ? ? ?��Ҫ����logn�ݹ����,��ռ临�Ӷ�Ϊ?O(logn)��
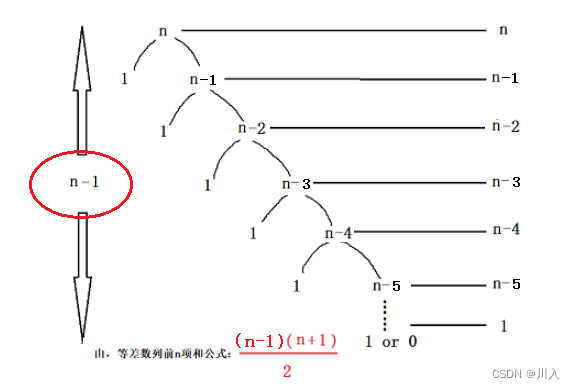
????????????????���O(N)�����:
? ? ? ? ? ? ? ? ? ? ? ?��Ҫ����n�\1�ݹ����,��ռ临�Ӷ�ΪO(n)��
2.1.3 �ȶ���:
2.2?����������Ż�:
? ? ? ? �Ż�:ʱ�临�Ӷȵ�������ռ临�Ӷȵ�������
2.2.1?ʱ�临�Ӷȵ��Ż�:
//����ȡ��
int GetMidIndex(int* a, int begin, int end)
{
int midi = (begin + end) / 2;
if (a[begin] < a[midi])
{
if (a[end] < a[begin])
return begin;
else if (a[end] < a[midi])
return end;
else
return midi;
}
else if (a[midi] < a[begin])
{
if (a[end] < a[midi])
return midi;
else if (a[end] < a[begin])
return end;
else
return begin;
}
}
? ? ? ? �����,��key��������������ֵ����Сֵ��ʱ��ʱ�临�Ӷ�ΪO(n^2),��ô,����������ȡ�з�ֹ������ķ�����
2.2.2?�ռ临�Ӷȵ��Ż�:
? ? ? ? �����ĵݹ��ÿ����һ��,Ϊ2������������������ֻҪ���Ǽ������һ��,�Ϳ���ֱ�Ӽ���һ��Ŀռ�����á�����,ѡ����һ����ʱ��Ͳ�ʹ�õݹ�,��ʹ��ֱ�Ӳ������������õ�ѡ��
�� ��ѡ��������:?
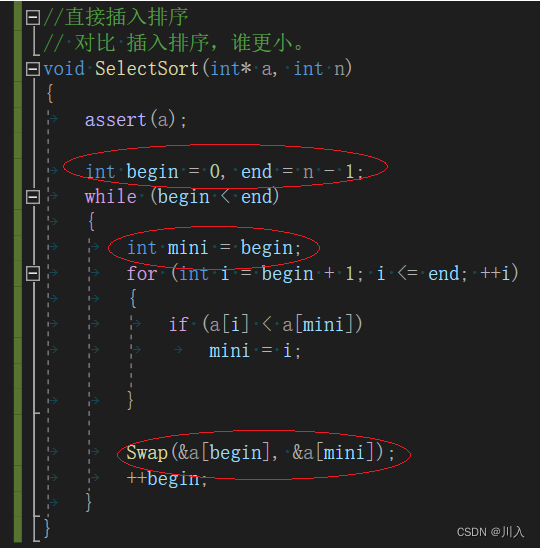
? 1��?ֱ��ѡ������:
- ��Ԫ�ؼ���array[i]--array[n-1]��ѡ��ؼ������(С)������Ԫ�ء�
- ������������Ԫ���е����һ��(��һ��)Ԫ��,����������Ԫ���е����һ��(��һ��)Ԫ�ؽ�����
- ��ʣ���array[ i ] ~?array[ n - 2 ](array[ i + 1 ] ~ array[ n - 1 ])������,�ظ���������,ֱ������ʣ��1��Ԫ�ء�
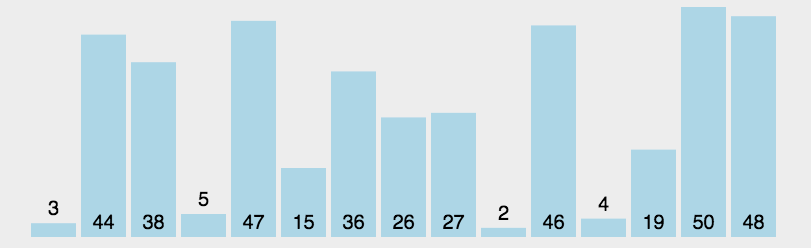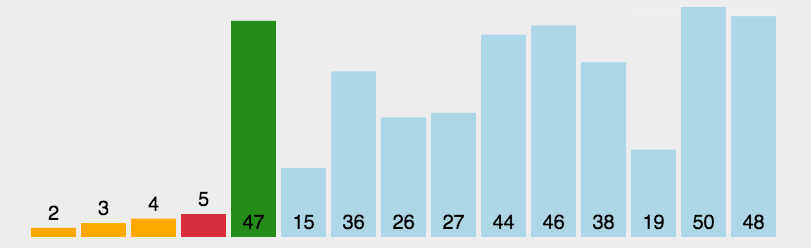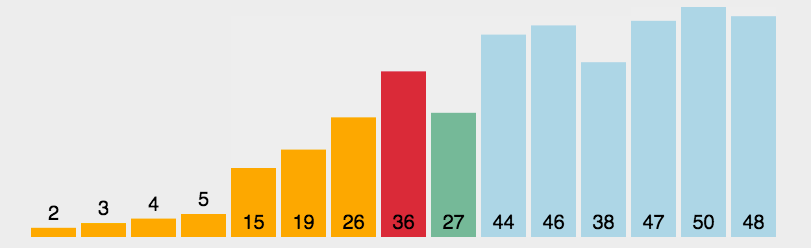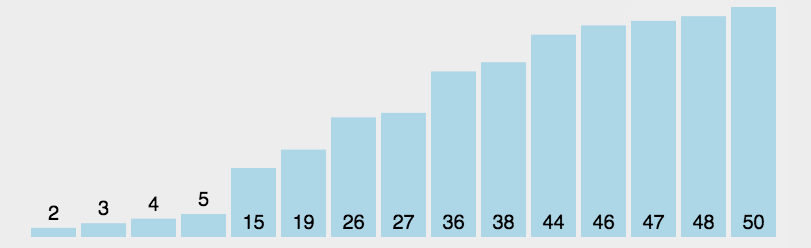
//ֱ�Ӳ�������
// �Ա� ��������,˭��С��
void SelectSort(int* a, int n)
{
assert(a);
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin;
for (int i = begin + 1; i <= end; ++i)
{
if (a[i] < a[mini])
mini = i;
}
Swap(&a[begin], &a[mini]);
++begin;
}
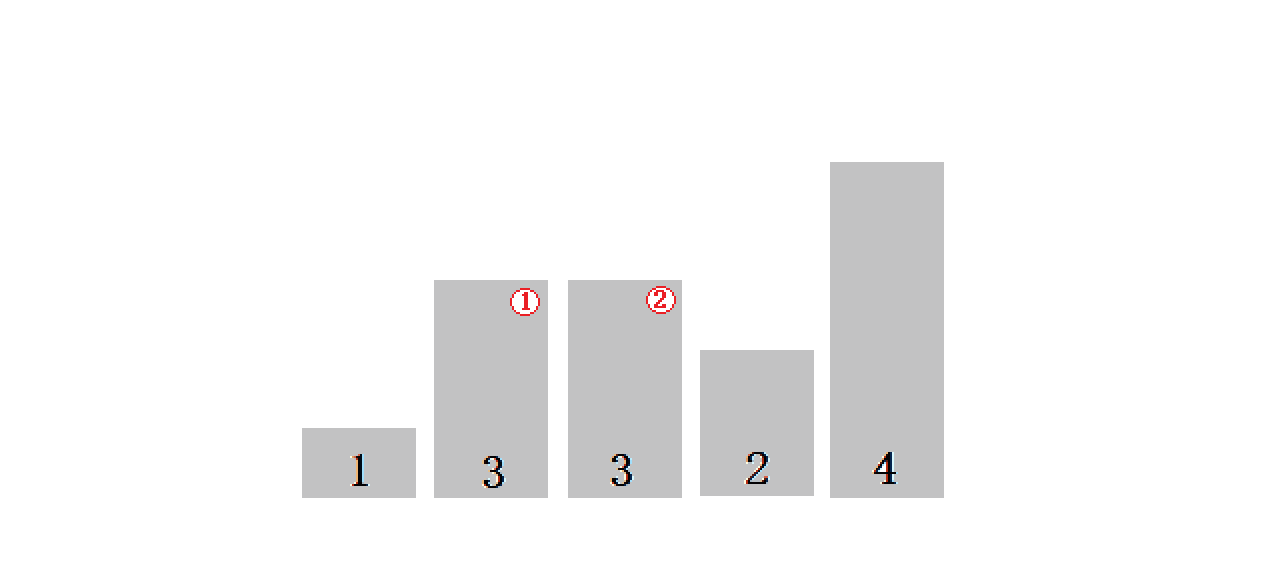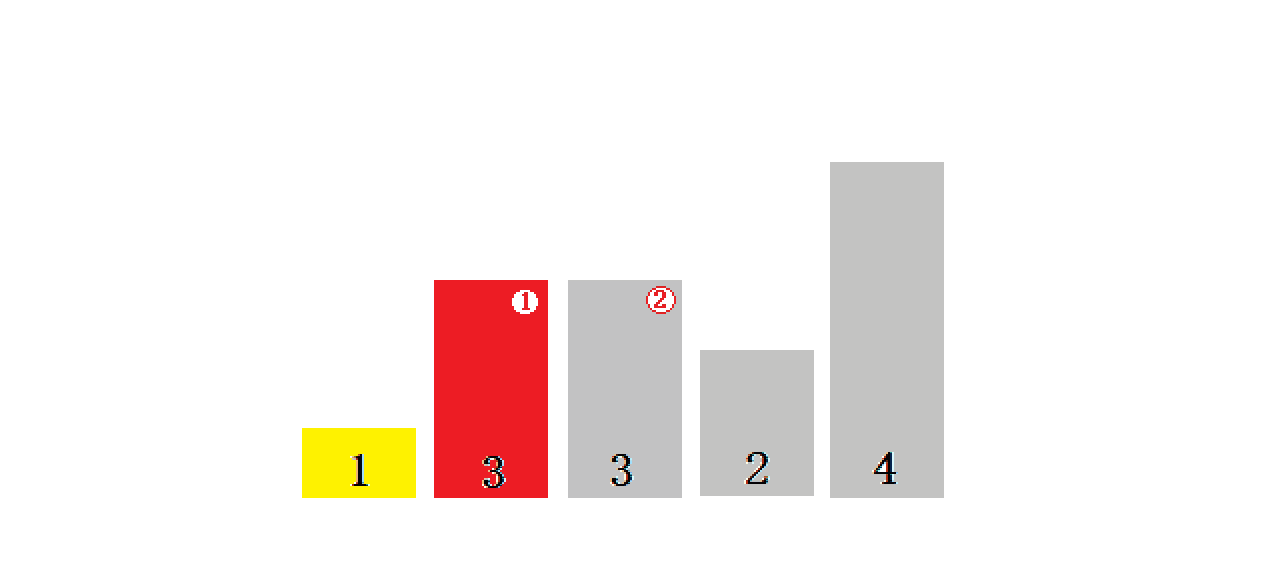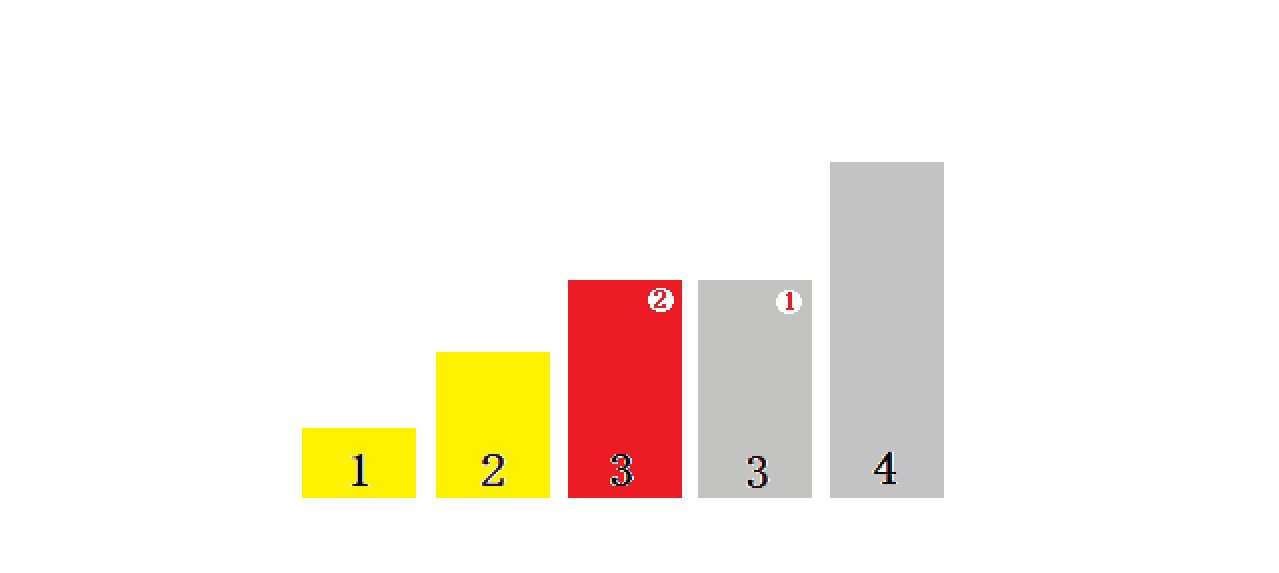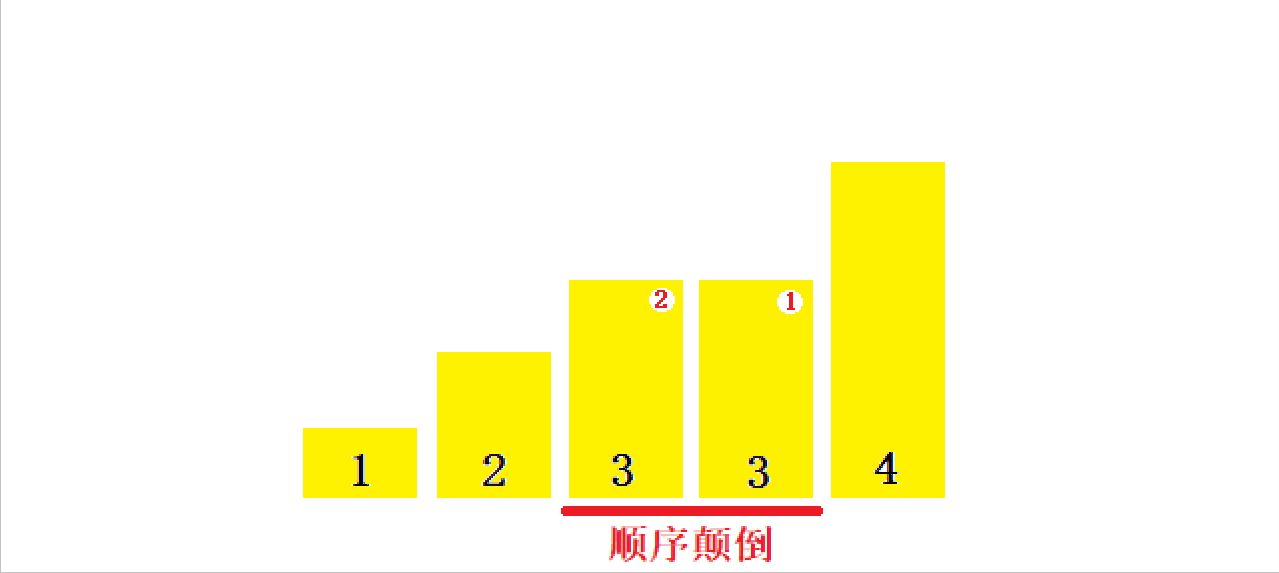
}1.1?ֱ��ѡ������������ܽ�:
- ֱ��ѡ������˼���dz�������,����Ч�ʲ��Ǻܺá�ʵ���к���ʹ��
- ʱ�临�Ӷ�:O(N^2)
- �ռ临�Ӷ�:O(1)
- �ȶ���:���ȶ�
1.1.1 ʱ�临�Ӷ�:
????????????????ʱ�临�Ӷ�:O(N^2)
? ? ? ? ? ? ? ? ? ? ? ?�dz����ĵȲ�����:n, n-1, n-2, ���� 1��
1.1.2?�ռ临�Ӷ�:
????????????????�ռ临�Ӷ�:O(1)
1.1.3 �ȶ���:?
?
??2�� ������:
//���ݽ���
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//���µ���
void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{ //>���,<��
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
//>���,<��
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//������
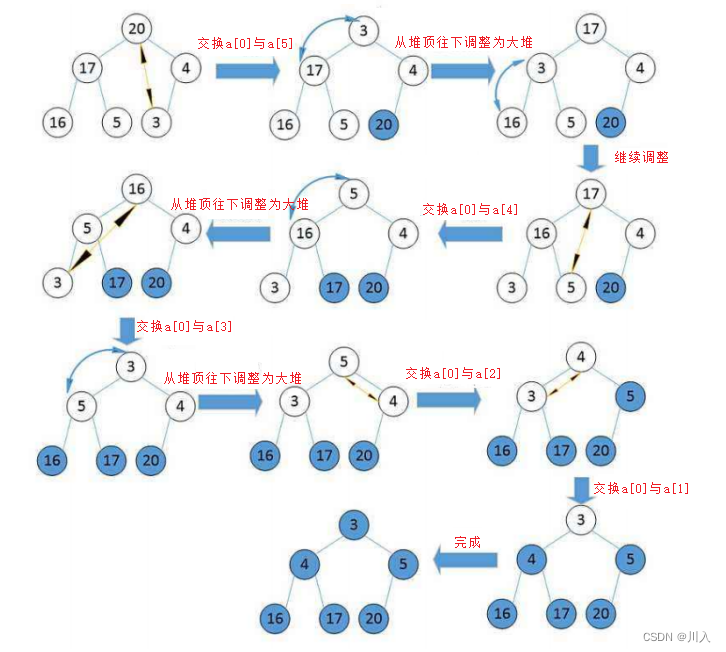
void HeapSort(int* a, int n)
{
assert(a);
// ����,�ȴ��������Ҷ���ϵĸ�(����Ϊ(n - 2) / 2��ʼ����
// ����С�Ķ�(���Ķ�)
for (int i = (n - 2) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
//end:��ʾ���һ��λ��
int end = n - 1;
//ֻʣһ����ʱ,�Ͳ���Ҫ������
while (end > 0)
{
//0λ�ú����һ��λ�ý���
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}1.?�������Ҫ�������:
1.1?��������:
? ? ? ? ? �������µ���,��Ҫ���ڵ�Ķѳ�����С��,����ᵼ�¶ѵĻ���,�������һ��δ����Ϊ�ѵ�����,�����a[0]Ϊ���ڵ�,�ᵼ�¶ѵĻ��ҡ�

- ��������ĸ��ڵ�
- ���Ƚϵ��ӽڵ�
- �ȽϺ���ѡ�����ӽڵ�
- ���ڵ�ʱ�ĸ��ڵ�,������õĽڵ�
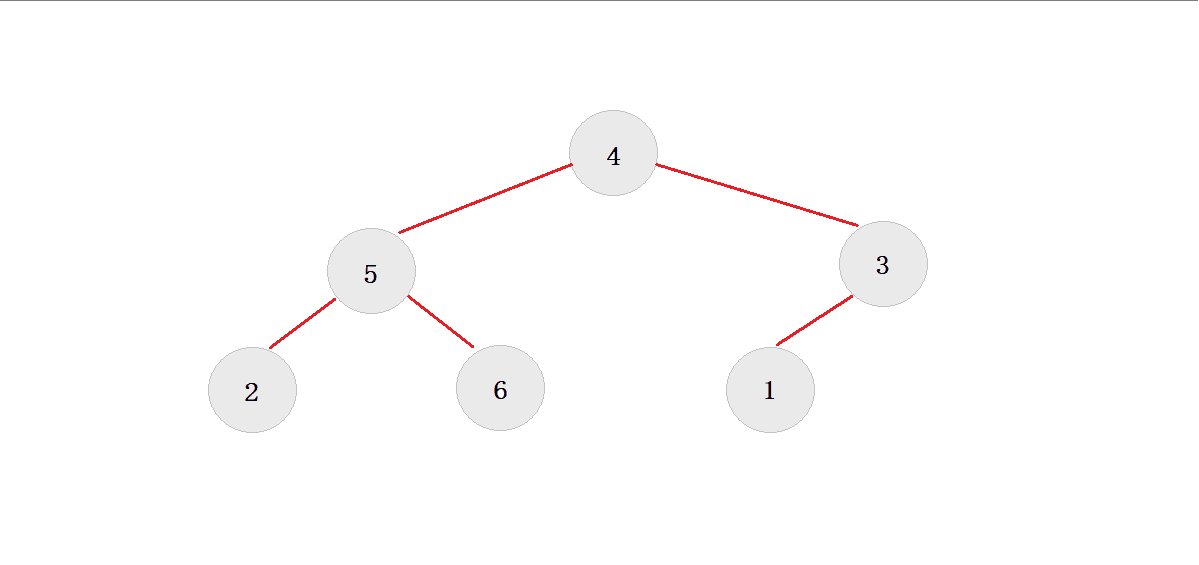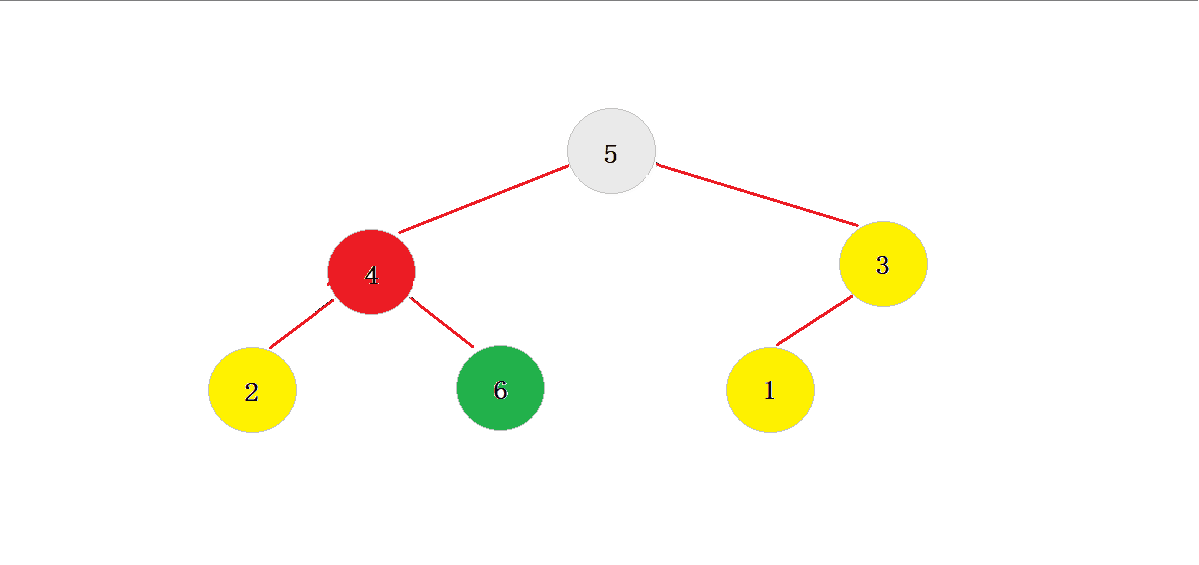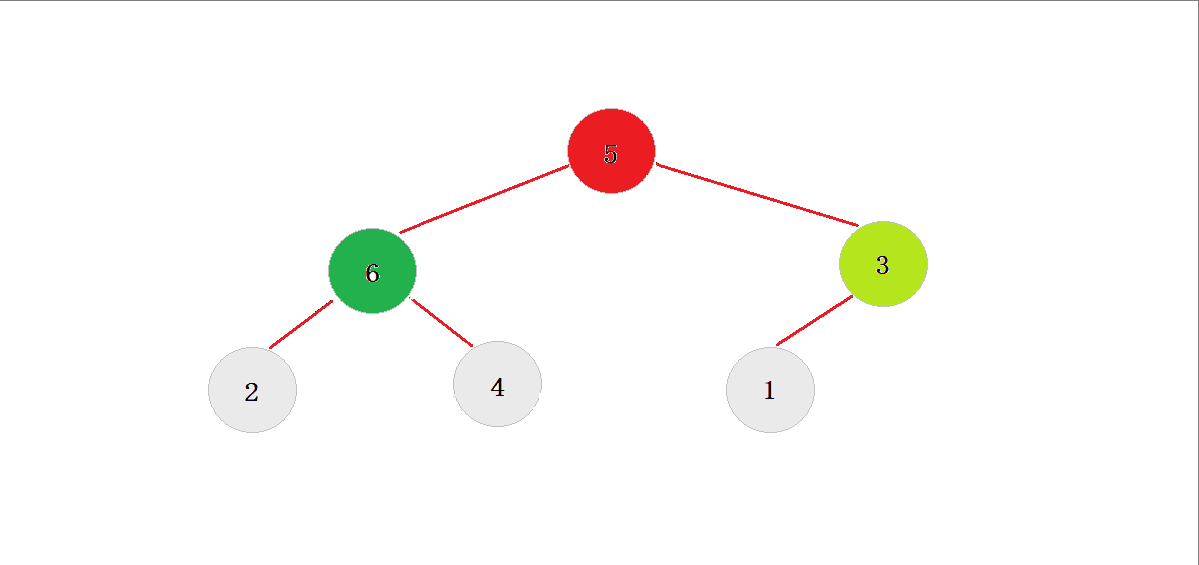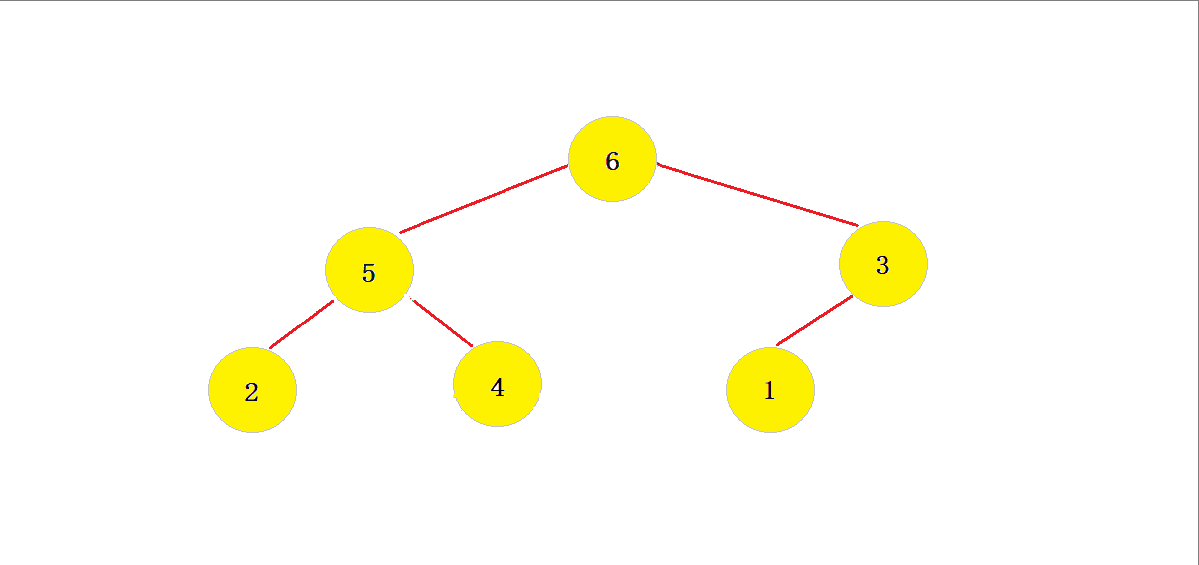
1.2 ���ô�С������:

2.1?������������ܽ�:
- ������ʹ�ö���ѡ��,Ч�ʾ��˺ܶࡣ
- ʱ�临�Ӷ�:O(N*logN)
- �ռ临�Ӷ�:O(1)
- �ȶ���:���ȶ�
2.1.1?ʱ�临�Ӷ�:
????????����,������Ҫ֪�����½��ѵ�ʱ�临�Ӷ�:
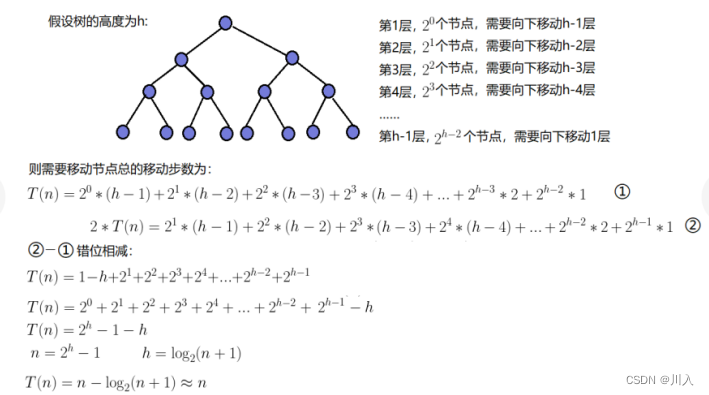
? ? ? ?��:O(N)��
? ? ? ?������С�ѵ�ʱ�临�Ӷ�:
? ? ? ? ����,ʱ�临�Ӷ�Ϊ:?O(N)��
(��������,ԭ���Ǵӵ�1���������㿴,����������Ǵ����һ�����ڵ㿪ʼ,���Ǿʹӵ�h-1�㿴)
???????���ô�С�������ʱ�临�Ӷ�:
?? ? ? ����,ʱ�临�Ӷ�Ϊ:?O(N*logN)��
? ����:
? ? ? ?��֮ǰ,�����Ѿ��������,�����������Ϊ���ǽ����һ��Ԫ�����һ��Ԫ�ؽ���λ�á�Ȼ�� n-1 ,����Ψһһ��������ľ��ǵ�һ��Ԫ�ء������������������Ҫ������ײ�,����ʱ�临�Ӷ�ΪO(logN)��
? ȫ��:
? ? ? ?������O(logN),һ����n��Ԫ��,���Ծ���:O(N*logN)��
2.1.2?�ռ临�Ӷ�:
? ? ? ?û��ʹ�õݹ�,���ұ����Ĵ���Ҳ�dz�����������O(1)��
2.1.3?�ȶ���:
- ��������ĸ��ڵ�
- ���Ƚϵ��ӽڵ�
- �ȽϺ���ѡ�����ӽڵ�
- ���ڵ�ʱ�ĸ��ڵ�,������õĽڵ�
? ? ? ?
�� ���鲢������:
? 1���鲢����:
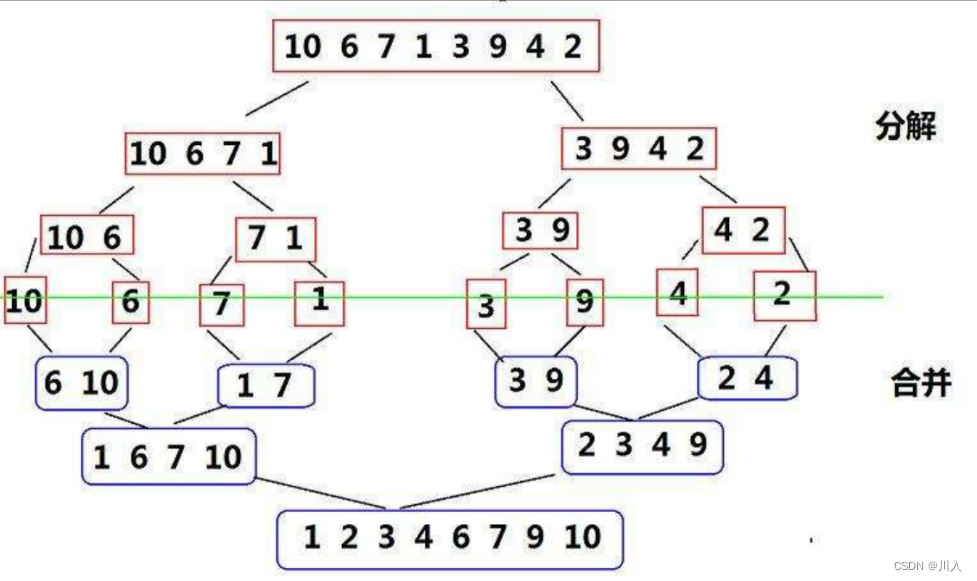
? ? ? ? ? ?��Ϊ�ݹ�ʵ�ֵķ���ͼ (�ݹ�ʵ����������)
1.1 ��д��ʽ
1.1 �ݹ鷽ʽ:
 ?
?
//�鲢����ĺ���ʵ��
void _MerceSort(int* a, int begin, int end, int* tmp)
{
assert(a && tmp);
if (begin >= end)
return;
//���õݹ�
int midi = (begin + end) / 2;
_MerceSort(a, begin, midi, tmp);
_MerceSort(a, midi + 1, end, tmp);
// [begin, mid] [mid+1, end] ���εݹ�,������������
int begin1 = begin, end1 = midi;
int begin2 = midi + 1, end2 = end;
int j = begin1;
//���бȽ�����
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[j++] = a[begin1++];
else
tmp[j++] = a[begin2++];
}
//��ֹδ�������
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
//���ǿ�����ȥ
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//�鲢����
void MerceSort(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
_MerceSort(a, 0, n - 1, tmp);
free(tmp);
}
1.2 �ǵݹ鷽ʽ:
//�鲢����
void MerceSortRone(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// end1Խ�����begin2Խ��,����Բ��鲢��
if (end1 >= n || begin2 >= n)
{
break;
}
else if (end2 >= n)
{
end2 = n - 1;
}
int m = end2 - begin1 + 1;
int j = begin1;
//���бȽ�����
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[j++] = a[begin1++];
else
tmp[j++] = a[begin2++];
}
//��ֹδ�������
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
//���ǿ�����ȥ
memcpy(a + i, tmp + i, sizeof(int) * m);
}
gap *= 2;
}
free(tmp);
}2. �鲢����������ܽ�:
- �鲢��ȱ��������ҪO(N)�Ŀռ临�Ӷ�,�鲢�����˼��������ǽ���ڴ����е����������⡣
- ʱ�临�Ӷ�:O(N*logN)
- �ռ临�Ӷ�:O(N)
- �ȶ���:�ȶ�
2.1?ʱ�临�Ӷ�:
? ? ? ? ? ��Ҳ���ǹ鲢���������,�����������ſ��������ͬ���ٶ�,�����DZ���,�ڸ���������������ﵽ���˿��ǵ�O(N^2),���ǹ鲢����,��Զ��O(N*logN)��
? ? ? ? ? �鲢�����ʵ�־������������ö���ʵ�֡�
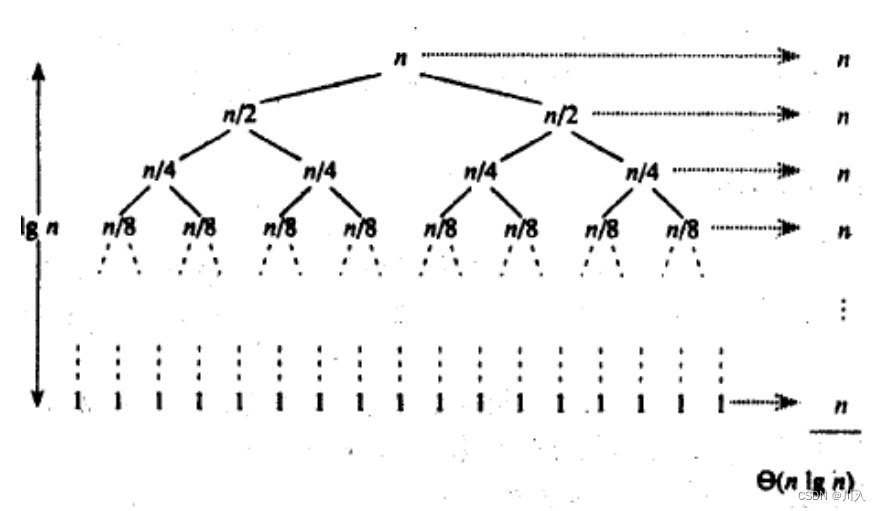
? ? ? ? ? ��������ʵ�������ڵݹ�ʵ�������۲����(�ݹ��൱�� 1 ~ lgN ��,�ǵݹ��൱�� lgN ~ 1 ��)

2.2?�ռ临�Ӷ�:
? ? ? ? ? �鲢������ʱ�临�Ӷȵ�������������Ч��,��Ҳ���������ڿռ��Ͼ��о������,�ڳ����������������ȶ���O(n)�Ŀռ�ľ����ġ�
? ? ? ? ?������Ҫ����һ�������������ͬ����С�Ŀռ䡣��O(n)��
2.3?�ȶ���:
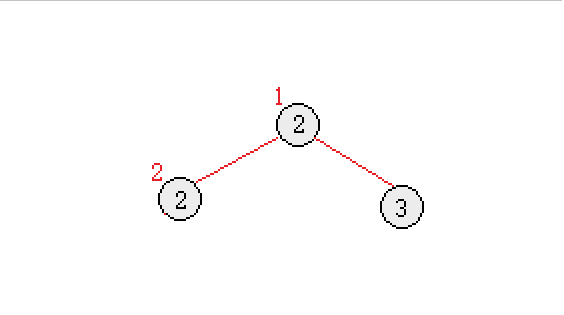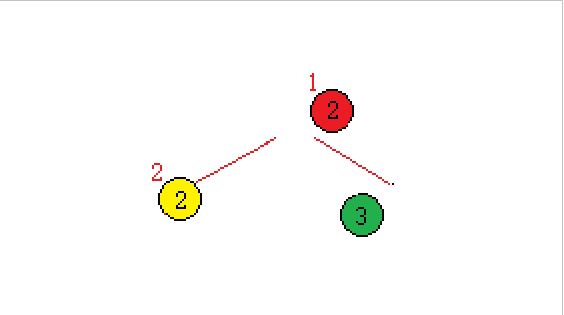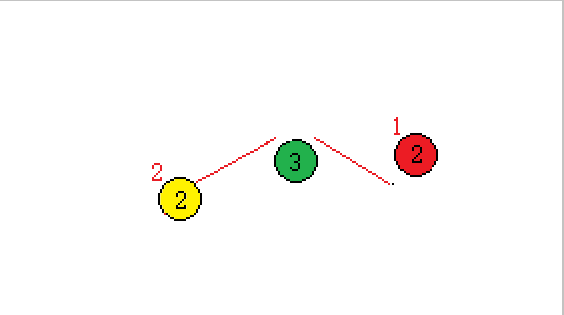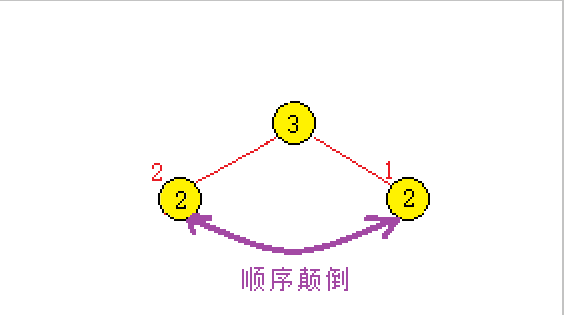
? ? ? ? ?[begin1,end1] �� [bgein2,end2] ֮ǰ,�����ڵ��ڵ�ʱ�� [begin1,end1] �еıض���ǰ�� [bgein2,end2]��

�� ���DZȽ�������:
? 1��?��������:
- ͳ����ͬԪ�س��ִ�����
- ����ͳ�ƵĽ�������л��յ�ԭ���������С�
//��������
void CountSort(int* a, int n)
{
//�ҳ����ֵ����Сֵ
int min = a[0], max = a[0];
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
// ͳ�ƴ���������
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
printf("malloc fail\n");
exit(-1);
}
memset(count, 0, sizeof(int) * range);
// ͳ�ƴ���
for (int i = 0; i < n; ++i)
{
count[a[i] - min]++;
}
// ��д-����
int j = 0;
for (int i = 0; i < range; ++i)
{
// ���ּ��ξͻ��д����i+min
while (count[i]--)
{
a[j++] = i + min;
}
}
}1. ��������ľ�����:
1.1 ����Ǹ����������ַ����Ͳ���������
?????????����,�������ݵĸ���ͳ��,���Ƕ�Ӧ�������±�� array[i]++ ��ͳ��,����ֻ��ͳ��������
1.2?������ݷ�Χ�ܴ�,�ռ临�ӶȾͻ�ܸ�,��Բ��ʺ�
? ? ? ? ?��Ϊ���ڼ�������Ĵ���,�Dz������ӳ��:
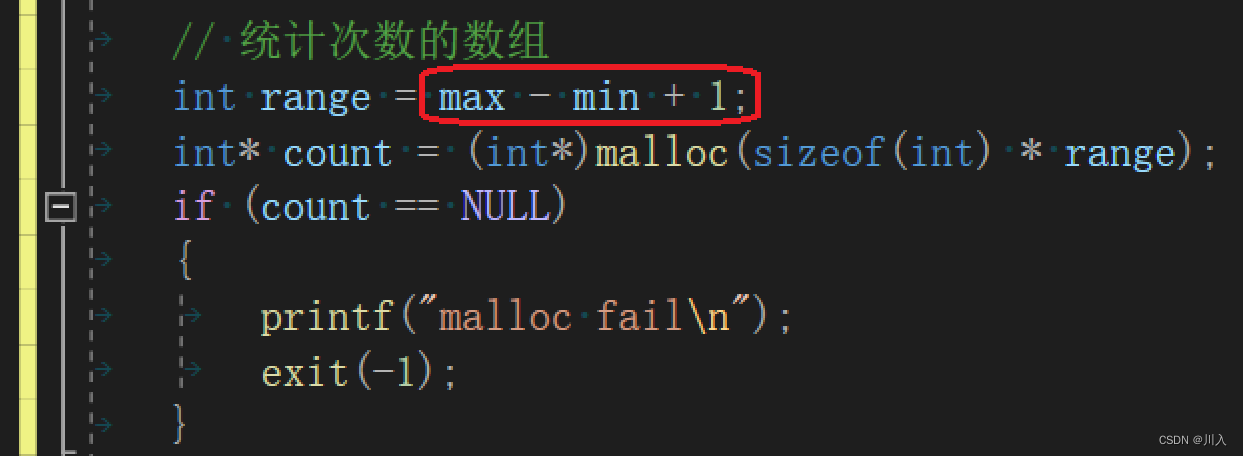
?? ? ? ? ?��˵,�Ҿ�����������:1 1000000,������鴴�����Dz���̫����?
2. ��������������ܽ�:
- �������������ݷ�Χ����ʱ,Ч�ʺܸ�,�������÷�Χ���������ޡ�
- ʱ�临�Ӷ�:O(MAX(N,��Χ))
- �ռ临�Ӷ�:O(��Χ)
- �ȶ���:�ȶ�
2.1 ʱ�临�Ӷ�:
????????O(MAX(N,��Χ))��
????????????????����N������:

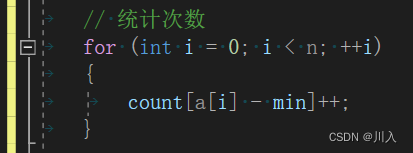
? ? ? ? ? ? ? ? ? ? ? ? ?����,����N�ĽǶ�,ʱ�临�Ӷ���:O(n)��
????????????????���ڷ�Χ������:

?? ? ? ? ? ? ? ? ? ? ? ? ����,���ڷ�Χ�ĽǶ�,ʱ�临�Ӷ���:O(��Χ)��
?? ? ? ? ?��˵,�Ҿ�����������:1 1000000,nΪ2,��Χȴ��999999������ʱ�临�Ӷ���:O(��Χ)������,ʱ�临�Ӷ�:O(MAX(N,��Χ))��(?Ҳ����˵��:O(N+��Χ) )
2.1 �ռ临�Ӷ�:
? ????????�ռ临�Ӷ�:O(��Χ)
2.1 �ȶ���:
????????ͳ����ͬ��ֵ�ĸ���,��˳��ӳ�䵽ԭ���顣