����Ŀ¼
һ�����ϸ���
1��Java�ж��ڸ������ݽṹ��ʵ��,���������õ��ļ���(�������ܹ���̬�������ȵ�����)��
2.����֮ǰ��ѧ��������:
��.����int a=10;
��.�������class Car{
String name;
int price;
}
��.����(����),����һ��ָ�����ȵ�����
Car[] cars = new Car[10];
��������ʱ,���������DZ仯��,�������鳤��һ������,�Ͳ��ܸı䡣��ҪƵ��������,������ŵ��Dz�ѯ�ٶȿ졣
Ȼ�������ݲ����Ƕ��ֶ�����,��ɾ�Ƚ϶��ѯ����,�����ṹ������ڳ�����,���ֲ�ͬ�洢��������,����ڳ�����,���ֲ�ͬ�洢��������,����java�����ṩ�����ͬ�Ĵ洢�ṹ(�Եײ�ṹ���а�װ):1.���� 2.���� 3.��ϣ 4.��
��������API
-������ϵ����
Java�ļ��Ͽ�����ɺܶ�ӿڡ������ࡢ��������ɵ�,��λ��java.util���С�

(Collection List Set MapΪ�ӿ�)
����Collection�ӿ�
1��Collection�ӿ�,��Ϊ���м��ϵĶ����ӿ�,���涨���˵��м��Ϲ��еķ���
��
��������,ɾ,��,��,�ж�,ת��Ϊ��
2��Collection, ArrayList������jdk5֮����������
����ͨ�������,Ϊ��������һ������,������ֻ�ܴ������õ���������
(�����н��鴢��ͬһ��������)��
3������������,���Դ洢��ͬ������,�ϸ��Ͻ������ǿ��Դ洢�κ����͵�(ֻ�ܴ洢��������)��
4������
boolean add(Object element);
boolean remove(Object element);
void clear();
int size();
boolean isEmpty();
boolean contains(Object element);
boolean retainAll(Collection c);��,�������ݷ����仯����true,���䷵��false
c.add("a");
c1.addAll(c);//��һ���������ӵ���һ������
// c.clear();//��������е�Ԫ��
c.equals(c1);//�Ƚ����������е������Ƿ���ͬ
c.retainAll(c1);//��c�б�����c����Ԫ�� ��c�仯��true ���仯false
System.out.println(c.size());//���鳤��length����,�ַ�������length����,���ϳ���size();
System.out.println(c1.remove("a"));//�Ӹü�����ɾ��ָ��Ԫ�صĵ���ʵ��(������ڷ���true)��
System.out.println(c.isEmpty());
System.out.println(c1);
Object[]objs=c.toArray();//������תΪObject��������
System.out.println(Arrays.toString(objs));
String[] sobject = c.toArray(new String[c.size()]);//������תΪָ����������
System.out.println(Arrays.toString(sobject));
�ġ�List�ӿ�
1��List�̳���Collection�ӿ�,������ʵ�ֵ��ࡣ
List���е��ص�:����(��������˳������),�������ظ�Ԫ�ء�
(1).ArrayList
�ײ���ͨ������ʵ�ֵ�,�ǿ��Ա䳤��
��ѯ��,�м���ɾ��
(2).LinkedList˫����
�ײ�������ʵ��
��ѯ��(�����ͷ/β��ʼ����,ֱ���ҵ�),�м���ɾ��,ֻ��Ҫ�ı��̽ڵ�λ��
(3).Vector
�ײ�������ʵ��,���̰߳�ȫ��
ArrayList�ײ�������ʵ��
����:
add();��������Ԫ��ʱ,�ײ��Ĭ�ϴ���һ������Ϊ10��Object��������,������װ����,�ٴ�����Ԫ��,�ᴴ��һ��ԭ�����鳤��1.5����������,��ԭ�������ݸ��ƹ���,�����������ĵ�ַ�����ײ�����顣
public boolean add(E e) { ensureCapacityInternal(size + 1);
// Increments modCount!!
elementData[size++] = e;
return true;}
if (minCapacity - elementData.length > 0)
grow(minCapacity);//�ײ���չ�ķ���
չ��:
ArrayList�ij��÷���
add(int index, E element)
get(int index)
indexOf(Object o)
lastIndexOf(Object o)
remove(int index) ɾ��������ָ��λ��Ԫ��
removeRange(int fromIndex, int toIndex) ɾ��ָ�������Ԫ��(����̳�ʹ��)
set(int index, E element)
list.add(0,"M");//��ָ���±�λ��������Ԫ��System.out.println(list.get(11));//���ش��б���ָ��λ�õ�Ԫ�ء�
System.out.println(list.remove(0));//ɾ��������ָ��λ�õ�Ԫ��
list.set(2,"k");//�滻ָ��λ�õ�Ԫ��System.out.println(list.size());//���ؼ�����ʵ�ʴ洢��Ԫ�ظ���
LinkedList�ij��÷���
�ײ�Ҳ������ʵ��,�������̰߳�ȫ��(synchronized����)
add(int index,Object element)
addFirist(Object element)
addLast(Object element)
get(int index)
removeFirst()
removeLast()
remove(int index)
getFirst()
getLast()
������������Ԫ��ʹ��node�ڵ�
˫����:���Դ�ͷ��ʼ�� Ҳ���Դ�β��ʼ��
llist.add("a");//������������Ԫ��
System.out.println(llist.get(3));//Ҫ�ҵ�Ԫ��λ��С��size/2,��ͷ�ڵ㿪ʼ��,�����β�ڵ㿪ʼ��
llist.addFirst("X");
llist.addLast("Y");
System.out.println(llist.removeFirst());//�Ӵ��б���ɾ�������ص�һ��Ԫ��
System.out.println(llist.removeLast());//�Ӵ��б���ɾ�����������һ��Ԫ��
System.out.println(llist);
�塢List�ӿڼ��ϵ���
�� forѭ������
�� ��ǿforѭ���ı���
�� ����������(Iterator��������ListIterator������(ֻ֧��List�ӿ��µ�ʵ����))
1��forѭ����������:
forѭ����������ʱ���Դ���ɾ��Ԫ��
ע��:ɾ��Ԫ�غ�,��������ƶ�,���ܳ��ִ�©����
for (int i = 0; i <= list.size(); i++) {
if (list.get(i).equals("a")) { list.remove(i);
}
}
System.out.println(list);
2����ǿforѭ����������:
�����ڱ��������в���ɾ��Ԫ��,���ɾ�����׳�ConcurrentModificationException(�������쳣)*/
for (String s:list) {
if(s.equals("d")){
list.remove(s);
}
}
System.out.println(list);
3������������List����
iterator();������һ��ArrayList�е��ڲ������,ʵ��Iterator�ӿ�
���ڲ���,ר�������Լ��Ͻ��б���ʱ�Ŀ���
hasNext();�жϼ������Ƿ���Ԫ��,�з���true,����false
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
if (s.equals("d")) {
it.remove();//�����Ҫ�ڱ�����ɾ��Ԫ��,��ʹ�õ������е�remove()
}
}
System.out.println(list);
����������List����
���List�ӿ��µļ�����ṩlistIterator()
ListIterator<String> it1 = list.listIterator(2);//��ָ����λ�ÿ�ʼ����
while (it1.hasNext()) {
String s = it1.next();
if (s.equals("d")) {
it1.remove();
}
}
System.out.println(list);
ListIterator<String> it2 =list.listIterator(list.size());
while (it2.hasPrevious()) {
String s2 = it2.previous();
System.out.println(s2);//�������
}
����Set�ӿ�
�����ص�:���ܴ洢�ظ�Ԫ��,����(���ǰ�������˳������)��
HashSet:�洢��Ԫ��˳�̶� b,c,a hashcode(); equals();
TreeSet:������Ԫ�ص���Ȼ˳������(c,a,b-----a,b,c) ���ӵ�Ԫ������,����ʵ������ӿڡ�
1��HashSet
�����Ҳ��ظ��ļ���
�ײ�ʹ�õ���HashMapʵ�ֵ�
public HashSet() {
map = new HashMap<>();
}
2������(���Ը���Ԫ����Ȼ˳������) �Ҳ��ܴ洢�ظ�Ԫ��
�ײ���TreeMapʵ��
public TreeSet() {
this(new TreeMap<E,Object>());
}
HashSet<String> set1 = new HashSet<>(list);//������û���ظ�Ԫ����HashSet System.out.println(set1);
TreeSet<String> set2 = new TreeSet<>(list);//ҡ�꽱����������TreeSet System.out.println(set2);
3.Set�ӿڱ�����ʽ
��ǿforѭ��
����������
�ߡ�Map�ӿ�
Map:˫�м��� ���C��ֵ
1��HashMap
���������
HashMap��Ԫ�ص�keyֵ�����ظ�,
����˳���Dz��̶���,���Դ洢һ��
Ϊnull�ļ���
2��TreeMap
�̰߳�ȫ��map
TreeMap�����е�Ԫ�ض�������ij�̶ֹ���˳��,�����Ҫ�õ�һ�������Map��Ӧ��ʹ��TreeMap,keyֵ���������ʵ��Comparable�ӿڡ�
3��HashTable
����ͨ������������
4��Map��������
5��Map�ӿڳ��õķ���
V put(K key,V value)
V remove(Object key)
void clear()
boolean containsKey(Object key)
boolean containsValue(Object value)
boolean isEmpty()
int size()
V get(Object key)
Collection values()
Set keySet()
Set<Map.Entry<K,V>> entrySet()
//eg:
Collection<String> c = hashMap.values();
System.out.println(c);//���ֵ
Set<String> set = hashMap.keySet();
System.out.println(set);//�����
2��Hashtable
HashMap�������ظ�,ֵ���ظ�
���������
�����Դ���һ��Ϊnull�ļ�,Ҳ���ܴ洢Ϊnull��ֵ
��synchronized����,���̰߳�ȫ��
3��TreeMap
TreeMap�������ظ�,ֵ�����ظ�
����������,��Ϊ�����͵������ʵ������ӿ�
HashMap<Car, String> chm =new HashMap<>();
Car bm1=new Car(1,"baoma1");
Car bm2=new Car(2,"baoma2");
Car bm3=new Car(3,"baoma3");
chm.put(bm1,"a");
chm.put(bm3,"b");
chm.put(bm2,"c");
System.out.println(chm);
public class Car implements Comparable<Car>{
/*@Override
public int compareTo(Car o) {
return this.no-o.no;
}*/
}
Map���ϱ���
��ʽ1:���ݼ���ֵ
? ��ȡ���м��ļ���
? �������ļ���,��ȡ��ÿһ����
? ���ݼ���ֵ
��ʽ2:���ݼ�ֵ�Զ����Ҽ���ֵ(Map����)
? ��ȡ���м�ֵ�Զ���ļ���
? ������ֵ�Զ���ļ���,��ȡ��ÿһ����ֵ�Զ���
? ���ݼ�ֵ�Զ����Ҽ���ֵ
Map<String, String> map = new HashMap();
map.put("a", "aa");
map.put("s", "ss");
map.put("b", "bbb");
map.put("x", "x1");
map.put("x", "x2");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) { System.out.println("keyΪ:" + entry.getKey() + ";valueΪ:" + entry.getValue());
}
3��TreeMap
TreeMap�������ظ�,ֵ�����ظ�
����������,��Ϊ�����͵������ʵ������ӿ�
TreeMap����keyֵ����,keyֵ��Ҫʵ��Comparable�ӿ�,
��дcompareTo������TreeMap����compareTo����,��
key��������
���Ǻ�����ṹ,���Ա�֤���������Ψһ��
�ˡ�Collections��
Collections�Ǽ�����Ĺ�����,������Ĺ�����Arrays���ơ�
addAl l(Col lection<? super T> c, T�� elements);
binarySearch(List<? extends Comparable<? super T>> l ist, T key)
sort(List l ist)
sort(List l ist, Comparator<? super T> c)
swap(List<?> l ist, int i, int j)
copy(List<? super T> dest, List<? extends T> src) ; ע�� dest size����ڵ���src.size
emptyList() ����Ϊ�յļ���,������������
fill(List<? super T> l ist, T obj) //��ָ����Ԫ�ش���ָ���б�������Ԫ�ء�
max(Col lection<? extends T> col l)
min(Col lection<? extends T> col l)
replaceAl l(List l ist, T oldVal, T newVal)
reverse(List<?> l ist) //�������
shuffle(List<?> l ist) //�������
copy(dest,src) //���ϸ���
�š�Hash�ṹ
1��HashSet
HashSet�в��ܴ洢�ظ�Ԫ�ء�
Object�е�haschcode��equals�ȽϵĶ��ǵ�ַ,������(��д��hashcode������equals����)�е�haschcode�Ƚϵ��ǹ�ϣֵ,equals�Ƚϵ������ݡ�(��ϣֵ���������������,���Dz���ȫ,����"ͨ��"��"�ص�"�Ĺ�ϣֵ��ͬ)
���ù�ϣֵ�ж�,����ͬ����equals,��߱Ƚ�Ч�ʡ�
�Զ�������Ҫ��дHashcode();��equals();
HashSet set = new HashSet;
2��HashMap
��ֵ��,˫�м���,���������ظ�,ֵ�����ظ�,���Դ���һ��null����
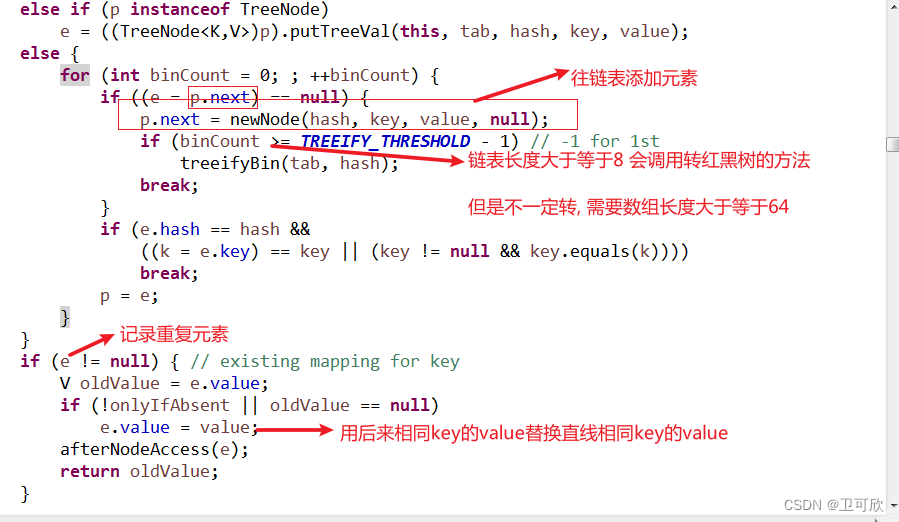
�ײ�洢�ṹ:java8
���������ݽṹ:
1.����(��ϣ��) 2.���� 3.�����
����Ԫ�ع���:
���Ԫ�ع�ϣֵ����Mod %���λ�á���Ԫ�ط�װ��һ��Node�����С�������ŵ�λ���ϡ�
��ϣ���鳤��Ĭ��16
������������0.75
(3/4ʱ����,Ϊԭ����2��)
��������Ϊ8�ҹ�ϣ���鳤�ȴ��ڵ���64ʱ��ɺ����
3.HashMapԴ�����