ЮФеТФПТМ
ЛљБОЫМЯы
УПВННЋвЛИіД§ХХађЕФЖдЯѓ,АДЦфЙиМќТыДѓаЁ,ВхШыЕНЧАУцвбОХХКУађЕФвЛзщЖдЯѓЕФЪЪЕБЮЛжУЩЯ,жБЕНЖдЯѓШЋВПВхШыЮЛжУЁЃ
МДБпВхШыБпХХађ,БЃжЄзгађСажаЫцЪБЖМЪЧХХКУађЕФЁЃ
ЛљБОВйзї:гаађВхШы
- дкгаађађСажаВхШывЛИідЊЫи,БЃГжађСагаађ,гаађГЄЖШВЛЖЯдіМгЁЃ
- Ц№Гѕ,a[0]ЪЧГЄЖШЮЊ1ЕФзгађСаЁЃШЛКѓ,ж№вЛНЋa[1]жСa[n-1]ВхШыЕНгаађзгађСажаЁЃ
гаађВхШыЗНЗЈ:
Ђй дкВхШыa[i]ЧА,Ъ§зщaЕФЧААыЖЮ(a[0] - a[i-1])ЪЧгаађЖЮ,КѓАыЖЮ(a[i] - a[n-1])ЪЧЭЃСєгкЪфШыДЮађЕФЁАЮоађЖЮЁБЁЃ
Ђк ВхШыa[i]ЪЙa[0] - a[i-1] гаађ,вВОЭЪЧвЊЮЊa[i]евЕНгаађЮЛжУj(0Ём j Ём i),НЋa[i]ВхШыдкa[j]ЕФЮЛжУЩЯЁЃ
ВхШыЭМЪО
ШчКЮевЕНВхШыЮЛжУ j Фи?
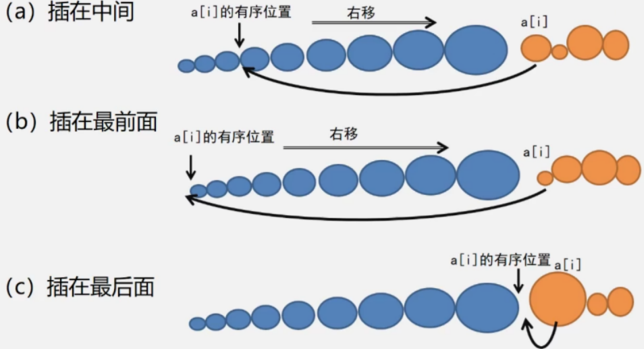
ВхШыХХађЕФжжРр
ЫГађЗЈЖЈЮЛВхШыЮЛжУЁЊЁЊжБНгВхШыХХађ
ЖўЗжЗЈЖЈЮЛВхШыЮЛжУЁЊЁЊЖўЗжВхШыХХађ
ЫѕаЁдіСПЖрБщВхШыХХађЁЊЁЊЯЃЖћХХађ
жБНгВхШыХХађ
жБНгВхШыХХађЁЊЁЊВЩгУЫГађВщевЗЈВщевВхШыЮЛжУЁЃ
ХХађЙ§ГЬ
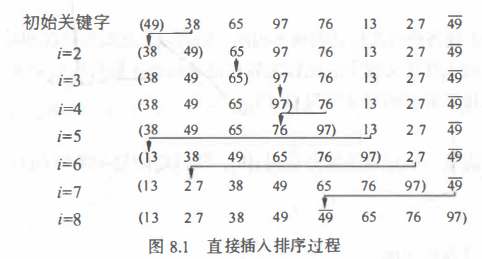
1.ИДжЦВхШыдЊЫи
x = a[i];
2.МЧТМКѓвЦ,ВщевВхШыЮЛжУ
for(j=i-1;j>=0&&x<a[j];j--)
a[j+1]=a[j];
3.ВхШыЕНе§ШЗЮЛжУ
a[j-1]=x;
ОпЬхЪЕЯж
void InsertSort(SqList &L)
{ //ЖдЫГађБэLзіжБНгВхШыХХађ
for(i=2;i<=L.length;++i)
if(L.r[i].key<L.r[i-1].key) // ЁА<ЁБ,ашНЋr[i]ВхШыгаађзгБэ
{
L.r[O]=L.r[i]; // НЋД§ВхШЫЕФМЧТМднДцЕНМрЪгЩкжа
L.r[i]=L.r[i-1]; // r[i-1]КѓвЦ
for(j=i-2; L.r[O].key<L.r[j].key; --j) // ДгКѓЯђЧАбАевВхШыЮЛжУ
L.r[j+1]=L.r[j]; // МЧТМж№ИіКѓвЦ,жБЕНевЕНВхШыЮЛжУ
L.r[j+1]=L.r[O]; // НЋ r[O]МДдr[i],ВхШЫЕНе§ШЗЮЛжУ
}
}
//if
ВхШыХХађадФмЗжЮі
ЪЕЯжХХађЕФЛљБОВйзїгаСНИі:
(1)ЁАБШНЯЁБађСажаСНИіЙиМќзжЕФДѓаЁ;
(2)ЁАвЦЖЏЁБМЧТМЁЃ
зюКУЕФЧщПі(ЙиМќзждкМЧТМађСажаЫГађгаађ):
11 25 32 47 56 70 81 85 92 96

зюЛЕЕФЧщПі(ЙиМќзждкМЧТМађСажаФцађгаађ):
81 85 92 96 70 56 47 32 25 11
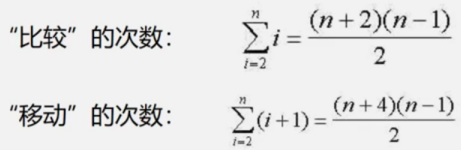
ЦНОљЧщПі:
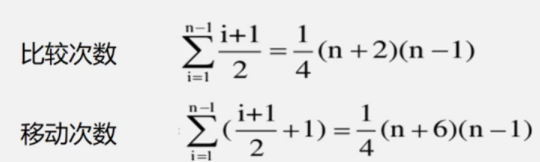
ЪБМфИДдгЖШНсТл
- дЪМЪ§ОндННгНќгаађ,ХХађЫйЖШдНПь
- зюЛЕЧщПіЯТ(ЪфШыЪ§ОнЪЧФцгаађЕФ)Tw(n) = O(n2)
- ЦНОљЧщПіЯТ,КФЪБВюВЛЖрЪЧзюЛЕЧщПіЕФвЛАы Te(n) = O(n2)
- вЊЬсИпВщевЫйЖШ,ОЭвЊМѕЩйдЊЫиЕФБШНЯДЮЪ§ЁЂМѕЩйдЊЫиЕФвЦЖЏДЮЪ§
елАыВхШыХХађ
ВщевВхШыЮЛжУЪБВЩгУелАыВщевЗЈЁЃ
ОпЬхЪЕЯж
void BinsertSort(SqList &L)
{ // ЖдЫГађБэLзіелАыВхШыХХађ
for (i=2; i < =L.length; ++i)
{
L.r[O]=L.r[i]; // НЋД§ВхШЫЕФМЧТМднДцЕНМрЪгЩкжа
low=1;high=i-1; // жУВщевЧјМфГѕжЕ
while(low<=high) // дкr[low .. high]жаелАыВщевВхШыЕФЮЛжУ
{
m=(low+high)/2; // елАы
if(L.r[O].key<L.r[m].key) high=m-1; // ВхШыЕудкЧАвЛзгБэ
else low=m+1; // ВхШыЕудкКѓвЛзгБэ
}
for (j=i-1;j>=high+1; --j) L.r[j+1]=L.r[j]; //МЧТМКѓвЦ
L.r[high+1]=L.r[O]; // НЋr[O]МДдr[i], ВхШыЕНе§ШЗЮЛжУ
} // for
}
елАыВхШыХХађЫуЗЈЗжЮі
- елАыВщевБШЫГађВщевПь,ЫљвделАыВхШыХХађОЭЦНОљадФмРДЫЕБШжБНгВхШыХХађвЊПь;
- ЫќЫљашвЊЕФЙиМќТыБШНЯДЮЪ§гыД§ХХађЖдЯѓађСаЕФГѕЪМХХађЮоЙи,НівРРЕгкЖдЯѓИіЪ§ЁЃдкВхШыЕкiИіЖдЯѓЪБ,ашвЊОЙ§log2i +1ДЮЙиМќТыБШНЯ,ВХФмШЗЖЈЫќгІВхШыЕФЮЛжУ;
- ЕБnНЯДѓЪБ,змЙиМќТыБШНЯДЮЪ§БШжБНгВхШыХХађЕФзюЛЕЧщПівЊКУЕУЖр,ЕЋБШЦфКУЧщПівЊВю;
- дкЖдЯѓЕФГѕЪМХХСавбОАДЙиМќТыХХКУађЛђНгНќгаађЪБ,жБНгВхШыХХађБШелАыВхШыХХађжДааЕФЙиМќТыБШНЯДЮЪ§вЊЩй;
- елАыВхШыХХађЕФЖдЯѓвЦЖЏДЮЪ§гыжБНгВхШыХХађЯрЭЌ,вРРЕгкЖдЯѓЕФГѕЪМХХСа
- МѕЩйСЫБШНЯДЮЪ§,ЕЋУЛгаМѕЩйвЦЖЏДЮЪ§
- ЦНОљадФмгХгкжБНгВхШыХХађ
ЪБМфИДдгЖШЮЊO(n2)
ПеМфИДдгЖШЮЊO(1)
ЪЧвЛжжЮШЖЈЕФХХађЗНЗЈ
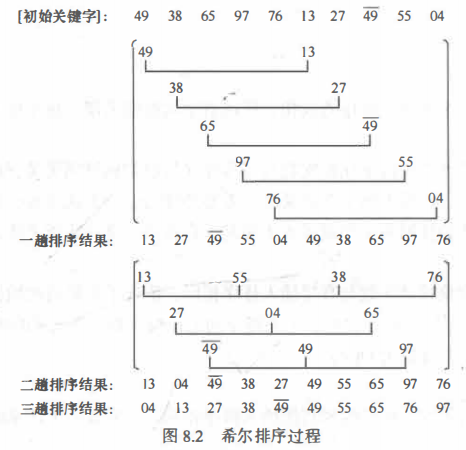
ЯЃЖћХХађ(Donald.L.Shell)
жБНгЁЂелАыВхШыХХађЕФЫМПМ
ПЩвддкжБНгЁЂелАыВхШыХХађЪБдіДѓвЦЖЏЕФВНЗљТ№?
гЩдРДЕФБШНЯвЛДЮвЦЖЏвЛВН,БфГЩБШНЯвЛДЮвЦЖЏвЛДѓВН?
жБНгВхШыХХађ, ЕБД§ХХађЕФМЧТМИіЪ§НЯЩйЧвД§ХХађађСаЕФЙиМќзжЛљБОгаађЪБ,аЇТЪНЯИпЁЃЯЃЖћХХађЛљгквдЩЯСНЕу,Дг ЁАМѕЩйМЧТМИіЪ§ЁБ КЭ ЁАађСаЛљБОгаађЁБ СНИіЗНУцЖджБНгВхШыХХађНјааСЫИФНјЁЃ
ЯЃЖћХХађЛљБОЫМЯы
ЯШНЋећИіД§ХХМЧТМађСаЗжИюГЩШєИЩзгађСа,ЗжБ№НјаажБНгВхШыХХађ,Д§ећИіађСажаЕФМЧТМЁАЛљБОгаађЁБЪБ,дйЖдШЋЬхМЧТМНјаавЛДЮжБНгВхШыХХађЁЃ
ЯЃЖћХХађЫуЗЈЬиЕу
(1)ЫѕаЁдіСП
(2)ЖрБщВхШыХХађ
- вЛДЮвЦЖЏ,вЦЖЏЮЛжУНЯДѓ,ЬјдОЪНЕиНгНќХХађКѓЕФзюжеЮЛжУ
- зюКѓвЛДЮжЛашвЊЩйСПвЦЖЏ
- діСПађСаБиаыЪЧЕнМѕЕФ,зюКѓвЛИіБиаыЪЧ1
- діСПађСагІИУЪЧЛЅжЪЕФ
ЯЃЖћХХађЙ§ГЬ
ОпЬхЪЕЯж
void ShellInsert(SqList &L, int dk)
{ // ЖдЫГађБэLзівЛЬЫдіСПЪЧdkЕФЯЃЖћВхШыХХађ
for(i=dk+1;i<=L.length;++i)
if(L.r[i].key<L.r[i-dk].key) // ашНЋL.r[i]ВхШыгаађдіГЖзгБэ
{
L.r[O]=L.r[i]; // днДцдкL.r[O]
for(j=i-dk; j >O&& L.r[O].key<L.r[j].key;j-=dk)
L.r[j+dk]=L.r[j]; // МЧТМКѓвЦ, жБЕНевЕНВхШыЮЛжУ
L.r[j+dk]=L.r[O]; // НЋ r[O]МДдr[i], ВхШыЕНе§ШЗЮЛжУ
}
}
void ShellSort(SqList &L,int dt[],int t)
{ //АДдіХњађСа dt[O .. t-1]ЖдЫГађБэ Lзїt ЬЫЯЃЖћХХађ
for (k=O;k<t;++k)
ShellInsert(L,dt[k]); // вЛЬЫдіжЗЮЊ dt[t]ЕФЯЃЖћВхШыХХађ
}
ЯЃЖћХХађЫуЗЈЗжЮі
ЯЃЖћХХађЫуЗЈаЇТЪгыдіСПађСаЕФШЁжЕгаЙи

ЪБМфИДдгЖШЪЧnКЭdЕФКЏЪ§:
O(n1.25) - O(1.6n1.25) ЁЊЁЊОбщЙЋЪН
ПеМфИДдгЖШЮЊO(1)
ЪЧвЛжжВЛЮШЖЈЕФХХађЗНЗЈ
ШчКЮбЁдёзюМбdађСа,ФПЧАЩаЮДНтОі;
зюКѓвЛИідіСПжЕБиаыЮЊ1,ЮоГ§СЫ1жЎЭтЕФЙЋвђзг;
ВЛвЫдкСДЪНДцДЂНсЙЙЩЯЪЕЯжЁЃ
ЯЃЖћХХађЫуЗЈЬиЕу
(1) МЧТМЬјдОЪНЕивЦЖЏЕМжТХХађЗНЗЈЪЧВЛЮШЖЈЕФЁЃ
(2) жЛФмгУгкЫГађНсЙЙ,ВЛФмгУгкСДЪННсЙЙЁЃ
(3) діСПађСаПЩвдгаИїжжШЁЗЈ,ЕЋгІИУЪЙдіСПађСажаЕФжЕУЛгаГ§1 жЎЭтЕФЙЋвђзг,ВЂЧвзюКѓвЛИідіСПжЕБиаыЕШгк1ЁЃ
(4) МЧТМзмЕФБШНЯДЮЪ§КЭвЦЖЏДЮЪ§ЖМБШжБНгВхШыХХађвЊЩй,nдНДѓЪБ,аЇЙћдНУїЯдЁЃЫљвдЪЪКЯГѕЪММЧТМЮоађЁЂnНЯДѓЪБЕФЧщПіЁЃ