6.4 �������㷨
1�����ʵ�ֶ�����?
(1)�۲�:BUILD-MAX-HEAP����������A[1��n]��������,����n=A.length,�����A[1]�ض�������Ԫ�ء�
(2)����:����ֻҪ��A[1]��A[n]����,Ȼ��A[n]�ų������(ͨ��n�C��ʵ��),�ٽ�ʣ��Ԫ����ɵ��µ���ͨ��MAX-HEAPIFY���¹�����һ�����ѡ�
(3)����:����(2)���̼��ɡ�
2�����
HEAPSORT(A)
1 BUILD-MAX-HEAP(A) //������ת��Ϊ����
2 for i = A.length downto 2
3 exchange A[1] with A[i] //��A[1]��A[i]����
4 A.heap-size = A.heap-size - 1 //��СA.heap-size
5 MAX-HEAPIFY(A,1) //���øú���ʹʣ��Ԫ�������������
3������
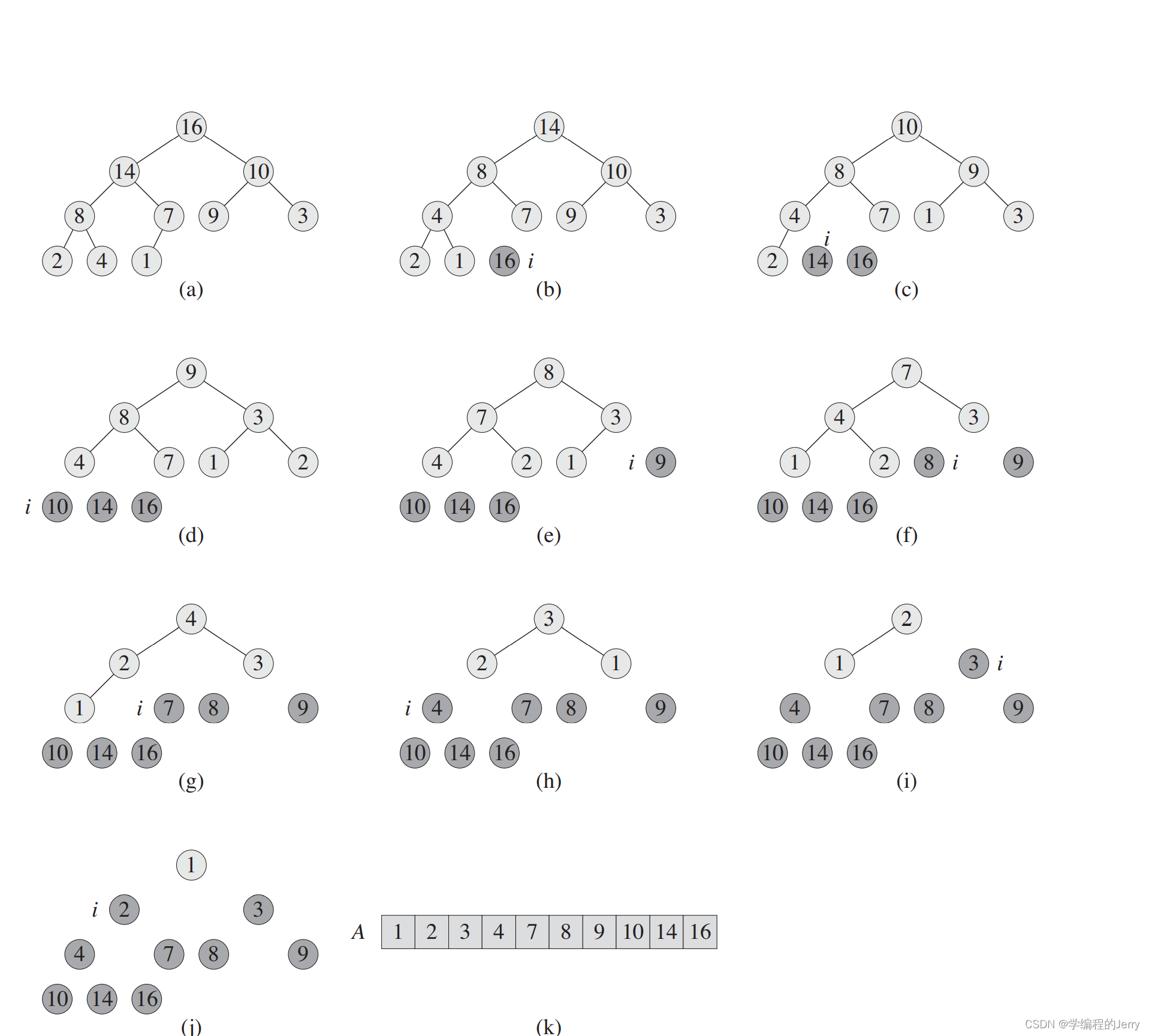
ͼ1 ������HEAPSORT(A)�Ĺ�������:
(a)ִ�е�һ��BUILD-MAX-HEAP(A),����һ�����ѡ�
(b)~(j)ÿ��ִ�к�������,����������(��ɫ��Ӱ)�ų�,����ʣ�ಿ��(dzɫ��Ӱ)��������Ϊ����,��ʶ��ǰ��i��
(k)��������A����������
6.5 ���ȶ���
һ������
������ܶѵ�һ��������Ӧ��:��Ϊ���ȶ��С�
�����������
1������:���ȶ�����һ������ά����һ��Ԫ�ع��ɵļ���S�����ݽṹ,����ÿһ��Ԫ�ض���һ����ص�ֵ,��Ϊ�ؼ�����
2��һ��������ȶ���֧�ֵIJ���:
(1)INSERT(S,X):��Ԫ��X���뵽����S�С�
(2)MAXIMUM(S):����S�о������ؼ��ֵ�Ԫ�ء�
(3)EXTRACT-MAX(S):ȥ��������S�еľ������ؼ��ֵ�Ԫ�ء�
INCREASE-KEY(S,x,k):��Ԫ��x�Ĺؼ���ֵ���ӵ�k,�������k��ֵ��С��x�Ĺؼ���ֵ��
��С���ȶ���������
��������
1��ͨ��HEAP-MAXIMUM��ʵ��MAXIMUM����,�ڦ�(1)��ʱ���ڡ�
HEAP-MAXIMUM(A)
1 return A[1]
2��ͨ��HEAP-EXTRACT-MAXʵ��EXTRACT-MAX����:
HEAP-EXTRACT-MAX
1 if A.heap-size < 1 //��֤�������Ƿ���Ԫ��
2 error "heap underflow"
3 max = A[1] //�������max��¼A[1]��ֵ
4 A[1] = A[A.heap-size] //��A[n]��ֵ��A[1]
5 A.heap-size = A.heap-size - 1 //��n--
6 MAX-HEAPIFY(A,1) //��ʣ�ಿ�ָֻ�Ϊ����
7 return max //�������ֵ
�������ʱ�临�Ӷ�ΪO(lg n),��Ϊ����ʱ�临�Ӷ�ΪO(lg n)��MAX-HEAPIFY����֮��,����������ֻ�軨������ʱ�䡣
3��ͨ��HEAP-INCREASE-KEYʵ��INCREASE-KEY����:
(1)���:
HEAP-INCREASE-KEY(A,i,key)
1 if key < A[i] //�ж�key�Ƿ�С��A[i],С�ھ�û������INCREASE����
2 error "new key is smaller than current key"
3 A[i] = key
//���A[i]���ڸ����,��ô��Ҫ�����븸��㽻��ֵ��������������
4 while i > 1 and A[PARENT(i)] < A[i]
5 exchange A[i] with A[PARENT(i)]
6 i = PARENT(i)
������̵�ʱ�临�Ӷ�ΪO(lg n),��Ϊ���㷨��3~6��������MAX-HEPIFY�IJ�����Ҫ��ʱ�䡣
(2)����:
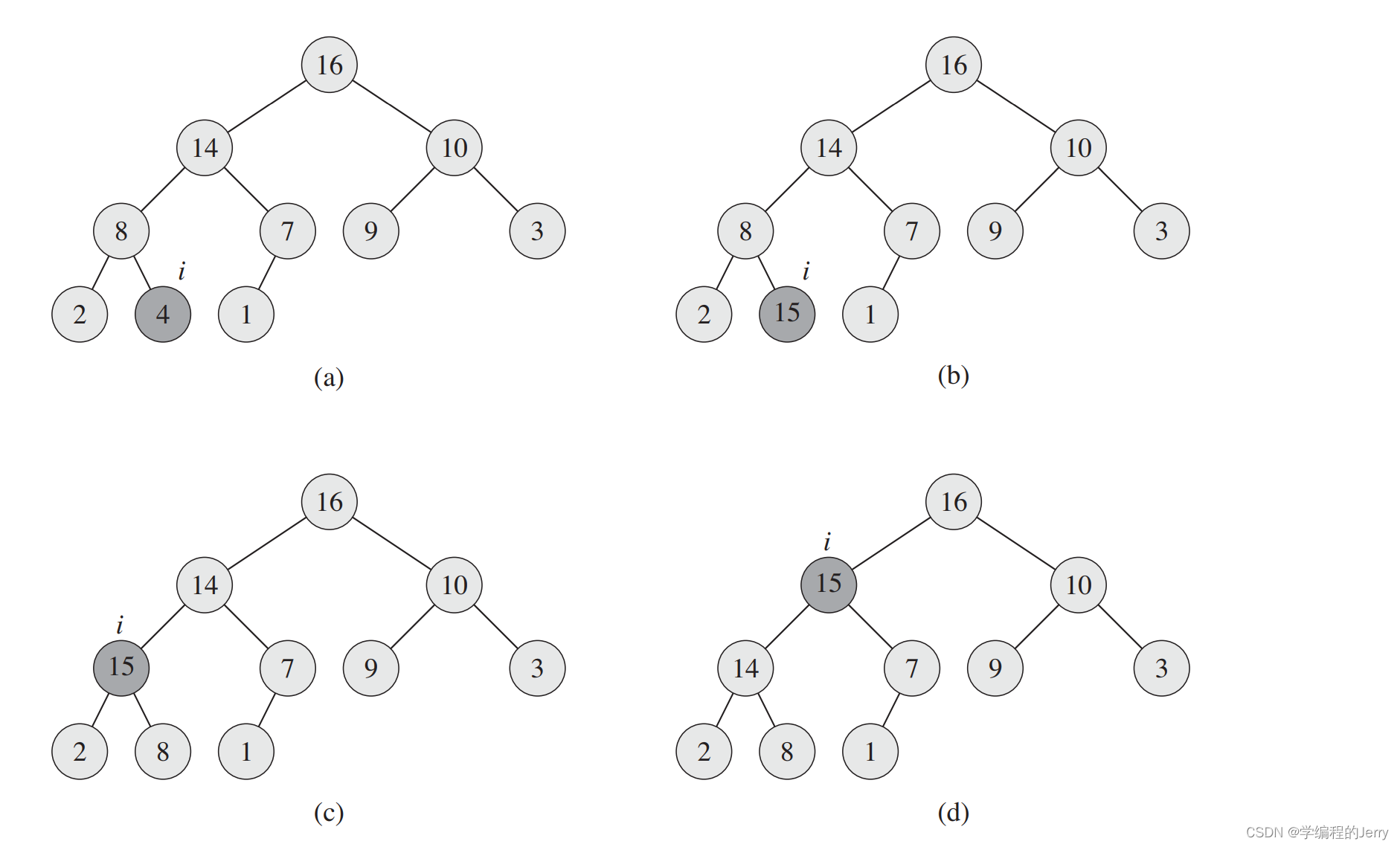
(a)ͼ��Ϊ����,�±�i�������ɫ��Ӱ��ʾ��
(b)���ùؼ������ӵ�15��
(c)����һ��4~6�еĵ���,i�븸��㽻��λ�á�
(d)������һ�ε���,ʹ��������������������,���������
4��ͨ��MAX-HEAP-INSERTʵ��INSERT����
MAX-HEAP-INSERT(A,key)
1 A.heap-size = A.heap-size + 1 //����һ��-��Ҷ�������������
2 A[A.heap-size] = -��
//ͨ������HEAP-INCREASE-KEY��Ϊ�½�����ö�Ӧ�Ĺؼ���,ͬʱ�������ѵ�����
3 HEAP-INCREASE-KEY(A,A.heap-size,key)
�ڰ���n��Ԫ�صĶ���,MAX-HEAP-INSERT������ʱ��ΪO(lg n)��