哈希表(hash table)
哈希表也称为散列表 , 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。也就是说关键字为K的元素存储到数组的位置K , 这也就意味着给定一个关键字K , 仅通过查找数组的第K个位置就可以找到该元素 , 这也称为直接寻址 ,这个映射函数叫做散列函数,存放记录的数组叫做散列表。
使用散列的查找算法分为两步 , 第一步是用散列函数将被查找的键转换为数组的一个索引 , 在理想情况下 , 每个键经过散列函数计算之后都会转换为不同的索引值 , 并且对应一个表中的地址(数组中的一个位置 , 也是内存中的一个地址) , 如下图所示 :

当然 , 这是理想的情况 , 不理想的情况就是多个key经过散列函数计算之后转换为的键是相同的 , 这个时候就会涉及到一个问题 : hash碰撞(如下图所示) , 所以散列算法的第二步也就是一个处理碰撞冲突的过程 , 解决hash冲突的算法有: 拉线法和线性探测法

线性探测法
线性探测法也叫开放定址法 , 把数组比作几套房子 , 当你正要付定金的时候 , 房子刚好被别人买了 , 这个时候怎么办呢?那就只能再找其他房子了 , 线性探测法也是类似的道理 , 如果当前散列地址有值了 , 那么就去寻找下一个空的散列地址 , 只要散列表足够大 , 那么就会有空的散列地址 , 如上图所示 , 在存放键为d的元素的时候发生了hash碰撞 , 那么就可以使用线性探测法 , 一直去判断 , 直到下标为3的时候发现可以存入元素 , 那么就将键为d的元素存到了下标为3的位置
拉线法
拉线法也叫拉链法 , 在hashMap中为了解决hash碰撞就用了拉链法 , 也就是JDK1.7的HashMap实现使用了数组+链表 , 而JDK1.8的实现中为了更快的检索拉出来的这个"链表"中的内容增加了红黑树 , 大致原理就是如下图所示
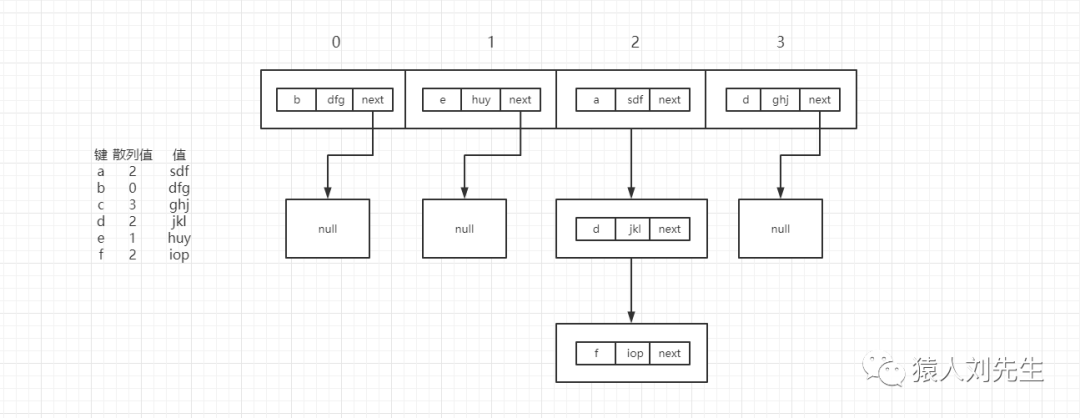
键为d , f的散列值出现了hash碰撞 , 这个时候就是用链表来存储重复的元素 , 如果需要根据键a找对应的值 , 那么时间复杂度为O(1) , 直接就可以找到 , 但是如果有多个key的hash值计算之后都为2 , 那么数组下标为2的位置的链表就会比较长 , 我们知道 , 链表的遍历是比较慢的 , 所以为了解决遍历链表慢的问题 , JDK1.8进行了优化 , 引入了红黑树来解决查询慢的问题 , 在HashMap中 , 这个数组又可以称为桶
散列函数
在散列的查找算法中 , 面对的第一个问题就是散列函数的计算 , 及把键转换为散列值(数组的索引)的计算 , 也就是说如果现在有一个长度为M的数组 , 那么就需要一个函数来将任意键转换为该数组范围内([0 , M-1])整数的索引, 而这个散列函数通常有以下特点:
-
尽可能的避免hash碰撞
-
计算简单且快速
-
将键值(key value) 均匀的分布在散列表
除留余数法
哈希函数的实现有好多种 , 其中比较常用的一种就是除留余数法 , 及使用key的哈希值取模一个素数 , 公式表达为 : H(key)=key MOD p (p<=m) , 但是素数的选择是非常重要的 , 尽可能的选择奇数并且接近m(因为偶数发生hash冲突的概率很大 , 接近m是因为这样计算出来的索引值分布更加均匀) , HashMap使用的就是类似的方法 , 在HashMap初始化或者扩容时 , 元素索引的计算为 : hash & (newCap - 1) , 这样就满足了最佳素数的选择条件 , 只不过HashMap的作者为了提高运算效率 , 没有使用% , 而选择了位运算 , 但是选择位运算数组的长度必须是2的N次方
解释一下: 为什么数组的长度必须是2的N次方
9为key , 4为数组的长度
使用除留余数法在平时的取余中我们是这样运算的 : 9 / 4 = 2…1 ,商为2余数为1 , 所以索引为1 , 换成位运算就是 : 9对应的二进制为: 1001 , 4为2的2次方 , 所以如果一个数除以2的N次方 , 那么我们就是要得到最后这个数最后N位二进制的值
9 (1001) / 2的2次方 = 2…1 等于 (1001 后两位 = 0001 = 1)
因为size为二的幂次方,size-1的二进制一定为111・・・11这种全是1的数,这样进行与操作就能提取到后N位,所以位运算取余公式是 key MOD p = 9 / (4(2的2次方) -1) 替换为位运算 hash & (size - 1) = 1001 & 0011 = 0001 = 0001 = 1
9为key , 3为数组的长度
如果数组的长度不为2的N次方 , 带入公式 key MOD p = 9 / (3 - 1) 替换为位运算 hash & (size - 1) = 1001 & 0010= 0000 = 0 , 由此可见无法达到预期的效果
java规范
而对于键的类型它可以有几种 , 比如整数 , 浮点数 , 字符串 , 所以散列函数和键的类型有关 , 严格一点来说就是 : 对于每种类型的键 , 都需要一个与之对应的散列函数 , 如果键是一个整数 , 那么可以直接使用这个数 , 如果是一个字符串 , 比如名称 , 那么就需要把这个字符串转换为一个数 , 如果这个键有多个部分 , 比如邮件地址 , 那么就需要把这些部分结合起来 , 对于常见类型的的键 , 可以使用java默认的实现
所以hash函数由于每种数据类型都需要相应的散列函数 , 所以java就令所有数据类型都继承了一个能够返回32比特整数的hashCode()方法
整数类型hashCode()实现
public static int hashCode(int value) {
return value;
}
字符串hashCode()实现
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
浮点型hashCode()实现
public static int floatToIntBits(float value) {
int result = floatToRawIntBits(value);
// Check for NaN based on values of bit fields, maximum
// exponent and nonzero significand.
if ( ((result & FloatConsts.EXP_BIT_MASK) ==
FloatConsts.EXP_BIT_MASK) &&
(result & FloatConsts.SIGNIF_BIT_MASK) != 0)
result = 0x7fc00000;
return result;
}
但是我们需要的是一个[0,M-1]的索引 , 而不是32比特的整数 , 所以在java中是这样计算hash值的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
首先把key的hashCode值赋值给h , 然后将h右移16位 , 然后进行^异或运算 , 由此可以引申两个问题
1.为什么要右移16位?
右移16位其实是为了减少hash碰撞 , int类型占4字节 , 也就是32位 , 无符号右移16位 , 高位补0 , 这个时候可以同时保留高16位和低16位的特征 , 或许举个例子就很好明白
如果现在有一个数的hash值为 11110001 数组默认长度为16 , 现在有两个值 : 241 193
241 % 15 换算为2进制 11110001 & 00001111 = 00000001
193 % 15 换算为2进制 11000001 & 00001111 = 00000001
这样这两个数据计算之后索引相同 , 因为HashMap使用的是拉链法 , 所以计算出索引容易一样 ,这就可能导致某个索引下的链表比较长 , 值的分布不均匀 , 但是右移16位 , 就可以使高位的数据也加入到取余计算 , 从而使值的分布更加均匀
2.为什么使用^运算 , 而不是用&或者是|
因为异或可以保证两个值的特性 , 位运算中与(&)运算的结果更加的偏向0 , 而|运算的结果更加偏向1
所以我们可以看出 右移是为了保持低16位与高16位的特征 , 而^运算可以使结果不会偏向0或者1 , 增加了散列程度 , 使数据分布的更加均匀
如果感觉博主写的还不错的话 可以来一个一键三连 , 并且同时可以顺便关注一下博主的公众号 : [猿人刘先生] , 下面我把链接贴出来 , 非常感谢大家的阅读与关注 , 希望我们可以不想学习 , 共同进步 !!!