֪֮����,����֮����;��֮����,��֪֮������?
ѧ������,���Dz���ˢˢ����������������ʶ?���첩��ѡȡʮһ������������,��ˢ���ߵĽǶ������ص���״���,������ķ���,�����ڸ���Ŀ����Ŀ����,�ص�������ȫ���òʱʱ�ע��,���ҷ���ʳ�á�
Ŀ¼
1��ɾ�������е��ڸ���ֵ val �����н��
1��ɾ�������е��ڸ���ֵ val �����н��

?��һƪ�������ǽ�������ɾ�����Ĺ���,���ɾ��һ������������˵�ѶȲ���,����������������Ҫɾ��������,����ͷ���ܿ��ܻᱻ�ı�,�����˵���,ͷ������һֱ�ڸı�,һֱ��ɾ��,�������������Ե��е㼬���ˡ�����ô������?���ǿ��������¶���һ��ͷ���NewHead,��֤���ͷ��㲻�ᱻɾ��,���ͷ�����nextָ��ָ�����֮ǰ��ͷ���,���NewHead->next(Ҳ������Ŀ��Ҫ�ص��µ�ͷ�ڵ�)
д����Ҫע��ļ���:
- NewHead�������Լ��ֶ����ӵ�ͷ�ڵ�,Ŀ�ľ��Ƿ�ֹ���ֶ����ͷ�ڵ�����,�������Ҫ��֤NewHead->val!=val,��д�Ĵ����о�ֱ�Ӱ�val+1��ֵ��NewHead->val,����Ҳ����val+2/val-1��ֵ,ֻҪ������val�Ϳ��ԡ�
- NewHeadһ��Ҫ�ǵó�ʼ��,���˳�ʼ���ṹ���Աval,��Ҫ��ʼ��nextָ��,��NewHead��head�ڵ�����������
- ���ǵ�����NewHead->next,����NewHead��
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* NewHead=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* cur=NewHead;
struct ListNode* prev=NULL;
//��֤NewHead��val��Ϊ���ֵ,���ᱻɾ��
NewHead->val=val+1;
NewHead->next=head;
while(cur!=NULL)
{
if(cur->val==val)
{
prev->next=cur->next;
}
else
{
prev=cur;
}
cur=cur->next;
}
return NewHead->next;
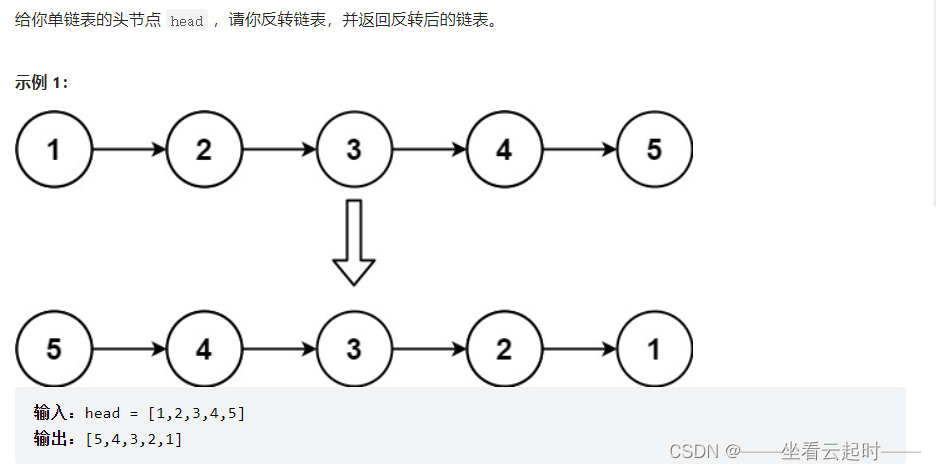
}2����ת����

?ͼ������Щ�ʲ�,���Ҿ��û��Dz�Ӱ������Ч��![]()
?���������鲻һ��,��ת������������İ�������ÿ�����λ�ö���ת,���ĵ�ַ��û�б��ı�,�ı��ֻ��ÿ�������ָ���������
������,�Ҿ��ô��Ӧ�û���˼·��,��������Ҫ��һ��cur���ָ��ȥ�������еĽ��,��ΪҪ�ı�cur->next,����ָ��ǰһ�����,��������Ҫ����������ָ��ȥ��¼��ַ,һ����prevָ��,ȥ��¼ǰһ�����ĵ�ַ,һ����nextָ��,ȥ��¼��һ�����ĵ�ַ��
����,��ע��:
- ��cur==headʱ,��ʱû����һ�����,����Ҫ��head->next=NULL��
- ����,�����ּ������,������Ϊ�յ�ʱ��,cur=NULL,��cur->next��������,����ύ����ͻ�����������(����ͼ
 ),��α���˵�����ǷǷ�ʹ���˿�ָ�롣
),��α���˵�����ǷǷ�ʹ���˿�ָ�롣 ���ǹ����������ͺ�,�������Ϊ�վ�ֱ�ӷ���NULL��
���ǹ����������ͺ�,�������Ϊ�վ�ֱ�ӷ���NULL�� - ��д��while���ж�������cur->next��ΪNULL,����cur��ΪNULL,����Ǻ���,����ֵ�Ͳ���cur,����prev,����ȥ��ѭ����cur->next=prev;
struct ListNode* reverseList(struct ListNode* head){
struct ListNode *cur=head,*next,*prev;
prev=next=NULL;
if(head==NULL)
return NULL;
while(cur->next)
{
next=cur->next;
if(cur==head)
{
head->next=NULL;
}
else
{
cur->next=prev;
}
prev=cur;
cur=next;
}
cur->next=prev;
return cur;
}?
3�����������

?OJ����
�ܶ��˿���������ܵ�һ��Ӧ��������������ij���,Ȼ��/2,����ָ�������߳���/2�����,��������Ľ�������ĿҪ����м��㡣
�����ҼӴ��Ѷ�,Ҫ��ֻ��������һ������,ʱ�临�Ӷ�Ҫ����O(n)��
������Ҫ�õ�����ָ�롪��fast��slow,fastÿ���ߵĽ����slow�ߵĽ�������,����ͱ�����ô������˼·��,�����һ������,������,��ס���ͺ��ˡ�
struct ListNode* middleNode(struct ListNode* head){
struct ListNode *slow,*fast;
slow=fast=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
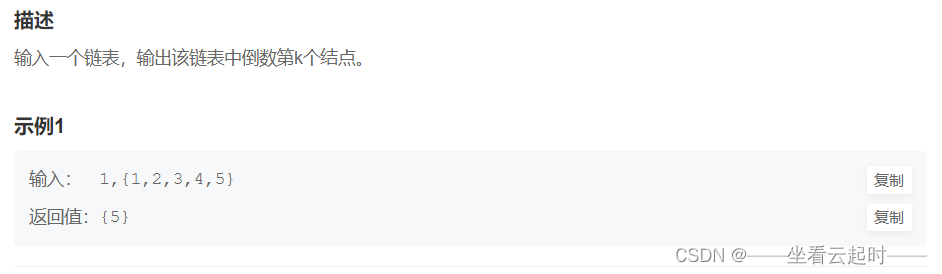
}4�����������k�����
OJ���� ?
�������һ��ţ������?(? ???��??? ?)?,��������Ҳ�Ǻ���Ŀ,����������,Ҳ���ÿ���ָ��,����������е�С���ˡ�
ͬ��,���ǼӴ��Ѷ�,ֻ��������һ������,ʱ�临�Ӷ�ΪO(N)��
�����˼·��:fast����k��,Ȼ��fast��slow��һ����,ֱ��fastΪNULL��
ΪʲôҪ��������,��Ϊfast��slow����k��,���һ����,��ôslow��fast�ľ���һֱ��k�����,���fastΪ��,ֹͣ�˶�ʱ,slow����NULL����k����㴦,���slow�͵���k����㴦�ˡ�
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
struct ListNode *slow,*fast;
slow=fast=pListHead;
while(k--)
{
fast=fast->next;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}�����������Ǹ����������,��˵���ǵĴ����жδ���(�����ڵĶδ����������)��
������Ϊ����ֻ������?kС���������ȵ����,���k���ڻ��ߵ�������������ô��?
����Ӧ����whileѭ���������һ��if���,���fast==NULL��,���Ǿͷ���NULL����Ϊk��ûΪ0,fast��Ϊ����,�Ǿ�֤��k���������ij��ȡ�
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
struct ListNode *slow,*fast;
slow=fast=pListHead;
while(k--)
{
//k������������
if(fast==NULL)
{
return NULL;
}
fast=fast->next;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}
};�����һ�Ҫ˵һ��,�ղ��¼ӵ�if���,��Ҫ����fast=fast->next��ǰ��(��Ȼ�ͻᱨ�δ���,???)��pListHead=NULLʱ,�����Ƚ���fast=fast->next,��ʱ�Կ�ָ������þͻ��������,Ҳ������dz����˵Ķδ�������������кܶ�ӵ�,�ú�ע��QAQ��
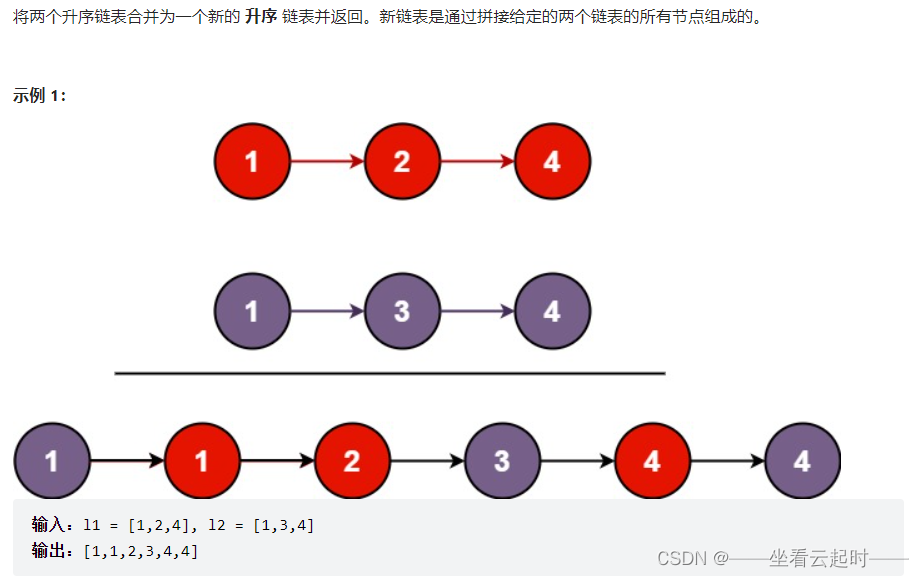
5���ϲ�������������
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
struct ListNode *cur1,*cur2,*cur;
cur1=list1;
cur2=list2;
struct ListNode* head=(struct ListNode*)malloc(sizeof(struct ListNode));
cur=head;
head->next=NULL;
while(cur1&&cur2)
{
if(cur1->val<cur2->val)
{
cur->next=cur1;
cur1=cur1->next;
}
else
{
cur->next=cur2;
cur2=cur2->next;
}
cur=cur->next;
}
if(cur1)
{
cur->next=cur1;
}
if(cur2)
{
cur->next=cur2;
}
return head->next;
}��������������һ���µ�ͷ���(�ڱ����),��Ϊ����IJ����ٶ�д���д���ȥȷ��ͷ����ֵ(����ľ�������������㰡,����ʲôͷ��㲻ͷ���,���н�㶼һ��ͬ��)��
ע��:
- �����ڱ�����Ǻ���,����,���ǵ�ע�list1��list2��ΪNULL�����,�������head->next����ֵ,��ô�ͻ����Bug,��ʱ����������Ϊ��,��ô����ֵҲΪNULL,head->nextҲ��ֵΪNULL��
- �Ҿ������˿��ܻ��ɻ����������if���,���ǿ��ܻ���Ϊ��һ��cur1����cur2����ѭ����,������β���кü������,��ô��if���������������һ��,������while���,��if��䲻��ֻ�ܴﵽ������������Ч����?(�Ҳ�֪�����ǻ���������ɻ�,���Լ�д�����ʱ��ͺܲ�����Ϊʲô��ͨ��)��ʵ����Ϊcur1����cur2ʣ�µ����н�㶼�Ǵ�������,��ֻ��Ҫ��ʣ�µ���Щ����еĵ�һ�������cur��������,ʣ�µĽ����Ȼ��Ȼ�ʹ���һ����(���Լ��������,������,����ҹ�������O(��_��)O)
6���ָ�����

?OJ����
?û��,������ţ�͵���,����Ҳͦ�����,ͦ����˼��
��ĿҪ�����ǽ�С��x�Ľ������������֮ǰ,���Ҳ��ܸı�ԭ��������˳��,�����Dz���ͻȻ���뵽����C�����е�����,����һ����,�������С�ľ���ǰ��(����),��������������ȥ���ǻᳬ���鷳,�Ȳ���ͷ��㲻��д(�������ͨ���ڱ������),ÿ����ǰ�ƶ�һ�����,���ǻ��ü�ס������ԭ����λ��,ԭ��λ�ô�������������λ��,��Ҫ��ס��һ�����ƶ��Ľ���λ��,��֤��һ���ƽ���,���еĽ���ܹ�������,������������������ͺܸ�����,��������ˮƽ���ߡ�һд����Bug99+��С����˵,����������Dz��ʺ��ҡ���������ô����?
��ʵ��������ϸ����,������ǰ��������ֳ�������,һ����valС��x�Ľ��,һ����val���ڵ���x�Ľ��,���ǿ����ڱ�������ʱ,��С��x�ķŵ�С���������,�Ѵ��ڵ���x�ķŵ�����������,����ٰ�С������������һ����������������ĵ�һ����㴮����,����ʵ���Dz��Ǽ���(��һ����,ǿ!)
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
struct ListNode *greatertail,*lesstail,*greaterguard,*lessguard,*cur=pHead;
greaterguard=(struct ListNode*)malloc(sizeof(struct ListNode));
lessguard=(struct ListNode*)malloc(sizeof(struct ListNode));
greatertail=greaterguard;
lesstail=lessguard;
while(cur)
{
if(cur->val>=x)
{
greatertail->next=cur;
greatertail=greatertail->next;
}
else
{
lesstail->next=cur;
lesstail=lesstail->next;
}
cur=cur->next;
}
greatertail->next=NULL;
lesstail->next=greaterguard->next;
return lessguard->next;
}
};ע��:
- �����ڶ����д���,����Ϊ�Dz��ܻ���˳���,���ǻ�����Ҳ����ͨ��(��֪���Dz���ţ�Ͳ��Ե�����̫����,�����������?),���������������ڱ����,���������ڱ�����next��û�г�ʼ��,����Ҫ�Ļ���greaterguard->nextû�г�ʼ��,�����������ǿ�����,������ص�Ӧ���ǿ�,lesstail��ʱ==lessguard,greatertail==greaterguard,�����ǰ�greatertai->next=NULL�ŵ�ǰ�����ÿ����������ּ��������
- ���������д���ΪʲôҪдgreatertai->next=NULL?��Ϊ���������һ������nextָ��NULL������ر����ױ����ӡ�
7����������

?����
ʲô�ǻ�������,�����Գƾͱ��������������� �Գ�,����˼��,����������������Ϊ�Գ���,������ߵĽ���val�����,��ô˵������������ǶԳƵ���
�ж��������Ƕ��Ѿ������,������ѶȾ������������з����,��ôһһ�Ƚ϶ԳƵĽ����?
����,����Ҫ�ҵ����������Ľ��,��������������������,��ѡ�Ǹ�Ψһ���м���,���������ż�������,�������м���,��ô��ѡ��ڶ����м��㡣Ȼ��,�����ڵڶ���ѧϰ�˷�ת����,���Ǿͷ�ת���м���Ϊͷ��������,������ķ���ֵΪ��ת���µ�ͷ��㡣�Ҿٸ�����,��ת���������������:

?Ȼ��ֱ��head��head1����ʼ�Ƚ�,����м��н���val�����,��ô�ͷ���false,����������ѭ����,��ô�ͷ���true��
struct ListNode* reverseList(struct ListNode* head){
struct ListNode *cur=head,*next,*prev;
prev=next=NULL;
if(head==NULL)
return NULL;
while(cur)
{
next=cur->next;
if(cur==head)
{
head->next=NULL;
}
else
{
cur->next=prev;
}
prev=cur;
cur=next;
}
return prev;
}
bool isPalindrome(struct ListNode* head){
struct ListNode* fast=head,*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
struct ListNode* head1=reverseList(slow);
while(head&&head1)
{
if(head->val==head1->val)
{
head=head->next;
head1=head1->next;
}
else
{
return false;
}
}
return true;
}���˿��ܻ����ɻ�:��һ�������ѭ������Ϊhead����head1ΪNULL,����һ��������ΪNULL,�Ǿ�֤��������������ǻ��Ľṹ��ѽ?(�ҵ�ʱд�����,��ľ�����˼����)
��������,��ת�����Ƿ�ת���м���Ϊ��ʼ��������,��ôhead��head1���������϶��ǶԳƵ�,�����һ��Ϊ��,��һ���϶�ҲΪ�ա�(Ϊ���ǵ��ҵ����!!!o( ̄�� ̄)d)
8����������

?OJ����
ʲô�ǻ�������,����������β����㲻ָ��NULL,����ָ�������е�����һ�����,��������һֱû�н����ı�־��
���ȥ�жϻ���������?���ǿ�������������ж������������Բ����ǻ�������,��һ��ָ��ȥ������������,������ָ��������˿�ָ��,��ʱ�������ߵ�ĩβ��,����Ȼ���ǻ���������������ÿ���ָ��,һ���ߵĿ�,һ��������,һ���ߵ���,һ����һ��,�������������,��ô��֤������һ����������������ֻҪ���ǻ�������,��ô��һ������,��֤��һ��:

�ϴ���:
bool hasCycle(struct ListNode *head) {
struct ListNode*fast,*slow;
fast=slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
return true;
}
}
return false;
}?ע��:
- whileѭ�����ж�������Ҫдfast&&fast->next����Ϊ��,ΪʲôҪдfast->next��Ϊ����,��Ϊfastһ��������,���fast->nextΪNULL,����fast=fast->next->next�IJ������ǶԿ�ָ��Ľ�������,����ֶδ���
- �������������д�����ʱ��,�Ҳ�֪����һ���,���һ�����˵һ��,���whileѭ������д������,��ͨ����?
while(fast&&fast->next) { if(fast!=slow) { fast=fast->next->next; slow=slow->next; } else { return true; } }����Dz���ͨ��,��Ϊfast��slow�ʼ������ȵ�,������head,��ôֻҪfast��fast->next��Ϊ��,��һ�ν�����ʱ��,������else����,Ȼ��true,��ʵ�ʲ�һ����true��
�������ָ��������,��ָ����һ��,һ��������?
���Dz�һ��:

9���ཻ����

?OJ����
������Ҫ��ѧ��˼·,˼·���˾Ͳ��᷸ʲô������,����˼������ע�ͱ�ע��������?
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
//��β���,β���������,��ô�϶����ཻ
struct ListNode* cur1=headA,*cur2=headB;
int len1=1,len2=1;
while(cur1->next)
{
cur1=cur1->next;
len1++;
}
while(cur2->next)
{
cur2=cur2->next;
len2++;
}
//β��㶼�����,��ô�϶����ཻ
if(cur2!=cur1)
{
return NULL;
}
int gap=fabs(len2-len1);
struct ListNode* larger=headA,*lesser=headB;
if(len2>len1)
{
larger=headB;
lesser=headA;
}
//�ý�����������ָ������gap��
while(gap--)
{
larger=larger->next;
}
//ͬʱ��,ֱ���������
while(larger!=lesser)
{
larger=larger->next;
lesser=lesser->next;
}
//�������,��������Ϊ�����ཻ���,Ҳ�����ǵ�������β��,����ΪNULL
return larger;
}10����������II(������)?

?˼·һ(��ʽ��):
��������е�����,������Ҫͨ���Ƶ���ʽ�ҵ�˼·

?�ϴ���:
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode*meet=NULL,*cur,*slow,*fast;
slow=fast=cur=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(slow==fast)
{
meet=slow;
break;
}
}
if(fast==NULL||fast->next==NULL)
return NULL;
while(meet!=cur)
{
meet=meet->next;
cur=cur->next;
}
return meet;
}˼·��(���ཻ���):

struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
//��β���,β���������,��ô�϶����ཻ
struct ListNode* cur1=headA,*cur2=headB;
int len1=1,len2=1;
while(cur1->next)
{
cur1=cur1->next;
len1++;
}
while(cur2->next)
{
cur2=cur2->next;
len2++;
}
//β��㶼�����,��ô�϶����ཻ
if(cur2!=cur1)
{
return NULL;
}
int gap=fabs(len2-len1);
struct ListNode* larger=headA,*lesser=headB;
if(len2>len1)
{
larger=headB;
lesser=headA;
}
//�ý�����������ָ������gap��
while(gap--)
{
larger=larger->next;
}
//ͬʱ��,ֱ���������
while(larger!=lesser)
{
larger=larger->next;
lesser=lesser->next;
}
//�������,��������Ϊ�����ཻ���,Ҳ�����ǵ�������β��,����ΪNULL
return larger;
}
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode*meet=NULL,*cur,*slow,*fast;
slow=fast=cur=head;
//�ҿ���ָ��������
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(slow==fast)
{
meet=slow;
//�Ͽ�����
struct ListNode*next,*NEXT;
next=NEXT=meet->next;
meet->next=NULL;
struct ListNode* GetInterNode=getIntersectionNode(next,head);
//��Ϊ�����ƻ������ṹ,����Ҫ��ԭ����
meet->next=NEXT;
return GetInterNode;
}
}
return NULL;
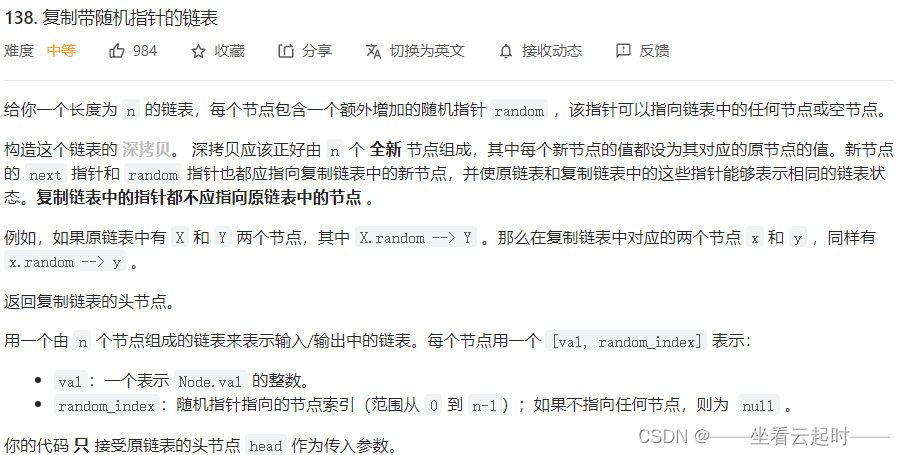
}11�����ƴ����ָ�������

?OJ����
�����������֮ǰѧ����������Щ��ͬ,֮ǰѧ������ֻ��������Ա,һ����¼value,һ����¼��һ�����ĵ�ַ,������Ľ����������Ա,�����һ��randomָ��,����ָ�������е�һ����㡣�������˼�������Ǹ��Ƴ�һ����ԭ����һģһ����������,��ֻ��ǵ�randomָ��ĸ�ֵ��
����һ(�������):
�������ʱ�临�Ӷ�ΪO(N^2),ʱ�临�ӶȻ���ͦ���,Ч���е��,����˼·��(���ʺ������ַǴ���С�����ð�)
struct Node* copyRandomList(struct Node* head) {
struct Node* newhead=(struct Node*)malloc(sizeof(struct Node)),*cur,*cur1,*cur3,*cur4;
if(head==NULL)
{
return NULL;
}
newhead->val=head->val;
cur=head->next;
cur1=newhead;
//�������Ƶ�������
while(cur)
{
struct Node* Node=(struct Node*)malloc(sizeof(struct Node));
Node->val=cur->val;
cur1->next=Node;
cur1=cur1->next;
cur=cur->next;
}
cur1->next=NULL;
//����random
cur1=newhead;
cur=head;
while(cur)
{
if(cur->random==NULL)
{
cur1->random=NULL;
}
else
{
cur3=head;
cur4=newhead;
//����Ϳ�ʼ����random��
while(cur3!=cur->random)
{
cur3=cur3->next;
cur4=cur4->next;
}
cur1->random=cur4;
}
cur1=cur1->next;
cur=cur->next;
}
return newhead;
}����������һ��, ��ֵrandomʱwhileѭ����������cur3!=cur->random,������cur4->val!=cur->random->val,��һ���������������洢��value��һ���ľʹ���!!!!!
������(�����õķ���):
��������е�����,����Ч�ʸ�,ʱ�临�Ӷ�ΪO(N)(���㶼�ܷ���,����Ҳ���ܶ���,��ѧһ����ķ���!!!)
��һ��:�ȴ����½ڵ�,��ÿ���½���λ�������������,������ÿ�����ƵĽ���value������ԭ����value��
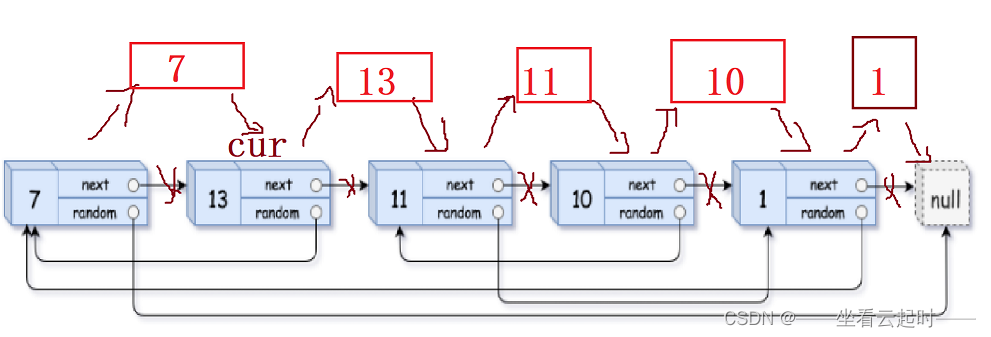
�ڶ���:����random,�ֳ��������,��һ�����,ԭ����randomָ��NULL,�Ǹ��ƵĽ���randomҲָ��NULL���ڶ������,ԭ����randomָ���NULL,���ƵĽڵ��randomָ��ԭ���random����һ����㡣(ע��:������ʱ������һ���ڵ����)
������:�Ͽ�ԭ�����������������Ҫ��Ϊ��ͷ���ͷ�ͷ�������,���������л�ͼȥ����,˼·���Ǻ���,ע��ϸ�ھ�ok��
struct Node* copyRandomList(struct Node* head) {
struct Node *cur,*newnode,*next=NULL;
cur=head;
//�����½��,��ֵvalue
while(cur)
{
struct Node*newnode=(struct Node*)malloc(sizeof(struct Node));
next=cur->next;
cur->next=newnode;
newnode->next=next;
newnode->val=cur->val;
cur=next;
}
//��ֵrandom
cur=head;
while(cur)
{
if(cur->random==NULL)
{
cur->next->random=NULL;
}
else
{
cur->next->random=cur->random->next;
}
//����
cur=cur->next->next;
}
//�Ͽ����������������
struct Node* newhead=NULL,*newtail=NULL;
cur=head;
while(cur)
{
next=cur->next->next;
if(newtail==NULL)
{
newhead=newtail=cur->next;
}
else
{
newtail->next=cur->next;
newtail=newtail->next;
}
//�ָ�
cur->next=next;
//����
cur=cur->next;
}
return newhead;
}LeetCode�ϻ��кö������������Ŀ,��ҿ�������ˢ��,����ƪ����ѡ������ʮһ����,ȫ��ѧ��,�������������һ��������һ��̨��!
���ݽṹ����,����Ҫ����Ŭ��ѧϰ��ѽ!
����,ϲ���ҵ�����,���ҵ����![]() &&�����ע���߰� !!
&&�����ע���߰� !!
?