Hash
ЙўЯЃКЏЪ§ЪЧЯыАбВЛЭЌЕФЪфШыЭЈЙ§ФГжжгГЩфЙиЯЕЪфГіВЛЭЌЕФжЕ,ОЁПЩФмЕиВЛвЊГхЭЛЁЃ
- ЙўЯЃКЏЪ§ЕФЪфШыгђПЩвдНќЫЦПДГЩЮоЧюДѓ
- ЯрЭЌЕФЪфШывЛЖЈЪфГіЯрЭЌЕФжЕ
- ВЛЭЌЕФЪфШыПЩФмЛсВњЩњЯрЭЌЕФЪфГі,етжжЧщПіГЦЮЊ
ХізВ,етжжИХТЪМЋЕЭ - ЙўЯЃКЏЪ§зюживЊЕФаджЪ:ВЛЭЌЕФЪфШыМИКѕПЩвдОљдШЕиЩЂСадкЪфГігђжа
**ОЙ§ЙўЯЃЫуЗЈКѓЕУЕНвЛИіКмДѓЕФЪфГіжЕ,етаЉжЕПЩвдБЃжЄЕШИХТЪЕФОљдШЩЂСа,ЕЋЪЧетаЉЪфГіжЕЕФЗЖЮЇЪЧКмДѓЕФ,ШчЙћдйЖдИУЪ§жЕШЁФЃ %m ОЭПЩвдНЋЫљгаЕФЪфГіжЕНјвЛВНМЏжаЕН [0, m-1] етИіЗЖЮЇФк,ВЂЧвгГЩфЕН [0, m-1] УПИіжЕЩЯЕФЪ§СПвВПЩвдБЃжЄМИКѕЪЧЕШИХТЪЕФЁЃШЁФЃВйзїОЭЪЧНјвЛВНАяЮвУЧНЋЫљгаЪфГіжЕгжЩЂСадкСЫвЛИіИќМЏжаЕФЗЖЮЇРя **
HashTable
ЙўЯЃБэЕФжїБэПЩвдПДГЩвЛИіЪ§зщ,Ъ§зщЕФГЄЖШОЭДњБэСЫЩЂСаЧјМфЕФГЄЖШ,ОЭЪЧmЕФШЁжЕгАЯьЕФЁЃУПвЛИіЪ§зщдЊЫиЖМЪЧвЛИіЕЅСДБэЕФЭЗ,ОЙ§ШЁФЃжЎКѓШчЙћЩЂСаЕНЯрЭЌЪ§зщдЊЫиЫїв§,ОЭздЖЏаЮГЩЕЅСДБэЁЃ
РЉШн
ЕБЕЅСДБэЕФГЄЖШДяЕНФГИіЯоЖШКѓ,ЙўЯЃБэЛсРЉШнЁЃРЉШнЕФТпМОЭЪЧ:дЯШЮвЪЧАбЫљгадЊЫиЩЂСадкСЫ7ИіЮЛжУ,ФЧЯждкЮвОіЖЈНЋЫљгадЊЫиЩЂСаЕН14ИіЮЛжУЩЯ,ЫљвдЪ§зщГЄЖШЛсБфЮЊ14,ВЂЧвЫљгадЊЫизюжеШЁФЃКѓЕФНсЙћвВвЊжиаТМЦЫуЁЃ
дкjavaжа,ЛЙЖдЕЅСДБэЪЕЯжСЫгХЛЏ,БШШчЫЕгУЪїДњЬцЕЅСДБэ
Р§Ьт
ЩшМЦвЛжжНсЙЙ,дкИУНсЙЙжагаШчЯТШ§ИіЙІФм:
- insert (key):НЋФГИіkeyМгШыЕНИУНсЙЙ,зіЕНВЛжиИДМгШы
- delete(key):НЋдБОдкНсЙЙжаЕФФГИіkeyвЦГ§
- getRandom():ЕШИХТЪЫцЛњЗЕЛиНсЙЙжаЕФШЮКЮвЛИіkeyЁЃ
вЊЧѓ:InsertЁЂdeleteКЭgetRandomЗНЗЈЕФЪБМфИДдгЖШЖМЪЧO(1)
public Hash(){
IntKeyMap = new HashMap<>();
KeyIntMap = new HashMap<>();
size = 0;
}
public void insert(K key){
if (!KeyIntMap.containsKey(key)){
KeyIntMap.put(key, size);
IntKeyMap.put(size++, key);
}
}
// ЩОГ§КѓindexОЭВЛСЌајСЫ,ФЧУДЫцЛњЕФЪБКђгаКмЖрЪ§ЖМВЛЪЧСЌзХЕФСЫЁЃЫљвдУПДЮгУзюКѓвЛИіЬюВЙвЊЩОГ§ЕФФЧИі
public void delete(K key){
if (KeyIntMap.containsKey(key)){
// ЛёЕУвЊЩОГ§ЕФkeyЕФindex
int index = KeyIntMap.get(key);
// ЛёЕУЕБЧАБэжазюКѓвЛИіindex
int lastIndex = --size;
// ЛёЕУЕБЧАБэжазюКѓвЛИіindexЖдгІЕФkey
K tail = IntKeyMap.get(lastIndex);
// ЬюВЙ
KeyIntMap.put(tail, index);
IntKeyMap.put(index, tail);
// ЩОГ§зюКѓЕФ
IntKeyMap.remove(lastIndex);
KeyIntMap.remove(key);
}
}
public K getRandom(){
if (size == 0)
return null;
int randomIndex = (int) (Math.random() * size);
return IntKeyMap.get(randomIndex);
}
}
hashвЛжТадЮЪЬт
дкЪ§ОнЗўЮёЦїЩЯ,ЭЈГЃгаЖрЬЈЗўЮёЦїДцДЂЪ§Он,ВЂЧвУПЬЈДцДЂЕФЖМВЛвЛбљ,ФЧУДвЛЬѕЪ§ОнШчКЮРДОіЖЈДцДЂдкФФЬЈЪ§ОнЗўЮёЦїЩЯФи? ЭЈГЃРДЫЕЪЧИљОнЙўЯЃЫуЗЈЧѓЙўЯЃжЕШЛКѓШЁФЃРДОіЖЈДцДЂдкФФЬЈЪ§ОнЗўЮёЦїЩЯЁЃетбљФмБЃжЄУПЬЈЗўЮёЦїЩЯЕФЪ§ОнОљКт,ВЂЧвжжРрвВОљКтЁЃЕЋЪЧЭЈЙ§ЪЙгУФФИізжЖЮРДЫуЙўЯЃОЭКмНВОПСЫЁЃМЬајжЎЧА,ЯШЕУУїАзЪВУДЪЧ ИКдиОљКт
ИКдиОљКтЪЧжИдквЛЬЈЗўЮёЦїЩЯ,АќКЌИпЦЕЪ§ОнЁЂжаЦЕЪ§ОнЁЂЕЭЦЕЪ§Он,ВЂЧвЪ§СПЯрЕБ,ОЭПЩвдШЯЮЊИУЗўЮёЦїИКдиОљКтЁЃ(етРяЕФИпжаЕЭЦЕЪЧжИБЛЫбЫїЕФЦЕТЪ)
ШчЙћвдзжЖЮЙњМвУћРДЙўЯЃЩЂСа,ВЂЧвгаШ§ЬЈЗўЮёЦї,ФЧБиШЛгавЛЬЈИКдиВЛОљКтЁЃвђЮЊИпЦЕЪ§ОнжЛгажаУРСНИіЙњМвЁЃ
ОЕфЗНЗЈЕФОжЯо
ЕБЭЛШЛаТдіЪ§ОнЗўЮёЦїЪБ,ЫљгаДцДЂЕФЪ§ОнЖМЕУШЋВПжиаТМЦЫуЙўЯЃжЕ,МѕЩйЗўЮёЦїЪБвВЪЧвЛбљЁЃгУЪВУДЗНЗЈВХФмШУетбљЗўЮёЦїЕФБфЖЏЕМжТЕФПЊЯњБфаЁФи?
ЙўЯЃвЛжТад
-
ЪзЯШАбЙўЯЃКЏЪ§ЕФЪфГігђЯыЯѓГЩвЛИіЛЗаЮгђЁЃ
-
МйЩшДЫЪБгаШ§ЬЈЪ§ОнЗўЮёЦї,ЫуЭъЙўЯЃжЕЮЊ5вк,6207вк,2Эђвк,ИљОнЙўЯЃжЕКѓЩЂСаГЩШчЯТЮЛжУ:
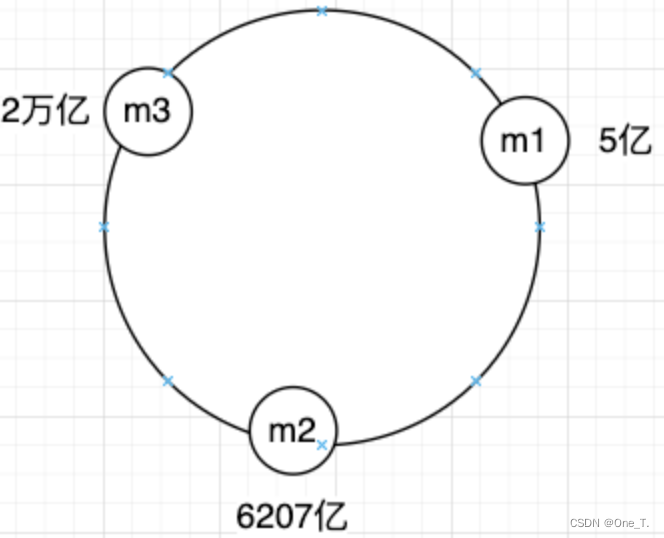 -
МйШчгаЬѕЪ§ОнЫуЭъЙўЯЃКѓвЊВхШыЕФЮЛжУШчЭМЫљЪО,ФЧгІИУДцДЂЕНФФИіЗўЮёЦїЩЯФи?
ЫГЪБеызюНќЕФЗўЮёЦї
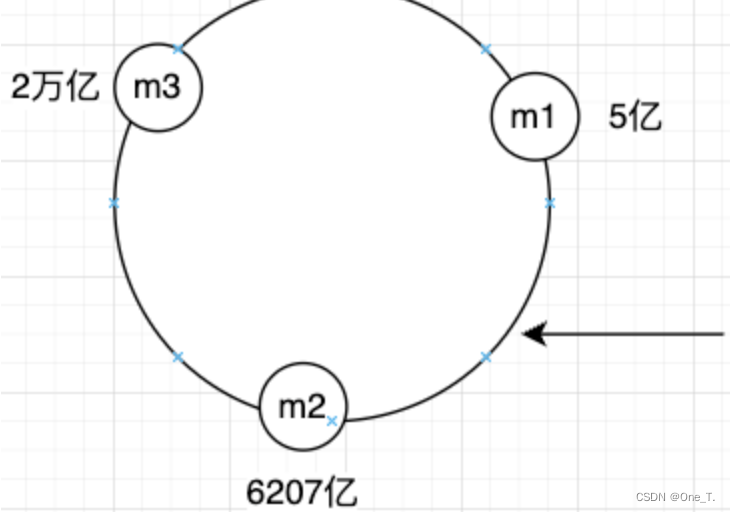
? етШ§ЬЈЗўЮёЦїЕФЙўЯЃНсЙћЛсАДееЫГађДцДЂдкЪ§зщжа,ШчКЮШЗЖЈЪ§ОндкФФЬЈЗўЮёЦїЩЯФи?НЋИУЪ§ОнЕФЙўЯЃНсЙћдкЪ§зщжагУЖўЗжВщевевЕНИУШЅФФЬЈЗўЮёЦїЁЃ
ЕБаТдівЛЬЈЗўЮёЦїЪБ,жЛашвЊвЛаЁВПЗжЕФЪ§ОнЧЈвЦОЭПЩвдЪЕЯжЗўЮёЦїЕФРЉШн,ДњМлБШжЎЧАаЁСЫКмЖрЁЃ
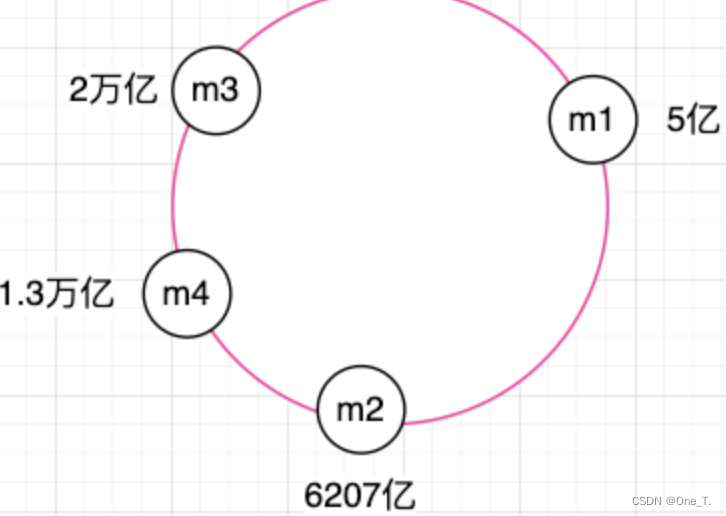
m2КЭm4жЎМфЕФЧјгђБОРДЪЧЙщm3ЙмЕФ,ЯждкаТМгСЫm4Кѓ,жЛашвЊвЊНЋетВПЗжЪ§ОнЧЈвЦжСm4ЩЯМДПЩ,ЦфгрЫљгаЕФЖМВЛгУЖЏЁЃМѕЩйЗўЮёЦїЪБвВвЛбљЁЃ
етжжНсЙЙШдШЛДцдкСНИіЮЪЬт
- ЗўЮёЦїКмЩйЪБ,ШчКЮФмОљЗжетИіЛЗаЮЕФЪфГігђ? ЩЯЭМШ§ЬЈЗўЮёЦїПЩВЛвЛЖЈЪЧОљЗжЪфГігђЕФ
- МДБуОљЗжСЫЪфГігђ,ЕБаТМгЛђепМѕЩйЗўЮёЦїЪБ,СЂПЬгжВЛОљКтСЫЁЃМгШыЩЯЪіШ§ЬЈЗўЮёЦїОљЗжЪфГігђ,УПЬЈИКд№ 1 / 3 1/3 1/3 ,ВЂЧвm4ЪЧm2КЭm3ЕФжаЕу,ДЫЪБm1,m2ИКд№ 1 / 3 1/3 1/3 ,Жјm3,m4жЛИКд№ 1 / 6 1/6 1/6
етСНИіЮЪЬтЖМПЩвдгУащФтНсЕуММЪѕНтОі
ащФтНсЕу
ЗжБ№ИјШ§ЬЈЗўЮёЦїЗжХф1000ИізжЗћДЎ,УПИізжЗћДЎЖМПЩвдДњБэЦфЫљЪєЕФЗўЮёЦї,ШчЯТ:
m 1 ?? ( a 1 , a 2 , . . . , a 1000 ) m1 \; (a_1,a_2,..., a_{1000}) m1(a1?,a2?,...,a1000?)
m 2 ?? ( b 1 , b 2 , . . . , b 1000 ) m2 \; (b_1,b_2,..., b_{1000}) m2(b1?,b2?,...,b1000?)
m 3 ?? ( c 1 , c 2 , . . . , c 1000 ) m3 \; (c_1,c_2,..., c_{1000}) m3(c1?,c2?,...,c1000?)
УПЬЈЛњЦїЩЯЕФ1000ИізжЗћДЎЗжБ№ЫувЛИіЙўЯЃжЕШЛКѓШЅЛЗЩЯеМЮЛ,етбљЛЗЩЯвЛЙВОЭга3000ИіНкЕу,етбљОЭПЩвдБЃжЄУПЬЈЛњЦїЙмЯНЕФЪфГігђДѓжТЯрЕШЁЃШчЙћгааТЕФЗўЮёЦївЊМгШы,ЭЌбљгУ1000ИіНсЕуЩЯШЅеМЮЛ,етбљаТЕФЛњЦїДгЦфЫћШ§ЬЈФЧРяЧРЙ§РДЕФЪ§СПМИКѕЯрЕШЁЃ
ДЫЭт,ащФтНсЕуЛЙФмИљОнЗўЮёЦїадФмЕФВювьЖЏЬЌЙмРэЗўЮёЦїЁЃМйШчm1адФмЬиБ№ЧПКЗ,ФЧЮвОЭПЩвдИјЫќЗжХф2000ИізжЗћДЎШЅеМЮЛ,ФГЬЈЛњЦїЕФадФмБШНЯШѕОЭПЩвдЗжХфНЯЩйЕФзжЗћДЎЁЃ