ХХађНщЩм
СаБэХХађ:НЋЮоађСаБэБфГЩгаађСаБэ(Щ§ађЛђНЕађ)
ФкжУХХађКЏЪ§:sort()
ГЃМћХХађЫуЗЈ:
LBШ§ШЫзщ:УАХнХХађЁЂбЁдёХХађЁЂВхШыХХађ
NBШ§ШЫзщ:ПьЫйХХађЁЂЖбХХађЁЂЙщВЂХХађ
ЦфЫћХХађ: ЯЃЖћХХађЁЂМЦЪ§ХХађЁЂЛљЪ§ХХађЁЂЭАХХађ
УАХнХХађ
СаБэУПСНИіЯрСкЕФЪ§,ШчЙћЧАУцБШКѓУцДѓ,дђНЛЛЛетСНИіЪ§ЁЃ(ж№вЛБШНЯ)вЛЬЫХХађЭъГЩКѓ,ЮоађЧјМѕЩйвЛИіЪ§,гаађЧјдіМгвЛИіЪ§ЁЃ(УПвЛЬЫЖМЛсАбЮоађЧјЕФзюДѓЪ§ЬєГіРД)
ДњТыЙиМќЕу:ЮоађЧјЁЂгаађЧјЁЂЬЫЁЂЮоађЧјЕФЗЖЮЇ
import random
def bubble_sort(li):
for i in range(len(li)-1):
#БъжОЮЛ
exchange = False #гХЛЏХХађ,ОжВПгаЫГађ,ПЩвдМѕЩйвЛЖЈЕФХХађВНжш
for j in range(len(li)-i-1):#ЮоађЧј
if li[j]>li[j+1]:##ДЫЮЊЩ§ађ,НЕађОЭашвЊИФЮЊ<
li[j],li[j+1] = li[j+1],li[j]#ЯрСкСНдЊЫиНјааНЛЛЛ
exchange = True
if not exchange:
return #вЛЬЫЖМВЛгУЗЂЩњНЛЛЛ,БэУївбОХХКУађ,ВЛгУНјааЖргрЕФВНжш
lii = [random.randint(0,10000) for i in range(1000)]
print(lii)
bubble_sort(lii)
print(lii)
бЁдёХХађ
УПЬЫХХађЖММЧТМзюаЁЕФЪ§,НЋЦфвРДЮЗХдкЧАУцЕФЮЛжУЁЃ
ДњТыЙиМќЕу:гаађЧјЁЂЮоађЧјЁЂЮоађЧјзюаЁЪ§ЕФЮЛжУ
#бЁдёзюаЁЕФЗХдквЛИіПеСаБэжа
def select_sort_sample(li):
li_new=[]#ЩњГЩСНИіСаБэ,еМгУИќЖрФкДц;O(n^2)
for i in range(len(li)):
min_val = min(li)
li_new.append(min_val)
li.remove(min_val)
return li_new
li = [2,1,6,9,6,7,3,2,6]
#print(select_sort_sample(li))
def select_sort(li):
for i in range(len(li)-1):
min_loc = i
for j in range(i+1,len(li)):
if li[j] < li[min_loc]:
min_loc = j
li[i],li[min_loc] = li[min_loc],li[i]#НЋзюаЁЕФЪ§ЗХдкЧАУц,гыжЎНЛЛЛЕФдЊЫиЗХдкЦфдРДЕФЮЛжУ
select_sort(li)
print(li)
ВхШыХХађ
ГѕЪМЕФСаБэЪЧгаађЕФ,УПДЮДгЮоађЧјжаФУГівЛИіЪ§,НЋЦфВхШыЕНгаађЕФСаБэжаЁЃ
def insert_sort(li):
for i in range(1,len(li)):
tmp = li[i]
j = i-1
while j>=0 and li[j]>tmp:#БШУўЕНЕФХЦДѓЕФЪ§ЭљКѓвЦ,jЯрЕБгквЛИіаЁжИеы
li[j+1] = li[j]
j -= 1
li[j+1] = tmp
li = [2,3,1,3,2,8,3,2,4]
insert_sort(li)
print(li)ПьЫйХХађ
ЫМТЗ:
1.ШЁвЛИідЊЫиp,ЪЙЦфЙщЮЛ;
2.СаБэБЛpЗжГЩСНВПЗж,зѓБпЖМБШpаЁ,гвБпЖМБШpДѓ(евЮЛжУашвЊгУЕНЗДЯђЫЋжИеы)
3.ЕнЙщЭъГЩХХађ
##аоИФЕнЙщзюДѓЩюЖШ
import sys
sys.setrecursionlimit(10000000)
##ЫцЛњПьЫйХХађ,БмУтзюЛЕЧщПі ##https://blog.csdn.net/The_Shiled/article/details/121777268
def partition(li,left,right):
tmp = li[left]
while left < right:
while left < right and li[right]>=tmp:#ДггвУцевГіБШtmpаЁЕФЪ§
right -= 1#ЭљзѓзпвЛВН
li[left] = li[right]#АбгвБпЕФжЕаДЕНзѓБпЕФПеЮЛЩЯ
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left]#АбзѓБпЕФжЕаДЕНгвБпЕФПеЮЛЩЯ
li[left] = tmp#НЋtmpЙщЮЛ
return left
def quick_sort(li,left,right):
if left < right:
mid = partition(li,left,right)
quick_sort(li,left,mid-1)
quick_sort(li,mid+1,right)ЖбХХађ
ЖўВцЪї:ЖШВЛГЌЙ§2ЕФЪїЁЃУПИіНкЕузюЖргаСНИізгНкЕуЁЃ
ТњЖўВцЪї:вЛИіЖўВцЪї,ШчЙћУПвЛВуЕФНкЕуЪїЖМДяЕНзюДѓжЕ,дђетИіЪїЮЊТњЖўВцЪїЁЃ
ЭъШЋЖўВцЪї:вЖНкЕужЛФмГіЯждкзюЯТВуКЭДЮЯТВу,ВЂЧвзюЯТВуЕФНкЕуЖММЏжадкИУВуЕФзюзѓБпЕФШєИЩИіЮЛжУЕФЖўВцЪїЁЃ
?ЖўВцЪїЕФДцДЂЗНЪНгаСДЪНДцДЂЗНЪНЁЂЫГађДцДЂЗНЪНЁЃетРяВЩгУЕФЪЧЫГађДцДЂЗНЪНЁЃ
Жб:вЛжжЬиЪтЕФЭъШЋЖўВцЪїНсЙЙЁЃгаЫГађЕФ
ДѓИљЖб:вЛПУЭъШЋЖўВцЪї,ТњзуШЮвЛНкЕуЖМБШЦфКЂзгНкЕуДѓЁЃ
аЁИљЖб:вЛПУЭъШЋЖўВцЪї,ТњзуШЮвЛНкЕуЖМБШЦфКЂзгНкЕуаЁЁЃ
ЖбЕФЯђЯТЕїећ:МйЩшНкЕузѓгвзгЪїЖМЪЧЖб,ЕЋздЩэВЛЪЧЖбЁЃПЩвдЭЈЙ§ЯђЯТЕїећБфГЩЖбЁЃ
ЖбХХађЙ§ГЬ:
1.НЈСЂЖбЁЃ
2.ЕУЕНЖбЖЅдЊЫи,ДЫЮЊзюДѓдЊЫиЁЃ
3.ШЅЕєЖбЖЅ,НЋЖбзюКѓвЛИідЊЫиЗХЕНЖбЖЅ,ДЫЪБПЩвдЭЈЙ§вЛДЮЯђЯТЕїећжиаТЪЙЖбгаађЁЃ
4.ЖбЖЅдЊЫиЮЊЕкЖўДѓдЊЫиЁЃ
5.жиИДВНжш3,жИЕМЖбБфПеЁЃ
#ДѓИљЖб
def sift(li,low,high):
'''
li:СаБэ
low:ЖбЕФИљНкЕуЮЛжУ
high:ЖбЕФзюКѓвЛИіНкЕуЕФЮЛжУ
'''
i = low#iзюПЊЪМжИЯђИљНкЕу,жЎКѓжИЯђУПвЛзгЪїЕФИљНкЕу евИИНкЕугызгНкЕуЕФЙиЯЕ
j = 2*i+1#jПЊЪМЪЧзѓКЂзг
tmp = li[low]#АбЖбЖЅДцЦ№РД
while j <= high:#жЛвЊjЮЛжУгаЪ§
if j+1<= high and li[j+1]>li[j]:#ШчЙћгвКЂзгДцдкЧвНЯДѓ
j = j+1#jжИЯђгвКЂзг
if li[j]>tmp:
li[i] = li[j]
i = j #ЭљЯТПДвЛВу
j = 2*i+1
else:
break#НсЪјбЛЗ
li[i] = tmp#зюКѓвЛВуСЫ СНДЮНсЪјбЛЗ,ЖМашвЊАбtmpЗХЛиРД
def heap_sort(li):
n = len(li)
for i in range((n-2)//2,-1,-1):#iБэЪОНЈЖбЪБЕїећВПЗжИљЕФЯТБъ
sift(li,i,n-1) #ЩшhighжИзюКѓвЛВу
#НЈЖбЭъБЯ
for i in range(n-1,-1,-1):#iжИЯђЕБЧАЖбЕФзюКѓвЛИіНкЕуЕФЮЛжУ
li[0],li[i] = li[i],li[0]
sift(li,0,i-1)#i-1ЪЧаТЕФhigh
li = [i for i in range(100)]
# li = list(range(100))
import random
random.shuffle(li)
print(li)
# heap_sort(li)
# print(li)
##ЖбХХађЕФФкжУДњТы
import heapq#гХЯШЖгСа аЁЕФЯШГі,ЛђДѓЕФЯШГі
heapq.heapify(li)#НЈЖб аЁИљЖб
#heapq.heappop(li)#ЯђЭтЕЏГізюаЁдЊЫи Щ§ађ
lii = []
for i in range(len(li)):
lii.append(li[i])
print(lii)ЖбХХађЁЊЁЊtopkЮЪЬт
ЯждкгаnИіЪ§,ЩшМЦЫуЗЈЕУЕНЧАkИіДѓЕФЪ§ЁЃ
ШЁСаБэЧАkИідЊЫиНЈСЂвЛИіаЁИљЖб,ЖбЖЅОЭЪЧФПЧАЕкkДѓЕФЪ§ЁЃ
вРДЮЯђКѓБщРњдСаБэ,ЖдгкСаБэжаЕФдЊЫи,ШчЙћаЁгкЖбЖЅ,дђКіТд;ШчЙћДѓгкЖбЖЅ,дђНЋЖбЖЅИќЛЛЮЊИУдЊЫи,ВЂЧвЖдЖбНјаавЛДЮЕїећЁЃ
БщРњСаБэЫљгадЊЫиКѓ,ЕЙађЕЏГіЖбЖЅЁЃ
def sift(li,low,high):#аЁИљЖб
'''
li:СаБэ
low:ЖбЕФИљНкЕуЮЛжУ
high:ЖбЕФзюКѓвЛИіНкЕуЕФЮЛжУ
'''
i = low#iзюПЊЪМжИЯђИљНкЕу,жЎКѓжИЯђУПвЛзгЪїЕФИљНкЕу
j = 2*i+1#jПЊЪМЪЧзѓКЂзг
tmp = li[low]#АбЖбЖЅДцЦ№РД
while j <= high:#жЛвЊjЮЛжУгаЪ§
if j+1<= high and li[j+1]<li[j]:#ШчЙћгвКЂзгДцдкЧвНЯаЁ
j = j+1#jжИЯђгвКЂзг
if li[j]<tmp:
li[i] = li[j]
i = j #ЭљЯТПДвЛВу
j = 2*i+1
else:
break#НсЪјбЛЗ
li[i] = tmp#зюКѓвЛВуСЫ СНДЮНсЪјбЛЗ,ЖМашвЊАбtmpЗХЛиРД
def topk(li,k):
heap=li[0:k]
for i in range((k-2)//2,-1,-1):#iБэЪОНЈЖбЪБЕїећВПЗжИљЕФЯТБъ
sift(li,i,k-1) #ЩшhighжИзюКѓвЛВу
for i in range(k,len(li)):#БщРњ
if li[i]>heap[0]:
heap[0] = li[i]
sift(heap,0,k-1)
for i in range(k-1,-1,-1):#ГіЪ§
heap[0],heap[i] = heap[i],heap[0]
sift(heap,0,i-1)
return heap
def heap_sort(li):
n = len(li)
for i in range((n-2)//2,-1,-1):#iБэЪОНЈЖбЪБЕїећВПЗжИљЕФЯТБъ
sift(li,i,n-1) #ЩшhighжИзюКѓвЛВу
#НЈЖбЭъБЯ
for i in range(n-1,-1,-1):#iжИЯђЕБЧАЖбЕФзюКѓвЛИіНкЕуЕФЮЛжУ
li[0],li[i] = li[i],li[0]
sift(li,0,i-1)#i-1ЪЧаТЕФhigh
import random
li = list(range(1000))
random.shuffle(li)
print(li)
print(topk(li,100))
ЙщВЂХХађ
МйЩшЯждкЕФСаБэЗжГЩСНЖЮгаађ,ШчКЮНЋЦфКЯГЩвЛИігаађСаБэ,етбљЕФВйзїГЦЮЊвЛДЮЙщВЂЁЃ
#ОжВПгаађЕФХХађ
def merge(li,low,mid,high):#ЭЌЯђЫЋжИеы
i = low
j = mid+1
l_tmp = []
while i <= mid and j <= high:#ашвЊСНБпЖМгаЪ§
if li[i]<li[j]:
l_tmp.append(li[i])
i += 1
else:
l_tmp.append(li[j])
j += 1
#жДааЭъwhileКѓ,ПЯЖЈгавЛВПЗжУЛгаЪ§
while i <= mid :
l_tmp.append(li[i])
i += 1
while j <= high:
l_tmp.append(li[j])
j+= 1
li[low:high+1] = l_tmp
li = [2,4,5,7,4,6,7,8]
merge(li,0,3,7)
#print(li)
def merge_sort(li,low,high):
mid = (low+high)//2
if low < high:#жСЩйгаСНИідЊЫи
merge_sort(li,low,mid)
merge_sort(li,mid+1,high)
merge(li,low,mid,high)
merge_sort(li,0,7)
print(li)
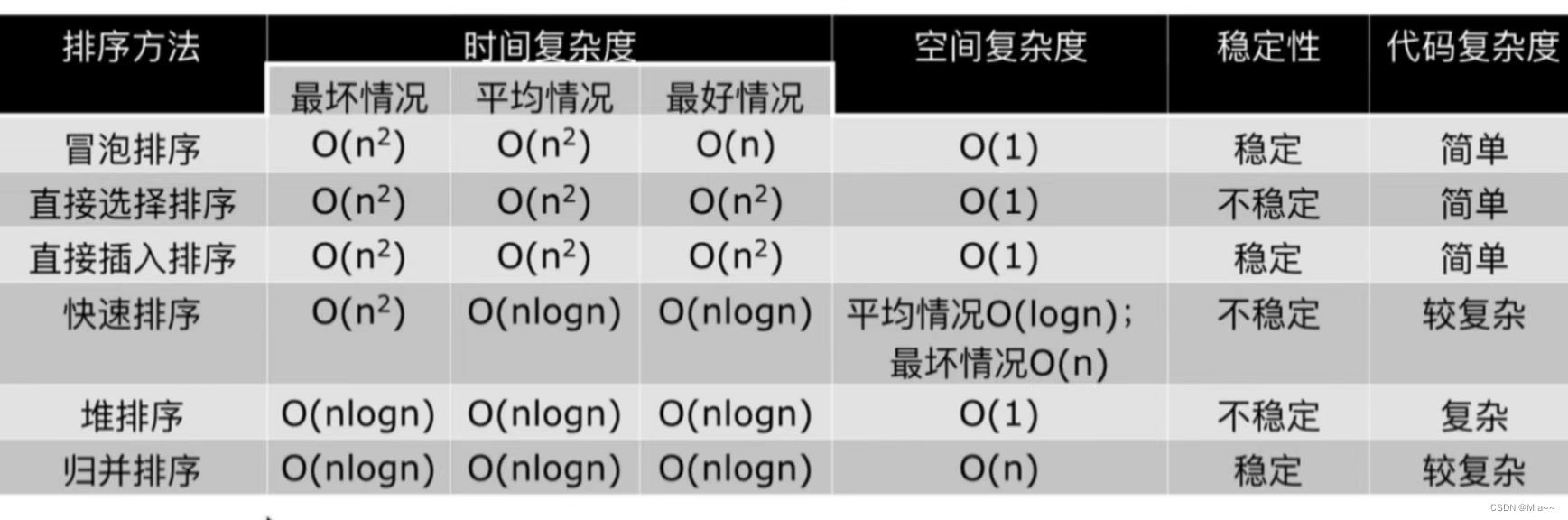
ЯЃЖћХХађ
вЛжжЗжзщВхШыХХађЁЃ
ЪзЯШШЁвЛИіећЪ§d1=n/2,НЋдЊЫиЗжЮЊdзщ,УПзщЯрСкдЊЫижЎМфОрРыЮЊd1,дкИїзщФкНјаажБНгВхШыХХађ;
ШЁЕкЖўИіећЪ§d2=d1/2,жиИДЩЯЪіЗжзщХХађЙ§ГЬ,жБЕНdi=1,МДЫљгадЊЫидкЭЌвЛзщФкНјаажБНгВхШыХХађЁЃ
ЯЃЖћХХађУПЬЫВЂВЛЪЧЪЙФГаЉдЊЫигаађ,ЖјЪЧЪЙећЬхЪ§ОндНРДдННгНќгаађ,зюКѓвЛЬЫХХађВХФмЪЙЪ§ОнгаађЁЃ
def insert_sort_gap(li,gap):
for i in range(gap,len(li)):
tmp = li[i]
j = i-gap
while j>=0 and li[j]>tmp:#БШУўЕНЕФХЦДѓЕФЪ§ЭљКѓвЦ,jЯрЕБгквЛИіаЁжИеы
li[j+gap] = li[j]
j -= gap
li[j+gap] = tmp
def shell_sort(li):
d = len(li)//2
while d >= 1:
insert_sort_gap(li,d)
d//=2
МЦЪ§ХХађ
ЖдСаБэНјааХХађ,вбжЊСаБэжаЕФЪ§ЗЖЮЇЖМдк0ЕН100жЎМфЁЃ
#ВЛЪЧБШНЯЗНЗЈ
def count_sort(li,max_count=100):
count = [0 for _ in range(max_count+1)]
for val in li:
count[val] += 1
li.clear()
for ind, val in enumerate(count):#ЕУЕНУПвЛИіЪ§зжГіЯжЕФЦЕЪ§
for i in range(val):
li.append(ind)
import random
li = [random.randint(0,100) for _ in range(100)]
print(li)
count_sort(li,max_count=100)
print(li)
# li = [1,2,3,6,3,4,2,1]
# count_sort(li,max_count=100)
# print(li)
ЭАХХађ
дкМЦЪ§ХХађжа,ШчЙћдЊЫиЕФЗЖЮЇБШНЯДѓ,ПЩвдЪЙгУЭАХХађЁЃ
ЭАХХађ:ЪзЯШНЋдЊЫиЗждкВЛЭЌЕФЭАжа,дйЖдУПИіЭАжаЕФдЊЫиХХађЁЃ
def bucket_sort(li,n = 100,max_num = 10000):
bucket = [[] for _ in range(n)]#ДДНЈвЛИіЖўЮЌСаБэ
for val in li:
i = min(val//(max_num//n),n-1)#ЗХЕНЕкМИКХЭАжа,ЖдгкзюКѓвЛИіЪ§,бЁдёЗХдкзюКѓвЛИіЭАжа
bucket[i].append(val)
#ХХађ РрЫЦгкУАХнХХађ ДгКѓЭљЧАж№вЛЕигыЧАУцЕиЪ§НјааБШНЯ
for j in range(len(bucket[i])-1,0,-1):
if bucket[i][j]<bucket[i][j-1]:
bucket[i][j],bucket[i][j-1] = bucket[i][j-1],bucket[i][j]
else:
break
sorted_li = []
for buc in bucket:
sorted_li.extend(buc)## extend:зЗМгСаБэ,СаБэБЛВ№ЗжЮЊвЛИівЛИідЊЫи
return sorted_li
import random
li = [random.randint(0,10000) for i in range(100)]
print(li)
#bucket_sort(li)
print(bucket_sort(li))
ЛљЪ§ХХађ
ЖрЙиМќзжХХађ:ШчМгШыЯждкгавЛИідБЙЄБэ,вЊЧѓЯШАДееаНзЪХХађ,ФъСфЯрЭЌЕФдБЙЄАДееФъСфХХађЁЃ
#РрЫЦгкЖрЙиМќДЪХХађ
#ЖрДЮзАЭА,АДееЮЛЪ§ДгаЁЕНДѓзАЭА,зюКѓЪфГі,УЛгаЭАФкХХађЕФЙ§ГЬ
#ИіЮЛНјЭА,ЪЎЮЛНјЭА,АйЮЛНјЭАЕШ
def radix_sort(li):
max_num = max(li)
it = 0
while 10**it <= max_num:
buckets = [[] for _ in range(10)]
for val in li :
digit = (val // 10**it)%10
buckets[digit].append(val)
li.clear()
for buc in buckets:
li.extend(buc)
it += 1
li = [234,678,945,34,65,78,231,765,987]
radix_sort(li)
print(li)