���ݽṹ

����
���� :�����������������ܱ�����������ĸ��ַ��ŵļ���
- ��������Ϣ������
- �ǶԿ�������Ż��ñ�ʾ
- ���ܹ��������ʶ�𡢴洢�ͼӹ�
����Ԫ��
- �����ݵ�������λ,�ڼ����������ͨ����Ϊһ�����忼�Ǻʹ���
- Ҳ��ΪԪ�� ���¼ ��� ��
- ����Ԫ�����������ɸ����������
������
-
��������Ԫ�ز����Էָ����С��λ ���ж������岻��ɷָ�
���ߵĹ�ϵ ���� > ����Ԫ�� > ������
? �� ѧ���� > ���˼�¼ > ѧ�š�����
���ݶ���
- ��������ͬ������Ԫ�صļ��� �����ݵ�һ���Ӽ�
����Ԫ�������ݶ���
- ����Ԫ�� ������ݵĻ�����λ
- �����ݵĹ�ϵ:�Ǽ��ϵ� �� ��
- ���ݶ��� ������ͬ������Ԫ�صļ���
- �����ݵĹ�ϵ�� :���ϵ��Ӽ�
���ݽṹ
? ���� : ������Ԫ��֮�����һ�ֻ�����ض���ϵ������Ԫ������
-
���ṹ
���� :������Ԫ�ؼ�Ĺ�ϵ
- ���� ����Ԫ��ͬ��һ������ ����������ϵ
- ���Խṹ ����Ԫ��֮����� һ�Ե�һ�Ĺ�ϵ ����һ��Ԫ�� ���е�Ԫ�ض���ǰ�� �������һ��Ԫ�� ����Ԫ�ض������ û��ǰ��Ԫ�صĵĽڵ����dz�Ϊ��ʼԪ�� û�к��Ԫ�ص�������Ԫ��Ϊ�ն�Ԫ��
- ���νṹ ����Ԫ�ش���һ�Զ��Ĺ�ϵ
- ͼ״�ṹ(��״�ṹ) ������Զ���Ԫ��
-
�����ṹ (�洢�ṹ)
����:���ṹ�������ڴ��е�ӳ��
- ˳��洢 ��һ�������洢��Ԫ�����洢����Ԫ�� ����Ԫ�� ֮�������ϵ��Ԫ�ص��洢λ������ʾ c��������������ʵ�ֱ�ʾ
- ��ʽ�洢 ��һ�������Ĵ洢��Ԫ�洢����Ԫ�� ����Ԫ��֮�������ϵ��ָ������ʾ
- �����洢 �ڴ洢Ԫ����Ϣ��ͬʱ ���������ӵ������� �������е�ÿ���Ϊ������ �������һ����ʽ��(�ؼ��� ��ַ) �ؼ�������Ψһ��ʶһ��Ԫ�ص�������
- ɢ�д洢 ����Ԫ�صĹؼ��ֿ���ֱ�Ӽ������Ԫ�صĴ洢��ַ �ֳƹ�ϣ�洢
-
���ݵ�����
����Ķ�����������ṹ�� �����ʵ������Դ洢�ṹ��

�������ͺͳ�����������
- ��������
? ���� :һ��������ͬ��ֵ�ļ��� �൱�ڶ������ֵ�����ϵ�һ������ܳ�
-
ԭ������ ���е�ֵ �������ٷ� �� int byte
-
�ṹ���� ��ֵ�����ٷֽ�Ϊ���ɵijɷ� ����������
-
������������
����: ָһ����ѧģ���Լ������ڴ���ѧģ���ϵ�һ���������ͨ���Ƕ����ݵ�ij�ֳ���,���������ݵ�ȡֵ��Χ�����ṹ��ʽ,�Լ������ݲ����ļ�����
- �������������� = ���ݵ����ṹ + ���������
- ���������ѧģ���� �������������ݽṹ�������ݽṹ������ ������ʵ�ʵĵĴ洢�ṹ �;���ʵ�ֵ��㷨 ͨ�����Ծ������۽�û�б�ʵ�ʶ���
- D���ݶ��� S���ݹ�ϵ p ��������
- ���� ��Ϣ���� ���ݷ�װ ʹ����ʵ�ַ���
�㷨
- ����: �㷨�Ƕ��ض���������ⲽ���һ������ ����ָ����������� ����ָ����һ����������
- �ص� :
- ������ ���� �� ʱ�� ���� �����������
- ȷ���� ÿ��ָ������ȷ�ĺ��� û�ж����� ��ͬ������ֻ�ܵõ���ͬ�����
- ������ �㷨�ǿ�ִ�е� ���Թ�ͨ��ʵ�ֻ�������ִ��������
- ������ �������������� ���� ������ָ���ⲿ�豸������
- ����� һ������������
- �㷨��Ƶ�Ҫ��
- ��ȷ�� :�㷨�ܹ���ȷ�Ľ������
- �ɶ���:����ʹ�˵����� �㷨���������������� �� �ͽṹ����
- ��׳�� �㷨���кܺõ��ݴ��� ���ں��������ݽ��м�� �������ж�
- ��Ч��:����ʱ���� �;����͵Ĵ洢����
�㷨ʱ�����ܷ���
- �º���㷨 ����������ü�ʱ������
- ��ǰͳ�Ʒ� �������ģ��С�й�
ʱ�临�Ӷ�
- ���� :��ǰԤ�� ʱ�俪��(Tn)�������ģn�Ĺ�ϵ
- ʱ�临�ӶȵĴ�С��ϵ
O ( 1 ) < O ( log ? 2 n ) < O ( n log ? 2 n ) < O ( n ) < O ( n 2 ) < O ( n 3 ) < O ( 2 n ) < O ( n ! ) O(1) < O(\log_2n) < O(n\log_2n) < O(n) < O(n^2) < O(n^3) < O(2^n) < O(n!) O(1)<O(log2?n)<O(nlog2?n)<O(n)<O(n2)<O(n3)<O(2n)<O(n!)
�ռ临�Ӷ�
����:�㷨����Ҫ�洢�ռ� �������ģ�Ĺ�ϵ
���Խṹ
���Ա�
- ���� : ���Ա��Ǿ�����ͬ����������n��������Ԫ�ص�һ����������
- �ص�
- ������ ���Ա��е�Ԫ�ظ���������
- һ���� һ�����Ա��е�����Ԫ�ص���������ͬ��
- ������ һ�����Ա�������Ԫ��֮������λ�������Ե�
- ����Ψһ����ʼԪ�����ն�Ԫ��,����֮��,ÿ��Ԫ��ֻ��Ψһ��ǰ��Ԫ���� ���Ԫ����
- ��Ԫ�������Ա��е� λ��ֻȡ�������ǵ����,������һ�����Ա��п��Դ�������ֵ��ͬ��Ԫ�ء�
- ��������
- ��ʼ����
- ����ij���
- ���ҵ�i��Ԫ��
- ����Ų���
- ָ��λ�ò���
- �ж��Dz��ǿձ�
- ɾ��ij��Ԫ��
˳���
����:ָ��һ����ַ�����Ĵ洢��Ԫ���δ洢���Ա��еĸ���Ԫ�ء�ʹ�����Ա��������ṹ�����ڵ�����Ԫ�ش洢�����ڵ������洢��Ԫ��
�ص�:
- �������,������O(1)ʱ�����ҵ���i��Ԫ�ء�
- �洢�ܶȸ�,ÿ���ڵ�ֻ�洢����Ԫ�ر���
- ��չ����������(�����ö�̬����ķ�ʽʵ�� )
- ���롢ɾ������������,��Ҫ�ƶ�����Ԫ��
����:
-
�ṹ��
typedef int dataType; //��̬���� typedef struct { dataType data[MAXSIZE]; //�����ʵ�ʳ��� int len; } SeqList; //��̬���� typedef struct { dataType *data; int MaxSize; int length } SqList; -
��ʼ��
//��̬�����ʼ�� void InitList(SqList *list, int initSize) { list->MaxSize = initSize; //����MaxSize�� �ڴ�ÿ��Ĵ�С��dataType��С list->data = calloc(list->MaxSize, sizeof(dataType)); //�����ڴ�ʧ��ֱ���˳� if (list->data == NULL) exit(1); //��ʼ���ڴ�ռ� for (int i = 0; i < list -> MaxSize; i++) { list->data[i] = 0; } list->length = 0; } //��̬�����ʼ�� void InitList(SqList *list) { list->length = 0; for (int i = 0; i < MaxSize; i++) { list->data[i] = 0; } } -
��������
bool ListInsert(SqList *list, int i, dataType e) { /** * @param list ����˳����ĵ�ָ����� * @param i ����Ԫ�صĵ�λ�� * @param e �����Ԫ�� * @return �Dz��Dz���ɹ� * */ if (i < 1 || i > list->length + 1) return false; //����ռ䲻���Ͷ�̬��������Ĵ�С ǰ���Ǹ������Ƕ�̬����Ŀռ� if (list->length == list->MaxSize) InCreaseSize(list, list->MaxSize); //��1��Ԫ�� ���һ��Ԫ�� ���һ��Ԫ�غ��� ��i��Ԫ�ؼ�֮��Ķ����� //�����ʱ��ֻ��Ҫ���е���i�μȿ����� for (int j = list->length; j >= i; --j) { list->data[j] = list->data[j - 1]; } list->data[i - 1] = e; //�ڵ�i��Ԫ�ش����Ԫ��e list -> length++; return true; }��õ�ʱ�临�Ӷ� ��Ԫ�ز��뵽��β����Ҫ�ƶ�Ԫ��
��ĵ�ʱ�临�Ӷ� ��Ԫ�ز��뵽��ͷ��Ҫ�ƶ�n��Ԫ��
ƽ����� (0+ 1+2+3 + 4 +5 +'��+n) / n + 1 = n 2 \frac{n}{2} 2n?
-
��̬���������С
//��̬�������鳤�� void InCreaseSize(SqList * list,int len){ list -> MaxSize += len; list -> data = realloc(list -> data, list -> MaxSize); } -
ɾ������
bool ListDelete(SqList *list, int i, dataType *e) { if (i < 1 || i > list -> length) return false; //�жϲ���ķ�Χ�Ƿ���Ч /** *@param list ˳��� * @param e ɾ��Ԫ�����ڵ�λ������ * @param i ɾ��Ԫ�ص�λ�� * */ *e = list->data[i - 1]; //�ѵ�i��Ԫ��ǰ�� for (int j = i - 1; j < list->length - 1; ++j) { list->data[j] = list->data[ j + 1]; } list->length--; return true; }- ʱ�临�Ӷ�
- ��õ� �ڱ�βһ��������Ҫɾ��
- � �ڱ�ͷ�ڵ�һ��
- ƽ�� (1 + 2 + 3 +��+n-1)/n = (n - 1)/2
- ʱ�临�Ӷ�
-
��������
//��ֵ�������� int Local_SeqList(SeqList al, dataType e) { int i; for (i = 0; i <= al.len; i++) { if (al.data[i] == e) return i + 1; } return ERROR; }- ʱ�临�Ӷ� (1 + 2 + 3 + ��+n)/n = (n + 1) / 2
-
��ȡֵ
//��ȡ���е�ֵ int get_SeqList(SeqList al, dataType i, dataType *j) { if (i < 1 || i < al.len + 1) return ERROR; return al.data[i - 1]; }
��ʽ
- ����Ԫ������ n - i + 1
- ɾ��Ԫ�� n - i
����
- ��ʽ�洢�ṹ
- ����:��ʽ�洢�����Ա���Ϊ����,�����еĴ洢Ԫ�ز�һ����������,Ԫ�ؽڵ��д������Ԫ���Լ�����Ԫ�صĵ�ַ��Ϣ ����Ԫ�ص���˳����ͨ�������е�ָ�����Ӵ���ʵ�ֵġ�
- �ص�:
- �洢�ܶȵ�
- ���ݵIJ����ɾ������Ҫ�ƶ�Ԫ�� �����������
- ����Ԫ��֮�������ϵͨ��ָ��ȷ��
������
- �������Ľṹ��
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList;
- ��ʼ��
//��ͷ�ڵ�ij�ʼ��
LinkList initList() {
//�����µĽڵ���Ϊͷ�ڵ�
LinkList list = malloc(sizeof(LNode));
list->next = NULL;
return list;
}
//����ͷ�ڵ�ij�ʼ��
LinkList initList() {
//�����µĽڵ���Ϊͷ�ڵ�
LinkList list = NULL;
return list;
}
- ͷ�巨��������
//��ͷ�ڵ�
void createList_H(LinkList list, int n) {
for (int i = 0; i < n; i++) {
//�����ڵ� ���Ҹ��ýڵ㸳ֵ
LNode *p = malloc(sizeof(LNode));
printf("�������%d����:", i + 1);
scanf("%d", &(p->data));
p->next = list->next;
list->next = p;
}
}
//����ͷ�ڵ��
void createList_H(LinkList *list, int n) {
for (int i = 0; i < n; i++) {
//�����ڵ� ���Ҹ��ýڵ㸳ֵ
LNode *p = malloc(sizeof(LNode));
printf("�������%d����:", i + 1);
scanf("%d", &(p->data));
//����ǵ�һ��Ԫ�صIJ���д��
if (*list == NULL){
p->next = NULL;
*list = p;
continue;
}
//��p����һ��λ��ָ���һ��Ԫ��
p->next = *list;
*list = p;//��listָ���µ�Ԫ��
}
}
- β�巨��������
void List_TailInsert(LinkList list,int n){
LNode *r = GetElem(list, getLength(list));
for (int i = 0; i < n; ++i) {
//�����µĽڵ㲢�Ҹ���ֵ
LNode *s = malloc(sizeof(LNode));
printf("�������%d��Ԫ��:",i + 1);
scanf("%d",&(s -> data));
s->next = NULL;
r->next = s;
r = s;
}
}
- �������IJ���
- ʱ�临�Ӷ���O(1)
//�������IJ��� ����ͷ�ڵ�
bool ListInsert(LinkList *list, int i, ElemType e) {
if (i < 1) return false;//�ж�λ�úϲ��Ϸ�
if (i == 1) {
LNode *s = malloc(sizeof(LNode));
s->data = e;
s->next = *list;
*list = s;
return true;
}
LNode *p = GetElem(*list, i - 1);
if (p == NULL) return false;
//�������µĽڵ㲢�Ҹ�ֵ
LNode *s = malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
//��ͷ�ڵ�
bool ListInsert(LinkList list, int i, ElemType e) {
if (i < 1) return false;//�ж�λ�úϲ��Ϸ�
LNode *p = GetElem(list, i - 1);
if (p == NULL) return false;
//�������µĽڵ㲢�Ҹ�ֵ
LNode *s = malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
- ��������ɾ��
- ʱ�临�Ӷ���O(1)
//��ͷ�ڵ�
bool ListDelete(LinkList list, int i, ElemType *e) {
if (i < 1) return false;
LNode *p = GetElem(list, i - 1);
if (p == NULL || p->next == NULL) return false;
LNode *q = p->next;
*e = q->data;
p->next = p->next->next;
free(q);
return true;
}
//����ͷ�ڵ�
bool ListDelete(LinkList *list, int i, ElemType *e) {
if (i < 1) return false;
if (i == 1) {
LNode *q = *list;
*e = q->data;
*list = q->next;
free(q);
return true;
}
LNode *p = GetElem(*list, i - 1);
if (p == NULL || p->next == NULL) return false;
LNode *q = p->next;
*e = q->data;
p->next = p->next->next;
free(q);
return true;
}
- ���������� ����
- ʱ�临�Ӷ�O(n)
//��ͷ�ڵ��
int getLength(LinkList list) {
int length = 0;
/**
* for (LNode *p = list->next; p != NULL;p = p -> next)
* length++; //forѭ���汾
* */
while (list->next) {
length++;
list = list->next;
}
return length;
}
//����ͷ�ڵ��
int getLength(LinkList list) {
int length = 0;
while (list) {
length++;
list = list->next;
}
return length;
}
����i��ȡԪ��
LNode *GetElem(LinkList L, int i) {
if (i < 0) return NULL;
LNode *p = L;
for (int j = 1; j <= i && p != NULL; ++j) {
p = p->next;
}
return p;
}
//����ͷ�ڵ�
LNode *GetElem(LinkList L, int i) {
if (i < 0) return NULL;
LNode *p = L;
for (int j = 2; j <= i && p != NULL; ++j) {
p = p->next;
}
return p;
}
��������ȱ��
- ֻ�ܴ�ͷ�������
- ���ܶ���ǰ���ڵ����
˫����
- ������������ָ�� һ��ָ��ǰǰ��һ��ָ����
����ʵ��
- �ṹ��
typedef struct DNode {
ElemType data;
struct DNode *prior, *next;
} DNode, *DLinklist;
- ��ʼ��
DLinklist InitDLinklist() {
DLinklist L = malloc(sizeof(DLinklist));
L->prior = NULL;
L->next = NULL;
return L;
}
- ����ڵ�
//��p�ڵ�����s�ڵ�
bool InsertNextDNode(DNode *p, DNode *s) {
if (p == NULL || s == NULL) return false;
//�������
s->next = p->next;
s->prior = p;
p->next = s;
//���һ���ڵ� ��Ҫ��ֹ��null
if (s->next != NULL)
s->next->prior = s;
}
- ɾ���ڵ�
bool DeleteNextDNode(DNode * p) {
if (p == NULL) return false;
DNode *q = p -> next;
//ɾ���ڵ�ĺ�һ��
if (q == NULL) return false; //û�к��
p -> next = q->next;
if (q->next != NULL )//�ж�q�Dz������һ���ڵ�
q->next->prior = p;
free(q);
return true;
}
ѭ������
- ����:���������һ���ڵ�ָ����ͷ�ڵ������
����ʵ��
- ��ʼ��
LinkList InitList() {
LinkList list = malloc(sizeof(LinkList));
list->next = list;
return list;
}
- �Dz�����
bool isTail(LinkList list, LNode *p) {
if (list->next == list)
return true;
else
return false;
}
- �Dz������һ���ڵ�
bool Empty(LinkList list) {
if (list->next == list)
return true;
else
return false;
}
��̬����
- ���� :�����������������Ա�����ʽ�洢�ṹ
- �ص�
- ��̬������next= =-1��Ϊ������ı�־
- ��̬�����IJ��롢ɾ�������붯̬��������ͬ,ֻ��Ҫ��ָ��,������Ҫ�ƶ�Ԫ��
- ȱ��:���������ȡ,ֻ�ܴ�ͷ��㿪ʼ�����������;�����̶����ɱ�
˳����������ıȽ�
ѭ���
- �ŵ�
- ������,���ָ������ж�������,����ʵ�֡�
- ����Ϊ��ʾ�ڵ�������ϵ�����Ӷ���Ĵ洢������
- ˳������а�Ԫ�����������ʵ��ص㡣
- ȱ��
- ��˳����������롢ɾ������ʱ,ƽ���ƶ����е�һ��Ԫ��,���n�ϴ��˳���Ч�ʵ͡�
- ��̬����,����ִ��֮ǰ������ȷ�涨�洢��ģԤ�ȷ����㹻��Ĵ洢�ռ�,���ƹ���,���ܻᵼ��˳�����������;Ԥ�ȷ����С,�ֻ�������
����
- �ŵ�
- ���롢ɾ�����㷽��
- ȱ��
- Ҫռ�ö���Ĵ洢�ռ�洢Ԫ��֮��Ĺ�ϵ,�洢�ܶȽ��͡��洢�ܶ���ָһ���ڵ�������Ԫ����ռ�Ĵ洢��Ԫ�������ڵ���ռ�Ĵ洢��Ԫ֮�ȡ�
- ��������һ������洢�ṹ,���������ȡԪ��
ջ�Ͷ���
ջ
��������
- ����:ֻ������һ�˽��в����ɾ�����������Ա� �Ƚ����
- �ص� :�Ƚ���� (LIFO)
- �ṹ
- ���Ա��������в���ɾ������һ��
- �̶���,���������в����ɾ������һ��
- ��������
- ��ͬԪ�ؽ�ջ ��ջ���еĸ���Ϊ 1 n + 1 C 2 n n \frac{1}{n+1} C_{2n}^{n} n+11?C2nn?
˳��ջ��ʵ��
- �ṹ��
typedef struct {
ElemType data[MaxSize];
int top;
} SqStack;
- ��ʼ��
void InitStack(SqStack *stack) {
stack->top = 0;
//��ʼ�������� �� -1 ���ַ�ʽ �ж�ջ�� ��ջ�� ��һ��
}
- ��ջ
bool Pop(SqStack *stack,ElemType *x){
//ջ�� ��ջʧ��
if (isEmpty(*stack)) return false;
stack->top--;
*x = stack -> data[stack -> top];
return true;
}
- ��ջ
bool Push(SqStack *stack, ElemType x) {
//ջ�ձ���
if (stack -> top == MaxSize) return false;
stack->data[stack->top] = x;
stack->top++;
return true;
}
- ��ջ��ȡֵ
bool getTop(SqStack stack,ElemType * x){
if (isEmpty(stack)) return false;
*x = stack.data[--stack.top];
return true;
}
����ջ
- �ṹ��
typedef struct {
ElemType data[MaxSize];
int top0;
int top1
}ShStack;
- ��ʼ
void InitStack(ShStack *s) {
s->top0 = -1; //Ԥ�ƻ�û�����λ��
s -> top1 = MaxSize;
}
- �Dz�����ջ
bool isFUll(ShStack s){
return s.top0 + 1 == s.top1;
}
��ջ
- ���� ����ʽ�洢�ķ�ʽʵ��ջ
- �ṹ��
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LiStack;
- �������
//��ʼ��ջ ����ͷ�ڵ�
LiStack InitStack() {
LiStack stack = NULL;
return stack;
}
bool InsertNextNode(LNode **p, ElemType e) {
//����һ���½ڵ㸳ֵ
LNode *s = malloc(sizeof(LNode));
s->data = e;
//���ڵ��ֵ����
s->next = *p;
*p = s;
return true;
}
bool getTop(LiStack stack, ElemType *x) {
if (isEmpty(stack)) return false;
*x = stack->data;
return true;
}
bool Push(LiStack *stack, ElemType x) {
if (*stack == NULL) {
LNode * s = malloc(sizeof(LNode));
s->data = x;
s->next = NULL;
*stack = s;
return true;
}
return InsertNextNode(stack, x);
}
bool Pop(LiStack *stack, ElemType *x) {
//ջ�� ��ջʧ��
if (isEmpty(*stack)) return false;
LNode *p = *stack;
*x = p->data;
if (p->next != NULL)
*stack = p->next;
free(p);
return true;
}
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LiStack;
����
- ����:ֻ���ڱ���һ�˽��в���,���ڱ�����һ��ɾ��
- �ص� �Ƚ��ȳ� FIFO
- �ṹ
- ��ͷ front ��ɾ����һ��
- ��β rear �������һ��
ѭ������
- �ṹ��
typedef struct {
ElemType data[MaxSize];
int front;
int rear;
} SqQueue;
- ��ʼ��
void InitQueue(SqQueue *queue) {
queue->rear = 0;//ָ����ӵ�Ԫ�ص�λ�ö�β
queue->front = 0;//ָ�����ӵ�λ�ö�ͷ
}
- �Ƿ�Ϊ��
//�ж϶����Ƿ�Ϊ��
bool queueEmpty(SqQueue queue) {
if (queue.rear == queue.front)
return true;
else
return false;
}
- �Ӷ����Dz�������
bool isFull(SqQueue queue) {
//queue.rear == MaxSize; ��̬����
return (queue.rear + 1) % MaxSize;//ѭ������ ������һ���ռ�Ų���
}
- ��ȡ����
int getLength(SqQueue queue) {
return (queue.rear + MaxSize - queue.front) %MaxSize;
}
- ���
bool enQueue(SqQueue *queue, ElemType x) {
if (isFull(*queue))
return false;
queue->data[queue->rear] = x;
queue->rear = (queue->rear + 1) % MaxSize;
return true;
}
- ����
//����
bool DeQueue(SqQueue *queue, ElemType *x) {
if (queueEmpty(*queue)) return false;
*x = queue->data[queue->front];
queue->front = (queue->front + 1) % MaxSize;
return true;
}
����
������������ʽʵ��
����ʵ��
typedef struct {
LNode *front, *rear;
} LinkQueue;
LinkQueue *InitQueue() {
LNode *head = malloc(sizeof(LNode));//����ͷ�ڵ�
//�����������ҽ���ͷ�Ͷ�βָ�붼ָ��ͷ���
LinkQueue *linkQueue = malloc(sizeof(LinkQueue));
//linkQueue->front = linkQueue->rear = NULL;
linkQueue->front = linkQueue->rear = head;
//front ��ͷ rear ��β
return linkQueue;
}
//��� ��β����Ԫ��
void enQueue(LinkQueue *linkQueue, ElemType x) {
// �����µ�Ԫ�ز��Ҹ�ֵ
LNode *s = malloc(sizeof(LNode));
s->data = x;
s->next = NULL;
//��rearָ��ָ�����Ԫ�� rearָ��ָ�����
linkQueue->rear->next = s;
linkQueue->rear = s;
}
//���� ɾ����ͷԪ��
bool deQueue(LinkQueue *linkQueue, ElemType *x) {
LNode *p = linkQueue->front->next;
if (p == NULL) return false;//����Ϊ�� ����ʧ��
*x = p->data;
// ��ͷָ��ִ��ͷָ��ָ���ϴһ���ڵ�
linkQueue->front = p->next;
free(p);
return true;
}
bool isEmpty(LinkQueue linkQueue) {
//����ͷ�ڵ� linkQueue.front == NULL
return linkQueue.front->next == NULL;
}
˫�˶���
- ����:�������˲�������ɾ�������Ա�
- ��������˫�˶��� :ֻ����һ�˲��� ����ɾ���ĵ����Ա�
- �������˫�˶���:ֻ�������˲���һ��ɾ�������Ա�
���к� Ӧ��
ջ��Ӧ��
-
���ŵ�ƥ��
bool bracketCheck(char str[], int length) { LiStack *stack = InitStack(); for (int i = 0; i < length; i++) { if (str[i] == '(' || str[i] == "{" || str[i] == "["){ Push(stack,str[i]); }else { if (isEmpty(stack)) return false; char topElem; Pop(stack,&topElem); if (str[i] == ")" && topElem != '(') return false; if (str[i] == "]" && topElem != ']') return false; if (str[i] == "}" && topElem != '{') return false; } } return isEmpty(stack); } -
������ʽ �沨������ʽ
- ����:�������������������
- �ֶ�ת������
- ȷ����������ȼ�
- Ȼ������������ȼ��ƶ������ֺ���
- �����ֺ����ֺ���IJ���������һ������ �ص�2 �ظ�
- ��ջʵ�ֺ��ļ����ʵ��
- ������ ��������ѹ��ջ
- ���������� �ʹ�ջ���������� �����ѹ��
- ���ջ����ʣ��ľ��ǽ��
- ����ת���ɺ� ����
- �����������ͼ��������ʽ
- ���������ž�ֱ����ջ( ����������)�ͽ����еIJ��������������ʽ
- ��������� ջ������������ڻ�������ڵ�������͵���ջ���������ʽ ��������ѹ��ջ�� ջ��ֱ��
- ��ת��������
- ������ջ һ���Ƿ����ֵ�ջ һ�����������ջ
- ɨ�赽���־�ѹ�� ��ջ
- ÿ���Ӳ�������ջ�е���һ���ʹ�����ջ�е������������� ��ѹ������ջ
-
ǰ����ʽ ��������ʽ
- ����:���������������ǰ��
-
�ݹ�
���е�Ӧ��
- ��ӡ�� FCFAS �����ȷ���
- ���IJ���
- ͼ�Ĺ�ȱ���
����,�ַ��� �����
����
- ���� ����n����ͬ���͵�����Ԫ�ع��ɵ���������
- �ص�:����һ��������,��ά����ά�粻���Ըı�
- ��ַ����
- һά�����ַ���� a[i] = LOC + i * sizeof(ElemType)
- ������ b[i] [j] = Loc + (i * N + J) * sizeof(ElemType)
- ������ b[i] [j] = = LOC + ( j*M+ i ) * sizeof(ElemType)
- �������
- �Գƾ���
- ���� �� n ����������һ��Ԫ�� ai,j���� ai,j = aj,i ��þ���Ϊ�Գƾ���
- ѹ���洢���� ֻ�洢���Խ���+��������
- ����Ĵ�С n ( 1 + n ) 2 \frac{n(1+n)}{2} 2n(1+n)?
- �����ȵ�ԭ�� [1+2+������+(i-1)] + j = i ( i ? 1 ) 2 + J \frac{i(i-1)}{2} + J 2i(i?1)?+J ��Ԫ�� ai,j = aj,i
- �����ȵ�ԭ�� [n + n -1 + �� n - (j -1) + 1] + i - j = ( j ? 1 ) ( 2 n ? j + 2 ) 2 \frac{(j-1)(2n-j + 2)}{2} 2(j?1)(2n?j+2)? + i - j
- ���ԽǾ���
- ���� ��|i -j| > 1 aij=0
- �������� Ԫ�ظ���3n -2 aij��3(i-1) -1 + j-i + 2 ��Ԫ��
- ϡ�����
- ����Ԫ��ԶԶ���ھ���Ԫ�صĸ���
- ѹ���洢����: ˳��洢������Ԫ�� <��,��,ֵ>
- ѹ���洢���Զ�: ��ʽ�洢����ʮ��������
- �Գƾ���
�ַ���
? ����:��,���ַ���(String)������������ַ���ɵ��������С�һ���Ϊ S = ��a1a2������������an�� (n ��0) n = 0 �մ�
? ���Ĵ洢�ṹ
//��̬����
typedef struct {
char ch[MaxSize];
int length;
} SString;
//��̬����
typedef struct {
char *ch;
int length;
} HString;
//ͨ������
typedef struct StringNode {
char ch; //char ch[MaxSize]
struct StringNode *next;
} StringNode, *String;
��������
- ���Ӵ�
//���Ӵ�
bool SubString(HString *sub, HString s, int pos, int len) {
/**
*@param sub �Ӵ�
* @param s ����
* @param pos ��ʼ��λ��
* @param len ��ȡ�ij���
* */
//�ִ��ķ�ΧԽ��
if (pos + len - 1 > s.length) return false;
int j = 0;
for (int i = pos; i < pos + len; ++i) {
// i - pos + 1
sub->ch[j++] = s.ch[i];
}
sub->length = len;
return true;
}
- �Ƚ�
int StrCompare(HString s1, HString s2) {
// ���㿪ʼ����С��ʵ�ʳ���
for (int i = 0; i < s1.length && i < s2.length; ++i) {
if (s2.ch[i] != s1.ch[i])
return s1.ch[i] - s2.ch[i];
}
//������е��ַ�������Ⱦͱȳ���
return s1.length - s2.length;
}
- Kmp�㷨��
int Index_KMP(SString s, SString t, int next[]) {
int i = 0, j = 0;
while (i < s.length && j < t.length) {
if (j == -1|| s.ch[i] == t.ch[i]){
//���������ȾͿ�ʼ������
i++;
j++;
}else {
j = next[j];
}
}
//��j����ȵ�ʱ�� j�ǵ���j+1
if (j == t.length) return i - t.length;
else return 0;
}
//��nextvalue
//�ӵڶ���Ԫ�ؿ�ʼ �����ǰ���ַ����ڻص�λ�õ��ַ� ��ônextvalue[j] = nextvalue(next[j])��ֵ
- �������Ӵ�
int Index(SString s, SString t) {
/**
* @param s ����
* @param t �Ӵ�
* */
int i = 0, j = 0; //i������ָ�� j�ִ���ָ��
while (i < s.length && j < t.length) {
if (s.ch[i] == t.ch[i]) {
//���������ȾͿ�ʼ������
i++;
j++;
} else {
//��Ϊi��j������ͬ�� i - j ֱ�ӻص�û��ƥ���ǰһ��λ�� +2 ֱ�ӵ���һ��ƥ���λ��
i = i - j + 2;
j = 0;
}
}
//j�ߵ������һ��
if (j == t.length) return i - t.length;
else return 0;
}
�����
- ���Ա����ƹ� �ݹ�Ķ��� �������Ԫ�ؿ������ӱ� �ӱ��ֿ������ӱ�
- GetHead ȡ��ͷ ȡ����һ��Ԫ�� �����ǵ�ԭ��Ҳ������һ���ӱ�
- GetTail ȡ��β ȡ������ͷԪ�ص�֮���������Ԫ�ع��ɵı�
�����Խṹ
���ṹ
��
���� :����n >= ���ڵ������� ÿ�������ĸ��ڵ����ҽ���һ��ֱ��ǰ��,���ǿ��������ɸ�ֱ�Ӻ��
��������
- �ڵ� ��������Ԫ�ص�ֵ��ָ�������ڵ�ķ�ָ֧��
- Ҷ�ӽڵ� :�ն˽ڵ� ��Ϊ��Ľڵ�
- �ڵ�Ķ�:�ڵ�������Ŀ���
- ���Ķ�:�����ڵ�Ķȵ����ֵ
- ɭ�� ɭ����m >=0 �û����ཻ�����ļ���
���õ�����
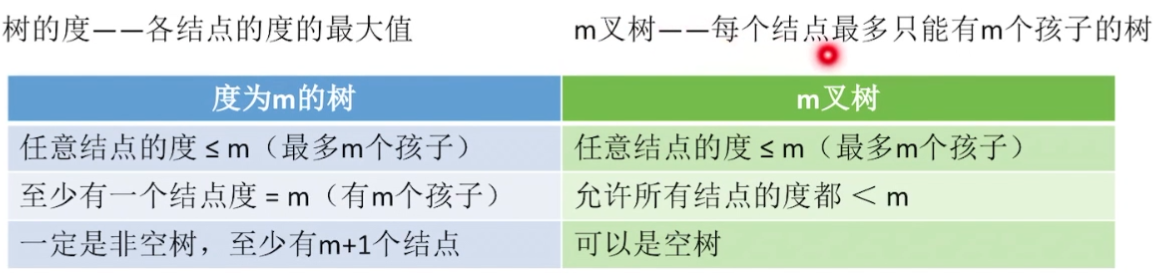
- �ڵ��� = �ܶ��� + 1
- ��Ϊm������i������� m i ? 1 m^{i-1} mi?1 ���ڵ�
- �߶�Ϊh�ĵ�m���� �õȱ�������� a1 - an + 1 / 1 - q
- �߶�Ϊh��m����������h���ڵ�
- �߶�Ϊh ��Ϊm����������h +m - 1���ڵ�
- ��С�߶� �ڵ�������ǰһ���ܽڵ� С��h����ܽڵ�
�洢��ʽ
-
˫�ױ�ʾ��
typedef struct { ElemType data; int parent; }PTNode; typedef struct { PTNode nodes[MaxSize]; int n }PTree; -
���ӱ�ʾ��
//��������� �����е�ֵ��ʾ���еĽڵ� �����е�next��ʾ��Ӧ�ĺ��ӵĽڵ� typedef struct TreeNode { ElemType data; struct TreeNode *next; }TreeNode; typedef struct{ ElemType data; TreeNode * firstChild; }ParentNode; typedef struct { ParentNode nodes[MaxSize]; int n,r; }; -
�����ֵܱ�ʾ��
typedef struct CSNode{ ElemType data; struct CSNode *firstChild,*nextSibling; }CSNode,*CSTree;
��������
-
���� �ڴ���nge��ȨҶ�ڵ�Ķ������� ���д�Ȩ·������(wpl)��С�Ķ�������Ϊ��������
-
����
- ÿ�δ�ѡȡ�ڵ�Ȩֵ��С�ĺϳ�һ������
- �����Ľڵ�Ȩֵ�������½ڵ��֮��
- �ظ� ֻʣһ��������
-
����������Ҷ�ӽڵ���n ����ÿ�������ϲ���Ҫһ���µĽڵ� ���Թ������� ��Ҫ�ϲ�n - 1 �� �ܹ���2n - 1 ���ڵ�
-
�������ı�����������һ�ķ�ʽ
-
�ؼ�����
//����������� //��һ���ǹ���Ĵ��� �ڶ����ҳ�������С����û�и��ڵ�� for (int i = 0; i < n - 1; ++i) { int w1 = MaxWeigh, w2 = MaxWeigh, index1, index2; for (int j = 0; j < n + i; ++j) { //�����һ��С ���� 14 6 98 99 if (HuffmanNode[j].parent == -1 && HuffmanNode[j].weight < w1) { //��ֹǰ����ֵĵڶ�Сֵ index2 = index1; w2 = w1; //�ѵڶ�Сֵ��ֵ index1 = j; w1 = HuffmanNode[j].weight; } else if (HuffmanNode[j].parent == -1 && HuffmanNode[j].weight < w2) { index2 = j; w2 = HuffmanNode[j].weight; } } //�ϲ����Ŷ����� HuffmanNode[index1].parent = n + i; HuffmanNode[index2].parent = n + i; HuffmanNode[n + i].weight = w1 + w2; HuffmanNode[n + i].lchild = index1; HuffmanNode[n+i].rchild = index2; }
���鼯
����:���鼯��һ�����͵����ݽṹ,���ڴ���һЩ���ཻ���ϵĺϲ�����ѯ���⡣
-
����ʵ��
//��ʼ�� void init(int S[]) { for (int i = 0; i < MaxSize; ++i) { S[i] = 0; } } //���Ҽ��� �Ӹýڵ���� int Find(int s[], int x) { int root = x; // �ҵ����ڵ� while (s[root] >= 0) root = s[root]; // ѹ��·�� while (x != root) { // ��¼����ǰ��˫�ڵ� int t = s[x]; s[x] = root; x = t; } return root; } /** * �ϲ����� * */ void Union(int s[], int root1, int root2) { if (root2 > root1) { s[root1] += s[root2]; s[root2] = root1; } else { s[root2] += s[root1]; s[root1] = root2; } } -
�Ż�ԭ��
- find ���Ż� ���������е�·�������нڵ�ҵ����ڵ�
- union �����Ż� ��С�� �͵������ڵ���
������
���� :��������n>= 0 ���ڵ�������: ÿ���ڵ����ֻ������������ �����������ܵߵ� (��������������)
��������
- �������� һ�Ÿ߶�Ϊh �Һ��� 2 h ? 1 2^{h} - 1 2h?1 ���ڵ�Ķ����� ֻ�����һ���� Ҷ�ӽڵ� �����ڶ�Ϊ1�Ľڵ�
- ��ȫ������ ���ҽ��� ��ÿһ���ڵ㶼��߶�h����ȫ������ ���еı��Ϊ 1 ~ n�Ľڵ�C��Ӧ ��Ϊ��ȫ������ ֻ��������������Ҷ�ӽڵ� ���ֻ��һ����Ϊ1�Ľڵ�
���õ�����
- Ҷ�ӽڵ� �ȷ�֧�ڵ��һ�� n0 = n2 + 1 n = n0 + n1 + n2 n = n1 + 2n2 + 1
- ��ȫ������ ��2k ���ڵ� ��n1 = 1, n0 = k ,n2 = k -1 �������� ���������ڵ�
����ʵ��
typedef char ElemType;
#define MaxSize 100
typedef struct TreeNode{
ElemType value;
bool isEmpty;
}TreeNode;
TreeNode t[MaxSize];
//�������
void InOrder(BiTree tree) {
if (tree == NULL) return;
InOrder(tree->lchild);
visit(tree);
printf("����������ɵ�˳��:");
InOrder(tree->rchild);
}
//��������
void postOrder(BiTree tree) {
if (tree == NULL) return;
postOrder(tree->lchild);
postOrder(tree->rchild);
visit(tree);
}
//ǰ�����
void preOrder(BiTree tree) {
if (tree == NULL) return;
visit(tree);
preOrder(tree->lchild);
preOrder(tree->rchild);
}
/*
*��һ��ջ���洢�ڵ�
* pָ��ָ����һ����Ҫ���ʵĽڵ�
* ����ýڵ�Ϊ�վ�ֱ�ӵ���ջȡ���������ڵ�
* ����������ջʵ����Ҫ���ñ�־λ�ǵڼ�����ջ
* */
void InOrderTraverse(BiTree tree) {
LiStack stack = NULL;
BiTNode *p = tree;
while (true) {
if (p != NULL) {
//��ȥջ֮����������������� ������û�������ó�������
visit(p);
push(&stack, p);
p = p->lchild;
} else {
if (stack == NULL) break;
BiTNode *temp = pop(&stack);
p = temp->rchild;
}
}
}
//����һ����
void createTree(BiTree *tree) {
//��������һ����
char ch;
//���������ݹ����ڵ�
printf("������ڵ��ֵ:");
scanf("%c", &ch);
getchar();
if (ch == '#') {
*tree = NULL;
return;
}
BiTNode *node = malloc(sizeof(BiTNode));
node->data = ch;
node->lchild = node->rchild = NULL;
//�õ�ǰ�ڵ�ĵ�ַ���ڹ����Ľڵ�
*tree = node;
BiTree t = *tree;
createTree(&(t->lchild));
createTree(&(t->rchild));
}
//����
void LeaveOrder(BiTree *tree) {
LinkQueue queue = malloc(sizeof(Queue));
queue -> front = NULL;
queue ->rear = NULL;
if (tree != NULL) enQueue(queue, tree);
while (!queueEmpty(queue)) {
BiTNode *node = Dequeue(queue);
if (node->lchild)
enQueue(queue, node->lchild);
if (node->rchild)
enQueue(queue, node->rchild);
}
}
//�������
int Depths(BiTree tree) {
if (tree == NULL) return 0;
int m = Depths(tree->lchild);//01
int n = Depths(tree->rchild);//01
if (m > n) return m + 1; //��1 �Ǽ��ϸ���һ���ڵ�
else return n + 1;//1
}
ͼ�ṹ
-
ͼ�Ķ���ͻ�������
- ͼ�Ķ��� :
- ͼ���ɶ��������ǿռ����Ͷ���֮��ߵļ������,��ʾΪG(V,E),����G��ʾһ��ͼ,V��ͼG�ж���ļ���,E��ͼG�бߵļ��ϡ�
- ͼG�ɶ��㼯�ͱ�E��� ��ΪG=(V,E)
- ��ͼ
- �������ظ��ı�
- �����ڶ��㵽�����ı�
- ����ͼ
- ͼG��ij�������֮��ı�������һ��
- �����Լ����Լ�����
- ����Ķ�
- ����ͼ :����V�Ķ���ָ�����ڸö���ıߵ�����
- ����ͼ : ��� + ����
- ·�� :�Ӷ���A -> B֮���һ��·����ָ���������
- ��·: ��һ����������һ��������ͬ��·����Ϊ��·��
- ��·��:��·��������,���㲻�ظ�����
- ��·:����һ����������һ��������,���ඥ�㲻�ظ����ֵĻ�·
- ·���ij���:·���ϱߵ���Ŀ
getchar();
if (ch == ��#��) {
*tree = NULL;
return;
}
BiTNode *node = malloc(sizeof(BiTNode));
node->data = ch;
node->lchild = node->rchild = NULL;
//�õ�ǰ�ڵ�ĵ�ַ���ڹ����Ľڵ�
*tree = node;BiTree t = *tree;
createTree(&(t->lchild));
createTree(&(t->rchild));
}
//����
void LeaveOrder(BiTree *tree) {
LinkQueue queue = malloc(sizeof(Queue));
queue -> front = NULL;
queue ->rear = NULL;if (tree != NULL) enQueue(queue, tree);
while (!queueEmpty(queue)) {
BiTNode *node = Dequeue(queue);
if (node->lchild)
enQueue(queue, node->lchild);
if (node->rchild)
enQueue(queue, node->rchild);
}
}
//�������
int Depths(BiTree tree) {
if (tree == NULL) return 0;
int m = Depths(tree->lchild);//01
int n = Depths(tree->rchild);//01
if (m > n) return m + 1; //��1 �Ǽ��ϸ���һ���ڵ�
else return n + 1;//1
} - ͼ�Ķ��� :
ͼ�ṹ
-
ͼ�Ķ���ͻ�������
- ͼ�Ķ��� :
- ͼ���ɶ��������ǿռ����Ͷ���֮��ߵļ������,��ʾΪG(V,E),����G��ʾһ��ͼ,V��ͼG�ж���ļ���,E��ͼG�бߵļ��ϡ�
- ͼG�ɶ��㼯�ͱ�E��� ��ΪG=(V,E)
- ��ͼ
- �������ظ��ı�
- �����ڶ��㵽�����ı�
- ����ͼ
- ͼG��ij�������֮��ı�������һ��
- �����Լ����Լ�����
- ����Ķ�
- ����ͼ :����V�Ķ���ָ�����ڸö���ıߵ�����
- ����ͼ : ��� + ����
- ·�� :�Ӷ���A -> B֮���һ��·����ָ���������
- ��·: ��һ����������һ��������ͬ��·����Ϊ��·��
- ��·��:��·��������,���㲻�ظ�����
- ��·:����һ����������һ��������,���ඥ�㲻�ظ����ֵĻ�·
- ·���ij���:·���ϱߵ���Ŀ
- ͼ�Ķ��� :