һ�� ����
1.����,���鶼�ǶԶ�����ݽ��д洢�����Ľṹ,���java����
˵��:��ʱ�Ĵ洢,ֻҪָ�����ڴ����Ĵ洢,���漰���־û��Ĵ洢(.txtjpg,.avi,����)
2.�����ڴ洢������ݷ�����ص�
һ����ʼ���Ժ�,�䳤�Ⱦ�ȷ����
����һ�������,��Ԫ�ص�����Ҳ��ȷ���ˡ�����Ҳ��ֻ�ܲ���ָ�����͵�������
����:String[]arr,int[]arr1,Object[]arrw
3.�����ڴ洢������鷽���ȱ��
һ����ʼ���Ժ�,�䳤�ȾͲ�����
�������ṩ�ķ����dz�����,��������,ɾ��,�������ݵȲ���,�dz�����,ͬʱЧ�ʲ���
��ȡ������ʵ��Ԫ�صĸ���������,����û���ֳɵ����Ի�����
����洢���ݵ��ص�:����,���ظ�����������,�����ظ�������,��������
4.���Ͽ����ϵ



ArrayList��Դ�����

����:���鿪����ʹ�ô��εĹ�����:ArrayList list=new ArrayList(int capacity)
Jdk8��ArrayList�ı仯
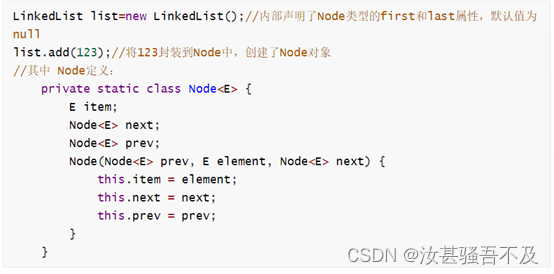
LinkedList��Դ�����
Veator��Դ�����:jdk7��jdk8ͨ��Vector()��������������ʱ,�ײ㶼�����˳���Ϊ10������
�����ݷ���,Ĭ������Ϊԭ�������鳤�ȵ�2��
ArrayList,LinkedList,Vector���ߵ���ͬ?
ͬ:�������ʵ����List�ӿ�,�洢���ݵ��ص���ͬ:�洢�����,���ظ�������
��ͬ:�ײ�Դ��ʵ�ַ�ʽ��ͬ
ArrayList��LinkedList����ͬ
���ߵ��̶߳�����ȫ,����̰߳�ȫ��Vector,ִ��Ч�ʸߡ�����,ArrayListʱʵ���˻��ڶ�̬��������ݽṹ,LinkedList�������������ݽṹ,�����������get��set,ArrayList��������LinkedList�Ƚ�ռ����,��ΪLinledListҪ�ƶ�ָ�롣����������ɾ������add(��ָ����)��remove,LinkedList�Ƚ�ռ����,��ΪArrayListҪ�ƶ����ݡ�
ArrayList��Vector������
Vector��ArrayList��������ȫ��ͬ��,Ψһ����������Vector��ͬ����(synchronized),����ǿͬ����,��Ϊ�����ͱ�ArrayListҪ��,����Ҫ�������������,�������java����Աʹ��ArrayList������Vector,��Ϊͬ����ȫ�����ɳ���Ա�Լ������ơ�Vectorÿ�������������С��2���ռ�,��ArrayList��1.5����
List�еķ���
Viod add(int index,Object ele):��undexλ�ò���eleԪ��
Boolean addAll(int index, Collection eles):��indexλ�ÿ�ʼ��eles�е����б�Ԫ�����ӽ���
IntindexOf(Object obj):����obj�ڼ������״γ��ֵ�λ��
intLastIndexOf(Object obj):����obj�ڼ�����ĩ�γ��ֵ�λ��
Object remlove(int index):�Ƴ�ָ��indexλ��Ԫ��,�����ش�Ԫ��
Object set(int index,Object ele):����ָ��indexλ�õ�Ԫ��ele
=List subList(int fromindex,int tonIndex):���ش�fromIndex��toIndex()λ�õ��Ӽ���=
�᳣ܽ�÷���:
��:add(Object obj)
ɾ:remove(int index)/remove(Object obj)
��:set(int index,Object ele)
��:get(int index)
��:add(int index,Object ele)
����:size()
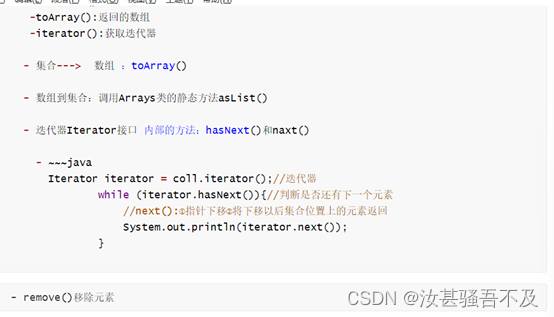
����:��Iterator��������ʽ����ǿforѭ������ͨforѭ��
���� Set�ӿڿ��
��ϵ
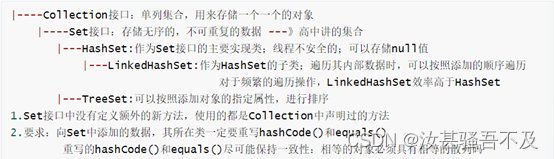
Set:�洢�����,�����ظ�������
��HashSetΪ��˵��
������:����������ԡ��洢�������ڵײ������в��ǰ�������������˳������,���Ǹ������ݵĹ�ϣֵ������
�����ظ���:��֤���ӵ�Ԫ�ذ���equals()�ж�ʱ,���ܷ���ture����:��ͬ��Ԫ��ֻ������һ��
����Ԫ�ع���:��HashSetΪ��
������HashSet������Ԫ��a,���ȵ���Ԫ��a�������hashCode()����,����Ԫ��a�Ĺ�ϣֵ,�˹�ϣֵ����ͨ��ij���㷨�����HashSet�ײ������еĴ��λ��(��Ϊ:����λ��),�ж������λ�����Ƿ��Ѿ���Ԫ��:
�����λ����û������Ԫ��,��Ԫ��a���ӳɹ��C>��1
�����λ����������Ԫ��b(������������ʽ���ڵĶ��Ԫ��),��Ƚ�Ԫ��a��Ԫ��b��hashֵ:
���hashֵ����ͬ,��Ԫ��a���ӳɹ���>���2
���hashֵ��ͬ,����Ҫ����Ԫ���������equals()����
equals()����true,Ԫ��a����ʧ��
equals()����false,��Ԫ��a���ӳɹ�
LinkedHashSet��ʹ��
LinkedHashSet��ΪHashSet������,���������ݵ�ͬʱ,ÿ�����ݻ�ά������������,��¼������ǰһ�����ݺͺ�һ������
�ŵ�:����Ƶ���ı�������,LinkedHashSetЧ�ʸ���HashSet
TreeSet��ʹ��
��TreeSet�����ӵ�����,Ҫ��ʱ��ͬ�Ķ���
��������ʽ:��Ȼ����(ʵ��Comparable�ӿ�)���ƶ�����(Comparator)
��Ȼ������,�Ƚ����������Ƿ���ͬ�ı�ΪcompareTo()����0,������equals()
����������,�Ƚ����������Ƿ���ͬ�ı�Ϊcompaew()����0,������equals()
����Map�ӿ�

2.Map�ṹ������
=Map�е�kye:�����,�����ظ���,ʹ��Set�洢���е�key��>key���ڵ���Ҫ��дequals()��hashCode(��HashMapΪ��)=
=Map�е�value:�����,���ظ���,ʹ��Collection�洢���е�value��>value������Ҫ��дequals()=
һ����ֵ��:key-value������һ��Entery����
Map�е�entry:�����,�����ظ���,ʹ��Set�洢���е�entry
3.HashMap�ĵײ�ʵ��ԭ��

4.LinkedHashMap�ĵײ�ԭ��(�˽�)

5.Map�ij��÷���
����,ɾ��,�IJ���
Object put(Object key,Object value):��ָ��key-value���ӵ�(����)��ǰmap������
void putAll(Map m):��m�е�����key-value�Դ�ŵ���ǰmap��
Object remove(Object key):�Ƴ�ָ��key-value��,���ҷ���value
void clear():��յ�ǰmap�е���������
��ѯ����
Object get(Object key):��ȡָ��key��Ӧ��value
boolean containsKey(Object key):�Ƿ����ָ����key
boolean containsKey(Object value):�Ƿ����ָ����value
int size():����map��key-value�Եĸ���
boolean isEmpty():�жϵ�ǰmap�Ͳ�������obj�Ƿ���ȡ�
Ԫ��ͼ��������
Set keyset():��������key���ɵ�Set����

Collection values():��������value���ɵ�Collection����
Set entrySet():��������key-vlue�Թ��ɵ�Set����

�᳣ܽ�÷���
����:put(Object key,Object value)
ɾ��:remove(Object key)
��:put(Object key,Object value)
��ѯ:get(Object key)
����:size()
����:keyset()/values()/entrySet()
6.TreeMap������key-value,Ҫ��key��������ͬһ���ഴ���Ķ���
��ΪҪ����key��������:��Ȼ����,��������
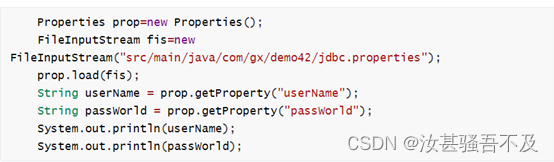
7.Properties:���������������ļ�:key��value����String����
�ġ�Collections���Ϲ�����
���÷���
reverse(List):��תList��Ԫ�ص�˳��
shuffle(List):��List����Ԫ�ؽ����������
sort(List):����Ԫ�ص���Ȼ˳���ָ��List����Ԫ�ذ���������
sort(List,Comparator):����ָ����Comparator������˳���List����Ԫ�ؽ�������
swap(List,int,int):��ָ��List������i��Ԫ�غ�j��Ԫ�ؽ��н���
Object max(Collection):����Ԫ�ص���Ȼ����,���ظ������������Ԫ��
Object max(Collection,Comparator):����Comparatorָ��˳��,���ظ������������Ԫ��
Object min(Collectton)
Object min(Collecton,Comparator)
int faequency(Collection,Object)����ָ��������ָ��Ԫ�صij��ִ���
void copy(List dest,List src):��src�е����ݸ��Ƶ�dest��
boolean replacecAll(List list,Object oldVal,Object newVal):ʹ������ֵ�滻List��������о�ֵ
ͬ������
Collection�����ṩ�˶��synchronizedXxx()����,�÷�����ʹ��ָ����
�ϰ�װ�߳�ͬ���ļ���,�Ӷ����Խ�����̲߳������ʼ���ʱ���̰߳�ȫ