问题:为什么散列表和链表会经常放到一块使用?
1. LRU缓存淘汰算法
算法过程:
- 维护一个按照访问时间从大到小的链表;
- 链表容量有限,超过容量,直接淘汰表头的数据;
- 插入数据时,先查找,如没有,直接放到链表尾部,如有,移动到链表尾部。
上述过程的时间复杂很高,是O(n)。结合散列表和链表,降低时间复杂度到O(1)。
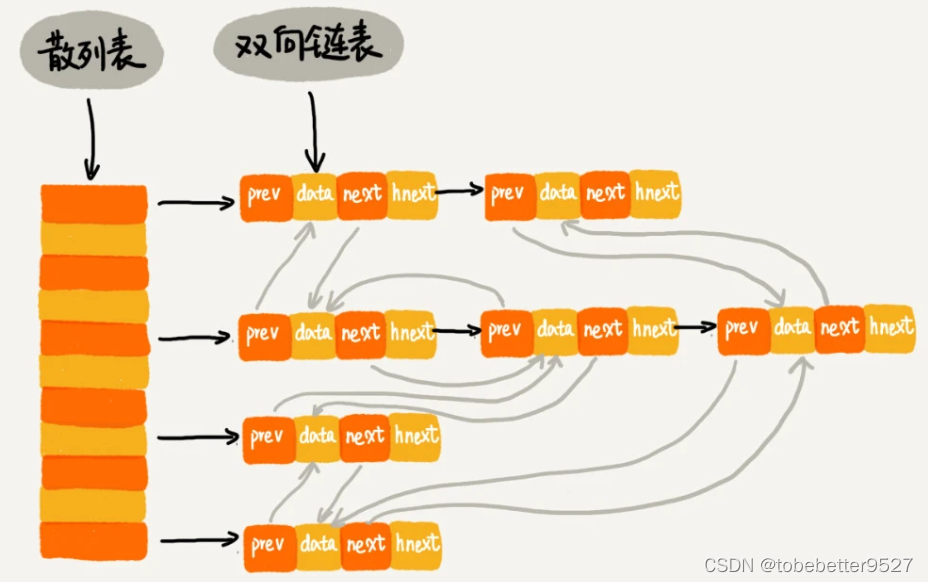
- 查找数据,通过散列表,时间复杂度接近O(1),查到数据移动到链表尾部;
- 删除数据,通过散列表,时间复杂度接近O(1),找到之后,删除;
- 插入数据,如果已经在表中,直接放到尾部;如果没在链表,如果容量满了,删除头节点,数据放到尾部,如果没满,直接放到尾部。
2. Redis有序集合
在有序集合中,每个成员对象有两个重要的属性,key(键值)和score(分值)。我们不仅会通过score来查找数据,还会通过key来查找数据。
如果按照分值构建跳表结构,那么按照键值查找删除插入就变得很慢;反之亦然。
解决方法:按照分值和键值构建两个跳表结构。
3. Java LinkedHashMap
以下代码的打印顺序:3,1,5,2.
HashMap<Integer, Integer> m = new LinkedHashMap<>();
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
以下代码的打印顺序:1,2,3,5
// 10是初始大小,0.75是装载因子,true是表示按照访问时间排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
注:LinkedHashMap的Entry结构:继承HashMap的Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 前后继指针
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
4.解答开篇&内容小结
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。
因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。