目录
四、封装unordered_set和unordered_map
一、哈希桶节点的修改
????????用哈希桶封装实现unordered_set和unordered_map,就要考虑到他们传给哈系统的数据元素不同,unordered_set传给哈希桶的是k,unordered_map传给哈希桶的是pair,那么哈希桶面对这两种不同的数据,如何做到统一处理呢?
?????????面对unordered_set传给哈希桶的是k,unordered_map传给哈希桶的是pair,就把K和V统一封装成T,用T代替pair<K,V>:
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};二、哈希表
类模板需要修改,模板里面必须包含K,因为要用K来计算数据映射的位置。由于哈希桶的节点类型换成了T ,用T来替代V。KeyOfT仿函数确定上传的是unordered_set还是unordered_map。
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<T> Node;
//哈希桶迭代器
template<class K,class T,class KeyOfT,class HashFunc>
friend struct __HTIterator;
public:
typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;
private:
vector<Node*> _table;
size_t _n = 0;
};1.构造
使用默认构造函数就可以了,vector自定义类型会调用自己的默认构造函数,size_t作为内置类型编译器不处理:
HashTable() = default; // 显示指定生成默认构造2.拷贝构造
_n 直接赋值就可以了。_table的拷贝就需要遍历ht的_table了,并且把ht的_table的每个结点都头插到_table表中:
//拷贝构造
HashTable(const HashTable& ht)
{
_n = ht._n;//存储有效数据的个数一致
_table.resize(ht._table.size());//开同样大小的空间
//遍历ht,将ht的_table的每个结点都拷贝到_table中
for (size_t i = 0; i < ht._table.size(); i++)
{
Node* cur = ht._table[i];
while (cur)
{
Node* copy = new Node(cur->_data);
//头插到新表
copy->_next = _table[i];//copy的下一个桶为_table[i]
_table[i] = copy;//把copy作为当前位置的第一个桶
cur = cur->_next;//cur往下移
}
}
}3.赋值运算符重载
只需要交换_table和_n即可:
//赋值运算符重载
HashTable& operator=(HashTable ht)
{
_table.swap(ht._table);
swap(_n, ht._n);
return *this;
}4.析构
只需要将_table 的每个结点删除后置空就可以了:
//析构
~HashTable()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}5.迭代器
迭代器的参数包含节点位置和哈希表地址,在下一节迭代器中会讲,为什么都要使用指针:
//迭代器开始
iterator begin()
{
size_t i = 0;
while (i < _table.size())
{
if (_table[i])
{
return iterator(_table[i], this);
}
++i;
}
return end();
}
//迭代器结束
iterator end()
{
return iterator(nullptr, this);
}6.查找
?这时候就要用到仿函数KeyOfT了,仿函数KeyOfT的对象kot对于unordered_set会取k,对于unordered_map会取作为pair的kv的first作为k和key进行比较:
//查找
iterator Find(const K& key)
{
//哈希表为空
if (_table.size() == 0)
{
return end();
}
KeyOfT kot;
HashFunc hf;
size_t index = hf(key) % _table.size();//计算在哈希表中的位置
//在哈希表当前位置的所有桶中找key
Node* cur = _table[index];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur,this);
}
else
{
cur = cur->_next;
}
}
return end();
}7.插入
①需要先判断data在不在哈希桶中,在就直接返回查找到的位置
②如果不在,需要判断哈希桶需不需要增容,如果不需要增容就计算映射位置头插到哈希表中
③需要增容就要取旧表中的节点一一头插到新表中,并交换旧表和新表
//插入
pair<iterator,bool> Insert(const T& data)
{
KeyOfT kot;
auto ret = Find(kot(data));
if (ret != end())
{
return make_pair(ret,false);
}
//仿函数
HashFunc hf;
//负载因子为1时,进行增容
if (_n == _table.size())
{
vector<Node*> newTable;
newTable.resize(GetNextPrime(_table.size()));
//取旧表中的结点,重新计算映射到新表中的位置,挂到新表中
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i])
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;//保存下一个结点
size_t index = hf(kot(cur->_data)) % newTable.size();//计算结映射到新表中的位置
//头插
cur->_next = newTable[index];//=nullptr,将cur->_next置空
newTable[index] = cur;//将结点插入到新表
cur = next;//哈希桶往下挪一个
}
_table[i] = nullptr;//当前哈希桶的第一个位置置空
}
}
_table.swap(newTable);
}
//不需要增容时,头插
size_t index = hf(kot(data)) % _table.size();
Node* newNode = new Node(data);
newNode->_next = _table[index];//让新节点newNode的next指向第一个桶
_table[index] = newNode;//让新节点newNode做第一个桶
++_n;//更新哈希表大小
return make_pair(iterator(newNode, this), true);
}8.删除
①删除节点之前要先保留该节点的前一个?节点,否则删除改节点后,让前一个节点要指向下一个,但是又找不到前一个节点了。
②当找到key的映射位置后,要判断找到的节点是不是当前位置的第一个桶,如果是,就让当前位置指向下一个节点;如果不是就直接让前一个节点指向后一个节点。
//删除
bool Erase(const K& key)
{
size_t index = hf(key) % _table.size();
Node* prev = nullptr;
Node* cur = _table[index];
while (cur)
{
if (kot(cur->data) == key)//cur这个桶就是key
{
if (_table[index] == cur)//cur是第一个桶
{
_table[index] = cur->_next;
}
else//cur不是第一个桶
{
prev->_next = cur->_next;
}
--_n;//更新表大小
delete cur;//删除节点
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}?三、迭代器
????????迭代器需要前置声明HashTable,因为HashTable类中使用了__HTIterator迭代器,且__HTIterator中使用了HashTable类的指针,为什么要用指针呢?
????????因为C++编译器自上而下编译源文件的时候,对每一个数据的定义,需要知道定义的数据类型的大小。在预先声明语句class HashTable;之后,编译器已经知道HashTable是一个类,但是其中的数据却是未知的,因此HashTable类型的大小也不知道,这样就造成了编译失败;将__HTIterator中的_node更改为HashTable指针类型之后,由于在特定的平台上,指针所占的空间是一定的(在Win32平台上是4字节,在64位平台上是8字节),这样可以通过编译。
? ? ? ?
迭代器的参数包含哈希节点和哈希表:
// 前置声明
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;
// 迭代器
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
struct __HTIterator
{
typedef HashNode<T> Node;//哈希节点
typedef __HTIterator<K, T, KeyOfT, HashFunc> Self;//实现++、--
typedef HashTable<K, T, KeyOfT, HashFunc> HT;//哈希表
Node* _node;
HT* _pht;
__HTIterator(Node* node, HT* pht)
:_node(node)//哈希节点
, _pht(pht)//哈希表
{}
};1.operator++( )
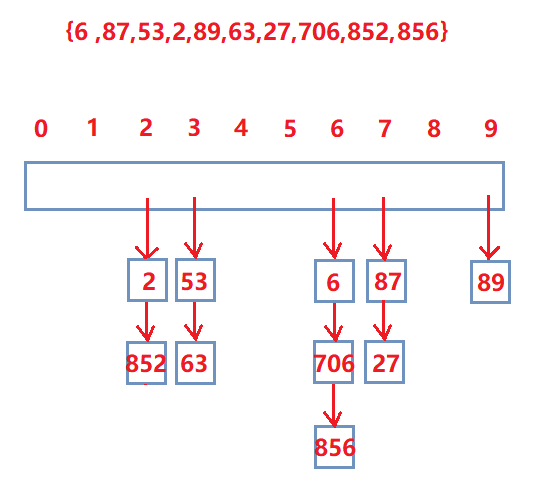
如下图,operator++ 分两种情况:
①当前节点不是哈希表当前位置的最后一个节点,如2、53,返回当前节点的next节点
②当前节点是哈希表当前位置的最后一个节点,如852、63,需要返回下一个非空位置的第一个节点
?
Self& operator++()
{
//不是当前位置最后一个节点
if (_node->_next)
{
_node = _node->_next;
}
else//是当前位置最后一个节点
{
KeyOfT kot;
HashFunc hf;
size_t index = hf(kot(_node->_data)) % _pht->_table.size();
//找哈希表中下一个不为空的位置
++index;
while (index < _pht->_table.size())
{
if (_pht->_table[index])//不为空
{
_node = _pht->_table[index];
return *this;
}
else//为空
{
++index;
}
}
_node = nullptr;//后面的所有位置都为空,_node置空,返回当前位置即可
}
return *this;
}2.operator*( )
取_data即可:?
T& operator*()
{
return _node->_data;
}3.operator->( )
?取_data的地址即可:
T* operator->()
{
return &_node->_data;
}4.operator !=( )
将s的_node和_node进行比较:
bool operator != (const Self& s) const
{
return _node != s._node;
}5.operator ==( )
将s的_node和_node进行比较:
bool operator == (const Self& s) const
{
return _node == s._node;
}四、封装unordered_set和unordered_map
?1.封装unordered_set
unordered_set的成员就是哈希表,不过要传模板参数,SetKeyOfT就是传给哈希表的仿函数
#pragma once
#include "HashTable.h"
namespace delia
{
template<class K>
class unordered_set
{
private:
OpenHash::HashTable<K, K, SetKeyOfT> _ht ;
};
}(1)仿函数SetKeyOfT
?set直接取k:
//set就取k
struct SetKeyOfT
{
const K& operator()(const K& k)
{
return k;
}
};(2)迭代器
? ? ? ? 对于unordered_set的迭代器,如果不加typename,类模板里面找迭代器的类型找不到,因为OpenHash::HashTable<K, K, SetKeyOfT>::iterator没有实例化,因此编译器并不知道它是类型还是成员函数或成员变量,编译无法通过。
? ? ? ? 用typename表明OpenHash::HashTable<K, K, SetKeyOfT>::iterator是一个类型,不是成员函数或成员变量,不需要等到实例化时才能确定。
????????unordered_set的迭代器都调用哈希表的迭代器进行操作:
public:
typedef typename OpenHash::HashTable<K, K, SetKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> Insert(const K& k)
{
return _ht.Insert(k);
}(3)实例
向unordered_set中插入一些数据,并打印:
void test_unordered_set1()
{
unordered_set<int> us;
us.Insert(100);
us.Insert(5);
us.Insert(6);
us.Insert(32);
us.Insert(8);
us.Insert(14);
us.Insert(65);
us.Insert(27);
us.Insert(39);
unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}2.封装unordered_map
unordered_map的成员就是哈希表,不过要传模板参数,MapKeyOfT就是传给哈希表的仿函数?:
#pragma once
#include "HashTable.h"
namespace delia
{
template<class K,class V>
class unordered_map
{
private:
OpenHash::HashTable<K, pair<K, V>, MapKeyOfT> _ht;
};(1)仿函数MapKeyOfT
map就取kv的first:?
//map就取kv的first
struct MapKeyOfT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};(2)迭代器
??同unordered_set的迭代器定义一样,前面要加上typename,unordered_map的迭代器都调用哈希表的迭代器进行操作:
public:
typedef typename OpenHash::HashTable<K, pair<K,V>, MapKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> Insert(const pair<K,V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->iterator;
}(3)实例
void test_unordered_map1()
{
unordered_map<string,string> um;
um.Insert(make_pair("spring", "春天"));
um.Insert(make_pair("summer", "夏天"));
um.Insert(make_pair("autumn", "秋天"));
um.Insert(make_pair("winter", "冬天"));
unordered_map<string,string>::iterator it = um.begin();
while (it != um.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
}五、完整代码段
HashTable.h
#pragma once
#include<vector>
#include<iostream>
using namespace std;
namespace OpenHash
{
//哈希仿函数
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
//string仿函数
template<>
struct Hash<string>//模板特化
{
size_t operator()(const string& s)
{
size_t value = 0;
for (auto e : s)
{
value += e;
value *= 131;
}
return value;
}
};
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
//前置声明HashTable,因为HashTable类中使用了__HTIterator,且__HTIterator中使用了HashTable类的指针,为什么要用指针
//C++编译器自上而下编译源文件的时候,对每一个数据的定义,总是需要知道定义的数据类型的大小。在预先声明语句class HashTable;之后,编译器已经知道HashTable是一个类,但是其中的数据却是未知的,因此HashTable类型的大小也不知道,这样就造成了编译失败;将__HTIterator中的_node更改为HashTable指针类型之后,由于在特定的平台上,指针所占的空间是一定的(在Win32平台上是4字节,在64位平台上是8字节),这样可以通过编译
// 前置声明
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;
// 迭代器
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
struct __HTIterator
{
typedef HashNode<T> Node;//哈希节点
typedef __HTIterator<K, T, KeyOfT, HashFunc> Self;//实现++、--
typedef HashTable<K, T, KeyOfT, HashFunc> HT;//哈希表
Node* _node;
HT* _pht;
__HTIterator(Node* node, HT* pht)
:_node(node)//哈希节点
, _pht(pht)//哈希表
{}
Self& operator++()
{
//不是当前位置最后一个节点
if (_node->_next)
{
_node = _node->_next;
}
else//是当前位置最后一个节点
{
KeyOfT kot;
HashFunc hf;
size_t index = hf(kot(_node->_data)) % _pht->_table.size();
//找哈希表中下一个不为空的位置
++index;
while (index < _pht->_table.size())
{
if (_pht->_table[index])//不为空
{
_node = _pht->_table[index];
return *this;
}
else//为空
{
++index;
}
}
_node = nullptr;//后面的所有位置都为空,_node置空,返回当前位置即可
}
return *this;
}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator != (const Self& s) const
{
return _node != s._node;
}
bool operator == (const Self& s) const
{
return _node == s._node;
}
};
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<T> Node;
template<class K,class T,class KeyOfT,class HashFunc>
friend struct __HTIterator;
public:
typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;
//构造函数,default指定生成默认构造函数
HashTable() = default;
//拷贝构造
HashTable(const HashTable& ht)
{
_n = ht._n;//存储有效数据的个数一致
_table.resize(ht._table.size());//开同样大小的空间
//遍历ht,将ht的每个结点都拷贝到_table中
for (size_t i = 0; i < ht._table.size(); i++)
{
Node* cur = ht._table[i];
while (cur)
{
Node* copy = new Node(cur->_data);
//头插到新表
copy->_next = _table[i];//copy的下一个桶为_table[i]
_table[i] = copy;//把copy作为当前位置的第一个桶
cur = cur->_next;//cur往下移
}
}
}
//赋值运算符重载
HashTable& operator=(HashTable ht)
{
_table.swap(ht._table);
swap(_n, ht._n);
return *this;
}
//析构
~HashTable()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
iterator begin()
{
size_t i = 0;
while (i < _table.size())
{
if (_table[i])
{
return iterator(_table[i], this);
}
++i;
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
static const size_t primeList[PRIMECOUNT] =
{
53ul,97ul,193ul,389ul,769ul,
1543ul,3079ul,6151ul,12289ul,24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < PRIMECOUNT; i++)
{
if (primeList[i] > prime)
{
return primeList[i];
}
}
return primeList[i];
}
//插入
pair<iterator,bool> Insert(const T& data)
{
KeyOfT kot;
auto ret = Find(kot(data));
if (ret != end())
{
return make_pair(ret,false);
}
//仿函数
HashFunc hf;
//负载因子为1时,进行增容
if (_n == _table.size())
{
vector<Node*> newTable;
newTable.resize(GetNextPrime(_table.size()));
//取旧表中的结点,重新计算映射到新表中的位置,挂到新表中
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i])
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;//保存下一个结点
size_t index = hf(kot(cur->_data)) % newTable.size();//计算结映射到新表中的位置
//头插
cur->_next = newTable[index];//=nullptr,将cur->_next置空
newTable[index] = cur;//将结点插入到新表
cur = next;//哈希桶往下挪一个
}
_table[i] = nullptr;//当前哈希桶的第一个位置置空
}
}
_table.swap(newTable);
}
//不需要增容时,头插
size_t index = hf(kot(data)) % _table.size();
Node* newNode = new Node(data);
newNode->_next = _table[index];//让新节点newNode的next指向第一个桶
_table[index] = newNode;//让新节点newNode做第一个桶
++_n;//更新哈希表大小
return make_pair(iterator(newNode, this), true);
}
//查找
iterator Find(const K& key)
{
//哈希表为空
if (_table.size() == 0)
{
return end();
}
KeyOfT kot;
HashFunc hf;
size_t index = hf(key) % _table.size();//计算在哈希表中的位置
//在哈希表当前位置的所有桶中找key
Node* cur = _table[index];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur,this);
}
else
{
cur = cur->_next;
}
}
return end();
}
//删除
bool Erase(const K& key)
{
size_t index = hf(key) % _table.size();
Node* prev = nullptr;
Node* cur = _table[index];
while (cur)
{
if (kot(cur->data) == key)//cur这个桶就是key
{
if (_table[index] == cur)//cur是第一个桶
{
_table[index] = cur->_next;
}
else//cur不是第一个桶
{
prev->_next = cur->_next;
}
--_n;//更新表大小
delete cur;//删除节点
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _table;
size_t _n = 0;
};
}?UnorderedSet.h
#pragma once
#include "HashTable.h"
namespace delia
{
template<class K>
class unordered_set
{
//set就取k
struct SetKeyOfT
{
const K& operator()(const K& k)
{
return k;
}
};
public:
//如果不加typename,类模板里面找迭代器的类型找不到,因为OpenHash::HashTable<K, K, SetKeyOfT>::iterator没有实例化,因此编译器并不知道它是类型还是成员函数或成员变量,编译无法通过
//用typename表明OpenHash::HashTable<K, K, SetKeyOfT>::iterator是一个类型,不是成员函数或成员变量,不需要等到实例化时才能确定
typedef typename OpenHash::HashTable<K, K, SetKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> Insert(const K& k)
{
return _ht.Insert(k);
}
private:
OpenHash::HashTable<K, K, SetKeyOfT> _ht ;
};
void test_unordered_set1()
{
unordered_set<int> us;
us.Insert(100);
us.Insert(5);
us.Insert(6);
us.Insert(32);
us.Insert(8);
us.Insert(14);
us.Insert(65);
us.Insert(27);
us.Insert(39);
unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
}UnorderedMap.h
#pragma once
#include "HashTable.h"
namespace delia
{
template<class K,class V>
class unordered_map
{
//map就取kv的first
struct MapKeyOfT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
public:
typedef typename OpenHash::HashTable<K, pair<K,V>, MapKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> Insert(const pair<K,V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->iterator;
}
private:
OpenHash::HashTable<K, pair<K, V>, MapKeyOfT> _ht;
};
void test_unordered_map1()
{
unordered_map<string,string> um;
um.Insert(make_pair("spring", "春天"));
um.Insert(make_pair("summer", "夏天"));
um.Insert(make_pair("autumn", "秋天"));
um.Insert(make_pair("winter", "冬天"));
unordered_map<string,string>::iterator it = um.begin();
while (it != um.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
}
}Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "HashTable.h"
#include "UnorderedSet.h"
#include "UnorderedMap.h"
int main()
{
delia::test_unordered_set1();
delia::test_unordered_map1();
return 0;
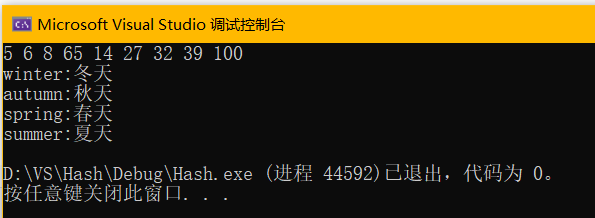
}运行结果:
unordered_set:
由于哈希表的初始大小为primeList中的第一个元素53,因此插入时:
100%53=47,
5%53=5,
6%53=6,
8%53=8,
65%53=12,
14%53=14,
27%53=27,
32%53=32,
39%53=39
且都没有发生冲突,因此排列顺序为5,6,8,65,14,27,32,39,100。
?
unordered_map:
字符串的Hash算法让每个字符*131再求和,再对53取模:
ASCII对照表如下:
| 97 | a |
| 98 | b |
| 99 | c |
| 100 | d |
| 101 | e |
| 102 | f |
| 103 | g |
| 104 | h |
| 105 | i |
| 106 | j |
| 107 | k |
| 108 | l |
| 109 | m |
| 110 | n |
| 111 | o |
| 112 | p |
| 113 | q |
| 114 | r |
| 115 | s |
| 116 | t |
| 117 | u |
| 118 | v |
| 119 | w |
| 120 | x |
| 121 | y |
| 122 | z |
spring:(((((((115*131)+112)*131)+114)*131+105)*131+110)*131+103)*131=359074819,中间发生了溢出,所以得到结果359074819,再用359074819对53取模,sunmmer,autumn和winter也都这么计算
?