���������㷨
����Ŀ¼
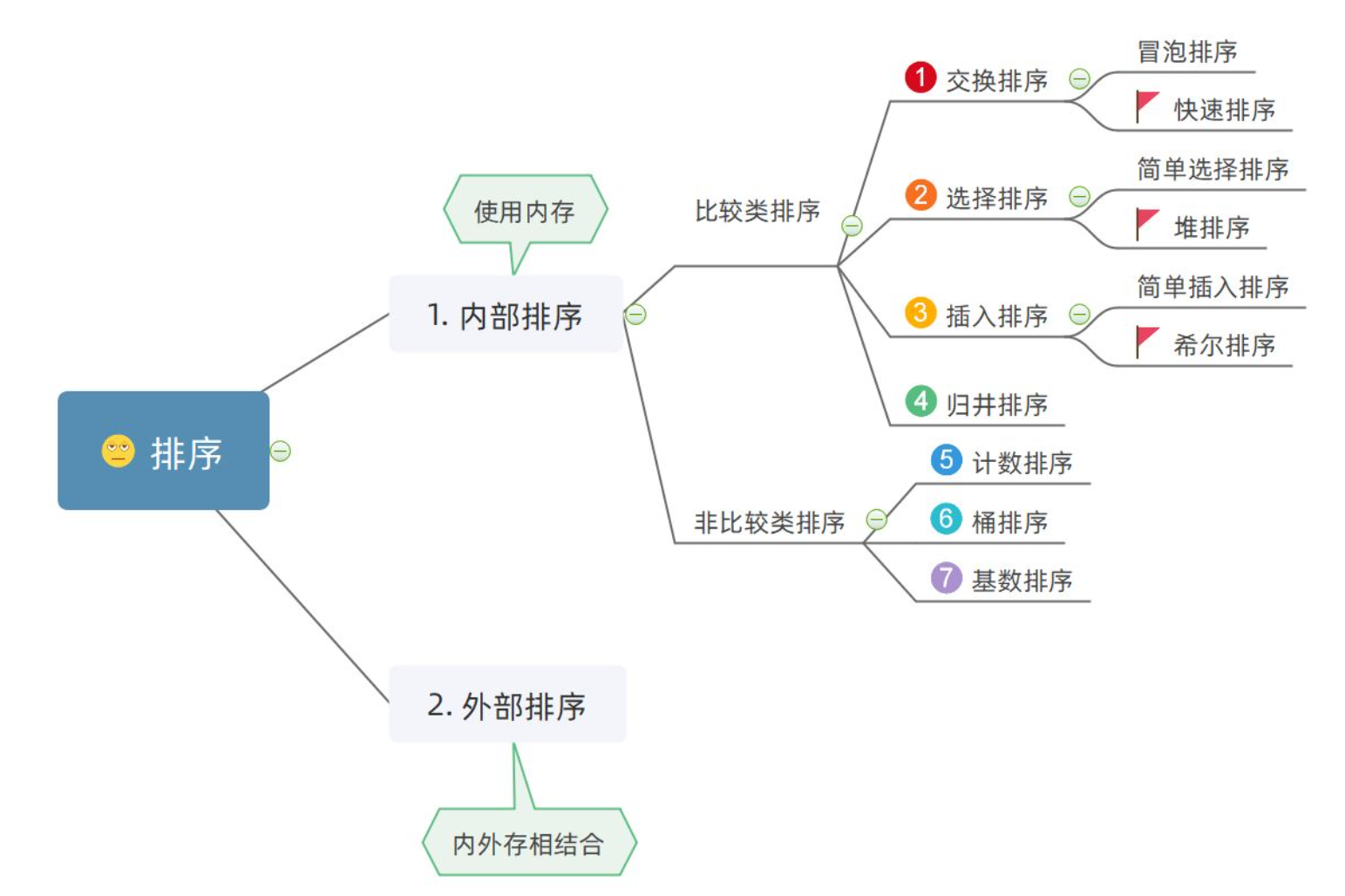
1.����Ļ�������
1.1 ����ĸ���
- ����:����ʹһ����¼,�������е�ij����ijЩ�ؼ��ֵĴ�С,������ݼ������������IJ���
- �ȶ���:�ٶ��ڴ�����ļ�¼��,���ڶ��������ͬ�ؼ��ֵļ�¼,����������,��Щ��¼����Դ��ֲ���,����ԭ������,r[i]=r[j],��r[i]��r[j]֮ǰ,��������������,r[i]����r[j]֮ǰ,������������㷨���ȶ���,�����Ϊ���ȶ���
- �ڲ�����:����Ԫ��ȫ�����ڴ��е�����
- �ⲿ����:����Ԫ��̫���ͬʱ�����ڴ���,����������̵�Ҫ�����������֮���ƶ����ݵ�����
1.2 ���������㷨
�������ӿ�:
// ����ʵ�ֵĽӿ� // �������� void InsertSort(int* a, int n); // ϣ������ void ShellSort(int* a, int n); // ѡ������ void SelectSort(int* a, int n); // ������ void AdjustDwon(int* a, int n, int root); void HeapSort(int* a, int n); // ð������ void BubbleSort(int* a, int n) // ��������ݹ�ʵ�� // ��������hoare�汾 int PartSort1(int* a, int left, int right); // ���������ڿӷ� int PartSort2(int* a, int left, int right); // ��������ǰ��ָ�뷨 int PartSort3(int* a, int left, int right); void QuickSort(int* a, int left, int right); // �������� �ǵݹ�ʵ�� void QuickSortNonR(int* a, int left, int right) // �鲢����ݹ�ʵ�� void MergeSort(int* a, int n) // �鲢����ǵݹ�ʵ�� void MergeSortNonR(int* a, int n) // �������� void CountSort(int* a, int n)
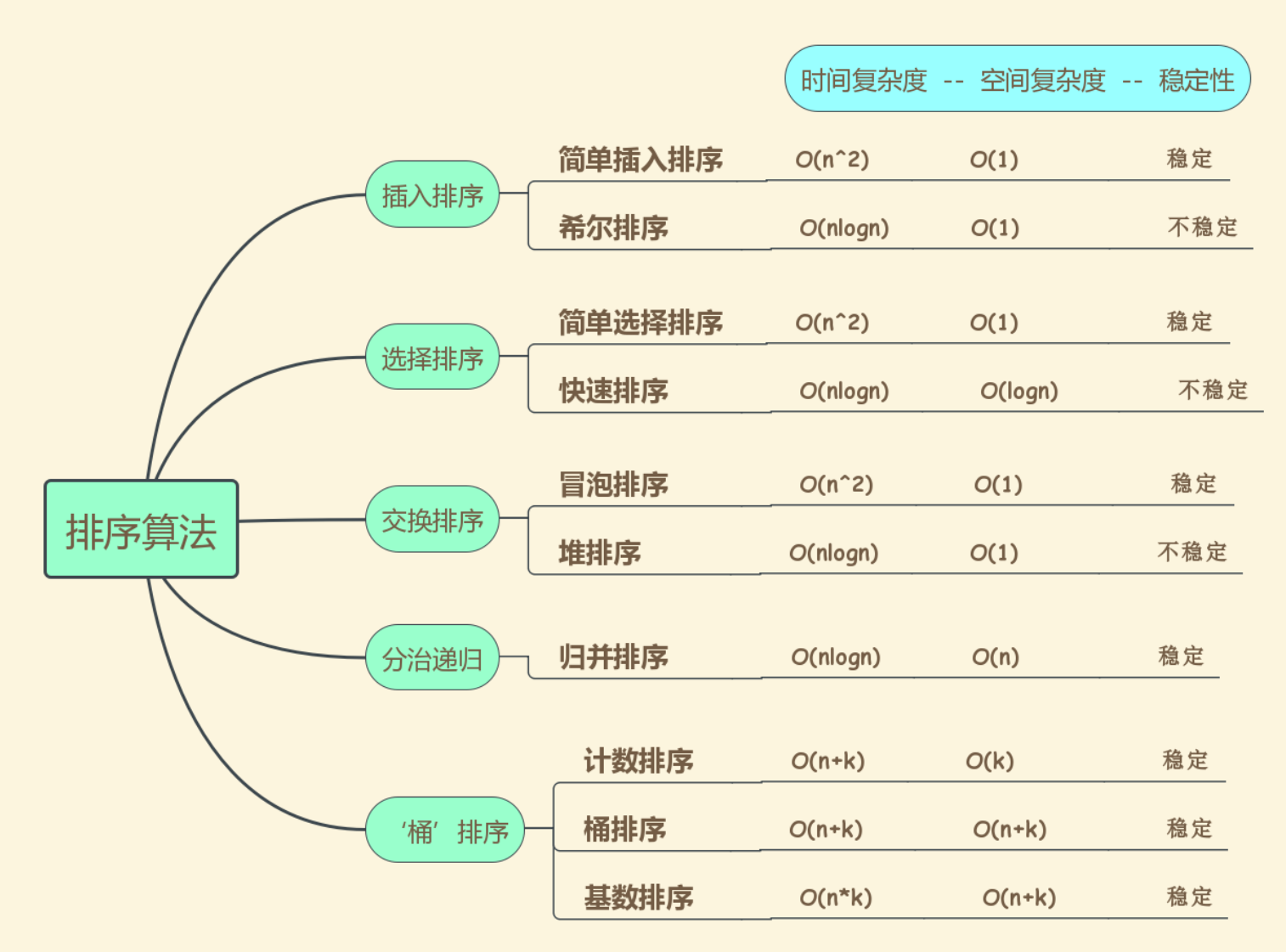
2.�����ԭ������
2.1 ��������ֱ�Ӳ�������ϣ������
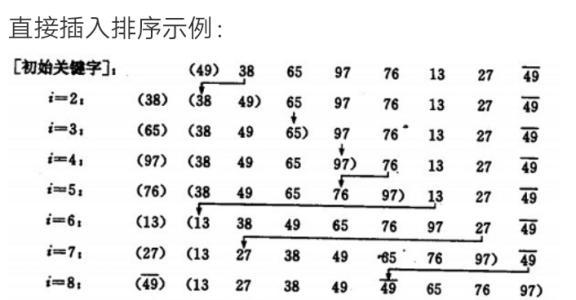
ֱ�Ӳ���������һ�ּIJ�������
����˼��:�Ѵ�����ļ�¼����ؼ���ֵ�Ĵ�С������뵽һ���Ѿ��ź��������������,ֱ�����еļ�¼������Ϊֹ,�õ�һ���µ���������
����:
- ֱ�Ӳ�������
- ϣ������
ֱ�Ӳ�����������:
- �������i(i>=1)��Ԫ��ʱ,ǰ���array[0],array[1],��,array[i-1]�Ѿ��ź���,��ʱ��array[i]����������array[i-1],array[i-2],����������˳����бȽ�,�ҵ�����λ�ü���array[i]����,ԭ��λ���ϵ�Ԫ��˳�����
ֱ�Ӳ��������ܽ�:
- Ԫ�ؼ���Խ�ӽ�����,ֱ�Ӳ��������㷨��ʱ��Ч��Խ��
- ʱ�临�Ӷ�:O(N^2)
- �ռ临�Ӷ�:O(1),����һ���ȶ��������㷨
- �ȶ���:�ȶ�
ϣ������(��С��������)����:
- ϣ�������ֳ���С������
- ϣ�����Ļ���˼����:��ѡ��һ������,�Ѵ������ļ������м�¼�ֳɸ���,���о���Ϊ�ļ�¼����ͬһ����,����ÿһ���ڵļ�¼��������Ȼ��ȡ�ظ��������������Ĺ�����������=1ʱ,���м�¼��ͳһ�����ź���
ϣ�������ܽ�:
- ϣ�������Ƕ�ֱ�Ӳ���������Ż�
- ��gap > 1ʱ����Ԥ����,Ŀ������������ӽ�������gap == 1ʱ,�����Ѿ��ӽ��������,�����ͻ�ܿ졣�����������,���Դﵽ�Ż���Ч��������ʵ�ֺ���Խ������ܲ��ԵĶԱ�
- ϣ�������ʱ�临�ӶȲ��ü���,��Ϊgap��ȡֵ�����ܶ�,���º���ȥ����,����ں�Щ���и�����ϣ�������ʱ�临�Ӷȶ����̶�
- ϣ������ʱ�临�Ӷ�:��ʱ��ΪO(N^1.25)��O(1.6 * N^1.25)
- �ȶ���:���ȶ�
ϣ������ʱ�临�Ӷȵļ���:

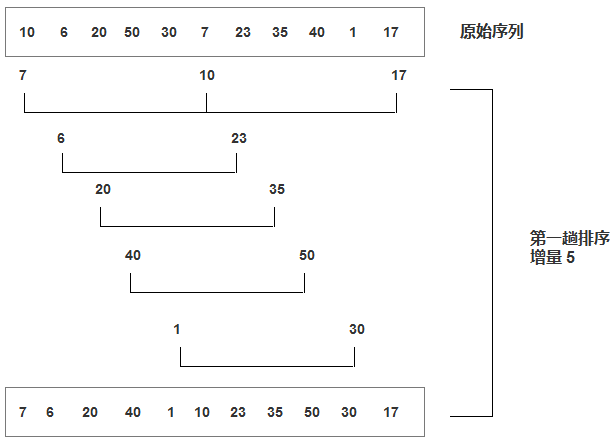



2.2 ѡ������ֱ��ѡ����������
����˼·:ÿһ�δӴ����������Ԫ����ѡ����С(�����)��һ��Ԫ��,��������е���ʼλ��,ֱ��ȫ�������������Ԫ������
����:
- ֱ��ѡ������
- ������
ֱ��ѡ����������:
- ��Ԫ�ؼ���array[i]�Carray[n-1]��ѡ��ؼ������(С)������Ԫ��������������Ԫ���е����һ��(��һ��)Ԫ��,����������Ԫ���е����һ��(��һ��)Ԫ�ؽ�����ʣ���array[i]�Carray[n-2](array[i+1]�Carray[n-1])������,�ظ���������,ֱ������ʣ��1��Ԫ��
ֱ��ѡ�������ܽ�:
- ֱ��ѡ���������ܺ�����,����Ч�ʲ���
- ʱ�临�Ӷ�:O(N^2)
- �ռ临�Ӷ�:O(N)
- �ȶ���:���ȶ�
����������:
- ������(Heapsort)��ָ���öѻ���(��)�������ݽṹ����Ƶ�һ�������㷨,����ѡ�������һ�֡�����ͨ����������ѡ�����ݡ���Ҫע�����������Ҫ�����,�Ž���С��
�������ܽ�:
- ������ʹ�ö���ѡ��,Ч�ʸ�
- ʱ�临�Ӷ�:O(N*logN)
- �ռ临�Ӷ�:O(1)
- �ȶ���:���ȶ�

2.3 ������������������
����˼��:��ν����,���Ǹ���������������¼��ֵ�ıȽϽ�����Ի���������¼�������е�λ��,����������ص���:����ֵ�ϴ�ļ�¼�����е�β���ƶ�,��ֵ��С�ļ�¼�����е�ǰ���ƶ�
����:
- ����
- ��������
����:
ð�������ܽ�:
- ð��������һ�ַdz��������������
- ʱ�临�Ӷ�:O(N^2)
- �ռ临�Ӷ�:O(1)
- �ȶ���:�ȶ�
��������:
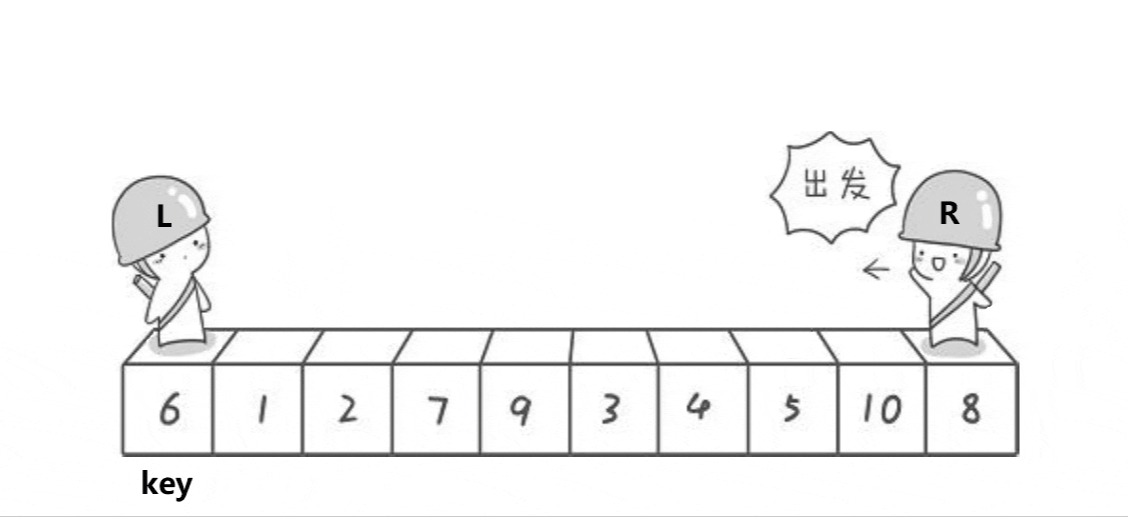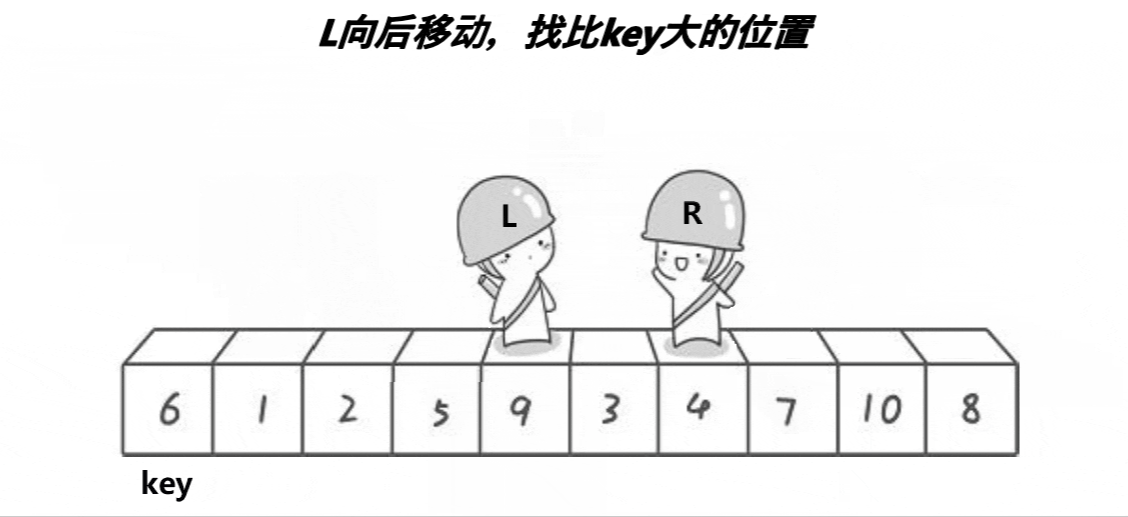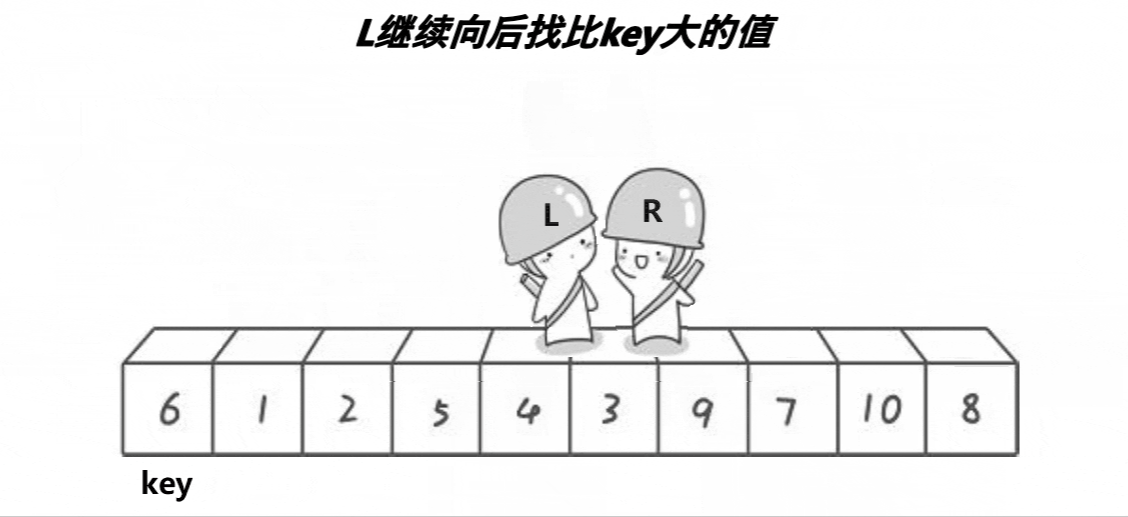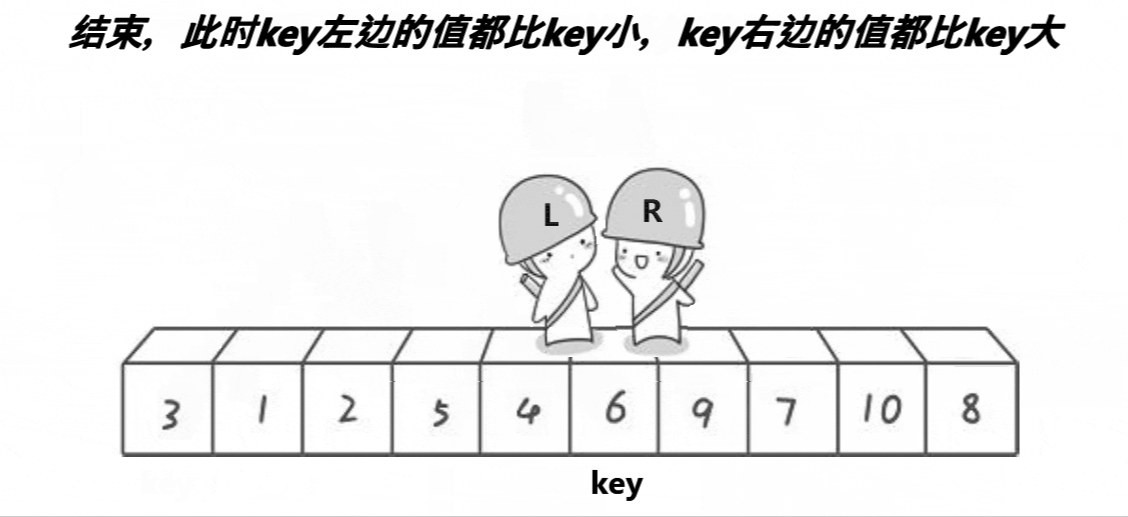
- ����������Hoare��1962�������һ�ֶ������ṹ�Ľ�������,�����˼��Ϊ:��ȡ������Ԫ�������е�ijԪ����Ϊ��ֵ,���ո������뽫�����Ϸָ����������,��������������Ԫ�ؾ�С�ڻ�ֵ,��������������Ԫ�ؾ����ڻ�ֵ,Ȼ���������������ظ��ù���,ֱ������Ԫ�ض���������Ӧλ����Ϊֹ
hoare��:
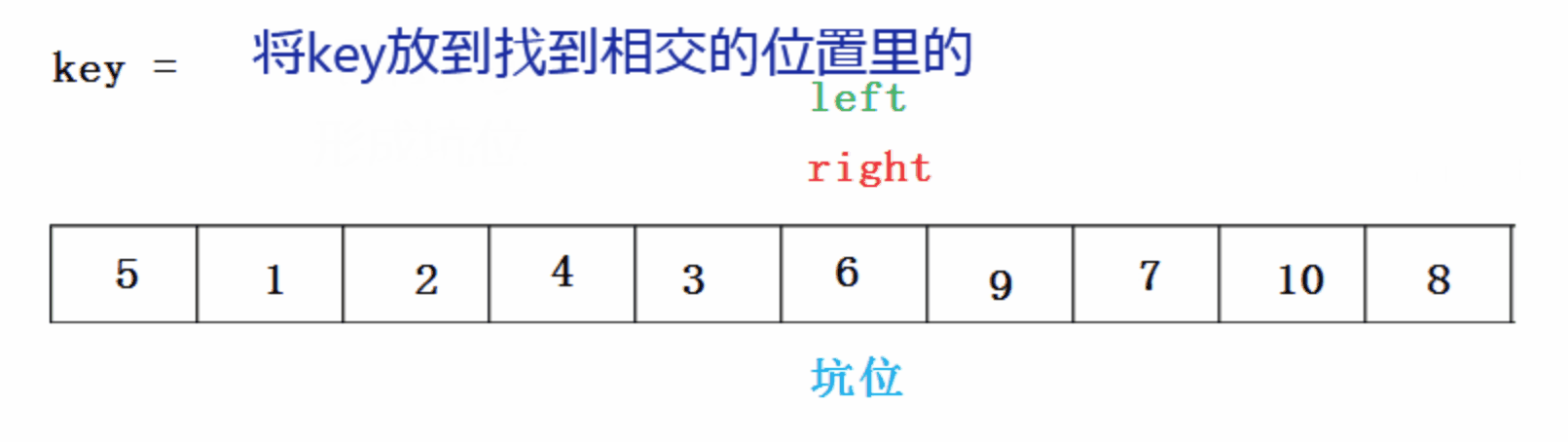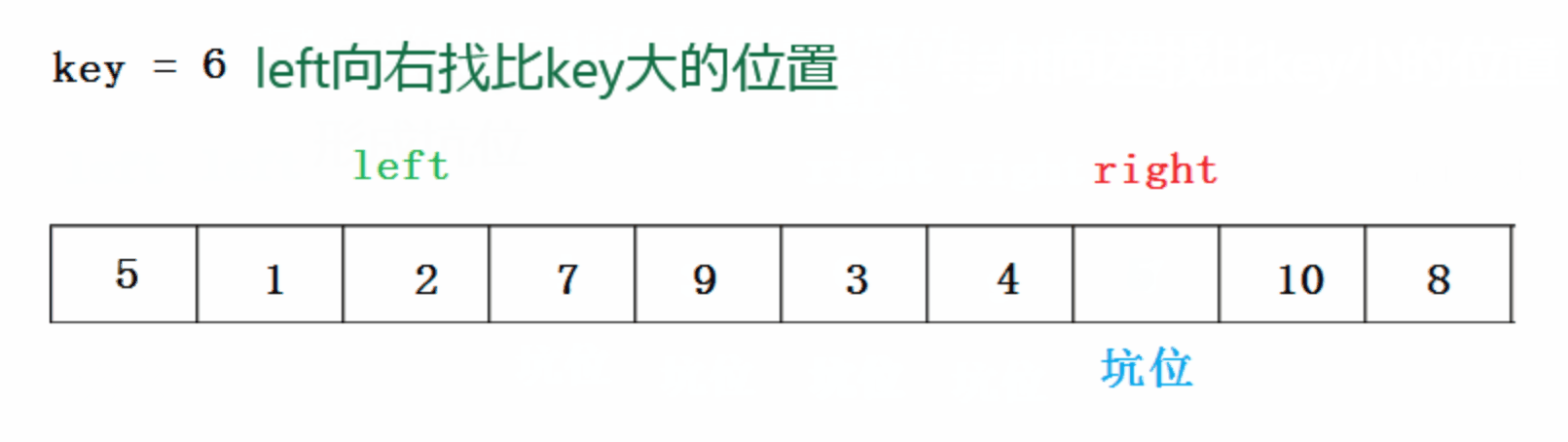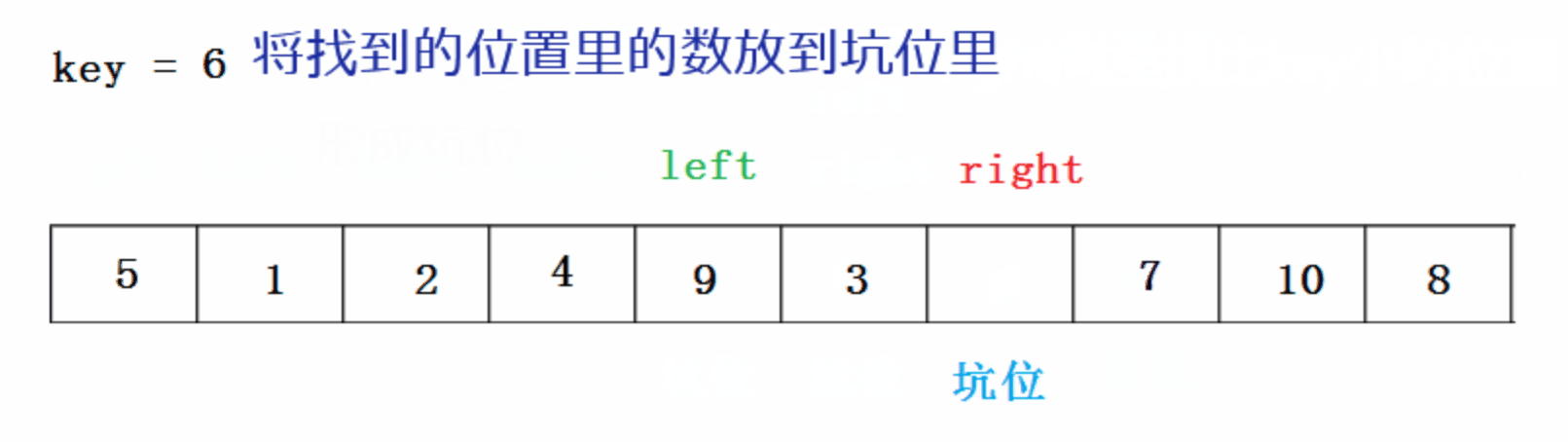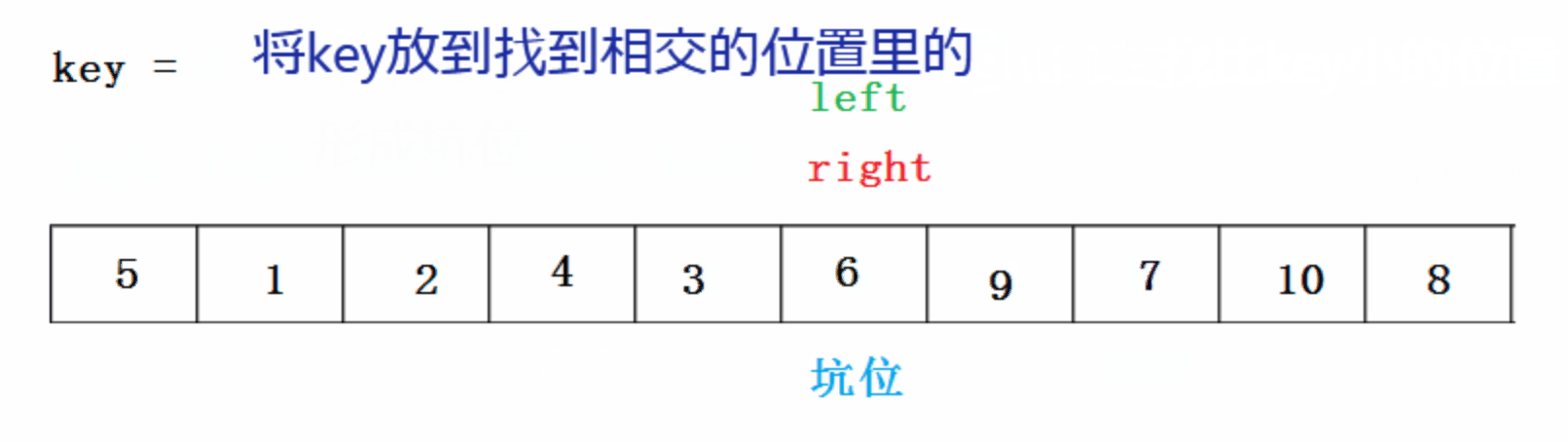
�ڿӷ�:
���Ŵ���:
// ���谴�������array������[left, right)�����е�Ԫ�ؽ������� void QuickSort(int array[], int left, int right) { if(right - left <= 1) return; // ���ջ�ֵ��array����� [left, right)�����е�Ԫ�ؽ��л��� int div = partion(array, left, right); // ���ֳɹ�����divΪ�߽��γ������������� [left, div) �� [div+1, right) // �ݹ���[left, div) QuickSort(array, left, div); // �ݹ���[div+1, right) QuickSort(array, div+1, right); } ����Ϊ��������ݹ�ʵ�ֵ������,�����������ǰ���������dz���,������д�ݹ���ʱ��������� ��ǰ��������ɿ���д����,����ֻ�������ΰ��ջ�ֵ�������������ݽ��л��ֵķ�ʽ���������䰴�ջ�ֵ����Ϊ�������벿�ֵij�����ʽ��:
1.hoare����
2.�ڿӷ�
3.ǰ��ָ�뷨
��չ:�����Ż��㷨�����������Ż�˼·:1.����ȡ�з�ѡkey 2.�ݹ鵽С��������ʱ,���Կ��Dz�������
#define MAX_LENGTH_INSERT_SORT7 //���鳤����ֵ //��˳���L�е�������L.r(low...height)���������� void QSort(SqList &L,int low,int high) { int pivot; if((high-low)>MAX_LENGTH_INSERT_SORT7) { //��high-low���ڳ���ʱ�ÿ������� pivot=Partition(L,low,high); //��L.r[low...high]һ��Ϊ���������pivot QSort(L,low,pivot-1);//�Ե��ӱ��ݹ����� QSort(L,pivot+1,high);//�Ը��ӱ��ݹ����� } else { InsertSort(L);//��high-lowС�ڳ���ʱ��ֱ�Ӳ������� } }��������ǵݹ鷽��:
void QuickSortNonR(int* a, int left, int right) { Stack st; StackInit(&st); StackPush(&st, left); StackPush(&st, right); while (StackEmpty(&st) != 0) { right = StackTop(&st); StackPop(&st); left = StackTop(&st); StackPop(&st); if(right - left <= 1) continue; int div = PartSort1(a, left, right); // �Ի�ֵΪ�ָ��,�γ�����������:[left, div) �� [div+1, right) StackPush(&st, div+1); StackPush(&st, right); StackPush(&st, left); StackPush(&st, div); } StackDestroy(&s) }���������ܽ�:
- ��������������ۺ����ܺ�ʹ�ó������DZȽϺõ�,���ԲŸҽп�������
- ʱ�临�Ӷ�:O(N*logN)
- �ռ临�Ӷ�:O(logN)
- �ȶ���:���ȶ�

2.4 �鲢����
����˼��:
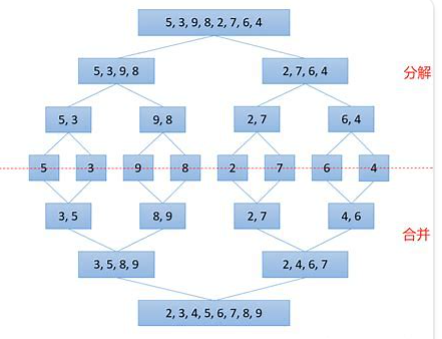
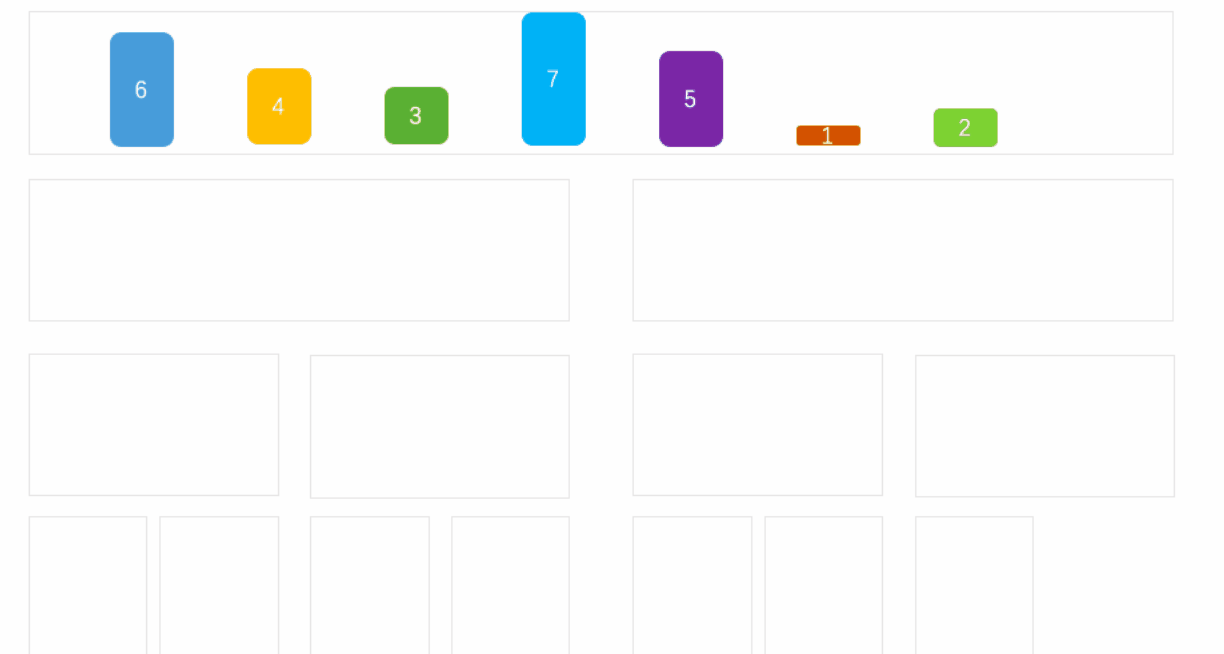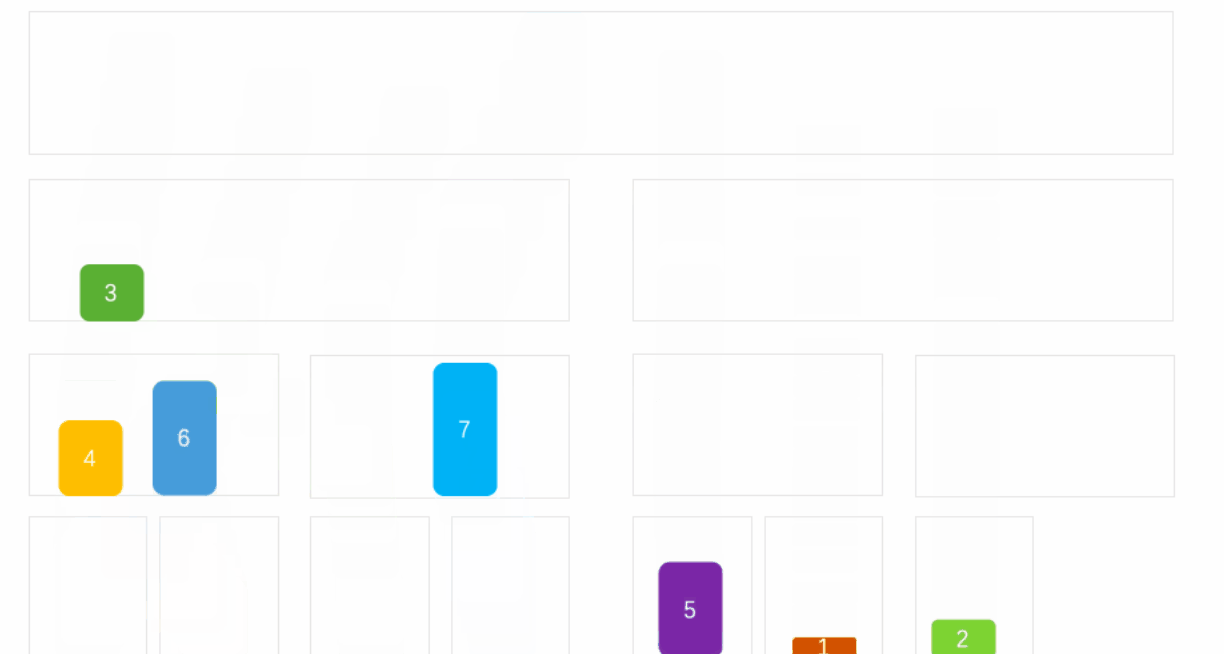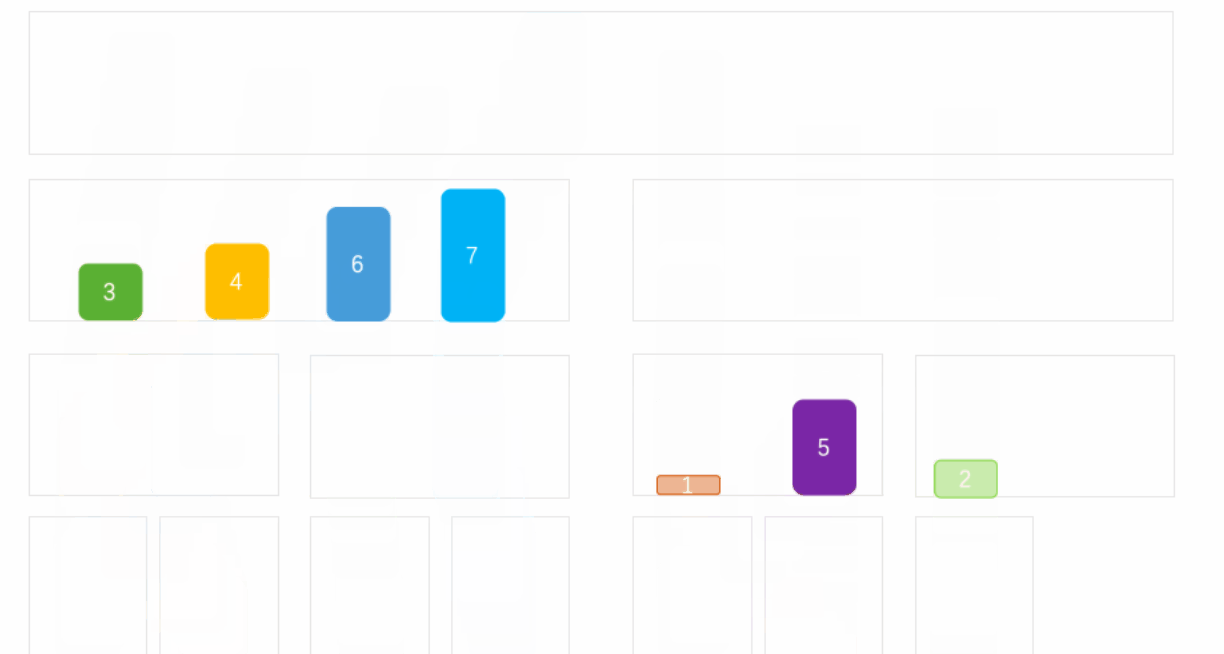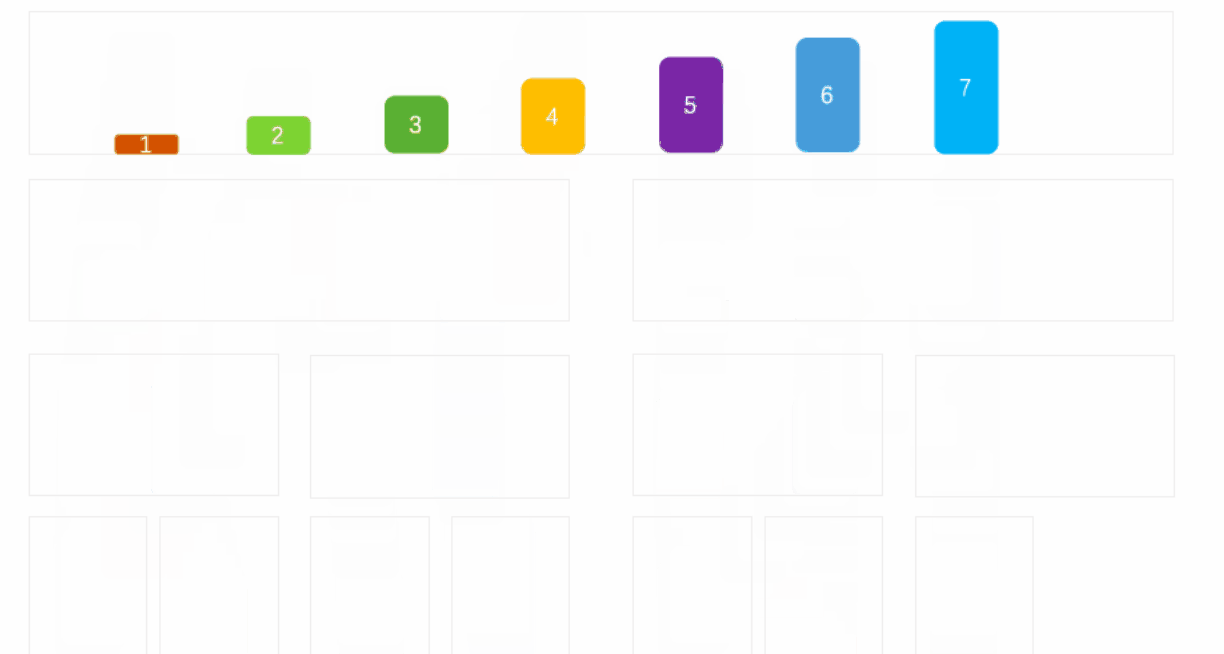
�鲢����(MERGE-SORT)�ǽ����ڹ鲢�����ϵ�һ����Ч�������㷨,���㷨�Dz��÷��η�(Divide andConquer)��һ���dz����͵�Ӧ�á���������������кϲ�,�õ���ȫ���������;����ʹÿ������������,��ʹ�����жμ�������������������ϲ���һ�������,��Ϊ��·�鲢�� �鲢������IJ���:
�鲢�����ܽ�:
- �鲢�����ȱ������ҪO(N)�Ŀռ临�Ӷ�,�鲢�����˼�������ǽ���ڴ����е�����������
- ʱ�临�Ӷ�:O(N*logN)
- �ռ临�Ӷ�:O(N)
- �ȶ���:�ȶ�
2.5 �DZȽ�����(��������)
���������ֳ�Ϊ�볲ԭ��,�ǶԹ�ϣֱ�Ӷ�ַ���ı���Ӧ��
����˼��:1.ͳ����ͬԪ�س��ִ��� 2.����ͳ�ƵĽ����������յ�ԭ����������
���������ܽ�:
- �������������ݷ�Χ����ʱ,Ч�ʺܸ�,�������÷�Χ����������
- ʱ�临�Ӷ�:O(MAX(N,��Χ))
- �ռ临�Ӷ�:O(N)
- �ȶ���:�ȶ�
Ͱ����:
��������:
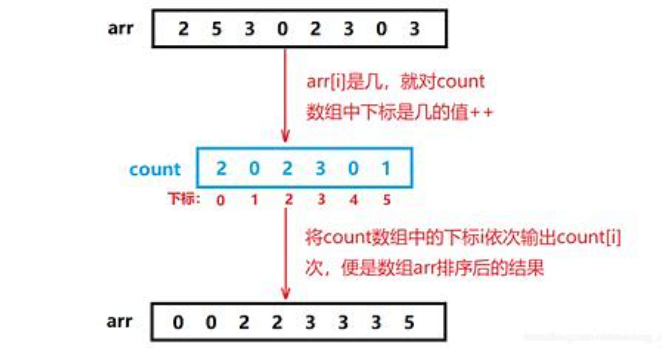
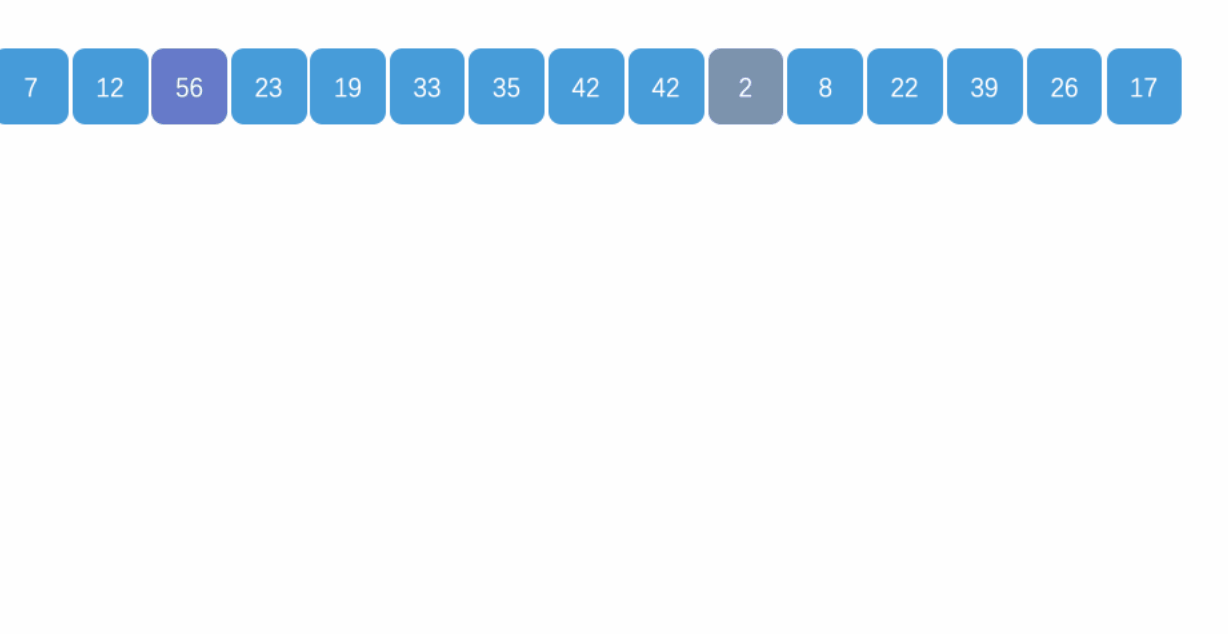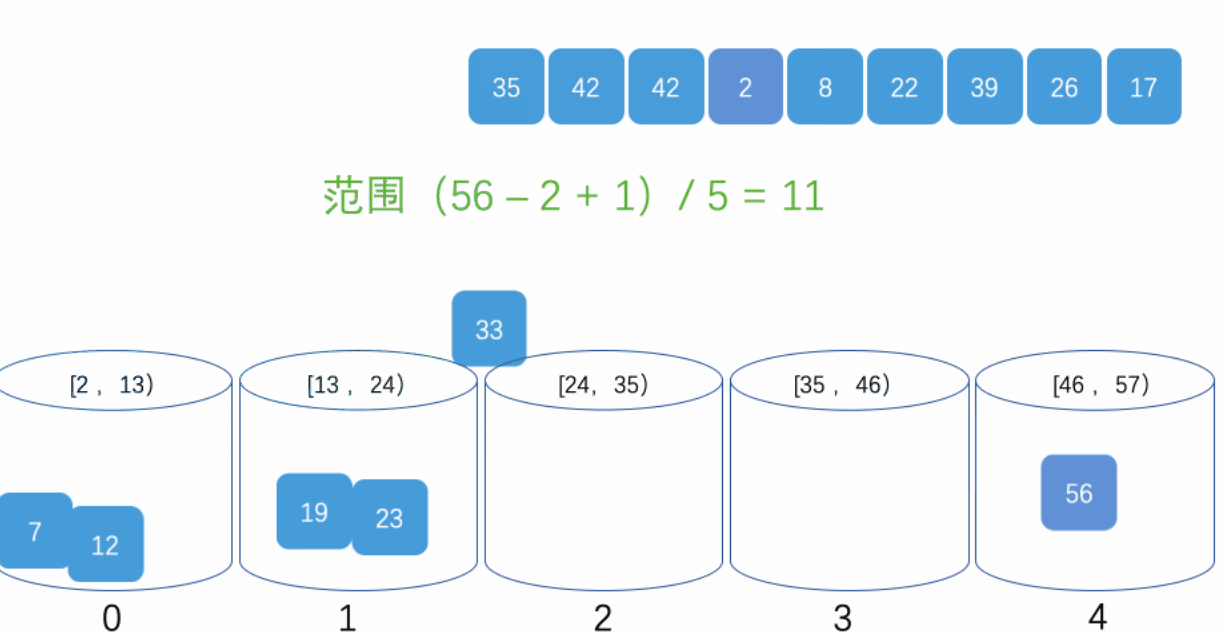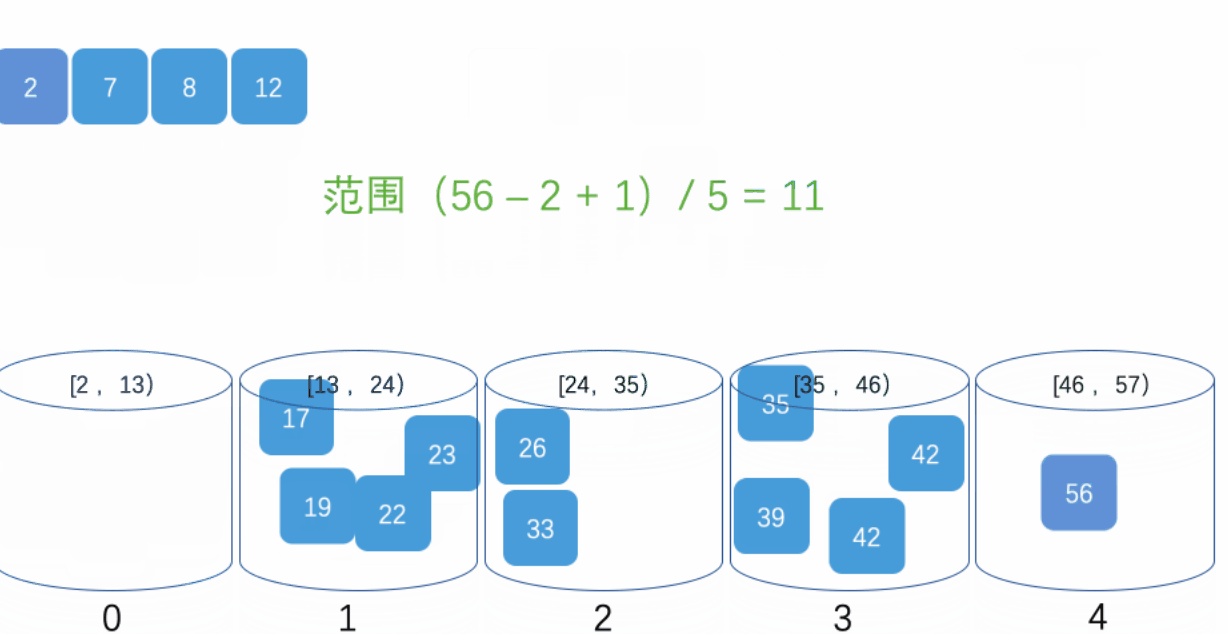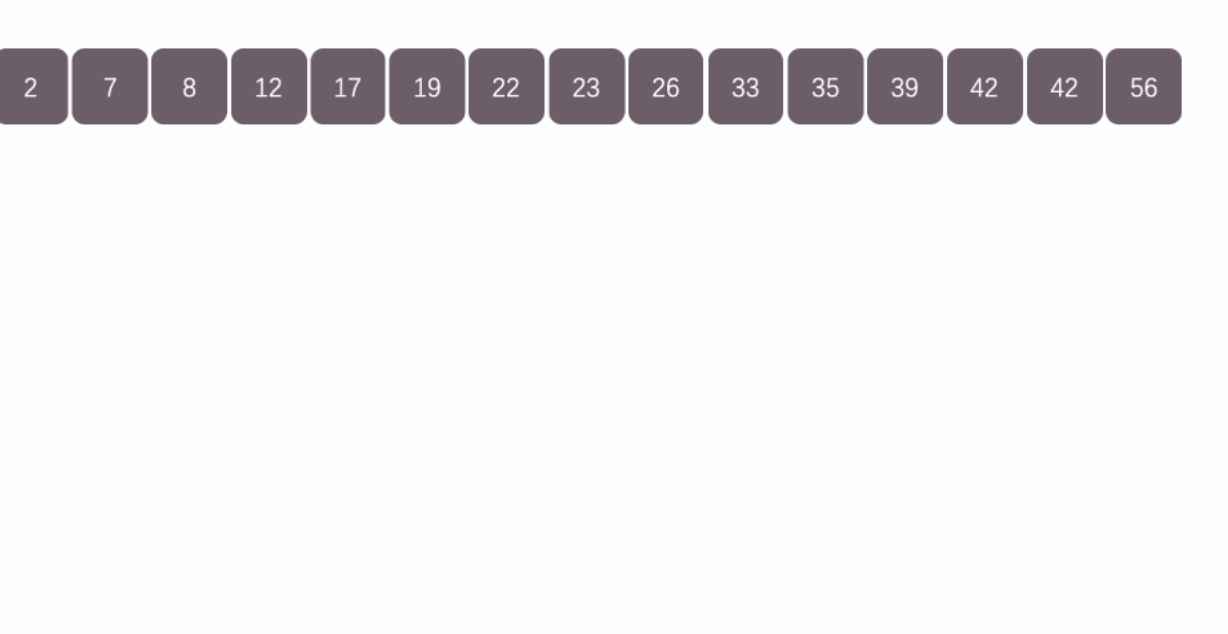
3.�����㷨�ĸ��ӶȺ��ȶ���