������ϣ����
- ֱ�Ӷ��Ʒ�
ȡ�ؼ��ֵ�ij�����Ժ���Ϊɢ�е�ַ:Hash(Key)= A*Key + B �ŵ�:������ ȱ��:��Ҫ����
֪���ؼ��ֵķֲ���� ʹ�ó���:�ʺϲ��ұȽ�С����������� - ����������
��ɢ�б��������ĵ�ַ��Ϊm,ȡһ��������m,����ӽ����ߵ���m������p��Ϊ����,���չ�ϣ��
��:Hash(key) = key% p(p<=m),���ؼ���ת���ɹ�ϣ��ַ - ƽ��ȡ�з�
����ؼ���Ϊ1234,����ƽ������1522756,��ȡ�м��3λ227��Ϊ��ϣ��ַ; �ٱ���ؼ���Ϊ
4321,����ƽ������18671041,��ȡ�м��3λ671(��710)��Ϊ��ϣ��ַ ƽ��ȡ�з��Ƚ��ʺ�:��֪
���ؼ��ֵķֲ�,��λ���ֲ��Ǻܴ����� - �۵���
�۵����ǽ��ؼ��ִ����ҷָ��λ����ȵļ�����(���һ����λ�����Զ�Щ),Ȼ���⼸���ֵ���
���,����ɢ�б�����,ȡ��λ��Ϊɢ�е�ַ��
�۵����ʺ����Ȳ���Ҫ֪���ؼ��ֵķֲ�,�ʺϹؼ���λ���Ƚ϶�����
�������۵�������ʵ��ʾ��ͼ:
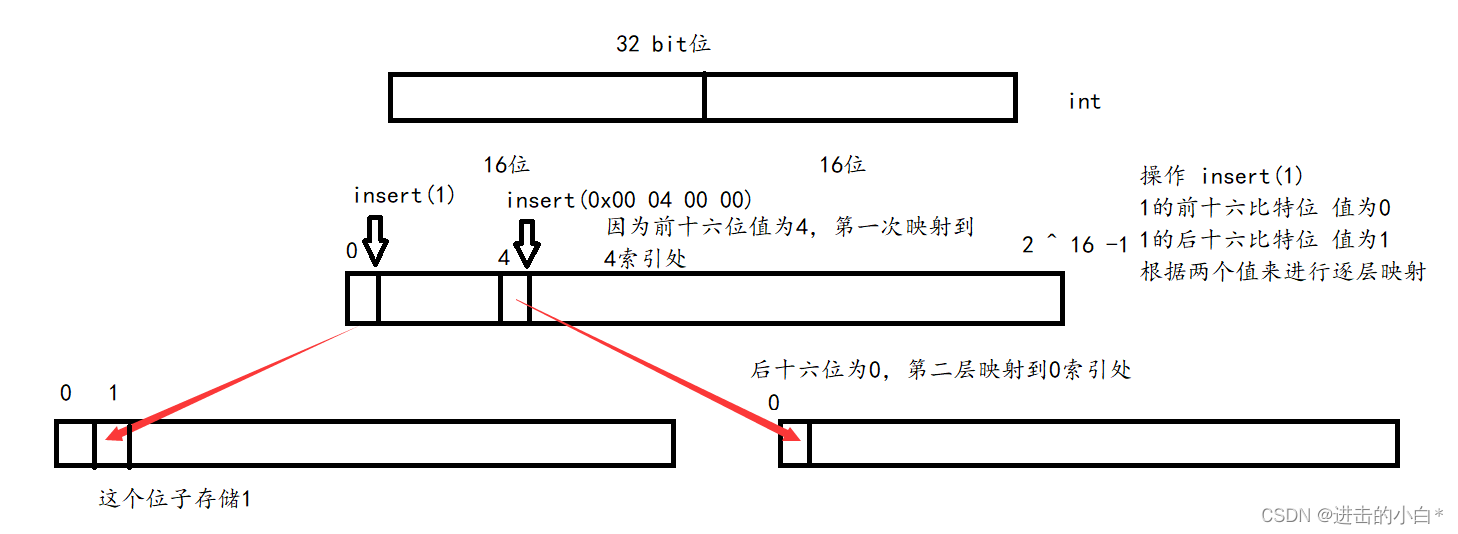
��������key��һ��unsigned int ,����ʹ��λ���������зֳɼ�Ƭ,���Ծ���Ҳ���Բ�����(ͼ�����и���ȵ���Ƭ)��Ȼ�����Ǽ���ÿһ�εĴ�С,��Ϊ16������λ��ʾ0 ~ 2 ^16 -1 ��ֵ,�������ǾͿ���ô��Ŀռ�,Ȼ��ͨ��ǰ16λ��Ӧ��ֵӳ�䵽��һ�����ٵ�������,Ȼ��ͨ����һ��ӳ��λ���ٿ�һ��vector��������,Ȼ��ͨ����ʮ��λ��ֵ���жϵڶ��������ֵ��
�Ż�����:��ͼʾ�������������˽ϴ�Ŀռ�,��Ϊ2 ^ 16�Ƚϴ�,������Կռ�����Ľϴ����ǿ���ͨ�����Ӷ�key�и����,�Ӷ�����ӳ��Ĵ���,�������Լ��ٿռ�Ĵ�С��(����ƽ���зֳ�4��,��ôÿһ��ֻ��Ҫ�� 2 ^ 8 = 256 ���ռ�)ÿһ��ֵ�Ĵ洢�������� 2 ^ 8 * 4 = 1024 ���ռ䡣���������и�����ڲ���ʱҲ����Ҫ���Ӳ��ҵĴ���,�и�����������,�и��Ĵ����ĴΡ�������Ҫ����Ӧ�ó�������ѡ���иʽ
- �������
ѡ��һ���������,ȡ�ؼ��ֵ��������ֵΪ���Ĺ�ϣ��ַ,��H(key) = random(key),����randomΪ�����������
ͨ��Ӧ���ڹؼ��ֳ��Ȳ���ʱ���ô˷�
�õĹ�ϣ�������Ծ������ٹ�ϣ��ͻ�ķ����ĸ���,���Dz�����ȫ��ֹ��ϣ��ͻ
λͼ��Ӧ��

����:����ֱ�Ӷ�ֵ��,ֻ��������keyΪ���ε����
�ײ�ʵ��:ͨ������һ��vector,��ÿһ������λ����һ������,���������key = 0,��һ������λ���ó��㡣���εĴ�С�ӽ�����ʮ���ھ�ǧ����ֽ�,Ҳ���൱��4G,��ÿ������ռ��һ������λ��ô��Ҫ���ٽӽ� 4G / 8 = 0.5G�Ŀռ䡣��ô���ǾͿ���ͨ�����Ϊ0.5Gλͼ���洢key
��Ҫ�ӿ�:
set :����һ��λ��,���������λ����Ϊ1
reset:����һ��λ��,���������λ����Ϊ0
test:����һ��λ��,�����λ��ֵΪ1 ��true Ϊ0 ��false
λͼ��Ӧ��
- ���ٲ���Ī�����Ƿ��ڼ�����
- ����
- ��
- ����ϵͳ�Ѵ��̿���б��
- �������ݴ���
λͼ��ģ��ʵ��
#pragma once
#include <iostream>
#include <vector>
using namespace std;
template<size_t N>
class my_bitset
{
public:
my_bitset() { v.resize(N / 8 + 1, 0); }
my_bitset& set(size_t pos);
my_bitset& reset(size_t pos);
bool test(size_t pos);
size_t size();
private:
vector<char> v;
};
template<size_t N>
my_bitset<N>& my_bitset<N>::set(size_t pos)
{
size_t index = pos / 8;
size_t bit_index = pos % 8;
v[index] = v[index] | (1 << bit_index);
return *this;
}
template<size_t N>
my_bitset<N>& my_bitset<N>::reset(size_t pos)
{
size_t index = pos / 8;
size_t bit_index = pos % 8;
v[index] = v[index] & (~(1 << bit_index));
return *this;
}
template<size_t N>
bool my_bitset<N>::test(size_t pos)
{
size_t index = pos / 8;
size_t bit_index = pos % 8;
return (bool)(v[index] & (1 << bit_index));
}
void my_bitset_test()
{
my_bitset<1000> bs;
bs.set(1);
bs.set(11);
bs.set(15);
cout << bs.test(11) << endl;
cout << bs.test(16) << endl;
}
λͼ����һ���ľ�����,λͼֻ�ܴ������ν��в���,������Ҫ��������Ҫ���������;���ij�ִ���ת��Ϊ���βſ��Դ��롣
��¡������
bloon filter(��¡������):�ײ�Ϊλͼ,Ϊ�������ݵĴ洢��ʡ�ռ�,�����Խ��ͳ�ͻ�ĸ���,��������ȫ�����ͻ�����Բ�¡�������������ڴ����������ʵ����,�ھ�����������Ҫ���н�һ������
��¡��������ʵ��ԭ��(��key����Ϊstring����)
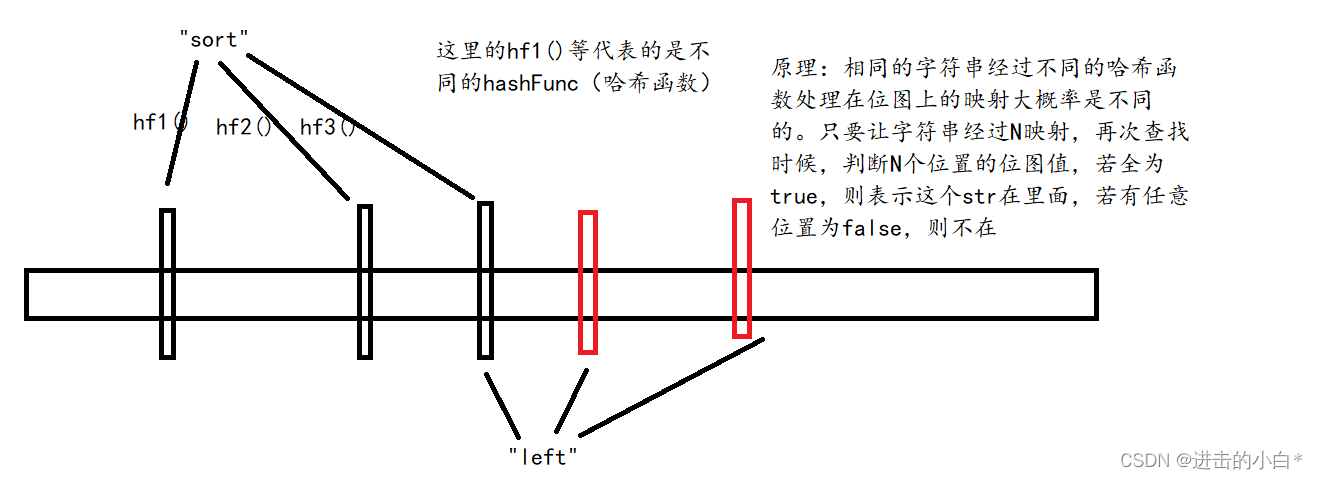
��ͼ,����ÿһ��key(string)����ʹ�����ι�ϣ����,��������ӳ����λͼ������λ������Ϊ1��
��¡�������жϴ���ʱҪ��,���key������ӳ�������Ϊ1,�ŷ���true����ͼ�ϵ�left��sort������ijһ����ϣ�����������ַ���ӳ�䵽ͬһ���ط�ʱ,��ô������sort�ڶ�left����,sort����left��,���߶��ڵ��������������ӳ��,��ӳ��λ��ȫ����һ��ĸ��ʾͻ�С�ܶࡣ��ͼʾ����Ϳ��Ա������ߵ��ж�ʧ��
����ӳ����Ҫ���ϴ�Ŀռ��Խ���ϣ��ͻ��Ч��,��¡�������ļ�ֵ���ڽ�ʡ�ռ併�ͳ�ͻ���ʡ�������Ȼ����ڳ�ͻ,�ڲ�¡����������������ض�����,���������
��¡������ģ��ʵ��
��ܽ���
template<size_t N, size_t X,
class HashFunc1,
class HashFunc2,
class HashFunc3>
class bloon_filter
{
public:
bloon_filter& set(const string& str);
bool test(const string& str);
private:
bitset<N * X> bs;
};
ģ�����:
N:���洢�����ݸ���
X:����λͼ�ij�����N�ı���
HashFunc + ����:��ϣ����
��Ա����
set:����ϣ������������keyӳ�䵽λͼ��
test:����key������ϣ������������ӳ����λͼ��λ�õ�ֵ,ȫΪһ����true ����false
��Ա����
��С���Դ洢N*X������λ��λͼ
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N, size_t X,
class HashFunc1,
class HashFunc2,
class HashFunc3>
class bloon_filter
{
public:
bloon_filter& set(const string& str)
{
HashFunc1 h1;
HashFunc2 h2;
HashFunc3 h3;
size_t len = X * N;
size_t index1 = h1(str) % len; //ӳ��ؼ�ֵ1
size_t index2 = h2(str) % len; //ӳ��ؼ�ֵ2
size_t index3 = h3(str) % len; //ӳ��ؼ�ֵ3
bs.set(index1); //������ӳ��ؼ�ֵ��λͼ�е�λ������Ϊ1
bs.set(index2);
bs.set(index3);
return *this;
}
bool test(const string& str)
{
HashFunc1 h1;
HashFunc2 h2;
HashFunc3 h3;
size_t len = X * N;
size_t index1 = h1(str) % len;
size_t index2 = h2(str) % len;
size_t index3 = h3(str) % len;
return bs.test(index1) //����ӳ��λ�ö�Ϊ1��true ����false
&& bs.test(index2)
&& bs.test(index3);
}
private:
bitset<N * X> bs;
};
��¡���������ܲ���
���˼·:
base:��һ�����Ƶ��ַ���ֱ��ӳ�䵽λͼ�Ϻ;�����¡������ӳ�䵽λͼ��
��һ���base���Ƶ��Dz���ȫ��ͬ���ַ������������ֱ���λͼ�Ͳ�¡�������в���,��¼���ڴ���(�����д���)
��һ���base��ͬҲ�����Ƶ��ַ��������ֱ���ڲ�¡��������λͼ�ϲ���,��¼���ڴ���(�����д���)
��Ϊ�ڶ���͵��������ݺ͵�һ��һ����ͬ,���ҵڶ��������������Ӧ���Ƿ��ز����ڵ�,������Ϊ���ڹ�ϣ��ͻ,���������,�������ǿ��Ը������еĴ������ж�����
#include "my_filter.h"
#define N 1000
#define X 10
void test1()
{
bloon_filter<N, X, BKDRHash, APHash, DJBHash> bf;
//�Ͳ�¡��������ͬ��С��λͼ
bitset<N * X> bs;
vector<string> v1;
vector<string> v2;
vector<string> v3;
//v1�洢N���ַ���,���Ƕ�������,ֻ�Ǻ���һ��
for (int i = 0; i < N; i++)
{
string base = "https://gitee.com/bithange/class_code/blob/master/class";
string end = base + to_string(1234 + i);
v1.push_back(end);
}
//v2�洢N���ַ���,���Ǻ�v1��Ҳ������,��Ҳ��һ��
for (int i = 0; i < N; i++)
{
string base = "https://gitee.com/bithange/class_code/blob/master/class";
string end = base + to_string(5678 + i);
v2.push_back(end);
}
//v3�洢N���ַ���, ���Ǻ�v1���ַ�����ͬ
for (int i = 0; i < N; i++)
{
string base = "https://fanyi.baidu.com/translate?aldtype=16047&query";
string end = base + to_string(5678 + i);
v3.push_back(end);
}
//ʹ�õ�����ϣ����
BKDRHash ap;
//��v1ÿһ���ַ�����ǽ���λͼ�Ͳ�¡������
for (auto str : v1)
{
bf.set(str);
bs.set(ap(str) % (N*X));
}
size_t n1 = 0; //�洢��¡�����������д���(ʹ������key)
size_t n3 = 0; //�洢ֱ��ʹ��λͼ���д���(ʹ������key)
for (auto str: v2)
{
if (bf.test(str))
n1++;
if (bs.test(ap(str) % (N*X)))
n3++;
}
size_t n2 = 0; //�洢��¡�����������д���(ʹ�ò�����key)
size_t n4 = 0; //�洢ֱ��ʹ��λͼ���д���(ʹ�ò�����key)
for (auto str : v3)
{
if (bf.test(str))
n2++;
if (bs.test(ap(str) % (N*X)))
n4++;
}
cout << "��¡����������������Ϊ" << (double)n1 / N << endl;
cout << "��¡������������������Ϊ" << (double)n2 / N << endl;
cout << "ֱ��λͼ����������Ϊ" << (double)n3 / N << endl;
cout << "ֱ��λͼ������������Ϊ" << (double)n4 / N << endl;
}
int main()
{
test1();
return 0;
}
���Խ��
[clx@VM-20-6-centos bloon_filter]$ ./test
N=1000 : X=5
��¡����������������Ϊ0.073
��¡������������������Ϊ0.095
ֱ��λͼ����������Ϊ0.323
ֱ��λͼ������������Ϊ0.021
[clx@VM-20-6-centos bloon_filter]$ ./test
N=1000 : X=10
��¡����������������Ϊ0.008
��¡������������������Ϊ0.009
ֱ��λͼ����������Ϊ0.293
ֱ��λͼ������������Ϊ0.021
[clx@VM-20-6-centos bloon_filter]$ ./test
N=1000 : X=15
��¡����������������Ϊ0
��¡������������������Ϊ0
ֱ��λͼ����������Ϊ0.293
ֱ��λͼ������������Ϊ0.021
���ǿ��Թ۲쵽��XԽС,������Խ��,˵���ռ��С�������ʹ�ϵ���Ƿdz����е�
���ռ��С��ͬ�������,��¡�������������ʶ�ԶС��ֱ��ʹ�õ�һ��ϣ��������λͼ�ж�
��ʡ�ռ���ٹ�ϣ��ͻ,����Dz�¡�������ļ�ֵ����
��¡����������ȱ��
��¡������������
1.��ѯԪ�ش��ڵ�ʱ�临�Ӷ�ΪO(K),KΪ��ϣ�����ĸ���(һ�㶼��С,��������������),����Ч�����λͼ�Ը�,����ʤ�ڽ�ʡ�����ռ䡣
2.��ϣ�����֮��û����ϵ,����Ӳ����������
3.��¡����������Ҫ�洢Ԫ�ر���,ֻ��Ҫ�洢key��Ӧ�Ĺ�ϣ�ؼ�֮,��ijЩ����Ҫ���ϸ�ij������ھ�����
4.�������������е������,��¡���������������ݽṹӵ�кܴ�Ŀռ�����
5.�������ܴ�ʱ,��¡���������Ա�ʾȫ��
6.��¡���������Զ�ͬһɢ�м����н���������
��¡������������
1.��������,���ܻ���ּ����Ե����
�������:�����˺�������������ȡ������������ݽṹ,���������ų�
2.���ܻ�ȡԪ�ر���
3.��¡������һ�㲻֧��ɾ��
4.������ü�����ʽɾ��,���ܴ��ڼ�����������
�˴���4���ľ��Dz�¡��������ɾ������,��������ɾ���Ľϳ����ֶΡ���Ϊ������Ŀռ�,��ÿһ��key�Ĺ�ϣ�ؼ�ֵռ��һС�����λ,ÿ������λ����һ�ξ���������λ��++,����˸�����λ�Ϳ��Ա�ʾ�����ϣ�ؼ�ֵ����0 ~ 255���ظ������,ɾ����K��key��Ӧ�Ĺؼ�ֵ�C����������һ��λ�ó���255��,�����±�Ϊ0,����Ǽ�������
����������Ȼ����˲�¡��������ɾ��,������Ĵ����е��ÿ��λ����Ҫ����Ŀռ�,�Լ۱Ⱥܵ�,���Բ�¡������һ�㲻֧��ɾ��
��ϣ�и�
��������:
��һ������100G��С��IP file, IP file�д���IP��ַ, ����㷨�ҵ����ִ�������IP��ַ?����ҵ�IP file�� top K��IP
1.���Խ�100G��С���ļ��ֳ�2000��,һ�ݰ�����˵Լ����50MB
2.��ÿһ��IP��ַ����ϣ������%2000,����100G�ļ��е�IP�ͱ����Ƿֵ���100G���ļ��С���Ϊ��ͬ��IP���й�ϣ������ӳ�䵽���ļ��϶�����ͬ�ġ�
3.��ÿ��С�ļ�IP���д���,���Խ���map���洢pair<IP, int> ǰһ�������洢IP,��һ����������,�Ϳ��Եõ�ÿһ��С�ļ��г��ִ�������IP��ַ,��ǧ���ļ�������ǧ��������,ȡ���������ľ���100G�ļ���������
���ϼ��ǹ�ϣ�и��˼·