жЊЪЖЕМКН
вЛ.ПьЫйХХађ
ПьЫйХХађЪЧ1960ФъгЩВщЖћЫЙЁЄАВЖЋФсЁЄРэВщЕТЁЄЛєЖћ(Charles Antony Richard Hoare),вЛАуГЦЮЊЖЋФсЁЄЛєЖћ(Tony Hoare)ЁЃНгЯТРДШУЮвУЧзпНјетИіЁАКмПьЁБ
ЕФХХађАЩ!
 🥳🥳ПьЫйХХађ,ЙЫУћЫМвхЪЧЪЕМљжавЛжжПьЫйЕФХХађЫуЗЈ,дйc++КЭjavaЛљБОРраЭжаЖМЬиБ№гагУЁЃЫћЕФЦНОљдЫааЪБМфЪЧO(NlogN),ИУЫуЗЈжЎЫљвдетУДПь,жївЊЪЧгЩгкЗЧГЃОЋСЖКЭИпЖШгХЛЏЕФФкВПбЛЗ,ЫќЕФзюЛЕЧщПіЪЧO(n2),ЕЋОЙ§ЩдаэХЌСІПЩвдЪЙетжжЧщПіМЋФбЪЕЯжЁЃ
🥳🥳ПьЫйХХађ,ЙЫУћЫМвхЪЧЪЕМљжавЛжжПьЫйЕФХХађЫуЗЈ,дйc++КЭjavaЛљБОРраЭжаЖМЬиБ№гагУЁЃЫћЕФЦНОљдЫааЪБМфЪЧO(NlogN),ИУЫуЗЈжЎЫљвдетУДПь,жївЊЪЧгЩгкЗЧГЃОЋСЖКЭИпЖШгХЛЏЕФФкВПбЛЗ,ЫќЕФзюЛЕЧщПіЪЧO(n2),ЕЋОЙ§ЩдаэХЌСІПЩвдЪЙетжжЧщПіМЋФбЪЕЯжЁЃ
вВе§ЪЧвђЮЊПьЫйХХађЕФИпОЋЖШвВЪЙЫуЗЈШчЙћЩдгаЮЪЬтОЭЛсВњЩњКмдуИтЕФЧщПіЁЃ
1.ПьЫйХХађЕФдРэ
ПьЫйХХађЕФжДааЙ§ГЬ:
(1) ДгађСажабЁдёвЛИіжсЕудЊЫи(pivot)
? МйЩшУПДЮбЁдё 0 ЮЛжУЕФдЊЫиЮЊжсЕудЊЫи
(2) РћгУ pivot НЋађСаЗжИюГЩ 2 ИізгађСа
? НЋаЁгк pivot ЕФдЊЫиЗХдкpivotЧАУц(зѓВр)
? НЋДѓгк pivot ЕФдЊЫиЗХдкpivotКѓУц(гвВр)
? ЕШгкpivotЕФдЊЫиЗХФФБпЖМПЩвд
(3) ЖдзгађСаНјаа (1) (2) Вйзї
? жБЕНВЛФмдйЗжИю(згађСажажЛЪЃЯТ1ИідЊЫи)
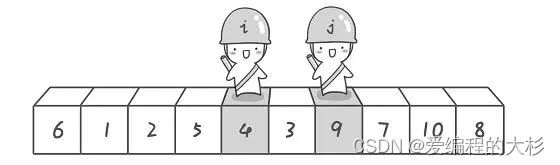
 ПьЫйХХађЕФБОжЪ:ж№НЅНЋУПвЛИідЊЫиЖМзЊЛЛГЩжсЕудЊЫи
ПьЫйХХађЕФБОжЪ:ж№НЅНЋУПвЛИідЊЫиЖМзЊЛЛГЩжсЕудЊЫи
2.жсЕуЙЙдьгыДњТыЪЕЯж
(1)вбжЊжсЕуЕФПьХХЪЕЯж
МйЩшЮвУЧЯШвдЕквЛИідЊЫизїЮЊжсЕуНјааЙЙдь
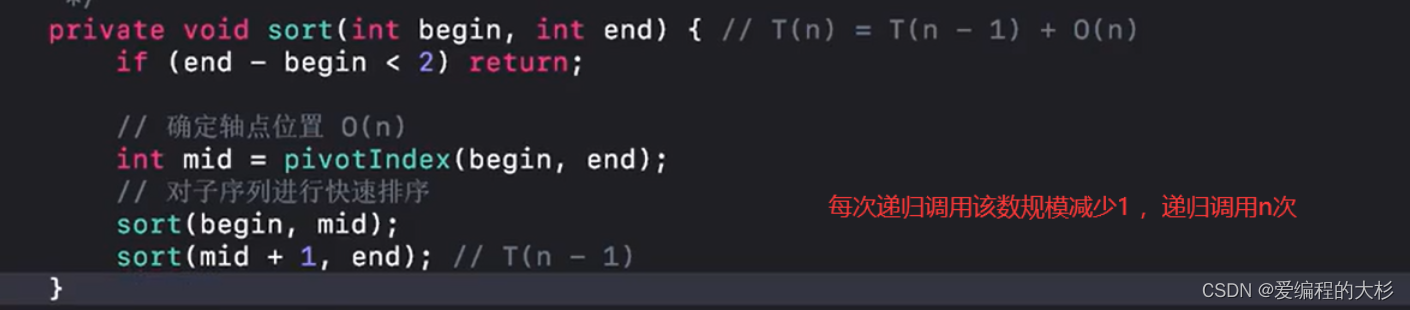
- НЋЕквЛИідЊЫиНјааЛКДц

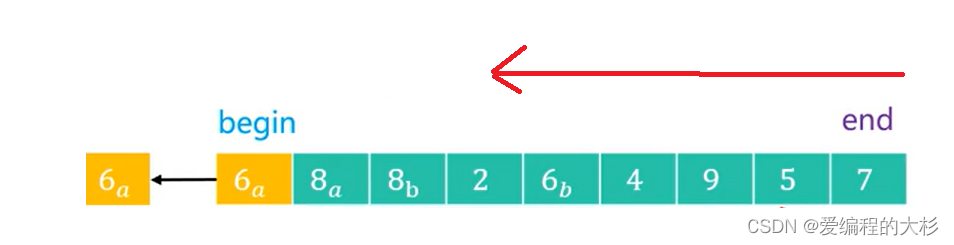
2.(1) Ъ§зщДггвЯђзѓНјааБщРњ,ШчЙћendЮЛжУЕФЪ§ОнБШЛКДцЕФжсЕудЊЫи(pivot)Ъ§Дѓ,дђжБНгНјааendЈC,вђЮЊгвБп БОРДОЭЪЧДцДЂБШжсЕудЊЫиДѓЕФдЊЫиЁЃ
(2)ШчЙћШчЙћendЮЛжУЕФЪ§ОнБШЛКДцЕФжсЕудЊЫи(pivot)Ъ§аЁЛђепЕШгк,дђНЋФПЧАЕФдЊЫиИВИЧЕНЧАУцЕФЮЛжУЁЃbegin++.ВЂЧвНЛЛЛБщРњЗНЯђЁЃ
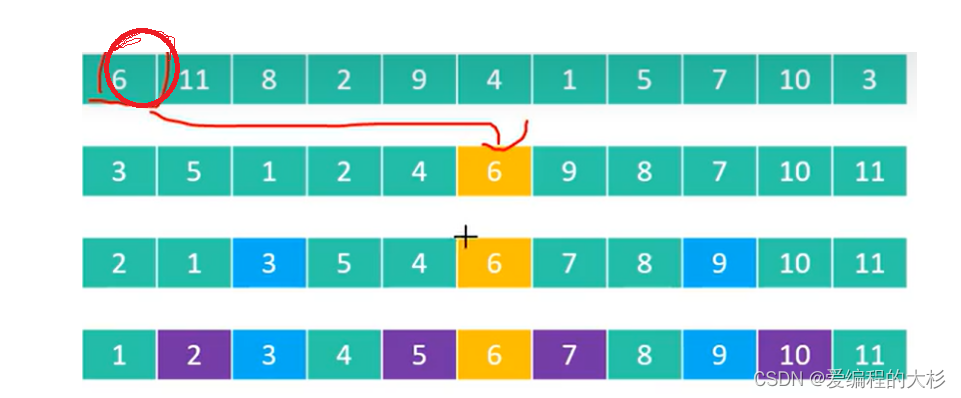
- жиИДжДаавдЩЯ1,2Й§ГЬ,ЕУГіНсЙћ,зюКѓНЋЛКДцЕФжсЕудЊЫиЙщЮЛ
 зЂвт:ЭМжаКкЩЋНкЕуДњБэПЩвдИВИЧЕФПеЯаНкЕу
зЂвт:ЭМжаКкЩЋНкЕуДњБэПЩвдИВИЧЕФПеЯаНкЕу
ДњТыЪЕЯж:
public class QuickSort <E extends Comparable<E>> extends Sort<E> {
@Override
public void sort() {
sort(0, array.length);
}
/**
* Жд [begin, end) ЗЖЮЇЕФдЊЫиНјааПьЫйХХађ
* @param begin
* @param end
*/
private void sort(int begin, int end) {
if (end - begin < 2) return;
// ШЗЖЈжсЕуЮЛжУ O(n)
int mid = pivotIndex(begin, end);
// ЖдзгађСаНјааПьЫйХХађ
//етРяЕФbeginВЛвЊаДГЩ0
sort(begin, mid);
sort(mid + 1, end);
}
/**
* ЙЙдьГі [begin, end) ЗЖЮЇЕФжсЕудЊЫи
* @return жсЕудЊЫиЕФзюжеЮЛжУ
*/
private int pivotIndex(int begin, int end) {
// БИЗнbeginЮЛжУЕФдЊЫи
//етРяЕФbeginВЛвЊаДГЩ0
E pivot = array[begin];
// endжИЯђзюКѓвЛИідЊЫи
end--;
while (begin < end) {
while (begin < end) {
if (com(pivot, array[end]) < 0) { // гвБпдЊЫи > жсЕудЊЫи
end--;
} else { // гвБпдЊЫи <= жсЕудЊЫи
array[begin++] = array[end];
break;
}
}
while (begin < end) {
if (com(pivot, array[begin]) > 0) { // зѓБпдЊЫи < жсЕудЊЫи
begin++;
} else { // зѓБпдЊЫи >= жсЕудЊЫи
array[end--] = array[begin];
break;
}
}
}
// НЋжсЕудЊЫиЗХШызюжеЕФЮЛжУ
array[begin] = pivot;
// ЗЕЛижсЕудЊЫиЕФЮЛжУ
return begin;
}
}
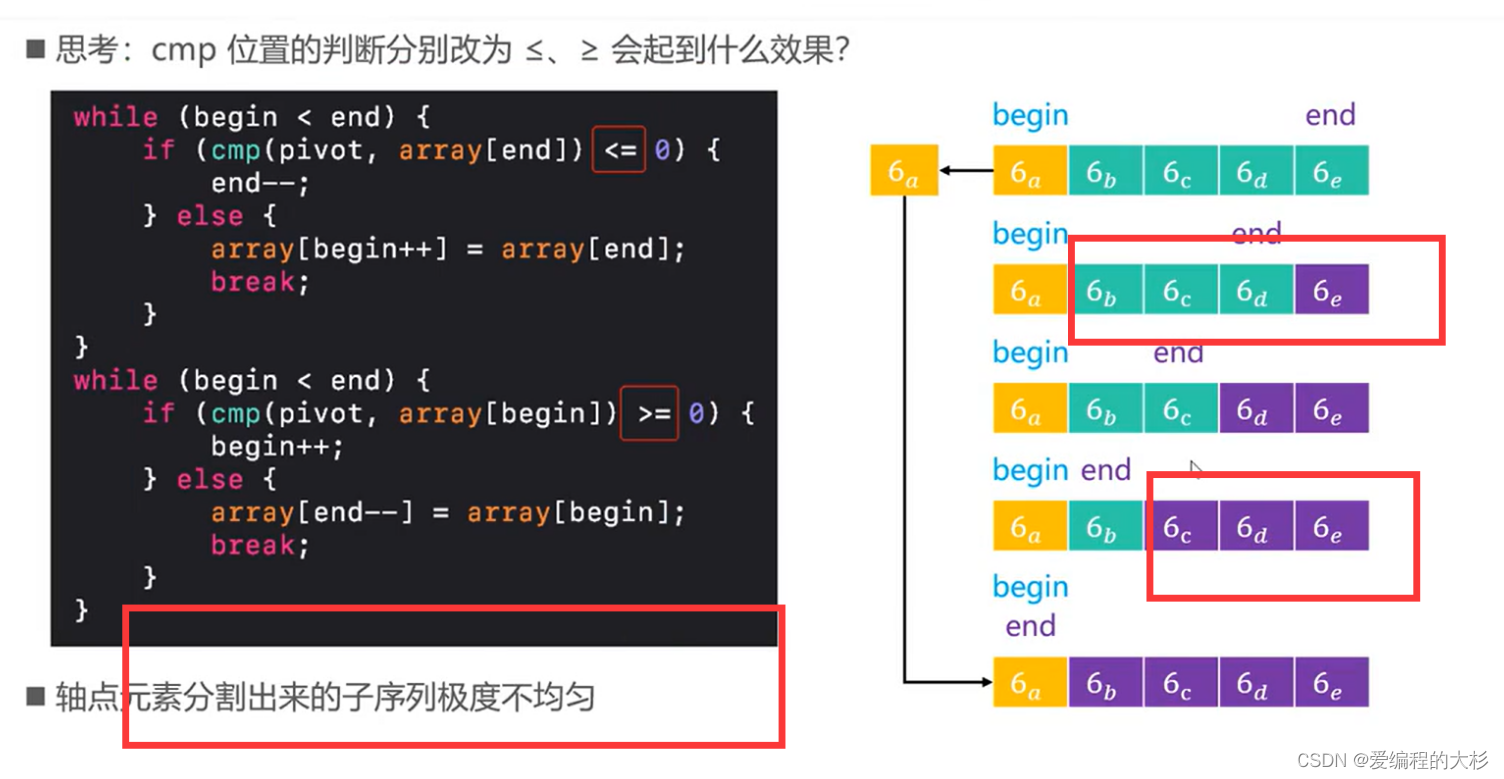
(2)жсЕуЙЙдьЕФДэЮѓгУЗЈ
ЩЯУцЕФСїГЬЮвУЧФЌШЯжсЕуЮЊЕквЛИідЊЫи,ЕЋЪЧетжжЩшМЦЯдШЛВЛФмЗЂЛгГіПьЫйХХађЕФгХЕуЩѕжСВЛФмПДГіЫќБШЙщВЂХХађЕНЕзЧПЕНФФРяЁЃ
жсЕуЙЙдьЕФДэЮѓЗНЗЈ
- НЋЕквЛИідЊЫизїЮЊжсЕудЊЫи
ШчЙћФЌШЯНЋЕквЛИідЊЫизїЮЊжсЕудЊЫи,ШчЙћЪфШыЪ§зщдЊЫиЪЧЫцЛњЕФФЧЪЧПЩвдНгЪмЕФ,ШчЙћЪфШыЪ§зщЪЧдЄХХађЕФЛђепЪЧЗДађЕФ,ФЧУДОЭЛсВњЩњвЛИіЖёСгЕФЗжИю,вђЮЊЫљгаЕуЕФдЊЫиЛсБЛЭГвЛЙцЛЎЕНвЛБпЁЃ - бЁШЁСНИіЛЅвьжаЕФНЯДѓепзїЮЊжсЕудЊЫи
етжжЗНЗЈКЭЕквЛжжЗНЗЈОпгаЭЌбљЕФЮЃКІад
(3)жсЕуЫцЛњЛЏ
НтОіЩЯУцЕФЕФЮЪЬтЮвУЧОЭвЊЖдЩЯУцЕФжсЕуЕФбЁШЁНјааЫцЛњЛЏ
ЮвУЧНЋbegin + (int)(Math.random() * (end - begin)зїЮЊжсЕудЊЫи
Math.random() * (end - begin)ЕФЗЖЮЇЪЧ[0,begin-end);
Ыљвдbegin + (int)(Math.random() * (end - begin)ЕФЗЖЮЇОЭЪЧ[begin,end)
ЮвУЧжЛашНЋЩЯУцЕФДњТыНјааМђвЊИФЖЏОЭФмЪЕЯжжсЕудЊЫиЫцЛњЛЏ
🌎 ЮвУЧжЛашжЛашжДааетИіВйзїswap(begin, begin + (int)(Math.random() * (end - begin)));НЋЫцЛњЩњГЩЕФжсЕудЊЫиЗХдкЕквЛИідЊЫиЕФЮЛжУОЭааСЫ
private int pivotIndex(int begin, int end) {
// ЫцЛњбЁдёвЛИідЊЫиИњbeginЮЛжУНјааНЛЛЛ
swap(begin, begin + (int)(Math.random() * (end - begin)));
// БИЗнbeginЮЛжУЕФдЊЫи
//етРяЕФbeginВЛвЊаДГЩ0
E pivot = array[begin];
// endжИЯђзюКѓвЛИідЊЫи
end--;
while (begin < end) {
while (begin < end) {
if (com(pivot, array[end]) < 0) { // гвБпдЊЫи > жсЕудЊЫи
end--;
} else { // гвБпдЊЫи <= жсЕудЊЫи
array[begin++] = array[end];
break;
}
}
while (begin < end) {
if (com(pivot, array[begin]) > 0) { // зѓБпдЊЫи < жсЕудЊЫи
begin++;
} else { // зѓБпдЊЫи >= жсЕудЊЫи
array[end--] = array[begin];
break;
}
}
}
5.ЯИНкЦЪЮігыИДдгЖШЗжЮі
ПьЫйХХађЕФКЫаФЕїгУДњТы:
- дкжсЕузѓгвдЊЫиЪ§СПБШНЯОљдШЕФЧщПіЯТ,ЭЌЪБвВЪЧзюКУЕФЧщПі
private void sort(int begin, int end) {
if (end - begin < 2) return;
// ШЗЖЈжсЕуЮЛжУ O(n),ашвЊБщРњЫљгадЊЫи
int mid = pivotIndex(begin, end);
// ЖдзгађСаНјааПьЫйХХађ
//етРяЕФbeginВЛвЊаДГЩ0
sort(begin, mid);//O(n/2)
sort(mid + 1, end);//O(n/2)
}
ЫљвдПьЫйХХађЕФЫљгУЕНЕФЪБМфНќЫЦЮЊ2O(T/2)+O(n),ЖдБШЕнЭЦЪНБэЕУжЊзюКУЕФЧщПіЪЧO(nlogn)
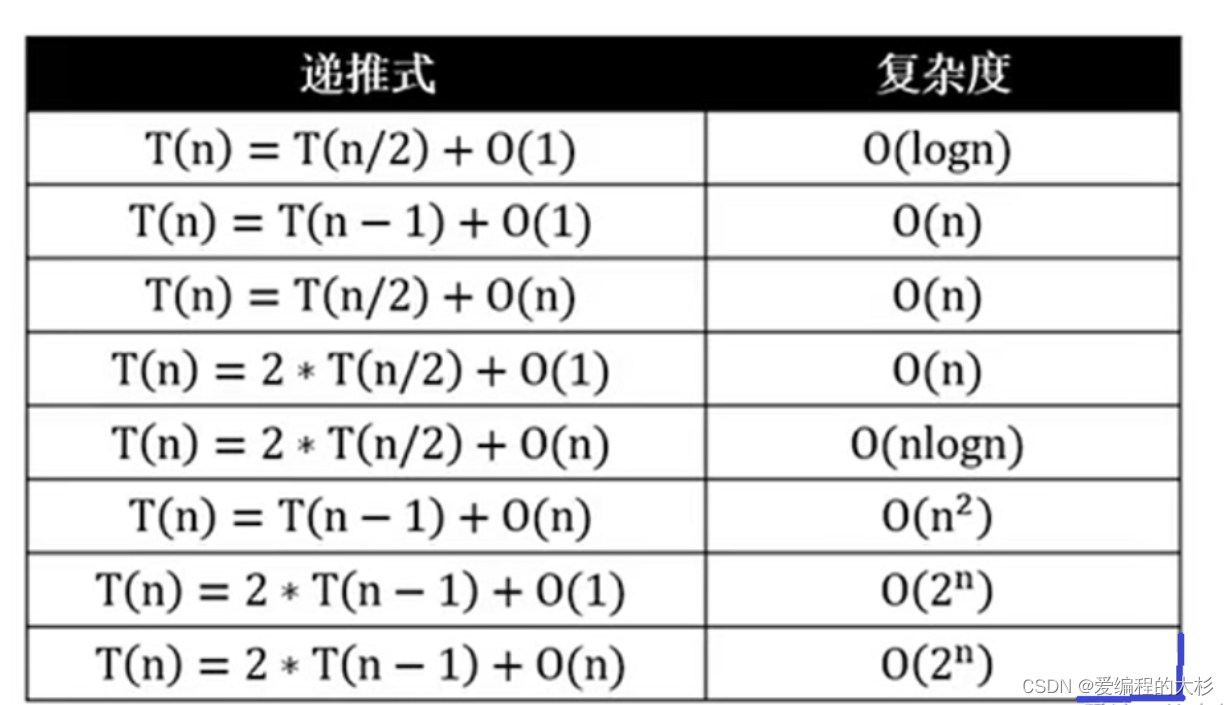
- ШчЙћжсЕузѓгвдЊЫиЪ§СПМЋЖШВЛОљдШ,зюЛЕЧщПі
T(n)=T(n-1)+O(n)=O(n2) зЂ:T(n-1)ОЭЪЧвЛжжЗЧГЃВЛОљдШЕФЧщПі,УПвЛДЮЪ§ОнЖМБЛЗжЕНвЛБп,дђашвЊЗжn-1ДЮЁЃ
Жў.ЯЃЖћХХађ
1.ЯЃЖћХХађЕФдРэ
🤑 1959ФъгЩЬЦФЩЕТЁЄЯЃЖћ(Donald Shell)ЬсГі
👏ЯЃЖћХХађАбађСаПДзїЪЧвЛИіОиеѓ,ЗжГЩ 𝑛 Са,ж№СаНјааХХађ
?𝑛 ДгФГИіећЪ§ж№НЅМѕЮЊ1
?ЕБ 𝑛 ЮЊ1ЪБ,ећИіађСаНЋЭъШЋгаађ
? вђДЫ,ЯЃЖћХХађвВБЛГЦЮЊЕнМѕдіСПХХађ(Diminishing Increment Sort)
? ОиеѓЕФСаЪ§ШЁОігкВНГЄађСа(step sequence)
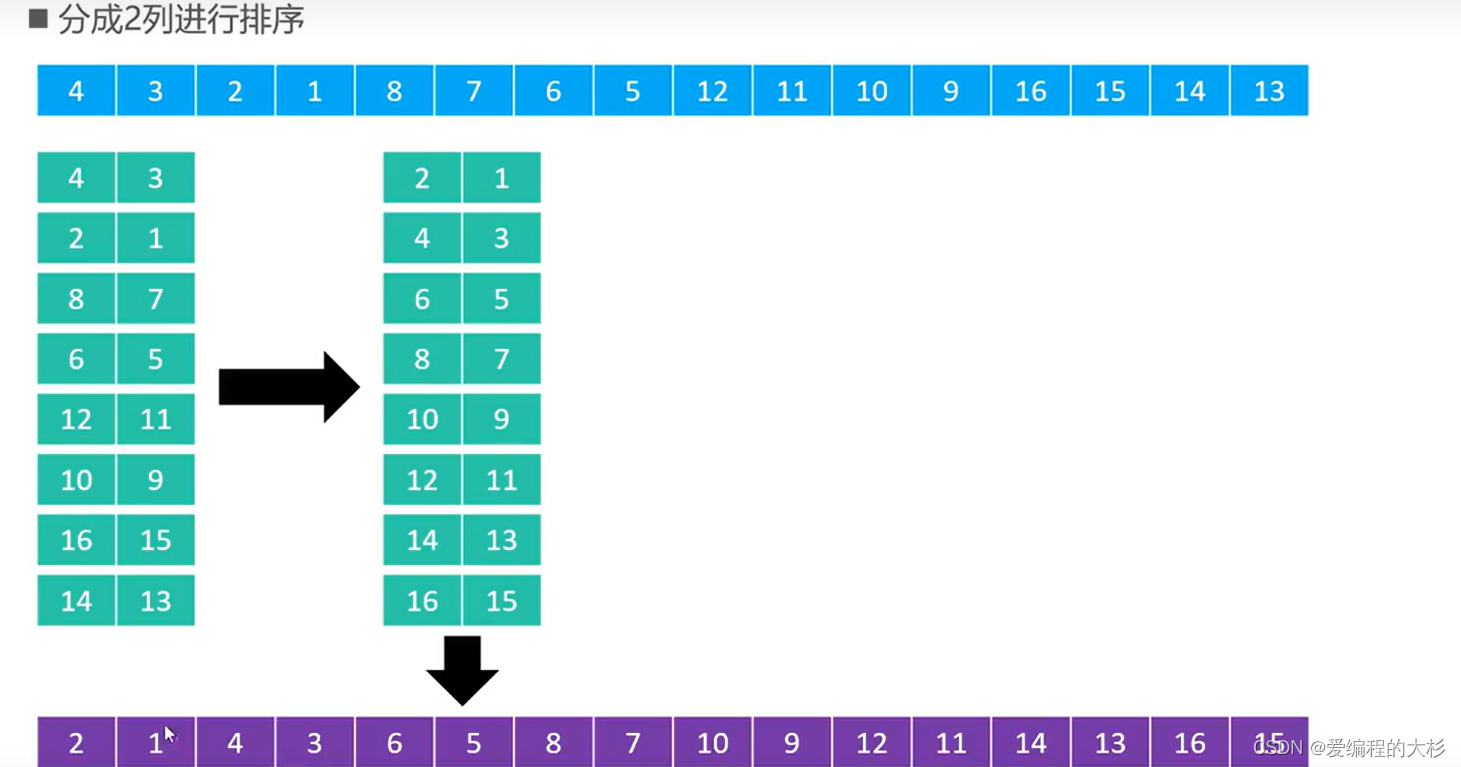
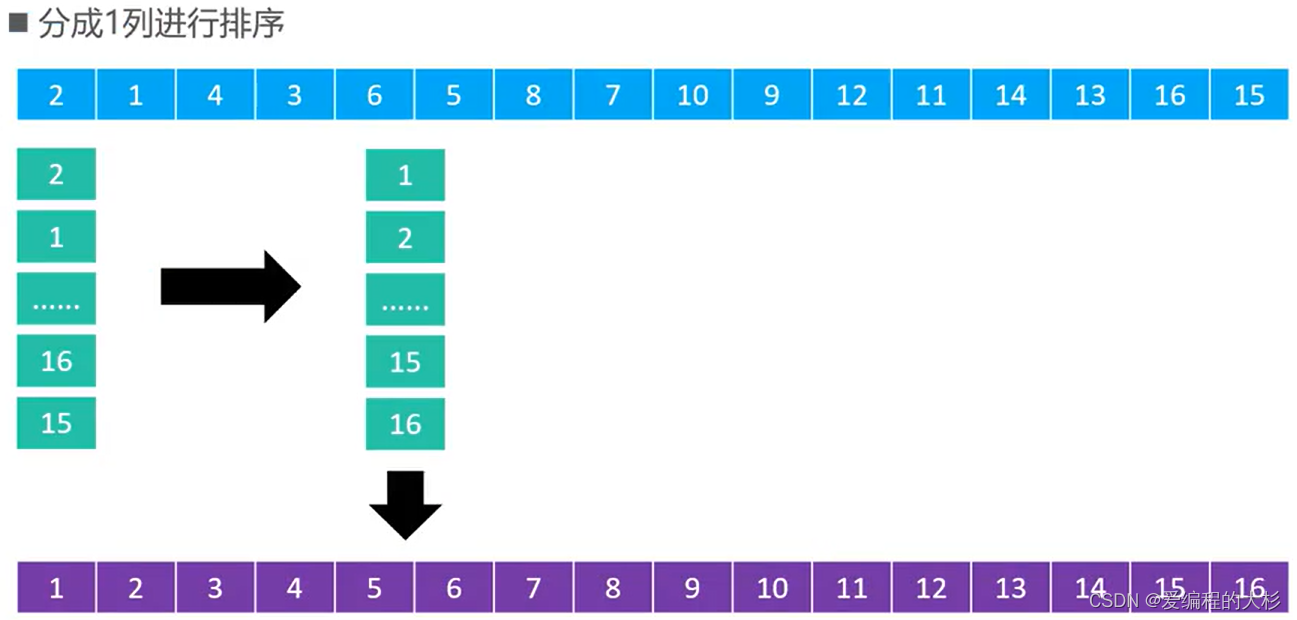
😂 БШШч,ШчЙћВНГЄађСаЮЊ{1,5,19,41,109,Ё},ОЭДњБэвРДЮЗжГЩ109СаЁЂ41СаЁЂ19СаЁЂ5СаЁЂ1СаНјааХХађ
2.ЯЃЖћХХађЪЕР§ЗжЮі
ЩЯУцЕФМђЕЅа№ЪіПЩФмЛЙВЛФмЙЛГфЗжРэНтЯЃЖћХХађЕФдРэ;УцЮвУЧЭЈЙ§МИИіЪЕР§НјааЬНОП
ЪЕР§:
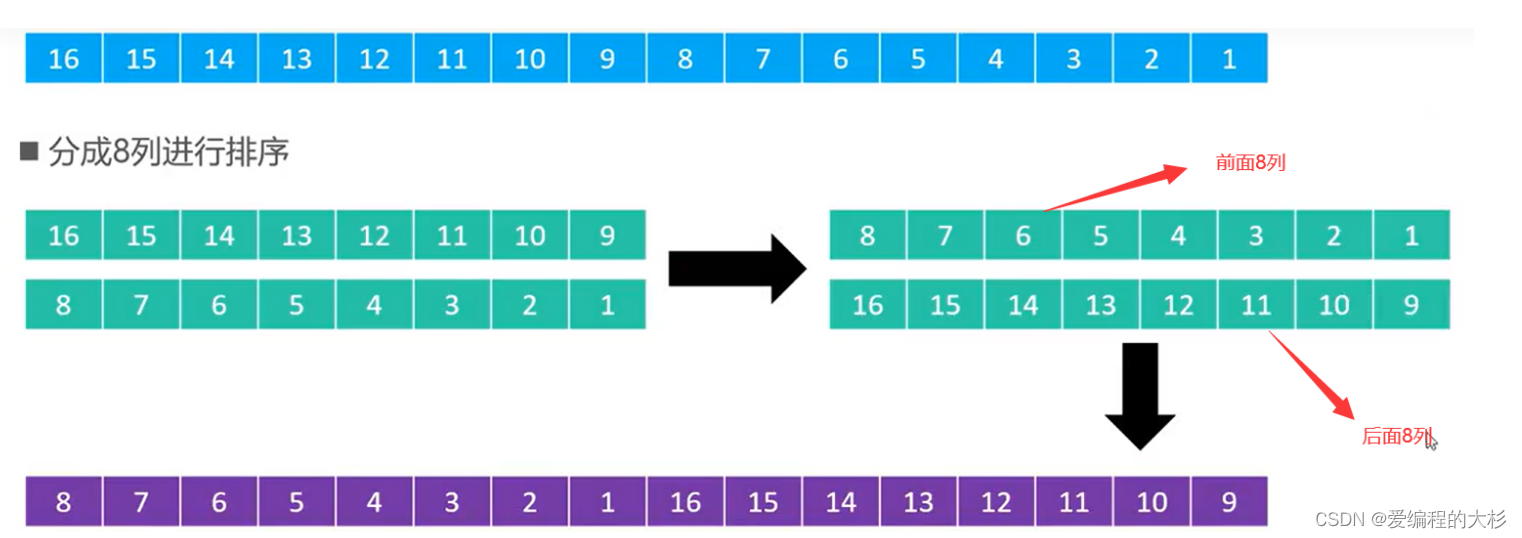
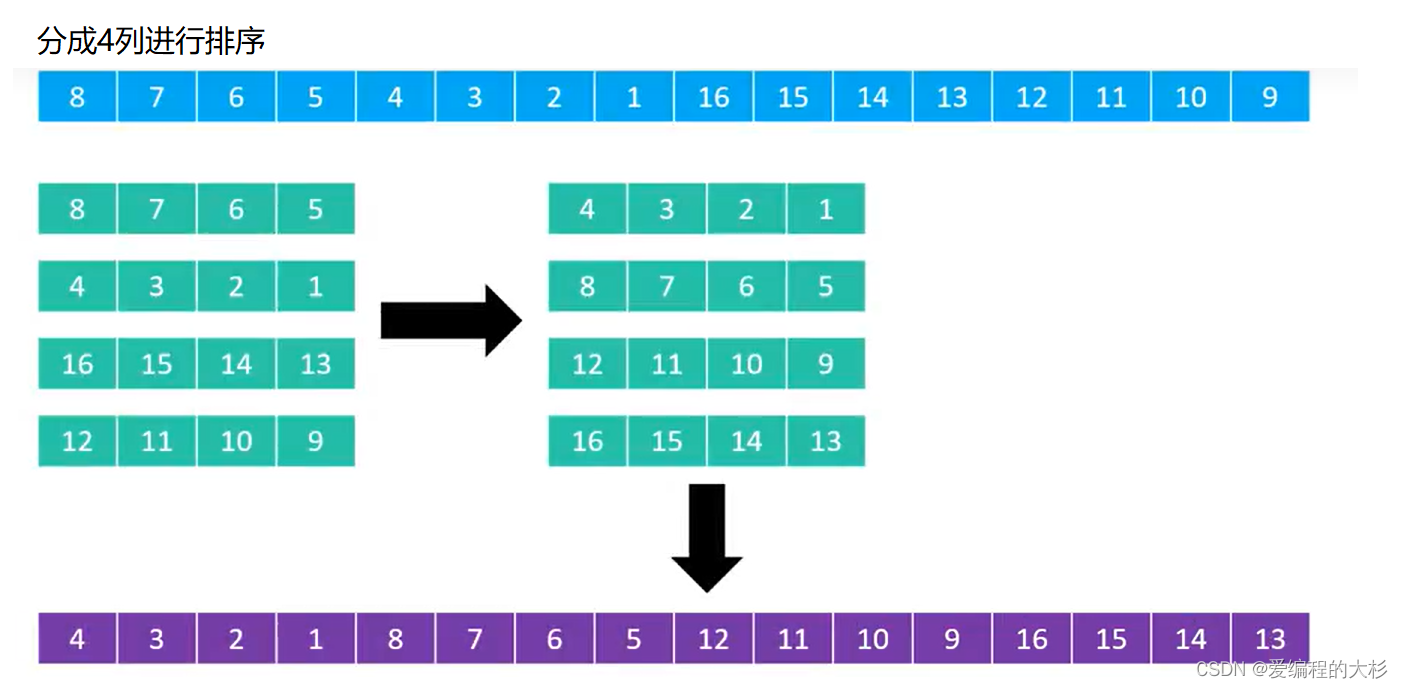
ЯЃЖћБОШЫИјГіЗЂВНГЄађСаЮЊn/2k,БШШчnЮЊ16ЪБВЙГЅађСаОЭЪЧ{8,4,2,1}
НЋЪ§зщПДГЩОиеѓ,АДСаВЛЖЯНјааХХађ
4.ДњТыЪЕЯж
public class ShellSort <E extends Comparable<E>> extends Sort<E>{
/**
* ЯЃЖћХХађОЭЪЧРћгУВНГЄађСа,НЋЪ§зщЪгЮЊОиеѓШЛКѓНјааВЛЖЯЕФСаХХађ
*/
@Override
public void sort() {
//ЛёШЁВНГЄађСа
List<Integer> stepSequence=shellStepSequence();
//ИљОнВНГЄађСаНјааЗжИюХХађ
for(int step:stepSequence){
sort(step);
}
}
private List<Integer> shellStepSequence() {
//НЋУПДЮЖўЗжГЄЖШзїЮЊВНГЄађСаЕФдЊЫи
List<Integer> stepSequence = new ArrayList<>();
int step = array.length;
while ((step >>= 1) > 0) {
stepSequence.add(step);
}
return stepSequence;
}
//РћгУВхШыХХађЕФХХађЕФдРэЖдЪ§зщОиеѓЕФСаНјааХХађ
private void sort(int step){
//col :Са
for(int col=0;col<step;col++)//ЖдЕкМИСаНјааХХађ
{
for(int begin=col+step;begin<array.length;begin+=step)
{
//вЛЖЈвЊзЂвтетРяЪЧ
E cur=array[begin];
while(begin>col&&com(cur,array[begin-step])<0){
swap(begin,begin-step);
begin-=step;
}
}
}
}
}
