Part 06-Hash Tables
An unordered associative array that maps keys to values.
Use hash function to compute an offset into the array for a given key.
Space Complexity: O ( n ) O(n) O(n)
Operation Complexity (look up)
- Average: O ( 1 ) O(1) O(1)
- Worst: O(n)
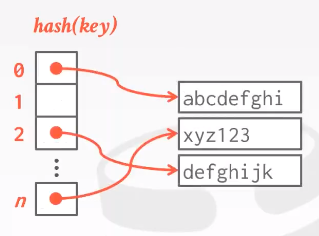
Static Hash Table
不需要在table里面保存原始的Key值,只需要保存指向这些key所在位置的指针。Like Table Index.
Assumptions
这种简单的hash table需要假设
- Each key is unique.
- You know the number of elements ahead of time
- Perfect hash function: if key_1 != key_2, then hash(key_1) != hash(key_2)
Hash Table
Design Decision
A trade-off between memory and compute
Hash Function
map a large key space -> a smaller domain, 整数

XXhash是坠吊的。
Hash Scheme
来处理碰撞。
Static Hashing Schemes
hash schemes处理的事情是:当hash完了得到值之后跳转到指定位置之后再进行的。
Static hashing意味着当我们分配内存时,我们一开始就知道我们希望保存的Key的数量。 hash的double或者说扩容代价很高,静态方法需要知道所需的容量。
Linear Probe Hashing
线性探查或者open addressing(开地址法),插入的时候如果不是空的slot就继续往下扫描,直到找到空的slot。
Handle Delete
- Tombstone 墓碑标志,逻辑上这个slot是空的,物理上这个slot是占用的
- Movement
在实际情况下,如何预测我们需要多少个slot呢?
answer is 2n,n 是 key的数量。或者n。
Robin Hood Hashing

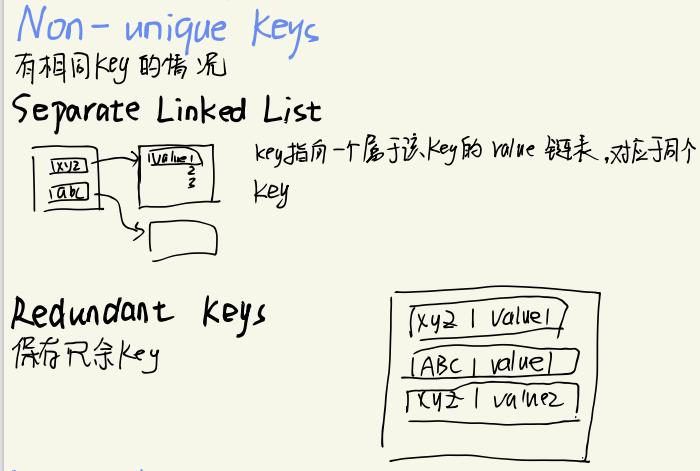
Cuckoo Hashing

Dynamic Hash Table
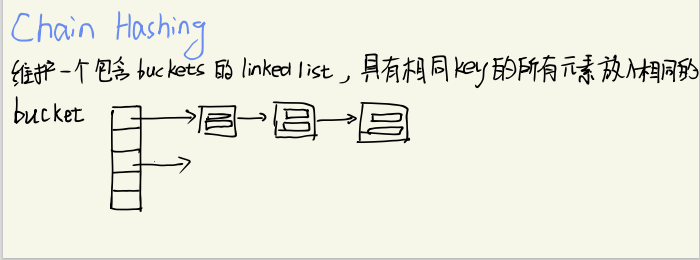
Chain Hashing
Extendible Hashing
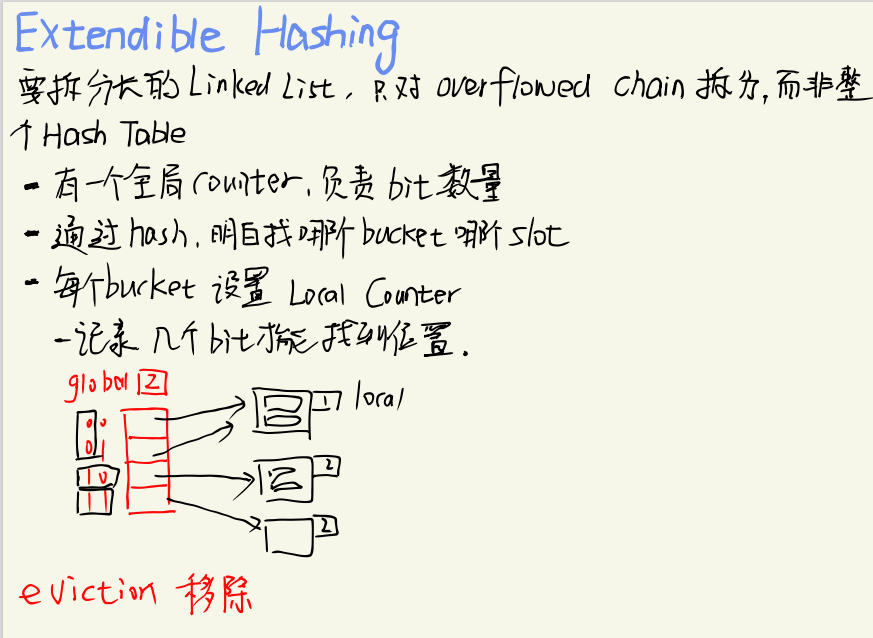
Linear Hashing

工作方式:维护多个hash函数,相同的function但是不同的seed
- 维护split pointer来跟踪下一个我们想去分割的溢出的page
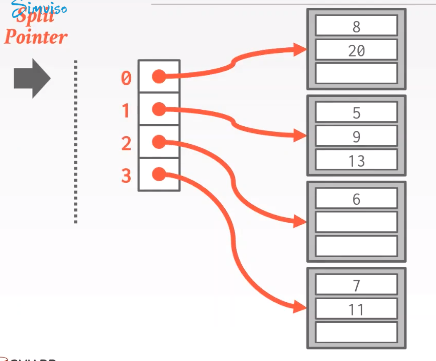
不管溢出的是不是bucket 0,都会拆分bucket 0,因为要拆分的是split pointer所指向的位置。
左侧是slot array 右侧是bucket
h a s h 1 ( k e y ) = k e y % n hash_1(key) = key \%n hash1?(key)=key%n
插入17,导致bucket 1 overflow了,首先在slot array增加一个entry,有一个新的hash函数, k e y % 2 n key \% 2n key%2n,这是split pointer可以来区分我们要使用第一个hash还是第二个hash函数,
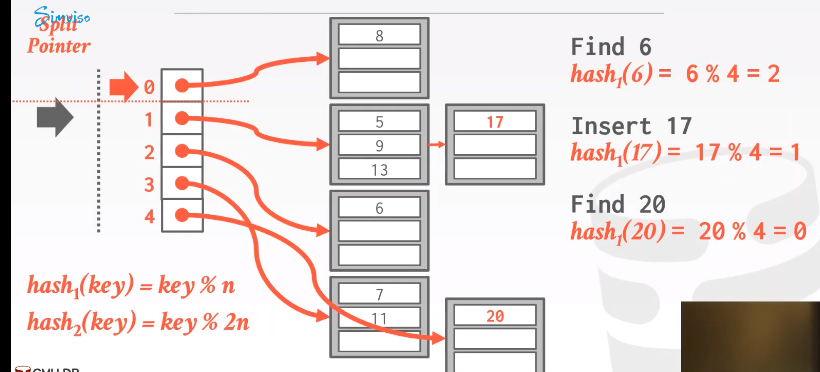
find 20
hash_1(20) = 0,在pointer上面,直到那个bucket以及被拆分了
使用第二个hash,hash_2(20) = 4
Delete操作
删除20,找到后可以把空page放在那,如果做内存回收,就是把插入反着做一遍。
如果删除6,只能把空bucket放在那.