����Ŀ¼:
ͼ�Ļ�������
ͼ(Graph)�����������Ϲ���,һ���Ƿǿյ����Ķ��㼯��V,��һ������������֮���ϵ ----- �ߵļ���E(������?)��ͼ���Ա�ʾΪ G=(V,E)��ÿ������һ�����(v,w)�� v,w��V��ͨ���� |V| ��ʾ���������,�� |E| ��ʾ�ߵ�������
🚀ͼ���ɶ��㼯�ϼ������Ĺ�ϵ��ɵ�һ�����ݽṹ:G = (V,E),����:���㼯�� V = {x|x ����ij�����ݶ���} ������ǿռ���;E = {(x,y)| x,y����V && Path(x,y)} �Ƕ�����ϵ�������,Ҳ�����ߵļ��ϡ�
(x,y) ��ʾ x �� y ��һ��˫��ͨ·,�� (x,y) �������;Path(x,y) ��ʾ�� x �� y ��һ����ͨ·,�� Path(x,y) ���з���ġ�
ͼ���������:
����ͱ�: ͼ�н���Ϊ����,�� i �������Ϊ vi���������� vi �� vj ������������� vi �Ͷ��� vj ֮����һ����,ͼ�еĵ� k ������ ek,ek = (vi,vj) �� <vi,vj>��
����ͼ������ͼ: ������ͼ��,�����<x, y>�������,�����<x,y>��Ϊ���� x ������ y ��һ��
��(��),<x, y>��<y, x>��������ͬ�ı�,������ͼ G3 �� G4 Ϊ����ͼ��������ͼ��,�����(x, y)
�������,�����(x,y)��Ϊ���� x �Ͷ��� y �������һ����,������û���ض�����,(x, y)��(y,x)
��ͬһ����,������ͼ G1 �� G2 Ϊ����ͼ��ע��:�����(x, y)���������<x, y>��<y, x>��
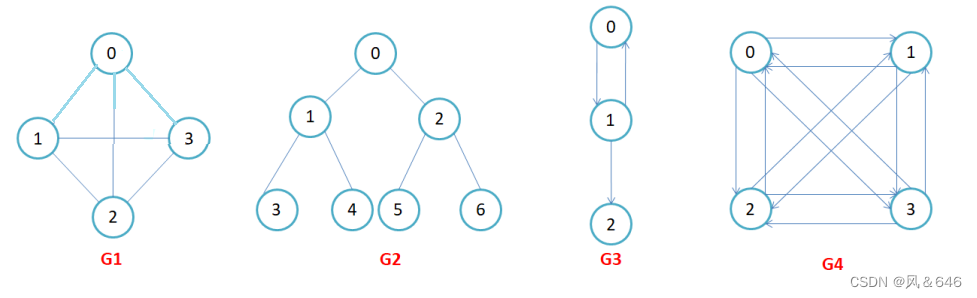
��ȫͼ: ���� n �����������ͼ��,���� n*(n-1)/2 ����,��������������֮�����ҽ���һ����,��ƴ�ͼΪ������ȫͼ,����ͼ G1;�� n �����������ͼ��,���� n*(n-1) ����,��������������֮�����ҽ��з����෴�ı�,��ͼ��Ϊ������ȫͼ,����ͼ G4��
�ڽӶ���: ������ͼ G ��,�� (u,v) �� E(G) �е�һ����,��� u �� v ��Ϊ�ڽӶ���,���Ʊ� (u,v) �����ڶ��� u �� v;������ͼ G ��,��<u,v> �� E(G) �е�һ����,��ƶ��� u �ڽӵ� v,���� v �ڽ��Զ��� u,����<u,v>�붥�� u �Ͷ��� v �������
����Ķ�: ���� v �Ķ���ָ����������ıߵ�����,����deg(v)��������ͼ��,����Ķȵ��ڸö������������֮��,���ж��� v ��������� v Ϊ�յ������ߵ�����,���� indev(v) ;���� v �ij������� v Ϊ��ʼ�������ߵ�����,���� outdev(v)�����:dev(v) = indev(v) + outdev(v)��ע��:��������ͼ,����Ķȵ��ڸö������Ⱥͳ���,�� dev(v) = indev(v) = outdev(v)��
·��: ��ͼ G = (V, E) ��,���Ӷ��� vi ������һ���ʹ��ɵ��ﶥ�� vj,��ƶ��� vi ������ vj �Ķ�������Ϊ�Ӷ��� vi ������ vj ��·����
·������: ���ڲ���Ȩ��ͼ,һ��·����·��������ָ��·���ϵıߵ�����;���ڴ�Ȩ��ͼ,һ
��·����·��������ָ��·���ϸ�����Ȩֵ���ܺ͡�
��·�����·: ��·���ϸ����� v1,v2,v3,��,vm �����ظ�,���������·��Ϊ��·
������·���ϵ�һ������ v1 �����һ������ vm �غ�,���������·��Ϊ��·��
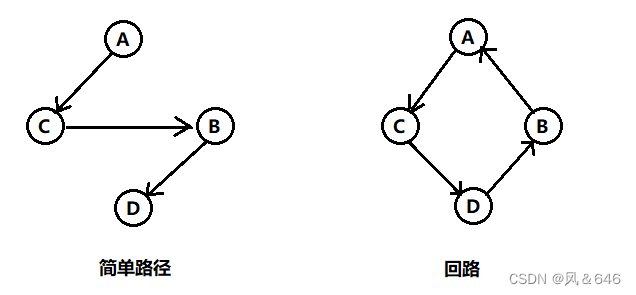
��ͼ: ��ͼG = {V, E}��ͼG1 = {V1,E1},��V1����V��E1����E,���G1��G����ͼ��
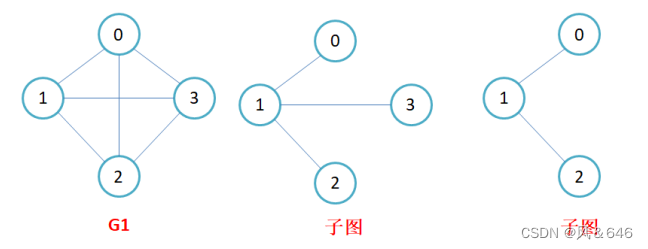
��ͨͼ: ������ͼ��,���Ӷ��� v1 ������ v2 ��·��,��ƶ��� v1 �붥�� v2 ����ͨ�ġ���ͼ������һ�Զ��㶼����ͨ��,��ƴ�ͼΪ��ͨͼ��
ǿ��ͨͼ: ������ͼ��,����ÿһ�Զ��� vi �� vj ֮�䶼����һ���� vi �� vj ��·��,Ҳ����һ���� vj �� vi ��·��,��ƴ�ͼ��ǿ��ͨͼ��
������: ������ͼ��,һ����ͨͼ����С��ͨ��ͼ������ͼ������������ n ���������ͨͼ���������� n ������� n-1 ���ߡ�
ͼ�Ĵ洢�ṹ
ͼ��һ�ֽṹ���ӵ����ݽṹ,��Ҫ�������������ⶥ��֮�䶼���Դ����ض���ϵ����ͼ�Ķ����֪,һ��ͼ����Ϣ����������,��ͼ�ж������Ϣ�Լ���������֮��Ĺ�ϵ ---- ��������Ϣ��������۲���ʲô��������ͼ�Ĵ洢�ṹ,��Ҫ������ȷ�ط�ӳ�����������Ϣ������������ֳ��õ�ͼ�Ĵ洢�ṹ��
�ڽӾ���
��Ϊ�ڵ���ڵ�֮��Ĺ�ϵ������ͨ���,��Ϊ 0 ���� 1,����ڽӾ���(��ά����)����:����һ�����齫���㱣��,Ȼ����þ�������ʾ�ڵ���ڵ�֮��Ĺ�ϵ��
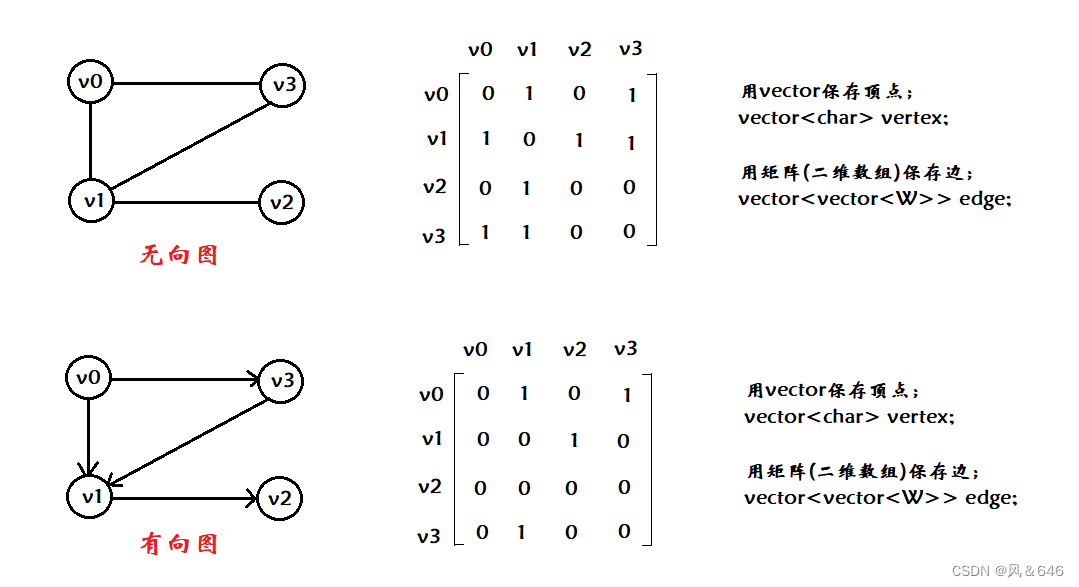
- ����ͼ���ڽӾ����ǶԳƵ�,�� i ��(��)Ԫ��֮�;��Ƕ��� i �Ķȡ�����ͼ���ڽӾ���һ���ǶԳƵ�,�� i ��(��)Ԫ��֮����Ƕ��� i �ij�(��)�ȡ�
- ���ߴ���Ȩֵ,���������ڵ�֮������ͨ��,��ͼ�еĹ�ϵ����Ȩֵ����,���������㲻��ͨ,��ʹ������������
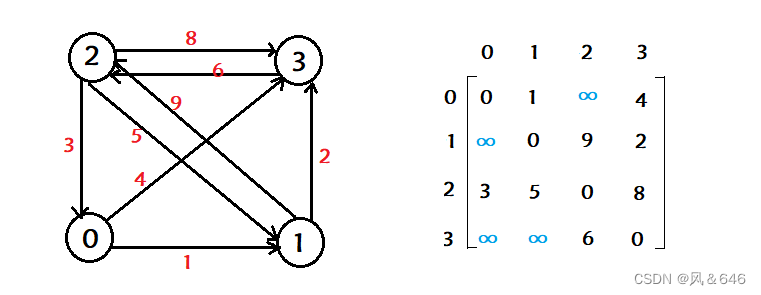
- �ڽӾ���洢ͼ���ŵ����ܹ�����֪��ͼ�����������Ƿ���ͨ,ȱ���Ƕ���ܶ��ұ߱Ƚ���ʱ,�Ƚ��˷ѿռ�,���������ڵ�֮���·����������Ҫȷ��ͼ���ж�������,��Ҫ����һ���ڽӾ���,�ռ临�Ӷ�Ϊ O(N^2) ���������ڽӾ������洢ͼ�ľ����ԡ�
�ڽӾ����ʵ��
�ڽӾ����ʾ���Ľṹ����������
�ڽӾ����ʵ�ֽṹ����Ҫ�� vector �洢��������,�Լ��� map �洢���������Ӧ���±�,������ҡ��ڽӾ�����һ����ά����,����ʹ�� vector ����Ƕ�ķ�ʽʵ�֡��ṹ��ģ������ĺ���:V - ����,W - Ȩֵ,MAX_W - ���ֵ(Ĭ�ϲ��������ε����ֵ),Direction - ��ʾͼ�Ƿ��з���
namespace matrix
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph
{
typedef Graph<V, W, MAX_W, Direction> Self;
public:
private:
vector<V> _vertexs; // ���㼯��
map<V, size_t> _indexMap; // ����ӳ���±�
vector<vector<W>> _matrix; // �ڽӾ���
};
}
���캯��
���캯����ҪΪ�洢��������鿪�ö�Ӧ�Ŀռ䲢������洢��ȥ��map �н����ö������±�֮���ӳ���ϵ,���ڽӾ����ʼ����
Graph() = default;
Graph(const V* a, size_t n)
{
// Ϊ�洢��������鿪�ÿռ�
_vertexs.reserve(n);
for (size_t i = 0;i < n;++i)
{
// �����������ֵ�洢��vector��
_vertexs.push_back(a[i]);
// �������е�ÿһ������ӳ��һ���±�
_indexMap[a[i]] = i;
}
// Ϊ�ڽӾ��ÿռ䲢��ʼ��,MAX_W��Ϊ�����ڱߵı�ʶֵ
_matrix.resize(n);
for (size_t i = 0;i < _martix.size();++i)
{
_matrix[i].resize(n, MAX_W);
}
// ������ĶԽ��߳�ʼ��Ϊ0
for (size_t i = 0;i < _matrix.size();++i)
{
for (size_t j = 0;j < _matrix[i].size();++j)
{
if (i == j)
_matrix[i][j] = 0;
}
}
}
������߶����±깹���ڽӾ���
// ���ض����±�
size_t GetVertexIndex(const V& v)
{
// �жϴ˶����Ƿ����
auto it = _indexMap.find(v);
if (it != _indexMap.end()) // ���ڴ˶���,�������±�
return it->second;
else // �����ڴ˶���,���׳��쳣
{
throw invalid_argument("�����ڵĶ���");
return -1;
}
}
// ͨ������ͱ߹����ڽӾ���
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
_AddEdge(srci, dsti, w);
}
// ͨ�������±깹���ڽӾ���
_AddEdge(size_t srci, size_t dsti, const W& w)
{
_matrix[srci][dsti] = w;
// ����ͼ����
if (Direction == false)
{
_matrix[dsti][srci] = w;
}
}
��ӡ����
Ϊ�˷����������д�Ĵ����Ƿ���ȷ,���Դ�ӡ�������Լ�������ߵĹ�ϵ����֤,��������������ֱ�ۡ���ӡ�ĸ�ʽ������Ҫ�������ơ�
void Print()
{
// ��ӡ������±���ӳ���ϵ
for (size_t i = 0;i < _vertexs.size();++i)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
// ��ӡ���������
cout << " ";
for (size_t i = 0;i < _vertexs.size();++i)
{
printf("%5d", i);
}
cout << endl;
// ��ӡ����
for (size_t i = 0;i < _matrix.size();++i)
{
cout << i << " "; // ��ӡ����������
for (size_t j = 0;j < _matrix[i].size();++j)
{
if (_matrix[i][j] == MAX_W)
printf("%5c", '*');
else
printf("%5d", _matrix[i][j]);
}
cout << endl;
}
cout << endl;
// ��ӡ���еı�
for (size_t i = 0;i < _matrix.size();++i)
{
for (size_t j = 0;j < _matrix[i].size();++j)
{
if (i < j && _matrix[i][j] != MAX_W)
cout << _vertexs[i] << "->" << _vertexs[j] << ":" << _matrix[i][j] << endl;
}
}
}
�ڽӱ�
�ڽӱ�(Adjacency Lists)��ͼ��һ��˳��洢����ʽ�洢��ϵĴ洢�������ڽӱ���ʾ�����Ƕ���ͼ G �е�ÿ������ vi,�������ڽ��� vi �Ķ��� vj ����һ��������,�����������Ϊ���� vi ���ڽӱ�,Ȼ�����е���ڽӱ���ͷ����һ��������,������ͼ���ڽӱ���
�ڽӱ�:ʹ�������ʾ����ļ���,ʹ��������ʾ�ߵĹ�ϵ��
����ͼ�ڽӱ��洢:

ע��:
- ����ͼ��ͬһ�������ڽӱ��г��������Ρ�����֪������ vi �Ķ�,ֻ��Ҫ֪������ vi �����������н�����Ŀ���ɡ�
- ��������ͼ�洢���ڽӱ���,���Դ�һ�����߱���һ����߱�,����ʵ��������һ��ֻ��Ҫ�洢���߱����ɡ�
- ����ͼ��ÿ�������ڽӱ���ֻ����һ��,�붥�� vi ��Ӧ���ڽӱ��������ĸ���,���Ǹö���ij���,Ҳ��Ϊ���ȱ�,Ҫ�õ����� vi �����,��Ҫ����������ж����Ӧ�ı�����,����ж��ٱ߶���� dst ȡֵ�� i ��
- ���ڽӱ�����Ҫ�洢Ȩֵ,����ֻ��Ҫ�ڴ洢���������һ���洢Ȩֵ�ı������ɡ�
�ڽӱ�ʵ��
namespace link_table
{
template<class W>
struct Edge
{
size_t _dsti; // Ŀ����±�
W _w; // Ȩֵ
Edge<W>* _next;
Edge(size_t dsti,const W& w)
:_dsti(dsti)
,_w(w)
,_next(nullptr)
{}
};
template<class V, class W, bool Dircetion = false >
class Graph
{
typedef Edge<W> Edge;
public:
Graph(const V* a, size_t n)
{
_vertexs.reserve(n);
for (size_t i = 0;i < n;++i)
{
_vertexs.push_back(a[i]);
_indexMap[a[i]] = i;
}
_tables.resize(n, nullptr);
}
// ��ȡ�����±�
size_t GetVertexIndex(const V& v)
{
auto it = _indexMap.find(v);
if (it != _indexMap.end())
return it->second;
else
{
throw invalid_argument("�����ڴ˶���");
return -1;
}
}
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
// ��������ͷ��ķ�ʽ���½ڵ��������
Edge* eg = new Edge(dsti, w);
eg->_next = _tables[srci];
_tables[srci] = eg;
// ����ͼ����
if (Dircetion == false)
{
Edge* eg = new Edge(srci, w);
eg->_next = _tables[dsti];
_tables[dsti] = eg;
}
}
void Print()
{
// ��ӡ����
for (size_t i = 0;i < _vertexs.size();++i)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
for (size_t i = 0;i < _tables.size();++i)
{
// ������ǰ����,����ӡ��������е������Ϣ
cout << _vertexs[i] << "[" << i << "]->";
Edge* cur = _tables[i];
while (cur)
{
cout << "[" << _vertexs[cur->_dsti] << ":" << cur->_dsti << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
private:
vector<V> _vertexs; // ���㼯��
map<V, size_t> _indexMap; // ����ӳ����±�
vector<Edge*> _tables; // �ڽӱ�
};
}
ͼ�ı���
����һ��ͼ G �����е�����һ������ v0,�� v0 ����,����ͼ�и��߷���ͼ�е����ж���,��ÿ�������������һ�Ρ�ͼ�ı������������ı����������ơ�ͼ�ı�����ͼ��һ�ֻ�������,ͼ�����������������ǽ����ڱ����Ļ���֮�ϡ����ǿ���ʹ�� O(V+E)DFS(�����������)�� BFS(�����������)�㷨��������ͼ��̽��ͼ������/���ԡ�ÿ���㷨�����Լ����ص㡢���������á�
ͼ�Ĺ����������(BFS)
�����������(Breadth First Search)��� BFS,�DZ���ͼ�洢�ṹ��һ���㷨,������������ͼ,Ҳ����������ͼ��
����ͨ��һ������,��ʾһ�¹�����������㷨�����ʵ��ͼ�ı�����:

˼·:
- ʹ��һ����������Ǹ��������״̬,�������� false �� true ����״̬,false ��ʾ�ö��㻹δ�����,true ��ʾ�ö����Ѿ���������ˡ�ÿ�����������ʱ,�ͽ��ö�����Ϊ true,��ֹ�ظ����ʡ�
- һ�����������ʱ,�ͽ��ö����δ����е��ڽӶ���������,����������еĶ����״̬��Ϊ true��
- ����Ϊ��ʱ,����ͼ�Ѿ�������ϡ�
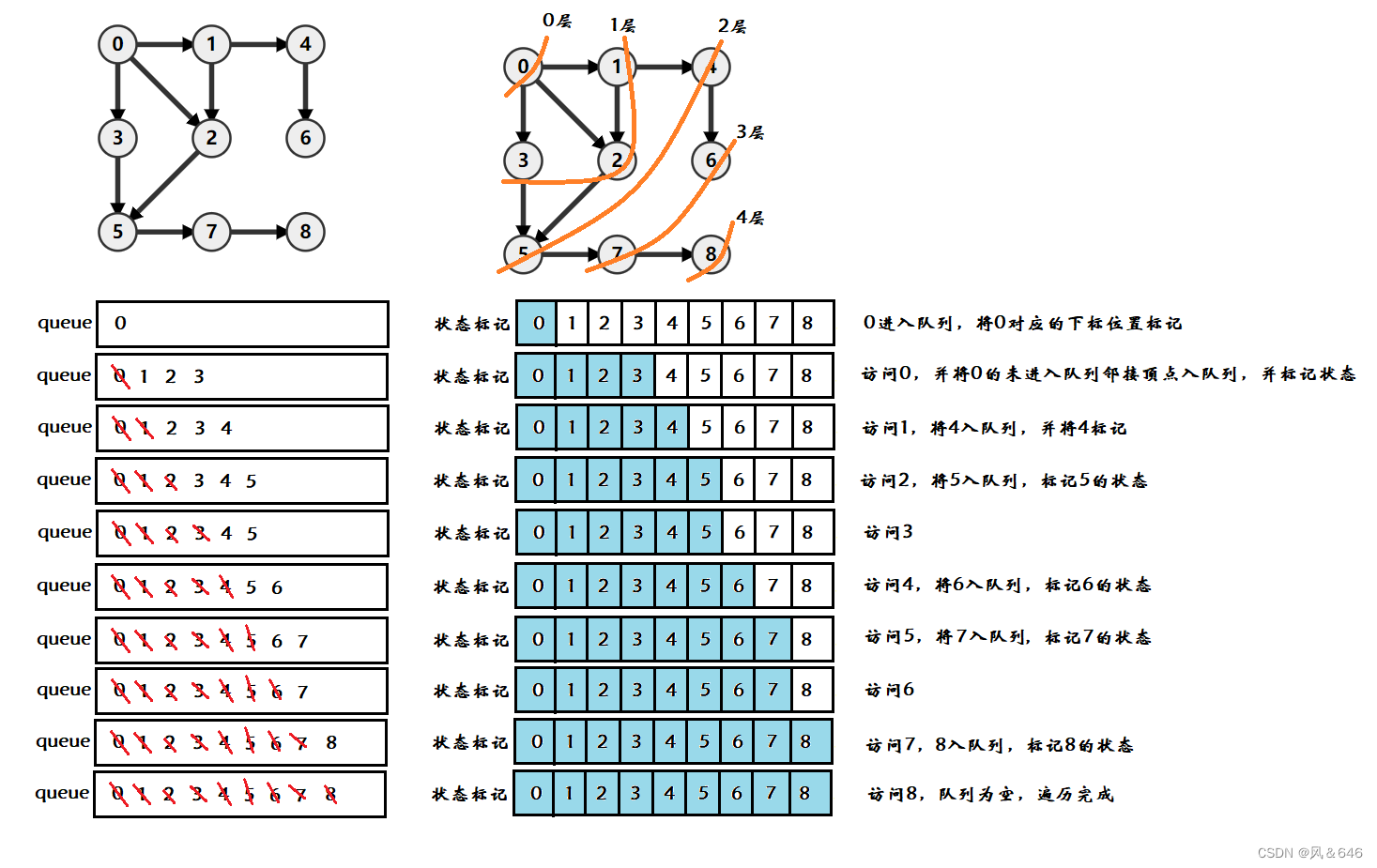
BFS����: ���д������ʱ����һ��һ������ķ�ʽ
void BFS(const V& src)
{
// ��ȡ��ʼ�����±�
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
// ���кͱ������,ʹ��false���г�ʼ��
queue<int> q;
vector<bool> visited(n, false);
// ���Ƚ���ʼ���������,������״̬��Ϊtrue
q.push(srci);
visited[srci] = true;
int levelSize = 1;
int count = 0;
// ������,���������
while (!q.empty())
{
cout << "��" << count++ << "��: ";
for (size_t k = 0;k < levelSize;++k)
{
// ���ʶ�ͷԪ�ز�����Ӷ�����ɾ��
int front = q.front();
q.pop();
cout << "[" << front << "]" << _vertexs[front] << " ";
// ���ö���δ���ʹ����ڽӶ��������,�������״̬
for (size_t i = 0;i < n;++i)
{
if (_matrix[front][i] != MAX_W && visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
levelSize = q.size();
cout << endl;
}
}
ͼ�������������(DFS)
�����������(Depth First Search)��� DFS,�DZ���ͼ�洢�ṹ��һ���㷨,������������ͼ,Ҳ����������ͼ��
����ͨ��һ������,��ʾһ��������������㷨�����ʵ��ͼ�ı�����:

˼·:
- ʹ��һ��״̬�������,�������� false �� true ����״̬,false ��ʾ�ö���δ���ʹ�,true ��ʾ�ö����Ѿ����ʹ���,û����һ������,�ͽ�״̬���������±��Ӧ��λ�ñ��Ϊ true��
- ʹ�õݹ�ķ�ʽ������ȱ�����
DFS����:
void _DFS(size_t srci, vector<bool>& visited)
{
// ���ʴ˶���Ԫ��,������״̬��Ϊtrue
cout << "[" << srci << "]" << _vertexs[srci] << " ";
visited[srci] = true;
// ��һ��srci��δ���ʹ����ڽӶ���ȥ����ȱ���
for (size_t i = 0;i < _vertexs.size();++i)
{
if (_matrix[srci][i] != MAX_W && visited[i] == false)
{
_DFS(i, visited);
}
}
}
void DFS(const V& src)
{
// ��ȡ��ʼ�����±�,���úñ������
size_t srci = GetVertexIndex(src);
vector<bool> visited(_vertexs.size(), false);
// �����Ӻ���,���еݹ����
_DFS(srci, visited);
}
ͼ�ı���������Ӧ��,��������ͨ������ŷ����·����������DAG���ж���DAG�ĸ����űߡ��ؽڵ�ȵļ��㶼����ͨ�����������С�
��������
һ����ͨ������Ȩͼ G �������� Spanning Tree(ST)�� G ����ͼ,ͬʱҲ��һ������ G �����нڵ������һ��ͼ G �����кܶ��������,��ÿһ�����в�ͬ����Ȩ��(�����������бߵ�Ȩ��֮��)��ͼ G ����С������ Min(imum) Spanning Tree(MST)�������е���������,������С��Ȩ�ص���������
��ͨͼ�е�ÿһ��������,����ԭͼ��һ����������ͼ,��:������ɾȥ�κ�һ����,�������Ͳ���ͨ��;��֮,�����������κ�һ���±�,�����γ�һ����·��
����ͨͼ�� n ���������,�������������� n ������� n-1 ���ߡ���˹�����С������������������:
- ֻ��ʹ��ͼ�еı���������С������
- ֻ��ʹ�� n-1 ��������ͨͼ�е� n ������
- ѡ�� n-1 ���߲��ܹ��ɻ�·
������С�������ķ���:Kruskal �㷨 �� Prim �㷨�������㷨��������������̰�IJ��ԡ�
̰���㷨: ��ָ�ڶ����������ʱ,����������ǰ������ʱ��õ�ѡ��Ҳ����˵,̰���㷨�������������ϼ��Կ���,����ij�������ϵľֲ����Ž⡣̰���㷨�����Ƕ����е����ⶼ�ܵõ���������Ž⡣
��С��������ʵ���е�Ӧ��:������Ҫ�� n-1 ���߽� n ��������������,·�����ȡ���ڵ��Ρ�����ȡ�����Ҫ��С�����,Ӧ����������Щ·��?(�����һ����С����������)
Kruskal�㷨
һ�� O(E log V) ��̰����С�������㷨������չһ����С��������ɭ��,ֱ����������ϳ�һ����С��������Kruskal �㷨��Ҫһ���Ϻõ������㷨����ͼ�еı���Ȩֵ�ķǵݼ�����(ͨ���洢�ڱ��б���)�Ͳ��鼯(UFDS)���ж�/Ԥ���ɻ���
Kruskal�㷨����:
�θ�һ���� n ���������ͨ���� N={V,E},���ȹ���һ������ n ��������ɡ������καߵ�ͼ G={V,NULL},����ÿ�������Գ�һ����ͨ����,���в��ϴ� E ��ȡ��Ȩֵ��С��һ����(���ж���Ȩֵ��ȵı�,����ȡһ��),���ñߵ������������Բ�ͬ����ͨ����,�˱��뵽 G �С��ظ��˲���,ֱ�����ж�����ͬһ����ͨ������Ϊֹ��
����:ÿ�ε���ʱ,ѡ��һ��������СȨֵ,�����˵㲻��ͬһ�����ϵı�,�����������С�
��ͼ��ʹ��һ����������ʾ Kruskal �㷨:

����:��α���ѡ�߹������γɻ�?
�������:��ѡ��һ����֮��,�������˵Ķ�����벢�鼯��,�������ٴ�ѡ����֮��,������Ҫʹ�ò��鼯�жϱߵ����������Ƿ���ͬһ�����鼯��,��������,���������ӵ���С�������С�
Kruskal�㷨ʵ�ֵĺ�������������:
- ѡ��һ��Ȩֵ��С�ıߡ����Բ������ȼ�����(��С��)�����ݽṹ,Ȼ������еı߶������ȥ������ʼ�ѵ�ʱ�临�Ӷ���O(E),ɾ���Ѷ�Ԫ�غ�����һ���ѵ�ʱ�临�Ӷ�ΪO(logE),�����ܵ�ʱ�临�ӶȻ���O(ElogE)��
- �ж�һ���ߵ������Ƿ�����ͬһ����,������ɲ��鼯��������ɡ��� InSameSet(u,v) �������Խڵ� u �� v Ϊ�˵�ı� e �Ƿ�ᵼ�»�(��ͬ�����ӷ�֧ �C ����һ���� u �� v ��·,�������ӱ�(u,v)�ᵼ�³ɻ�)����� IsSameSet(u,v) Ϊ false,̰�ĵ�ѡ����һ����С�ĺϸ�� e ������ UnionSet(u,v) ��Ԥ�����ܵ���˱���صĻ���
- ��� IsSameSet(u,v) Ϊ false,̰�ĵ�ѡ����һ����С�ĺϸ�� e ������ UnionSet(u,v) ��Ԥ�����ܵ���˱���صĻ���
Kruskal�㷨����:����ʵ��ϸ�ڲο����´���
struct Edge
{
size_t _srci;
size_t _dsti;
W _w;
Edge(size_t srci,size_t dsti,const W& w)
:_srci(srci)
,_dsti(dsti)
,_w(w)
{}
bool operator>(const Edge& e)const
{
return _w > e._w;
}
};
W Kruskal(Self& minTree)
{
int n = _vertexs.size();
// ��ʼ����С������
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (size_t i = 0;i < n;++i)
{
minTree._matrix[i].resize(n, MAX_W);
}
// ��ͼ�еĸ��������ӵ����ȼ�������
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
if (i < j && _matrix[i][j] != MAX_W)
{
minque.push(Edge(i, j, _matrix[i][j]));
}
}
}
// ѡ�� n-1 ����
int size = 0;
// ����ͳ��ѡ���ߵ�Ȩ��֮��
W totalW = W();
// ʹ�ò��鼯���ж��Ƿ�ɻ�
UnionFindSet ufs(n);
while (!minque.empty())
{
//ȡ�����ȼ����еĶ�ͷԪ��
Edge min = minque.top();
minque.pop();
// �ò��鼯�����ѡ���ı��Ƿɻ�
if (!ufs.InSameSet(min._srci, min._dsti))
{
//cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
// ���ı����ӵ���С��������
minTree._AddEdge(min._srci, min._dsti, min._w);
// ��ѡ��������������뵽���鼯��
ufs.Union(min._srci, min._dsti);
// ͳ��ѡ���ı�����ѡ���ߵ�Ȩֵ֮��
++size;
totalW += min._w;
}
}
// ��ѡ���ı���Ϊn-1,����Ȩ��
if (size == n - 1)
return totalW;
// û��ѡ����С������,����Ĭ��ֵ
else
return W();
}
Prim�㷨
����ķ(Prim)�㷨,�Ϳ�³˹�����㷨���ơ�һ�� O(E log V) ��̰����С�������㷨������һ����ʼ��Դ�ڵ㿪ʼ�����ŵ�����ͼ,�Ӷ�����һ����С��������Prim �㷨��Ҫʹ�����ȼ�������Ȩ�صķǵݼ���������̬����ǰ�ı�,���ڽӾ������ҵ�һ���ڵ���ڽӶ���,��һ�����������������жϻ���
��ͼ��ʹ��һ����������ʾ Prim �㷨:

Prim�㷨ʵ�ֲ���:
- ��ȡ���붥����±�,Ȼ���ʼ����С��������
- ����������������(S �� D),S ������������Ѿ���ѡ����Ķ���,D �����������ͼ��δ��ѡ��Ķ���,��������������Դ��Ĵ���״̬���¡�
- ��һ�����ȼ����н�Դ�����ӳ�ȥ�ı����ӽ�ȥ��
- �Զ����Ƿ�Ϊ������Ϊѭ��������,�����ж���������,�ж�ѡ���ı��Ƿɻ���
- ��ѡ���ı߷�������֮��,�ͽ������ӵ���С��������,Ȼ��������������иñ�Ŀ�궥��Ĵ���״̬�����ñ�Ŀ�궥�����ӳ�ȥ�ı����ӵ����ȼ�������(ѡ����Ŀ�궥������D�����д���,���������ӵ����ȼ�������)��
Prim�㷨ʵ�ִ���: ����ʵ��ϸ�ڲο�����
struct Edge
{
size_t _srci;
size_t _dsti;
W _w;
Edge(size_t srci,size_t dsti,const W& w)
:_srci(srci)
,_dsti(dsti)
,_w(w)
{}
bool operator>(const Edge& e)const
{
return _w > e._w;
}
};
W Prim(Self& minTree, const V& src)
{
// ��ȡԴ���±�
size_t srci = GetVertexIndex(src);
int n = _vertexs.size();
// ��ʼ����С������
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (size_t i = 0;i < n;++i)
{
minTree._matrix[i].resize(n, MAX_W);
}
// ����һ�����ȼ��������������,��S->D���������ӵı�����ѡ����С�ı�
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
// SΪԴ���� - ��������Ѿ���ѡ��Ķ���
// DΪĿ������ - ������ʶû�б�ѡ��Ķ���
vector<bool> S(n, false);
vector<bool> D(n, true);
S[srci] = true;
D[srci] = false;
// ��ͼ����srciΪԴ��ĸ����������ȼ�������
for (int i = 0;i < n;++i)
{
if (_matrix[srci][i] != MAX_W && i != srci)
{
minque.push(Edge(srci, i, _matrix[srci][i]));
}
}
size_t size = 0; // ������¼ѡ��ı���Ŀ
W totalW = W(); // ��¼ѡ���ıߵ���Ȩ��
while (!minque.empty())
{
Edge min = minque.top();
minque.pop();
// ��ѡ������С�ߵ�Ŀ���Ҳ�ڼ���S��,�ɻ�
if (S[min._dsti]){}
else
{
// ��ѡ���ı����ӵ���С��������
minTree._AddEdge(min._srci, min._dsti, min._w);
// ���¸ñߵ����˶��������������е�״̬
S[min._dsti] = true;
D[min._dsti] = false;
// ��������������¼������
++size;
totalW += min._w;
// ѡ���ıߴﵽҪ��,������ѭ��
if (n - 1 == size)
break;
// ��ѡ���ıߵ�Ŀ�궥��ΪԴ��ѡ�������ڽӶ��������,���ڽӶ�����D������Ϊtrue״̬
for (size_t i = 0;i < n;++i)
{
if (_matrix[min._dsti][i] != MAX_W && D[i])
{
minque.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
if (size == n - 1)
return totalW;
else
return W();
}
���·��
���·������:���ڴ�Ȩ����ͼ G �е�ijһ�������,�ҳ�һ��ͨ����һ��������·��,���Ҳ������·�����ߵ�Ȩֵ�ʹﵽ��С��
���·��������ͼ���е�һ�������㷨����,ּ��Ѱ��ͼ(�ɽ���·����ɵ�)�������֮������·�����㷨�������ʽ����:ȷ���������·������ - Ҳ�е�Դ���·������,����֪��ʼ���,�����·�������⡣�ڱ�Ȩ�Ǹ�ʱ�ʺ�ʹ�� Dijkstra �㷨,����ȨΪ��ʱ���ʺ�ʹ��Bellman - ford �㷨���� SPFA �㷨��
��Դ���·�� - Dijkstra�㷨
��Դ���·������:����һ��ͼ G = (V,E),��Դ��� s �� V ��ͼ��ÿ����� v �� V �����·����Dijkstra �㷨�������ڽ����Ȩ�ص�����ͼ�ϵĵ�Դ���·������,ͬʱ�㷨Ҫ��ͼ�����бߵ�Ȩ�طǸ���һ����������·����ʱ������֪һ������һ���յ�,����ʹ�� Dijkstra �㷨������Ҳ�͵õ���������㵽�յ�����·����
���һ����Ȩ����ͼ G ,�����н���Ϊ���� S �� Q ,S ���Ѿ�ȷ�����·���Ľ�㼯��,�ڳ�ʼʱΪ��(��ʼʱ�Ϳ��Խ�Դ�ڵ� s ����,�Ͼ�Դ�ڵ㵽���Լ���Ȩֵ��0),Q Ϊ����δȷ�����·���Ľ�㼯��,ÿ�δ� Q ���ҳ�һ����㵽�ý��Ȩֵ��С�Ľ�� u,�� u �� Q ���Ƴ�,������ S ��,�� u ��ÿһ���ڽӶ��� v �����ɳڲ������ɳڼ���ÿһ���ڽӶ��� v ,�ж�Դ�ڵ� s ����� u ��Ȩֵ�� u �� v ��Ȩֵ֮���Ƿ��ԭ�� s �� v ��Ȩֵ��С,��Ȩֵ��ԭ��С��Ҫ�� s �� v ��Ȩֵ����Ϊ s �� u �� u �� v ��Ȩֵ֮��,����ԭ�������һֱѭ��ֱ������ Q Ϊ��,�����нڵ㶼�Ѿ����ҹ�һ�鲢ȷ�������·��,����һЩ��㵽�ﲻ�˵Ľ�����㷨ѭ������Ȩֵ��Ϊ��ʼ�趨��ֵ,�������仯��Dijkstra �㷨ÿ�ζ���ѡ�� V-S ����С��·���ڵ������и���,������ S ��,���Ը��㷨ʹ�õ���̰�IJ��ԡ�
Dijkstra �㷨���ڵ������Dz�֧��ͼ�д���Ȩ·��,�����и�Ȩ·��,����ܻ��Ҳ���һЩ·�������·����
��ͼ��ʹ��һ����������ʾ Dijkstra �㷨:

�������á��㷨���ۡ��ϵİ���������һ��ʵ��Ҫ�㼰����:
- ������ vector<W> dist ����¼ srci ��������������·��Ȩֵ,���� vector<int> pPath ����¼ srci �������������·�������㡣Ȼ�����������ʼ��,�� dist �е� n �����ݳ�ʼ��Ϊ���ֵ(��Դ�� srci ��Ӧ��λ��,srci ��λ�ó�ʼ��Ϊ 0);�� pPath �е� n �����ݳ�ʼ��Ϊ -1(��Դ�� srci ��Ӧ��λ��,srci ��λ�ó�ʼ��Ϊ 0)��
- ��һ���������� S ����¼�Ѿ�ȷ�����·���Ķ��㼯�ϡ�
- ѡ��δȷ�����·���Ķ�����Ȩֵ��С����һ������,�ɳڸ��¸ýڵ����ӳ�ȥ��δȷ�����·�����ڽӶ����Ȩֵ��
- ѭ������ n �Ρ����¹�����һֱ��¼·�����顣
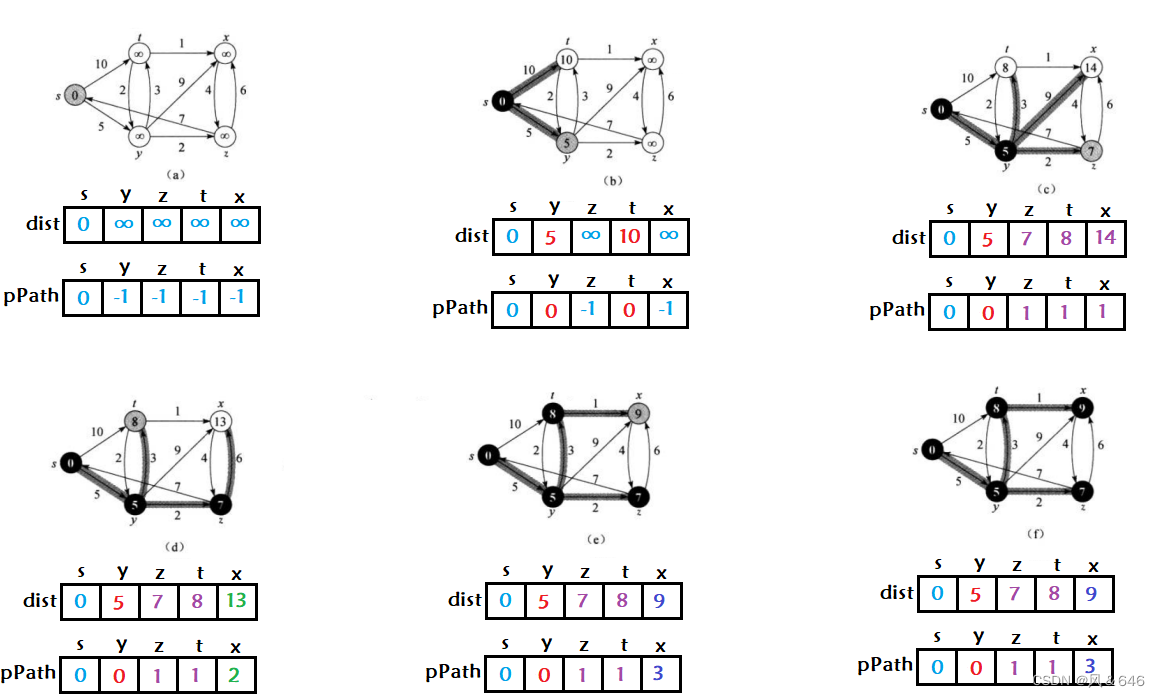
Dijkstra�㷨ʵ�ִ���:
// dist�����洢��ǰ�����Ȩֵ,pPth������¼����·��
void Dijkstra(const V& src, vector<W>& dist, vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
// vector<W> dist,��¼srci - �����������·��Ȩֵ����
dist.resize(n, MAX_W);
// vector<int> pPath,��¼srci - �����������·������������
pPath.resize(n, -1);
dist[srci] = 0;
pPath[srci] = srci;
// ����Ѿ�ȷ�����·���Ķ��㼯��
vector<bool> S(n, false);
// ѭ������n��
for (size_t k = 0;k < n;++k)
{
// ѡ���·�������Ҳ���S���ϵĶ����������·��
int u = 0;
W min = MAX_W;
for (size_t i = 0;i < n;++i)
{
if (S[i] == false && dist[i] < min)
{
u = i;
min = dist[i];
}
}
S[u] = true;
// �ɳڸ���u���ӵĶ���v,�� srci->u + u->v < srci->v ����
for (size_t v = 0;v < n;++v)
{
if (S[v] == false && _matrix[u][v] != MAX_W && dist[u] + _matrix[u][v] < dist[v])
{
dist[v] = dist[u] + _matrix[u][v];
pPath[v] = u;
}
}
}
}
// ��ӡ���·�������㷨
void PrintShortPath(const V& src, const vector<W>& dist, const vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
for (size_t i = 0;i < n;++i)
{
if (i != srci)
{
// �ҳ�i�����·��
vector<int> path;
size_t parenti = i;
while (parenti != srci)
{
path.push_back(parenti);
parenti = pPath[parenti];
}
path.push_back(srci);
reverse(path.begin(), path.end());
for (auto index : path)
{
cout << _vertexs[index] << "->";
}
cout << dist[i] << endl;
}
}
}
��Դ���·�� - Bellman-Ford�㷨
Dijkstra �㷨ֻ�����������Ȩͼ�ĵ�Դ���·������,����ijЩ����»���ָ�Ȩͼ����ʱ������㷨�Ͳ��ܰ������ǽ��������,�� Bellman-Ford �㷨���Խ����Ȩͼ�ĵ�Դ���·�����⡣�����ŵ��ǿ��Խ���и�Ȩ�ߵĵ�Դ���·������,���ҿ��������ж��Ƿ��и�Ȩ��·������ʱ�临�Ӷ� O(N*E)(N �ǵ���,E�DZ���)�ձ���Ҫ���� Dijkstra �㷨 O(N^2) �ġ�����������ʹ���ڽӾ���ʵ��,��ô�������бߵ�������ʱ�临�ӶȾ��� O(N^3),������Կ������㷨����һ�ֱ��������¡�
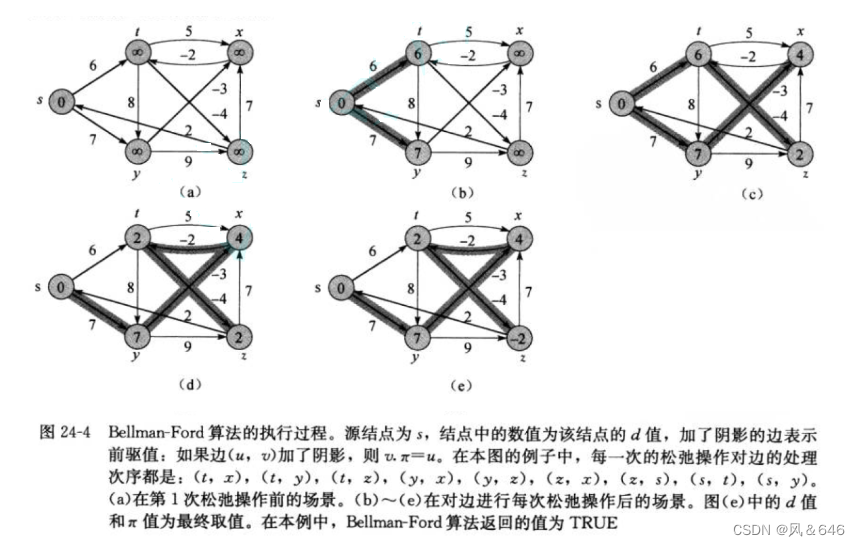
���潫ʹ������������ Bellman - Ford �㷨���ֱ���ʾ ����Ȩ��ͼ�������·�� �� ���и�Ȩ��·��ͼ�����ҳ����·�� �Ĺ���:
����Ȩ·����ͼ:

����Ȩ��·��ͼ

Bellman - Ford �㷨���ö�̬�滮(Dynamic Programming)������ơ�Bellman - Ford �㷨����:
- ����Դ���� srci ��ͼ�����ж���ľ��뼯�� vector<W> dist ,Ϊͼ�е����ж����ʼ��һ������ֵ,��ʼ��Ϊ �� ,Դ����ľ����ʼ��Ϊ�������͵�Ĭ��ֵ W()�����������������·������������ vector<int> pPath ,�������е�ÿ��λ�ó�ʼ��Ϊ -1��
- ���·����� Dijkstra �㷨����,��Ϊ���ܴ��ڸ�·��,���� n �α����������·����
- n �α�������Ч���ϱȽϵ�,������Ǽ�һ����DZ��� update �����ÿһ�����Ƿ���³����̵�·��,����ѭ��ʱ���ٸ��³����̵�·��,��ֱ������ѭ����
- ������������,�ٴν���һ�α���,�����ܸ��³����̵�·��,��˵��ͼ�д��ڸ�Ȩ��·��
˼·���� Dijkstra �㷨���IJ�ͬ��ÿ�ζ��Ǵ�Դ�� srci ���³��������ɳڸ��²���,�� Dijkstra �㷨���Ǵ�Դ������������������ڽӶ���,�����ظ������ڵ㡣���,Dijkstra �㷨��Ч����Ը��ߡ����� Dijkstra �㷨����������Ȩ�����·�����⡣�� Bellman - Ford �㷨���ܴ�����Ȩ·��,����Ч�ʵ�,������˾Ͷ� Bellman - Ford �㷨�������Ż�������Ͳ�˵��,��Ҫ�˽�Ŀ��Բο���ƪ����:���·��|�Ż�Bellman-Ford(SPFA)
Bellman - Ford�㷨ʵ�ִ���:
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
size_t n = _vertexs.size();
size_t srci = GetVertexIndex(src);
// vector<W> dist,��¼srci - �����������·��Ȩֵ����
dist.resize(n, MAX_W);
// vector<int> pPath,��¼srci - �����������·������������
pPath.resize(n, -1);
// �ȸ��� srci->srci Ϊȱʡֵ
dist[srci] = W();
cout << "���±�:i->j" << endl;
// �ܹ�����n��
for (size_t k = 0;k < n;++k)
{
// i->j �����ɳ�
bool update = false; // ������Ǹ��ִ��Ƿ���³����̵�·��
cout << "���µ�" << k << "��" << endl;
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
// srci->i + i->j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
update = true;
cout << _vertexs[i] << "->" << _vertexs[j] << ":" << _matrix[i][j] << endl;
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
}
}
}
// �������ִ���û�и��³����̵�·��,��ô�������ִξͲ���Ҫ����ִ����
if (update == false)
break;
}
// ���ж�һ��,���ͼ���Ƿ��д���Ȩ�Ļ�·,�����ܸ���,�����Ȩ��·
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
// ���и�Ȩ��·,�����,����false
return false;
}
}
}
return true;
}
��Դ���·�� - Floyd-Warshall�㷨
Floyd - Warshall �㷨�ǽ���������������·����һ���㷨��Floyd �㷨���ǵ���һ�����·�����м�ڵ�,����·�� p=(v1,v2,��,vn) �ϳ� v1 �� vn ������ڵ㡣�� k �� p ��һ���м�ڵ�,��ô�� i �� j ��·�� p �ͱ��ֳɴ� i �� k �� k �� j ���������·�� p1,p2��p1 �Ǵ� i �� k ���м�ڵ�����(1,2,��,k)ȡ�õ�һ�����·����p2 �Ǵ� k �� j ���м�ڵ�����(1,2,��,k)ȡ�õ�һ�����·����

�� Floyd �㷨��������ά��̬�滮,D[i][j][k] ��ʾ�ӵ� i ���� j ֻ���� 0 �� k ��������·��,Ȼ������ת�Ʒ���,Ȼ��ͨ���ռ��Ż�,�Ż������һά��,���һ�����·���ĵ����㷨,��õ����е�����·����
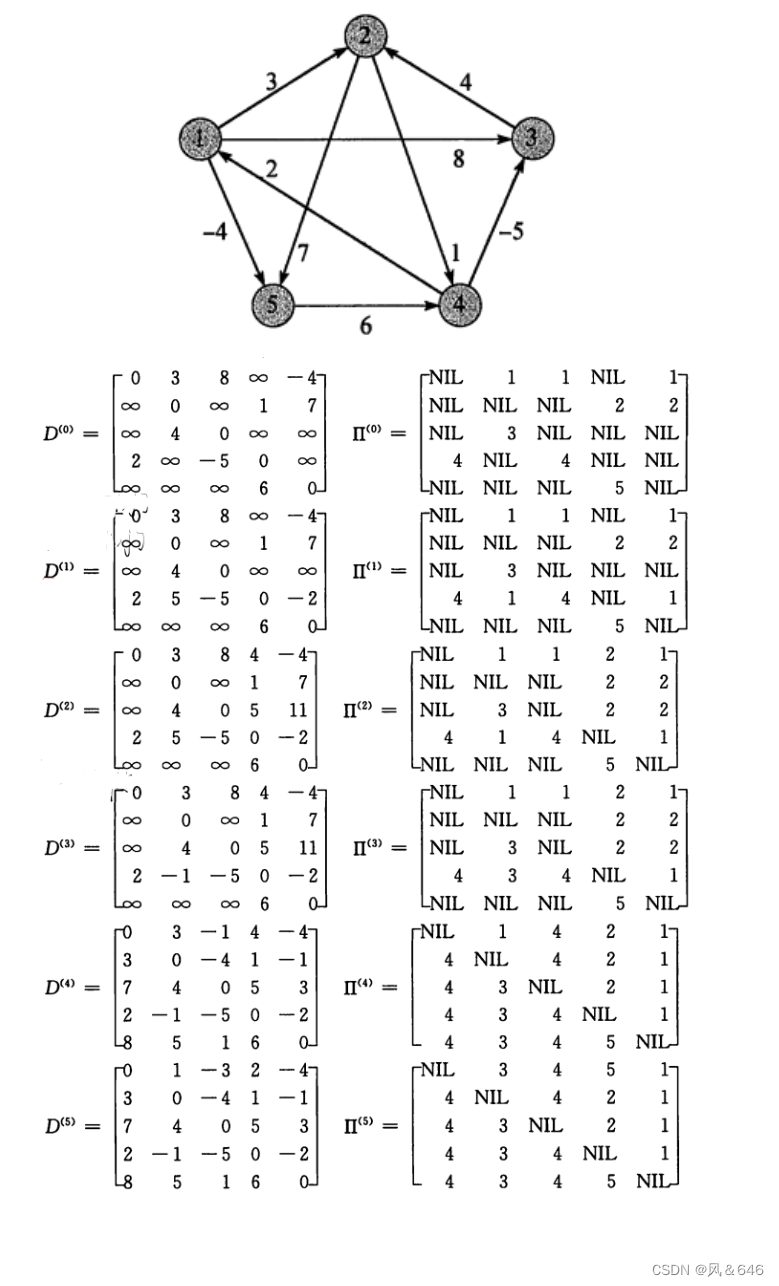
Floyd �㷨������ APSP(All Pairs Shortest Paths,��Դ���·��),��һ�ֶ�̬�滮�㷨,����ͼЧ�����,��Ȩ�����ɸ������㷨����Ч,��������ѭ���ṹ����,���ڳ���ͼ,Ч��Ҫ����ִ��|V|�� Dijkstra �㷨,ҲҪ����ִ��|V|�� SPFA �㷨��
�ŵ�:��������,�������������������֮�����̾���,�����д��
ȱ��:ʱ�临�ӶȽϸ�,���ʺϼ���������ݡ�
Floyd-Warshall�㷨����ʵ��:
void FloydWarshall(vector<vector<W>>& vvDist, vector<vector<int>>& vvpPath)
{
size_t n = _vertexs.size();
vvDist.resize(n);
vvpPath.resize(n);
// ��ʼ��Ȩֵ��·������
for (size_t i = 0;i < n;++i)
{
vvDist[i].resize(n, MAX_W);
vvpPath[i].resize(n, -1);
}
// ֱ�������ı߸���һ��
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
if (_matrix[i][j] != MAX_W)
{
vvDist[i][j] = _matrix[i][j];
vvpPath[i][j] = i;
}
// ���Խ����Լ����Լ��ľ��봦��Ϊ����Ĭ��ֵ
if (i == j)
{
vvDist[i][j] = W();
}
}
}
// ���·���ĸ��� i->{��������}->j
// �����ö���k��Ϊ��ת��������·��
for (size_t k = 0;k < n;++k)
{
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
// k ��Ϊ�м�㳢��ȥ���� i->j ��·��
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W && vvDist[i][k] + vvDist[k][j] < vvDist[i][j])
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
// �Ҹ�j��������һ���ڽӶ���
// ���k->jֱ������,��һ�������k,vvpPath[k][j]�����k
// ���k->jû��ֱ������,k->...->x->j,vvpPath[k][j]�����x
vvpPath[i][j] = vvpPath[k][j];
}
}
}
// ����������Ϊ�������Դ������ȷ�Ե�,�����ڴ����ʵ�ֲ���
//================================================
// ��ӡȨֵ��·������۲�����
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
if (vvDist[i][j] == MAX_W)
printf("%3c", '*');
else
printf("%3d", vvDist[i][j]);
}
cout << endl;
}
cout << endl;
for (size_t i = 0;i < n;++i)
{
for (size_t j = 0;j < n;++j)
{
printf("%3d", vvpPath[i][j]);
}
cout << endl;
}
cout << "===========================" << endl;
}
}
���в���ͼ�Լ�����˼��ο��鼮���㷨���ۡ���