文章目录
本文旨在将每月的所做的事情、想法和积累做个总结,以反思自己在过去的不足之处,以指导后续前进方向。此博客可能长期维护,具体不定,先记录试试。
以下每月的内容包括:1. 知识积累模块;2. 所做事情模块和想法模块;3. 鸡汤模块
2021年5月和6月
知识积累
- 英语表达:
- a significant level of …
- We derive insights …
- Various approaches have been proposed in the literature aiming at reducing manual debugging efforts throught automatically generating patches.
- recent years have witnessed the explosive growth of the number of Java techniques.
- primary(最主要的)
- in terms of 依据 with respect to对于
- as shown in figure; as presented in Table XXX
- prior studies have shown that XXXX.
- off-the-shelf 现成的
- To overcome this disadvantage
- A XXX approach to XXX via incorporating XXX.
- A deep-learning-based approach to predict potential faulty locations via incorporating various dimensions of fault diagnosis information.
- A comparative summary of the the computation costs and communication costs for the three protocols and ours are depicted in Fig. XX.
- detrimental effects on the user experience of client programs 有害的影响
- To the best of our knowledge, XXX
- the number of failing test cases are fewer than those of XXX
- This result suggests that a large proportion of fixing attempts suffered from the non-repairability factors during executions and it is of great significance to dissect the reasons for these non-repairability factors for avoiding identical problems in future studies.
- XXX is the most common exception type which has occurred for 1128 times, account for 37% of the total amount, followed by XXX and XXX which are 463 and 329 respectively.
- substantially = great
SeAPR can substantially reduce patch executions before find- ing the first plausible/correct patches for almost all studied repair tools, with a maximum improvement of 78.81%/72.96%. - Unfortunately, these methods do not always guarantee XXX
-
在latex中,如果表格中的标题或者内容带有#,需要使用转义字符。经实践,无论是正文还是bibtex中的链接里的#都会导致错误。== 这里要强调一下bibtex,很容易被忽略。==(刚刚整理时,又发现&也属于这种,我想找到这个需要转义的模式。
找到了:https://www.cnblogs.com/litifeng/p/11663716.html
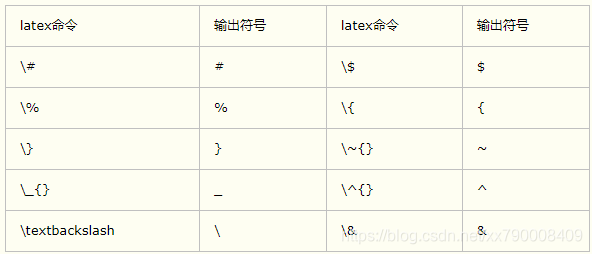
-
信息安全课程答辩积累:
论文:Image encryption based on compressed sensing and DNA encoding
- 混沌系统和DNA编码可以用于图像加密。压缩感知用于图像压缩。
- 混沌系统可以用于加密。混沌系统有两个特点,一是对初值的敏感性,初值差距很小,但是经过若干次混沌系统的迭代后,差距会很大,可以简单概括为蝴蝶效应;二是混沌系统具有伪随机性,在舍弃掉混沌系统的前n轮迭代值之后,后面的数据在人们看来,都是无规律的数据。
- 这次的两篇文章,虽然都是用压缩感知做图像压缩,但是其中一篇文章是将原始图像的稀疏表示进行分块,分为1个低频块,保留主要信息,3个高频块,保留细节信息。压缩感知只对高频块进行压缩,这样的操作会极大地保留图片的主要信息,损失的只是图片的细节部分。
- Flaky test出现的原因:1. 异步等待;2. 并发;3. 资源泄露;4. 远程服务;5.测试依赖性;6. 其他,比如系统时间,随机数,平台依赖性。
其实这可以反应到实际工程中,有时候写代码的时候,有时候运行结果正确,有时候运行结果错误,可以从这些方面进行考虑。 - 这个博客讲RNN讲得挺好:https://zhuanlan.zhihu.com/p/30844905
- 关于归一化、标准化和正则化的记录:https://zhuanlan.zhihu.com/p/29957294
这里的normalize 可以是min-max归一化、可以是均值方差归一化(这个也叫标准化!)
正则化regularization主要用于避免过拟合的产生和减少网络误差。
L1正则又叫Lasso回归
L2正则又叫岭回归 - 零样本学习的具体例子:
在已有样本中,存在马,老虎和熊猫三种类型的样本。模型从这三种数据中分别学到特征,比如学到马的整体形态,学到老虎的条纹和熊猫的黑白颜色。
然后零样本学习的一个关键是,有一个知识库,这个知识库里面存了斑马的特性:和马的形态相似,有黑白色的条纹。
然后如果遇到一个训练数据中从来没有的数据,如斑马,则模型通过结合已有样本的特征 和 知识库,对新的样本进行识别。
零样本学习其实就是迁移学习中的一个分支。
可以利用知识图谱建立unseen class与seen class之间的关系。
零样本学习的本质是利用知识完成推理的过程。
做的事和想法
- 写作之前,一定要先构思内容,细化到每个点
- 做别人的论文的汇报的时候,需要加上期刊,年份,作者信息等等。加入一些思考。
- 调研program slice过后的大小
An Empirical Study of Static Program Slice Size
后向切片的统计数据:最小7.4%,最大61.7%,平均28.1%
前向切片的统计数据:最小9.0%,最大29.9%,平均20.1%
结论:首先切片进行筛选波动很大,存在不稳定因素;然后就是平均值只有20-30%。
可以这样说: The average slice just under one-third of the program for the most precise slicer. - 受学长启发,接下来想做的事情:
主题: 机器学习应用在缺陷定位中的方法的实证研究
基础:刘春燕的文献综述
类型:statement level , method level
方法:
(1)dataset:探索所用数据集是否一致,这里探索数据集的biase。
(2)method:所用神经网络
阅读文献,查找是否有开源代码信息
若没有开源,则尝试联系通讯作者,能否给代码
若没有回复,则看论文中是否给出了能够实现ML-FL的细节
(3)baseline:和SBFL,和其他state-of-the-art的MLFL比
(4)metrics:EXAM,RImp,Top-K,MAR,MFR,Wilconx sign-rank test
目的:探索在基于ML的FL的biase,存在的问题,以后后续做基于深度学习的定位相关的指导。
挑战:实现工具,给出有贡献的建议。
可行性:
参考Empirical review of Java program repair tools: A large-scale experiment on 2,141 bugs and 23,551 repair attempts(FSE 19 distinguished paper)
11个APR工具,在不同数据集上效果不一样,最后的结论是benchmark overfitting - 为研究已知的baise对APR的影响,做了文献阅读。
Flaky test(FlakiMe: Laboratory-Controlled Test Flakiness Impact Assessment. A Case Study on Mutation Testing and Automated Program Repair):文章用5%的几率变异测试用例,让测试用例失败,以此测试变异测试,缺陷定位,自动修复等的效果。实验在PRAPR和AJRA上进行,发现Flaky test对修复的影响很大,主要体现在(1)影响缺陷定位效果,从而影响搜索空间,导致生成的补丁的数量减少(2)补丁验证阶段可能会筛选掉可行的补丁。
Benchmark overfitting(Empirical Review of Java Program Repair Tools):文章目标是比较APR工具在不同benchmark上的效果。文章中回答了三个问题:(1)11种修复工具的修复性能;(2)benchmark overfitting;(3)没有产生补丁的原因。文中还提到了一个可能的bias,就是在实证研究的时候,要注意比较不同方法的可修复性
On the Efficiency of Test Suite based Program Repair: 文中主要解决:(1)可修复性:最新的工具修得更多,但是需要效率作为补充指标;(2)效率:不是一个广泛采用的指标 - 论文阅读:
- regression faults: Changes and modifications can introduce some faults in version (i + 1), thereby regressing the behavioral functionality of the software, these are called regression faults.
问题描述:有个程序,能通过当前测试用例(回归测试用例),我程序修改了,引入了新的功能,然后有测试用例来测试,但是引入了新的bug!这就是这篇文章要修复的bug类型。(h感觉和传统的bug差不多啊) - Beyond Tests: Program Vulnerability Repair via Crash Constraint Extraction
提出了一种无需大量测试用例的修复技术
crash-free constraint
只用一个测试用例,但是测试用例会导致crash - Concolic Program Repair
这一篇和上一篇用的数据集一样,写作方式也很相似,原来是有一个共同作者。。。
这篇文章主要贡献是筛选补丁过拟合的问题。 - DeepRL4FL:
DeepRL4FL里面的观点是:虽然DeepFL用了很多信息(spectrum-based, mutation-based, code complexity metric),但是却没有充分挖掘code coverage的信息!
spectrum-based 和 mutation-based的缺点:statements are covered by both passing test cases and failing test cases.
-
在想要公平评估的过程中,学长想要做这样一件事:
先评估APR工具针对不同bug的可修复性:直接给perfect fault localization,然后剔除不能修复的bug。
针对可修复的bug,1.可能超时都没有correct,2. 可能验证到plausible的时候停了,这两种情况都会block找到正确的patch。在定位的时候就能筛掉,比如错误语句排名1002,而
然而评估需要一个指标precisions,就是第一个通过测试用例的补丁是正确的补丁。
如果用这样的pipeline,就无法评估precisions了?我感觉可以啊,这个定义不是说在可能的修复的bug里面,找到的第一个就是correct的比例。这里筛选掉的也是不能修复的啊??? -
阅读写作相关书籍:
每一章的结构:
1、 例子
2、语法和写作技巧
3、创建自己的模板
4、答案
proofreader: 校对员
attempt, conduct, interpret, evaluate, determine, implement, formulate, classify, correlate, enhance
核心主旨:
carefully examine good examples of the kind of writing you would like to produce, identify and master the structure, grammar and vocabulary you see in these examples and then apply them in your own writing
重要!!!
Writing and publishing a research paper is the best way to get your
career off the ground。
Science writing is much easier than it looks. -
项目上传到服务器,出现ModuleNotFoundError,检查一个地方:项目映射路径对不对!!!
出现运行直接程序结束,且为正常结束(return 0),有可能是你把运行main函数的代码注释了。
一般会议的paper列表:Tracks-> technical track->accpected papers
鸡汤
- 青岛之行,看到ph公司的管理人员,对着老师的不屑,心情的急切,言语的吼叫,我反思,我不应该成为一个这样的人。而应该成为像各位老师一样,面对这样的发怒的人,坦然面对,用实力安静地证明自己。下面这张图能够很好地说明这个问题!

文末
醉翁亭记
环滁皆山也。其西南诸峰,林壑尤美,望之蔚然而深秀者,琅琊也。山行六七里,渐闻水声潺潺,而泻出于两峰之间者,酿泉也。峰回路转,有亭翼然临于泉上者,醉翁亭也。作亭者谁?山之僧智仙也。名之者谁?太守自谓也。太守与客来饮于此,饮少辄醉,而年又最高,故自号曰醉翁也。醉翁之意不在酒,在乎山水之间也。山水之乐,得之心而寓之酒也。
若夫日出而林霏开,云归而岩穴暝,晦明变化者,山间之朝暮也。野芳发而幽香,佳木秀而繁阴,风霜高洁,水落而石出者,山间之四时也。朝而往,暮而归,四时之景不同,而乐亦无穷也。
至于负者歌于途,行者休于树,前者呼,后者应,伛偻提携,往来而不绝者,滁人游也。临溪而渔,溪深而鱼肥。酿泉为酒,泉香而酒洌;山肴野蔌,杂然而前陈者,太守宴也。宴酣之乐,非丝非竹,射者中,弈者胜,觥筹交错,起坐而喧哗者,众宾欢也。苍颜白发,颓然乎其间者,太守醉也。
已而夕阳在山,人影散乱,太守归而宾客从也。树林阴翳,鸣声上下,游人去而禽鸟乐也。然而禽鸟知山林之乐,而不知人之乐;人知从太守游而乐,而不知太守之乐其乐也。醉能同其乐,醒能述以文者,太守也。太守谓谁?庐陵欧阳修也。