1. ǰ��
��Һ�,����Arthur,ӵ������10�����ϵ����в��Ծ���,Ŀǰ��һ����������ҵ��˾���β��Ծ������������Ǹ����,�����϶��Dz���д����������Թ���,���һ������Ǵ��ֹ�;�������,���Կ�����ʼ����,��������ҵԽ��Խ���Ӳ�����Ա���ۺ�����,ʹ��������Щ�ϲ���Ҳ����ת��,���ܸ���ʱ���IJ���,�����Ҳ�����˿�ʦ��ʦ�� ȫջ�ѵ��Ӫ,֮ǰ��Ҳ��һЩ������ѵ��վ��ѧϰһЩ�µ�֪ʶ��,���Ҹо���ʦ�Ŀγ������Ƿ�Χ����ȡ���ȱȴ������ѵ����ǿ�ܶ�,Ҳ���ǹ������о������õ�������,�dz�ֵ�ô��ѧϰ����ô,�����ҽ����ѵ��Ӫ�γ̵Ľ���,����һЩ���ڽӿ��Զ�������ѧϰʵ���ܽ�,������Щ���Ѿ�Ӧ�õ���ʵ�ʹ�����,ϣ���Դ��Ҳ����������
2. ��������
- ����
Pytest+Request+Allure+Jenkinsʵ�ֽӿ��Զ���; - ʵ��һ�ű�������ִ��;
- ���ò�������������ģʽ,ʵ�ֽӿ���������ݷ���
- ʹ��
logger����ʵ���Զ���������־��¼

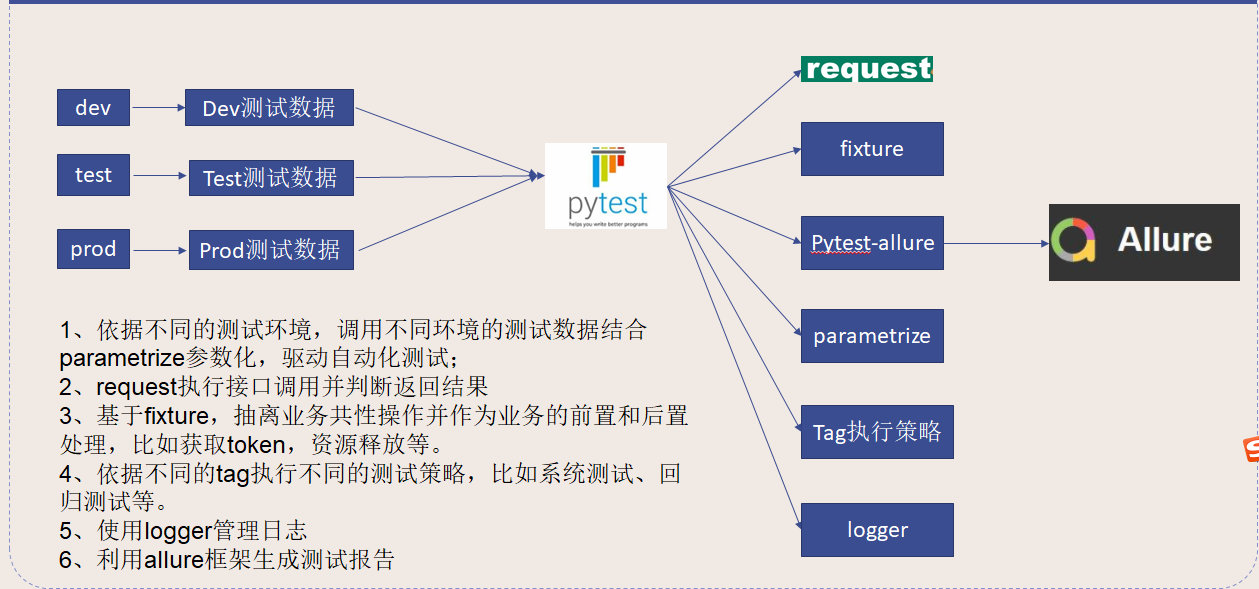
3. �ӿ��Զ�����Ŀ�����д(����windowʵ��)
3.1 ��Ŀ��
����window��װ��Ӧ�Ļ�������
- ��װpython3.7(Ҫ��֤pip����,һ�㰲װpython3.7���Զ���װpip)
- ��װpytest���---- pip install pytest
- ��װrequest��---- pip install request
- ��װopenpyxl��(�������ݱ�����excel��,��Ҫ������ȡexcel�Ŀ�)---- pip install openpyxl
- ��װpycharm(��дpython�ű�����)
ע��:���ܻ���ҪһЩ�����Ķ���,��Ŀ�������������Ҫ���а�װ
3.2 ��ƻ���pytest�IJ��Կ�ܽṹ
��pycharm�п���������Ŀ�ṹ

- common:��Ź�������
- config:��Ż���������Ϣ
- lib:��ŵ�������
- main:��������
- report:���allure���Ա���
- test_case:��Ų�������
- test_data:��Ų�������
3.3 ʵ�ֽӿڹ�������������
����һ����ʼ��ʽ��д����

��װhttp����Ĺ�������(��װrequest��,����Լ��Ĺ�����������),�ŵ�commonĿ¼�¡�
# encoding: utf-8
# ������Դ:ȫջ�ѵ��Ӫ
import requests
import urllib3
# from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings()
# ����䲻�ᱨ��(requests֤�龯��)
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
class HTTPRequests(object):
def __init__(self, url):
self.url = url
self.req = requests.session()
# �����Լ���˾������ͷĬ��ֵ����
self.head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, '
'application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, '
'application/msword, */*',
'Accept-Language': 'zh-CN'}
# ��װ�Լ���get����,��ȡ��Դ
def get(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
# print("����ͷ��:{}".format(headers))
url = self.url + uri
response = self.req.get(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# ��װ�Լ���post����,��ȡ��Դ
def post(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.post(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# ��װ�Լ���put����,��ȡ��Դ
def put(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.put(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# ��װ�Լ���delete����,��ȡ��Դ
def delete(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.delete(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
3.4 ������Ի���������Ϣ
��������Ŀ��������
- Ϊ������������ͬ����(���ԡ�����������)��URL,ÿ�������ӿڲ��Ե�URL�Dz�һ����,��������һ��ö����,�������ij�����ݲ�ͬ�Ļ���,��ȡ��ͬ������URL,�����URL�����Լ���˾�ĵ�ַ��,�ŵ�configĿ¼
- ��ȡtoken��Ҫ��¼,�����������һ��ȫ�ֵ��˺�����,����˺������ȡ��token���Ը������ӿ��Զ���ʹ��
- ���û�ȡtoken��uri,���uri������������һ�µ�,��¼�Ľӿ����ݻ���ֻ��URL��ͬ,URI����һ�µġ�
# encoding: utf-8
# ������Դ:ȫջ�ѵ��Ӫ
import enum
class URLConf(enum.Enum):
"""����������Ϣ"""
url_mapping = {
'dev': 'https://www.dev.com',
'test': 'https://www.test.com',
'prod': 'https://www.prod.com'
}
# token�̶����û�������,�̶���"/"�ָ��û���������
email_user = {
'dev': 'dev@qq.com',
'test': 'zidonghua@qq.com/96e79218965eb72c92a549dd5a330112',
'prod': 'prod@qq.com'
}
login_uri = r'/api/auth/login/account/v1'
3.5 ����conftest.py����һЩ������fixture
1��pytest_addoption,������ֻ��������dev/test/prod��������,�����ֲ��ԡ�������������������
2��get_env��fixture,��������������������ִ�нӿ��Զ���ʱ,��������Cenv test����Ӧ�Ļ�����Ϣ�����ȥ
3��http��fixture,�������ݨCenv test����Ļ�����Ϣ,ȥö�������ȡ��Ӧ������URL,Ȼ��һ��http��session,��������ʹ��
4��get_token_head,���ݨCenv test����Ļ�����Ϣ,���û�ȡtoken����,����token���õ�����ͷhead�ﷵ��(tokenһ���������ͷ��,���������Լ���˾������,���ض�Ӧ��token��Ϣ�Ϳ�����)
# encoding: utf-8
# ������Դ:ȫջ�ѵ��Ӫ
import logging
import os
import pytest
from common.http_request import HTTPRequests
from config.url_config import URLConf
datadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
logger = logging.getLogger('conftest��־')
def pytest_addoption(parser):
# choices ֻ���������ֵ�ķ�Χ
parser.addoption(
"--env", action="store", default='test', choices=['dev', 'test', 'prod'], help="set env"
)
# ��ȡ�����в�����fixture
@pytest.fixture(scope='session')
def get_env(request):
# print("fixutre..................")
return request.config.getoption('--env')
# ����һ������http��������fixture,����������һ��session��
# @pytest.fixture(scope='module', autouse=True)
@pytest.fixture(autouse=True)
def http(request):
env = request.getfixturevalue("get_env")
url_mapping = URLConf.url_mapping.value
url = url_mapping.get(f'{env}')
http = HTTPRequests(url)
return http
@pytest.fixture(scope='session')
def get_token_head(request):
env = request.getfixturevalue("get_env")
url_mapping = URLConf.url_mapping.value
url = url_mapping.get(f'{env}')
http = HTTPRequests(url)
user = URLConf.email_user.value
user_list = user.get(f'{env}').split("/")
username = user_list[0]
password = user_list[1]
param = {'clientType': 2,
'language': 'en',
'loginId': username,
'loginPassword': password}
logger.info("�����url=={}".format(url))
response = http.post(uri=r'/api/auth/login/account/v1', data=param)
logger.info("��ȡ�ķ���ֵ��:".format(response.text))
token = None
if response.status_code == 200:
token = response.json().get('result')['token']
else:
token = 'get token fail'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, '
'application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, '
'application/msword, */*',
'Accept-Language': 'zh-CN',
'Authorization': token}
yield head
3.6 ���������ݷŵ�excel��
���ǵIJ��������Ƿ���excel��,ע��,������prod\test\dev����Ŀ¼,��Ӧ���������IJ�������,������ֻ������test���Ի����IJ������ݡ�����IJ���������Ҫ����������:
- ����ýӿڴ�������в���;
- ��Ҫ���Ե�������Ϣ,��Ϊ�㴫�IJ�����ͬ,���ص����ݾͲ�ͬ,����Ե�����Ҳ�Ͳ���ͬ�ˡ�

��ô��ʱ��,����Ҫһ����ȡexcel�Ĺ���������,�ŵ�common��
# ��������excel�ķ���
import logging
from openpyxl import load_workbook
logger = logging.getLogger("��ȡexcel")
class ParseExcel(object):
def __init__(self, excelPath, sheetName):
self.wb = load_workbook(excelPath)
self.sheet = self.wb[sheetName]
self.maxRowNum = self.sheet.max_row
# ���ݴ��������,������ȡ����excel����
def getDataFromSheet(self, num):
dataList = []
for line in self.sheet.rows:
tmplist = []
for i in range(num):
tmplist.append(line[i].value)
dataList.append(tmplist)
print("dadddddd:{}".format(dataList))
return dataList[2:]
����,����Ҫ��test_data��,����һ���ļ�,Ϊ�˻�ȡǰ��test_data���ݻ���������dev/test��prod�ļ�Ŀ¼
ע��:����ֻ��һ��test��prod��dev������,��Ϊ��ƴ�ӡ�test_data/testĿ¼��ȡ��Ӧ������excel�������ݶ�ʹ�õ�,ÿ�λ����л�ǰ,��Ҫ��������ļ�,�����Ⲣ����һ���÷���,���������ҵ����õķ���,Ҳ���Է���һ��
3.7 ��ʼ��д�Զ�����������
���������м�����,��Ҫ����һ��:
1��authBaseDir,������Ǹ���test_data/testƴ�ӳ����Ļ�ȡ�������ݵ�Ŀ¼
2��allure.feature,�ڲ��Ա�����,��չ������ӿ�����,�������������㹫˾�Ŀ���д�Ľӿ�ģ�鱣��һ��,���������������
3��allure.story ����ҲҪ�뿪��д�ľ���ij���ӿڵ����Ʊ���һ�¡�
4��pytest.mark.parametrize,����������õ�DDT����������ģʽ,��excel��һ��һ���Ļ�ȡ����,Ȼ��ִ��ͬһ���ӿڲ�������,excel�б�����3������,��ô�ͱ�ʾ�����������ÿһ�����ݵIJ���,�ܹ�ִ��������
# encoding: utf-8
"""
create by Arthur
Account Apiģ��
"""
import logging
import os
import allure
import pytest
from common.get_data_url import get_data_url
from common.parse_excel import ParseExcel
datadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
data_url = get_data_url()
# ��ȡ��test_data\test��Ŀ¼,�����prod����,��ô���ǻ�ȡtest_data\prodĿ¼
authBaseDir = os.path.join(datadir, data_url)
logger = logging.getLogger("Account Apiģ����־")
@allure.feature("AccountApiģ��")
@pytest.mark.webtest
class TestAccountApi(object):
"""Query Related Achievements: /api/auth/account/achievement/related/query/v1
"""
Query_Related_Achievements_dir = os.path.join(authBaseDir, 'Query_Related_Achievements.xlsx')
logger.info("Query_Related_Achievements�������ݵ�·����:{}".format(Query_Related_Achievements_dir))
parse = ParseExcel(Query_Related_Achievements_dir, 'Sheet1')
Query_Related_Achievements_params = parse.getDataFromSheet(5)
@allure.story("Query Related Achievements(��ѯ�û��ɾ���Ϣ)")
@pytest.mark.parametrize("clientType,language,retCode,istoken,result", Query_Related_Achievements_params)
def test_001_Query_Related_Achievements(self, get_token_head, http, clientType, language, retCode, istoken, result):
uri = '/api/auth/account/achievement/related/query/v1'
params = {"clientType": clientType, "language": language}
if istoken == 'yes':
header = get_token_head
response = http.get(uri=uri, params=params, headers=header)
json_req = response.json()
logger.info("Query_Related_Achievements��token�ķ���ֵ��:{}".format(json_req))
assert json_req.get('retCode') == 200
assert json_req.get('result')[0]['smallImg'] == result
else:
response = http.get(uri=uri, params=params)
json_req = response.json()
logger.info("Query_Related_Achievementsû��token�ķ���ֵ��:{}".format(json_req))
assert json_req.get('retCode') == 401
assert json_req.get('message') == result
3.8 ����allure
д������,�Dz��Ƿ���ǰ���allure.feature�Dz����ò�����?������Ϊ���ǻ�û�м���allure��ȥ��
1������allure,�ŵ�libĿ¼��,ʹ��Ĺ��̾߱�allure��������

2��pip install allure-pytest ��װpytest��Ӧ��allure��
3.9 ��ʱ��Ϳ��Դ���һЩִ�в�����
1������main�д���һ��pytest.ini�ļ�,����һЩִ�в���
2����main�д���ִ�в���
- ����run_pytest������,ִ�а���������allure��json��ʽ�ı����ļ�,������Դ��Cenv prod����Ӧ������Ϣ����,����û�д�����ΪĬ����test����,������Ļ�����ִ�е�test������������
- general_report����ʱ�����ɵ�json��ʽ�ı���,��������html�ļ����õ�report�����Ŀ¼��
- ����һ���߳�,��ִ��run_pytest,��ִ��general_report,����json�ļ�û������,��������html�ļ��ı������ݿ��ܲ�ȫ,����û�С�
# encoding: utf-8
# ������Դ:ȫջ�ѵ��Ӫ
"""
���а���ִ�в�����allure���Ա����ִ�в���
"""
import os
import sys
import threading
import pytest
sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../')
from common.report import Report
project_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
report_dir = os.path.join(project_root, 'report')
# ��Ų��Խ����Ŀ¼,������һ��json�ļ�
result_dir = os.path.join(report_dir, 'allure_result')
allure_report = os.path.join(report_dir, 'allure_report')
report = Report()
# ������������,����������test��ͷ������
tag = 'test'
def run_pytest():
# --clean-alluredir
# pytest.main(['-vv', '-s', '-m', 'webtest', f'--alluredir={result_dir}', '--clean-alluredir'])
# ִ��ǰ���allure_result����,�������ɱ���ʱ,����ϴ�ִ�е����ݴ���ȥ
pytest.main(['-vv', '-s', '-k', f'{tag}', f'--alluredir={result_dir}', '--clean-alluredir'])
def general_report():
# ����cmd���� report.allure,����windows��linux�����ж�
# Ȼ��ִ�����ɱ���ķ���generate
# --clean ����·��,���ϴεĽ�����ǵ�
cmd = "{} generate {} -o {} --clean".format(report.allure, result_dir, allure_report)
# ִ������������,��ͨ��read()����������Ľ������
print(os.popen(cmd).read())
if __name__ == '__main__':
# ���������߳�,�ֱ�ִ����������
run = threading.Thread(target=run_pytest)
gen = threading.Thread(target=general_report)
run.start()
# ��ִ�е�һ���߳�,����߳�ִ����Ż�ִ��������̺߳����߳�
run.join()
gen.start()
gen.join()
3.10 �Զ���ִ�����ɽ��
��windows��,�Ҽ�ִ��main�����run_test_allure_html.py(������һ�������python�ļ�),Ȼ���report/allure_report/index.html���������Ƿ����ɳɹ�

4. jenkins�����(linux����)
����,����һ��,��windows�������Ѿ�ִ�гɹ�,��������Ҫ���ɵ�jenkins����ȥ,�����linux�����¡�
1���������ϴ�����˾��git(û��git���Լ��һ�װ�)
2����һ̨linux����(�Լ�ȥ�Լ���˾����Դ)
3����linux�°�װjenkins(���Ƿ�ֹ��tomcat��)��python3��pytest��allure��openpyxl(��Щ���������Ͽ���������,���ﲻ����)
4������linux�µ�tomcat,Ȼ����window�´�jenkins�ķ����ַ

5������һ�����ɷ���job
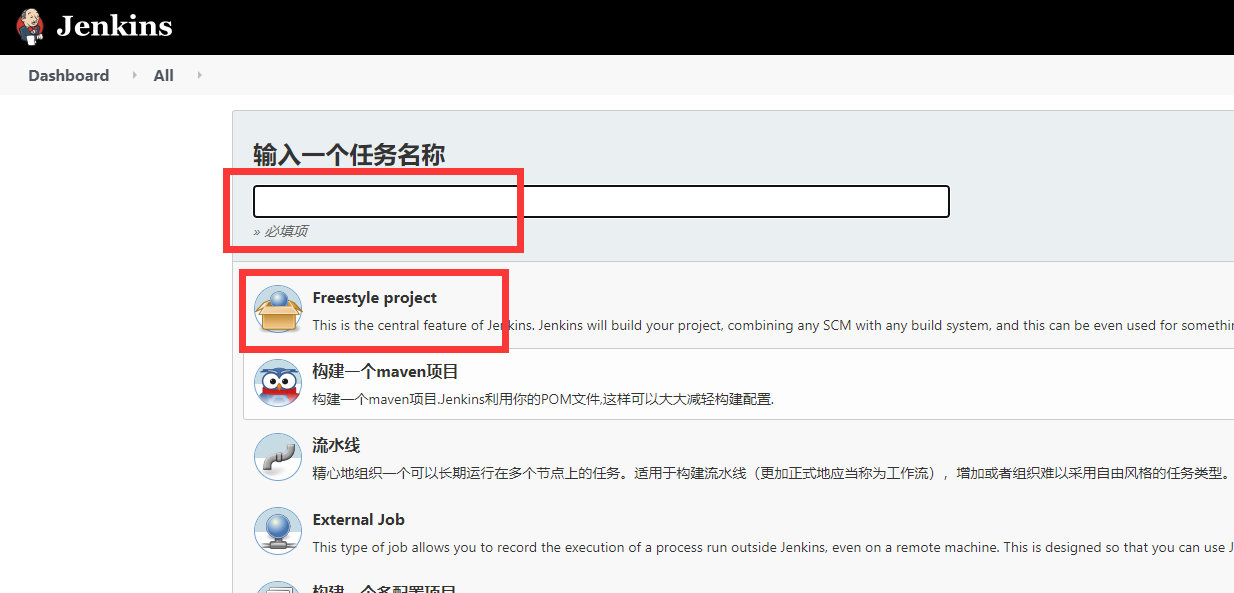
6��Job��Ҫ��д�ľ���������:
- A��ѡ�����ɵĹ���(�����Ĺ������������Լ������ѡ��)

- B����������Ŀ�����нڵ㡱�����Լ������ѡ��(��������ҵ�jenkins��������ȡ��һ����linux�ı�ǩ,�ҵĻ���Ҳ��linux����)

- C��git�C��git�ϵĴ���������
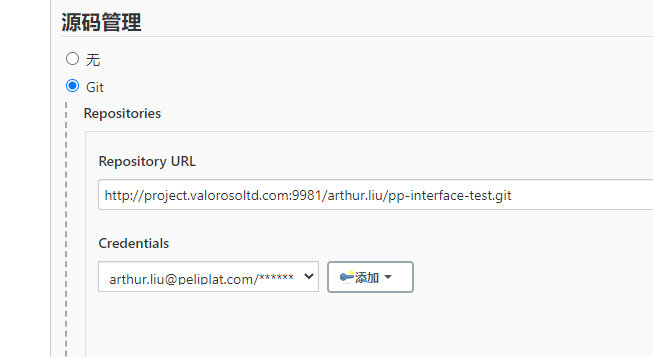
- D����ִ��shell��,����Ѵ����git������jenkins��ִ��Ŀ¼��,һ����linux�µ�root/.jenkins��,��ִ��shellʱ,���chmod�����������̵�Ŀ¼Ȩ��,��Ϊ�п�����Ȩ������ִ�в���

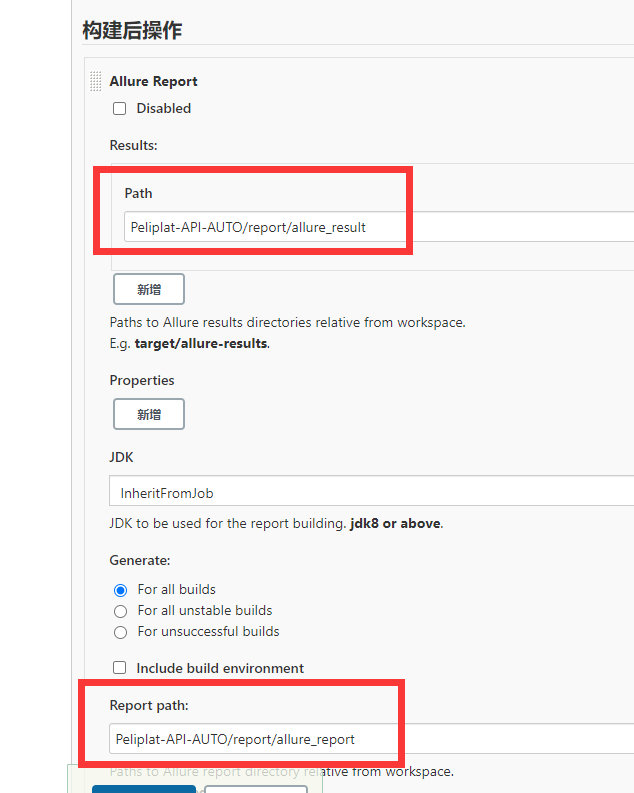
- E��������IJ���:������Ҫ��jenkins�ﰲװallure������ܿ���allure Report,��һ��Path,����д����allure���ɵ�json�ļ���Ŀ¼,������report/allure_result,�ڶ���Report pathָ�������ɵ�index.html�ļ���Ŀ¼,������report/allure_report
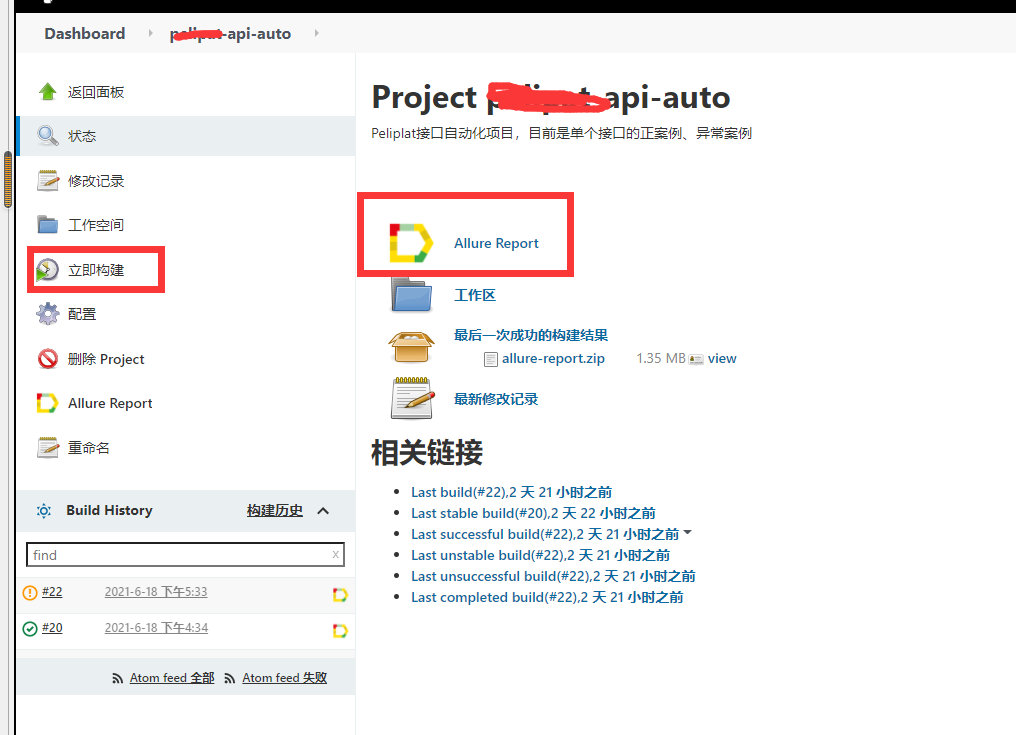
4.2 �����������鿴����
�����job���ɺ�,�Ϳ��Ե����������,ִ���ˡ�ִ�����,���allure Report�鿴���յı��档

5. ��
����ķ�����ʵҲֻ��ȫջ�ѵ��Ӫ���뼶���Կ��������ܰ����,��С��һ����֪ʶ��,�����漰����֪ʶ,�ڹ����ж��dz�ʵ��,�dz�ֵ��ѧϰ��
�˴η����͵�������,����һ����ѧϰ�ܽ�ɡ�����Ȼ����һֻ��������IJ����ϱ�,�����赲�����ҳ���ѧϰǰ���IJ���,ϣ������Щ����ͬ��ѧϰ�����ͬѧ���㡣