selenium介绍(下)
不管页面是动态加载还是静态加载出来的,只要是elements中能找到的,都能用selenium来获取数据,selenium获取数据的方式是以页面最终渲染后的前端为基础的,不需要去分析数据接口了,看到什么内容就直接去获取,“所见即所爬”,但也不是100%的爬取,使用时需要先加载驱动,速度比较慢。
driver.page_source 前端结构的源码 ,跟渲染之后有关系,与requests获取源码是有区别的
vs requests 响应内容中的源码
find() 用来查找某个字符串在HTML结构源码中是否存在,存在就返回数字,不存在就返回-1
node 元素对象,通过selenium可以获取元素的属性值,get_attribute 获取属性值,text用来获取节点文本,包括子节点和后代节点
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get('https://www.baidu.com/')
time.sleep(1)
# 获取html结构的源码
# html = driver.page_source
# print(html) # 获得html的源码
# find(),用来查找某个字符串是否在html结构的源码(渲染后的页面源码)中
print(driver.page_source.find('kw')) # 5682
print(driver.page_source.find('su')) # 964
print(driver.page_source.find('11122233aa')) # -1
比如获取豆瓣top250第一个电影的图片
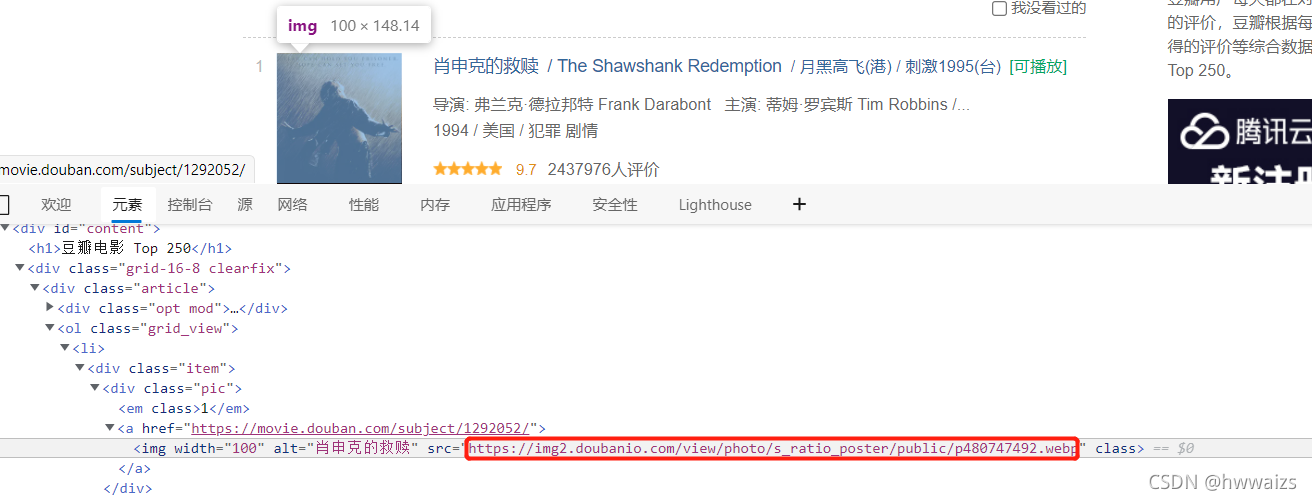
# 获取豆瓣top250,第一个电影的图片
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get('https://movie.douban.com/top250')
time.sleep(1)
img_tag = driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[1]/a/img')
# get_attribute 获取属性值
print(img_tag.get_attribute('src'))
# 图片的地址。https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp
# text用来获取节点文本,包括子节点和后代节点
img_tag = driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]')
print(img_tag.text) # 获取节点内所有的文本
# 肖申克的救赎 / The Shawshank Redemption / 月黑高飞(港) / 刺激1995(台) [可播放]
选择select
select元素不能直接点击。因为点击后还需要选中元素。这时候selenium就专门为select标签提供了一个类from selenium.webdriver.support.ui import Select。将获取到的元素当成参数传到这个类中,创建这个对象。以后就可以使用这个对象进行选择了。
案例分析:17素材网
进入网站:https://www.17sucai.com/boards/53562.html,选择左侧的下拉框图片,进去之后,选择右边的查看演示。

我们要进行的操作,是让程序模仿人的行为,点击"Try Me!"按钮,进行里面选项的选择。右键点击第一个红框,检查,可以发现"Try Me!"在select标签有name和class两个属性,我们可以select进行操作。

在定位到select标签后,对选项进行选择有两种方式,一是通过value值,每个值代表一个选项;第二种是通过索引选择。
from selenium import webdriver
import time
drive = webdriver.Edge()
drive.get('https://www.17sucai.com/pins/demo-show?id=5926')
# 定位到select标签
ipt_tag = drive.find_element_by_class_name('nojs')
# 根据值来选择
ipt_tag.select_by_value('AU')
这时我们会发现程序没有按照设置的内容进行选择选项,报出了错误:Message: no such element: Unable to locate element: {“method”:“css selector”,“selector”:".nojs"}
我们再检查网页代码,往上翻会看到代码中有iframe标签,里面的src里的url打开后跟刚才显示的网页一模一样。

iframe 是文档中的标签,文档中的文档,所以要对文档进行操作的时候,需要切换到iframe标签内,由于select没有不能直接点击,所以需要将获取到的元素当成参数传到select类中,完成点击的选择。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
drive = webdriver.Edge()
drive.get('https://www.17sucai.com/pins/demo-show?id=5926')
# 找到iframe
ifra_tag = drive.find_element_by_id('iframe')
# 切换到iframe
# drive.switch_to_frame(ifra_tag) # 被弃用的的方法,只是过时了,还可以用
drive.switch_to.frame(ifra_tag) # 新方法
# 定位到select标签
ipt_tag = drive.find_element_by_class_name('nojs')
# select不能点击,将获取到的元素当成参数传到这个类中,需要导入select库
sele_tag = Select(ipt_tag)
# 根据值来选择
sele_tag.select_by_value('AU')
# 根据索引来选择
sele_tag.select_by_index(1) # 跟按值选择结果一样

实现了程序自动选择Australia。
总结:
如果我们碰上了iframe标签 而且这个标签里面嵌套的内容刚好有我们要操作的元素,这种情况下面 就得先切换到iframe标签
找到iframe
iframe_tag = driver.find_element_by_id(‘iframe’)
切换到iframe
driver.switch_to_frame(iframe_tag)
如何操作select标签
第一步 导入 from selenium.webdriver.support.ui import Select
?
第二步 定位到select标签 把定位到的标签以参数的形式传递到Select中
select_tag = driver.find_element_by_class_name(‘nojs’)
new_select_tag = Select(select_tag)
?
第三步 选择
两种选择方式
一种是根据值来选择
new_select_tag.select_by_value(‘AU’)
第二种是通过索引选择
第二个"Try Me!"选项
select值能服务于select对象,所以进行选项框选择的时候可以模仿人的操作,先点击,再选择,然后再点击。
选项的属性值在li中,而li并没有id和class属性,可以用xpath去定位,在CA处点击右键,复制xpath路径

from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
drive = webdriver.Edge()
drive.get('https://www.17sucai.com/pins/demo-show?id=5926')
# 找到iframe
ifra_tag = drive.find_element_by_id('iframe')
# 切换到iframe
drive.switch_to.frame(ifra_tag)
# 定位到select标签
div_tag = drive.find_element_by_id('dk_container_country-nofake')
# select不能点击,将获取到的元素当成参数传到这个类中,需要导入select库
# sele_tag = Select(div_tag) # 会报错,select值能服务与select对象
# 模仿人的操作,先点击有选择
div_tag.click()
time.sleep(1)
div_tag.find_element_by_xpath('//*[@id="dk_container_country-nofake"]/div/ul/li[3]/a').click()

模拟登录豆瓣
需求分析

打开豆瓣后,默认的光标在“短信登录/注册”,现在需要把光标位于“密码登录”处,自动输入账号密码,再点击“登录豆瓣”,出现图形验证码,目前只做到用手工进行图形验证。
页面分析
光标放到“密码登录”处,点击鼠标右键,检查,可以看到“密码登录”位于li标签内,我们要定位到这个li标签,完成点击的操作。
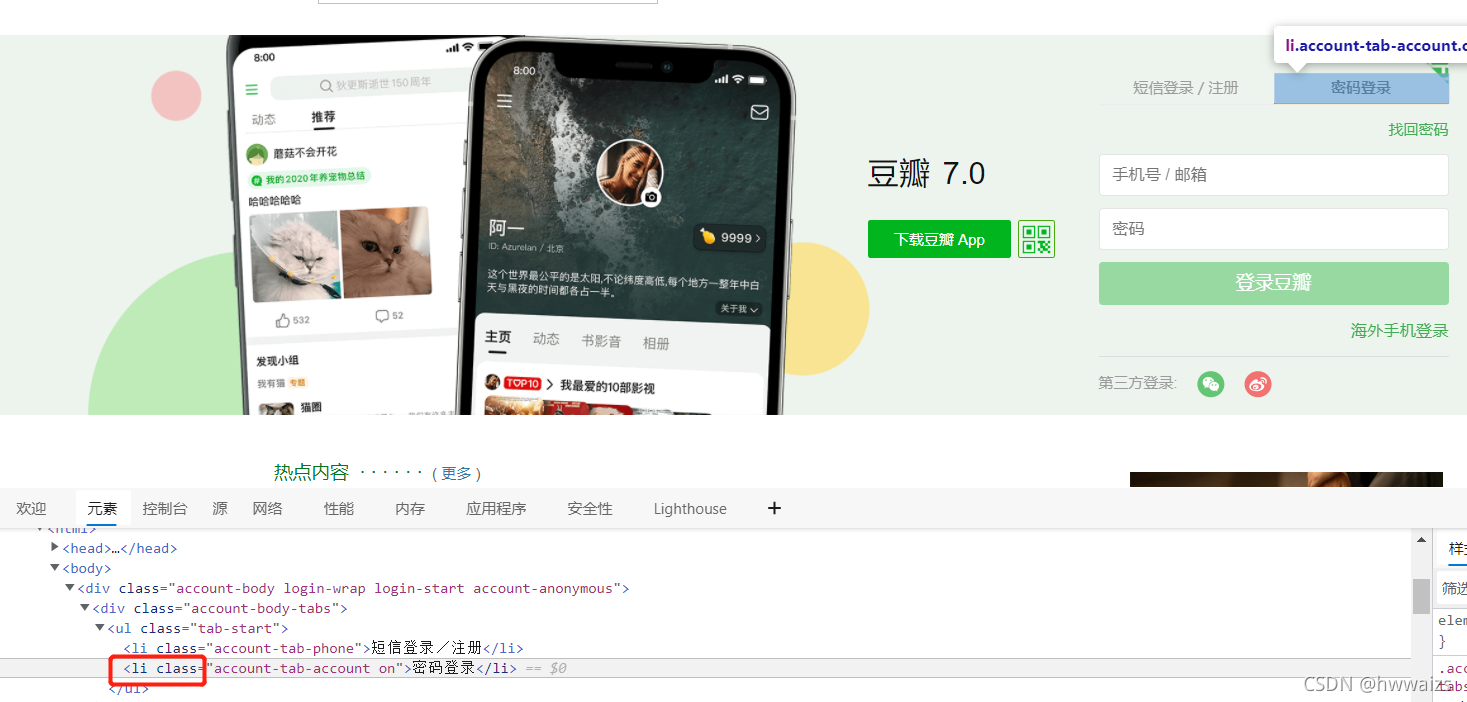
下面要输入账号密码,遇到需要填入的表格内容,我们需要先看一下网页代码中是否含有iframe标签,网上滚动代码,可以看到存在iframe标签,复制标签内的src在新网页中打开,可以看到跟要操作的登录框一样的网页,这时我们就需要先切换到iframe标签进行输入框的定位和操作。

通过鼠标右键分别检查账号密码输入框,可以看到题目分别位于两个input标签内,我们需要对两个标签分别进行定位和输入内容。


在“登录豆瓣”按钮处点击鼠标右键,检查,可以看到“登录豆瓣”位于a标签内,我们需要对a标签进行定位和点击

登录后会加载图形验证码,这里用手工滑动验证。
代码实现
from selenium import webdriver # 导入库
import time # 浏览器加载需要时间,需要等待一下
driver = webdriver.Edge() # 加载驱动
driver.get('https://www.douban.com/') # 以字符串的形式传入网页,使用驱动打开
time.sleep(1)
# 切换iframe
# 定位到iframe,发现标签里没有可定位的属性,可以用xpath定位
iframe_tag = driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')
# 切换到定位的标签内
driver.switch_to.frame(iframe_tag)
# 定位切换登录模式的位置
"""class标签‘account-tab-account on’里面有空格。1.可以采取保留长的那一部分
2.采用xpath的方式定位"""
# li_tag = driver.find_element_by_class_name('account-tab-account') # 第一种
li_tag = driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]') # 第二种
# 在li标签处,点右键,复制xpath
li_tag.click()
time.sleep(1)
# 定位用户名,输入用户名
driver.find_element_by_id('username').send_keys('xxxxx')
# 定位密码框
psw_ipt = driver.find_element_by_id('password')
# 输入密码
psw_ipt.send_keys('yyyyy')
time.sleep(1)
# 定位登录按钮
div_tag = driver.find_element_by_class_name('btn-account')
div_tag.click()
通过selenium获取cookie
之前的操作是在浏览器中找到cookie,复制下来加到请求头里。有些网站的数据是需要登录之后才能爬取的
cookie在爬虫中的作用:
- 模拟登录
- 反反爬:useragent 反反爬第一步,很多网站都会检查,还会有网站检查 cookie referer,但是cookie有时效性,几个小时到几天不等,可以通过selenium去动态的更新cookie值。
通过Network里查找到的cookie

通过浏览器驱动访问到的cookie,可以看到是一个列表里面放了很多的字典,在这里只需要取出每个字典的中key为name和value对应的value值,看网页代码中,n和v是通过“=”连接的字符串,个“=”连接的字符串中间用’; '隔开的,可以进行字符串的拼接。

代码实现:
from selenium import webdriver
import time
# 加载驱动
driver = webdriver.Edge()
# 用驱动打开网站
driver.get('https://www.baidu.com/')
# 获取cookie
cookies = driver.get_cookies()
# print(cookies)
# 打印出来是一个列表里面放了很多的字典,
# 在这里只需要取出每个字典的中key为name和value对应的value值
cookie = []
for cook in cookies:
n = cook['name']
v = cook['value']
# 看网页代码中,n和v是通过“=”连接的字符串
cookie.append(n + '=' + v)
# print(cookie)
# 每个“=”连接的字符串中间用'; '隔开的,可以进行字符串的拼接
end_cookies = '; '.join(cookie)
print(end_cookies)
模拟登录QQ空间
之前做的模拟登录是把cookie复制下来,放到header里,把获取到的网页源码保存下来就可以去访问。
这次是通过selenium获取到的cookie放到 对QQ空间发送请求的请求头里,如果能进入到QQ空间则说明获取到的cookie是可用的
进入网页后会出现如一个二维码框和一个QQ头像框,我们需要把鼠标移到头像框处,点击进入QQ空间,获取到cookie值,再把获取的cookie经过拼接整合以后放到requests请求里去访问,如果能进入QQ空间代表获取的cookie值是有效的
from selenium import webdriver
import time
import requests
"""1.通过selenium获取cookie值,2.进一步解析拼接cookie值,
3.把最终拼接好的cookie值放到代码中测试"""
# 1.通过selenium获取cookie值
# 加载驱动
driver = webdriver.Edge()
# 打开网页
driver.get('https://xui.ptlogin2.qq.com/cgi-bin/xlogin?proxy_url=https%3A//qzs.qq.com/qzone/v6/portal/proxy.html&daid=5&&hide_title_bar=1&low_login=0&qlogin_auto_login=1&no_verifyimg=1&link_target=blank&appid=549000912&style=22&target=self&s_url=https%3A%2F%2Fqzs.qzone.qq.com%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_qr_app=手机QQ空间&pt_qr_link=http%3A//z.qzone.com/download.html&self_regurl=https%3A//qzs.qq.com/qzone/v6/reg/index.html&pt_qr_help_link=http%3A//z.qzone.com/download.html&pt_no_auth=0')
time.sleep(1)
# 找到头像
span_tag = driver.find_element_by_id('img_out_“自己的QQ号”')
# 需要QQ在线才能出现QQ的头像框
time.sleep(1)
# 点击头像
span_tag.click()
# 等待页面加载一会
time.sleep(2)
cookies = driver.get_cookies()
# print(cookies)
# 打印出来是一个列表里面放了很多的字典,
# 在这里只需要取出每个字典的中key为name和value对应的value值
# 2.拼接cookie
# 第一种方法:
cookie = []
for cook in cookies:
n = cook['name']
v = cook['value']
# 看网页代码中,n和v是通过“=”连接的字符串
cookie.append(n + '=' + v)
# print(cookie)
# 每个“=”连接的字符串中间用'; '隔开的,可以进行字符串的拼接
end_cookies = '; '.join(cookie)
# 第二种方法:列表推导式
cookie = [item['name'] + '=' + item['value'] for item in cookies]
end_cookies = '; '.join(cookie)
# 第三种:
end_cookies = '; '.join([item['name'] + '=' + item['value'] for item in cookies])
# 3.测试代码,如果把selenium获取到的cookie放进请求头中,能成功模拟登录成功
# 就证明我们获取的cookie是没问题的
url = 'https://user.qzone.qq.com/“自己的QQ号”/infocenter'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'cookie': end_cookies
}
res = requests.get(url, headers=headers)
html = res.content.decode('utf-8')
with open('qzone.html', 'w', encoding='utf-8') as f:
f.write(html)
如果出现问题,很大的可能是没有用time对程序进行暂停,因为程序执行的很快,网页反应的有点慢,如果没有暂停,会出现网页还没有加载,下一步程序就执行了,导致出现问题。打开生成的qzone.html文件,可以进到QQ空间里,看到QQ名字就说明selenium获取到的cookie是有效的,这个时候加载的QQ空间会跟正常打开的稍微有区别,因为我们正常打开的网页是最终渲染出来的。
行为链
鼠标一系列的行为和动作,单击,双击,左键点击,右键点击等等。
有时候在页面中的操作可能要有很多步,那么这时候可以使用鼠标行为链类ActionChains来完成。比如现在要将鼠标移动到某个元素上并执行点击事件
还有更多的鼠标相关的操作
click:点击
click_and_hold(element):点击但不松开鼠标,按着不丢。
context_click(element):右键点击。
double_click(element):双击。
drag_and_drop(source, target):拖拽
drag_and_drop_by_offset(source, xoffset, yoffset):拖拽,有一定的位移量
更多方法请参考:http://selenium-python.readthedocs.io/api.html
使用行为链需要提前导入库,“from selenium.webdriver import ActionChains”
from selenium import webdriver
from selenium.webdriver import ActionChains
import time # 导入库
# 加载驱动
driver = webdriver.Edge()
# 打开网页
driver.get('https://www.baidu.com/')
time.sleep(1)
# 第一种之前使用的方法
# 获取标签,输入内容
# driver.find_element_by_id('kw').send_keys('python')
# 获取点击框,点击百度一下搜索
# driver.find_element_by_id('su').click()
# 第二种方法使用行为链,先导入行为链的库
ipt_tag = driver.find_element_by_id('kw')
btn_tag = driver.find_element_by_id('su')
# 通过导入的类实例化action对象
action = ActionChains(driver)
# 往输入框中输入内容
action.send_keys_to_element(ipt_tag, 'python')
time.sleep(1)
# 第1中方式在行为链外部点击按钮
# 提交行为链
# action.perform()
# 通过标签的点击行为,不能放在行为链内部,要放行为链外
# btn_tag.click()
# 第2中方式在行为链内部点击按钮
# 把鼠标移动到按钮的位置
action.move_to_element(btn_tag)
#进行点击操作
action.click()
# 切记,要提交行为链
action.perform()
注意:
1 一定不要忘记提交鼠标行为链
2 要注意鼠标行为链中的点击操作:直接点击某个元素的逻辑是需要放在行为链外面的;如果是放行为链里面,要先定位点击按钮,把鼠标移到按钮的位置,再进行点击操作
Selenium页面等待
Cookie操作
获取所有的cookie
根据cookie的name获取cookie
删除某个cookie
页面等待
现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。为了解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待、一种是显式等待
隐式等待:调用driver.implicitly_wait。那么在获取不可用的元素之前,会先等待10秒中的时间
显示等待:显示等待是表明某个条件成立后才执行获取元素的操作。也可以在等待的时候指定一个最大的时间,如果超过这个时间那么就抛出一个异常。显示等待应该使用selenium.webdriver.support.excepted_conditions期望的条件和selenium.webdriver.support.ui.WebDriverWait来配合完成
一些其他的等待条件
presence_of_element_located:某个元素已经加载完毕了。
presence_of_all_elements_located:网页中所有满足条件的元素都加载完毕了。
element_to_be_clickable:某个元素是可以点击了。
更多条件请参考:http://selenium-python.readthedocs.io/waits.html
打开多窗口和切换页面
有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to_window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到