根据学习部分极客时间 《设计模式之美》专栏 (王争 前Google工程师)和《阿里 java 规范》整理总结。
分别介绍编码规范的三个部分:命名与注释(Naming and Comments)、代码风格(Code Style)和编程技巧(Coding Tips)。
关于命名
- 命名的关键是能准确达意。对于不同作用域的命名,我们可以适当地选择不同的长度。作用域小的变量(比如临时变量),可以适当地选择短一些的命名方式。除此之外,命名中也可以使用一些耳熟能详的缩写。
- 我们可以借助类的信息来简化属性、函数的命名,利用函数的信息来简化函数参数的命名。
- 命名要可读、可搜索。不要使用生僻的、不好读的英文单词来命名。除此之外,命名要符合项目的统一规范,不要用些反直觉的命名。
- 接口有两种命名方式:一种是在接口中带前缀“I”;另一种是在接口的实现类中带后缀“Impl”。对于抽象类的命名,也有两种方式,一种是带上前缀“Abstract”,一种是不带前缀。这两种命名方式都可以,关键是要在项目中统一。
关于注释
- 注释的目的就是让代码更容易看懂。只要符合这个要求的内容,你就可以将它写到注释里。总结一下,注释的内容主要包含这样三个方面:做什么、为什么、怎么做。对于一些复杂的类和接口,我们可能还需要写明“如何用”。
- 注释本身有一定的维护成本,所以并非越多越好。类和函数一定要写注释,而且要写得尽可能全面、详细,而函数内部的注释要相对少一些,一般都是靠好的命名、提炼函数、解释性变量、总结性注释来提高代码可读性。
补充:
开发前,我一般先写注释,再写代码。比如写一个方法,我会先拆分业务逻辑,把注释给写上。后面再看注释,写代码。
// todo
public void createOrder(RequestVo request) {
// todo 校验用户登录
// todo 校验商品
// todo 创建订单
// todo 拼装、返回结果集
}
关于注释:之前我的看法只要逻辑清晰命名准确达意就不用写注释了,现在回过来想这个问题,代码是需要不断维护的,即使当时你思路清晰那么过了一段时间后还能那么清晰么。人的大脑只会记住关键的信息,那么注释就是帮助我们梳理自己的想法和逻辑沉淀下来,是百利无害的事情,当别人接手也能迅速理解,降低沟通成本。如何注释才是好的注释呢?文中提到三点:做什么、为什么做、怎么做、怎么用(API)。这里最重要的事做什么,。我再补充一点,可以加下使用场景或者业务场景。
关于命名:这点我基本无疑义,总结下来就是两点:简洁达意和风格统一。
理论五:让你最快速地改善代码质量的20条编程规范(中)
1 函数、类多大才合适?
函数的代码行数不要超过一屏幕的大小,比如 50 行。类的大小限制比较难确定。
2.一行代码多长最合适?
最好不要超过 IDE 显示的宽度。当然,限制也不能太小,太小会导致很多稍微长点的语句被折成两行,也会影响到代码的整洁,不利于阅读。
3. 善用空行分割单元块
对于比较长的函数,为了让逻辑更加清晰,可以使用空行来分割各个代码块。在类内部,成员变量与函数之间、静态成员变量与普通成员变量之间、函数之间,甚至成员变量之间,都可以通过添加空行的方式,让不同模块的代码之间的界限更加明确。
4. 四格缩进还是两格缩进?
我个人比较推荐使用两格缩进,这样可以节省空间,特别是在代码嵌套层次比较深的情况下。除此之外,值得强调的是,不管是用两格缩进还是四格缩进,一定不要用 tab 键缩进。
5. 大括号是否要另起一行?
我个人还是比较推荐将大括号放到跟上一条语句同一行的风格,这样可以节省代码行数。但是,将大括号另起一行,也有它的优势,那就是,左右括号可以垂直对齐,哪些代码属于哪一个代码块,更加一目了然。
6. 类中成员的排列顺序
在 Google Java 编程规范中,依赖类按照字母序从小到大排列。类中先写成员变量后写函数。成员变量之间或函数之间,先写静态成员变量或函数,后写普通变量或函数,并且按照作用域大小依次排列。
关于编码技巧
1. 将复杂的逻辑提炼拆分成函数和类。
2. 通过拆分成多个函数或将参数封装为对象的方式,来处理参数过多的情况。
? 我个人觉得,函数包含 3、4 个参数的时候还是能接受的,大于等于 5 个的时候,我们就觉得参数有点过多了,会影响到代码的可读性,使用起来也不方便。针对参数过多的情况,一般有 2 种处理方法。
-
考虑函数是否职责单一,是否能通过拆分成多个函数的方式来减少参数。示例代码如下所示:
public User getUser(String username, String telephone, String email); // 拆分成多个函数 public User getUserByUsername(String username); public User getUserByTelephone(String telephone); public User getUserByEmail(String email); -
将函数的参数封装成对象。示例代码如下所示:
public void postBlog(String title, String summary, String keywords, String content, String category, long authorId); // 将参数封装成对象 public class Blog { private String title; private String summary; private String keywords; private Strint content; private String category; private long authorId; } public void postBlog(Blog blog);
3. 函数中不要使用参数来做代码执行逻辑的控制。
不要在函数中使用布尔类型的标识参数来控制内部逻辑,true 的时候走这块逻辑,false 的时候走另一块逻辑。这明显违背了单一职责原则和接口隔离原则。我建议将其拆成两个函数,可读性上也要更好。我举个例子来说明一下。
// 将其拆分成两个函数
public void buyCourse(long userId, long courseId);
public void buyCourseForVip(long userId, long courseId);
不过,如果函数是 private 私有函数,影响范围有限,或者拆分之后的两个函数经常同时被调用,我们可以酌情考虑保留标识参数。示例代码如下所示:
// 拆分成两个函数的调用方式
boolean isVip = false;
//...省略其他逻辑...
if (isVip) {
buyCourseForVip(userId, courseId);
} else {
buyCourse(userId, courseId);
}
// 保留标识参数的调用方式更加简洁
boolean isVip = false;
//...省略其他逻辑...
buyCourse(userId, courseId, isVip);
除了布尔类型作为标识参数来控制逻辑的情况外,还有一种“根据参数是否为 null”来控制逻辑的情况。针对这种情况,我们也应该将其拆分成多个函数。拆分之后的函数职责更明确,不容易用错。具体代码示例如下所示:
public List<Transaction> selectTransactions(Long userId, Date startDate, Date endDate) {
if (startDate != null && endDate != null) {
// 查询两个时间区间的transactions
}
if (startDate != null && endDate == null) {
// 查询startDate之后的所有transactions
}
if (startDate == null && endDate != null) {
// 查询endDate之前的所有transactions
}
if (startDate == null && endDate == null) {
// 查询所有的transactions
}
}
// 拆分成多个public函数,更加清晰、易用
public List<Transaction> selectTransactionsBetween(Long userId, Date startDate, Date endDate) {
return selectTransactions(userId, startDate, endDate);
}
public List<Transaction> selectTransactionsStartWith(Long userId, Date startDate) {
return selectTransactions(userId, startDate, null);
}
public List<Transaction> selectTransactionsEndWith(Long userId, Date endDate) {
return selectTransactions(userId, null, endDate);
}
public List<Transaction> selectAllTransactions(Long userId) {
return selectTransactions(userId, null, null);
}
private List<Transaction> selectTransactions(Long userId, Date startDate, Date endDate) {
// ...
}
4. 函数设计要职责单一。
我们在前面讲到单一职责原则的时候,针对的是类、模块这样的应用对象。实际上,对于函数的设计来说,更要满足单一职责原则。相对于类和模块,函数的粒度比较小,代码行数少,所以在应用单一职责原则的时候,没有像应用到类或者模块那样模棱两可,能多单一就多单一。
具体的代码示例如下所示:
public boolean checkUserIfExisting(String telephone, String username, String email) {
if (!StringUtils.isBlank(telephone)) {
User user = userRepo.selectUserByTelephone(telephone);
return user != null;
}
if (!StringUtils.isBlank(username)) {
User user = userRepo.selectUserByUsername(username);
return user != null;
}
if (!StringUtils.isBlank(email)) {
User user = userRepo.selectUserByEmail(email);
return user != null;
}
return false;
}
// 拆分成三个函数
public boolean checkUserIfExistingByTelephone(String telephone);
public boolean checkUserIfExistingByUsername(String username);
public boolean checkUserIfExistingByEmail(String email);
5. 移除过深的嵌套层次,方法包括:去掉多余的 if 或 else 语句,使用 continue、break、return 关键字提前退出嵌套,调整执行顺序来减少嵌套,将部分嵌套逻辑抽象成函数。
代码嵌套层次过深往往是因为 if-else、switch-case、for 循环过度嵌套导致的。我个人建议,嵌套最好不超过两层,超过两层之后就要思考一下是否可以减少嵌套。过深的嵌套本身理解起来就比较费劲,除此之外,嵌套过深很容易因为代码多次缩进,导致嵌套内部的语句超过一行的长度而折成两行,影响代码的整洁。解决嵌套过深的方法也比较成熟,有下面 4 种常见的思路。
-
去掉多余的 if 或 else 语句。代码示例如下所示:
// 示例一 public double caculateTotalAmount(List<Order> orders) { if (orders == null || orders.isEmpty()) { return 0.0; } else { // 此处的else可以去掉 double amount = 0.0; for (Order order : orders) { if (order != null) { amount += (order.getCount() * order.getPrice()); } } return amount; } } // 示例二 public List<String> matchStrings(List<String> strList,String substr) { List<String> matchedStrings = new ArrayList<>(); if (strList != null && substr != null) { for (String str : strList) { if (str != null) { // 跟下面的if语句可以合并在一起 if (str.contains(substr)) { matchedStrings.add(str); } } } } return matchedStrings; } -
调整执行顺序来减少嵌套。具体的代码示例如下所示:
// 重构前的代码 public List<String> matchStrings(List<String> strList,String substr) { List<String> matchedStrings = new ArrayList<>(); if (strList != null && substr != null) { for (String str : strList) { if (str != null) { if (str.contains(substr)) { matchedStrings.add(str); } } } } return matchedStrings; } // 重构后的代码:先执行判空逻辑,再执行正常逻辑 public List<String> matchStrings(List<String> strList,String substr) { if (strList == null || substr == null) { //先判空 return Collections.emptyList(); } List<String> matchedStrings = new ArrayList<>(); for (String str : strList) { if (str != null) { if (str.contains(substr)) { matchedStrings.add(str); } } } return matchedStrings; } -
将部分嵌套逻辑封装成函数调用,以此来减少嵌套。具体的代码示例如下所示:
// 重构前的代码 public List<String> appendSalts(List<String> passwords) { if (passwords == null || passwords.isEmpty()) { return Collections.emptyList(); } List<String> passwordsWithSalt = new ArrayList<>(); for (String password : passwords) { if (password == null) { continue; } if (password.length() < 8) { // ... } else { // ... } } return passwordsWithSalt; } // 重构后的代码:将部分逻辑抽成函数 public List<String> appendSalts(List<String> passwords) { if (passwords == null || passwords.isEmpty()) { return Collections.emptyList(); } List<String> passwordsWithSalt = new ArrayList<>(); for (String password : passwords) { if (password == null) { continue; } passwordsWithSalt.add(appendSalt(password)); } return passwordsWithSalt; } private String appendSalt(String password) { String passwordWithSalt = password; if (password.length() < 8) { // ... } else { // ... } return passwordWithSalt; }除此之外,常用的还有通过使用多态来替代 if-else、switch-case 条件判断的方法。这个思路涉及代码结构的改动。
6. 用字面常量取代魔法数。
常用的用解释性变量来提高代码的可读性的情况有下面 2 种.
-
常量取代魔法数字。示例代码如下所示:
public double CalculateCircularArea(double radius) { return (3.1415) * radius * radius; } // 常量替代魔法数字 public static final Double PI = 3.1415; public double CalculateCircularArea(double radius) { return PI * radius * radius; } -
使用解释性变量来解释复杂表达式。示例代码如下所示:
if (date.after(SUMMER_START) && date.before(SUMMER_END)) { // ... } else { // ... } // 引入解释性变量后逻辑更加清晰 boolean isSummer = date.after(SUMMER_START)&&date.before(SUMMER_END); if (isSummer) { // ... } else { // ... }
7. 用解释性变量来解释复杂表达式,以此提高代码可读性。
https://time.geekbang.org/column/article/188882
其他《阿里 JAVA 规范》
OOP 规约:
1. 【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用 is_xxx 的命名方式,所以,需要
在设置从 is_xxx 到 xxx 的映射关系。
反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时
候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。
2. 【推荐】在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。
正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT
反例:startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD
3. 【强制】注释的双斜线与注释内容之间有且仅有一个空格。
正例:
// 这是示例注释,请注意在双斜线之后有一个空格
String commentString = new String();
4.【强制】 POJO 类必须写 toString 方法。
使用 IDE 中的工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
5. 【强制】构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在 init 方法中。
6. 【强制】定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
反例:POJO 类的 createTime 默认值为 new Date(),但是这个属性在数据提取时并没有置入具体值,在更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间。
7. 【推荐】final 可以声明类、成员变量、方法、以及本地变量,下列情况使用 final 关键字:
1) 不允许被继承的类,如:String 类。
2) 不允许修改引用的域对象,如:POJO 类的域变量。
3) 不允许被覆写的方法,如:POJO 类的 setter 方法。
4) 不允许运行过程中重新赋值的局部变量。
5) 避免上下文重复使用一个变量,使用 final 关键字可以强制重新定义一个变量,方便更好地进行重构。
8. 【推荐】类成员与方法访问控制从严:
1) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。
2) 工具类不允许有 public 或 default 构造方法。
3) 类非 static 成员变量并且与子类共享,必须是 protected。
4) 类非 static 成员变量并且仅在本类使用,必须是 private。
5) 类 static 成员变量如果仅在本类使用,必须是 private。
6) 若是 static 成员变量,考虑是否为 final。
7) 类成员方法只供类内部调用,必须是 private。
8) 类成员方法只对继承类公开,那么限制为 protected。
说明:任何类、方法、参数、变量,严控访问范围。过于宽泛的访问范围,不利于模块解耦。
思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 service 成员方法或成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的视线内,变量作用域太大,无限制的到处跑,那么你会担心的。
日期时间:
1. 【强制】日期格式化时,传入 pattern 中表示年份统一使用小写的 y。
说明:日期格式化时,yyyy 表示当天所在的年,而大写的 YYYY 代表是 week in which year(JDK7 之后引入的概念),意思是当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,返回的 YYYY 就是下一年。
正例:表示日期和时间的格式如下所示:
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
2. 【强制】在日期格式中分清楚大写的 M 和小写的 m,大写的 H 和小写的 h 分别指代的意义。
说明:日期格式中的这两对字母表意如下:
1) 表示月份是大写的 M;
2) 表示分钟则是小写的 m;
3) 24 小时制的是大写的 H;
4) 12 小时制的则是小写的 h。
3. 【推荐】使用枚举值来指代月份。如果使用数字,注意 Date,Calendar 等日期相关类的月份 month 取值在 0-11 之间。
说明:参考 JDK 原生注释,Month value is 0-based. e.g., 0 for January.
正例: Calendar.JANUARY,Calendar.FEBRUARY,Calendar.MARCH 等来指代相应月份来进行传参或比较。
集合处理:
1.【强制】关于 hashCode 和 equals 的处理,遵循如下规则:
1) 只要覆写 equals,就必须覆写 hashCode。
2) 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须覆写这两种方法。
3) 如果自定义对象作为 Map 的键,那么必须覆写 hashCode 和 equals。
说明:String 因为覆写了 hashCode 和 equals 方法,所以可以愉快地将 String 对象作为 key 来使用。
2.【强制】判断所有集合内部的元素是否为空,使用 isEmpty()方法,而不是 size()==0 的方式。
说明:在某些集合中,前者的时间复杂度为 O(1),而且可读性更好。
正例:
Map<String, Object> map = new HashMap<>(16);
if(map.isEmpty()) {
System.out.println("no element in this map.");
}
3.【强制】在使用 Collection 接口任何实现类的 addAll()方法时,都要对输入的集合参数进行NPE 判断。
说明:在 ArrayList#addAll 方法的第一行代码即 Object[] a = c.toArray(); 其中 c 为输入集合参数,如果为 null,则直接抛出异常。
4.【强制】不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁。
正例:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if (删除元素的条件) {
iterator.remove();
}
}
反例:
for (String item : list) {
if ("1".equals(item)) {
list.remove(item);
}
}
说明:以上代码的执行结果肯定会出乎大家的意料,那么试一下把“1”换成“2”,会是同样的结果吗?
5. 【强制】在 JDK7 版本及以上,Comparator 实现类要满足如下三个条件,不然 Arrays.sort,Collections.sort 会抛 IllegalArgumentException 异常。
说明:三个条件如下
1) x,y 的比较结果和 y,x 的比较结果相反。
2) x > y,y > z,则 x > z。
3) x = y,则 x,z 比较结果和 y,z 比较结果相同。
反例:下例中没有处理相等的情况,交换两个对象判断结果并不互反,不符合第一个条件,在实际使用中
可能会出现异常。
new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getId() > o2.getId() ? 1 : -1; }
};
6. 【推荐】使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的
value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用
Map.forEach 方法。
正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是一个 Set 集合对
象;entrySet()返回的是 K-V 值组合集合。
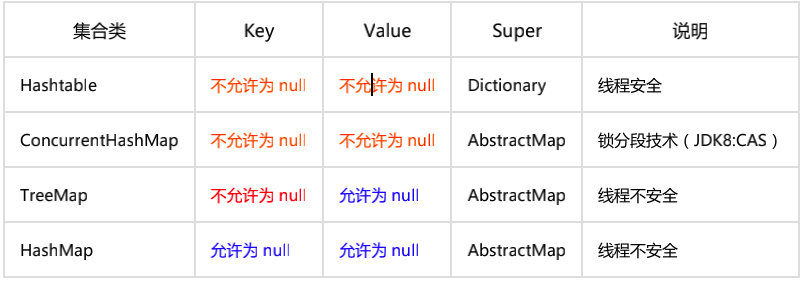
反例:由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储 null 值时会抛出 NPE 异常。
前后端规约:
1. 【强制】前后端交互的 API,需要明确协议、域名、路径、请求方法、请求内容、状态码、响应体。
说明:
1) 协议:生产环境必须使用 HTTPS。
2) 路径:每一个 API 需对应一个路径,表示 API 具体的请求地址:
? a) 代表一种资源,只能为名词,推荐使用复数,不能为动词,请求方法已经表达动作意义。
? b) URL 路径不能使用大写,单词如果需要分隔,统一使用下划线。
? c) 路径禁止携带表示请求内容类型的后缀,比如".json",".xml",通过 accept 头表达即可。
3) 请求方法:对具体操作的定义,常见的请求方法如下:
? a) GET:从服务器取出资源。
? b) POST:在服务器新建一个资源。
? c) PUT:在服务器更新资源。
? d) DELETE:从服务器删除资源。
4) 请求内容:URL 带的参数必须无敏感信息或符合安全要求;body 里带参数时必须设置 Content-Type。
5) 响应体:响应体 body 可放置多种数据类型,由 Content-Type 头来确定。
2.【强制】前后端数据列表相关的接口返回,如果为空,则返回空数组[]或空集合{}。
说明:此条约定有利于数据层面上的协作更加高效,减少前端很多琐碎的 null 判断。
3. 【强制】服务端发生错误时,返回给前端的响应信息必须包含 HTTP 状态码,errorCode、errorMessage、用户提示信息四个部分。
说明:四个部分的涉众对象分别是浏览器、前端开发、错误排查人员、用户。其中输出给用户的提示信息要求:简短清晰、提示友好,引导用户进行下一步操作或解释错误原因,提示信息可以包括错误原因、上下文环境、推荐操作等。 errorCode:参考附表 3。errorMessage:简要描述后端出错原因,便于错误排查人员快速定位问题,注意不要包含敏感数据信息。
正例:常见的 HTTP 状态码如下
1) 200 OK: 表明该请求被成功地完成,所请求的资源发送到客户端。
2) 401 Unauthorized: 请求要求身份验证,常见对于需要登录而用户未登录的情况。
3) 403 Forbidden:服务器拒绝请求,常见于机密信息或复制其它登录用户链接访问服务器的情况。
4) 404 Not Found: 服务器无法取得所请求的网页,请求资源不存在。
5) 500 Internal Server Error: 服务器内部错误。
4. 【强制】对于需要使用超大整数的场景,服务端一律使用 String 字符串类型返回,禁止使用Long 类型。
说明:Java 服务端如果直接返回 Long 整型数据给前端,JS 会自动转换为 Number 类型(注:此类型为双精度浮点数,表示原理与取值范围等同于 Java 中的 Double)。Long 类型能表示的最大值是 2 的 63 次方-1,在取值范围之内,超过 2 的 53 次 (9007199254740992)的数值转化为 JS 的 Number 时,有些数值会有精度损失。扩展说明,在 Long 取值范围内,任何 2 的指数次整数都是绝对不会存在精度损失的,所以说精度损失是一个概率问题。若浮点数尾数位与指数位空间不限,则可以精确表示任何整数,但很不幸,双精度浮点数的尾数位只有 52 位。
反例:通常在订单号或交易号大于等于 16 位,大概率会出现前后端单据不一致的情况,比如,“orderId”: 362909601374617692,前端拿到的值却是: 362909601374617660。
异常处理:
1.【推荐】方法的返回值可以为 null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回 null 值。
说明:本手册明确防止 NPE 是调用者的责任。即使被调用方法返回空集合或者空对象,对调用者来说,也并非高枕无忧,必须考虑到远程调用失败、序列化失败、运行时异常等场景返回 null 的情况。
2. 【推荐】防止 NPE,是程序员的基本修养,注意 NPE 产生的场景:
1) 返回类型为基本数据类型,return 包装数据类型的对象时,自动拆箱有可能产生 NPE。
反例:public int f() { return Integer 对象}, 如果为 null,自动解箱抛 NPE。
2) 数据库的查询结果可能为 null。
3) 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null。
4) 远程调用返回对象时,一律要求进行空指针判断,防止 NPE。
5) 对于 Session 中获取的数据,建议进行 NPE 检查,避免空指针。
6) 级联调用 obj.getA().getB().getC();一连串调用,易产生 NPE。
正例:使用 JDK8 的 Optional 类来防止 NPE 问题。
3. 【强制】捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
4. 【参考】对于公司外的 http/api 开放接口必须使用 errorCode;而应用内部推荐异常抛出;跨应用间 RPC 调用优先考虑使用 Result 方式,封装 isSuccess()方法、errorCode、errorMessage;而应用内部直接抛出异常即可。
说明:关于 RPC 方法返回方式使用 Result 方式的理由:
1)使用抛异常返回方式,调用方如果没有捕获到就会产生运行时错误。
2)如果不加栈信息,只是 new 自定义异常,加入自己的理解的 error message,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。
日志规约:
1.【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append()方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。
正例:logger.debug(“Processing trade with id: {} and symbol: {}”, id, symbol);
2.【推荐】尽量用英文来描述日志错误信息,如果日志中的错误信息用英文描述不清楚的话使用中文描述即可,否则容易产生歧义。
说明:国际化团队或海外部署的服务器由于字符集问题,使用全英文来注释和描述日志错误信息。
设计规约:
1.【强制】存储方案和底层数据结构的设计获得评审一致通过,并沉淀成为文档。
说明:有缺陷的底层数据结构容易导致系统风险上升,可扩展性下降,重构成本也会因历史数据迁移和系统平滑过渡而陡然增加,所以,存储方案和数据结构需要认真地进行设计和评审,生产环境提交执行后,需要进行 double check。
正例:评审内容包括存储介质选型、表结构设计能否满足技术方案、存取性能和存储空间能否满足业务发展、表或字段之间的辩证关系、字段名称、字段类型、索引等;数据结构变更(如在原有表中新增字段)也需要进行评审通过后上线。
2.【强制】如果系统中某个功能的调用链路上的涉及对象超过 3 个,使用时序图来表达并且明确各调用环节的输入与输出。
说明:时序图反映了一系列对象间的交互与协作关系,清晰立体地反映系统的调用纵深链路。
3.【推荐】类在设计与实现时要符合单一原则。
说明:单一原则最易理解却是最难实现的一条规则,随着系统演进,很多时候,忘记了类设计的初衷。
4.【推荐】谨慎使用继承的方式来进行扩展,优先使用聚合/组合的方式来实现。
说明:不得已使用继承的话,必须符合里氏代换原则,此原则说父类能够出现的地方子类一定能够出现,比如,“把钱交出来”,钱的子类美元、欧元、人民币等都可以出现。
5.【推荐】系统设计阶段,根据依赖倒置原则,尽量依赖抽象类与接口,有利于扩展与维护。
说明:低层次模块依赖于高层次模块的抽象,方便系统间的解耦。
6.【推荐】系统设计阶段,注意对扩展开放,对修改闭合。
说明:极端情况下,交付的代码是不可修改的,同一业务域内的需求变化,通过模块或类的扩展来实现。
7. 【推荐】系统设计阶段,共性业务或公共行为抽取出来公共模块、公共配置、公共类、公共方法等,在系统中不出现重复代码的情况,即 DRY 原则(Don’t Repeat Yourself)。
说明:随着代码的重复次数不断增加,维护成本指数级上升。随意复制和粘贴代码,必然会导致代码的重复,在维护代码时,需要修改所有的副本,容易遗漏。必要时抽取共性方法,或者抽象公共类,甚至是组件化。
正例:一个类中有多个 public 方法,都需要进行数行相同的参数校验操作,这个时候请抽取:
private boolean checkParam(DTO dto) {…}
8.【推荐】避免如下误解:敏捷开发 = 讲故事 + 编码 + 发布。
说明:敏捷开发是快速交付迭代可用的系统,省略多余的设计方案,摒弃传统的审批流程,但核心关键点上的必要设计和文档沉淀是需要的。
反例:某团队为了业务快速发展,敏捷成了产品经理催进度的借口,系统中均是勉强能运行但像面条一样的代码,可维护性和可扩展性极差,一年之后,不得不进行大规模重构,得不偿失。
9.【参考】设计文档的作用是明确需求、理顺逻辑、后期维护,次要目的用于指导编码。
说明:避免为了设计而设计,系统设计文档有助于后期的系统维护和重构,所以设计结果需要进行分类归档保存。
10.【参考】可扩展性的本质是找到系统的变化点,并隔离变化点。
说明:世间众多设计模式其实就是一种设计模式即隔离变化点的模式。
正例:极致扩展性的标志,就是需求的新增,不会在原有代码交付物上进行任何形式的修改。
11.【参考】代码即文档的观点是错误的,清晰的代码只是文档的某个片断,而不是全部。
说明:代码的深度调用,模块层面上的依赖关系网,业务场景逻辑,非功能性需求等问题是需要相应的文档来完整地呈现的。
未完待续~
