做SEO的同学和各位站长都知道,网站的原创内容在被大量收录后,适当的做一点白帽的刷流量,对于网站关键词排名提升还是有些好处的,本篇就先介绍一个用百度搜索来刷流量的简单Demo。
一、Demo系统设计思路
模拟真实用户在百度搜索网站关键词,在搜索结果中通过翻页查找到自己公司网站快照,然后点击快照链接跳转到公司网站来,通过模拟这个场景过程来提升网站关键词的热度和排名。
二、Demo系统功能特点
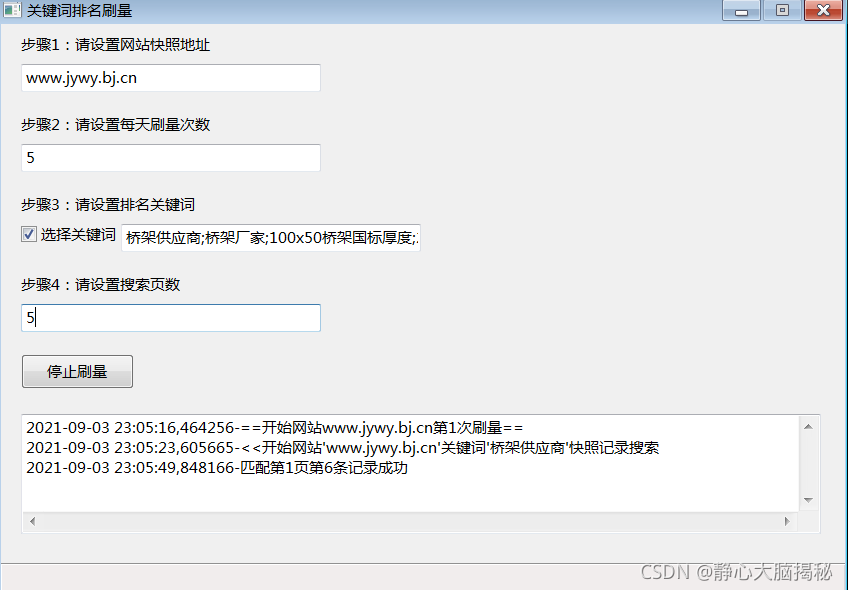
1、网站快照地址可设置:通过配置网站快照地址,可以实现对不同网站关键词进行刷量
2、每天刷量次数可设置:通过配置刷量次数,可以实现对不同网站不同关键词的刷量频率
3、排名关键词可设置:排名关键词可以从文件中读取,支持关键词增加、删除和修改。
4、搜索结果页数可设置:可以配置搜索结果翻页数,如果设置为5,则会从搜索结果前5页中查找公司网站快照,如果设置为10,则会从搜索结果前10页中查找公司网站快照。
5、支持人工中止刷量
6、支持记录刷量日志
三、Demo系统主要代码
代码段1、创建WebDriver浏览器驱动器,具体代码如下:
#创建浏览器驱动器
def createWebDriver():
# 配置参数
options = webdriver.ChromeOptions()
# 手动指定使用的浏览器位置
# options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
# 设置网页编码
options.add_argument('lang=zh_CN.UTF-8')
# 禁止加载图片
options.add_argument('blink-settings=imagesEnabled=false')
# 禁用显卡
# options.add_argument('--disable-gpu')
# 无界面模式
options.add_argument('--headless')
# 禁用浏览器正在被自动化程序控制的提示,目前看起来没啥用
# options.add_argument('--disable-infobars')
# 设置不同请求头
# useragent=['--User-Agent=Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0',
# '--User-Agent=Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6',
# '--User-Agent=Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11',
# '--User-Agent=Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)',
# '--User-Agent=Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0',
# '--User-Agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36']
# options.add_argument(useragent[random.randint(0, len(useragent)-1)])
# 针对IP代理的操作
# ip=getProxyId()
# logger.info("proxyIp:%s" % ip)
# options.add_argument('--proxy-server=http://%s' % ip)
driver = webdriver.Chrome(options=options, keep_alive=True)
# 防止selenium访问被识别出来,不算流量
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
return driver代码段2、定时任务线程,用来并发执行定时任务的,具体代码如下:
# 工作线程
class JobThread(threading.Thread):
def __init__(self,index,waitime):
threading.Thread.__init__(self)
self.index=index
self.waittime = waitime
self.bgntime=0
def run(self):
# 等待触发任务
while (not myframe.stop_refresh_page_thread) and self.bgntime<self.waittime:
time.sleep(1)
self.bgntime=self.bgntime+1
# 执行任务
runjob()
# 执行完成
my_logger_info(logger,'thread%d bgntime is %d second'%(self.index,self.bgntime))
# 人工停止结束或者等待指定时间才结束
def runIdleSomeTime(idletime):
bgntime = 0
while not myframe.stop_refresh_page_thread and bgntime < idletime:
time.sleep(1)
bgntime = bgntime + 1
代码段3、输入关键词进行百度搜索,从搜索结果中查找网站快照,具体代码如下:
# 寻找网站快照,找到点击打开
def findSiteSnapshot(driver,siteurl):
# 加载排名关键词
wdary=myframe.nowtask_keywordlist.split(";")
for n in range(len(wdary)):
# 1、加载登录页面
wd_s=wdary[n]
# wd=urllib.parse.quote(wdary[n])
wd=wd_s
url ="https://www.baidu.com/"
driver.get(url)
locator = (By.ID, 'kw')
WebDriverWait(driver, 1, 0.5).until(EC.presence_of_element_located(locator))
driver.find_element_by_id("kw").send_keys(wd)
submitinput=driver.find_element_by_id("su")
driver.execute_script("arguments[0].click();", submitinput)
# 获取主窗口句柄
mainpagehandle = driver.current_window_handle
locator = (By.LINK_TEXT,"下一页 >")
WebDriverWait(driver, 3, 0.5).until(EC.presence_of_element_located(locator))
sitelink_s=None
kuaizhaostr="百度快照"
includeurl = False
iskuaizhao = False
matchnum=0
my_logger_info(logger,"<<开始网站'%s'关键词'%s'快照记录搜索" % (siteurl,wd_s))
# 循环每页
pagenum = myframe.pagenuminput.GetValue()
pagenum = int(pagenum)
for pageindex in range(1,pagenum+1):
# 模拟在当前页查找关键词快照记录
runIdleSomeTime(random.randint(10, myframe.pagewaittime))
# 查找当前页记录
pagesource = driver.page_source
soup = BeautifulSoup(pagesource, "html.parser")
#记录条目 class有时候为 result c-container xpath-log new-pmd ,例如"200x100桥架国标厚度"
# 有时候为 result c-container new-pmd 例如"桥架"、"桥架安装"
recorddiv=soup.find_all(class_="result c-container xpath-log new-pmd")
if len(recorddiv)==0:
recorddiv = soup.find_all(class_="result c-container new-pmd")
# 循环当前页每个记录
for recordindex in range(len(recorddiv)):
includeurl = False
iskuaizhao = False
for link in recorddiv[recordindex].find_all("a"):
if link.text==kuaizhaostr:
iskuaizhao=True
if link.text.find(siteurl.replace("www.","")+"/")>-1:
sitelink_s=link
includeurl=True
if iskuaizhao and includeurl:
my_logger_info(logger,"匹配第%d页第%d条记录成功"%(pageindex,recordindex+1))
try:
sitelink = driver.find_element_by_link_text(sitelink_s.text)
driver.execute_script("arguments[0].click();", sitelink)
windows = driver.window_handles
driver.switch_to.window(windows[0])
matchnum+=1
except Exception as e:
info = traceback.format_exc()
my_logger_info(logger,info)
else:
pass
# logger.info("正在比对第%d页第%d条记录"%(pageindex,recordindex+1))
# 支持人工停止刷量
if (myframe.stop_refresh_page_thread):
break
# 支持人工停止刷量
if (myframe.stop_refresh_page_thread):
break
# 翻到下一页继续寻找
nextpagelink=driver.find_element_by_link_text("下一页 >")
if nextpagelink and nextpagelink.is_displayed():
driver.execute_script("arguments[0].click();", nextpagelink)
else:
break
# 支持人工停止刷量
if (myframe.stop_refresh_page_thread):
break
# 显示匹配记录数量
my_logger_info(logger,"网站'%s'关键词'%s'快照记录合计%d个"%(siteurl,wd_s,matchnum))
my_logger_info(logger,">>结束网站'%s'关键词'%s'快照记录搜索" % (siteurl,wd_s))
# 打印人工停止刷量日志
if (myframe.stop_refresh_page_thread):
my_logger_info(logger, "已经停止刷量")
四、Demo系统运行截图
?
有需要Demo源码的同学,可以扫描下面的微信信二维码付款购买,
 ?
?
?扫描付款时注意把转账单号记录下来,然后加微信 sfjsffjjj928 ,? 发送验证信息格式如下:
购买刷量Demo源码-转账单号
验证通过后,会发送Demo源码到你的微信。
?