????????本文演示如何使用Selenium爬取《率土之滨》藏宝阁账号信息(武将数量,武将姓名,战法数量,宝物数量,价格,收藏数量等等),因为不同的信息需要进行各种点击才能获取,因此需要使用动态网页自动化工具Selenium。本文仅供个人学习,不做商业用途。
准备工具python +?Selenium
????????这部分并非本文重点,Selenium安装及使用教程请参考:Python Selenium库的使用_凯耐的博客-CSDN博客_python selenium
使用Selenium打开《率土之滨》藏宝阁主页
? ? ? ? 本次演示的是使用的是火狐浏览器(使用别的浏览器也行)。
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://stzb.cbg.163.com/cgi/mweb/pl/role?view_loc=all_list')????????接下来,火狐浏览器就能自动打开《率土之滨》藏宝阁主页,发现需要进行账号登陆,此时可以手动输入账号密码登陆也可以自动登录。
? ? ? ? 输入账号密码登陆之后藏宝阁的商品列表就出现在网页中了。
?爬取第一个商品的信息
? ? ? ? ?点击审查元素,查看点击第一商品的区域,然后使用click()函数自动点击进入第一个商品。
browser.find_element_by_xpath('//div[@class="infinite-scroll list-block border"]/div/div/div[1]').click()
xmlps = etree.HTML(browser.page_source) # 保存页面xml?
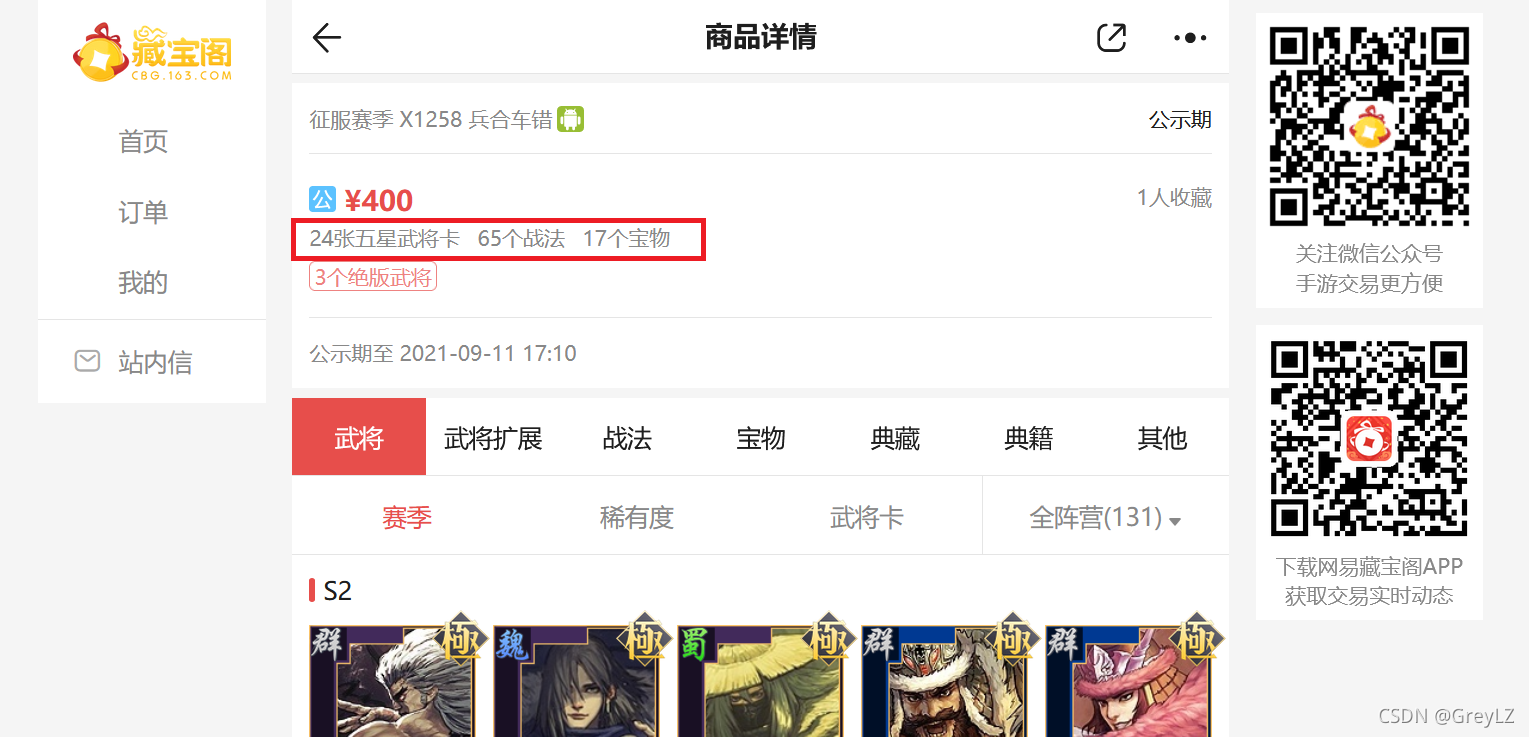
?收集武将数量,战法数量,宝物数量
? ? ? ? ?找到显示武将数量,战法数量,宝物数量的区域,打开审查元素。
?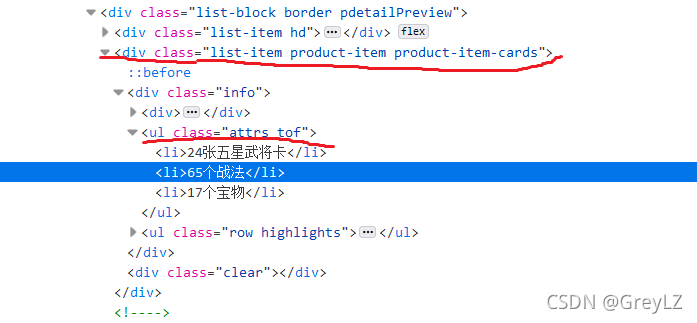
?找到div标签 class=list-item product-item product-item-cards 以及 ul标签class=attrs tof就能定位到武将数量,战法数量,宝物数量的区域。
count0 = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//ul[@class="attrs tof"]/li/text()')
counts = re.findall("\d+",str(count0)) # 找出字符串中的数字
WJcount = int(counts[0]) # 第一个数字代表武将数量
ZFcount = int(counts[1]) # 第二个数字代表战法数量
if counts.__len__()==2: # 第三个数字代表宝物数量
BWcount = 0
else:
BWcount = counts[2]?收集价格、收藏人数、客户端类型、典藏数量、战法名称
? ? ? ? 基本上是按照上述方法
# 价格
Price = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//div[@class="price-wrap"]/div[@class="price icon-text"]/span/text()')
#收藏人数
Favorites = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//span[@class="collect pull-right"]/text()')
# 客户端
Port = browser.find_element_by_xpath('//div[@class="color-gray"]/span[2]').get_attribute('class')
# 典藏数量
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[5]').click()
xmlps = etree.HTML(browser.page_source)
DCcount = xmlps.xpath('//div[@class="content"]//div[@class="product-content content-dian-cang"]/ul/li[@class="tab-item selected"]/text()')
# 战法名字
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[3]').click()
xmlps = etree.HTML(browser.page_source)
ZFname = xmlps.xpath('//div[@class="product-content content-card-extend"]/div[@class="module"]/ul[@class="skills"]/li/p[2]/text()')?收集武将信息
收集武将信息稍微有些不同,武将信息包括武将名字、所属势力以及进阶数量,而且不同账号拥有的武将总数也不一样。需要通过一个循环获取账号中的武将信息。
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[1]').click()
xmlps = etree.HTML(browser.page_source)
shili = list() # 武将所属势力
WJname = list() # 武将名字
WJStars = list() #武将进阶数量
for i in range(WJcount):
j = i+1
shili0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="wrap"]/div[2]/i/text()'% j)
WJname0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]/div/div[@class="name tC"]/text()'% j)
WJname0 = [XX.replace('\n','') for XX in WJname0] #去除\n
WJname0 = [XX.strip() for XX in WJname0]
WJStars0 = xmlps.xpath('count(//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="stars"]/div[@class="stars-wrap"]/span[@class="star up"])'% j)
shili.append(shili0)
WJname.append(WJname0)
WJStars.append(WJStars0)保存收集的数据
? ? ? ? 最后把所有收集的数据放到一个列表中,然后保存为json文件。
ACCOUNT0 = list()
ACCOUNT0.append(counts)
ACCOUNT0.append(Price)
ACCOUNT0.append(Favorites)
ACCOUNT0.append(Port)
ACCOUNT0.append(DCcount)
ACCOUNT0.append(shili)
ACCOUNT0.append(WJname)
ACCOUNT0.append(WJStars)
ACCOUNT0.append(ZFname)
?爬取多个商品的信息
? ? ? ? 需要通过鼠标进行下滑操作才能展开多个商品的信息(这个是可以通过Selenium实现的),下面贴出完整代码。
from selenium import webdriver
import lxml.etree as etree
import re
import json
import os
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import numpy as np
import pandas as pd
browser = webdriver.Firefox()
browser.get('https://stzb.cbg.163.com/cgi/mweb/pl/role?view_loc=all_list')
#滑到底部 获取账号总数
Accounts_num = 0
for i in range(40):
# js="window.scrollTo(0,document.body.scrollHeight)"
browser.execute_script('window.scrollTo(0,1000000)')
xmlps = etree.HTML(browser.page_source)
Accounts_num0 = xmlps.xpath('count(//div[@class="infinite-scroll list-block border"]/div/div/div[@class="product-item product-item-cards list-item list-item-link"])')
print('Accounts_num0:',Accounts_num0)
print('Accounts_num:',Accounts_num)
if Accounts_num0 > Accounts_num :
Accounts_num = Accounts_num0
else:
break
time.sleep(0.45)
# 收集一个账号信息的函数
def getDATA(index):
browser.find_element_by_xpath('//div[@class="infinite-scroll list-block border"]/div/div/div[%d]' % index).click()
# xmlps = etree.HTML(browser.page_source)
# 测试网页是否加载完毕
try:
element = WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="list-item product-item product-item-cards"]'))
)
xmlps = etree.HTML(browser.page_source)
finally:
print('网页加载完毕')
# 武将数量,战法数量,宝物数量
count0 = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//ul[@class="attrs tof"]/li/text()')
print(count0)
counts = re.findall("\d+", str(count0))
WJcount = int(counts[0])
ZFcount = int(counts[1])
if counts.__len__() == 2:
BWcount = 0
else:
BWcount = counts[2]
# 价格
Price = xmlps.xpath(
'//div[@class="list-item product-item product-item-cards"]//div[@class="price-wrap"]/div[@class="price icon-text"]/span/text()')
# 收藏人数
Favorites = xmlps.xpath(
'//div[@class="list-item product-item product-item-cards"]//span[@class="collect pull-right"]/text()')
# ios 或者 Android
Port = browser.find_element_by_xpath('//div[@class="color-gray"]/span[2]').get_attribute('class')
print(Port, index)
# 出售剩余时间
RestDays = xmlps.xpath('//div[@class="ft clearfix"]/p//span/text()')
# 抓取武将卡牌数据
# browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[1]').click()
# xmlps = etree.HTML(browser.page_source)
shili = list()
WJname = list()
WJStars = list()
for ji in range(WJcount):
j = ji + 1
shili0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="wrap"]/div[2]/i/text()' % j)
WJname0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]/div/div[@class="name tC"]/text()' % j)
WJname0 = [XX.replace('\n', '') for XX in WJname0] # 去除\n
WJname0 = [XX.strip() for XX in WJname0]
WJStars0 = xmlps.xpath(
'count(//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="stars"]/div[@class="stars-wrap"]/span[@class="star up"])' % j)
shili.append(shili0)
WJname.append(WJname0)
WJStars.append(WJStars0)
# 战法名字
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[3]').click()
xmlps = etree.HTML(browser.page_source)
ZFname = xmlps.xpath(
'//div[@class="product-content content-card-extend"]/div[@class="module"]/ul[@class="skills"]/li/p[2]/text()')
# 典藏数量
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[5]').click()
xmlps = etree.HTML(browser.page_source)
DCcount = xmlps.xpath(
'//div[@class="content"]//div[@class="product-content content-dian-cang"]/ul/li[@class="tab-item selected"]/text()')
ACCOUNT0 = list()
ACCOUNT0.append(counts)
ACCOUNT0.append(Price)
ACCOUNT0.append(Favorites)
ACCOUNT0.append(Port)
ACCOUNT0.append(RestDays)
ACCOUNT0.append(DCcount)
ACCOUNT0.append(shili)
ACCOUNT0.append(WJname)
ACCOUNT0.append(WJStars)
ACCOUNT0.append(ZFname)
# 数据保存
index = index + numAccount
with open('data003/account%d.json' % index, 'w') as Account:
json.dump(ACCOUNT0, Account)
print("第%d个数据保存完毕" % index)
browser.back() #返回前一个网页
time.sleep(0.2) #等待网页加载时间
# 通过循环获取多个账号信息
for i in range(Accounts_num):
index = i + 1
getDATA(index)收集完数据之后,就可以进行数据分析,例如使用随机深林分析、XGBoost、线性回归等方法分析不同的武将的价值,将会在下一篇文章展示。