文章目录
前言
Jmeter大家都有所了解,官网中都给我了哪些建议呢,一起来看看吧
一、官网地址
地址:https://jmeter.apache.org/usermanual/best-practices.html
二、最佳实践
推荐这个下面的内容最好都去了解下,这里我们看下如何减少资源需求,先看下原文

嗯。。。我英语不太溜,就直接翻译了

1.使用CLI模式
使用命令模式去运行。
我们每次启动Jmeter的时候,黑窗口就会有一些英文,不知道你们注意过没,大概翻译下,
不要使用GUI模式(图形化界面)去进行压测,仅仅用它作为创建测试和调试,如果进行压测的话,最好使用CLI模式,下面是命令
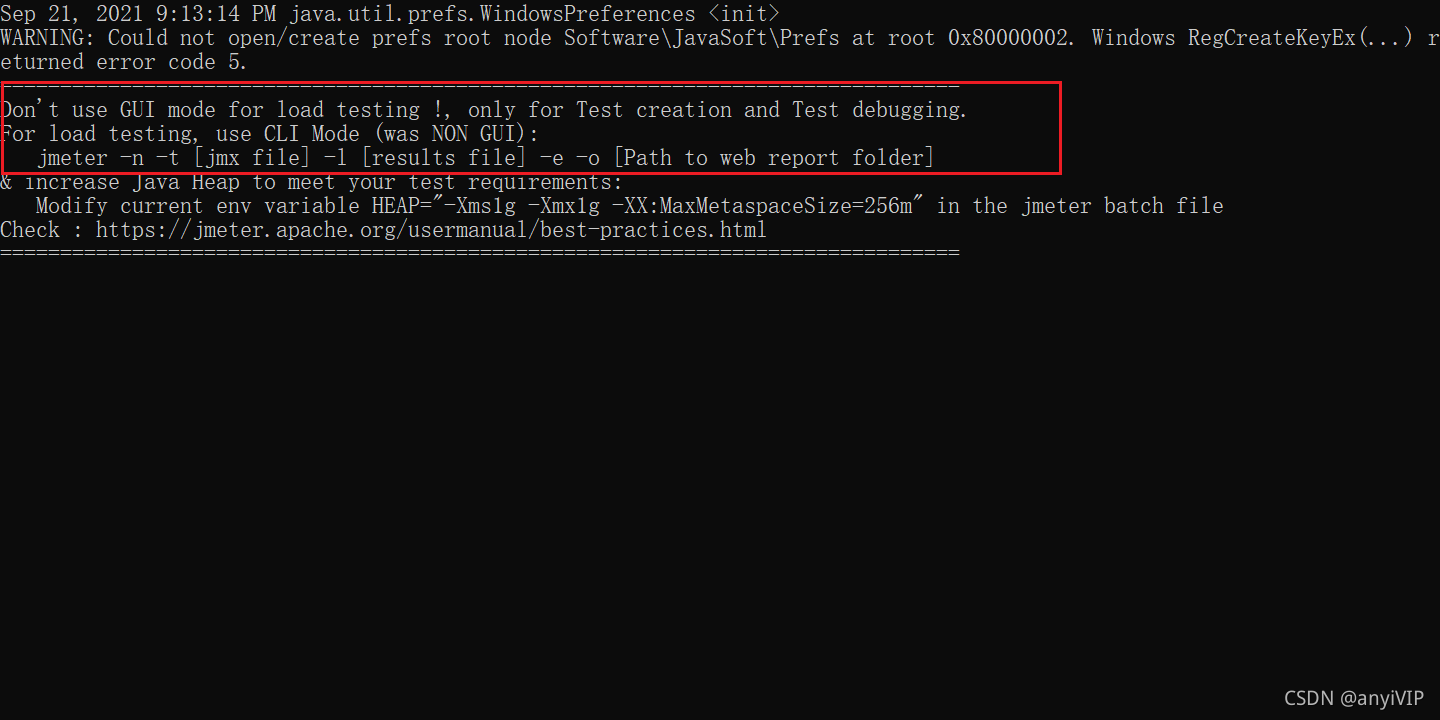
jmeter -n -t [jmx file] -l [results file] -e -o [Path to web report folder]
-n:非GUI模式执行
-t:测试计划保存路径
jmx file:测试计划文件名
-l:log,生成测试结果文件
results file:结果的文件名,有jtl和csv格式,到时候打开jmeter导入文件,选择jtl就能看到结果
-e:生成测试报告
-o:测试报告生成文件夹,文件夹必须为空,参数为文件夹路径
path to web report folder:生成HTML报告的路径
例子:
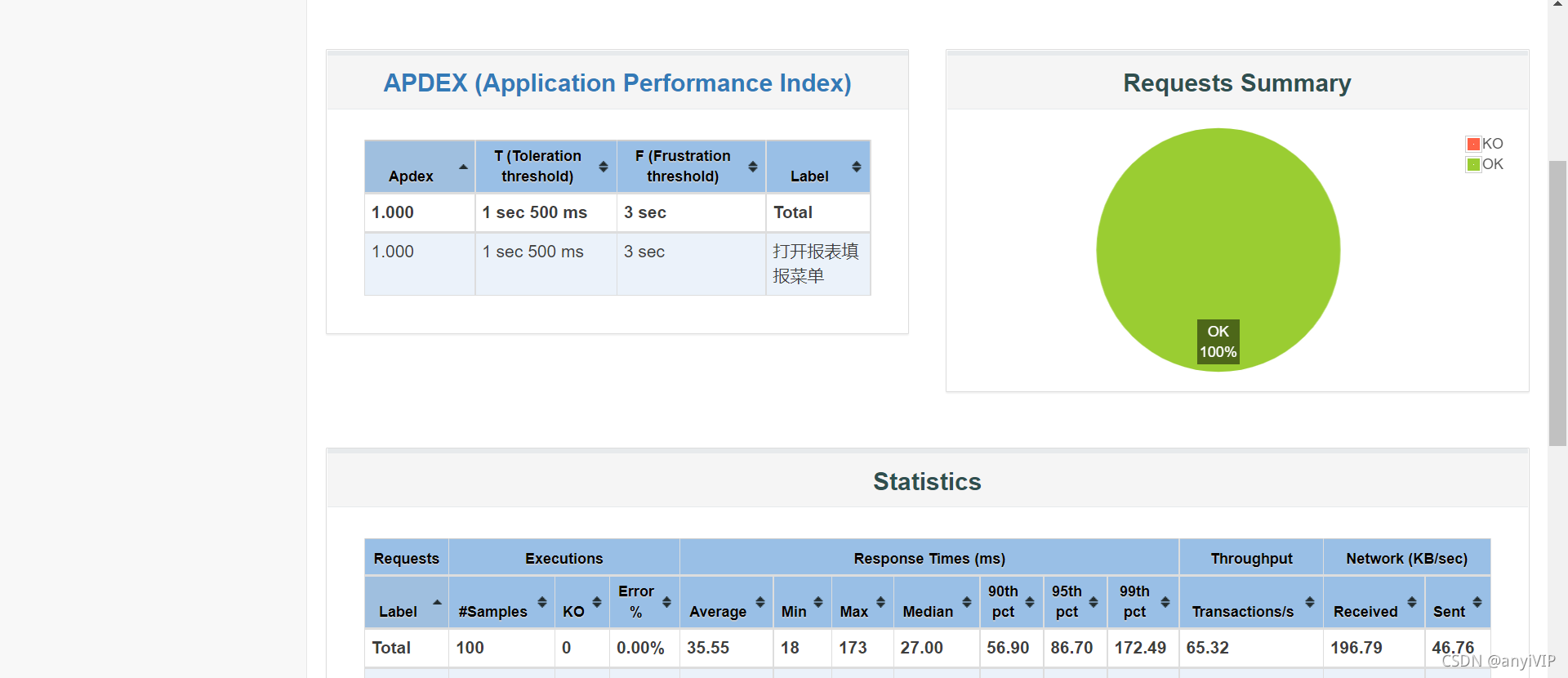
jmeter -n -t D:\yace\kjyace\script\08_test.jmx -l D:\yace\report\08_test.jtl -e -o D:\yace\report\08
这是生成的HTML报告
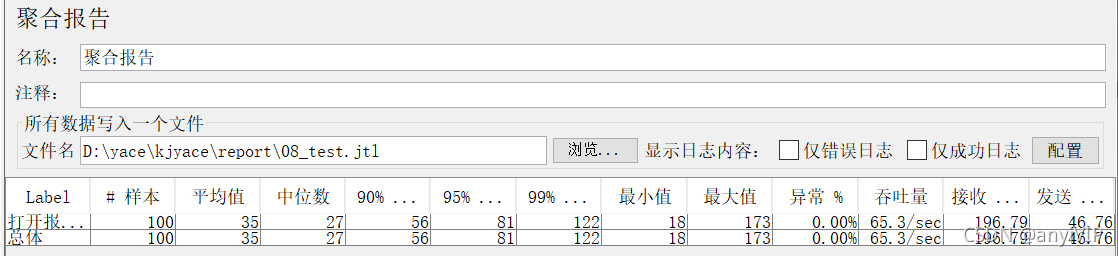
这是导入jtl文件的聚合报告
2.尽可能少地使用监听器
尽可能少地使用监听器;如果使用上面的-l标志,它们都可以被删除或禁用。
没有查看查看结果树的话,可能不便于我们排查问题,当请求比较多的时候,可以选择只查看错误日志,也可以减少一些资源。
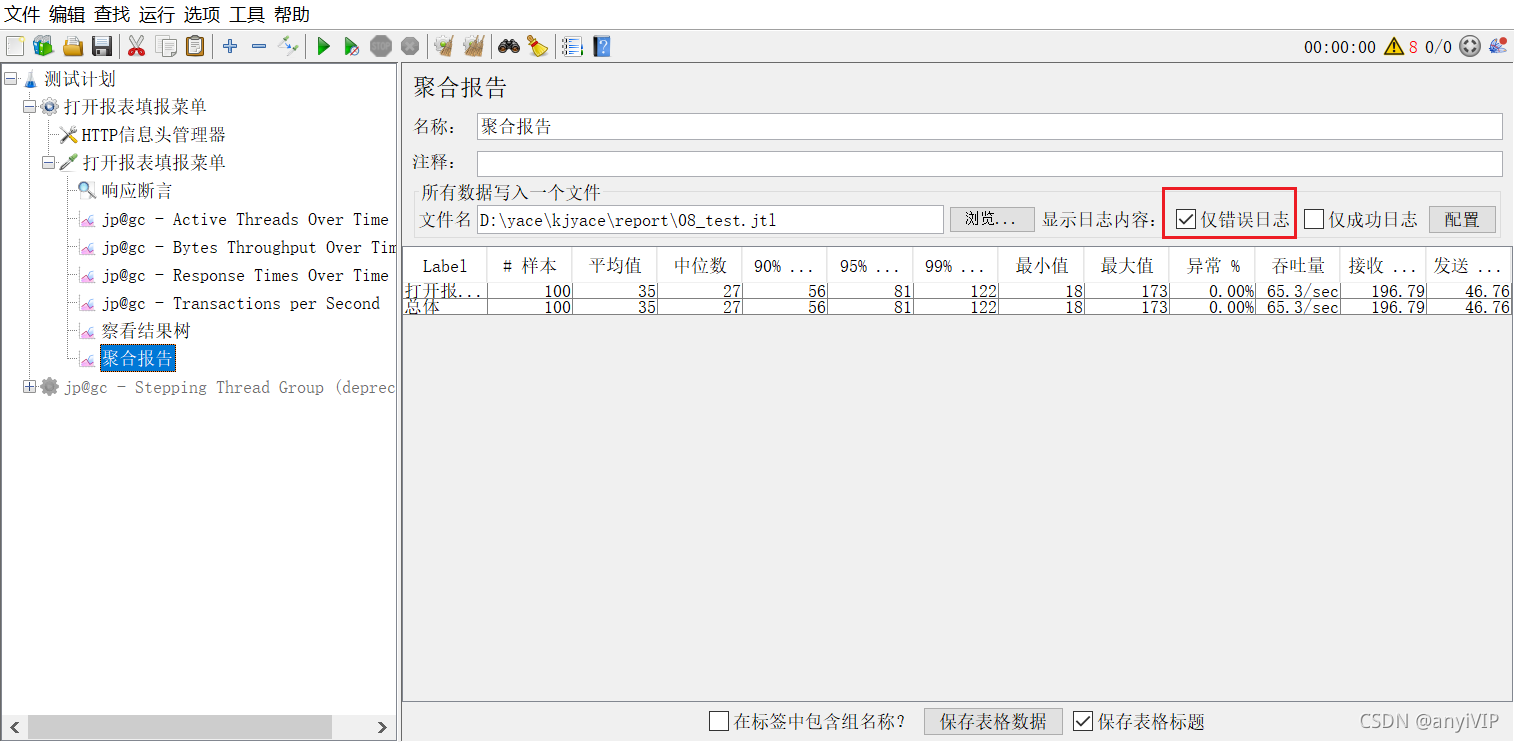
3.不要在负载测试期间使用“查看结果树”
不要在负载测试期间使用“查看结果树”或“在表中查看结果”侦听器,仅在脚本编写阶段使用它们来调试您的脚本,这个问题同上面。
4.使用CSV data
与其使用大量相似的采样器,不如在循环中使用相同的采样器,并使用变量(CSV 数据集)来改变样本。[Include Controller 在这里没有帮助,因为它将文件中的所有测试元素添加到测试计划中。]
额。。。这里我也没太看懂,个人见解,需要参数化的时候,可以使用csv来处理,如果多个线程或请求使用同一个文件,可以把它放在测试计划下面,避免每次都去循环读取。
例如:
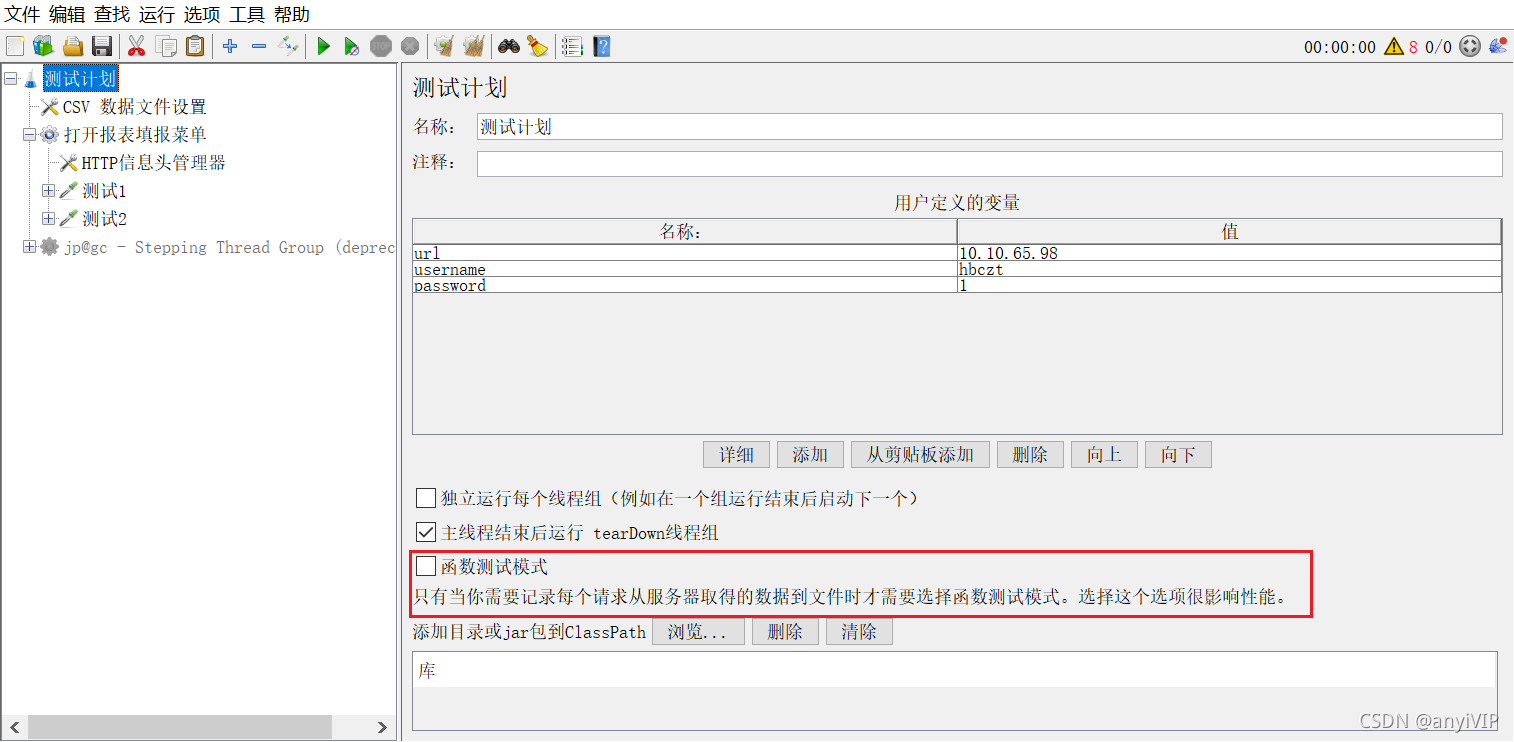
5.不要使用功能模式
之前还不知道这个模式在哪里,就在测试计划下面,因为我的已经是中文了,翻译之后叫函数测试模式,下面也给出了提示:只有当你需要记录每个请求从服务器取得的数据到文件时才需要选择函数测试模式。选择这个选项很影响性能。
6.使用 CSV 输出而不是 XML
使用 CSV 输出而不是 XML。平时一般保存结果文件的时候用的都是csv格式,xml几乎没用过,有了解的小伙伴可以留言探讨一下。
7.只保存您需要的数据
只保存您需要的数据。
8.尽可能少地使用断言
尽可能少地使用断言。额。。。这点对我来说有点难,因为不去做断言的话,我也不太清楚接口返回是对是错。
9.使用性能最好的脚本语言
使用性能最好的脚本语言(参见 JSR223 部分)。JSR223 有这几种语言,平时beanshell用的比较多,网上看了别人的对比,与Beanshell和Javascript相比,Groovy表现更好,有余力的小伙伴可以去对比下,是我们的性能测试指标更加准确。
JSR223 PostProcessor - Beanshell
JSR223 PostProcessor - Javascript
JSR223 PostProcessor - Groovy
有些也是第一次见到,翻译着对比看看,受到的启发也不少呢!给的建议很不错,我们在使用过程中可以往这方面去思考,写出不错的脚本!