【本文正在参与炫“库”行动――人大金仓有奖征文活动。
CSDN
https://marketing.csdn.net/p/98bd30353e7cb998b6070a89e8b91edb
】
运维篇
来到金仓的第一感觉可以用两个字形容:融洽,同事与同事之间都特别和睦,领导特别幽默,无论是金仓集体活动、还是部门的小活动,给我感觉到就是每个人都在积极参数且乐在其中,从工位上讨论技术问题,到午休吃饭讨论生活问题,同事们关系都特别好,我十分有幸加入金仓这个家庭。
在这里融入金仓指的是熟练使用金仓的产品,成为金仓一名优秀的技术人员。目前我加入了运维部门,负责金仓的KADB分布式数据库,简单分享一些分布式数据库的一些技术问题。
在测试数据库性能阶段,我最常用的几个工具有:jmeter、nmon、java。接下来简单说一下这些工具的应用场景与使用方法。Jmeter分为四个性能工具分别是:负载发生器、用户运行器、资源生成器、报表生成器。对jmeter的使用前提是要有java环境,windows的jmeter的使用添加线程组-配置元件-取样器,以JDBC做接口为例,可以自由选择接入数据库的方式,在配置元件处填写URL连接串,在取样器输入测试语句。
Jmeter的好用之处在于可以模拟多用户并发对数据库执行操作,并且通过加入不同监听器,可以实时掌握数据库的性能变换、响应时间(以可视化方式展现),但是有一点,进行操作后如果java缓存未能及时释放,jmeter就会报错;centos上操作也比较简单,通过保存windows下jmeter的xml文件使用命令:jmeter -n -t *.jmx -l result/report.jtl -e -o report来进行压测,有时java的缓存实在不够的话,就通过跑tpcds来压数据库性能。
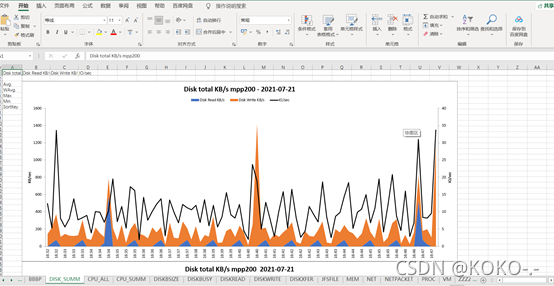
nmon是一个linux和AIX的性能分析工具,虽然平常可以用系统自带的top等命令来关注磁盘、CPU、网络等性能,但是nmon的优点是可以将性能检测结果保存下来,通过nmon的分析器生成一个excel的可视化表格,更为清晰的看到性能在一个时间段内的性能变动情况。
Java,功能十分强大,用的最多的还是在做数据库的扩、缩容等操作,为了能体现用户在进行业务,通过一个简单的不间断插入、查询等脚本来模拟用户在进行业务,观察扩容和缩容是否会影响业务的进行。并且可以通过java脚本来执行一个后台造数的操作。这是我利用java来进行的一些平常常用的操作,有更常用的操作还请各位多多指点。
在性能测试阶段,每个人有每个人各有一套的测试方法和测试工具,在此仅分享我个人的一个方式,要是有其它更方便的工具还请各位指点指点我。
KADB常见问题处理方式:
一、系统配置
1.配置时区:PostgreSQL中存储的可用时区 全部取自于Internet Assigned Numbers Authority (IANA) 时区数据库,一旦PostgreSQL的IANA数据库发生 改变,MPP数据库也 会随之更新它的可用时区列表。
查看当前集群所用时区:gpconfig -s TimeZone
修改集群时区:gpconfig -c TimeZone -v ‘US/Pacific’
修改完后需要重启MPP数据库:gpstop -ra
2.端口配置
ip_local_port_range要设置为不与MPP数据库端口范围冲突,例:/etc/sysctl.conf中的设置:
net.ipv4.ip_local_port_range = 10000 65535
客户端可以设置MPP数据库基础端口号为下列值:
PORT_BASE = 6000
MIRROR_PORT_BASE = 7000
3.数据倾斜
更改分布键:alter table t1 set distributed by (id);
查询各segment上数据条:select gp_segment_id,count(1) from t1 group by 1;
查询储存在每个segment上的数据的变异系数:
select * from gp_toolkit.gp_skew_coefficients;
skccoeff(CV)即变异系数,值越高数据倾斜越严重,越低越好
扫描系统空闲的百分数:
select * from gp_toolkit.gp_skew_idle_fractions;
siffraction值表示百分之多少的数据发生偏移
4.参数设置
初始化阶段
vm.overcommit_ratio:用来执行应用进程可以使用的内存百分比,剩余的内存留给操作系统。/etc/sysctl.conf
gp_resource_group_memory_limit:系统分配给MPP数据库的内存百分比
/home/mppadmin/dbdata/master/mppseg-1
gp_workfile_limit_files_per_query:用以限制每个查询允许使用的临时溢出文件的最大数量,当查询所需的内存比它所能分配的更多时,就会创建溢出文件,查询会被终止,设为0即默认允许无限多的溢出文件,弊端在于会填满文件系统。
gp_vmem_protect_limit:可以设置实例可以为每个segment数据库中执行的所有工作分配的最大内存
KADB常用拓展功能:
FTP多数据库集成:以ORACLE-KADB为例
配置pxf拓展环境
root用户下
设置环境变量(每个节点安装java并配置变量)
cat >> ~/.bashrc <<EOF(每个节点)
export PXF_CONF=/home/mppadmin/pxf
export PATH=/home/mppadmin/mpp/pxf/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-5.uel20.aarch64
EOF
source ~/.bashrc

加载拓展
su - mppadmin
psql postgres
create extension pxf;
下载异构数据库JDBC驱动,登录到mppadmin并拷贝到各台服务器的/home/mppadmin/mpp/pxf/lib/shared目录,如:

cp *.jar /home/mppadmin/mpp/pxf/lib/shared
scp *.jar mppadmin@mpp200:/home/mppadmin/mpp/pxf/lib/shared


初始化pxf服务
pxf cluster init
pxf cluster start
操作异构数据库
(1) Oracle
配置连接信息
使用mppadmin用户在mppadmin家目录下操作:
mkdir $PXF_CONF/servers/oracle
cp $PXF_CONF/templates/jdbc-site.xml $PXF_CONF/servers/oracle
vi $PXF_CONF/servers/oracle/jdbc-site.xml
(编辑内容,按照选项填写连接参数),如:

<property>
<name>jdbc.driver</name>
<value>oracle.jdbc.driver.OracleDriver</value>
<description>Class name of the JDBC driver (e.g. org.postgresql.Driver)</description>
</property>
<property>
<name>jdbc.url</name>
<value>jdbc:oracle:thin:@192.168.0.34:1521/prod</value>
<description>The URL that the JDBC driver can use to connect to the database (e.g. jdbc:postgresql://localhost/postgres)</description>
</property>
<property>
<name>jdbc.user</name>
<value>scott</value>
<description>User name for connecting to the database (e.g. postgres)</description>
</property>
<property>
<name>jdbc.password</name>
<value>scott</value>
<description>Password for connecting to the database (e.g. postgres)</description>
</property>
EOF
同步配置到所有节点: pxf cluster sync pxf cluster restart
在oracle的scott用户下创建测试表,查看监听是否开启,若处于关闭状态,需要启动监听
打开另一终端操作oracle
ssh 192.168.0.34
su - oracle
lsnrctl status
lsnrctl start
sqlplus / as sysdba
startup;
conn scott/scott
CREATE TABLE pxf_oracle(id int);
INSERT INTO pxf_oracle VALUES (1);
INSERT INTO pxf_oracle VALUES (2);
INSERT INTO pxf_oracle VALUES (3);
commit;
在kadb中test库中创建读外部表(若库不存在,自己创建)
psql postgres
\c test;
create extension pxf;
CREATE EXTERNAL TABLE pxf_read_oracle(id int)
LOCATION (‘pxf://pxf_oracle?PROFILE=Jdbc&SERVER=oracle’)
FORMAT ‘CUSTOM’ (FORMATTER=‘pxfwritable_import’);
在kadb中查询oracle表数据
select * from pxf_read_oracle;
在kadb中test库创建写外部表
CREATE WRITABLE EXTERNAL TABLE pxf_write_oracle(id int)
LOCATION (‘pxf://pxf_oracle?PROFILE=Jdbc&SERVER=oracle’)
FORMAT ‘CUSTOM’ (FORMATTER=‘pxfwritable_export’);
在kadb写入oracle表数据
INSERT INTO pxf_write_oracle VALUES (111);
INSERT INTO pxf_write_oracle VALUES (222);
INSERT INTO pxf_write_oracle VALUES (333);
在oracle中查询表数据
select * from pxf_oracle;
管理MPP数据库
MPP启停工具位于MPP数据库master主机$PGHOME/bin目录下
:gpstart gpstop
不要用kill命令直接杀死任何后台Postgres,可以使用数据库内命令
pg_cancel_backend()
使用kill -9 或kill -11可能引发数据库损坏并且妨碍目前数据库的表现进行问题根源分析
移除膨胀的方法:
――vacuum :对于频繁更新的表定期运行vacuum,过期行所占用的空间可以被迅速的重用,防止表文件生长的更大,在做analyze表前先vacuum得到的statistic信息效果更好
――vacuum full :当表文件生长的足够大,积累了显著的膨胀时,运行vacuum命令并不能起到明显作用,此时运行vacuum full tablname能够回收导致空闲空间映射溢出的行所使用的空间并且减小表文件的尺寸
弊端:对应的表被上ACCESS EXCLUSIVE锁,只能等待vacuum full操作完成后才可继续服务
――拷贝换名:创建一个将过期行排除在外的表拷贝,删除原始表,最后将拷贝的表换名为原来的表名,例:
gpadmin=# CREATE TABLE mytable_tmp AS SELECT * FROM mytable; --拷贝
gpadmin=# DROP TABLE mytable; --删表
gpadmin=# ALTER TABLE mytabe_tmp RENAME TO mytable; --换名
――修改分布列:
把表的分布列记下来。
把该表的分布策略改为随机分布:
ALTER TABLE mytable SET WITH (REORGANIZE=false) DISTRIBUTED randomly;
这会为该表更改分布策略,但不会移除任何数据。该命令应该会立即完成。
将分布策略改回其初始设置:
ALTER TABLE mytable SET WITH (REORGANIZE=true) DISTRIBUTED BY ();
这一步会重新分布数据。因为表之前是用同样的分布键分布的,表中的行只 需要简单地在同一Segment上重写 即可,同时排除过期行。
――从索引移除膨胀
vacuum操作只会从表中恢复空间,移除膨胀还可以从索引中恢复空间,需要使用reindex命令来重建索引;
要在一个表上重建所有的索引,可以运行:reindex table_name
要重建一个特定的索引可运行:reindex index_name
――从系统目录移除膨胀
MPP数据库系统目录也是堆表,且随时间推移变得膨胀,数据库对象的增删改操作都会将过期行留在系统目录。
使用gpload装载数据会加剧膨胀。gpload会创建并且删除外部表
以下是较为彻底解决系统目录膨胀的步骤。
停止MPP数据库上所有系统目录操作。
在系统目录表上执行REINDEX操作来重建系统目录索引。该操作可以移除索 引膨胀 并提高VACUUM性能。
在系统目录表上执行VACUUM FULL操作。注意关注下面提到的注意事项。
在系统目录表上执行ANALYZE操作来更新系统目录表的统计信息。
Note: 系统目录表pg_attribute通常是这里面最大的表。如果pg_attribute 表明显膨胀,在该表上的VACUUM FULL操作会占用很长时间,此时可能需要将操作分解。
以下两种情形表明pg_attribute表存在明显膨胀并可能需要运行长时间的VACUUM FULL 操作:
pg_attribute表包含大量记录。
Mpp数据库最佳实践 gp_toolkit.gp_bloat_diag视图中有关pg_attribute表 的诊断信息上显示该表存在明显膨胀。
gplogfilter -t,在master日志中搜索ERROR、FATAL等报错日志
参数:路径/home/mppadmi/dbdata/master/mppseg-1/postgresql.conf
log_rotation_size: 配置参数设置单独一个日志文件的循环触发大小。当前日志文件大小大于等于该值时,该文件被关闭并新建另一个日志文件
log_rotation_age:配置参数指定当前日志文件的循环触发年龄。当从该文件创建到目前的时间达到该设置时,创建一个新的日志文件。默认的log_rotation_age为1d(1天),当前日志文件写完后,会创建一个新的以天Mpp数据库最佳实践为单位的文件