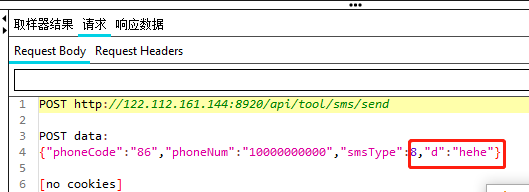
|
之前已经介绍过了jmeter的安装以及部分简单使用,这篇文章主要用来详细描述Jmeter的界面功能
jmeter界面包括五个部分:标题栏、菜单栏、常用工具栏、测试计划标签、测试计划标签内容’

标题栏
记录计划的标题、jmeter的版本信息
菜单栏
文件

| 子菜单 | 描述 |
|---|
| 新建 | 新建一个测试用例 | | 模板 | 常用用例模板指导 | | 打开 | 打开一个新的jmx文件 | | 最近打开 | 打开最近使用过的jmx文件 | | 合并 | 合并多个jmx文件 | | 保存测试计划 | 保存当前编辑的测试计划,不包括测试工作台相关内容 | | 保存测试计划为 | 将当前编辑的测试计划保存为另一个指定的jmx文件,不包括测试工作台内容的相关编辑 | | 选中部分保存为 | 将当前编辑的测试计划选中部分,另存为一个指定的jmx文件,包括测试工作台内容的相关编辑 | | 保存为测试片段 | 只能保存除线程组、测试计划、工作台之外的测试片段 | | 还原 | 将修改后的jmx还原为上一次已经保存过的jmx | | 重启 | 重新启动jmeter |
模板-Templates:
| 用例模板 | |
|---|
| BeanShell Sampler | 简单的BeanShell用例 (BeanShell 一种类似于java的脚本语言) | | Building a SOAP WebService Test Plan | 创建一个SOAP web服务的测试计划(SOAP 一种简单XML协议,使程序通过HTTP进行通信) | | Building a Web Test Plan | 创建一个web测试用例 | | Building an Advanced Web Test Plan | 创建一个优化版本的测试计划 | | Building an Extended LDAP Test Plan | 创建一个扩展的LDAP测试用例 (LDAP 一种轻型目录访问协议,通过IP协议提供访问控制和维护分布式信息的目录信息,常用于单点登录) | | Building an LDAP Test Plan | 创建一个LDAP测试计划(LDAP 一种轻型目录访问协议,通过IP协议提供访问控制和维护分布式信息的目录信息,常用于单点登录) | | Building an FTP Test Plan | 创建一个FTP测试计划(FTP 一种文件传输协议) | | Functional Testing Test Plan [01] | 功能测试测试计划 | | JDBC Load Test | JDBC压力测试(JDBC java数据库) | | MongoDB Load Test | MongoDB压力测试 | | JSR223 Sampler using Groovy | 使用Goovy的JSR223用例(JSR223 java中的script脚本引擎) | | Recording | 录制脚本 | | Recording with Think Time | 录制带有思考时间的脚本(更真实模拟用户操作) | | Think Time at a point | 在某时刻设置思考时间 |
OverView:模板简介
Useful links:使用帮助文档链接
编辑
(对选中的标签进行处理(也可选中相应标签,右击鼠标))

| 子菜单 | 功能 |
|---|
| 添加 | 为计划添加相关测试组件 | | 粘贴 | 将剪切板中的组件内容粘贴至计划中(仅限于计划下的一级子菜单内容) | | 打开 | 打开一个已存在的jmx文件 | | 合并 | 将多个jmx文件合并成一个jmx文件(仅合并单个文件,不将文件内容合并) | | 选中部分保存为 | 将当前计划另存为一个jmx文件 | | 保存节点为图片 | 将当前标签内容保存为图片形式 | | 保存屏幕为图片 | 将当前整个jmeter屏幕保存为图片形式 | | 启用 | 启用当前组件 | | 禁用 | 禁用当前组件 | | 切换 | 当前选中取样器禁用和启用两种状态的切换 | | 帮助 | 官方帮助使用jmeter文档 |
- 选中线程,点击编辑(或者右击鼠标):

| 子菜单 | 功能 |
|---|
| 添加 | 添加线程下的相关组件 | | 剪切 | 剪切当前线程组至剪切面板 | | 复制 | 复制当前线程组 | | 粘贴 | 将剪切面板中的线程下的相关组件复制到该线程下 | | 复写 | 复制一份相同的线程组至当前测试计划下 | | 删除 | 删除该线程组 | | 打开 | 打开一个已存在的 .jmx文件 | | 合并 | 将其它线程组与当前选中线程组进行合并 | | 选中部分保存为 | 将当前线程组保存为一份jmx文件 | | 保存节点为图片 | 将当前线程组界面内容保存为一张图片形式 | | 保存屏幕为图片 | 将当前整个JMetre界面保存为图片形式 | | 启用 | 启用当前选中的线程组 | | 禁用 | 禁用当前选中的线程组 | | 切换 | 切换当前线程组的启用和禁用状态 | | 帮助 | 跳转至介绍线程组使用的官方文档 |
- 选中取样器,点击编辑(或者右击鼠标)

| 子菜单 | 功能 |
|---|
| 添加 | 在取样器下添加相关元件 | | 插入上级 | 在当前取样器上一级插入逻辑控制器,控制取样器的执行 | | 剪切 | 将当前取样器剪切至剪切面板中 | | 复制 | 复制当前取样器 | | 粘贴 | 将剪切板中的取样器下包含的元件复制到当前取样器下 | | 复写 | 复制一份相同的取样器至当前线程组下 | | 删除 | 删除当前取样器 | | 打开 | 打开一个已存在的 .jmx文件 | | 合并 | 将其它jmx文件的取样器内容合并至当前取样器下 | | 选中部分保存为 | 将当前取样器的内容保存为另一份 .jmx文件 | | 保存为测试片段 | 将当前取样器脚本保存为可复用的测试片段,可在其它模块中进行添加复用 | | 保存节点为图片 | 将当前取样器内容保存为图片形式 | | 保存屏幕为图片 | 将当前JMetre界面保存为图片形式 | | 启用 | 启用该取样器 | | 禁用 | 禁用该取样器 | | 切换 | 切换取样器的禁用和启用状态 | | 帮助 | 点击至介绍取样器使用的官方文档 |
- 选中元件,点击编辑(或者右击鼠标):
监听器会多一个子菜单:清除,其它子菜单功能均与上述子菜单类似
查找
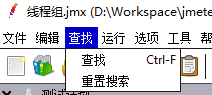
| 子菜单 | 功能 |
|---|
| 查找 | 查找/替换标签树中相匹配的标签,点击search All 会将所有模糊匹配成功的标签都标红,只有点击重置搜索,才可恢复 | | 重置搜索 | 取消查找标记 |

运行
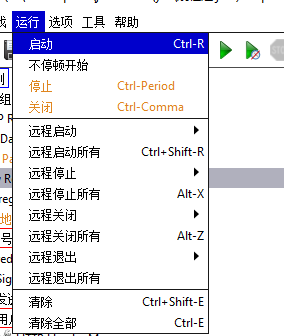
| 子菜单 | 功能 |
|---|
| 启动 | 运行启用状态下的线程组 | | 不停顿开始 | 直接不停顿运行,忽略定时器 | | 停止 | 停止测试计划的运行 | | 关闭 | 关闭测试计划 | | 远程启动 | 指定一个远程代理运行测试计划 | | 远程启动所有 | 让所有远程代理运行测试计划 | | 远程停止 | 指定一个远程代理停止运行测试计划 | | 远程停止所有 | 让所有远程代理停止运行测试计划 | | 远程关闭 | 关闭一个指定的远程代理 | | 远程关闭所有 | 关闭所有远程代理 | | 远程退出 | 指定一个远程代理退出执行 | | 远程退出所有 | 所有远程代理退出执行 | | 清除 | 清除选择菜单中的运行结果数据 | | 清除全部 | 清除所有历史运行结果数据 |
选项
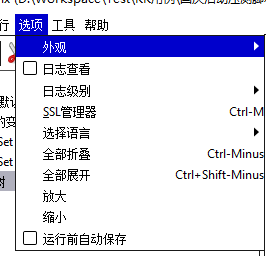
| 子菜单 | 功能 |
|---|
| 外观 | 界面展示选择,主要是字体及背景颜色、边框线的区别 | | 日志查看 | 查看运行日志,启用后会在标签内容下出现 | | 日志级别 | 选择需要查看相应级别的日志,有6种 | | SSL管理器 | 选择相应的SSL证书(在进行https请求时,需要安装SSL证书),每次重启jmeter都需要选择一次 | | 选择语言 | 选择jmeter使用的描述语言 | | 全部折叠 | 折叠所有标签 | | 全部展开 | 展开所有标签 | | 放大 | 放大整个界面的内容 | | 缩小 | 缩小整个界面的内容 | | 运行前自动保存 | 在每次运行测试计划前都自动保存编辑内容 |
工具

| 子菜单 | 功能 |
|---|
| 创建一个堆转储 | 创建当JVM崩溃的堆转储(堆转储是某个时间点应用程序内存的快照),这个文件可以用堆分析工具(如JHAT),以确定根本原因进行分析 | | 创建一个线程转储 | 创建当JVM崩溃的线程转储 (线程转储是某个时间点在应用程序中运行的所有线程的快照) | | 函数助手对话框 | 在编写脚本的时候,使用函数助手可以协助生成指定的代码,比入随机码,正则过滤等 | | Generate HTML report | 将测试结果输出为html报告 | | Compile JSR223 Test Elements | 编译JSR223测试元素 | | 导出交换报告 | 导出交换报告 | | Generate Schematic View(alpha) | 生成结构数视图 | | Import from cURL | 导入 |
函数助手对话框:生成相对应的函数字符串

可选函数:
| 函数 | 功能 |
|---|
| BeanShell | 执行传递的脚本,返回相应的结果 | | changeCase | 更改大小写功能返回一个字符串值 | | char | 将一串数字翻译成Unicode字符 | | counter | 计数器,可配置为独立计数器(统计测试计划执行了多少次)或者全局计数器(统计总共请求了多少次) | | CSVRead | 从CSV文件读取一个字符串,遇到空行停止读取,遇到逗号断行,需区分文件名大小写。支持从多个文件中读取 | | dataTimeConvert | 时间戳转为本地时间 | | digest | 摘要函数在特定的哈希算法中返回加密的值,并带有可选的salt,大写字母和变量名 | | escapeHtml | 将字符转换为HTML格式的字符 | | escapeOroRegexpChars | 把正则表达式转换成Java正则引擎能识别的表达式 | | escapeXML | 转义字符串中的字符(使用HTML实体),例如,“bread” & "butter"变为"bread" & "butter" | | eval | 执行一个字符串表达式,并返回执行结果.可以对字符串(存储在变量中)中的变量和函数引用做出修改。例如,给定变量name=Smith、column=age、table=birthdays、SQL=select ${column} from ${table} where name=’${name}’,那么通过${__eval(${SQL})},就能执行"select age from birthdays where name=‘Smith’" | | evalVar | 执行保存在变量中的表达式,并返回执行结果。用户可以从文件中读取一行字符串,并处理字符串中引用的变量。例如,假设变量 query 中包含有 select ${column} from ${table} ,而 column 和 table 中分别包含有 name 和 customers ,那么${__evalVar(query)}将会执行 select name from customers | | FileToString | 用来读取设置的整个文件,与StringFromFile区别在于,StringFromFile读取的是字符串,并非一次性读取整个文件 | | groovy | 执行Apache Groovy脚本,并返回结果 | | intSum | 用来计算多个整数值的和,最后一个指定的包含字母的参数为其它参数求和的结果变量名,结果变量名非必填 | | IsPropDefined | 判断属性是否存在 | | isVarDefined | 判断变量是否存在 | | javaScript | 执行javaScript代码片段,可作为脚本语言做计算 | | jexl2 | 用于执行通用JEXL表达式,并返回执行结果 | | jexl3 | 用于执行通用JEXL表达式,并返回执行结果 | | log | 记录日志,并返回函数的输入字符串 | | logn | 记录日志,返回空字符串 | | longSum | 用来计算多个长整型的和,最后一个指定的包含字母的参数为其它参数求和的结果变量名,结果变量名非必填 | | machineIP | 返回本地IP地址 | | machineName | 返回本机主机名 | | p | 简化版的属性函数,目的是使用命令行中定义的属性,若默认值未设定,则默认为1 | | property | 返回一个Jmeter属性的值,如果函数没有返回属性值,也没有指定默认值,则将返回属性的名称 | | Random | 指定最大值和最小值之间的随机数,并指定结果变量名,结果变量名非必填 | | RandomDate | 返回位于给定开始日期和结束日期值之间的随机日期 | | RandomFromMultipleVars | 根据源变量提供的变量值返回一个随机值 | | RandomString | 随机字符串函数 | | regexFunction | 正则表达式函数,可使用正则表达式解析之前服务器响应/变量值,也可用于保存变量值,便于后期调用 | | samplerName | 返回当前采样器的名称 | | setProperty | 设置JMeter属性值,默认返回空字符串,属性对于JMeter是全局的,可以被用来在线程和线程组之间通信 | | split | 通过分隔符来拆分传递的字符串,并返回原始的字符串。连接在一起的分隔符将会返回变量值 ?,拖尾的分隔符也会被认为缺少一个变量,返回 ? | | StringFromFile | 从文本文件中一行一行地读取字符串,用于处理大文件数据,类似于配置元件CSV Data Set Config的功能。打开/读取文件发生错误时,返回Error | | StringToFile | 用于将字符串写入文件。每次调用它时,它都会向文件中写入一个字符串,并追加或覆盖该字符串,默认返回空字符串 | | TestPlanName | 返回当前测试计划的名称 | | threadGroupName | 返回当前线程组的名字 | | threadNum | 线程编号,无函数参数,不可使用于配置元件中(不同线程可能拥有相同的线程编号) | | time | 通过设置不同格式返回当前时间 | | timeShift | 计算时间差,不填写任何参数则返回当前时间 | | unescape | 反转义Java-escaped字符串 | | unescapeHtml | 反转义一个包含HTML实体的字符串,将其变为包含实际Unicode字符的字符串,例如,字符串"<Français>“变为”<Fran?ais>" | | urldecode | 使用UTF8编码方案解密application/x-www-form-urlencoded这种类型的字符串 | | urlencode | 加密一个字符串成为application/x-www-form-urlencoded类型的字符串 | | UUID | 返回伪随机类型4通用唯一标识符(UUID) | | V | 执行变量名表达式,并返回执行结果,可以被用于执行嵌套函数引用 | | XPath | 读取XML文件,并在文件中寻找与指定XPath相匹配的地方。每调用函数一次,就会返回下一个匹配项。到达文件末尾后,会从头开始,如果没有匹配的节点,那么函数会返回空字符串,另外,还会向JMeter日志文件写一条警告信息 |
| 函数参数 | 函数参数描述 |
|---|
| TRUE,每个用户有自己的计数器;FALSE,使用全局计数器 | 指定全局计数器或者独立计数器 | | 存储结果的变量名(可选) | 指定存储计数值的变量 |
| 函数参数 | 函数参数描述 |
|---|
| 用于获取值的CSV文件 | *别名 | 设置从哪个文件读取(或者*ALIAS),使用*ALIAS特性可以多次打开同一个文件,另外还能缩减文件名称 | | CSV文件列号| next| *alias | 从文件的哪一列读取。0 =第一列, 1 =第二列,依此类推。next为走到文件的下一行。*ALIAS为打开一个文件,并给它分配一个别名 |
注意:
1、如果希望在输入的列中使用逗号,那么需要换一个分隔符(通过设置属性csvread.delimiter来实现),且该符号没有在CSV文件的任何列中出现
2、每一个线程都有独立的内部指针指向文件数组中的当前行。当某个线程第一次引用文件时,函数会为线程在数组中分配下一个空闲行。如此一来,任何一个线程访问的文件行,都与其他线程不同(除非线程数大于数组包含的行数)
3、当对某个文件进行第一次读取时,文件将被打开并读取到一个内部数组中,一旦数据量大,将会占用大量内存空间,因此不适用于大数据文件,大数据文件可选择使用StringToFile函数或者CSV Data Set进行存取
- dataTimeConvert

| 函数参数 | 函数参数描述 |
|---|
| 格式化时间 | 被转换的时间,为空时,表示当前时间戳,精确到毫秒 | | 源时间格式 | 被转换时间转换前的时间格式 | | 目标时间格式 | 被转换时间转换后的时间格式 | | 存储结果的变量名(可选) | 转换后时间的引用变量名 |
- digest

| 函数参数 | 函数参数描述 |
|---|
| 算法摘要 | 加密算法,常见的有MD2、MD5、SHA-1、SHA-224、SHA-256、SHA-384、SHA-512 | | String to be hashed | 需加密的字符串 | | Salt to be used for hashing (optional) | 用于计算散列的盐(可选项) | | Upper case result, defaults to false (optional) | 结果是否为大写,默认为小写(False),大写为True | | 存储结果的变量名(可选) | 存储加密结果的引用名 |
| 函数参数 | 函数参数描述 |
|---|
| 输入文件的全路径 | 包含路径的文件名(路径可以是相对于JMeter启动目录的相对路径) | | File encoding if not the platform default (opt) | 读取文件需要用到的文件编码方式。如果没有指明就使用平台默认的编码方式 | | 存储结果的变量名(可选) | 引用名(refName)用于重用函数创建的值 |
- javaScript

| 函数参数 | 函数参数描述 |
|---|
| JavaScript expression to evaluate | 待执行的JavaScript代码片段 | | 存储结果的变量名(可选) | 指定结果变量名,方便后期调用 |
常见调用变量:
| 变量 | 描述 |
|---|
| Log | 该函数的日志记录器 | | Ctx | JmeterContext对象 | | Vars | JmeterVariables对象 | | threadName | 字符串包含当前线程名称 | | sampler | 当前采样器对象 | | sampleResult | 前面的采样结果对象 | | props | JMeter属性对象 | | 通过它的包对象来访问静态方法 | example:访问JMeterContextService静态方法 Packages.org.apache.jmeter.threads.JMeterContextService.getTotalThreads() |
注意:为文本字符串添加必要的引号以及对类似于逗号一类字符用 \ 进行转义
| 函数参数 | 函数参数描述 |
|---|
| String to be logged (and returned) | 待记录的字符串 | | Log level (default INFO) or OUT or ERR | 日志级别,OUT、ERR、DEBUG、INFO(默认)、WARN或者ERROR | | Throwable text (optional) | 可抛弃的文本,如果非空,会创建一个可抛弃的文本传递给记录器 | | Additional comment (optional) | 注释, 会在字符串中展示,用于标识日志记录了什么 |
注意:OUT 和ERR的日志级别,将会分别导致输出记录到System.out和System.err中。在这种情况下,输出总是会被打印(它不依赖于当前的日志设置)
| 函数参数 | 函数参数描述 |
|---|
| String to be logged | 待记录的字符串 | | Log level (default INFO) or OUT or ERR | 日志级别,OUT、ERR、DEBUG、INFO(默认)、WARN或者ERROR | | Throwable text (optional) | 可抛弃的文本,如果非空,会创建一个可抛弃的文本传递给记录器 |
注意:OUT 和ERR的日志级别,将会分别导致输出记录到System.out和System.err中。在这种情况下,输出总是会被打印(它不依赖于当前的日志设置)
- RandomDate

| 函数参数 | 函数参数描述 |
|---|
| Format string for DateTimeFormatter (optional) (default yyyy-MM-dd) | 生成的随机日期的格式 | | 开始时间(可选)(默认:现在) | 可取随机时期开始时间 | | 结束时间 | 可取随机日期结束时间 | | String format of a locale (ex: fr_FR , en_EN) (optional) | 日期相关的地区信息 | | 存储结果的变量名(可选) | 存储随机日期的引用变量名 |
| 函数参数 | 函数参数描述 |
|---|
| Source Variable(s) (use | as separator) | 源数据的变量名,如a|b|c,此时a、b、c均为赋值过的变量,此处不可直接填写源数据 | | Target Variable | 随机获取到的值的引用变量名 |
- RandomString

| 函数参数 | 函数参数描述 |
|---|
| Random string length | 随机字符的长度 | | Chars to use for random string generation | 用来生成随机字符串的字符,可以是纯数字,纯字符,字符字母数字组合 | | 存储结果的变量名(可选) | 生成的随机字符串变量名 |
| 函数参数 | 函数参数描述 |
|---|
| 用于从前一个请求搜索结果的正则表达式 | 第1个参数是用于解析服务器响应数据的正则表达式。它会找到所有匹配项。如果测试人员希望将表达式中的某部分应用在模板字符串中,一定记得为其加上圆括号。例如,< a href="(.)" >。这样就会将链接的值存放到第一个匹配组合中(这里只有一个匹配组合)。又如,<input type=“hidden” name="(.)“value=”(.*)">。在这个例子中,链接的name作为第一个匹配组合,链接的value会作为第二个匹配组合。这些组合可以用在测试人员的模板字符串中(必填项) | | Template for the replacement string, using groups from the regular expression. Format is
[
g
r
o
u
p
]
[group]
[group]. Example
1
1
1. | 这是一个模板字符串,函数会动态填写字符串的部分内容。要在字符串中引用正则表达式捕获的匹配组合,请使用语法:
[
g
r
o
u
p
n
u
m
b
e
r
]
[group_number]
[groupn?umber]。例如
1
1
1或者
2
2
2 (必填项) | | Which match to use. An integer 1 or greater, RAND to indicate JMeter should randomly choose, A float, or ALL indicating all matches should be used ([1]) | 第3个参数告诉JMeter使用第几次匹配。填写的正则表达式可能会找到多个匹配项。对此,有4种选择:整数,直接告诉JMeter使用第几个匹配项。"1"对应第一个匹配,"2"对应第二个匹配,以此类推;RAND,告诉JMeter随机选择一个匹配项;ALL,告诉JMeter使用所有匹配项,为每一个匹配项创建一个模板字符串,并将它们连接在一起;浮点值0到1之间,根据公式(找到的总匹配数目*指定浮点值)计算使用第几个匹配项,计算值向最近的整数取整 。默认为1(非必填项) | | Between text. If ALL is selected, the between text will be used to generate the results ([""]) | 如果在上一个参数中选择了“ALL”,那么这个参数会被插入到重复的模板值之间(非必填项) | | Default text. Used instead of the template if the regular expression finds no matches ([""]) | 如果没有找到匹配项返回的默认值(非必填项) | | 存储结果的变量名(可选) | 重用函数解析值的引用名,如果输入"refName"作为该参数变量名,则:$ {refName}为第2个参数(Template for the replacement string)的计算结果;$ {refName_g0}为函数解析后发现的所有匹配结果;$ {refName_g1}为函数解析后发现的第一个匹配组合;$ {refName_gN}为函数解析后发现的第N个匹配组合;${refName_matchNr}为函数总共发现的匹配组合数目 (非必填项) | | Input variable name containing the text to be parsed ([previous sample]) | 输入变量名称。如果指定了这一参数,那么该变量的值就会作为函数的输入,而不再使用前面的采样结果作为搜索对象(非必填项) |
| 函数参数 | 函数参数描述 |
|---|
| 属性名称 | 待设置的属性名 | | Value of property | 属性的值 | | Return Original Value of property (default false)? | 是否返回属性的初始值,选择True的话,函数会返回该属性的初始值 |
- split

| 函数参数 | 函数参数描述 |
|---|
| String to split | 待拆分的字符串 | | 函数名称。用于存储在测试计划中其他的方式使用的值。 | 重用函数计算值的引用名称 | | String to split on. Default is , (comma). | 分隔符,默认使用逗号作为分隔符,若手动设置逗号为空格符,则需要对逗号进行转义:\, |
- StringFromFile

| 函数参数 | 函数参数描述 |
|---|
| 输入文件的全路径 | 文件名(可以使用相对于JMeter启动目录的相对路径)。如果要在文件名中使用可选的序列号,那么文件名必须适合转成十进制格式,文件名需要使用格式字符串java.text.DecimalFormat。如果要在文件名中使用可选的序列号,当前的序列号会作为唯一的参数。如果不指明可选的初始序列号,就使用文件名作为起始值。一些有用的格式序列如下:#:插入数字,不从零开始,不包含空格(pin#:pin1,pin2,…);000:插入数字,包含3个数字组合,不从零开始(pin000:pin001,pin002,…) | | 存储结果的变量名(可选) | 一个引用名(refName),目的是复用这一函数创建的值。可以使用语法${refName}来引用函数创建的值。默认值为“StringFromFile_” | | Start file sequence number (opt) | 初始序列号(如果省略这一参数,终止序列号会作为一个循环计数器) | | Final file sequence number (opt) | 终止序列号(如果省略这一参数,序列号会一直增加下去,不会受到限制) |
注意:如果不希望某个格式字符被翻译,需要为它加上单引号,如"."是格式字符,必须被单引号所包含
| 函数参数 | 函数参数描述 |
|---|
| Path to file (absolute) | 文件名的路径(路径为绝对路径) | | String to write | 要写入文件的字符串,如果需要在内容中插入换行符,请在字符串中使用\n | | Append to file (true appends, false overwrites, default true) | 写入字符串的方法,true表示追加,false表示覆盖。如果未指定,则默认附加为true | | Charset (defaults to UTF-8) | 用于写入文件的编码。如果未指定,则默认编码为UTF-8 |
- time

| 函数参数 | 函数参数描述 |
|---|
| Format string for SimpleDateFormat (optional) | 当前时间返回的格式,默认以毫秒的形式返回当前时间 | | 存储结果的变量名(可选) | 结果返回的变量名 |
时间采用的格式:
| 时间格式 | 描述 |
|---|
| YMd | yyyyMMdd,年月日,eg:20211020 | | Hms | HHmmss,时分秒,eg:173440 | | YMdHms | 年月日时分秒,eg:2021102931710653 |
- timeShift

| 函数参数 | 函数参数描述 |
|---|
| Format string for DateTimeFormatter (optional) (default unix timestamp in millisecond) | 格式化时间,如果不填,时间戳精确到毫秒,如果填了,就格式化输出时间 | | 转换时间(可选)(默认:现在) | 需进行处理的时间 | | Amount of seconds/minutes/hours/days to add (e.g. P2D : plus two days) (optional) | 时间位移,第一位:负号或正号,负号表示整个时间相减;正号或者不填表示相加;第二位p或者P,表示后面跟具体位移数和单位;第三位:数字+单位’D’,表示天;第四位:‘T’,表示后面跟时分秒和单位;第五位:数字+单位’H’,表示小时;第六位:数字+‘M’,表示分钟,第七位:数字+‘S’,表示秒。数字可以是正数或负数;天\时\分 前的数字为整数,秒,可以是小数。如在当前日期上增加 2 天 4 小数 6 分 10.234 秒:p2dt4h6m10.234s)} | | String format of a locale (ex: fr_FR , en_EN) (optional) | 区域语言 | | 存储结果的变量名(可选) | 计算后结果的引用变量名 |
eg:存在变量A1、A2和N=1
${A1} = A1变量的值
${A${N}}:无法正常工作(嵌套变量引用)
${__V(A${N})}:可以正常工作。A${N}变为A1,函数 __V返回变量值A1
| 函数参数 | 函数参数描述 |
|---|
| XML file to get values from | 一个待解析的XML文件名 | | XPath expression to match against | 一个XPath表达式,用于在XML文件中寻找目标节点 |
使用时可参考网上XPath表达式语法
Generate HTML report

点击Generate report:

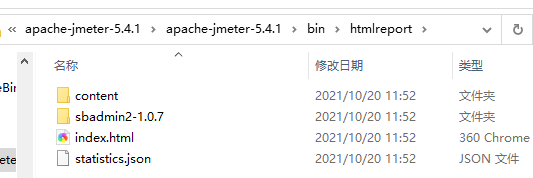
生成的测试报告:

注:jmeter.properties文件中有个output_format的属性配置,如果不是默认的csv格式,在生成报告时,会报错
帮助
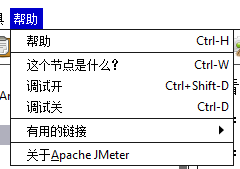
| 子菜单 | 描述 |
|---|
| 帮助 | 点击后跳转至Apache JMeter官方使用文档介绍界面 | | 这个节点是什么? | 点击后将在控制台打印出当前选中标签的GUI 和测试元件的类名 | | 调试开 | 开启debug调试日志记录 | | 调试关 | 关闭debug调试日志记录 | | 有用的链接 | 点击后可访问apache Jmeter官网版本发布信息、发布页、组件介绍、变量属性介绍 等链接 | | 关于Apache JMetre | 当前使用的Apache JMetre的版本信息 |
常用工具栏
从菜单栏提取出来的常用工具,鼠标悬浮可展示图标功能

测试计划标签及内容
线程(用户)
| 子菜单 | 描述 |
|---|
| setUp线程组 | 在其他线程执行开始前自动执行的预操作,一般用于准备测试数据 | | tearDown线程组 | 在所有线程执行完毕后自动执行,一般用于测试清理工作,删除数据、回收等 | | 线程组 | 正式执行的普通线程组 |
配置元件:
| 子菜单 | 描述 |
|---|
| CSV Data Set Config | 导入批量数据,用来模拟大量用户并发场景 | | HTTP信息头管理 | 设置HTTP头部信息 | | HTTP Cookie管理器 | Cookie管理器,会在登录成功后,自动存储cookie值,用于之后的请求 | | HTTP缓存管理器 | 向HTTP请求添加缓存,模拟浏览器缓存功能。会对照当前时间检查“Cache-Control/Expires”值。如果请求是GET请求,并且时间戳记在缓存之后,则取样器将立即返回,而无需从远程服务器请求URL | | HTTP请求默认值 | 设置请求默认携带的param参数、请求,每次请求将会自动携带该部分信息 | | Bolt Connection Configuration | 提供给Bolt Request取样器使用的Bolt连接池(表示咱目前不懂) | | DNS缓存管理器 | 允许测试在负载平衡器(CDN等)后面有多个服务器的应用程序;在每次迭代时分别解析每个线程的名称,并将解析结果保存到其内部DNS缓存中,该缓存独立于JVM和系统DNS缓存 | | FTP默认请求 | FTP(文件传输协议)默认请求,配置相应请求信息进行上传或者下载文件 | | HTTP授权管理器 | 设置自动对一些需要验证的页面进行验证和登录 | | JDBC Connection Configuration | 数据库连接设置,需下载相应的数据库连接jar包使用 | | Java默认请求 | 配合java 请求使用,设置请求时携带的默认值,每个java请求都会携带该配置中的值 | | Keystore Configuration | 秘钥库配置,允许配置密钥库的加载方式以及它将使用的密钥,通常用于HTTPS方案中,在响应时间内不考虑秘钥初始化时间 | | LDAP扩展请求默认值 | 配合LDAP默认请求使用,设置请求默认值(LDAP:轻型访问目录协议) | | LDAP默认请求 | 向LDAP服务器发送不同的LDAP请求(添加、修改、删除和搜索) (LDAP:轻型访问目录协议) | | Random Variable | 随机变量 | | TCP取样器配置 | 配合TCP取样器发送TCP协议请求 | | 用户定义的变量 | 配置用户常使用的默认变量值 | | 登陆配置元件/素 | 用来配置取样器验证的默认用户名和密码,如可配置所要测试的服务器的用户名和密码 | | 简单配置元件 | 允许在取样器中添加或覆盖任意值,主要是供开发人员在开发新的JMeter组件时使用的基本GUI | | 计数器 | 根据配置的递增规则,产生递增的变量值 |
监听器:可参考 https://copyfuture.com/blogs-details/202008041651527922ld7vnymru0bwps 但更推荐查看官网描述
| 子菜单 | 描述 |
|---|
| 查看结果树 | 展示每一个取样器的结果、请求信息和响应信息,可以查看这些内容分析脚本是否存在问题,请求是否出错 | | 汇总报告 | 为测试中的每个不同命名的请求创建一个表行,统计测试数据,分析被测系统的性能,相比较聚合报告消耗更低的内存 | | 聚合报告 | 统计测试数据,分析测试被测系统的性能 | | 后端监听器 | 异步侦听器,可以将数据推入都数据库中 | | JSR223 Listener | JSR223脚本代码应用于示例结果,得出自己想要的结果格式 | | 保存响应到文件 | 创建一个响应数据文件。它的主要用途是创建功能测试,也可以应用于因响应太大而无法显示在视图结果树侦听器中的场景 | | 响应时间图 | 查看整个请求过程响应时间的变化图 | | 图形结果 | 以曲线图展示出TPS、响应时间、偏差等数据 | | 断言结果 | 可以文件形式保存测试过程中的所有请求断言结果 | | 比较断言可视化器 | 显示任何比较断言元素的结果 | | 汇总图 | 表格数据结果展示成图表 | | 生成概要结果 | 在日志文件和/或标准输出中生成到目前为止的测试运行摘要。显示运行和差异总计。在适当的时间边界上,每n秒(默认为30秒)生成一次输出,以便同步在同一时间上的多个测试运行 | | 用表格查看结果 | 为每个示例结果创建一行,与查看结果树一样,使用大量内存 | | 简单数据写入器 | 将结果记录到文件中,但不能记录到UI中。它旨在通过消除GUI开销来提供记录数据的有效方法 | | 邮件观察仪 | 可在服务器多次响应失败时,使用该元件发送email | | BeanShell Listener | 允许使用BeanShell处理样本以进行保存等 |
定时器:
作用域:
1、定时器是在每个sampler(采样器)之前执行的,而不是之后(无论定时器位置在sampler之前还是下面);
2、当执行一个sampler之前时,所有当前作用域内的定时器都会被执行;
3、如果希望定时器仅应用于其中一个sampler,则把定时器作为子节点加入
| 子菜单 | 描述 |
|---|
| 固定定时器 | 控制请求的时间间隔,延迟请求到达服务器的时间,模拟真实用户的行为;获取服务端某些数据之前加固定定时器,用以确保之前的请求已经在服务端生成了数据。(固定定时器的延时不会计入单个sampler的响应时间,但会计入事务控制器的时间) | | 统一随机定时器 | 控制请求的时间间隔,延迟请求到达服务器的时间。这个延迟的时间是随机的,延时时间在指定范围内且每个时间的取值概率相同,每个时间间隔都有相同的概率发生,总的延迟时间就是随机值和偏移值之和:总的延时 = 固定延迟时间 + 随机生成的延时 | | Precise Throughput Timer | 精确吞吐量计时器,此计时器引入了可变暂停,计算的目的是使总吞吐量(例如,以每分钟样本数为单位)尽可能接近给定的数字)。用于揭发并发问题 | | Constant Throughput Timer | 常数吞吐量定时器,此计时器引入可变暂停,计算时使总吞吐量(以每分钟样本数为单位)尽可能接近给定的数字,尽管计时器被称为恒定吞吐量计时器,但吞吐量值不需要恒定。它可以通过变量或函数调用来定义,并且可以在测试期间更改值 | | JSR223 Timer | 用于使用JSR223脚本语言生成延迟 | | Synchronizing Timer | 同步定时器,将相同请求的线程组集合到一起进行释放,可以瞬间产生很大的压力,模拟并发测试 | | 泊松随机定时器 | 在每个线程请求之前按随机的时间停顿(这个随机时间符合泊松分布,更符合自然停顿时间),大部分的时间间隔出现在一个特定的值,总的延迟就是泊松分布值和偏移值之和 | | 高斯随机定时器 | 在每个线程请求之前按随机的时间停顿(这个随机时间符合高斯分布,更符合自然停顿时间),总的延时 = 固定延迟时间 + 高斯随机生成的偏差值 | | BeanShell Timer | 用于自定义编程设置取样器延时时间 |
Precise Throughput Timer 配置元素:
| 元素 | 描述 |
|---|
| Target throughput (in samples per ‘throughput period’) | 每个“吞吐量周期”(包括组中的所有线程)从所有受影响的采样器获取的最大样本数吞吐量周期 | | Throughput period (seconds) | 吞吐量周期。例如,如果“吞吐量”设置为42,“吞吐量周期”设置为21秒,则每秒将获得2个样本 | | Test duration (seconds) | 这用于确保在“测试持续时间”时间段内获得吞吐量*持续时间样本。 | | Number of threads in the batch (threads) | 如果该值超过1,则多个线程同时离开计时器。平均吞吐量仍然满足“吞吐量”值 | | Delay between threads in the batch (ms) | 例如,如果设置为42,且批大小为3,则线程将在x、x+42ms、x+84ms处离开 | | Random seed (change from 0 to random) | 注意:不同的计时器最好具有不同的种子值。恒定种子确保计时器在每次测试启动时产生相同的延迟。值“0”表示计时器是真正随机的(从一个执行到另一个执行不可重复)。。 |
Constant Throughput Timer配置元素:
| 元素 | 描述 |
|---|
| Target throughput(in samples per minute) | 目标吞吐量(单位分钟),即每分钟要求发出的吞吐量(QPS) | | Calculate Throughput based on | 计算吞吐量策略 | | This thread only | 仅对当前线程,也就是每个线程相互是不干扰的,都互相分开计算需要多少延迟时间(总吞吐量=Target throughput乘以线程数 | | All active threads | 设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程 | | All active threads in current thread group | 设置的target Throughput将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和All active threads选项的效果完全相同 | | All active threads(shared) | 线程延迟计算是基于任意一个线程上次运行的时间,也就是随便获取一个线程的运行时间来计算,既然是随机,结果就不一定准确,所以只能是努力控制吞吐量在某一个范围 | | All active threads in current thread group (shared) | 在当前线程组中任取一个线程的上次运行时间来计算延时,与上面意思相近 |
Synchronizing Timer 配置元素:
| 元素 | 描述 |
|---|
| Number of Simulated users to Group by | 集合点集合够N个用户开始并发,如果设置为0,等同于设置为线程租中的线程数量 | | Timeout in milliseconds | 如果设置为0,Timer将会等待线程数达到了“Number of Simultaneous Users toGroup”中设置的值才释放。如果大于0,那么如果超过Timeout inmilliseconds中设置的最大等待时间(毫秒为单位)后还没达到“Number of Simultaneous Users toGroup”中设置的值,Timer将不再等待,释放已到达的线程。默认为0 |
前置处理器:在取样之前运行
| 子菜单 | 描述 |
|---|
| JSR223 PreProcessor | 使用JSR223脚本获取取样器所需要的的准备数据,如登录时对相关传参进行加密 | | 用户参数 | 对不同用户设置相应的传参变量 | | HTML链接解析器 | 用于从前一个sampler返回的html页面中按照规则解析链接和表单(input/textarea/select/option等),再根据此处理器所在的sampler中的规则进行匹配修改 | | HTTP URL 重写修饰器 | 专用于使用url重写来存储sessionId而非cookie的http request。Session Argument Name参数:sessionID存储的名称。应用场景:系统只允许登录成功的用户才可以访问系统,当用户登录成功后返回一个SessionID(或者JsessionId)给用户,后续访问都需要验证这个SessionID | | JDBC PreProcessor | 数据库预处理器,用于在sample开始前查询数据库并获取一些值,参考JDBC Request | | 取样器超时 | 用于设定sample的超时时间,如果完成时间过长,此预处理器会调度计时器任务以中断样本 | | 正则表达式用户参数 | 使用正则表达式为从另一个HTTP请求中提取的HTTP参数指定动态值,配合regular expression extractor使用 | | BeanShell PreProcessor | 使用java脚本获取取样器所需要的的准备数据,如登录时对相关传参进行加密 |
后置处理器:发出“取样器请求”之后执行一些操作
| 子菜单 | 描述 |
|---|
| CSS/Query提取器 | 通过css选择器定位页面元素并读取数据 | | JSON JMESPath Extractor | 使用JMESPath查询语言从Json结果中提取值,只支持提取一个变量 | | JSON提取器 | 使用JSON-PATH语法从JSON格式的响应中提取数据,支持提取多个个变量 | | 正则表达式提取器 | 使用正则表达式从服务器响应中提取值 | | 边界提取器 | 填写左右边界提取服务器响应的值 | | JSR223 PostProcessor | 使用JSR223脚本提取服务器响应值 | | Debug PostProcessor | 调试后置处理程序,脚本调试,察看结果树可以看到取样器的相关变量、系统相关属性、JMeter相关变量与属性 | | JDBC PostProcessor | JDBC后置处理器,相当于JDBC Request,可发送JDBC请求 | | XPath2 Extractor | 可以使用XPath2查询语言从结构化响应(XML或(X)HTML)中提取值 | | XPath提取器 | 提取请求返回的消息为xml或html格式的数据 | | 结果状态处理器 | 控制请求遇到错误后执行的操作 | | BeanShell PostProcessor | jBeanShell后置处理器,可使用java编写脚本处理服务器响应内容或者提取响应值 |
断言:
| 子菜单 | 描述 |
|---|
| 响应断言 | 对各种返回类型的结果进行断言 | | JSON断言 | 针对响应结果是applicaton/json格式的请求进行断言 | | 大小断言 | 对服务器响应返回的结果字节大小进行断言 | | JSR223 Assertion | 针对取样器中的JSR223 sampler而使用的断言 | | XPath2 Assertion | 断言测试文档的格式是否良好 | | Compare Assertion | 比较断言可用于比较其范围内的样本结果。可以比较内容或经过的时间,并且可以在比较之前过滤内容。断言比较可以在“ 比较断言可视化器”中看到,负载测试中不可使用,因为它消耗大量资源(内存和CPU) | | HTML断言 | 针对sampler中的SOAP/XML-RPC Request而使用的断言 | | JSON JMESPath Assertion | 使用JMESPath对JSON文档内容执行断言 | | MD5Hex断言 | 允许用户检查响应数据的MD5 hash | | SMIME断言 | 用于评估来自邮件阅读器采样器的样本结果,此断言验证邮件消息的主体是否已签名。签名也可以针对特定的签名者证书进行验证 | | XML Schema断言 | 对返回结果为xml-schema xml模式数据类型的消息进行断言 | | XML断言 | 判断返回结果是否和xml的格式即<></>成对出现,即测试响应数据包含形式正确的XML文档 | | XPath断言 | 针对返回信息为XPAth的数据类型进行断言 | | 断言持续时间 | 在限定的时间内得到响应数据,如果响应时间大于设置的响应时间,则断言失败,否则成功 | | BeanShell断言 | 针对sampler中的Bean Shell sampler而使用的断言 |
测试片段:
非测试元件:
| 子菜单 | 描述 |
|---|
| HTTP代理服务器 | 录制脚本使用,作为web浏览器代理,对浏览器请求进行脚本录制 | | HTTP镜像服务器 | | | 属性显示 | |
取样器:
| 子菜单 | 描述 |
|---|
| HTTP请求 | HTTP请求取样器,发送http或者https请求 | | 测试活动 | | | Debug Sampler | 可以将其元组范围内的变量进行输出,输出结果包含在相应数据中,元组范围指的是该元组可以调用的所有变量,都会进行输出,变量的来源一般是以下几种:用户自定义变量,正则表达式提取的变量,用户定义的全局变量,参数文件导入的变量 | | JSR223 Sampler | | | AJP/1.3 取样器 | | | Access Log Sampler | | | BeanShell取样器 | | | Bolt Request | | | FTP请求 | | | GraphQL HTTP Request | | | JDBC Request | JDBC请求取样器 | | JMS发布 | | | JMS点到点 | | | JMS订阅 | | | JUnit请求 | | | Java请求 | | | LDAP扩展请求默认值 | | | LDAP请求 | | | OS进程取样器 | | | SMTP取样器 | | | TCP取样器 | | | WebSocket Sampler | WebSocket取样器 | | 邮件阅读者取样器 | |
逻辑控制器:参考https://www.cnblogs.com/du-hong/category/1149349.html?page=1
| 子菜单 | 描述 |
|---|
| 如果(if)控制器 | 实现了代码中IF的功能,通过判断表达式的True/False来判定是否执行相应的操作 | | 事务控制器 | 事务控制器可以把其他节点下的取样器执行消耗时间累加在一起,便于统计其响应时间、吞吐量等 | | 循环控制器 | 控制在其节点下的元件的执行次数,可以是具体数字,也可以是变量 | | While控制器 | 其节点下的元件将一直运行直到While 条件为false | | ForEach控制器 | 一般搭配用户变量使用。依次调用用户定义的变量,直到最后一个,结束循环;为了满足ForEach Controller提取数据,变量命名的格式一般为“变量名_数字”,其中数字从1开始 | | Include控制器 | 导入外部的测试片段(非完整的测试计划),在执行时会执行导入的测试计划,但是被导入的测试计划有特殊要求,它不能有线程组,只能包含简单的控制器及控制器下的元件。换句话说就是相当于加了一个执行单元,一个封装了的业务操作单元,类似我们程序开发中的函数(方法)一样 | | Runtime控制器 | 用来控制其子元件的执行时长。市场单位是秒(Runtime默认为1,去掉1则默认为0,此时不执行其节点下的元件。与线程组中的调度器的持续时间 效果一致;如果线程组中设置了持续时间,Runtime 控制器也设置了 运行时间,那么会优先于线程组中的设置。) | | 临界部分控制器 | 控制它的子元素(samplers /控制器等)在执行控制器的子程序之前只执行一个线程作为指定的锁,使其按顺序执行取样器和线程循环 | | 仅一次控制器 | 通常用于控制需要登录的请求,测试过程中,我们往往都只需要登录一次,获取到对应的登录信息后即可执行后续相关的请求,而不是每执行一个请求都登录一次,如将login请求放入仅一次控制器,则在线程组循环运行期间,不论循环次数设置为多少次,login请求都将仅在第一次执行时运行 | | 录制控制器 | 实际上它是一个位置,当我们用JMeter代理进行录制时,录制的脚本默认放在此控制器的节点下面。没有实际的逻辑作用,我们用简单控制器也可以代替它 | | 简单控制器 | 简单控制器可以被模块控制器所引用,其作用就是分组 | | 交替控制器 | 根据被控制器触发执行次数,去依次执行控制器下的子节点<逻辑控制器、采样器>。被触发执行可以由线程组的线程数、循环次数、逻辑控制器触发,每个线程只执行次控制器下的一个子节点 | | 随机控制器 | 节点下的元件随机运行,与交替控制器不一样的是节点下的元件运行顺序不定 | | 随机顺序控制器 | 随机顺序控制器是将节点下的所有子节点都正常执行,只是将执行顺序打乱 | | 吞吐量控制器 | 用来控制其下元件的执行次数,并无控制吞吐量的功能(1、吞吐量控制器有两种模式:Total Executions:设置运行次数与Percent Executions:设置运行比例(1~100之间);2、Per User:线程数,当选Total Executions时,是线程数;当选percent Executions时,是线程数*循环次数) | | Switch控制器 | 开关控制器,通过其下样例顺序数值或名称 控制执行某一个样例 | | 模块控制器 | 可以快速的切换脚本,不用来回的新建,方便脚本调试,是从内部文件中引用,引用上相对比较灵活,可以只引用部分测试片段或模块内容,包括控制器是从外部文件引用,只能引用整个测试片段的内容 |
|