XPath���� Seleniumʹ��Xpath��λ
ʲô��Xpath
XPath ʹ��·������ʽ��ѡȡ XML �ĵ��еĽڵ��ڵ㼯���ڵ���ͨ������·�� (path) ���߲� (steps) ��ѡȡ�ġ�XPath ������ XML �ĵ���ͨ��Ԫ�غ����Խ��е���,XPath��ΪXML·������(XML Path Language),����һ������ȷ��XML�ĵ���ij����λ�õ�����
ʲô��XML
XML��һ�ָ�ʽ,XML�DZ�ͨ�ñ������,����һ�ּ����ݴ洢����,ʹ��һϵ�мı����������,XML����ּ�������ݵ�,������ͬ����ͨ�ñ�����Ե�HTML��Ҫ������ʾ����
XML �� HTML ����Ҫ����
XML ���� HTML �����
XML �� HTML Ϊ��ͬ��Ŀ�Ķ����:
XML �����Ϊ����ʹ洢����,�佹�������ݵ�����
HTML �����������ʾ����,�佹�������ݵ����
HTML ּ����ʾ��Ϣ,�� XML ּ�ڴ�����Ϣ
�������ȡ��Ҫ��Xpath·��
�ȸ������Ϊ��
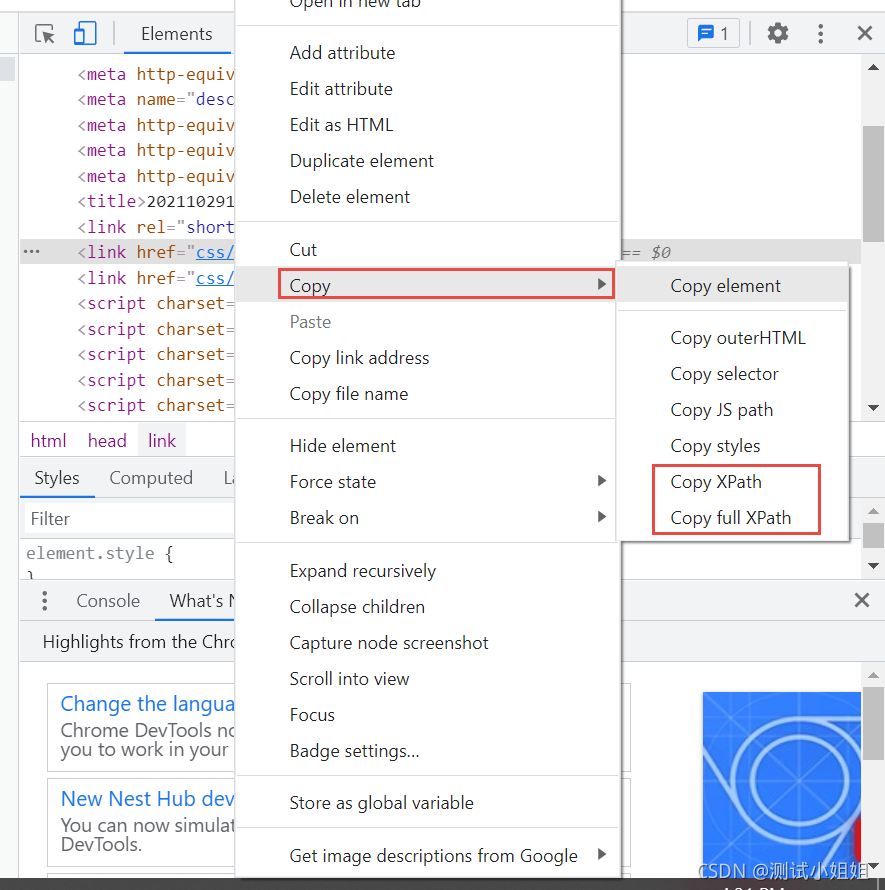
ʹ�ùȸ��������ȡ��ҪץȡԪ�ص�xpath·��
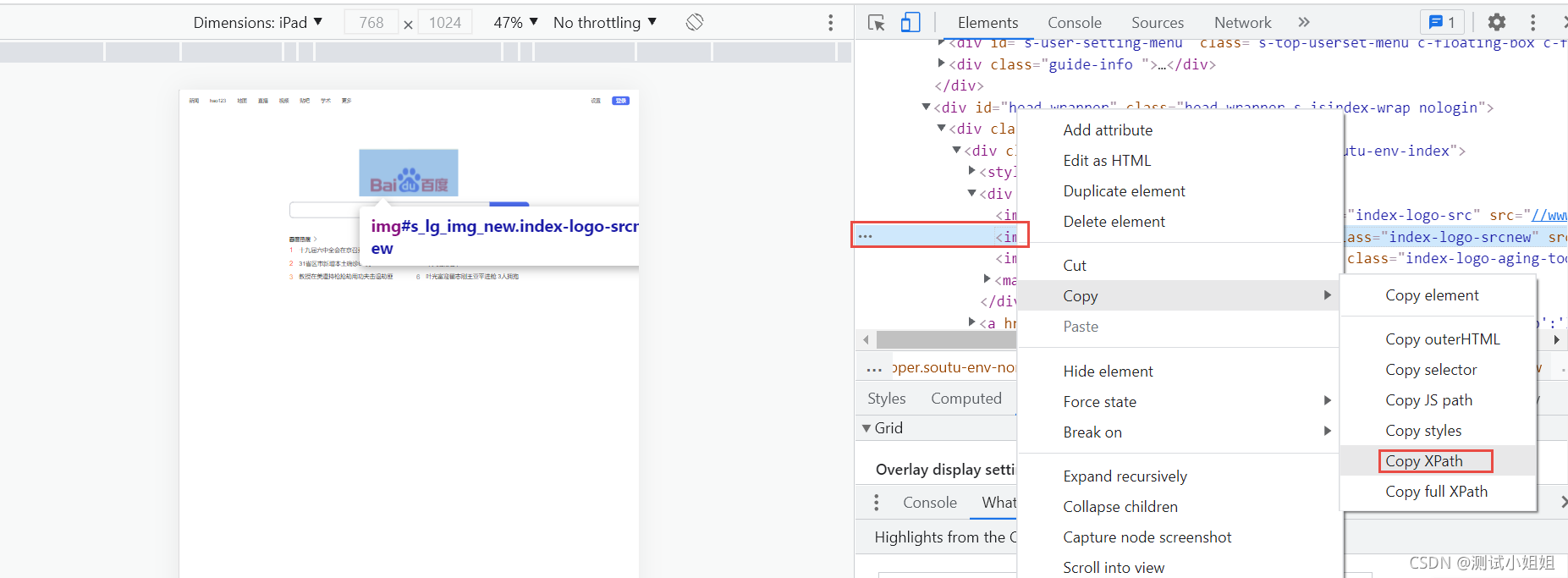
���Զ����ɵ�·��: //*[@id=��s_lg_img_new��]
���ջ����,�����е�HTMLΪ��,ץȡ��ͬ�Ľڵ�
<html>
<body>
<div>
<a href="http://www.baidu.com">
<a href="http://test.com"><img src="xx" alt="����" /></a>
</div>
<body>
<html>
�ڵ��Լ��ڵ�֮��Ĺ�ϵ,��������HTML��˵��
���ڵ�(Parent)
Ԫ��div��Ԫ��a�ĸ��ڵ�;�ڶ���Ԫ��aҲ��Ԫ��img�ĸ��ڵ�
�ӽڵ�(Children)
Ԫ��a��Ԫ��div���ӽڵ�;Ԫ��img���ӽڵ�
�ֵ�/ͬ���ڵ�(Sibling)
�ֵܽڵ���HTML�еĵ�λ���,��������ͬ�ĸ��ڵ㡣������������,����aԪ�ػ�Ϊ�ֵܽڵ�
�ȱ��ڵ�(Descendant)
����imgԪ����˵,���ĸ��ڵ�(�ڶ���aԪ��),�����ĸ��ڵ�ĸ��ڵ�(Ԫ��div)ͳ��Ϊimg���ȱ��ڵ㡣��һ��HTML�ļ���,�ȱ��ڵ�һ�㲻Ψһ,���������������,Ԫ��img���ȱ��ڵ��������Ԫ��
����ڵ�(Descendant)
����imgԪ����˵,�����ӽڵ�(�ڶ���aԪ��),�������ӽڵ���ӽڵ�(Ԫ��img)ͳ��Ϊdiv�ĺ���ڵ�
��ʹ��Xpath��,������ڵ��Ĺ�ϵ�Ǻ���Ҫ
XPath��������
XPath�ɷ�Ϊ������������:
�ڵ㼯(node-set)
�ڵ㼯��ͨ��·��ƥ�䷵�صķ���������һ��ڵ�ļ��ϡ��������͵����ݲ���ת��Ϊ�ڵ㼯��
����ֵ(boolean)
�ɺ���������ʽ���ص�����ƥ��ֵ,��һ�������еIJ���ֵ��ͬ,��true�� false����ֵ������ֵ���Ժ���ֵ���͡��ַ��������ת����
�ַ���(string)
�ַ���������һϵ���ַ��ļ���,XPath���ṩ��һϵ�е��ַ����������ַ���������ֵ���͡�����ֵ���͵������ת����
��ֵ(number)
��XPath ����ֵΪ������,������˫����64λ���������������һЩ��ֵ����������,�����ֵNaN(Not-a-Number)���������infinity������ ���-infinity������0�ȵȡ�number������ֵ����ͨ������ȡ��,����,��ֵҲ���ԺͲ������͡��ַ��������ת����
XPath�ڵ�����
����XPath�������Ƕ��ĵ��ṹ����һϵ�в���,һ��XML�ļ�������Ԫ�ء�CDATA��ע�͡�����ָ�����Ҫ��,����Ԫ�ػ�����������,�������������������������ռ䡣��XPath ��,���ڵ㻮��Ϊ���ֽڵ�����:
���ڵ�(Root Node)
���ڵ���һ���������ϲ�,���ڵ���Ψһ�ġ�������������Ԫ�ؽڵ㶼�������ӽڵ�����ڵ㡣�Ը��ڵ�Ĵ��������������ڵ���ͬ����XSLT�ж�����ƥ�������ȴӸ��ڵ㿪ʼ
Ԫ�ؽڵ�(Element Nodes)
Ԫ�ؽڵ��Ӧ���ĵ��е�ÿһ��Ԫ��,һ��Ԫ�ؽڵ���ӽڵ������Ԫ�ؽڵ㡢ע�ͽڵ㡢����ָ��ڵ���ı��ڵ㡣����ΪԪ�ؽڵ㶨��һ��Ψһ�ı�ʶid��Ԫ�ؽڵ㶼��������չ��,��������������ɵ�:һ�����������ռ�URI,��һ�����DZ��ص�����
�ı��ڵ�(Text Nodes)
�ı��ڵ������һ���ַ�����,��CDATA�а������ַ����κ�һ���ı��ڵ㶼�����н��ڵ��ֵ��ı��ڵ�,�����ı��ڵ�û����չ��
���Խڵ�(Attribute Nodes)
ÿ һ��Ԫ�ؽڵ���һ������������Խڵ㼯��,Ԫ����ÿ�����Խڵ�ĸ��ڵ�,�����Խڵ�ȴ�����丸Ԫ�ص��ӽڵ㡣�����˵,ͨ������Ԫ�ص��ӽڵ����ƥ���Ԫ �ص����Խڵ�,��������������,ֻ�ǵ���ġ�����,Ԫ�ص����Խڵ�û�й�����,Ҳ����˵��ͬ��Ԫ�ؽڵ㲻����ͬһ�����Խڵ�
�����ռ�ڵ�(Namespace Nodes)
ÿһ��Ԫ�ؽڵ㶼��һ����ص������ռ�ڵ㼯����XML�ĵ���,�����ռ���ͨ����������������,���,��XPath��,����ڵ������Խڵ㼫Ϊ����,�����븸Ԫ��֮��Ĺ�ϵ�ǵ����,���Ҳ����й�����
����ָ��ڵ�(Processing Instruction Nodes)
����ָ��ڵ��Ӧ��XML�ĵ��е�ÿһ������ָ���Ҳ����չ��,��չ���ı�������ָ��������,�������ռ䲿��Ϊ��
ע�ͽڵ�(Comment Nodes)
ע�ͽڵ��Ӧ���ĵ��е�ע��
xpath���
ѡȡ�ڵ�
nodename----ѡȡ�˱�ǩ�������ӱ�ǩ
/ ----�Ӹ��ڵ㿪ʼ��
// ----������λ�ÿ�ʼ��,���������ǵ�λ��
. ----��ǰ�ڵ�
�� ----���ڵ�
@----ѡȡ����
text()----ѡȡ����
������:��
[]----д��Ԫ�غ���,���������Ԫ��
[@class=��abc��]----class����Ϊabc��Ԫ��
[@id=��aaa��]----id����Ϊaaa��Ԫ��
[@class]----ѡȡ��class���Ե�Ԫ��
[1]----��һ��
[last()]----ѡ���һ��
[last()-1]----�����ڶ���
[position()>2]----ѡȡλ�ô���2
book[position()>2���ӵ������鿪ʼѡȡ
[contains(������a,����ֵb)]����a����b�ı�ǩ
book[contains(@href,��baidu��)]
ͨ���
*ƥ���κ�Ԫ�ؽڵ�
@*ƥ���κ����Խڵ�
ѡȡ����·��
//title|//price ��ѡȡ���е�title��price��ǩ
�ܽ�
XPath���������������ٶ�,������Ϊ����html�����εĽṹ���д洢,����ͨ���㼶��ϵ���ҽڵ��ʱ��,������Ҫ�������ַ������б���,���ĵײ���ͨ��libxml����һ��DOM��ʵ�ֵIJ���
XPath��ʵ������������(��������),������ͺ������dz���,ѧϰ�����ɱ�Ҳ�Ƚϸ�,��������ͨ��ץȡҵ����,ֻ��Ҫ����һЩ�����ľ��㹻��
Selenium�Զ���������ʹ��Xpath��λ
һ��xpath������λ�÷�
1.ʹ��id��λ �C driver.find_element_by_xpath(��//input[@id=��kw��]��)
2.ʹ��class��λ �C driver.find_element_by_xpath(��//input[@class=��s_ipt��]��)
����xpath���·��/����·����λ
1.��Զ�λ �C ��// ��ͷ ��://form//input[@name=��phone��]
2. ���Զ�λ �C ��/ ��ͷ,����Ҫ�Ӹ�Ŀ¼��ʼ,�ȽϷ���,һ�㲻����ʹ�� ��:/html/body/div/a
����xpath�ı���ģ��������λ
1.���ı���λ��ʹ��text()Ԫ�ص�text���� ��://button[text()=����¼��]
2. ��ģ����λ��ʹ��contains() �������� ��://button[contains(text(),����¼��)]��//button[contains(@class,��btn��)] ����contains����=����
3. ��ģ����λ��ʹ��starts-with �C ƥ����xx��ͷ������ֵ;ends-with �C ƥ����xx��β������ֵ ��://button[starts-with(@class,��btn��)]��//input[ends-with(@class,"-special")]
4. ʹ��������� �C and��or;��://input[@name=��phone�� and @datatype=��m��]