- 🎉粉丝福利送书:《 Java多线程与大数据处理实战》
- 🎉点赞 👍 收藏 ?留言 📝 即可参与抽奖送书
- 🎉下周二(11月17日)晚上20:00将会在【点赞区和评论区】抽一位粉丝送这本北京大学出版社的书~🙉
- 🎉详情请看最后的介绍嗷~?

实验 1
1.1 题目
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://www.dangdang.com/
1.2 思路
1.2.1 setting.py
-
打开请求头

-
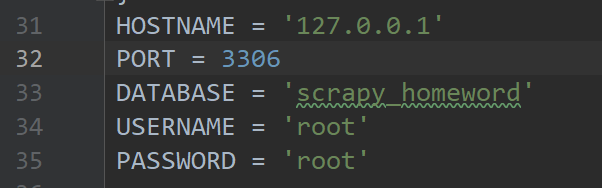
连接数据库信息
-
ROBOTSTXT_OBEY设置为False

-
打开pipelines

1.2.2 item.py
编写item.py的字段
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
1.2.3 db_Spider.py
- 观察网页,查看分页
第二页
第三页
所以很容易发现这个page_index就是分页的参数
- 获取节点信息
def parse(self, response):
lis = response.xpath('//*[@id="component_59"]')
titles = lis.xpath(".//p[1]/a/@title").extract()
authors = lis.xpath(".//p[5]/span[1]/a[1]/text()").extract()
publishers = lis.xpath('.//p[5]/span[3]/a/text()').extract()
dates = lis.xpath(".//p[5]/span[2]/text()").extract()
prices = lis.xpath('.//p[3]/span[1]/text()').extract()
details = lis.xpath('.//p[2]/text()').extract()
for title,author,publisher,date,price,detail in zip(titles,authors,publishers,dates,prices,details):
item = DangdangItem(
title=title,
author=author,
publisher=publisher,
date=date,
price=price,
detail=detail,
)
self.total += 1
print(self.total,item)
yield item
self.page_index += 1
yield scrapy.Request(self.next_url % (self.keyword, self.page_index),
callback=self.next_parse)
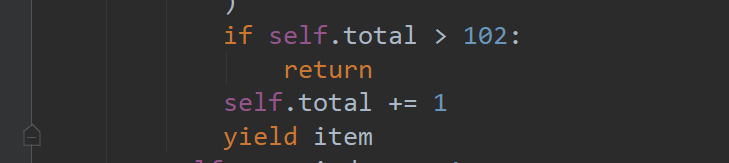
- 指定爬取数量
爬取102条
1.2.4 pipelines.py
- 数据库连接
def __init__(self):
# 获取setting中主机名,端口号和集合名
host = settings['HOSTNAME']
port = settings['PORT']
dbname = settings['DATABASE']
username = settings['USERNAME']
password = settings['PASSWORD']
self.conn = pymysql.connect(host=host, port=port, user=username, password=password, database=dbname,
charset='utf8')
self.cursor = self.conn.cursor()
- 插入数据
def process_item(self, item, spider):
data = dict(item)
sql = "INSERT INTO spider_dangdang(title,author,publisher,b_date,price,detail)" \
" VALUES (%s,%s, %s, %s,%s, %s)"
try:
self.conn.commit()
self.cursor.execute(sql, [data["title"],
data["author"],
data["publisher"],
data["date"],
data["price"],
data["detail"],
])
print("插入成功")
except Exception as err:
print("插入失败", err)
return item
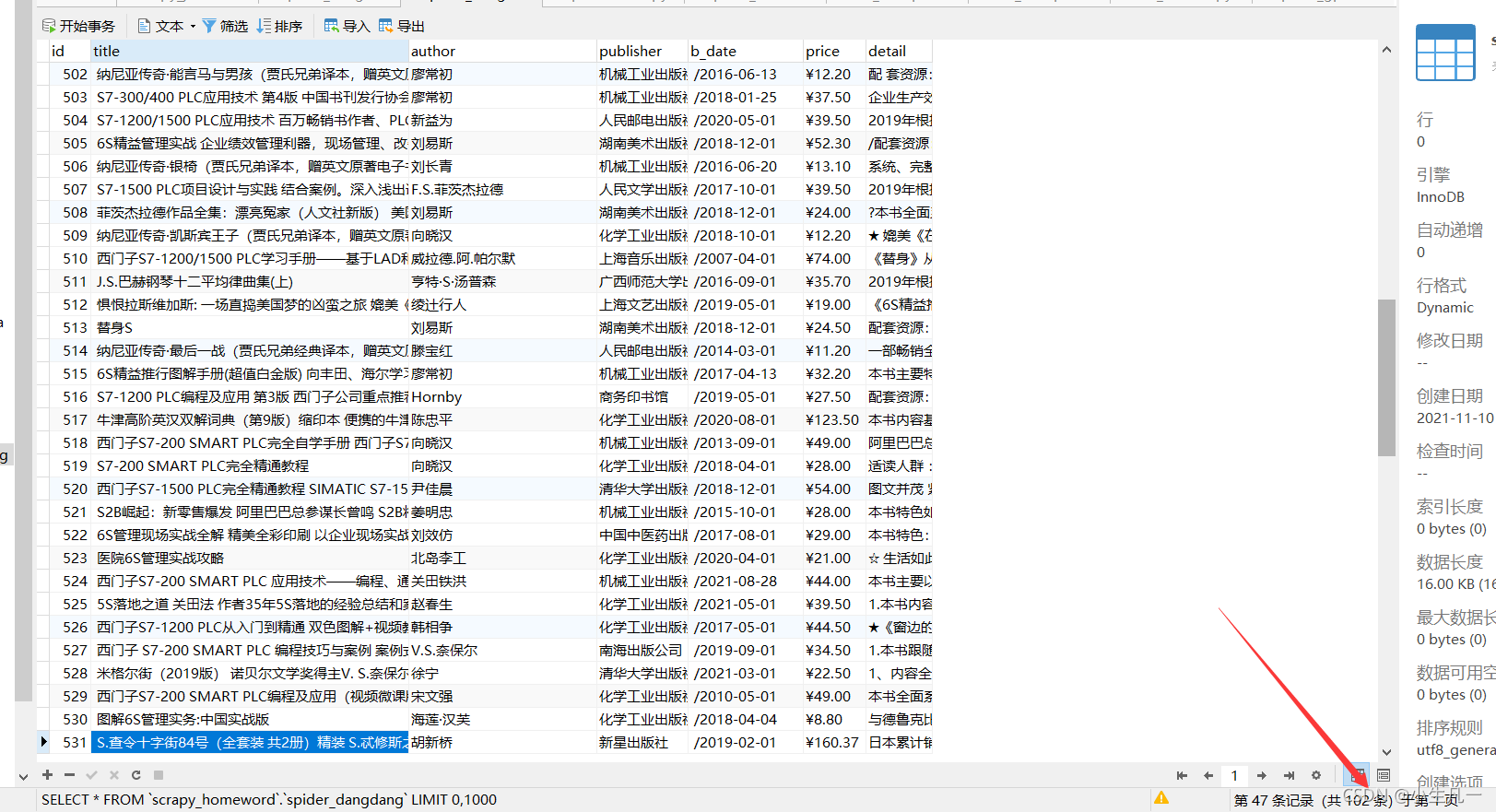
结果查看,一共102条数据,这个id我是设置自动自增的,因为有之前测试的数据插入,所以id并没有从1开始
实验 2
2.1 题目
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用
scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
2.2 思路
2.2.1 setting.py
与1.2.1的setting.py相似,就不过多展示了
2.2.2 item.py
编写item.py
class CmbspiderItem(scrapy.Item):
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
2.2.3 db_Spider.py
- 数据解析
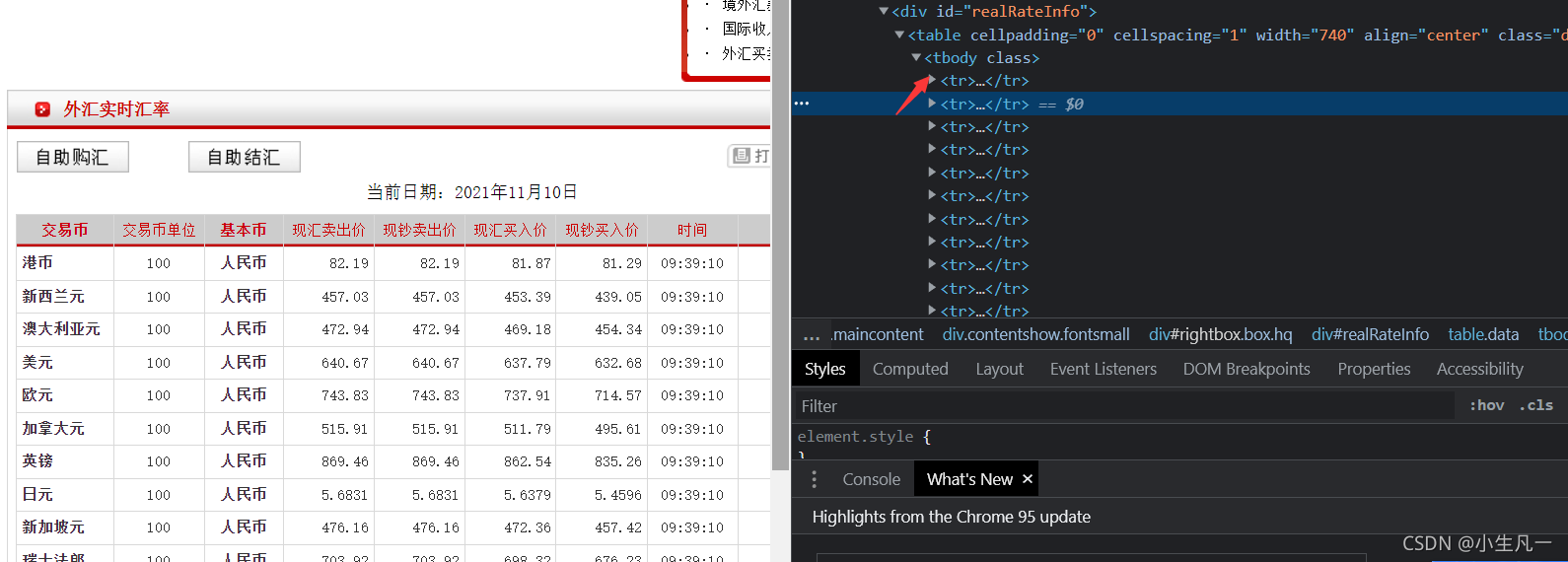
lis = response.xpath('//*[@id="realRateInfo"]/table')
currencys = lis.xpath(".//tr/td[1]/text()").extract()
tsps = lis.xpath(".//tr/td[4]/text()").extract()
csps = lis.xpath(".//tr/td[5]/text()").extract()
tbps = lis.xpath(".//tr/td[6]/text()").extract()
cbps = lis.xpath(".//tr/td[7]/text()").extract()
times = lis.xpath(".//tr/td[8]/text()").extract()
注意: 这里有一个坑点,因为这个table后面应该是有一个tbody的!
但是我们如果加了的话,就爬不下来了!所以要删掉这个tbody,然后下面的元素全从\改成\\
- 数据处理
去除数据的前后空格和一些'\r\n'
for currency, tsp, csp, tbp, cbp, time in zip(currencys, tsps, csps, tbps, cbps, times):
count+=1
currency = currency.replace(' ', '')
tsp = tsp.replace(' ', '')
csp = csp.replace(' ', '')
tbp = tbp.replace(' ', '')
cbp = cbp.replace(' ', '')
time = time.replace(' ', '')
currency = currency.replace('\r\n', '')
tsp = tsp.replace('\r\n', '')
csp = csp.replace('\r\n', '')
tbp = tbp.replace('\r\n', '')
cbp = cbp.replace('\r\n', '')
time = time.replace('\r\n', '')
if count ==1 :
continue
item = CmbspiderItem(
currency=currency, tsp=tsp, csp=csp, tbp=tbp, cbp=cbp, time=time
)
yield item
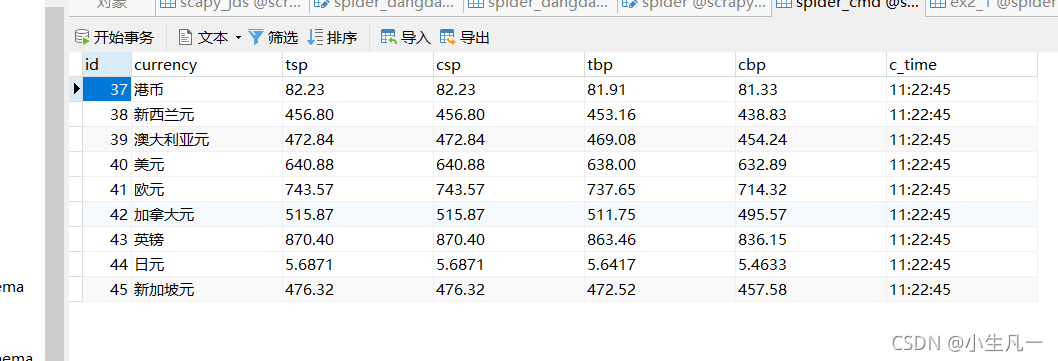
2.2.4 pipelines.py
与1.2.4的操作相似,不再过多描述
实验 3
3.1 题目
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
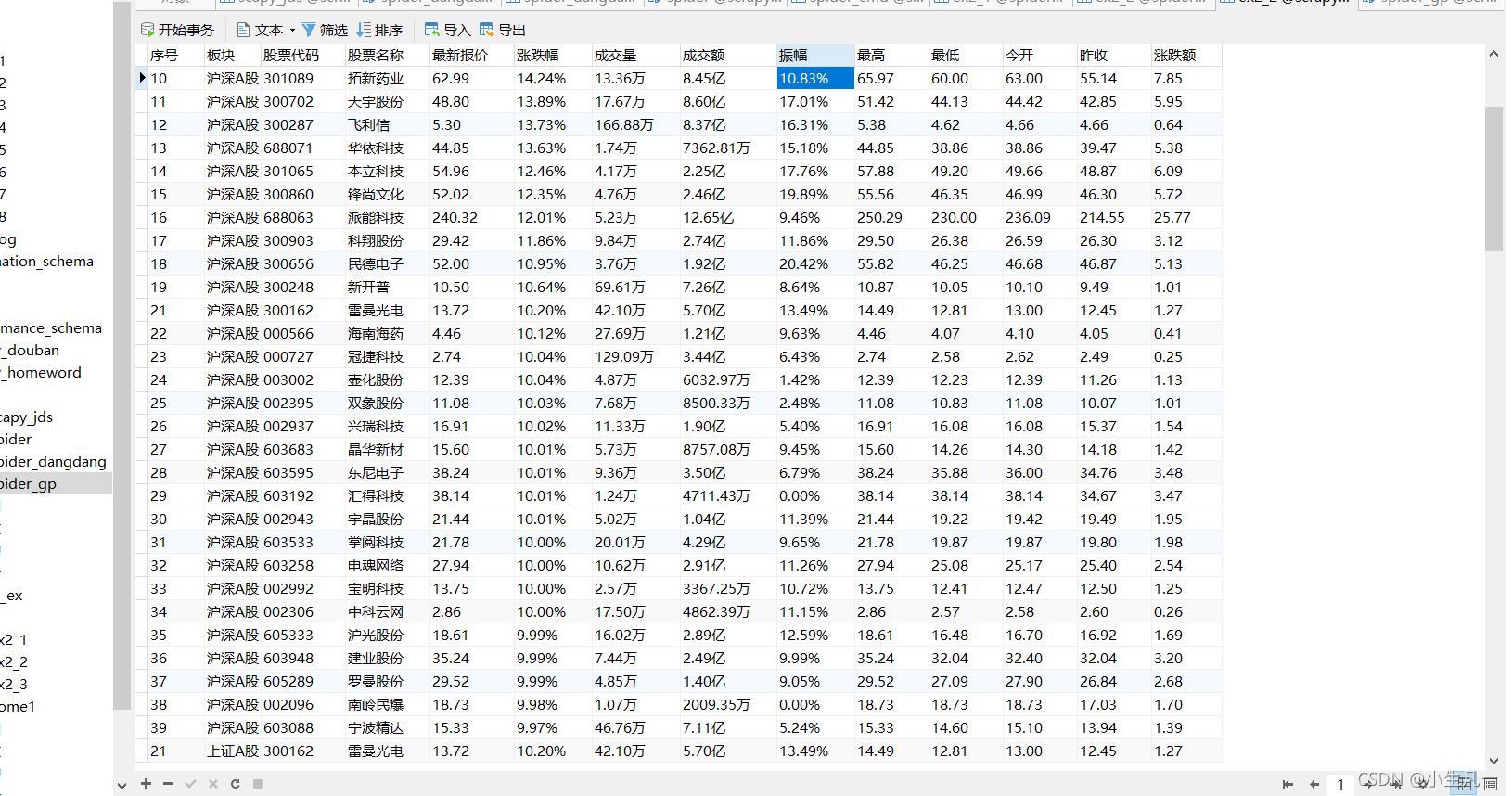
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.2 思路
3.2.1 发送请求
- 引入驱动
chrome_path = r"D:\Download\Dirver\chromedriver_win32\chromedriver_win32\chromedriver.exe" # 驱动的路径
browser = webdriver.Chrome(executable_path=chrome_path)
- 保存需要爬取的版块
target = ["hs_a_board", "sh_a_board", "sz_a_board"]
target_name = {"hs_a_board": "沪深A股", "sh_a_board": "上证A股", "sz_a_board": "深证A股"}
计划是爬取三个模板的两页信息。
- 发送请求
for k in target:
browser.get('http://quote.eastmoney.com/center/gridlist.html#%s'.format(k))
for i in range(1, 3):
print("-------------第{}页---------".format(i))
if i <= 1:
get_data(browser, target_name[k])
browser.find_element_by_xpath('//*[@id="main-table_paginate"]/a[2]').click() # 翻页
time.sleep(2)
else:
get_data(browser, target_name[k])
注意: 这里的翻页一点要time.sleep(2)
不然他会请求会很快,以至于你虽然翻到第二页了,但是还是爬取第一页的信息!!
3.2.2 获取节点
- 解析网页的时候也要
implicitly_wait等待一下
browser.implicitly_wait(10)
items = browser.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr')
然后这个items就是所以的信息了
for item in items:
try:
info = item.text
infos = info.split(" ")
db.insertData([infos[0], part, infos[1], infos[2],
infos[4], infos[5],
infos[6], infos[7],
infos[8], infos[9],
infos[10], infos[11],
infos[12], infos[13],
])
except Exception as e:
print(e)
3.2.3 保存数据
- 数据库类,封装了初始化和插入操作
class database():
def __init__(self):
self.HOSTNAME = '127.0.0.1'
self.PORT = '3306'
self.DATABASE = 'scrapy_homeword'
self.USERNAME = 'root'
self.PASSWORD = 'root'
# 打开数据库连接
self.conn = pymysql.connect(host=self.HOSTNAME, user=self.USERNAME, password=self.PASSWORD,
database=self.DATABASE, charset='utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
self.cursor = self.conn.cursor()
def insertData(self, lt):
sql = "INSERT INTO spider_gp(序号,板块,股票代码 , 股票名称 , 最新报价 ,涨跌幅 ,涨跌额,成交量,成交额 , 振幅, 最高 , 最低 , 今开 , 昨收 ) " \
"VALUES (%s,%s, %s, %s, %s, %s,%s, %s, %s, %s, %s,%s,%s,%s)"
try:
self.conn.commit()
self.cursor.execute(sql, lt)
print("插入成功")
except Exception as err:
print("插入失败", err)
福利送书

【内容简介】
- 《Java多线程与大数据处理实战》对 Java 的多线程及主流大数据中间件对数据的处理进行了较为详细的讲解。
- 本书主要讲了
Java的线程创建方法和线程的生命周期,方便我们管理多线程的线程组和线程池,设置线程的优先级,设置守护线程,学习多线程的并发、同步和异步操作,了解 Java 的多线程并发处理工具(如信号量、多线程计数器)等内容。 - 引入了
Spring Boot、Spring Batch、Quartz、Kafka等大数据中间件。这为学习Java 多线程和大数据处理的读者提供了良好的参考。多线程和大数据的处理是许多开发岗位面试中容易被问到的知识点。 - 学好
多线程的知识点,无论是对于日后的开发工作,还是正要前往一线开发岗位的面试准备,都是非常有用的。 - 本书既适合高等院校的计算机类专业的学生学习,也适合从事软件开发相关行业的初级和中级开发人员。
【评论区】和 【点赞区】 会抽一位粉丝送出这本书籍嗷~
当然如果没有中奖的话,可以到当当,京东北京大学出版社的自营店进行购买。
也可以关注我!每周都会送一本出去哒~