Jmeter
1����Ӣ���л�
��Ҫ�л�������binĿ¼�µ�jmeter.properties�ļ�,�����ļ������ݽ�����,�ĺ�������
#language=en
�ij�:
language=zh_CN
2��threads(users)
- thread Group
- setUp thread Group
- teardown thread Group

3��NON-TESTELEMENTS
- HTTP Mirror Server(HTTP�������)
- HTTP(s) Test Script Recorder (HTTP(s)���Խű���¼��,HTTP����������)
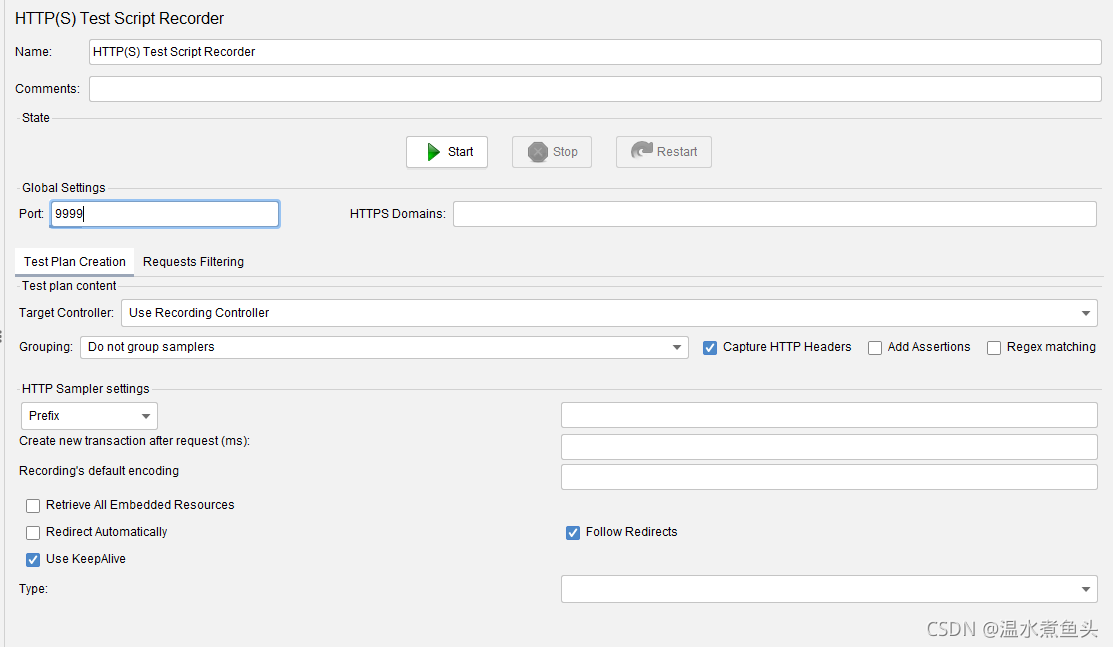
- Target Controller
- Use Recording Controller ʹ��¼�ƿ�����
- Test Plan>HTTP(S) Test Script Recorder ���Լƻ�>HTTP���������� ��
- Grouping
- Do not group samplers ������������
- Add separators between groups ��������ӷָ�
- Put each group in a new controller ÿ�������һ���µĿ�����
- Store 1st sampler of each group only ֻ�洢ÿ����ĵ�һ������
- Put each group in a new transaction controller ��ÿ�������һ���µ������������
- Property Display (������ʾ)
3��Listener
- View Results Tree �鿴�����
- Summary Report ���ܱ���
- Aggregate Report �ۺϱ���
- Backend Listener ��˼�����
- Aggregate Graph �ۺ�ͼ��
- Assertion Results ���Խ��
- Comparison Assertion Visualizer �Ƚ϶��Կ�����
- Generate Summary Results ���ɸ�Ҫ���
- Graph Results ͼ�����
- JSR223 Listener JSR223������
- Mailer Visualizer �ʼ��۲���
- Response Time Graph ��Ӧʱ��ͼ��
- Save Responses to a file ������Ӧ���ļ�
- Simple Data Writer �������
- View Result in Table �ñ���鿴���
- BeanShell Listener Bean Shell ������
jmeter¼��
1��http(s)����������
2���߳���
3��¼�ƿ�����
��1��ѡ��˿�,¼�Ƶĵ�ʲô������,Ȼ��ʼ¼��,�����Ҫ���õ��ԵĴ����˿���jmeter��1�����õĶ˿�һ��
badboy
����ͨ��badboy��badboy�������ҳ�����,������jxm�ļ�,��ͨ��jmeter����,����badbobyֻ֧��IE,������Щ��Ҫ֧�ֹȸ���������в�ͨ
Jmeterרҵ�������
1��Jmeter���(Ԫ��)
Jmeter �߳���
�߳���:ÿ����������ıر����,������ģ���û������������JMeter ��ÿ�����������߳��������ġ�
-
1���߳���:����������
- setUp �����������û�����,teardown�����������û������Ĺ���(ɾ�������û��ȵ�)

- ��ȡ�������������ִ�ж���

- setUp �����������û�����,teardown�����������û������Ĺ���(ɾ�������û��ȵ�)
-
2��Ramp-Up Period(in seconds):�ڶ������ڴ����߳����ж���������̡߳�ÿ�벢���� = �߳���/RUP ������Ǽ��㲢����,���ڶ������ڴ���������õ��߳���,ÿ��IJ����������߳�����RUP�Ͻ��м���
-
3��ѭ������:��ʾÿ���߳�ִ�ж��ٴ�����;������Զ,��ʾ�����ֹͣ������ʱ�佫��һֱִ����ȥ, ��Ϊ�˷���������ĵ���
-
4��������:��ѡ��,������ʱ,����ʱ��ſɱ༭
-
5������ʱ��:��ʾ�ű��������е�ʱ��,����Ϊ��λ,���������Ҫ���û��������ϵ�¼1��Сʱ,��������ı�������д3600,�����Ҫ��ѭ�����������ù���,ת�ɳ���ʱ��,�����ѭ��������������,��ߵij���ʱ���û������
-
6�������ӳ�:��ʾ�ű��ӳ�������ʱ��,�ڵ��������,�������ʱ���Ѿ�����,���ǻ�û�е������ӳٵ�ʱ��,��ô,�ȵ������ӳٵ�ʱ�䵽���,������ϵͳ(������������Ҫ�ȴ���ʱ��,����˵���������ʱ��Ҫ�ȴ���ʱ��,�����Ҫ��ϳ���ʱ��)
Jmeter �߳���2(Stepping Thread Group)
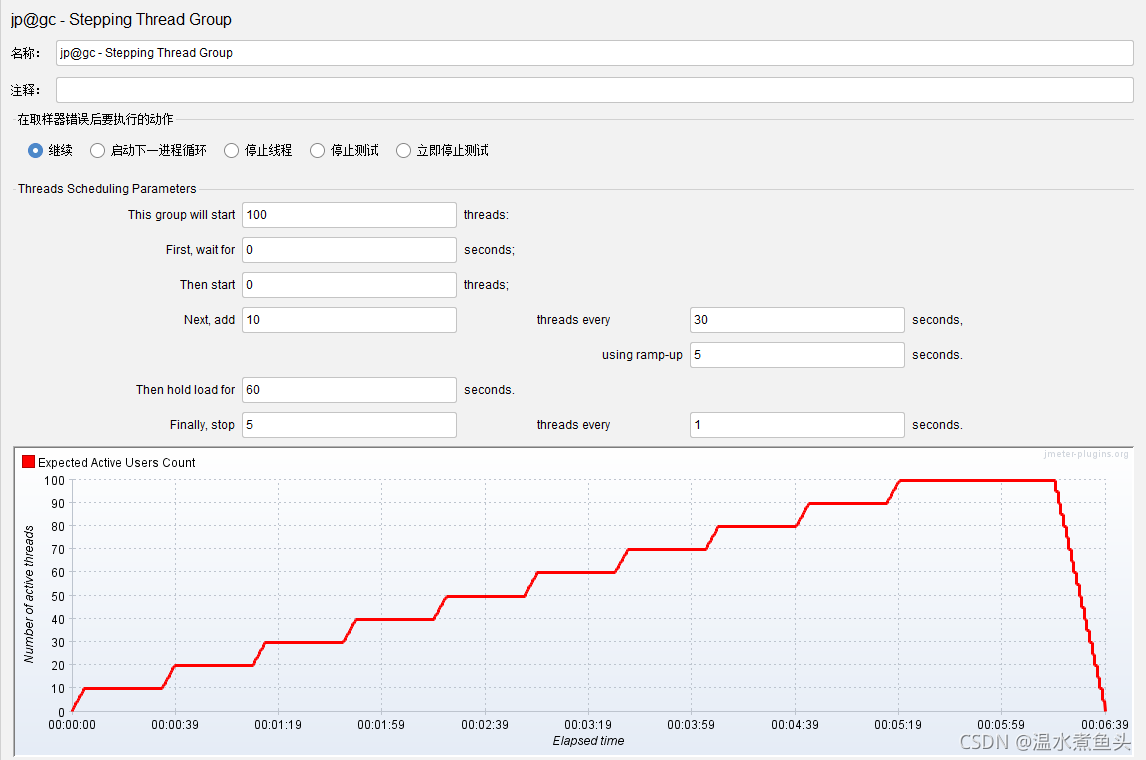
This Group will start 100 threads:���β���100���̡߳�
First , wait for 0 seconds:�ӳ�0�뿪ʼִ�в���
Then start 0 threads;��0���߳̿�ʼ��������(һ������Ϊ0��)
Next,add 10 threads every 30 seconds:ÿ����10���̺߳�����30s,�������µ�10���߳�,������30s,�Դ�����,�������ӵ��߳��Լ����е��̳߳����ܵ�ʱ��
Using ramp-up 5 seconds:ǰ��ÿ��10���̵߳�ʱ��30s,��������������5s����10���߳�,����30s,Ȼ����5s������10���߳�,������30s,�Դ����ơ�
Then hold load for 60 seconds. :ȫ�����߳�������,����60s ��ʼֹͣ��
Finally , stop 5 threads every 1 seconds:���ֹͣ�߳�,5���߳�ͣһ��,��1s��ͣ5���̡߳�
����:�Ҽ����Լƻ�->����->������->jp@gc - Active Threads Over Time
��������HTTP Request��,������в���,�鿴Active Threads Over Time���н�����ɲ鿴�߳�½������������,�������õ�����߳�����,�������������õ�ʱ��,�������õij���ʱ���,½���������̡�
Jmeter �е�sampler(ȡ����)
ȡ����(Sampler)�����ܲ��������������������,JMeter ԭ��֧�ֶ��ֲ�ͬ��sampler�� HTTP Request Sampler �� FTP Request Sampler ��TCP Request Sampler ��JDBC Request Sampler ��,ÿһ�ֲ�ͬ���͵� sampler ���Ը������õIJ����������������ͬ���͵�������Jmeter������Sampler��,Java Request Sampler�ǿɶ��Ƶ�Sampler��
����Ƭ��
����Ƭ��Ҫ���ģ�������,�����ǰ�һЩ�ϸ��ӵIJ����γɲ���Ƭ��,ͨ��ģ�����������ִ����ЩƬ��
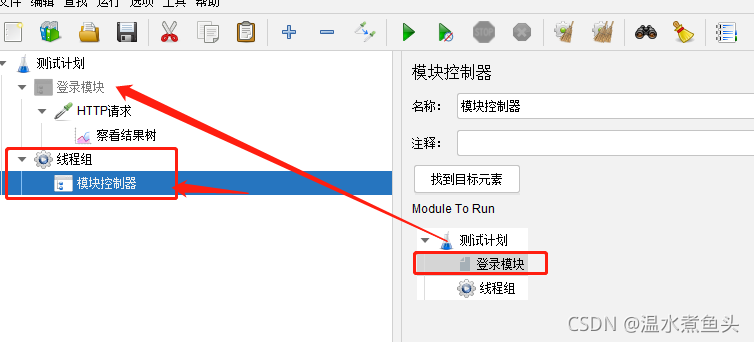
�Dz���Ԫ��
HTTP����������app�ӿ�����
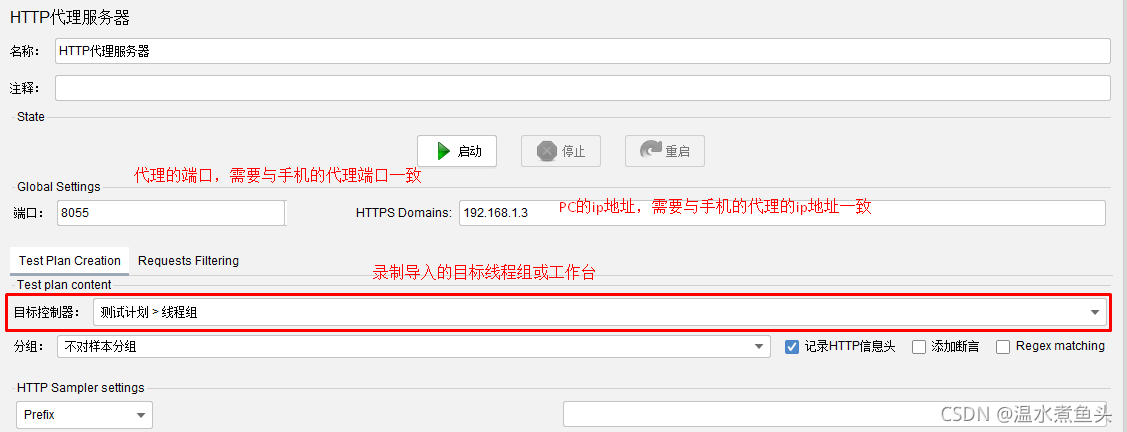
HTTPS������Ҫ��װ֤��,֤����jmeter��bin¼��,�追�����ֻ��ڰ�װ���ɡ�
2.ȡ����
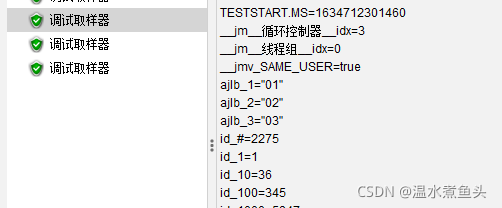
Dummy Sampler
Response Code (eg 200):��Ӧ��200
Response Message (eq OK):��Ӧ��Ϣok
Connect Time (milliseconds):����ʱ��(����)
Latency (milliseconds):�ӳ�ʱ��(����)
Response Time (milliseconds):��Ӧʱ��(����)
Simulate Response Time (sleep):ģ����Ӧʱ��
Request Data:��������
Response Data:��Ӧ����
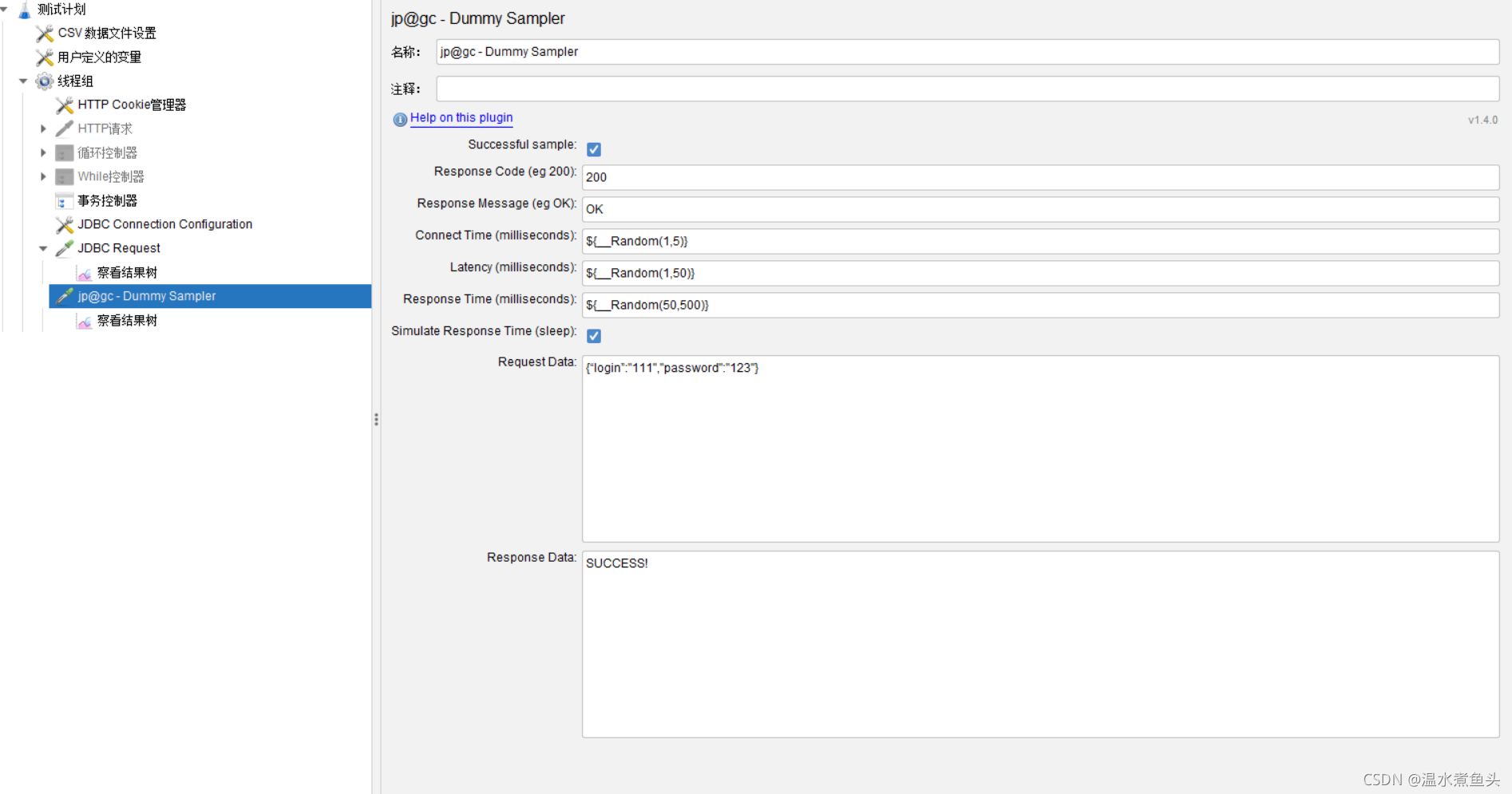
�����ڷ���û�п�����ȫǰ,ģ���һ��mock,�ɹ��������Խ���
��ϲ鿴�����,���ɲ鿴������Ӧ������:


Debug Sampler(����ȡ����)
Debug Sampler ��������Զ���ı�������� response data ��,�������ǵ��Ե�ʱ��ʹ
��
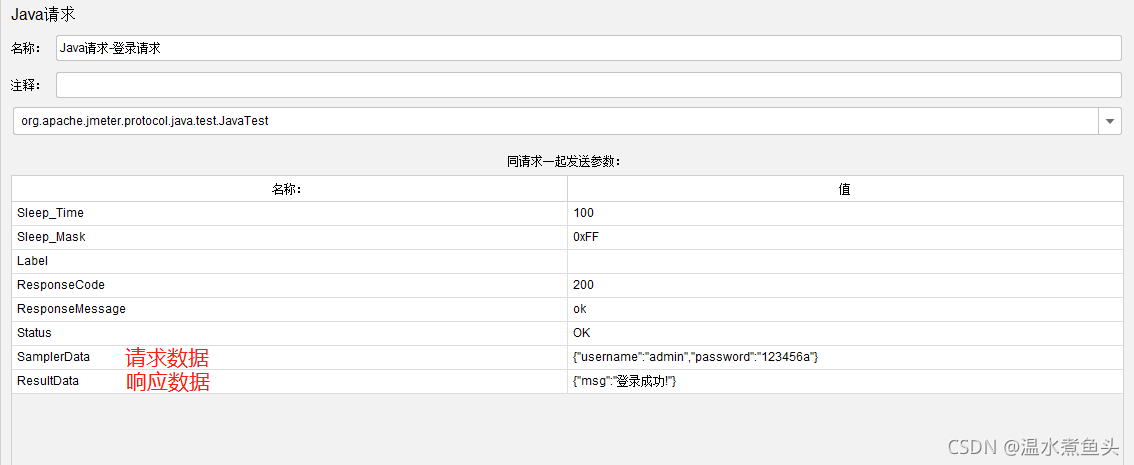
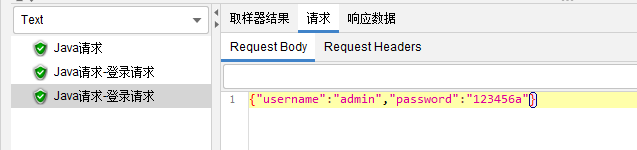
Java request(java ����)
3.��������
��������,��������,һ�������ڿ���test plan �� sampler �ڵ㷢���������˳��Ŀ�����,���õ��� ���(If)������ ��switch Controller ��ѭ���������ȡ���һ����������֯�ɿ��� sampler ���ڵ��,�� ����������������
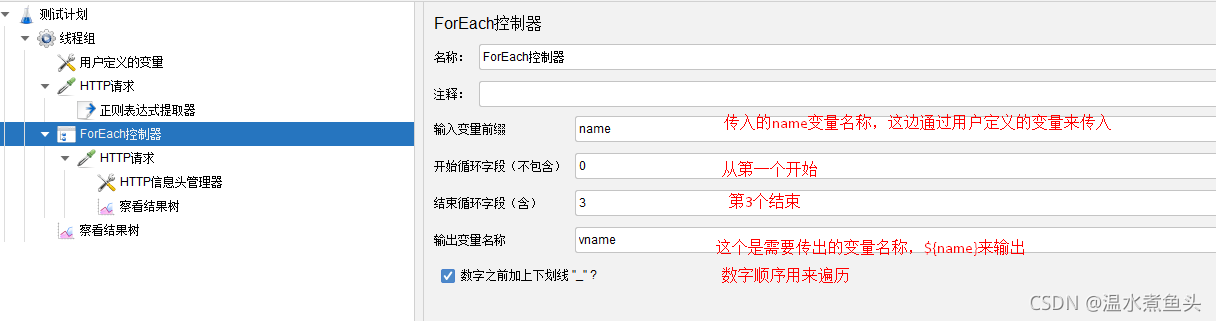
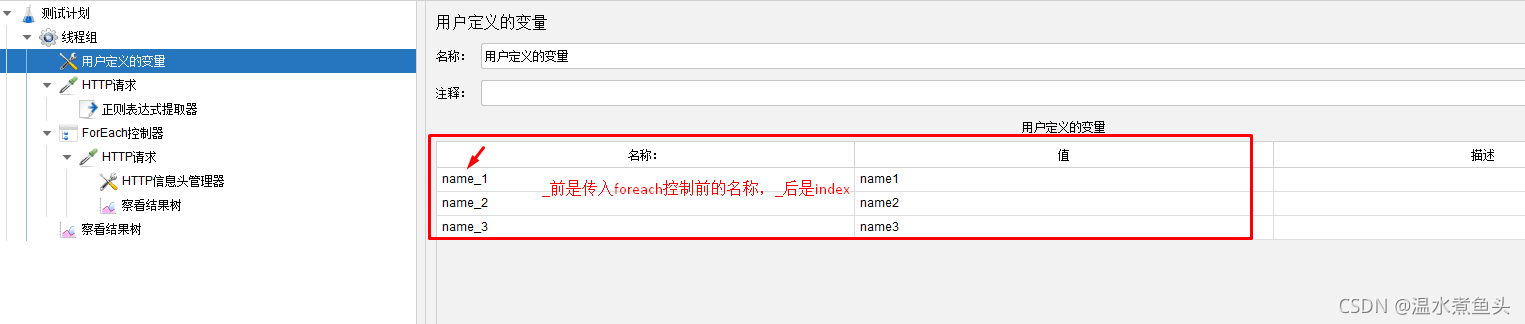
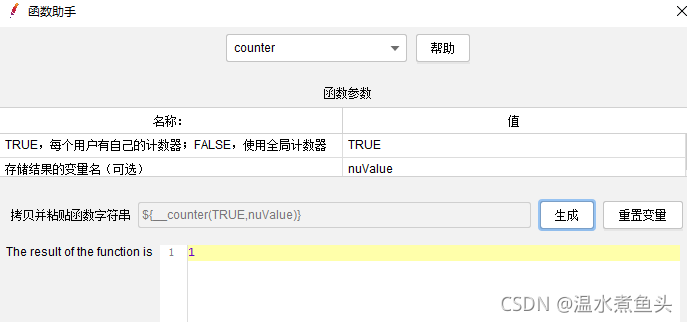
ForEach��������
ͨ������û��Զ��������ʹ��
 ��һ��ʵ��Ч��:����Ƕ���������ͷ
��һ��ʵ��Ч��:����Ƕ���������ͷ
���Է��������ͨ�������ʵ��ִ�еĴ���(�߳��鱾��ֻ��1)
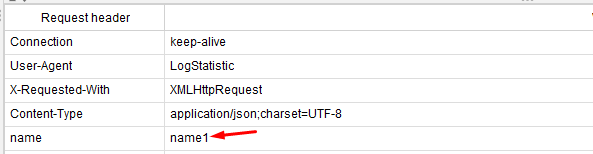
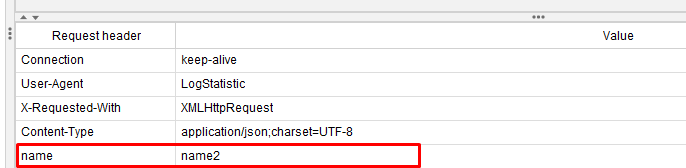
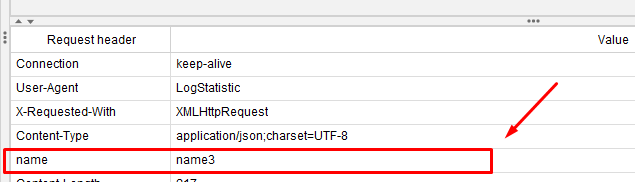
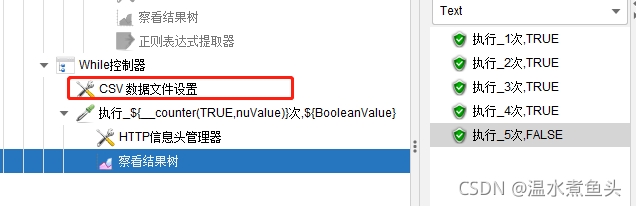
While������
- ������������һ��,�ж��Ƿ�ΪTrue,��ΪFalse��ʱ��ִֹͣ�С�
- Ϊ��(�������κ�ֵ) �C ֱ��ij������ִ��ʧ�ܲ��˳�ѭ��
- LAST �C ֱ�����һ����������ʧ�ܲ��˳�ѭ��
- ���� �C ����ֵ����"false"ʱ(��������Ϊ��false��ͬ��),�˳�ѭ��
����:
${value} == 10 #������value������10ʱ,�˳�ѭ��
${__javaScript(${count}<A&& ${code}=="B")} #���� count<A �� code==B ����ѭ��,�����˳�ѭ��
�ж�BooleanValue�Ƿ�ΪFalse,�������Ԫ��->CSV�����ļ�����,ÿ�λ�ȡcsv�ļ���ֵ,������falseʱ�˳�ѭ����
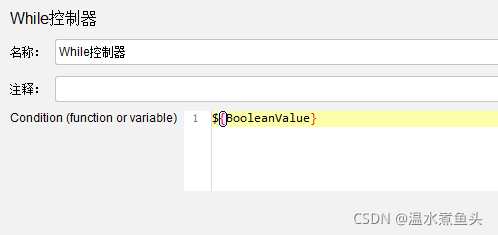
ע��,��ʱ��CSVҪ����While����������,�������While֮ǰ,�ͻ���ֻ�ȡcsv���ݺ����while�ж�,�����һ����TRUE�Ļ�,�ͻ�һֱѭ��,��ȷ��Ӧ����csv���÷���while��,ÿ��while��ȡһ��csv���ݡ�
ͨ�������������������
ѭ��������
��ߵ����õĴ���������ӽڵ�����ѭ��,�ǿ��Զ��̵߳Ĵ�����˵�
��:�߳�ѭ��������2,ѭ��������Ҳ��2,ͬʱ��ߵ�ForEach�������ı�������3��ֵ,ִ�д�������2X2X3 =12
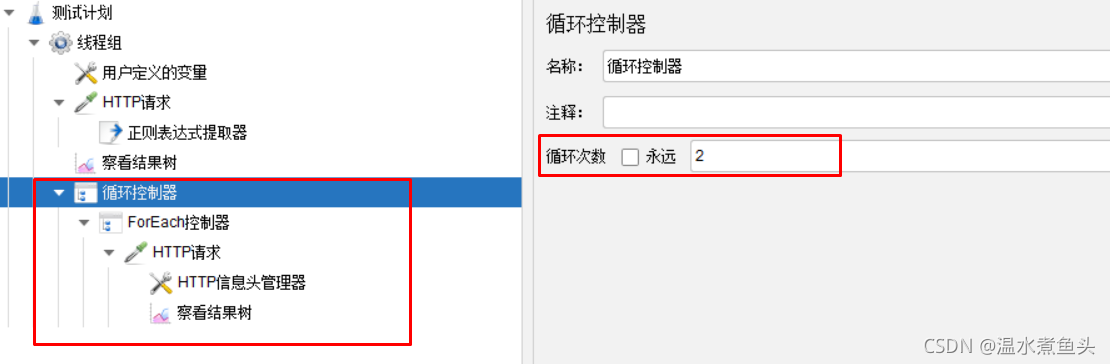
���������
��ѡ�� generate ֮��,����������µ����� sampler �ڽ�����ж��ᱻ����һ��ģ�顣
�����ھۺϱ�����,��Щ sampler ����Ӧ���ݻᱻ����
Jmeter �еĶ�ʱ��
��ͬ���������ĵȴ�ʱ��,���������Ƶļ��ϵ�,�������߳�½��ִ����ǰ�ò�����,�����ϵ�ȴ�ִ�в�������
��ʱ��(Timer)���ڲ���֮�����õȴ�ʱ��,�ȴ�ʱ�������ܲ����г��õĿ��ƿͻ���QPS���ֶΡ�������LoadRunner����ġ�˼��ʱ�䡱�� JMeter ������Bean Shell Timer��Constant Throughput Timer���̶���ʱ���Ȳ�ͬ���͵�Timer��
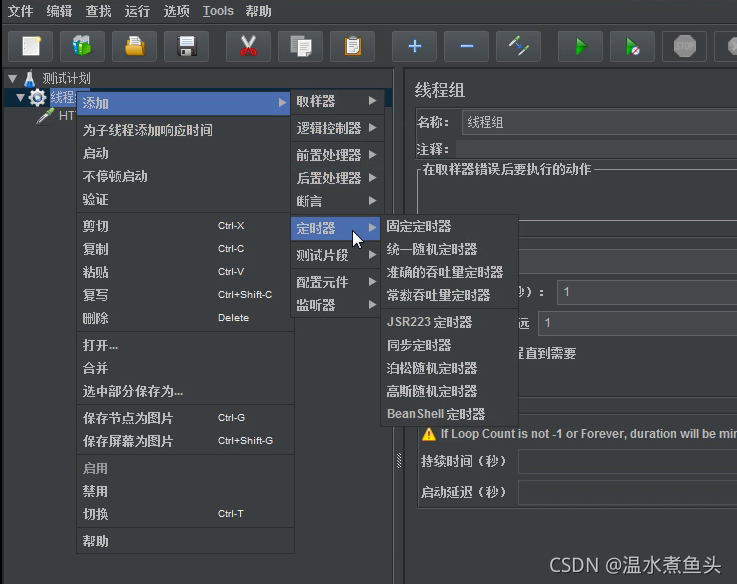
Jmeter �е�ǰ�ô������ͺ��ô�����
��ǰ�ô�������ȥ�༭�û��IJ�����,��������ȵ�,������
ǰ�ô�����������ʵ�ʵ�����֮ǰ�Լ���������������������������,��RUL����sessionID һ���session��Ϣʱ,����ͨ���ô�������䷢�������ʵ�ʵ�sessionID ;��������á�
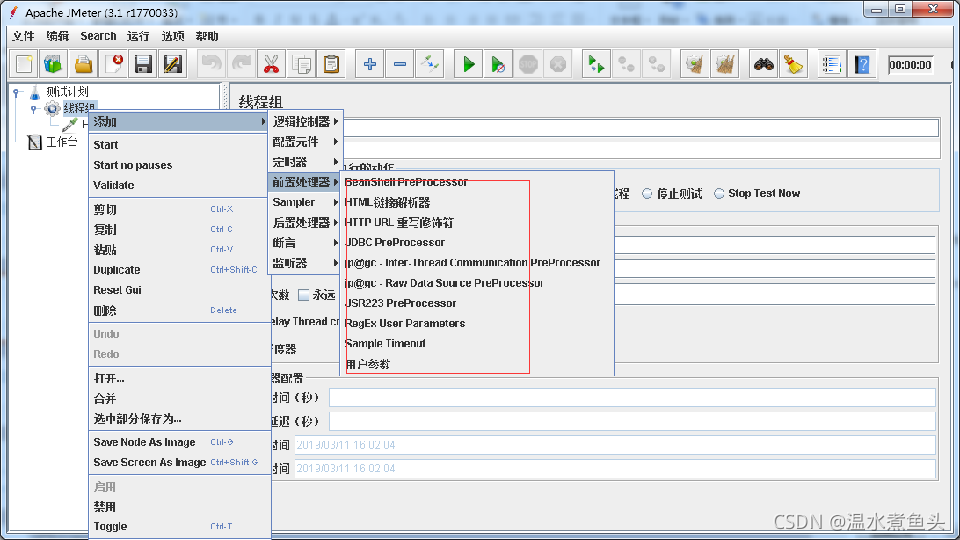
���ô����������ڶ�Sampler ���������õ��ķ�������Ӧ���д�����һ��������ȡ��Ӧ�е��ض�����(����LoadRunner���Թ����еĹ�������)������,XPath Extractor �����������ȡ��Ӧ������ͨ������XPath ֵ��õ�����;�������ʽ��ȡ��,�������ȡ��Ӧ������ͨ���������ʽ��õ�����
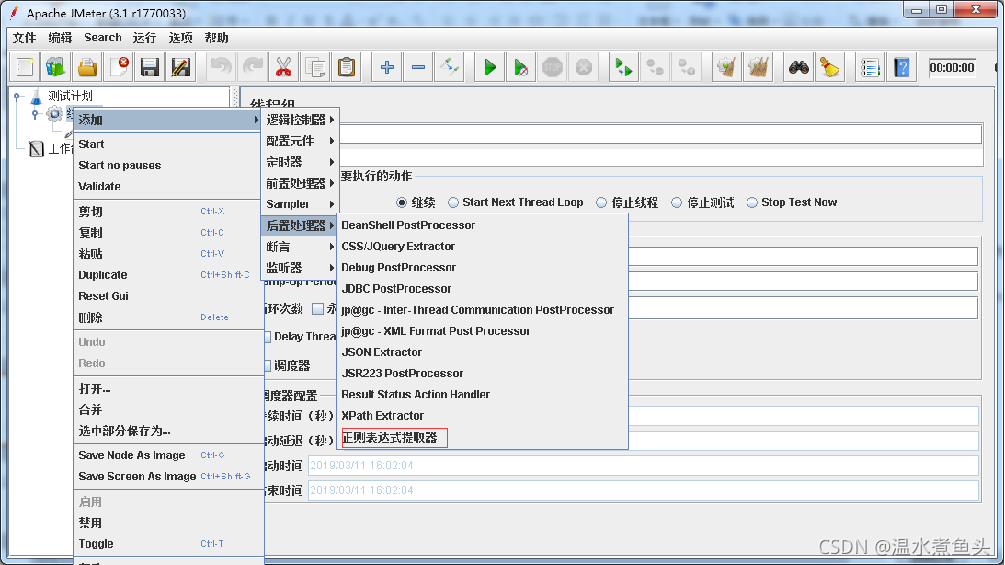
Jmeter �еĶ���
һ��ʹ����Ӧ����Response Assertion
�������ڼ������еõ�����Ӧ���ݵ��Ƿ����Ԥ��,����һ���������ü���,���Ա�֤���ܲ��Թ����е����ݽ����Ƿ���Ԥ��һ�¡�
4.ǰ�ô�����
5.������
JSON��ȡ��
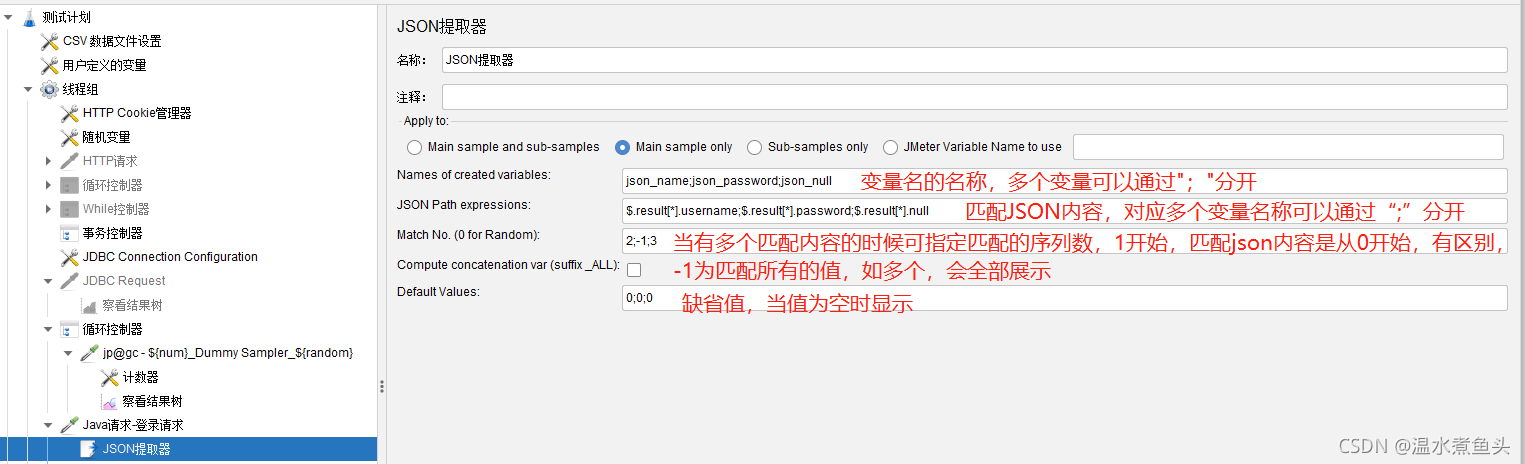
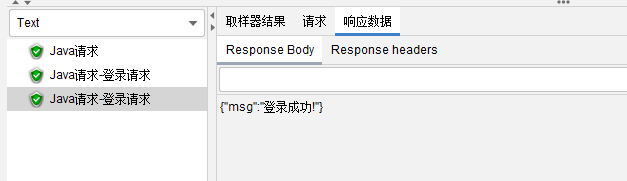
ģ���json��Ӧ����:
{"msg":"��¼�ɹ�!",
"result":[
{"username":"hy",
"password":"123456a"},
{"username":"hy2",
"password":"123456b"}
],
"element":[
{"ele":"ele1"},
{"ele":"ele2"},
{"ele":"ele3"}
]
}
$.key ƥ�䵥��key,�������msg,$.msg,ƥ������Ϊ:��¼�ɹ�!
��Ҫƥ��username������,����Ҫ$..name,��ʾƥ���������ݵ�name,���ؾ��С�������_1��= hy �� ��������_2�� = hy2
$.result[*].username[0]; �ڵ����result�²���username,��usernameΪkey��ȡvalueֵ,"hy"
$.result[1].password; �ڵ���result���ų���һλ,�µ�passwordֵ,"123456b"
$..[?(@.ele== "ele1")] ����ele== "ele1"���ڵ�list����
$.element[2] ,��ʾ˳��ȥindex+1������,����ǵ�3������
$.element[:2], ����ȡindex������
$.element[2:],
$.element[-3], ��Χ"ele":"ele1"
$..[?(@.username)] ,��ȡ��username�����нڵ�,
1.{"password":"123456a","username":"hy"}
2.{"password":"123456b","username":"hy2"}
��߽��java������������JSON��ȡ�����ݽ��з���
$.result[*].username;$.result[*].password;$.result[*].null
�������ʽ��ȡ��
1������:��Ӧ���ĵ�����
2��Body(unescaped):����,���滻�����е�htmlת�������Ӧ��������,ע��htmlת�������ʱ������������,��˿����в���ȷ��ת��,��̫����ʹ��
3��Body as a Document:�Ӳ�ͬ���͵��ļ�����ȡ�ı�,ע�����ѡ��Ƚ�Ӱ������
4��Response Headers:��Ϣͷ,����Ӧͷ
5��Request Headers:������Ϣͷ
6��URL:����url
7��Response Code:��Ӧ״̬��,����200��404��
8��Response Message:��Ӧ��Ϣ
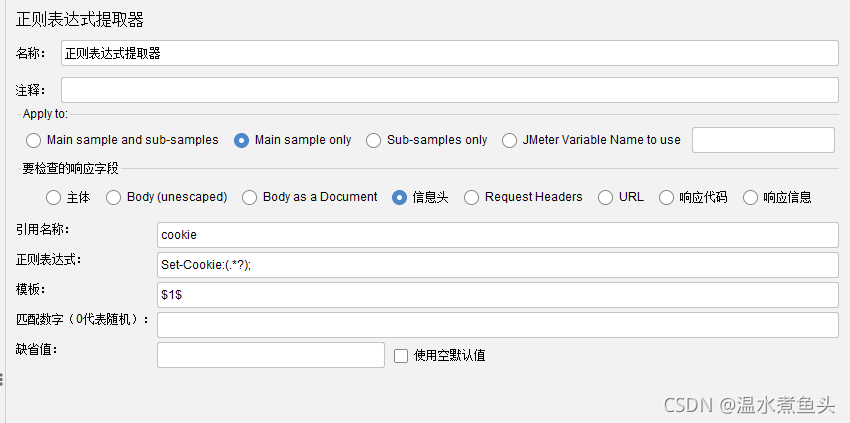
- ��������:
����ʹ�øñ���ʱ��:${��������}
- �������ʽ:
��ͼ��:set-Cookie:(.?);
��set-Cookie��ͷ,��;��β,ƥ��()�������
��߽�(.?)�ұ߽�,���ұ߽����Ϊ����ȷ��λ����ƥ�������,(.*?) ���滻����Ҫ��ȡ������
():�������IJ��־���Ҫ��ȡ�ġ�
.:ƥ���κ��ַ�����
+:һ�λ��Ρ�
?:��Ҫ̫̰��,���ҵ���һ��ƥ�����ֹͣ��
- ģ��(Template):
�������ʽ����ȡģʽ��
����������ʽ�ж����ȡ���,������������ʽ,ģ��
1
1
1,
2
2
2�ȵ�,��ʾ�ѽ������ĵڼ���ֵ��������;��1��ʼƥ��,�Դ����ơ���ֻ��һ�����,��ֻ����
1
1
1;
- ȱʡֵ:ƥ��ʧ��ʱ���Ĭ��ֵ;
- ƥ������:�������ʽƥ�����ݵĽ�����Կ���һ������,��ʾ���ȡֵ:0�������ȡֵ,����n���ʾȡ��n��ֵ(����1����ȡ��һ��ֵ),�������ʾ��ȡ���з���������ֵ��
���״̬������(Result Status Action Handler)
�������û�����ص�����(ȡ����)ʧ��ʱ,ֹͣ�̻߳�ֹͣ���Եȶ��ַ�ʽ��
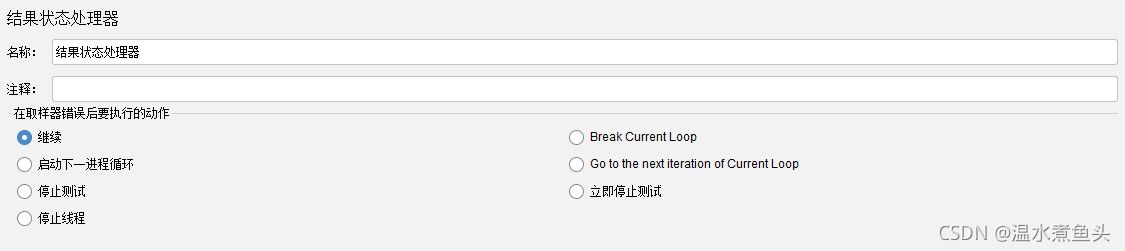
Break Current Loop:������ǰѭ��
go to the next iteration of current loop:���뵱ǰѭ������һ������
6.����Ԫ��
����Ԫ��(config element)�����ṩ�Ծ�̬�������õ�֧�֡�CSV Data Set config ���Խ����������ļ��γ����ݳ�(Data Pool),����Ӧ�� HTTP ��Ϣͷ������ ����������������������������ʽ����¼���ݷ��ء�
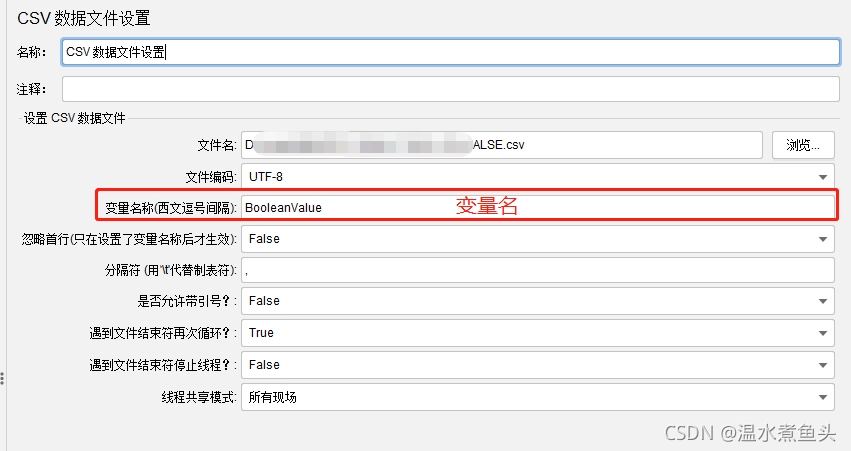
CSV�����ļ�����
��������һ������demo���������ݻ�ȡ
��������,��ÿ��ִ��ʱ���ȡһ������,���ݱ���ͨ����,������,�ӵ�����������Whileѭ�����ʹ�á���������->While������
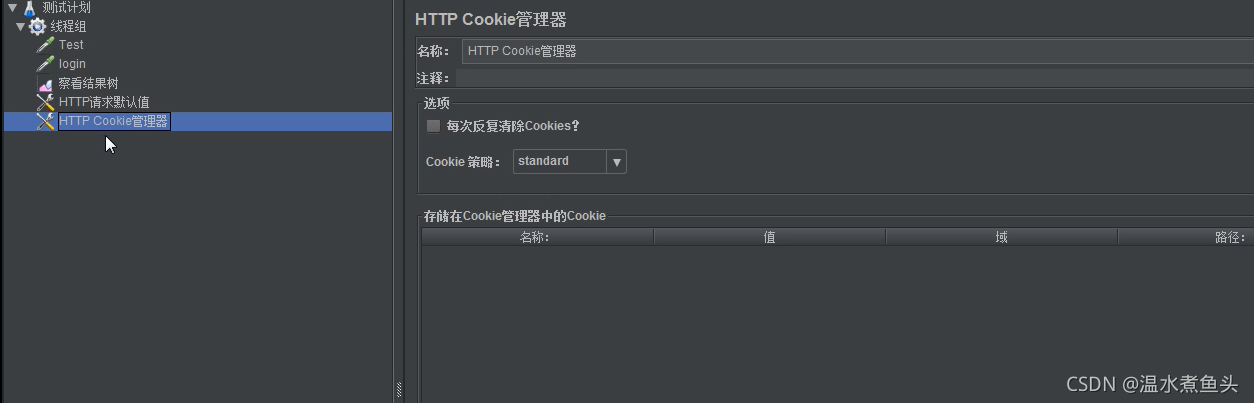
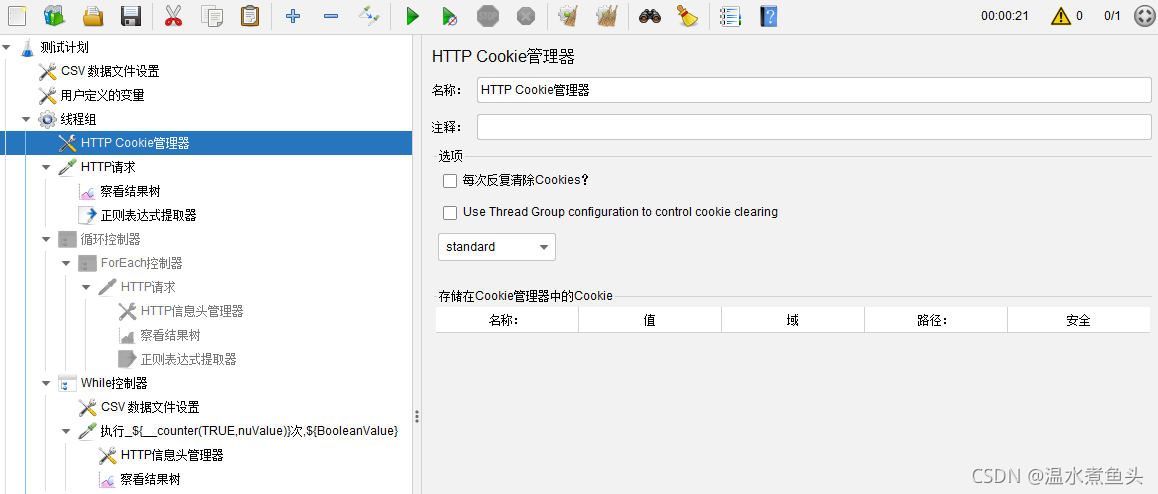
HTTP Cookie������
Cookie��������Ĭ������,�ڽ���һ���������ȡ��ǰ�����cookieֵ�����ں���������
����ͼ����2��HTTP����,��������HTTP Cookie��������,��һ��������Cookie���������ռ���һ�������Cookie,���ڵڶ���������ʹ�á�
HTTP��Ϣͷ������
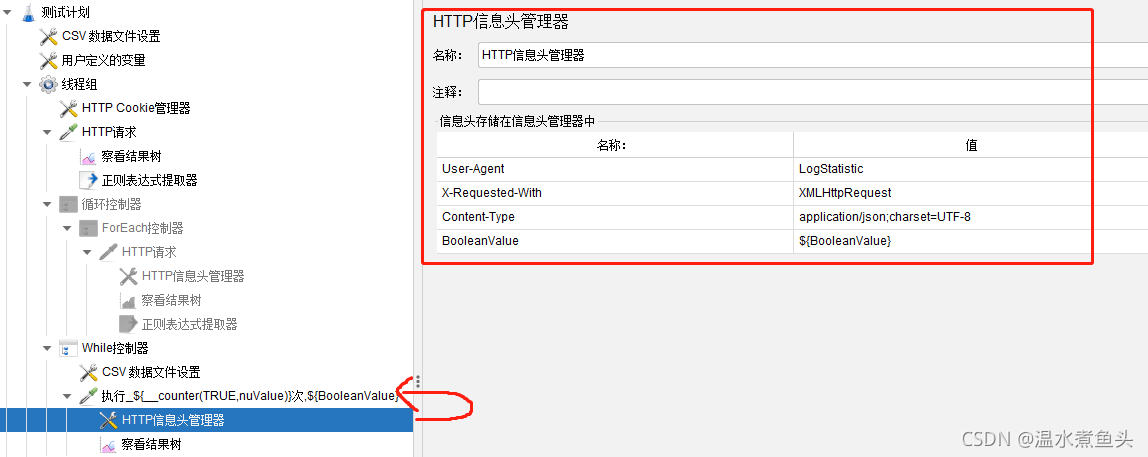
���õ���Ϣͷ:
Accept:text/htmil,application/xhtml+xml,application/xml:a=0.9,image/webp,image/apng,/:q=0.8
Accept-Encoding:gzip,deflate,br
Accept-Language:zh-CN,zh;q=0.8
Coonection:keep-alive
User-Agent:Mozilla/5.0 (Windows NT 6.1; WoW64) AppleWebKit/537.36(kHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36
Content-Type(�������ʵ���Ӧ��MIME��Ϣ,ʹ��Content-type��ָ����ͬ��ʽ��������Ϣ):
1.application/x-www-form-urlencoded : form�������ݱ�����Ϊkeyvalue��ʽ���͵�������(����Ĭ�ϵ��ύ���ݵĸ�ʽ)
2.mutipart/form-data :��Ҫ�ڱ����н����ļ��ϴ�ʱ,����Ҫʹ�øø�ʽ
3.application/json : JSON���ݸ�ʽ
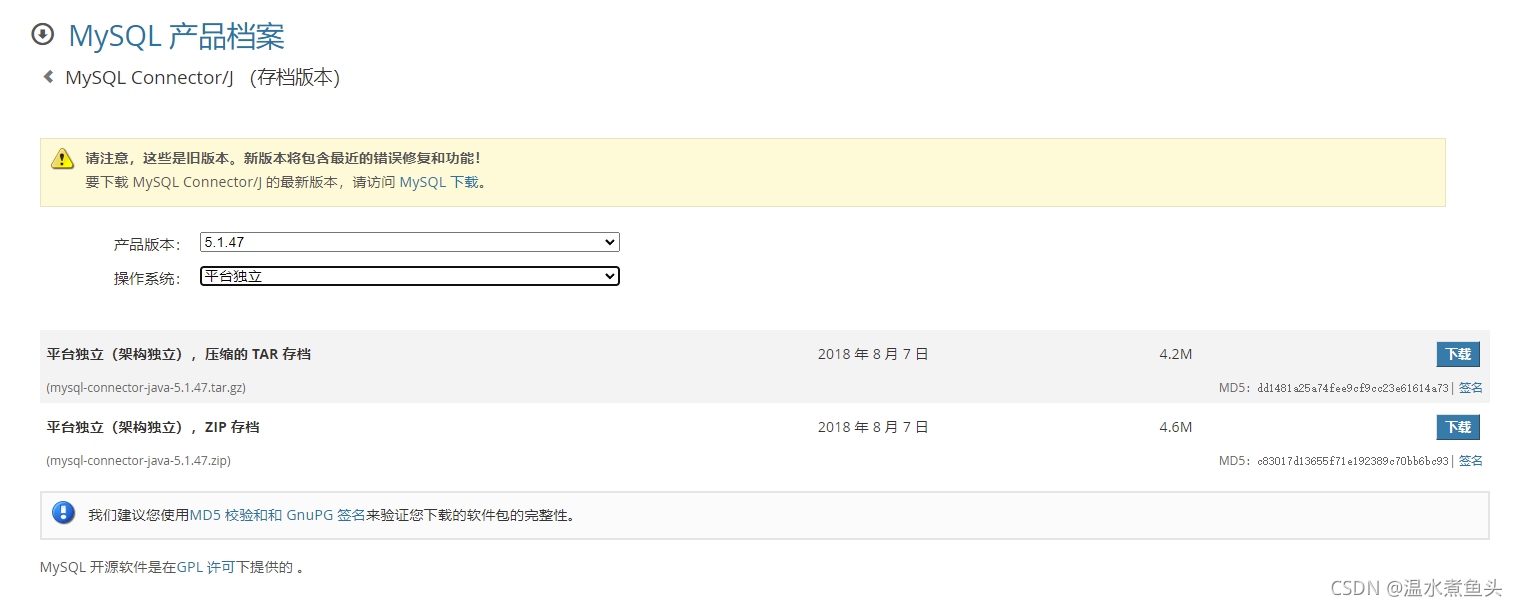
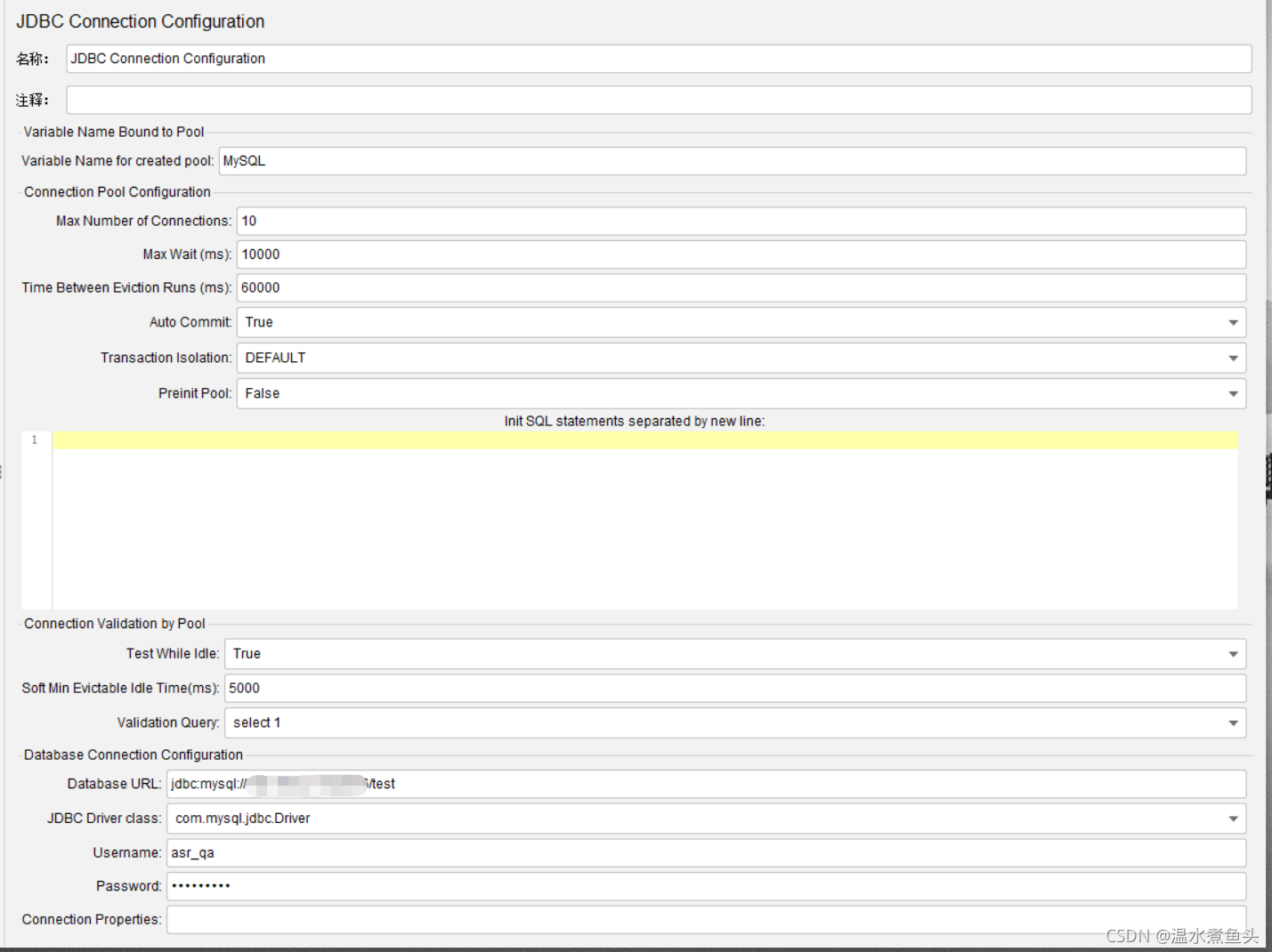
JDBC Connection Configuration
��Ҫװmysql-connector-java-5.1.47.jar��lib/Ŀ¼��
https://downloads.mysql.com/archives/c-j/
- Variable Nam
���ݿ����ӳص�����,��Ϊһ�����Լƻ������ж�� JDBC Connection Configuration,ÿ
������ȡ��ͬ�����ơ��� jdbc request ��ͨ���������ѡ����ʵ����ӳؽ���ʹ�á� - Connection Pool Connetion:���ӳز�������,��������Ĭ��,������Ҫ������;
- Max Number of Connections: ���������;���������ʱ,������ 0,���Ĭ��Ϊ 10,
���ֻ������ 10 ���߳�; - Max Wait(ms):���ȴ�ʱ��,��λ����;
- Time Between Eviction Runs(ms):�п��е��߳���,�ͷŲ�ʹ�õ��߳�;
- Auto Commit:�Զ��ύ,Ĭ��Ϊ true,�������ݿ�ʱ,�Զ� commit;
- Transaction isolation:�������(Ĭ��);
��������������,��Ҫ�����¼���ѡ��:(��JMX�ӽ���)
��TRANSACTION_NODE ����ڵ� ��
TRANSACTION_READ_UNCOMMITTED ����δ�ύ����
TRANSACTION_READ_COMMITTED �������ύ�� ��
TRANSACTION_SERIALIZABLE �������л� ��
DEFAULT Ĭ�ϡ�
TRANSACTION_REPEATABLE_READ �����ظ����� - Connection Validation by pool:��֤���ӳ�;
- Test While idle:���ڲ��Կ���
- Soft Min Evictable Idle Time(ms):
- Validation Query: ��֤��ѯ,����selcet 1
- Database Connection Configuration:���ݿ���������:
- Database URL:���ݿ����� url;jdbc:mysql://localhost:3306/dbname,ipaddr:3306
- JDBC Driver class:���ݿ�����;com.mysql.jdbc.Driver
- username:�û���
- password:����
- Connection Properties:��������
���JDBC������ʹ��
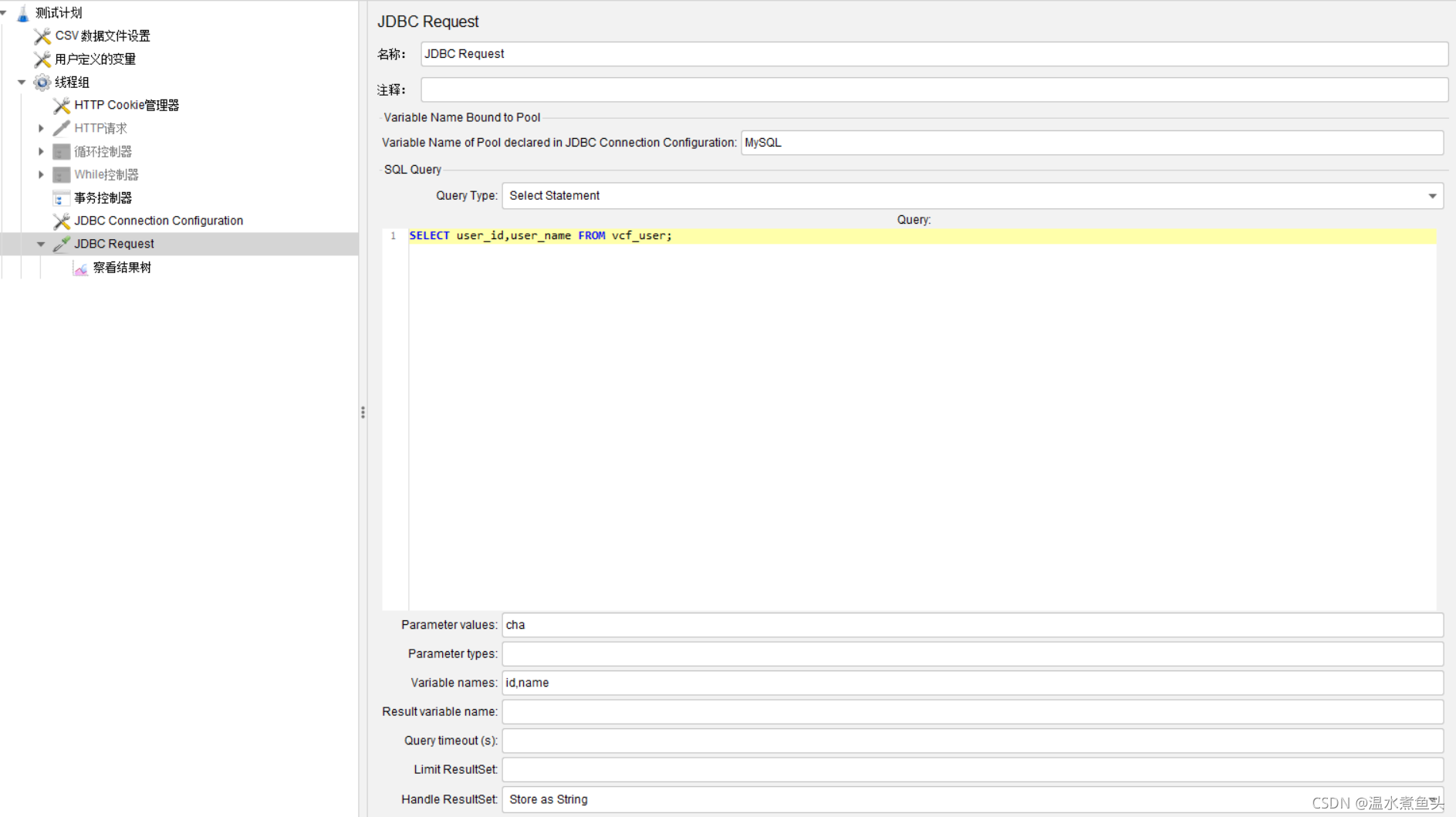
��� Sampler ����ͨ�� sql ��������ݿⷢ��һ�� jdbc ����,���Ի�ȡ���ص����ݽ���
��������������Ҫ�� JDBC Connection Configuration(�������ݿ����ӵ��������)һ��
ʹ��
Parameter values:����ֵ
Parameter types:��������
Variable Name:���ݿ����ӳص�����,��Ҫ�� JDBC Connection Configuration �� Variable
Name Bound Pool ���ֱ���һ��
Query:��� sql ���
Parameter valus:����ֵ
Variable names:���� sql ��䷵�ؽ���ı�����
Result variable name:����һ���������,�������з��صĽ��
Query timeout:��ѯ��ʱʱ��
Handle result set:������δ����� callable statements ��䷵�صĽ��
�������(Random Variable)
ÿִ��һ���̻߳��ȡһ�α�������
���¾�������1~20��һ������,��random���
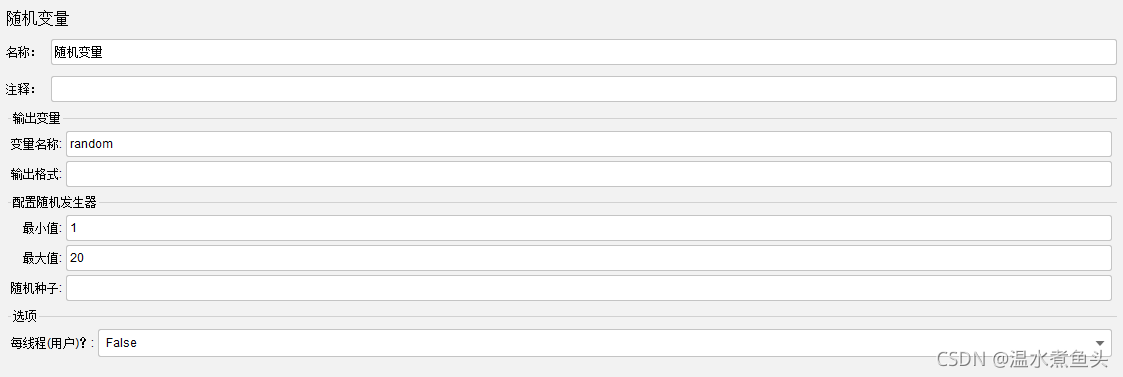
������
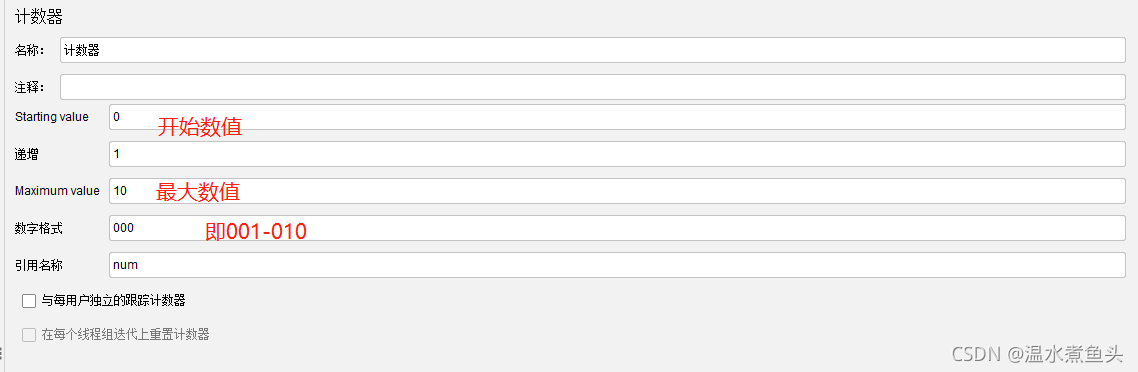
�����ѭ����������ʹ��,��ѭ���н��м���
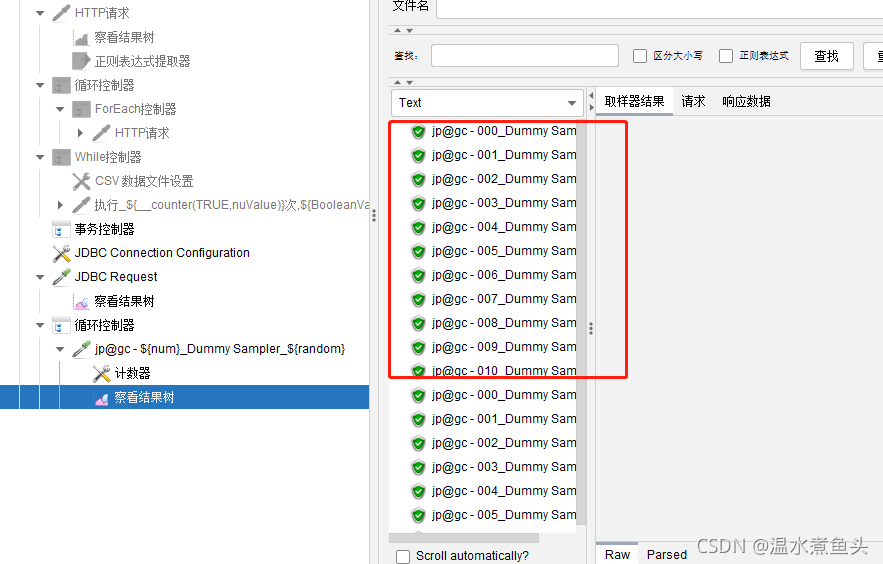
7.����
����,��Ϊ˳��ִ�еĵ����ڶ���,Ϊ������֮ǰִ�С�������Ӧ���ԡ�
��Ӧ����
����:��Ӧ���ݰ�����Ҫƥ������ݾ���ɹ���
ƥ��:��Ӧ����Ҫ��ȫƥ������,�����ִ�Сд��
���:������ȫ������Ӧ�����ݡ�
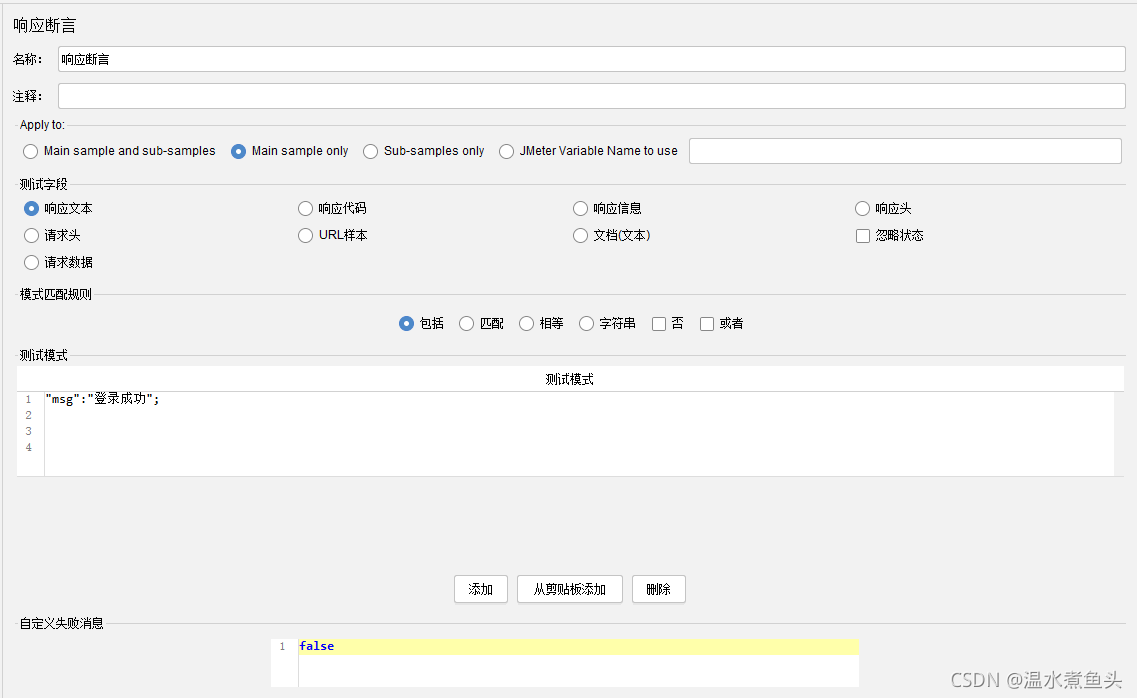
���Գ���ʱ��
Լ����Ӧʱ��,��Ӧʱ���������Լ��,�����Ϊʧ��
8.������
����������ɲ�����������ϵͳ��Դ��Ԫ�������������Բ��Խ�����ݽ��д����Ϳ��ӻ�չʾ��һϵ��Ԫ����ͼ�ν�����鿴��������ۺϱ��桢�ñ���쿴����������Ǿ����õ���Ԫ����
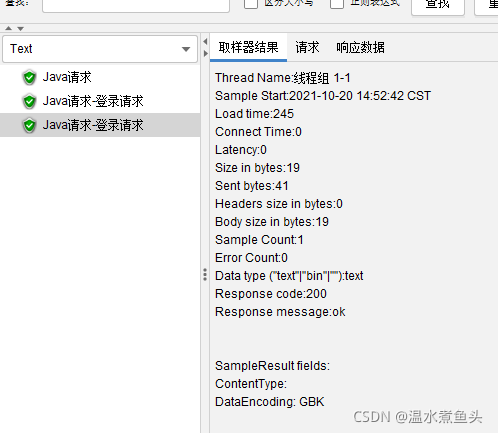
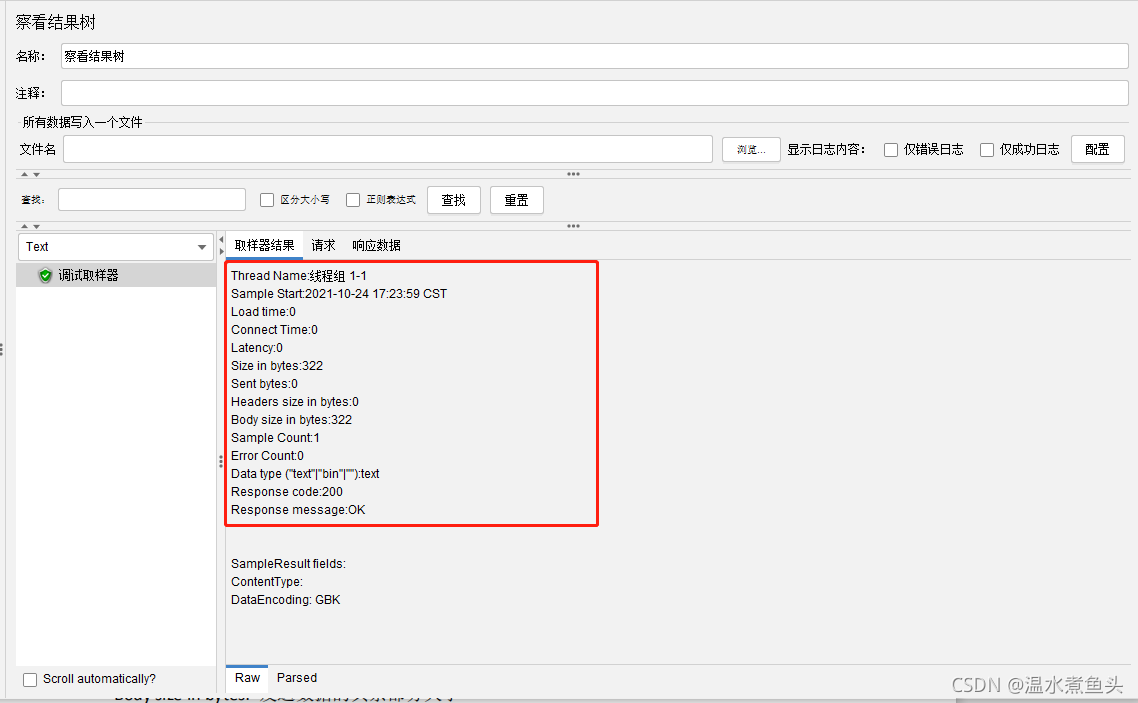
�鿴�����
Thread Name: �߳�������
Sample Start: ������ʼʱ��
Load time: ����ʱ��,���ʱ�������Dz��Գ��õ�ʱ��,Ҳ���������������ʱ��,��
���͵��������ȫ�����ĵ�ʱ��
Latency: �ȴ�ʱ��,������,��ʾ�������͵��տ�ʼ������Ӧʱ��ʱ��
Size in bytes: ���͵������ܴ�С
Headers size in bytes: ����ͷ��С
Body size in bytes: �������ݵ����ಿ�ִ�С
Sample Count: ����������ͳ��
Error Count: ��������ͳ��
Response code: ������
Response message: ������Ϣ
Response headers: ���ص�ͷ����Ϣ
���Խ��
��չʾ���ж��ԵĽ��
PerfMon Metrics Collector(��ط�����)
���ڼ�������������Դ���,��Ҫ��װ��������øò��,����Ҫ�ڷ������ϰ�װ��������ز����
�� ServerAgent-x.x.x.zip ��ѹ�������Ҫ��صķ�������,��ִ��
chmod 777 startAgent.sh ������ҪrootȨ��
./startAgent.sh ִ��
������ִ�е�ʱ���������:
�������Ͽ�����Ĭ�϶˿�:./startAgent.sh -�Cudp-port XXXX -�Ctcp-port XXXX
����ǽ�ϵĶ˿���Ҫ����
���������IP/�˿�,��Ҫ��һ��������ļ�
xxx.txt ���ݿ����±༭
<?xml version="1.0" encoding="UTF-8"?>
<testResults version="1.2">
</testResults>
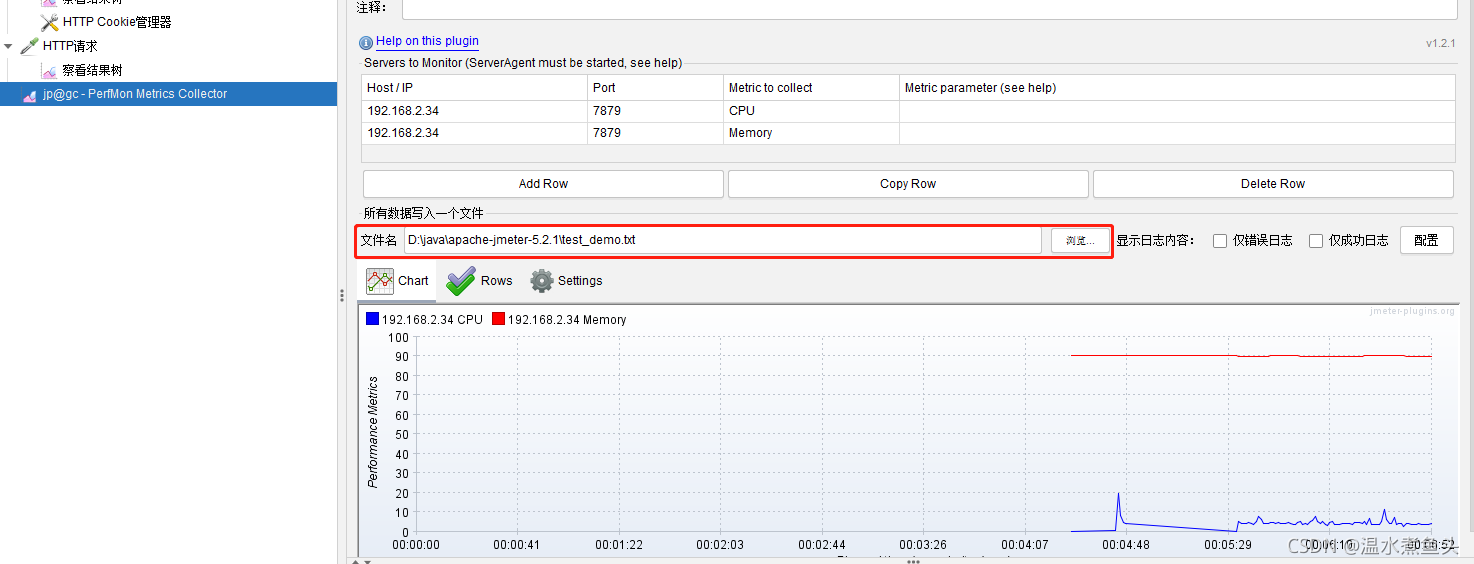
AutoStop Listener (�Զ�ֹͣ������)
- average Response Time is greater than 10000ms for 10 seconds :���� 10sƽ����Ӧʱ�����10000ms ֹͣ���ԡ�
- average Latency is greater than 5000ms for 10seconds :���� 10s ƽ���ȴ�ʱ����� 5000ms ��ֹͣ���ԡ�
- Error Rate is greater than 50% for 10 seconds :10s �ڴ�����һֱ���� 50%��ֹͣ���ԡ�
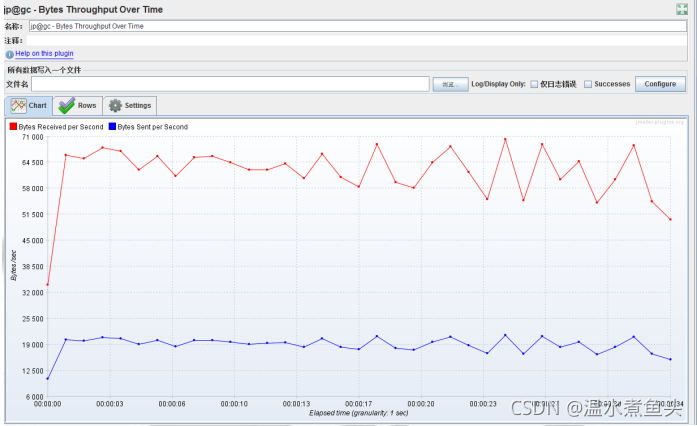
Bytes Throughput Over Time(��ͬʱ��������չʾ,���ֽ�չʾ)
9�����˳��
��ͬһ����������Χ��(��������������),���Լƻ��е�Ԫ����������˳��ִ�С�
- ����Ԫ��(config elements)
- ǰ�ô�������(Per-processors)
- ��ʱ��(timers)
��ʱ���Ƕ�ÿ���������ļ���������������ļ��,��������ʱ���Ƿ���ij�������������,��ô�Ƕ�����������������õ� - ȡ����(Sampler)
- ��������(Post-processors)
- ����(Assertions)
- ������(Listeners)
10�������Ӧ����������
��ʽһ:
����һ�����ô�����BeanShell ���ô�������
prev.setDataEncoding("UTF-8");
����֮���ٲ鿴��Ӧ����Ͳ���������,����BeanShell��������������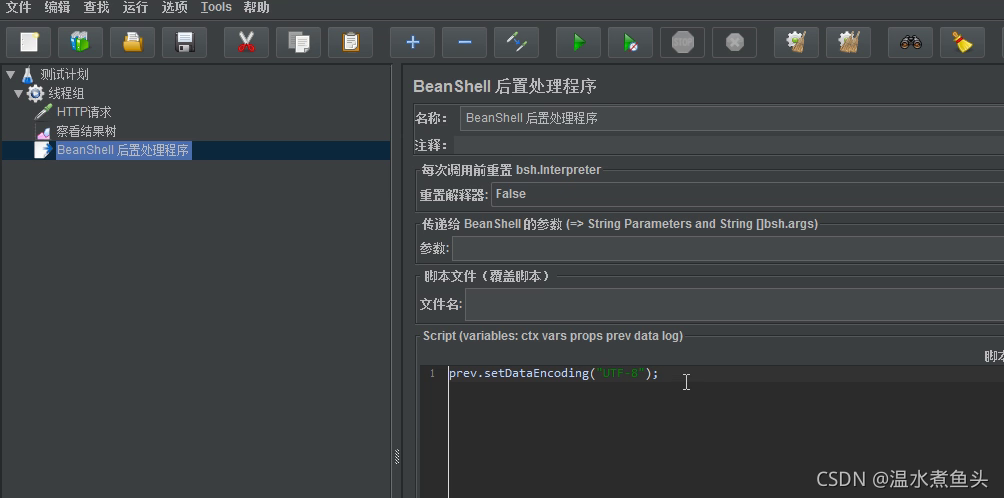
��ʽ��:
�����Խ��:
��Jmeter��binĿ¼���ҵ�Jmeter.properties
����֮��Ϳ�����Ч��

11��Jmeter����
1.JMeter����ͳһ������jmeter.properties�ļ���,���ǿ����ڸ��ļ��������Զ��������
2.JMeter�����ڲ��Խű����κεط����ǿɼ���(ȫ��),ͨ������������һЩJMeterʹ�õ�Ĭ��ֵ,�����������̼߳䴫����Ϣ��
3��JMeter���Կ����ڲ��Լƻ���ͨ������ _P ��������,���Dz�����Ϊ�ض��̵߳ı���ֵ��
4��JMeter���Կ���ͨ��_setProperty ����������JMeter����
5��JMeter�����Ǵ�Сд���е�
��������

����1:__setProperty
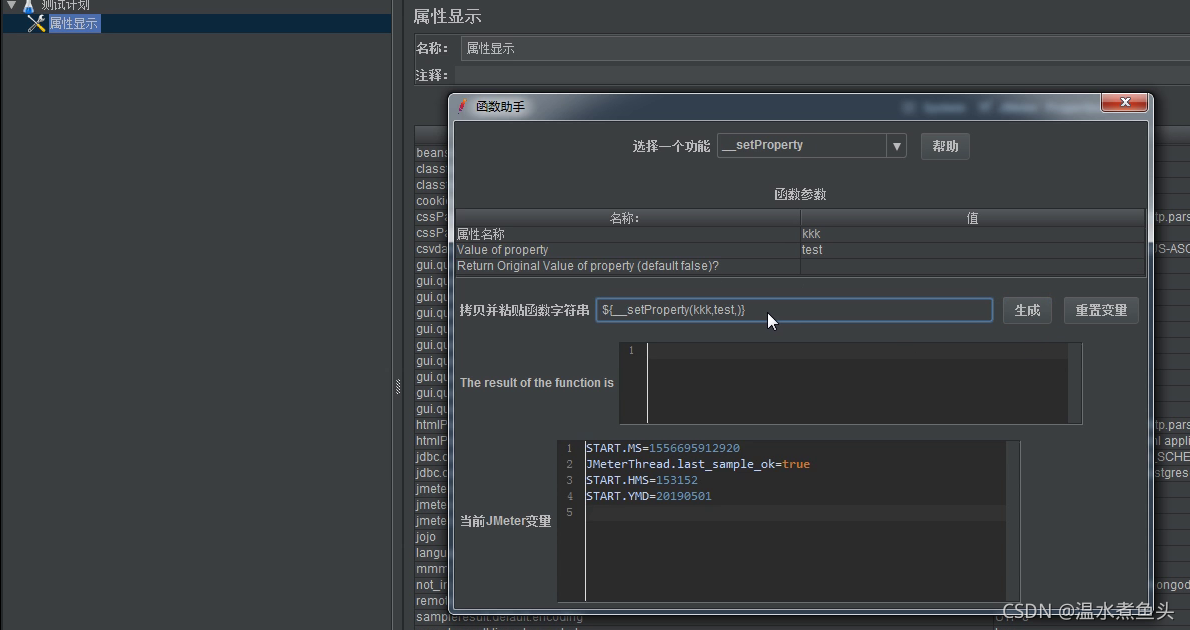
����֮��,��Jmeter�������ͻ�������ƴ���kkk������
���Կ���������ȫ��
����2:___p
ƥ�亯������,�����ƥ��ĺ�������Ĭ��ֵȡĬ��ֵ,
12��Jmeter����
���巽ʽһ:
���Լƻ�ģ��ʱ���Զ��������
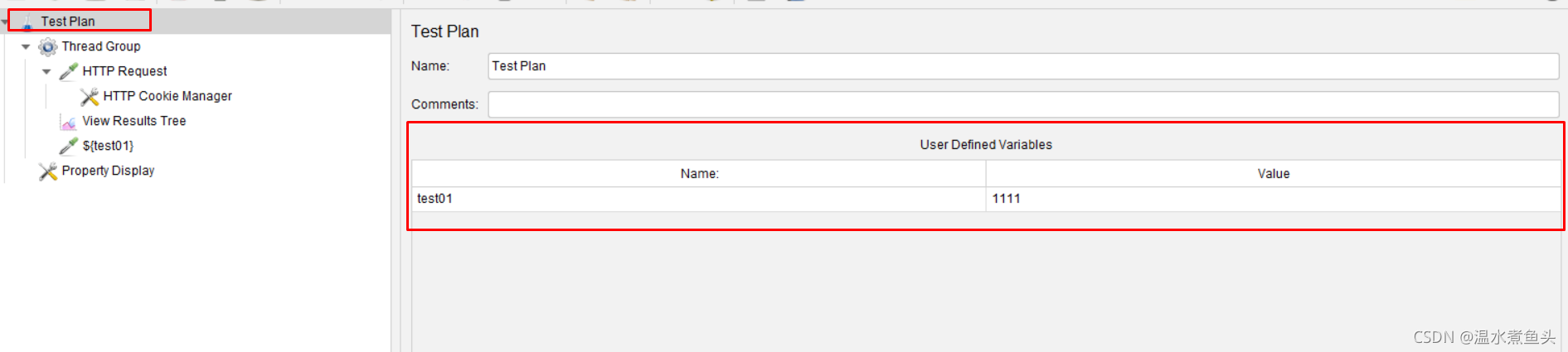
1��JMeter�������ڲ����̶߳����Ǿֲ�������
2���ڲ�ͬ�����߳���,JMeter�����ȿ�������ȫ��ͬ��,Ҳ�����Dz�ͬ�ġ�
3��JMeter�������÷���:${name}
4��JMeter�����Ǵ�Сд���е�
5�������ij���̸߳����˱���,��ô�����Ǹ����˱����ڸ��߳��и��Ƶ�ֵ
6��Jmeter�ж�������ĵط�:
����a) ������������ͬ����һ���͵IJ��������ݷ��������õ���������,�����Ӳ�ͬ���͵IJ���
��b) �߳���,�Ҽ�ѡ�� ����Ԫ��( config element)�C>User Defined Variables
7��Jmeter�еı���
��������:�����Ǿ����ֵ,Ҳ�����Ǻ���(�������Զ�����:ѡ��-�������ֶԻ���)
13.Jmeter��������
����ָ��
����: �Ա���ϵͳ����ʩѹ,ֱ������ָ�곬��Ԥ�ڻ�ij����Դʹ�ôﵽ����,��֤ϵͳ�Ĵ�������,Ϊϵͳ���ܵ����ṩ���ݡ�
����:
�����岢��:�����û���ͬһʱ������ͬ���IJ���,����1000���û�ͬʱ��½��
�ڹ����ϵIJ���:����û���ϵͳ�����˽���,��Щҵ����������ͬ��Ҳ�����Dz�ͬ��,��������ʹ����ࡣ
ѹ��: ϵͳ�ڱ���״̬��(CPU\�ڴ�ȱ���),�ܹ������Ự������,�Լ�ϵͳ�Ƿ����ִ���
�ص�:��ҪĿ���Ǽ��ϵͳ����ѹ�������Ӧ�õ����ܱ���,�ص�������������Ϣ����,ϵͳ��Ӧʱ��ȡ�
��Ӧʱ��: ��Ӧʱ���ǡ�������������Ӧ����Ҫ��ʱ�䡱
һ����չ�ֵ�ʱ��,һ����ϵͳ��Ӧʱ��,�û����ܵ�����չ��ʱ��,ȡ���ڿͻ��˽��յ���Ӧ���ݺ���ֵ�ҳ�������ĵ�ʱ��,��ϵͳ��Ӧʱ����ָ��������ʼ���ͻ��˽��յ����������ĵ�ʱ�䡣
��������ͼ
����ƽ̹����:�ڲ����и������ܵ�����������������ﵽ���������
ѹ������:�������½�������
�յ�����:���ܿ�ʼ�����½�������
������
�����ܲ��Թ����������ϴ�������������ܺ͡��ڵ���ҵ����,�ͻ�����������˽��е����ݽ�������
��ɫ:ÿ������ֽ���
��ɫ:ÿ�뷢���ֽ���
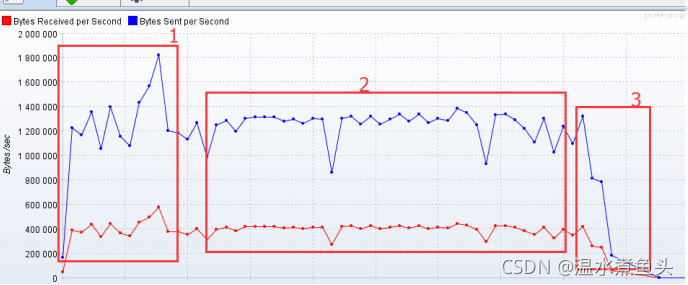
������������������ ,˵����ϵͳ�ĸ�������
1 ��������,�������븺�س�����,���Խ������Խǿ
2 ��ƽ�Ƚ�,�������渺�ر����ȶ�,���Խ��ϵͳԽ�ȶ�
3 ���½���,�������븺�سɷ���,���Խ��ϵͳ�ݴ���Խǿ
�Խ���ʽӦ����˵,������ָ�귴ӳ���������ܵ�ѹ��,�����滮�IJ��������ܹ�˵��ϵͳ����ĸ�������
������
������/����ʱ��,����λʱ���������ϴ����������,Ҳ����ָ��λʱ���ڴ����ͻ���������,���Ǻ����������ܵ���Ҫָ�ꡣ
ͨ�������,�������á��ֽ���/�롱������,��Ȼ,Ҳ�����á�������/�롱�͡�ҳ����/�롱
��������Jmeter �ṩ�����ֲ�ͬ��ͼ����չʾ��
TPS
Transaction Per Second:ÿ��������,ָ�������ڵ�λʱ����(��)���Դ�������������,һ���� request/second Ϊ��λ;
QPS
Query Per Second:ÿ���ѯ��,�е�����TPS,��ʾÿ���ѯ��Ӧ������,ָ�������ڵ�λʱ����(��)�����IJ�ѯ��������;
Response Time:��Ӧʱ��,ָһ�����Ѷʱ�����;ϸ�ֻ�����С�����Ӧʱ��,50%��90%�û���Ӧʱ��ȡ�
��Դָ��
CPU ʹ����
ָ�û�������ϵͳ�������ĵ�CPUʱ��ٷֱ�,�����ֵ��������95%,����CPU����ƿ����
cpuƿ������:
1����Ӧʱ�����(slow response time)
2��CPU ����ʱ��Ϊ��(zero percent idle CPU)
3�����ߵ�ϵͳռ�� CPU ʱ��(high percent system CPU)
4�����ߵ��û�ռ�� CPU ʱ��(high ercent user CPU)
5����ʱ����кܳ������н��̶���(large run queue size sustainedover time)
�ڴ�������
�ڴ������� = (1-�����ڴ�/���ڴ��С)*100%,һ��������10%�����ڴ档�����ֵż���߸�,������ʱ���߳̾����ڴ档��������߸�,���ڴ������ƿ��,Ҳ�������ڴ���������ʵ͡�
�ڴ�ƿ������:
1�����̽��벻�״̬;
2�����������д��̵Ļ�����ܸ�;
3���ܸߵ�CPU������;
4���ڴ����(out of memory errors)
����I/O
������Ҫ���ڴ�ȡ����,���˵��IO������ʱ��,������������Ӧ�IJ���,�����ݵ�ʱ���Ӧ����дIO,ȡ���ݵ�ʱ���Ӧ���Ƕ�IO,һ��ʹ��%Disk Time(�������ڶ�д������ռ�õ�ʱ��ٷֱ�)�������̶�д���ܡ�
����ò���һ�ºܸ�,����I/O������,���Կ��Ǹ��������Ӳ��ϵͳ��
����ƿ������:
1�����ߵĴ���������(high disk utilization)
2��̫���Ĵ��̵ȴ�����(large disk queue length)
3���ȴ����� I/O ��ʱ����ռ�İٷ���̫��(large percentage of timewaiting for disk I/O)
4��̫�ߵ����� I/O ����:large physical I/O rate(not sufficient initself)
5�����͵Ļ���������(low buffer cache hit ratio(not sufficient initself))
6��̫�������н��̶���,�� CPU ȴ����(large run queue with idleCPU)
�������
һ��ʹ�ü����� Bytes Total/sec ������,���ʾΪ���ͺͽ����ֽڵ�����,����֡�ַ�����;��
�����������ٶ��Ƿ���ƿ��,�����øü�������ֵ��Ŀǰ����Ĵ����Ƚ�
ϵͳָ��
�����û���
��λʱ������ϵͳ�����������û���;
�����û���
ij��ʱ���ڷ���ϵͳ���û���,��Щ�û�����һ��ͬʱ��ϵͳ�ύ����;
ƽ����Ӧʱ��
ϵͳ�����������Ӧʱ���ƽ��ֵ;�������Ӧʱ���Ǵӿͻ����ύ�������ͻ��˽��յ���������Ӧ�����ĵ�ʱ��;
����ɹ���
���ܲ�����,�����������ڶ���һ�����߶��ҵ�����̵�����ָ��,���û���¼���ύ�������ɶ���Ϊ����,��λʱ����ϵͳ���Գɹ���ɶ��ٸ����������,��һ���̶��Ϸ�Ӧ��ϵͳ�Ĵ�������,һ��������ɹ���������;
��ʱ������
��Ҫָ�������ڳ�ʱ��ϵͳ�ڲ�����������ʧ��ռ������ı���;
ע������
��jmeterʹ�ù�����,���ǿ���ͨ�����滯������ȥ����һ������,��ʵ��ִ�о���������������ʡ��Դ,���ѽ��������һ����־����,Ȼ���ٰ������־�����ó�������,չʾ�ͱ���������ĵ���Դ�Dz�һ���ġ�
������302���ֻ�����Զ��ض���
��ȡ������ͼƬ
cookie��ȡ
����Ԫ��-