����Ŀ¼
ǰ��
locust��һ����python��д��ѹ���,���Ժܺõĺ�python���н��ʹ��,����ǿ��
locust�ĵ���Ӣ�İ��,�������Ķ�,���Ĵ��ĵ�����,ģ����ʵ��ѹ�������볡��,��������locust��ǿ��
��װ
locust��װ����,ֱ��ʹ��pip3���а�װ
pip3 install locust
����Ƿ�װ�ɹ�
locust -V
����ʹ��
����1: ��Ŀ����,�ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,��Ҫģ��100���û�ͬʱ����,ÿ���û�����urlƵ����1-5��֮�����ѡ��,ѹ��10���ӡ�
��������������,��α�дlocustѹ��ű���?������������Žű���
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
����ýű��ļ�����Ϊlocust_test.py,����ʹ���Լ������������ű�
locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html
����������ں�����ϸ�о١�
-f locust_test.py //����ִ����һ��ѹ��ű�
--headless //��������ִ��
-u 100 //ģ��100���û�����
-r 100 //ÿ���û�������
-t 10m //ѹ��10����
--html report.html //html���������ļ�·������
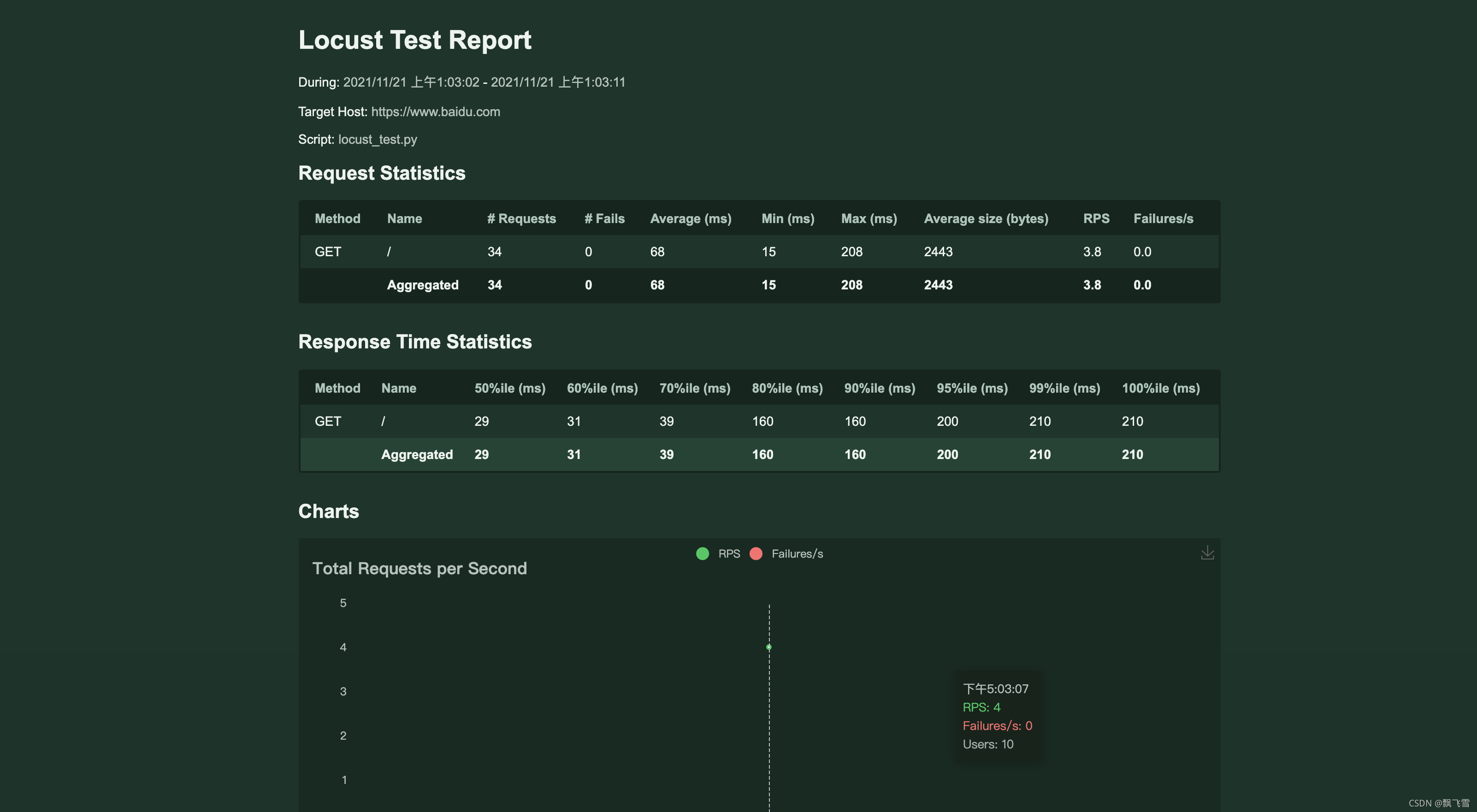
���html���Խ���������
User��
ÿ��locust�ű�����Ҫ�̳�User��,��User�ඨ����ÿ���û���ѹ����Ϊ��������������,QuickstartUser��̳�HttpUser��,��HttpUser��̳�User��,��ôUser���о�������Щ�����ء�
@taskװ����
��Ȼlocust������һ���û���,��ô��Ȼÿ���û���Ҫִ�ж�Ӧ������,@taskװ�����Ͷ�����һ������,������������ִ�еĹ���,����װ��������IJ������Զ���һ��int���������Ȩ�ء�
����2: �ӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com" ,get����,��Ҫģ��100���û�ͬʱ����,ÿ���û�����ѭ������"/hello"��"/world"�������ӿ�,����֮��û�м��,�����û�ѡ���������ӿڵı���Ϊ1:3,ѹ��10���ӡ�
import os
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
# wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
@task(3)
def hello_world(self):
self.client.get("/world")
if __name__ == '__main__':
os.system("locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html")
����Ұ�wait_time = between(1, 5)ע�͵��ˡ�����ִ��û�м��,����ÿ���û�ִ��wile True������ͣ����������������@task(3)����������Ȩ��,�ű������������ÿִ��4������,3���ǡ�/world�� 1����"/hello"
������
��������1,���������ÿ���û�����urlƵ�ʹ̶�2��,�����ô����?����������������ĸ���,��Ϊ����3��:
- ����������wait_time = between(a, b)
- ����̶����wait_time =constant(a)
- �������
��ô��������?��ʵ������ô����,ѹ����ʵ����ģ���û���������������,�����������ÿ���û���ͣ��while 1��������������,����̶�������������while 1 sleep�̶�ʱ���������������
����3: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,��Ҫģ��100���û�ͬʱ����,ÿ���û�����urlƵ�ʹ̶�2�뷢һ��,ѹ��10���ӡ�
from locust import HttpUser, task, constant
class QuickstartUser(HttpUser):
wait_time = constant(2)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
@tagװ����
��������Ҫѡȡ����һ������������������ѹ��ʱ,@tagװ�����ͷ��������ˡ�
class QuickstartUser(HttpUser):
# wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
@tag("task1")
def hello_world(self):
self.client.get("/hello")
@task(3)
@tag("task2")
def hello_world2(self):
self.client.get("/world")
@task(3)
@tag("task3")
def hello_world3(self):
self.client.get("/world")
��ǰ��3������,������Ҫֻѡȡtask2��task3������ô�� --tags task2 task2 �����Ϳ��Խ��������⡣
locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html --tags task2 task2
ǰ�������
�û���������on_start������/��on_stop�������û�������on_start������ʼ����ʱon_stop��������������on_start������ģ���û���ʼִ�и�����ʱ����,����on_stop��ģ���û�ִֹͣ�и�����ʱ����(��interrupt()�����û���ɱ��)
HttpUser��
HttpUser��̳���User��,����User���е�����HttpUser���,Ψһ���ڲ�ͬ����HttpUser���Լ�ʵ����http��������
ʹ�÷�����requests����ͬ,��ȡrequests�������ʹ��self.client�ķ�ʽ��ȡ������ص����һ��self.client�Ķ��Է�ʽ��
����4: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,post����,���ؽ��Ϊjson��ʽ{��code��:0,��msg��:��ok��},����code0�����ɹ�,-1����ʧ��,��Ҫģ��100���û�ͬʱ����,ÿ���û�����urlƵ�ʹ̶�2�뷢һ��,ѹ��10���ӡ�
import json
import os
from locust import HttpUser, task, tag, constant
class QuickstartUser(HttpUser):
wait_time = constant(2)
host = "https://www.baidu.com"
@task
@tag("task1")
def hello_world(self):
with self.client.post("/hello", catch_response=True) as response:
try:
status_code = response.status_code
text = json.loads(response.text)
if status_code != 200:
response.failure("status_code����ʧ��")
elif text["code"] != 0:
response.failure("code����ʧ��")
elif response.elapsed.total_seconds() > 0.5:
response.failure("Request took too long")
except Exception as e:
response.failure(str(e))
����
������ٷ��ĵ�:http://docs.locust.io/en/stable/configuration.html
����������
����г��������õIJ���
- -f locust_test.py //����ִ����һ��ѹ��ű�
- �Cheadless //��������ִ��
- -u 100 //ģ��100���û�����
- -r 100 //ÿ���û�������
- -t 10m //ѹ��10����
- �Chtml report.html //html���������ļ�·������
- -H https://www.baidu.com //������ʵ�host
- �Ccsv=CSV_PREFIX //����ǰ����ͳ����Ϣ�洢��CSV��ʽ���ļ��С����ô�ѡ����������ļ�:[CSV_PREFIX]_stats.CSV,[CSV_PREFIX]_stats_history.CSV��[CSV_PREFIX]_failures.CSV
- �Conly-summary //ֻ��ӡժҪͳ��
- �Cprint-stats //�ڿ���̨�д�ӡͳ����Ϣ
�����ļ�����
# master.conf in current directory
locustfile = locust_files/my_locust_file.py
headless = true
master = true
expect-workers = 5
host = http://target-system
users = 100
spawn-rate = 10
run-time = 10m
locust --config=master.conf
����ѹ�ⳡ��ʵս
���û��߲�������ѹ��
����5: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,��Ҫģ��4000���û�ͬʱ����,ÿ���û�����url�����,ѹ��10���ӡ�
HttpUser��֧�ָ߲���ѹ��,��ʱ����Ҫ��HttpUser����FastHttpUser����
from locust import FastHttpUser, task
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
ÿ���û�ѭ��ȡ����
����6: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,�и�������id,��ȡ�������ݽ�����ʵ����ѹ��,ÿ���û�ѭ����ȡ���ݡ�
from locust import FastHttpUser, task
def prepare_data():
# ��ids����,ģ����ļ��ж�ȡ
return [i for i in range(100)]
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data = prepare_data()
def on_start(self):
self.index = 0
@task
def hello_world(self):
id = self.data[self.index]
print(id)
self.client.get("hello", params={"id": id})
self.index += 1
self.index = self.index % (len(self.data))
��֤������������Ψһ��,��ѭ��ȡ����
����7: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,�и�������id,��ȡ�������ݽ�����ʵ����ѹ��,��֤ÿ��idֻ����һ��,��ѭ��ȡ���ݡ�
���ʹ�õ���python������Queue,�����̰߳�ȫ�ġ�
from queue import Queue
from locust import FastHttpUser, task
def prepare_data():
q = Queue()
# ��ids����,ģ����ļ��ж�ȡ
for i in range(100):
q.put(i)
return q
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data_queue = prepare_data()
@task
def hello_world(self):
id = self.data_queue.get(timeout=3)
print(id)
self.client.get("hello", params={"id": id})
if self.data_queue.empty():
print("����ѹ��")
exit()
��֤������������Ψһ��,ѭ��ȡ����
����8: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,�и�������id,��ȡ�������ݽ�����ʵ����ѹ��,��֤ÿ��idֻ����һ��,ѭ��ȡ���ݡ�
from queue import Queue
from locust import FastHttpUser, task
def prepare_data():
q = Queue()
# ��ids����,ģ����ļ��ж�ȡ
for i in range(100):
q.put(i)
return q
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data_queue = prepare_data()
@task
def hello_world(self):
id = self.data_queue.get()
print(id)
self.client.get("hello", params={"id": id})
self.data_queue.put_nowait(id)
���ʹ��data_queue.put_nowait(id),id����֮�������ض�����
�ݶ���ѹ
����9: �ҽӵ��˸�ѹ������,url��ַΪ"https://www.baidu.com/hello" ,get����,������Ҫ��������ݶ���ѹ,ÿ10��������20���û�,ѹ��3Сʱ,�Կ�̽������ƿ����
import math
import os
from locust import HttpUser, LoadTestShape, task
class QuickstartUser(HttpUser):
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("hello")
class StepLoadShaper(LoadTestShape):
'''
����ʵ��
��������:
step_time -- ����ʱ��
step_load -- �û�ÿһ�����ӵ���
spawn_rate -- �û���ÿһ����ֹͣ/����
time_limit -- ʱ������
'''
setp_time = 600
setp_load = 20
spawn_rate = 20
time_limit = 60 * 60 * 3
def tick(self):
run_time = self.get_run_time()
if run_time > self.time_limit:
return None
current_step = math.floor(run_time / self.setp_time) + 1
return (current_step * self.setp_load, self.spawn_rate)
if __name__ == '__main__':
os.system("locust -f test4.py --headless -u 10 -r 10 --html report.html")
��߾���Ҫʹ�õ�LoadTestShape���������,�����ڿ��˸��߳�,ÿ�붼�����tick����,����һ��Ԫ��(��ǰ�û���,������)
��httpЭ��ѹ��
��Щ�����,����ѹ�Ⲣ���ǻ���httpЭ���,����websocketЭ��ѹ��,jceЭ���ѹ��,��ʱ�����Ҫ��дUser���client,�����Լ���ѹ��������������дclient��Ҫ����:
- self.client: locustЭ�����ʵ��,����ֻҪ��дһ��ʵ����client���ɡ�
- ���������¼�,�����ռ�������Ϣ,����д�ú�ִ����ᷢ���ռ�������������
events.request_failure.fire()
events.request_success.fire()
����10: �ҽӵ��˸�ѹ������,����websocketЭ��ӿڽ���ѹ�⡣
import os
import time
import websocket
from locust import task, events, User
class WebSocketClient(object):
def __init__(self, host):
self.host = host
self.ws = websocket.WebSocket()
def connect(self, burl):
start_time = time.time()
try:
self.conn = self.ws.connect(url=burl)
except websocket.WebSocketTimeoutException as e:
total_time = int((time.time() - start_time) * 1000)
events.request_failure.fire(request_type="websockt", name='urlweb', response_time=total_time, exception=e)
else:
total_time = int((time.time() - start_time) * 1000)
events.request_success.fire(request_type="websockt", name='urlweb', response_time=total_time,
response_length=0)
return self.conn
def recv(self):
return self.ws.recv()
def send(self, msg):
self.ws.send(msg)
class WebSocketUser(User):
"""
A minimal Locust user class that provides an XmlRpcClient to its subclasses
"""
abstract = True # dont instantiate this as an actual user when running Locust
def __init__(self, environment):
super().__init__(environment)
self.client = WebSocketClient(self.host)
class QuickstartUser(WebSocketUser):
url = 'ws://localhost:8000/v1/ws/marketpair'
def on_start(self):
self.client.connect(self.url)
@task
def hello_world(self):
self.client.send("ok")
if __name__ == '__main__':
os.system("locust -f locust_test.py --headless -u 10 -r 10 -t 10s --html report.html")
����Ҫ��events.request_failure.fire��events.request_success.fire�����������ռ���������,�����д�����ռ������������ݡ�
�ο�
- ��locust�ٷ��ĵ���http://docs.locust.io/en/stable/writing-a-locustfile.html
- ��locust-����python�����ܲ��Թ���(����ƪ)�� https://km.woa.com/group/571/articles/show/411249
- ��locustѹ��rpcЭ�顷https://www.cnblogs.com/yhleng/p/10031209.html