contents
selenium可以伪装成真实的浏览器,被封禁的概率更低,有动态JS加载,登录验证,表单提交,只是相比requests,性能比较差爬取的慢
安装
如: selenium库
如: ChromeDriver
如: chrome浏览器
step1:浏览器驱动安装要对应真实浏览器的版本,查看chrome浏览器版本
step2:找到对应或接近的版本,下载浏览器驱动ChromeDriver
https://www.selenium.dev/documentation/webdriver/getting_started/install_drivers/
将该chromedriver.exe所在目录放到环境路径下。
step3:pip install selenium
selenuim小实验
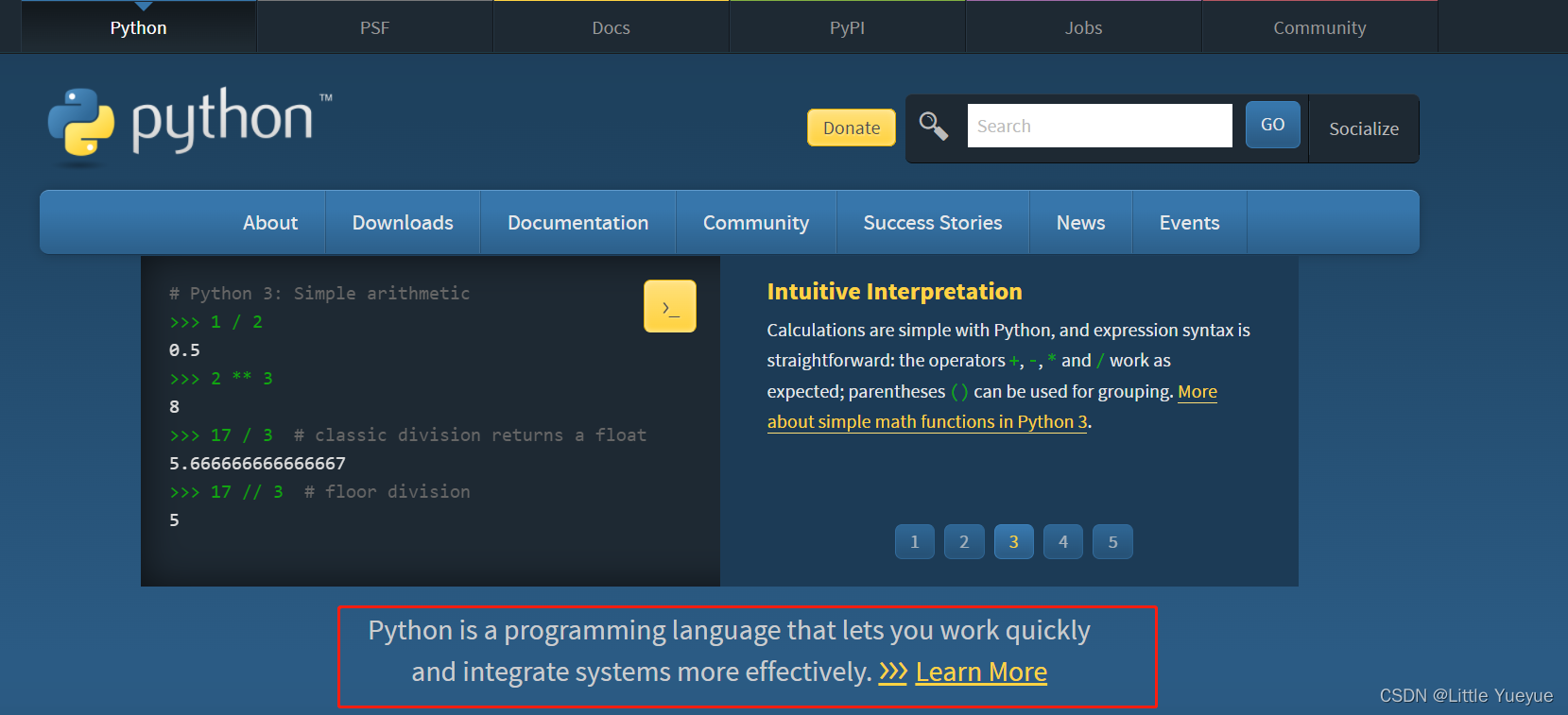
目标:爬取红框内的文字
from selenium.webdriver import Chrome #导入chrome的浏览器驱动chromedriver
from selenium.webdriver.support.ui import WebDriverWait #网页检测
# 创建 WebDriver 类型的对象,通过这个对象来操控浏览器,比如打开网址、选择界面元素等。
driver=Chrome(executable_path=r"C:\WebDriver\bin\chromedriver.exe")
#创建实例,executable_path参数若加入到了环境变量可不写
#这行代码启动浏览器驱动,可在任务管理器中看到
#使用WebDriver 的get 方法打开网址
driver.get("https://www.python.org/")
#Chome浏览器接收到该请求后,就会打开百度网址,通过浏览器驱动,告诉自动化程序打开成功。
#想关闭浏览器窗口可以调用WebDriver对象的 quit 方法,像这样 driver.quit()
#判断网页是否加载完毕
WebDriverWait(driver,10).until(lambda d: "python" in d.title) #等待10s 检测网页的title中是否已经显示python
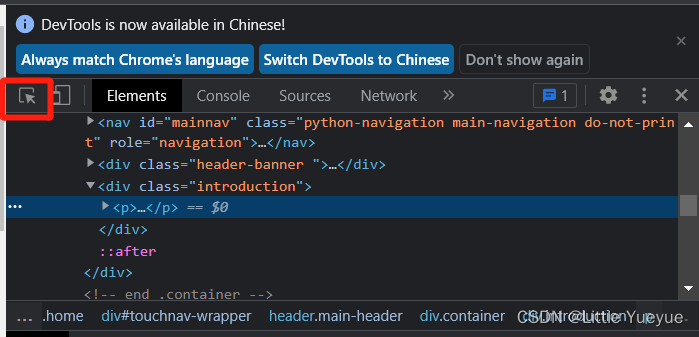
打开https://www.python.org/,在页面右键点击检查,点击红框中的符号,再找到要爬取的内容点击,下图中的元素(element)就会定位到文本中的地址,右键copy,选copy Xpath
from selenium.webdriver.common.by import By
#用XPATH爬取元素的内容
print(driver.find_element(By.XPATH,'//*[@id="touchnav-wrapper"]/header/div/div[3]/p').text) #打印爬取到的内容
关闭日志信息的打印
默认情况下 chromedriver被启动后,会在屏幕上输出不少日志信息,关闭方式如下
from selenium import webdriver
# 加上参数,禁止 chromedriver 日志写屏
options = webdriver.ChromeOptions()
options.add_experimental_option(
'excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(
options=options # 这里指定 options 参数
)
selenium常用语法
访问常用操作
首先
from selenium import webdriver
options = webdriver.ChromeOptions()# 加上参数,禁止 chromedriver 日志写屏
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver=webdriver.Chrome(options=options)
返回的是 WebDriver 类型的对象,一切都要通过这个对象来操控浏览器。
| 访问URL和导航 | code |
|---|---|
| 访问一个网页 | driver.get(“放一个网址”) |
| 获取当前URL | driver.current_url |
| 返回上一页 | driver.back() |
| 前往一页 | driver.forward() |
| 刷新页面 | driver.refresh() |
| 获取标题 | driver.title |
| 最大化窗口 | driver.maximize_window() |
| 全屏窗口 | driver.fullscreen_window() |
| 屏幕截图 | driver.save_sreenshot("./image.png") |
| 元素截图 | element.screenshot("./image.png") |
| 关闭driver | driver.close |
选择元素常用操作
web要操控元素,首先需要选择、 定位界面元素,即让浏览器先找到元素,然后,才能操作元素。
| 定位和查找页面元素 | code |
|---|---|
| 定位单个元素 | driver.find_element(By.NAME,“q”) |
| 定位多个元素 | driver.find_elements(By.TAG_NAME,“q”) |
| 获取元素的子元素 | search_form.find_element(By.TAG_NAME,“q”) |
| 获取元素的多个子元素 | search_form.find_elements(By.TAG_NAME,“p”) |
| 获取标签名 | driver.find_element(By.CSS_SELECTOR,“h1”).tag_name |
| 获取文本 | driver.find_element(By.CSS_SELECTOR,“h1”).text |
| 获取属性 | activate_element.get_attribute(“属性名”) |
元素的特征查看
方法一:
可以使用浏览器的开发者工具栏查看Elements标签,即可查看页面对应的HTML 元素。
点击小箭头,

挪动鼠标到网页界面元素,element下就会高亮显示对应的html元素。
方法二:
在界面元素上右击检查,就会出现开发者工具栏,和该界面元素对应的高亮html元素
通过元素特征定位
定位元素的常用方式:class,name, css selector, id, name, link text, partial link text, tag name, xpath
元素的id
查看输入框的hmtl,发现一个属性叫id,根据规范, 如果元素有id属性 ,这个id 必须是当前html中唯一的。

发起一个请求通过driver转发给浏览器,需要选择一个id为 keyword 的元素:
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'keyword')
浏览器找到该元素后,将结果通过driver返回给程序,即返回一个 WebElement 类型的对象。
用该WebElement 对象可对其对应的页面元素进行操控,如点击,输入字符等。
note:
不论哪种方式去选择元素,返回的都是该元素对应的WebElement对象。
元素的class属性、tag名
不是每个元素都有id,但大概率会有<标签名 属性名1=‘属性值1’ 属性名2=‘属性值2’>
- 如果我们要选择同一个标签TAG的所有元素, 就写:
elements = drivers.find_elements(By.TAG_NAME, 'div')
- 如果我们要选择同一个class属性的所有元素, 就写:
elements = driver.find_elements(By.CLASS_NAME, 'block-title')
note:
- 注意element后面多了个s,返回的是找到的符合条件的所有元素, 放在一个列表中返回。
- 若使用 driver.find_element () 方法, 就只会返回第一个元素。
- 若没有找到元素,driver.find_element () 方法会抛出异常,driver.find_elements () 方法会返回空列表
一个元素也可以有多个class类型 ,多个class类型的值之间用空格隔开,<span class="chinese student">张三</span>如用代码选择这个元素,这里标签为span的元素有两个class属性,分别是 chinese和student。指定任意一个class属性值,都可以选择到这个元素。
通过WebElement对象选择元素
#区别
element = driver.find_element(By.ID,'container')
spans = element.find_elements(By.TAG_NAME, 'span')
spans = driver.find_elements(By.TAG_NAME, 'span')
| 对象 | 元素选择范围 |
|---|---|
| WebDriver对象 | 整个 web页面 |
| WebElement对象 | 该元素的内部 |
操作元素的基本方法
element = driver.find_element(By.ID, 'animal')选择到元素之后,得到元素对应的 WebElement对象,就可以操控元素了。操控元素通常包括:
| 操作 | 常用代码 | 说明 |
|---|---|---|
| 点击元素 | element .click() | 浏览器接收到自动化命令,点击的是该元素的 中心点 位置 |
| 在元素中输入字符串,通常是对输入框这样的元素 | element .send_keys() | 把输入框中已经有的内容清除掉,可以使用WebElement对象的clear()方法 |
| 获取元素包含的信息,比如文本内容,元素的属性 | element.get_attribute(‘属性名’) | <标签名 属性名1=‘属性值1’ 属性名2=‘属性值2’> |
获取元素信息具体方法,首先获取界面元素的对应WebElement,element = driver.find_element(By.ID, 'animal')
| 获取 | code |
|---|---|
| 元素的文本内容(展示在界面上的文本内容) | element.text |
| 元素的文本内容没有展示在界面上,或者没有完全完全展示在界面上 | element.get_attribute(‘innerText’) ,或者 element.get_attribute(‘textContent’) |
| 整个元素对应的HTML | element.get_attribute(‘outerHTML’) |
| 元素内部的HTML文本内容 | element.get_attribute(‘innerHTML’) |
| 输入框里面的文字 | element.get_attribute(‘value’) |
示例1:元素对应的高亮html
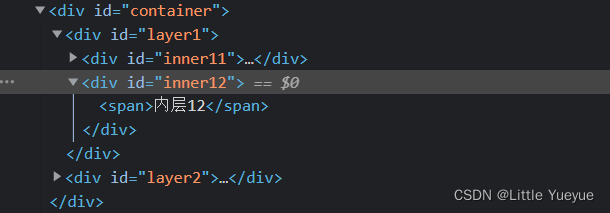
| 代码 | 结果 |
|---|---|
| element.get_attribute(‘outerHTML’) | <div id=“inner12”> ? ? ? ? ? ? ? <span>内层12</span> ? ? ? ? ? ? </div> |
| element.get_attribute(‘innerHTML’) | <span>内层12</span> |
示例2:先清理信息,输入内容
from selenium.webdriver.common.keys import Keys
SearchInput=driver.find_element(By.NAME,"q")
SearchInput.clear()
SearchInput.send_keys("selenium爬虫"+Keys.ENTER)
也可使用点击.click()
SearchInput=driver.find_element(By.XPATH,"q1")
SearchInput.clear()
SearchInput.send_keys("selenium爬虫")
driver.find_element(By.XPATH,"q2").click()
甚至可直接使用回车\n
SearchInput=driver.find_element(By.XPATH,"q1")
SearchInput.clear()
SearchInput.send_keys("selenium爬虫\n")
等待界面元素
等待页面加载完毕,元素加载完毕再取数据,否则会报错。
- 方式一:
用python的time模块,设定固定的等待时间
import time
time.sleep(3)
缺点:设置等待多长时间合适是个问题
- 方式二:
用Selenium.Webdriver里的implicitly_wait隐式等待方法,设置最长等待时间
from selenium import webdriver
wd.implicitly_wait(10) #写在所有要等待的操作前面
改进:当发现元素没有找到的时候, 不会立即返回找不到元素的错误。而是周期性(每隔半秒钟重新寻找该元素,直到该元素找到,或者超出指定最大等待时长,这时才停止寻找,抛出异常(如果是 find_elements 之类的方法, 则是返回空列表)。
缺点:虽然比sleep快一点,但隐式等待不针对某一个元素,是全局元素等待,即寻找每个元素的时候(find开题的),需要等待页面全部元素加载完成,才会执行下一个语句。如果超出了设置时间的则抛出异常。
- 方式三:
用WebDriverWait显式等WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
| 参数 | 说明 |
|---|---|
| driver | 浏览器驱动 |
| timeout | 最长超时时间,默认以秒为单位 |
| poll_frequency | 检测的间隔步长,默认为0.5s |
| ignored_exceptions | 超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常。 |
通常结合until()或until_not()方法+expected_conditions或者返回布尔值的lambda函数,在等待期间,每隔一定时间(默认0.5秒),调用until或until_not里的方法,直到它返回True或False。如果超过设置时间未发生,则抛出异常。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver,timeout=3).until(EC.条件) #等待10s 检测网页的title中是否已经显示python
| expected_conditions方法 | 含义 |
|---|---|
| title_is | 判断当前页面的 title 是否完全等于(==)预期字符串,返回布尔值 |
| title_contains | 判断当前页面的 title 是否包含预期字符串,返回布尔值 |
百度爬虫(翻页,爬取标题)
from selenium.webdriver import Chrome #导入chrome的浏览器驱动chromedriver
from selenium.webdriver.support.ui import WebDriverWait #网页是否加载完毕
from selenium.webdriver.support.expected_conditions import title_contains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
#驱动selenium打开网页
driver=Chrome() #创建实例,如果加入到了环境变量可不写
driver.get("https://www.baidu.com/")
searchinput=driver.find_element(By.XPATH,'//*[@id="kw"]')
searchinput.send_keys('Python'+Keys.ENTER)
#判断网页是否加载完毕
WebDriverWait(driver,10).until(title_contains("Python"))
#写文件
with open('baidu.txt','a') as f:
i=0
while i <3:
h3=driver.find_elements(By.CSS_SELECTOR,'h3.t')
for h in h3:
f.write(h.text+"\n")
#翻页
driver.find_element(By.XPATH,'//*[@id="page"]/div/a[last()]').click() #XPATH原本是//*[@id="page"]/div/a[10],但是他不一定是第十个位置,改成last()
i+=1
time.sleep(3)#给加载预留时间