目录
一、Selenium介绍与配置
1.Selenium简介
??Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具。Selenium测试直接运行在浏览器中,可以模拟真实用户的行为。支持的浏览器包括IE(7、8、9)、Mozilla Firefox、Mozilla Suite等。这个工具的主要功能包括:测试与浏览器的兼容性――测试你的应用程序看是否能够很好地工作在不同浏览器和操作系统之上。测试系统功能――创建回归测试检验软件功能和用户需求。
2. Selenium+Python环境配置
pip install selenium
二、网页自动化测试
1.启动浏览器并打开百度搜索
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
2.定位元素
- 在开发者工具中找到输入框
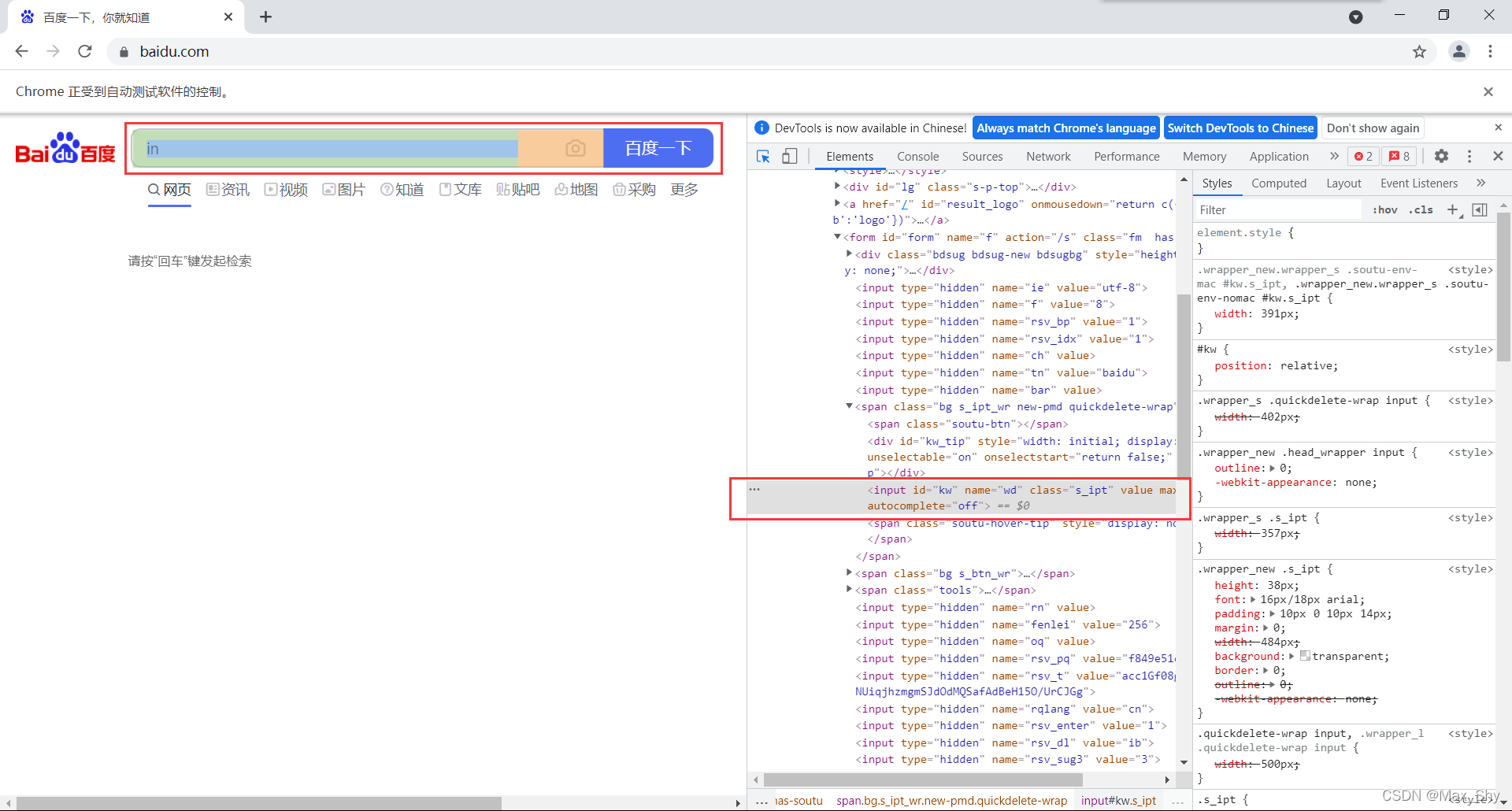
- 输入要查询的值并通过button点击事件实现
input_btn = web.find_element_by_id('kw')
input_btn.send_keys('原神', Keys.ENTER)
测试:
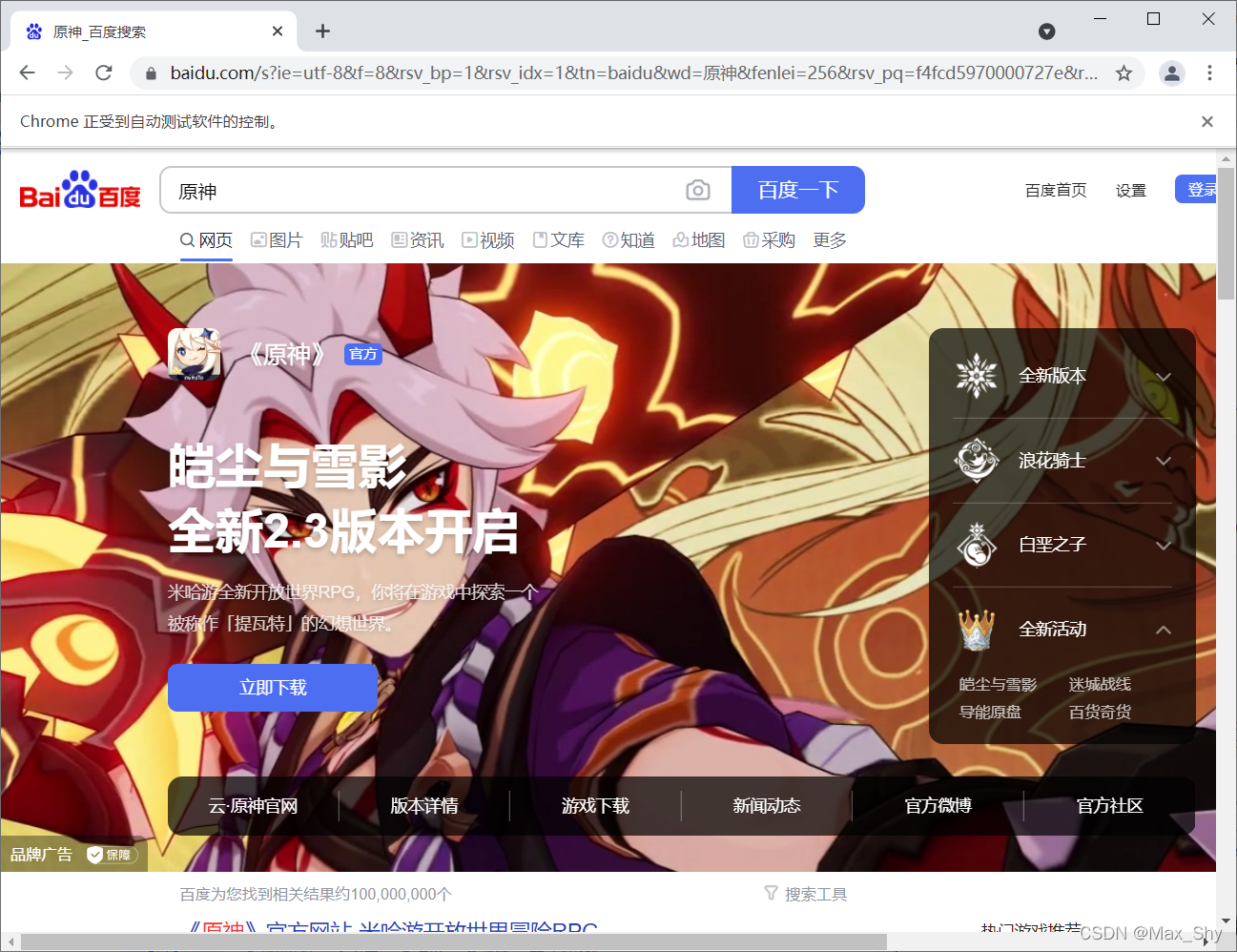
三、爬取动态网页的名人名言
1. 网页数据分析
在开发者工具中查看每一组名言(名言+名人)的位置:
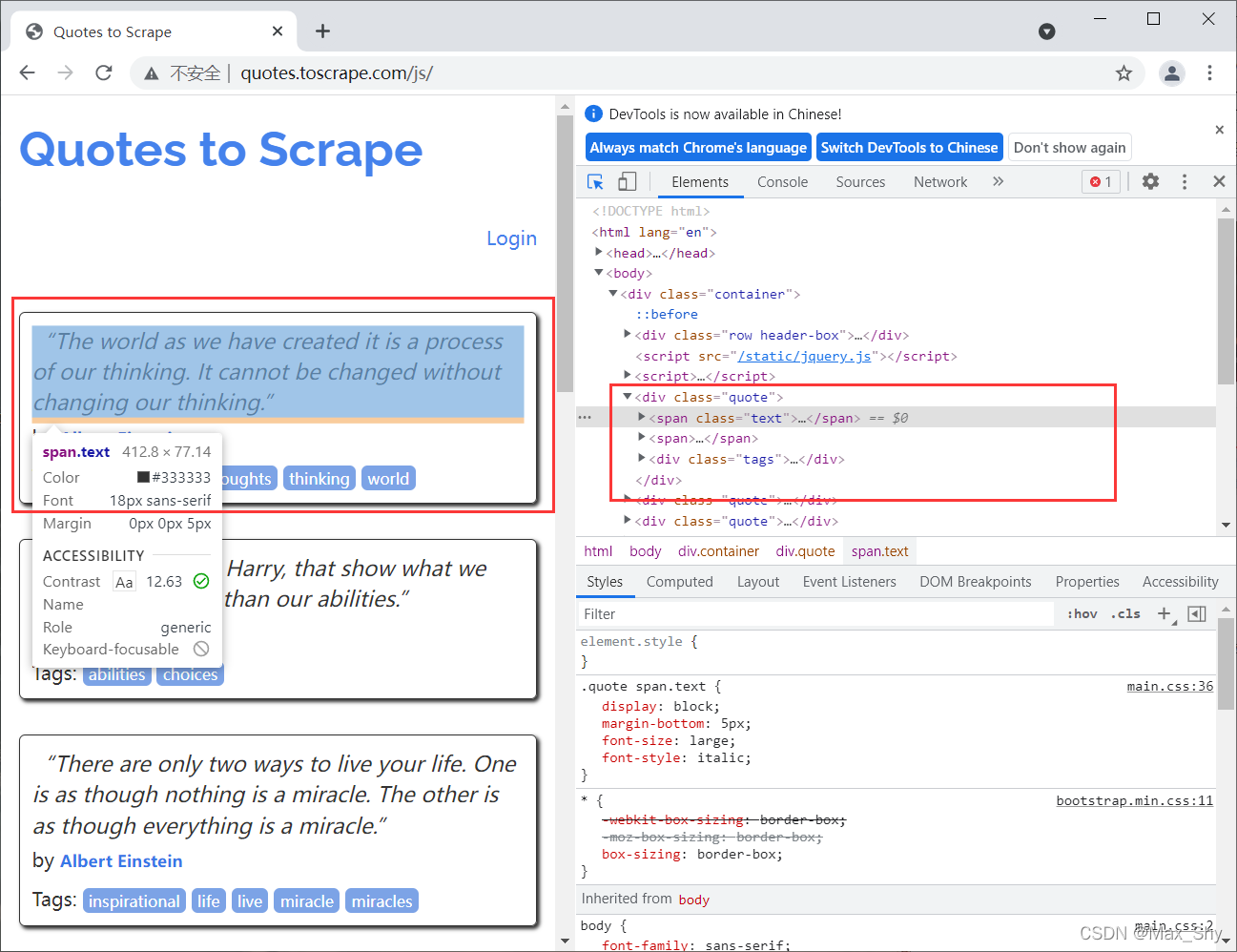
现每一组名言都是在class="quote"的div中,并且没有其他class="quote的标签。
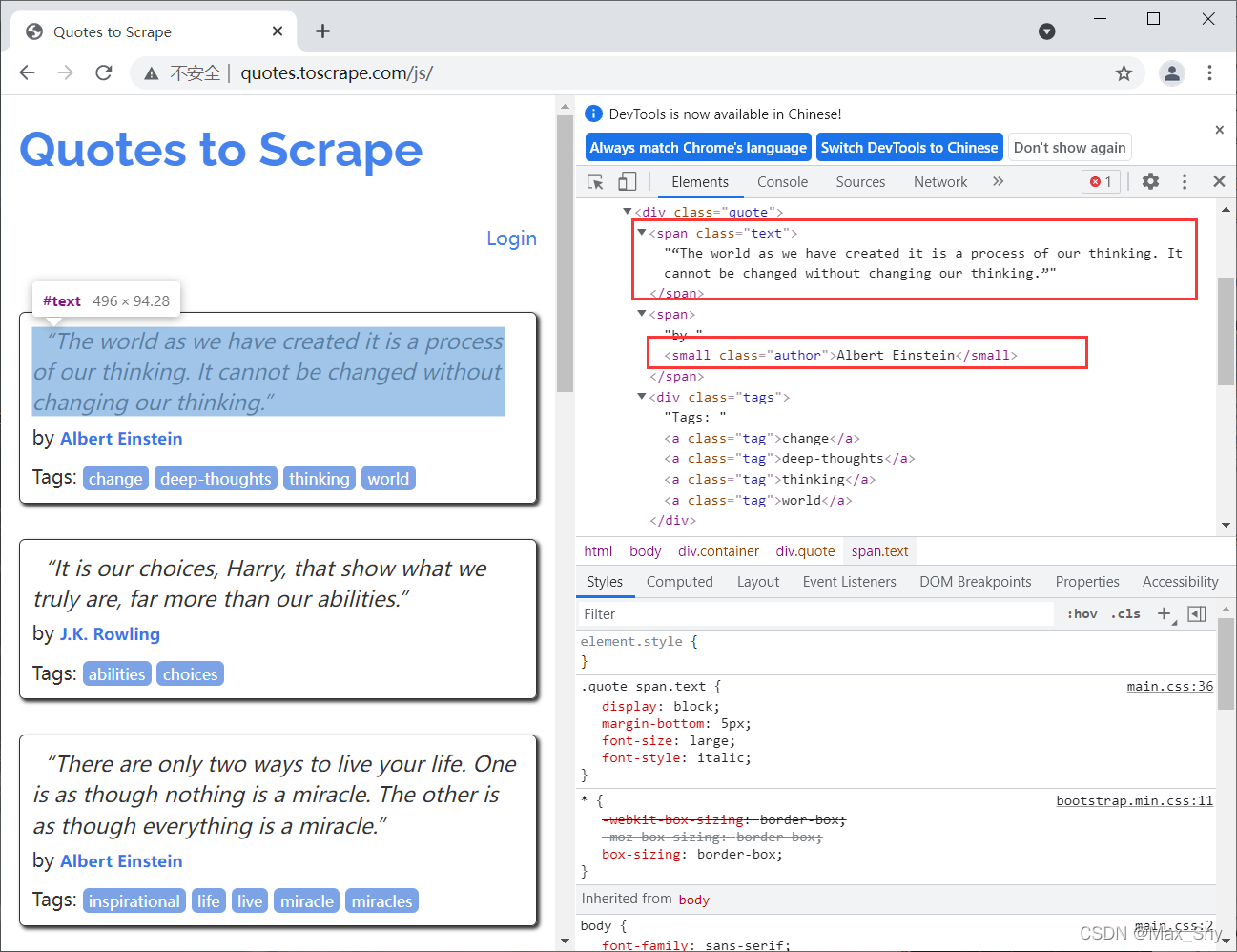
且名句在class="text"的<span>标签中,作者在class="author"的small标签中。
2. 翻页分析
在开发者工具中查看Next翻页按钮
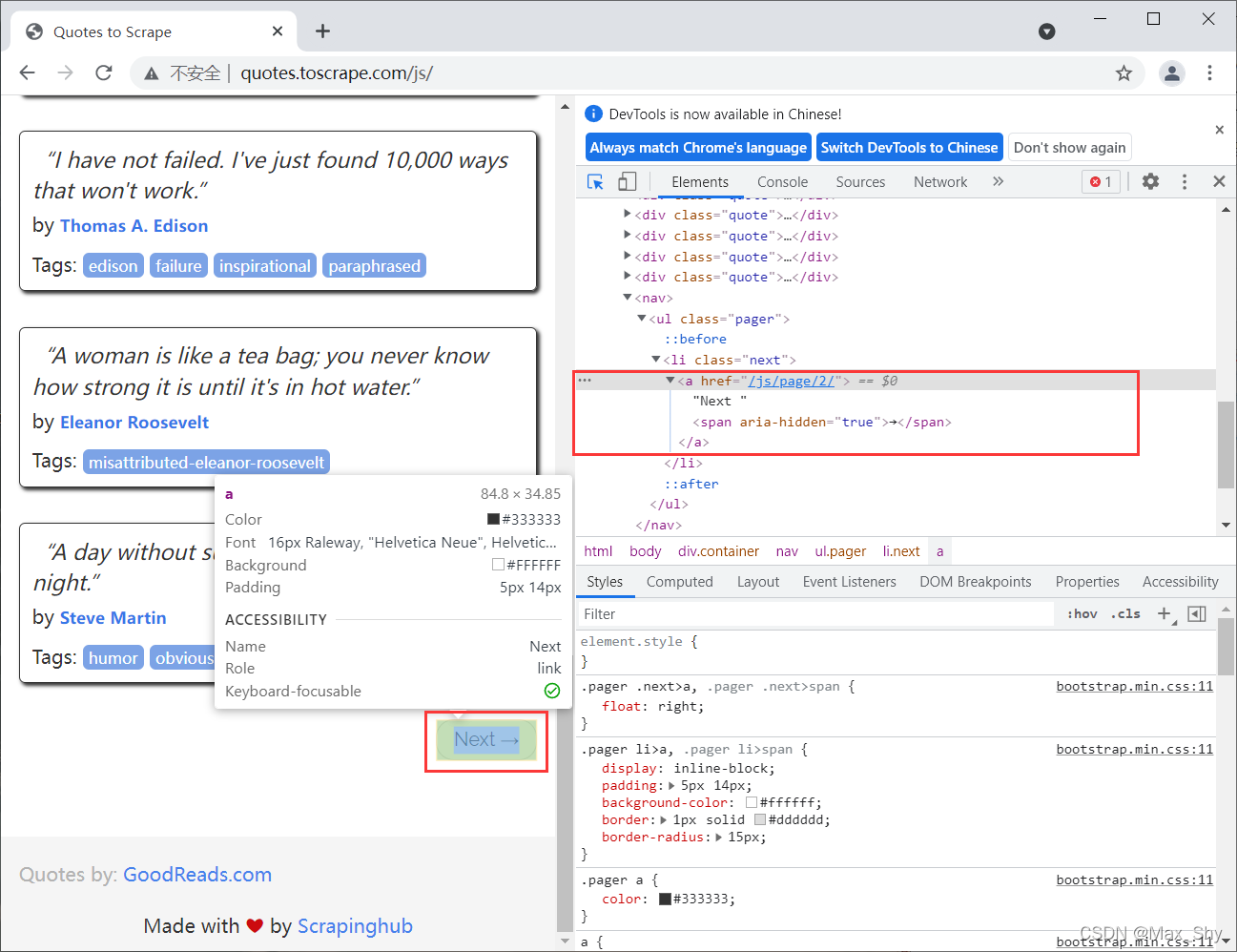
可发现Next按钮只有href属性,无法定位。但可以通过查找网页最后一个有aria-hidden属性的span标签,进行点击以跳转到下一页。
3.爬取数据的存储
爬取后的数据需要存储至csv文件中,编写代码如下:
with open('Saying.csv', 'w', encoding='utf-8')as fp:
fileWrite = csv.writer(fp)
fileWrite.writerow(['名言', '名人'])
fileWrite.writerows(sayingAndAuthor)
web.close()
4. 爬取数据
代码准备:
from selenium.webdriver import Chrome
import time
import csv
web = Chrome(r"D:\\DevTools\\Anaconda\\download\\Anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe")
web.get('http://quotes.toscrape.com/js/')
sayingAndAuthor = []
n = 5
for i in range(0, n):
div_list = web.find_elements_by_class_name('quote')
for div in div_list:
saying = div.find_element_by_class_name('text').text
author = div.find_element_by_class_name('author').text
info = [saying, author]
sayingAndAuthor.append(info)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
web.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
with open('Saying.csv', 'w', encoding='utf-8')as fp:
fileWrite = csv.writer(fp)
fileWrite.writerow(['名言', '名人']) # 写入表头
fileWrite.writerows(sayingAndAuthor)
web.close()
爬取结果:

四、爬取京东网站书籍信息
爬取某个关键字书籍的前三页书籍信息,本文以计算机图形学为例
- 进入网页并搜索
计算机图形学
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
web = Chrome(r"D:\\DevTools\\Anaconda\\download\\Anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe")
web.get('https://www.jd.com/')
web.maximize_window()
web.find_element_by_id('key').send_keys('计算机图形学', Keys.ENTER) # 找到输入框输入,回车
成功。
-
网页分析
使用开发者工具可查看每一个商品信息的位置
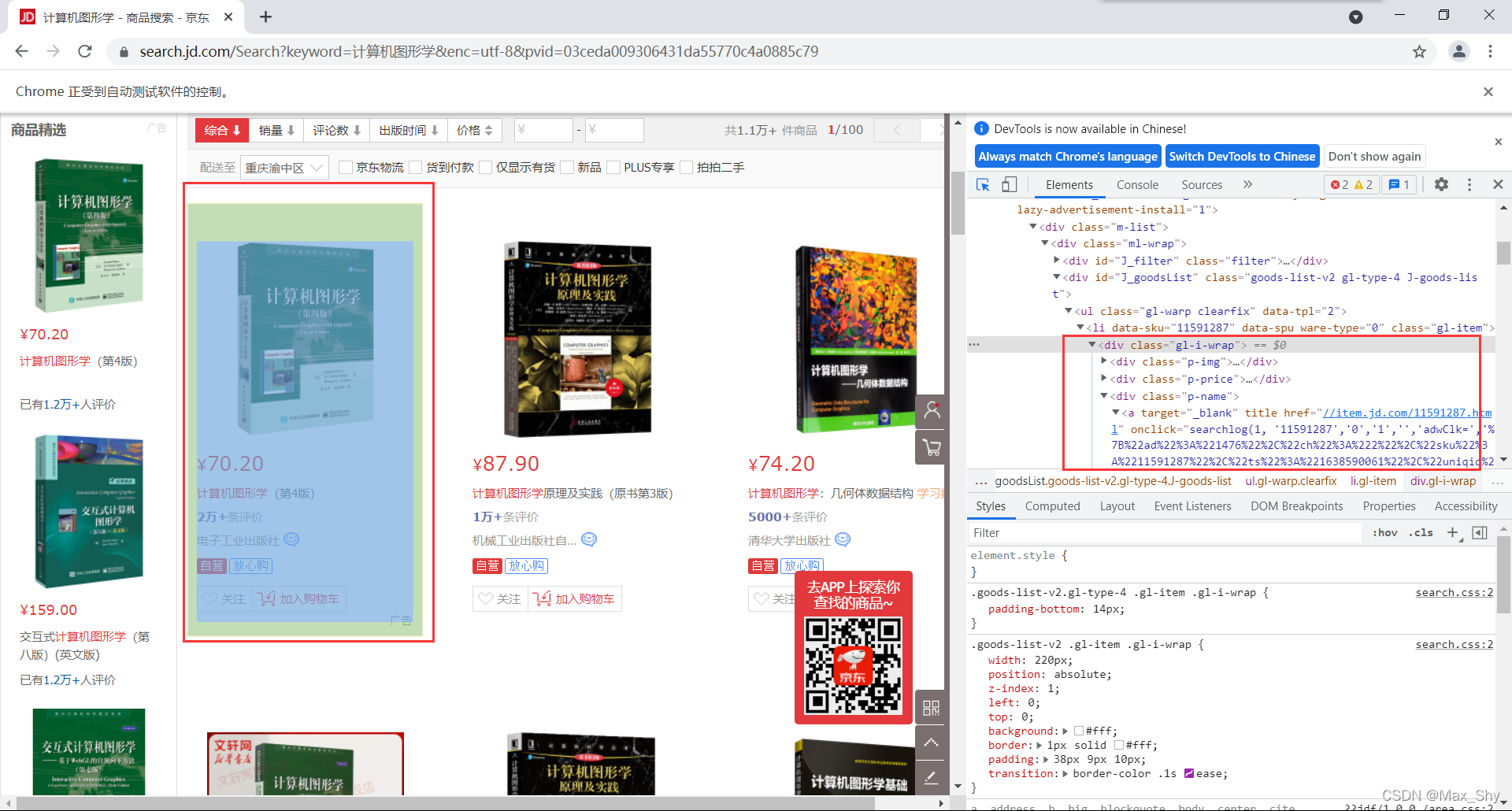
发现每一个商品信息都存在于class包含gl-item的li中。因此获取该页面下所有li,由此爬取书籍信息(包括书名和价格)。 -
翻页
web.find_element_by_class_name('pn-next').click() # 点击下一页
- 数据保存
with open('计算机图形学.csv', 'w', encoding='utf-8')as fp:
writer = csv.writer(fp)
writer.writerow(['书名', '价格', '作者', '出版社', '预览图片地址'])
writer.writerows(all_book_info)
- 代码准备
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
import csv
web = Chrome(r"D:\\DevTools\\Anaconda\\download\\Anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe")
web.get('https://www.jd.com/')
web.maximize_window()
web.find_element_by_id('key').send_keys('计算机图形学', Keys.ENTER)
def get_onePage_info(web):
web.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text = web.page_source
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
book_infos = []
for li in li_list:
book_name = ''.join(
li.xpath('.//div[@class="p-name"]/a/em/text()')) # 书名
price = '¥' + \
li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
author_span = li.xpath('.//span[@class="p-bi-name"]/a/text()')
if len(author_span) > 0: # 作者
author = author_span[0]
else:
author = '无'
store_span = li.xpath(
'.//span[@class="p-bi-store"]/a[1]/text()') # 出版社
if len(store_span) > 0:
store = store_span[0]
else:
store = '无'
img_url_a = li.xpath('.//div[@class="p-img"]/a/img')[0]
if len(img_url_a.xpath('./@src')) > 0:
img_url = 'https' + img_url_a.xpath('./@src')[0] # 书本图片地址
else:
img_url = 'https' + img_url_a.xpath('./@data-lazy-img')[0]
one_book_info = [book_name, price, author, store, img_url]
book_infos.append(one_book_info)
return book_infos
def main():
web = Chrome(
r"D:\\DevTools\\Anaconda\\download\\Anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe")
web.get('https://www.jd.com/')
web.maximize_window()
web.find_element_by_id('key').send_keys('计算机图形学', Keys.ENTER) # 找到输入框输入,回车
time.sleep(2)
all_book_info = []
for i in range(0, 3):
all_book_info += get_onePage_info(web)
print('爬取第' + str(i+1) + '页成功')
web.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
with open('计算机图形学.csv', 'w', encoding='utf-8')as fp:
writer = csv.writer(fp)
writer.writerow(['书名', '价格', '作者', '出版社', '预览图片地址'])
writer.writerows(all_book_info)
if __name__ == '__main__':
main()
- 爬取结果
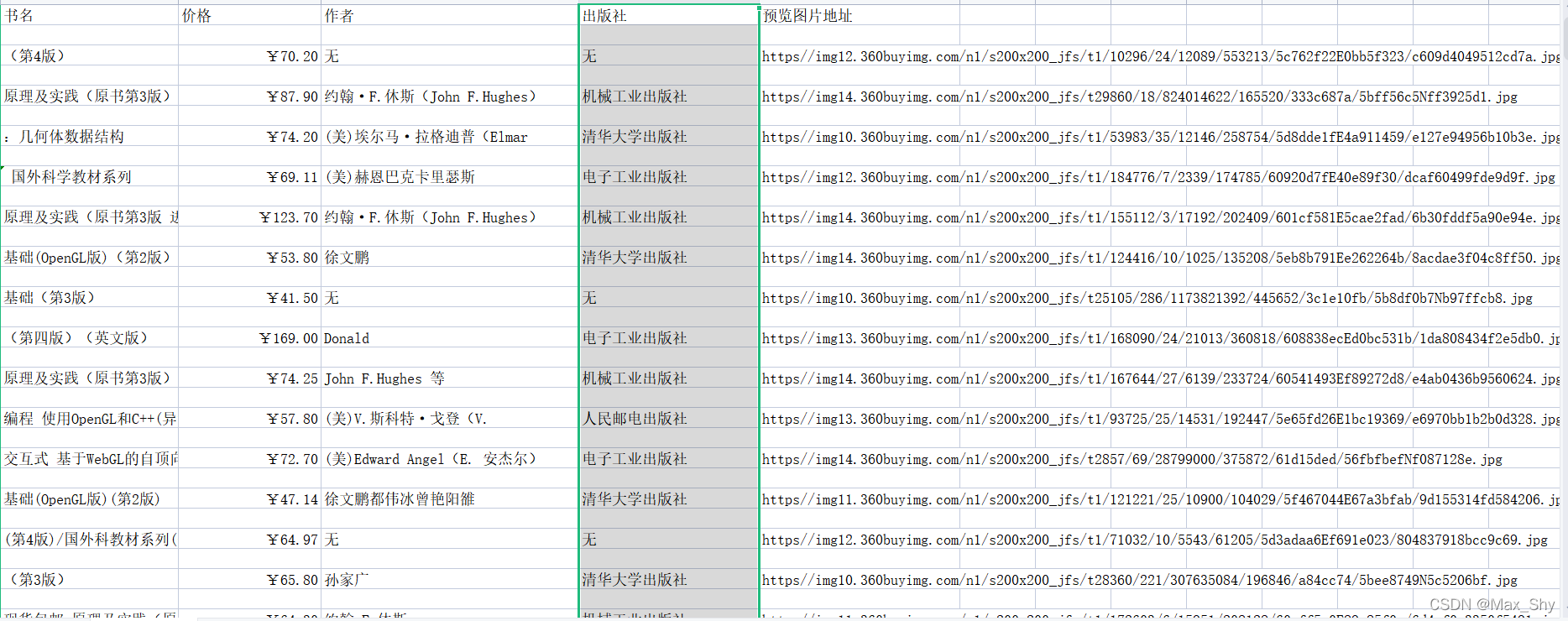
成功
五、总结
??本文通过Selenium和webdrive等库,对动态网页的信息进行爬取。