一篇学会爬取打卡记录,就不用一一就复制粘贴了
背景:老师要求要记录每天的打卡情况,然而人数有点多,不想一一点开记录.那怎么办呢,诶我们可以利用爬虫Selenium来爬取数据
一般是用request来爬取,但是这里利用cookie信息登入的时候有些问题,所以就利用Selenium了,这里就可以避免一些问题
这里以CTFd平台为例子一、必备工具
首先下载 chromedriver,注意要和自己的谷歌浏览器版本要对应,谷歌什么版本,你就下载什么版本就可
工具地址
然后就安装selenium库
pip install selenium
直接安装即可
安装完必备工具后,就可以使用了
然后在python环境中导入即可
from selenium import webdriver
diver=webdriver.Chrome(executable_path="D:\Chromdriver\chromedriver_win32\chromedriver3.exe")
二、获取cookie信息
要想实现直接登入,那末cookie信息事必不能少的.
我们先模拟登入F12 查看网页代码
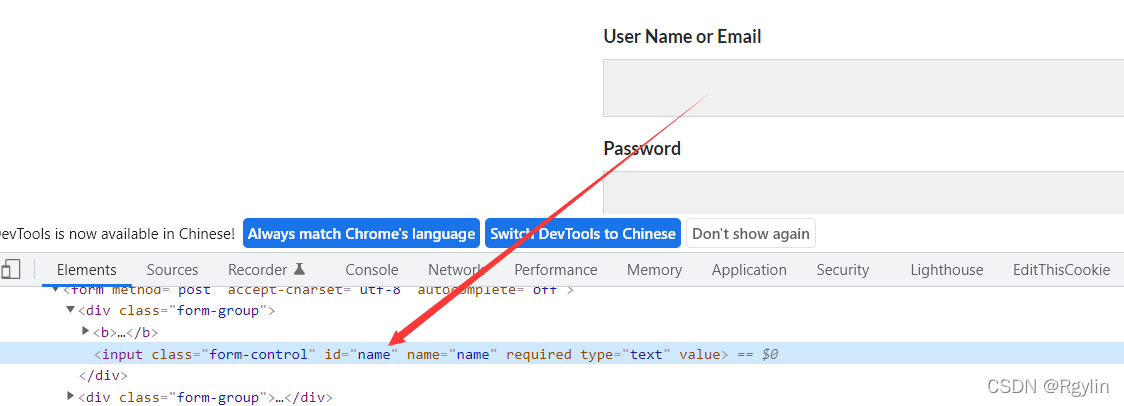
定位到用户名密码,然后实现自动登入,send_keys()实现填入用户名密码
diver.find_element_by_id('name').send_keys('haisen')
diver.find_element_by_id('password').send_keys('12345678')
定位到提交按钮实现自动提交,用click()模拟点击
diver.find_element_by_id('_submit').click()
然后打印cookie就行啦,总的代码如下
diver=webdriver.Chrome(executable_path="D:\Chromdriver\chromedriver_win32\chromedriver3.exe")
diver.get('http://URL:8000/login?next=%2Fchallenges%3F')
time.sleep(2)
diver.find_element_by_id('name').send_keys('haisen')
diver.find_element_by_id('password').send_keys('12345678')
time.sleep(2)
diver.find_element_by_id('_submit').click()
time.sleep(2)
print(diver.get_cookies())
我们可以看到cookie信息已经打印出来
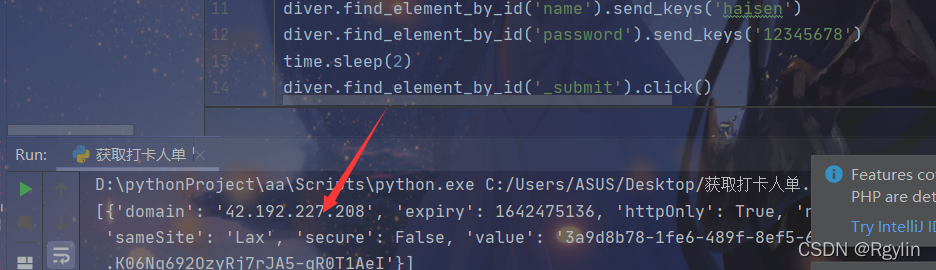
然后我们在添加cookie进去,就是先自动登入了
for item in cookie:
diver.add_cookie(item)
三、获取要找的信息
实现登入以后,然后我们就找需要记录的信息了,这里我以名字为例
找到某个
题目后点开,点开Sloves 就能发现要找的name了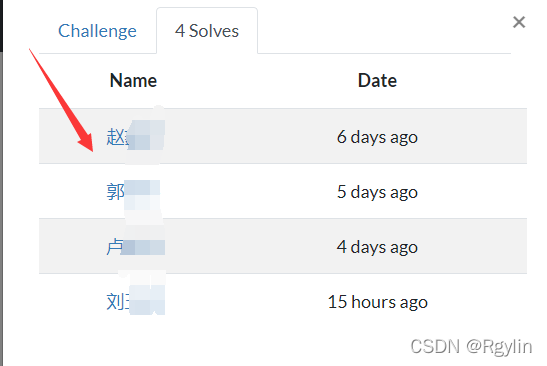
点开后url为
http://42.URL:8000/challenges#福尔摩斯-3
然后我们再点开Solves 就能看见name名
f12后找到sloves对应的类名
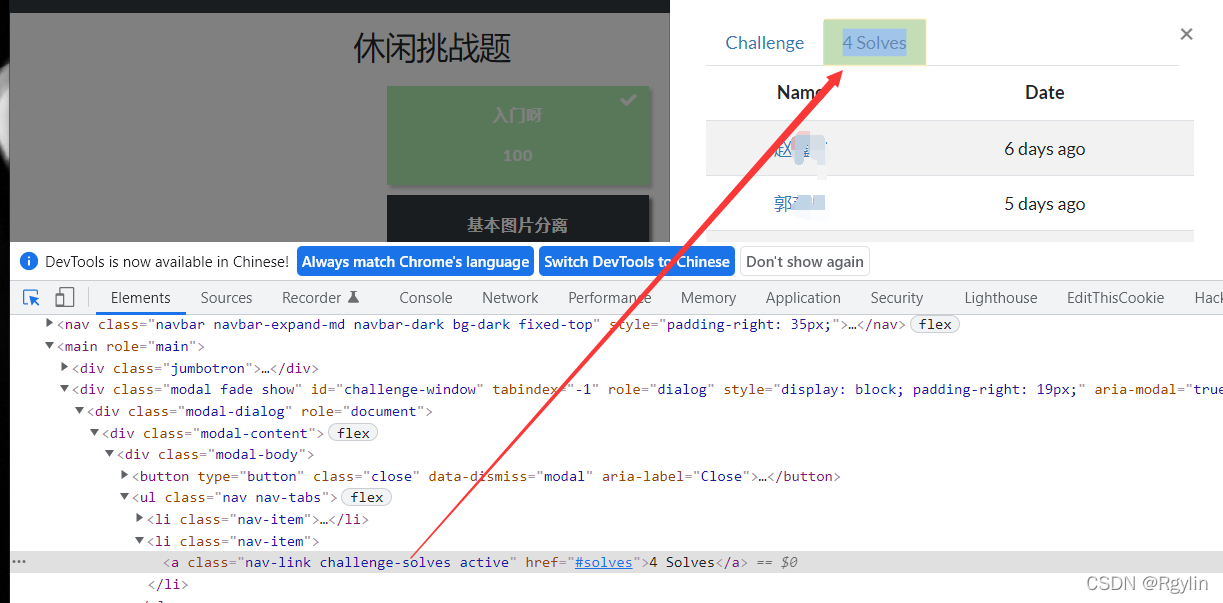
我们可以用diver.find_element_by_class_name(’’)来找到对应的元素,并实现点击
diver.find_element_by_class_name('challenge-solves').click()
点开后我们就可以用xpath语法来将name 获取
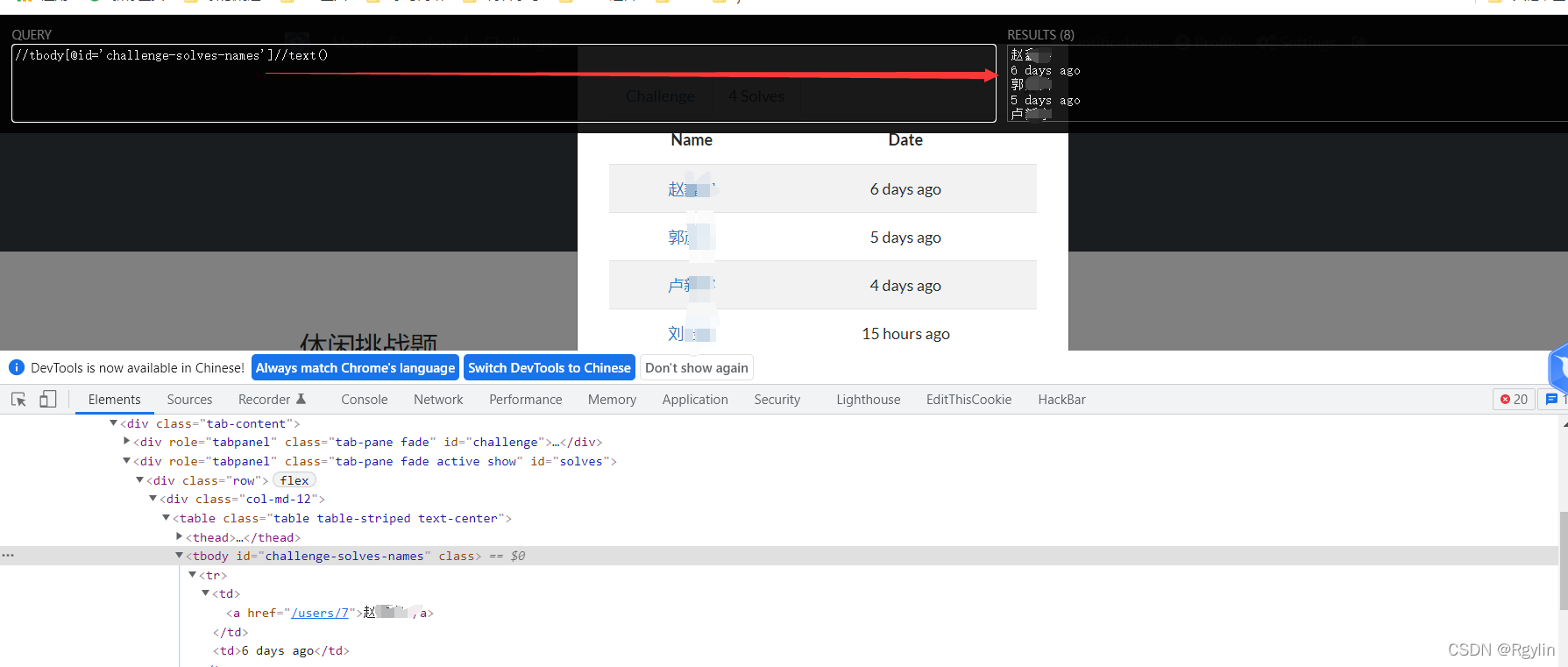
这样就可以获取了
然后用diver打印出来即可
总的代码为
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import re
import time
diver=webdriver.Chrome(executable_path="D:\Chromdriver\chromedriver_win32\chromedriver3.exe")
diver.get('http://URL:8000/login?next=%2Fchallenges%3F')
time.sleep(2)
cookie=[{'domain': 'URL', 'expiry': 1642423459, 'httpOnly': True, 'name': 'session', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '7af6d510-a94e-4dbb-b7b2-50dee11811a6._CJfH_7ffk6NIa_aCXJmN63ZS-E'}]
for item in cookie:
diver.add_cookie(item)
url='http://URL:8000/challenges#Base家族-19'
diver.get(url)
time.sleep(3)
diver.find_element_by_class_name('challenge-solves').click()
time.sleep(2)
daka_name=diver.find_element_by_xpath("//tbody[@id='challenge-solves-names']").text
print(daka_name)
简单的几行代码就可以实现捕获信息了.结果如图
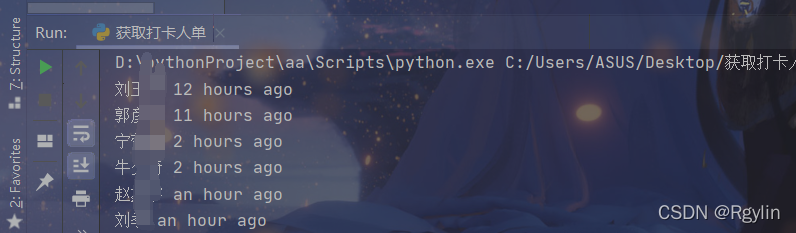
然后利用正则提取汉字
hanzi= re.compile(r'[\u4E00-\u9FA5]+')
mingdan=re.findall(hanzi,daka_name)
count=0
for i in mingdan:
print('第{0}名 {1} 打卡次数{2}'.format(str(count),i,1))
count+=1
这里只是以一个challenge来说,我们可以利用列表来存取所有challenge然后for循环就实现了所有挑战的打卡信息,这里就不写了,感兴趣的可以自己实现一下
四、存储所读取的数据
import xlwt
book = xlwt.Workbook()
sheet = book.add_sheet('打卡')
for i in range(len(mingdan)):
sheet.write(i,1,mingdan[i])
sheet.write(i,2,'你统计的次数')
book.save('task.xls')
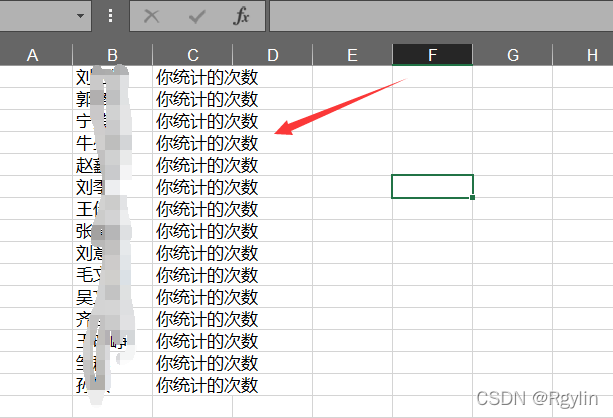
总的代码如下
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import re
import time
diver=webdriver.Chrome(executable_path="D:\Chromdriver\chromedriver_win32\chromedriver3.exe")
diver.get('http://url:8000/login?next=%2Fchallenges%3F')
time.sleep(2)
# diver.find_element_by_id('name').send_keys('haisen')
# diver.find_element_by_id('password').send_keys('12345678')
# time.sleep(2)
# diver.find_element_by_id('_submit').click()
# time.sleep(2)
# print(diver.get_cookies())
cookie=[{'domain': 'url', 'expiry': 1642423459, 'httpOnly': True, 'name': 'session', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '7af6d510-a94e-4dbb-b7b2-50dee11811a6._CJfH_7ffk6NIa_aCXJmN63ZS-E'}]
for item in cookie:
diver.add_cookie(item)
url='http://url:8000/challenges#Base家族-19'
diver.get(url)
time.sleep(3)
diver.find_element_by_class_name('challenge-solves').click()
time.sleep(2)
daka_name=diver.find_element_by_xpath("//tbody[@id='challenge-solves-names']").text
print(daka_name)
hanzi= re.compile(r'[\u4E00-\u9FA5]+')
mingdan=re.findall(hanzi,daka_name)
count=0
for i in mingdan:
print('第{0}名 {1} 打卡次数{2}'.format(str(count),i,1))
count+=1
print(mingdan)
import xlwt
book = xlwt.Workbook()
sheet = book.add_sheet('打卡')
for i in range(len(mingdan)):
sheet.write(i,1,mingdan[i])
sheet.write(i,2,'你统计的次数')
book.save('task.xls')
总结
可以使用Selenium,xlwt等模块将打卡name 进行表格统计.
后续还会更新更好的数据爬取.求个关注鸭