一、引言
作为一名测试点工,我们是需要经常写测试用例的,一般我们都会使用xmind或者freemain先写出导图,然后根据导图再编写我们的测试用例。那我们能不能直接把导图中的内容直接转成Excel测试用例呢,…有了想法,开始行动起来,测试人不要怂,开始干。
二、环境准备
点工一般都使用python居多,本次我们也是用python来写脚本实现本次需求,从网上了解到xmindparser库可以解析xmind文件数据,支持将xmind文件解析为dict、json、xml数据类型。数据解析完成后,还需要把解析的数据存在Excel中,python处理Excel库很多,在这边我使用的是openpyxl库。
python 3.7.1
xmindparser 1.0.9
openpyxl 3.0.9
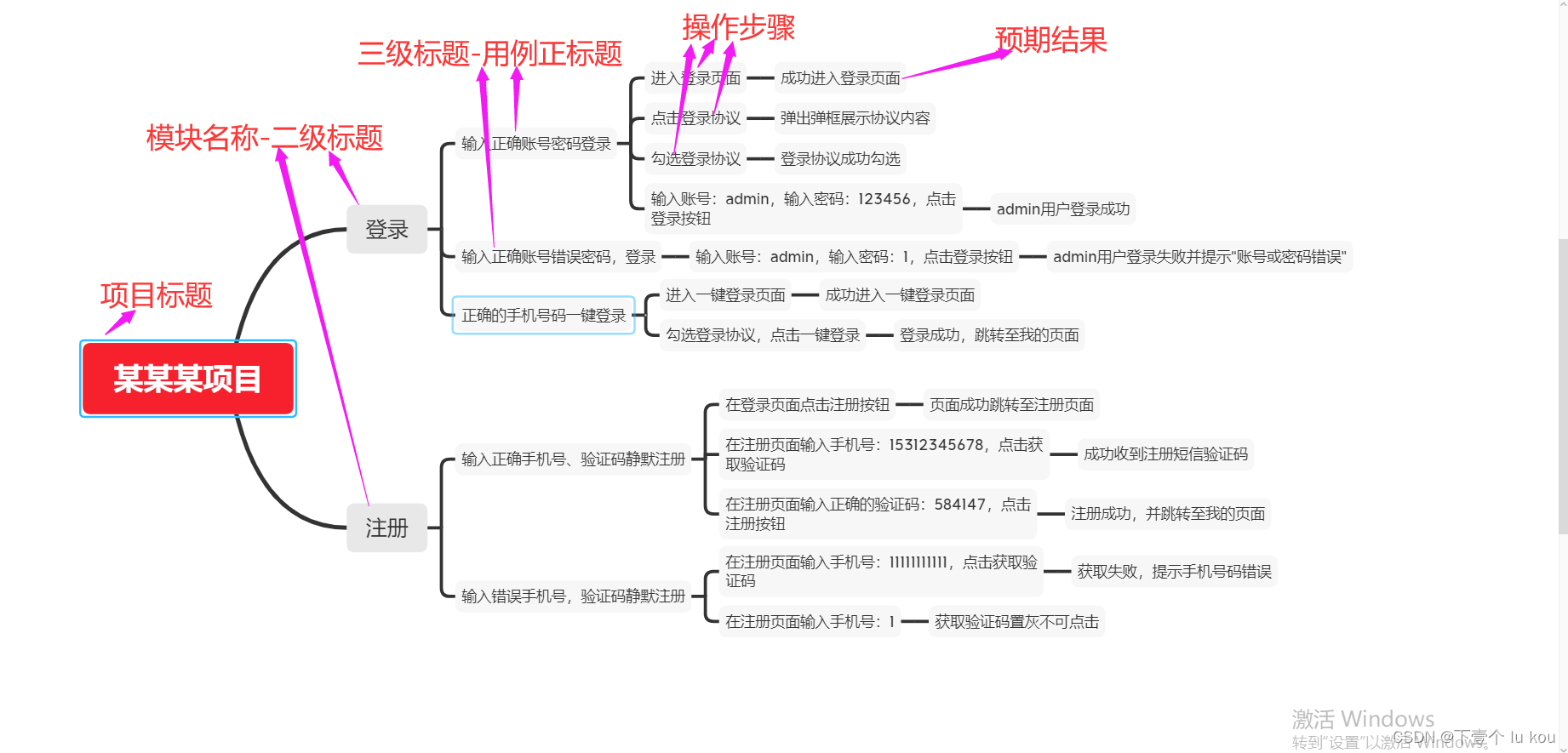
上面介绍完本次使用的库,还有一个重点就是,xmind的导图如何每个人写法都不一样,我们该如何解析形成统一标准呢,所以我们应该制定一个写导图的规则,下方是我制定的一个规则,后面都以此规则讲解。规则不是唯一,可根据实际情况自行制定。
中心主题:项目标题
二级标题:模块标题
三级标题:用例正标题
四级标题:操作步骤
五级标题:预期结果
三、脚本编写
1、读取xmind文件
读取xmind文件数据,xmind_to_dict(xmind_file_path)[0][“topic”] 返回数据如图所示,我们读取文件时把中心主题和二级目录下分支数据取出,用于后续处理。
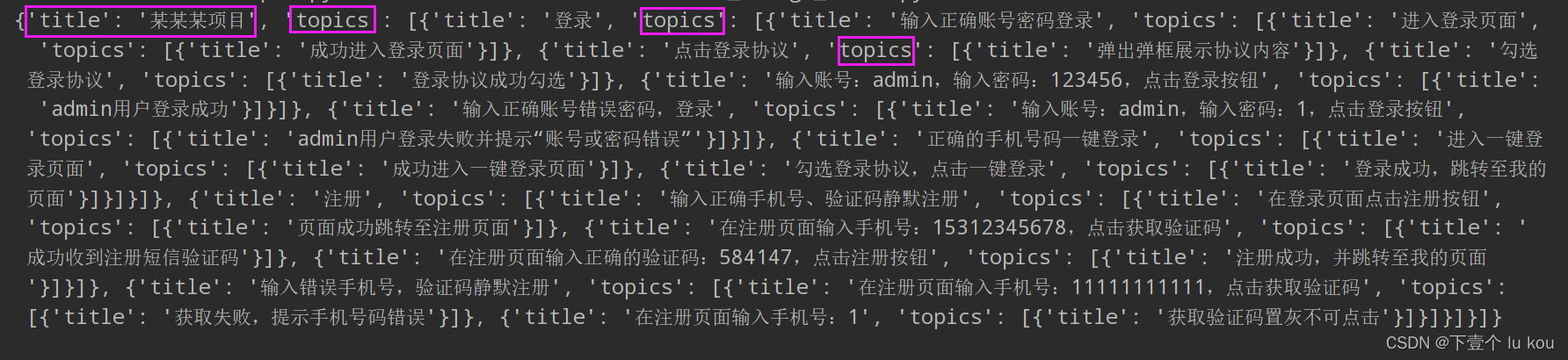
代码如下:
from xmindparser import xmind_to_dict
def read_xmind_data(xmind_file_path):
"""
读取xmind文件,返回中心主题标题和其他分支list数据
:param xmind_file: xmind文件路径
:return:
"""
case_data_dict=xmind_to_dict(xmind_file_path)[0]["topic"]
title = case_data_dict["title"]
data_list=case_data_dict["topics"]
return title,data_list
2、根据读取数据,解析数据
上面我们已经读取出数据,先分析下数据构成,我们发现每一个topics下面都有下一级的list,我们可以使用循环或者递归来提取出数据,并形成类似:登录-输入正确账号密码登录-进入登录页面-成功进入登录页面 这种结构的数据。
返回数据如下:

代码如下:
def xmind_to_caselist(data_list,title,listcase,strcase=''):
"""
根据传入的list数据,递归解析出数据,形成以:
登录-输入正确账号密码登录-进入登录页面-成功进入登录页面 的数据
:param data_list: 传入解析后list
:param strcase: 初始字符串,默认为空
:param listcase: 存用例数据的list
:return: 返回以每条用例数据的list
"""
for branch_one in data_list:
strcase_one = strcase + branch_one['title'] + '_'
if 'topics' not in branch_one:
# 分支中不存在topics时,把数据添加到listcase中
strcase_one=title+'_'+ strcase_one
listcase.append(strcase_one)
continue
branch = branch_one['topics']
# 递归,遍历所有分支
xmind_to_caselist(branch,title,listcase,strcase=strcase_one)
return listcase
3、定义测试用例标题
目前我所在的公司使用tapd,tapd中所用的测试用例模板标标题为:ID 用例目录 用例名称 前置条件 用例步骤 预期结果 用例类型 用例状态 用例等级。其中一些标题一般都没什么变化,我这边使用默认值。由上面返回的listcase数据,把数据拆分后重新组成一条用例,一条用例为一个list,方便后续写入Excel中。
返回数据如下:

代码如下:
def change_case(listcase,top_term='',case_type='功能测试',case_state='待更新',case_grade='中'):
"""
Excel中用例标题分为如下9个(tapd上的上传标准):
ID 用例目录 用例名称 前置条件 用例步骤 预期结果 用例类型 用例状态 用例等级
ID:自增
用例目录:项目名称-模块名称 例如:某某某项目-登录模块
用例名称:提取传入数据的三级标题+四级标题+五级标题
前置条件:默认为空,可自己填写通用数据
用例步骤:提取数据的四级标题
预期结果:提取数据的五级标题
用例类型:默认值为功能测试,可填其他值为:性能测试,安全性测试
用例状态:默认值为待更新,可填其他值为:正常,已废弃
用例登记:默认值为中,可填其他值为:高,低
:param data_list: 传入已从xmind分解成的list数据
:param top_term: 前置条件
:param case_type: 用例类型
:param case_state: 用例状态
:param case_grade: 用例等级
:return: 返回以一条用例为一个list的数据,例如[[用例1],[用例2],[用例3]]
"""
total_case=[]#总的用例格式的list
case_id=1
for data in listcase:
case_list=[]#每一条用例的list
data_sp=data.split('_')
case_list.append(case_id)
case_list.append(data_sp[0]+"-"+data_sp[1])
case_list.append(data_sp[2]+','+data_sp[3]+','+data_sp[4])
case_list.append(top_term)
case_list.append(data_sp[3])
case_list.append(data_sp[4])
case_list.append(case_type)
case_list.append(case_state)
case_list.append(case_grade)
total_case.append(case_list)
case_id+=1
return total_case
4、数据写入Excel中
在上面步骤中,已经完成对数据的梳理,下面使用openpyxl库完成对数据的写入并相应的调整样式。
代码如下:
def write_excel_case(total_case,save_path):
"""
把解析的数据写入Excel中
:param total_case: 解析完成的数据
:param save_path: 文件保存路径
:return:
"""
wb=Workbook()
ws=wb.active
ws['A1']='ID'
ws['B1']='用例目录'
ws['C1']='用例名称'
ws['D1']='前置条件'
ws['E1']='用例步骤'
ws['F1']='预期结果'
ws['G1']='用例类型'
ws['H1']='用例状态'
ws['I1']='用例等级'
i=1
for case in total_case:
ws['A{}'.format(i + 1)] = case[0]
ws['B{}'.format(i + 1)] = case[1]
ws['C{}'.format(i + 1)] = case[2]
ws['D{}'.format(i + 1)] = case[3]
ws['E{}'.format(i + 1)] = case[4]
ws['F{}'.format(i + 1)] = case[5]
ws['G{}'.format(i + 1)] = case[6]
ws['H{}'.format(i + 1)] = case[7]
ws['I{}'.format(i + 1)] = case[8]
i+=1
column_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
cell_list = ['A1', 'B1', 'C1', 'D1', 'E1', 'F1', 'G1', 'H1', 'I1']
#设置表头字体
font=Font(name='宋体',bold=True)
for cel in cell_list:
cell=ws[cel]
cell.font=font
# 设置列的表格居中
alignment = Alignment(horizontal='center',wrapText=True)
for col_name in column_list:
col_list = ws[col_name]
for col in col_list:
col.alignment = alignment
#设置列的宽度
ws.column_dimensions['B'].width = 20
ws.column_dimensions['C'].width = 60
ws.column_dimensions['D'].width = 30
ws.column_dimensions['E'].width = 30
ws.column_dimensions['F'].width = 30
ws.column_dimensions['G'].width = 15
ws.column_dimensions['H'].width = 15
ws.column_dimensions['I'].width = 15
#设置行的高度
for x in range(2,ws.max_row+1):
ws.row_dimensions[x].height = 40
wb.save(save_path)
5、运行入口
上述步骤中已经把脚本所需函数完成,下面写下运行脚本函数:
代码如下:
def run_main(xmind_file_path,save_path,top_term='',case_type='功能测试',case_state='待更新',case_grade='中'):
"""
:param xmind_file_path: xmind文件路径
:param save_path: 文件保存路径
:param top_term: 前置条件
:param case_type: 用例类型
:param case_state: 用例状态
:param case_grade: 用例等级
:return:
"""
title,data_list=read_xmind_data(xmind_file_path)
listcase=xmind_to_caselist(data_list,title,[])
total_case = change_case(listcase, top_term=top_term,case_type=case_type,case_state=case_state,case_grade=case_grade)
write_excel_case(total_case,save_path)
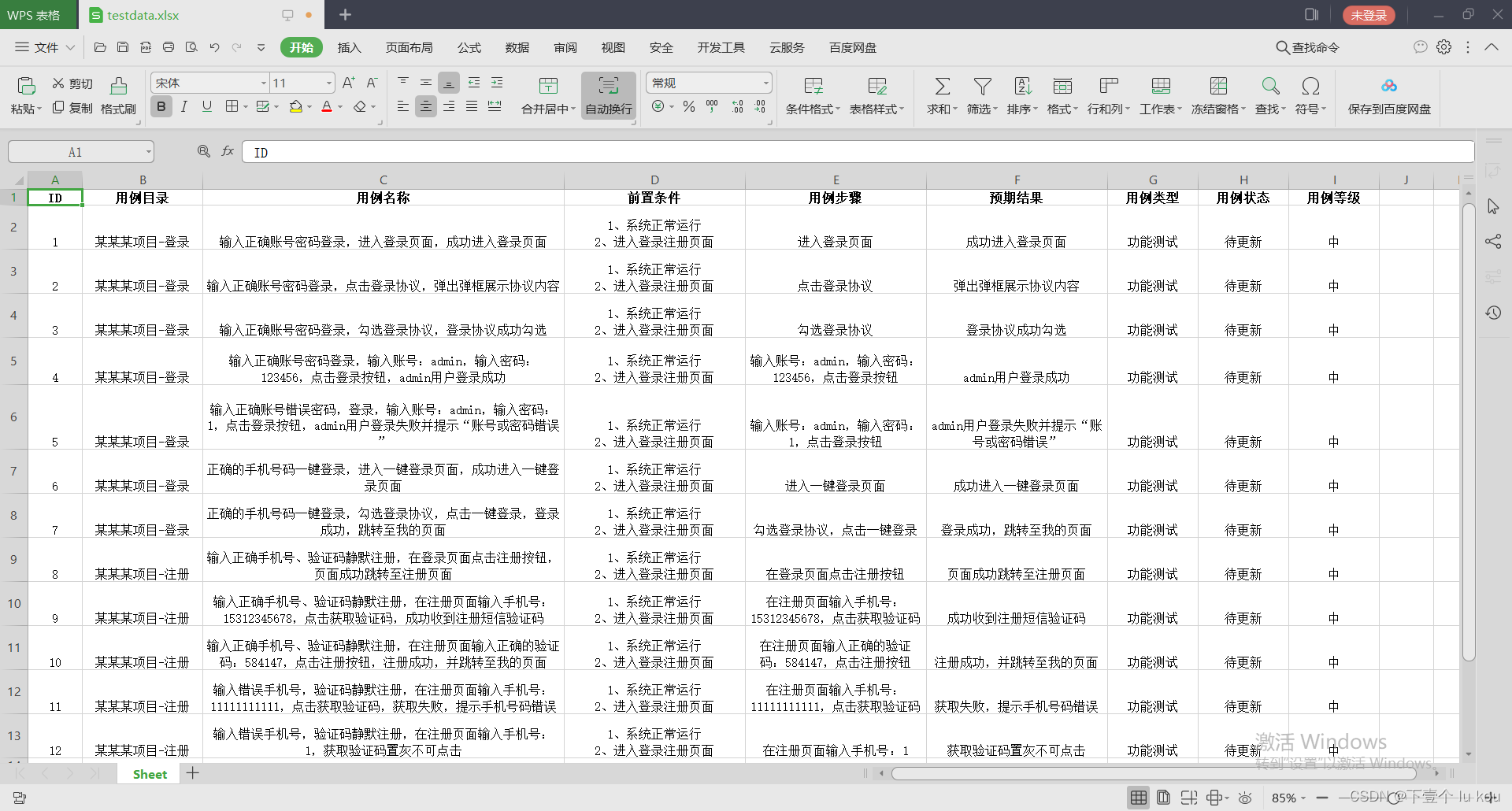
运行结果图如下:
四、总结
实现该需求并不是很难,主要是使用对应库解析数据并保存,目前只是实现了脚本,后续继续学习,希望把脚本转换成Tkinter桌面应用,使用更方便。