NEEA�Զ���λ���� Getting Started with NEEA TOEFL Testseat Crawler
���ĵ���Ҫ������NEEA�и���λ���������ʹ�÷�����
This document provides a brief intro of the usage of NEEA TOEFL Test Seats Selenium Crawler.
Github: https://github.com/jianqiaomo/NEEA-TOEFL-Testseat-Crawler
https://jqmo.top
https://engineering.nyu.edu/jianqiao-mo
���� Motivation
NEEA �и���λ��վ�����ṩ�Ų���ķ�����Ѱ�ҿ�λʱ,������Ҫ��ÿ������,ÿ������һ������������λ,
��Ϊ��Щ�뾡���ҵ�������λ���˴����������ܵ����顣

Ϊʲô��ֱ���Ա�����ʽ��ʾ���п�λ?
NEEA TOEFL Test Seat website, supported by Chinese National Education
Examinations Authority (NEEA), is providing an inconvenience service. When looking for a test seat,
we need to search date by every date, every city, which brings an intolerable experience for those
who just want to find a test seat ASAP. Why not display the form of all the test seat?
��װҪ�� Requirements
- Firefox mozilla geckodriver v0.26.0
- Firefox �� 60
- pip install selenium
��װ��ʽ Install
-
Firefox mozilla geckodriver: the default geckodriver path is ��C:\Program Files\Mozilla Firefox\geckodriver.exe��.
If you want to set your executable path, please use �Cwebdriver_path=��your path�� to start. -
Ĭ��Firefox mozilla geckodriver�ǰ�װ��"C:\Program Files\Mozilla Firefox\geckodriver.exe"·����,�����ϣ��ʹ������·��,
��ʹ�� �Cwebdriver_path=��your path�� ���������档
Get start
default start
python crawler_toefl.py --username='NEEA ID number' --password='password'
When finished, you can get a .csv form file. ������ɺõ�.csv�����ļ���
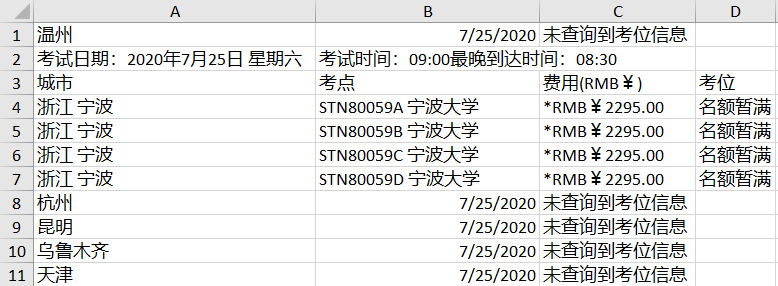
Todo:
- faster, test time is 25min �����ٶ�̫����, ����ȫ������Ŀǰ��Ҫ25����
- headless mode ����ģʽ��ô�ƿ�������?
- Anti anti-crawler when click the ��search seats�� button ��ô�ƿ�������?
- online crawler (use a server) ��������(������)
- different modes �û����ƻ�����
Acknowledgement
This idea is initially coming from https://www.jianshu.com/p/2541d918869e, thanks!
Github crawler_toefl.py:
# *_*coding:utf-8 *_*
# test on python 3.6
# thanks https://www.jianshu.com/p/2541d918869e
# version 1.0
# author cambridge.mo@foxmail.com
# month Jul 2020
import os
import csv
import time
import requests
from PIL import Image
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import random
import win32gui
import win32api
import argparse
CITYS = []
DATES = []
def parse_args():
# Parse input arguments
parser = argparse.ArgumentParser(description='TOEFL crawler args')
parser.add_argument('--username', dest='USERNAME_TF',
type=str, default='8625374')
parser.add_argument('--password', dest='PASSWORD_TF',
type=str, default='mJq3183601mJq!!')
parser.add_argument('--headless', dest='headless',
help='(Not suport in this version) start headless, browser will not display',
default=False, action='store_true')
parser.add_argument('--eager', dest='eager',
help='eager mode (unstable!) is faster when loading web-page',
default=False, action='store_true')
parser.add_argument('--webdriver_path', dest='webdriver_path',
help='set Firefox webdriver path',
type=str, default="C:\Program Files\Mozilla Firefox\geckodriver.exe")
# parser.add_argument('--mode', dest='mode',
# help='enum the mode',
# type=int)
args = parser.parse_args()
return args
class GetToeflTestInfos():
def __init__(self):
args = parse_args()
self.username = args.USERNAME_TF
self.password = args.PASSWORD_TF
if self.username==None:
self.username = input('�������˻��� Please enter username:')
if self.password==None:
self.password = input('���������� Please enter password:')
self.index_url = "https://toefl.neea.cn/login"
self.hwnd = None
self.option = webdriver.FirefoxOptions() # for anti-crawler, only FireFox can be used
self.option.add_argument('--user-agent="Firefox/60.0"')
if args.headless:
self.option.add_argument('--headless') # start 'headless', browser will not display
if args.eager:
desired_capabilities = DesiredCapabilities.FIREFOX
desired_capabilities["pageLoadStrategy"] = "eager" # eager mode (unstable) is faster when loading web-page
try:
self.driver = webdriver.Firefox(executable_path=args.webdriver_path, options=self.option)
except:
print("Your webdriver executable path is wrong: Cannot start webdriver.")
print("Please use --webdriver_path to set webdriver executable path")
print('See https://github.com/jianqiaomo/NEEA-TOEFL-Testseat-Crawler#%E5%AE%89%E8%A3%85%E6%96%B9%E5%BC%8F-install')
raise
self.wait = WebDriverWait(self.driver, timeout=50)
self.CITY = None
self.DATE = None
def input_infos(self):
"""
Enter username and password
"""
self.driver.get(self.index_url)
print("�Զ������û��������� Automatically enter username and password")
# username
time.sleep(2)
input_name = self.wait.until(
EC.presence_of_element_located((By.ID, "userName"))
)
input_name.clear()
input_name.send_keys(self.username)
# password
input_pwd = self.wait.until(
EC.presence_of_element_located((By.ID, "textPassword"))
)
input_pwd.clear()
input_pwd.send_keys(self.password)
def get_captcha(self):
"""
get captcha, :return: captcha
"""
print("�ȴ�������֤�� Loading captcha...")
# ģ����
input_code = self.wait.until(
EC.element_to_be_clickable((By.ID, "verifyCode"))
)
self.hwnd = win32gui.FindWindow('MozillaWindowClass', '��ҳ - ���������������и����ϱ��� - Mozilla Firefox')
win32api.keybd_event(27, 0, 0, 0) # VK_code
win32gui.SetForegroundWindow(self.hwnd)
while True:
input_code.click()
time.sleep(4)
# get captcha link, send requests
src = self.wait.until(
EC.presence_of_element_located((By.ID, "chkImg"))
)
time.sleep(2.5)
src_url = src.get_attribute("src")
print(src_url)
if (not ('loading' in src_url)) and (src_url is not None):
break
res = requests.get(src_url)
time.sleep(1.5)
with open('code.png', 'wb') as f:
f.write(res.content)
# Open local captcha, manually identify
try:
im = Image.open('code.png')
im.show()
im.close()
except:
print('������Ŀ¼��code.png��ȡ��֤�� Go local directory, open code.png to see captcha')
finally:
captcha = input('��������֤�� Please enter the captcha:')
os.remove('code.png')
print('���Ե�¼�� Logging in...')
return captcha
def login(self, code):
input_code = self.wait.until(
EC.presence_of_element_located((By.ID, "verifyCode"))
)
input_code.send_keys(code)
submit_button = self.wait.until(
EC.element_to_be_clickable((By.ID, "btnLogin"))
)
submit_button.click()
# Check if the login is successful
try:
success = self.wait.until(
EC.text_to_be_present_in_element((By.XPATH, '//div[@class="myhome_info_cn"]/span[2]'), self.username)
)
if success:
print("==��¼�ɹ�ҳ�� Page Login Success==")
except:
self.input_infos()
code_str = self.get_captcha()
self.login(code_str)
def find_seat(self):
print('��ʼ��λ��ѯ Turn to Page Find-Seat')
success = False
while not success:
self.driver.get("https://toefl.neea.cn/myHome/8625374/index#!/testSeat")
time.sleep(1)
try:
success = self.wait.until(
EC.text_to_be_present_in_element((By.XPATH, '//div[@class="span12"]/h4'), "��ѯ����")
)
if success:
print("==��λ��ѯҳ�� Page Find-Seat==")
except:
success = False
# self.driver.switch_to.alert.accept()
def get_all_DATE(self):
CITYS, DATES = [], []
CITY = "�Ϻ�"
time.sleep(1)
city = Select(self.driver.find_element_by_id("centerProvinceCity")).select_by_visible_text(CITY)
CITYS = self.driver.find_element_by_id("centerProvinceCity").text.split("\n")
del CITYS[0]
all_options = self.driver.find_element_by_id("testDays").find_elements_by_tag_name('option')
for option in all_options:
DATES.append(option.get_attribute("value"))
del DATES[0]
print("�ѻ�ȡȫ�����С��������� get all test DATE/CITYs")
return [CITYS, DATES]
def send_query_condition(self, virgin=False):
city = Select(self.driver.find_element_by_id("centerProvinceCity")).select_by_visible_text(self.CITY)
date = Select(self.driver.find_element_by_id("testDays")).select_by_value(self.DATE)
if virgin:
click = False
while not click:
try:
win32api.keybd_event(27, 0, 0, 0) # VK_code
win32gui.SetForegroundWindow(self.hwnd)
print("���ڷ�-������, ������Ҫ����һ�»������� Anti anti-crawler, you can click the Firefox browser...")
scrool = random.randint(0, 100)
self.driver.execute_script('window.scrollBy(0,%d)' % scrool)
time.sleep(1)
self.driver.execute_script('window.scrollBy(0,%d)' % -scrool)
query_button = self.wait.until(
EC.element_to_be_clickable((By.ID, "btnQuerySeat"))
)
time.sleep(1)
query_button.click()
click = bool(WebDriverWait(self.driver, timeout=5).until(alert_or_success()))
except:
click = False
else:
time.sleep(0.2)
query_button = self.wait.until(
EC.element_to_be_clickable((By.ID, "btnQuerySeat"))
)
query_button.click()
def save_date(self, i=1):
"""
save to .csv
"""
csv_fp = open("toefl_{}_check.csv".format(time.strftime('%Y-%m-%d', time.localtime(time.time()))), "a+",
encoding='utf-8-sig', newline='')
writer = csv.writer(csv_fp)
try:
is_success = EC.text_to_be_present_in_element((By.XPATH, '//td[@style="text-align:center;vertical-align: middle"]'), s_city)(
self.driver)
except:
is_success = 0
print('save: �Ƿ��п�λ Seats Available ', bool(is_success))
if bool(is_success):
# head 1: test date
boxhead1 = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//table[@class="table table-bordered table-striped"][{}]/thead/tr[1]/th/span'.format(i))
)
)
head1_ls = []
for head1 in boxhead1:
if not head1.text:
continue
head1_ls.append(head1.text)
writer.writerow(head1_ls)
print(head1_ls)
# head 2
boxhead2 = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//table[@class="table table-bordered table-striped"][{}]/thead/tr[2]/th'.format(i))
)
)
head2_ls = []
for head2 in boxhead2:
head2_ls.append(head2.text.replace('\n', ''))
writer.writerow(head2_ls)
print(head2_ls)
# inquiry form
items = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//table[@class="table table-bordered table-striped"][{}]/tbody/tr'.format(i))
)
)
for item in items:
body_dict = {}
body_dict["test_city"] = item.find_element_by_xpath('./td[1]').text
body_dict["test_venues"] = item.find_element_by_xpath('./td[2]').text
body_dict["test_fee"] = item.find_element_by_xpath('./td[3]').text
body_dict["test_seat"] = item.find_element_by_xpath('./td[4]').text
writer.writerow(body_dict.values())
print(body_dict)
else:
null_line = [self.CITY, self.DATE, "δ��ѯ����λ��Ϣ"]
print(null_line)
writer.writerow(null_line)
csv_fp.close()
class alert_or_success:
def __init__(self):
self.is_success, self.is_alert = 0, 0
def __call__(self, driver):
'''
wait to see whether is '��λ��ѯ���' or 'δ��ѯ����λ��Ϣ'
'''
try:
self.is_success = EC.text_to_be_present_in_element((By.XPATH, '//div[@id="qrySeatResult"]/h4'), "��λ��ѯ���")(
driver)
except:
self.is_alert = EC.visibility_of_element_located(
(By.XPATH, '//i[@class="layui-layer-ico layui-layer-ico0"]'))(driver)
if bool(self.is_success):
self.is_alert = 0
return True
elif bool(self.is_alert):
self.is_success = 0
return True
else:
self.is_success, self.is_alert = 0, 0
return False
if __name__ == "__main__":
GetToeflCrawler = GetToeflTestInfos()
GetToeflCrawler.input_infos()
captcha = GetToeflCrawler.get_captcha()
GetToeflCrawler.login(captcha)
GetToeflCrawler.find_seat()
[CITYS, DATES] = GetToeflCrawler.get_all_DATE()
CITYS.reverse()
for s_date in DATES:
for s_city in CITYS:
GetToeflCrawler.CITY, GetToeflCrawler.DATE = s_city, s_date
if [s_city, s_date] == [CITYS[0], DATES[0]]:
virgin = True
else:
virgin = False
GetToeflCrawler.send_query_condition(virgin)
flag = WebDriverWait(GetToeflCrawler.driver, timeout=50).until(alert_or_success())
GetToeflCrawler.save_date(i=1)
GetToeflCrawler.driver.quit()