一、背景
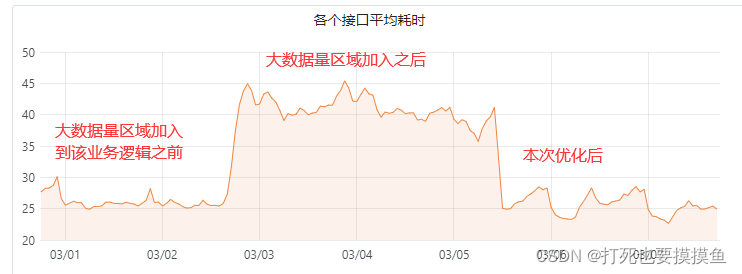
最近这几天,发现公司线上服务中,有一个接口耗时剧增,刚开始以为是gc导致的,后面通过检查日志发现是由于部分请求的数据量比较大,导致接口处理耗时增大导致的,于是尝试对接口进行优化,接口耗时从原来的20-50ms,经过优化后稳定在25ms。在减少接口耗时的同时,也增强了接口的稳定性。
原来接口对数据大致的处理逻辑:
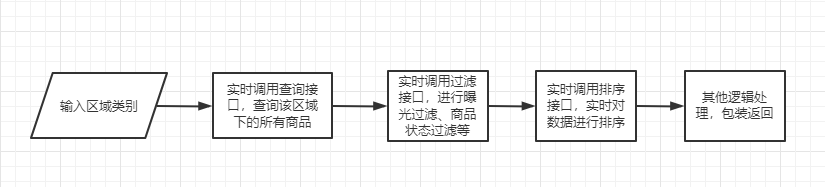
存在的问题:
1、多次串行调用接口,增大了接口总的耗时。
2、数据处理未作分片并行处理,某些区域下商品少处理速度快,某些区域下商品多处理速度慢,接口耗时不稳定。
优化后对数据处理的大致逻辑:
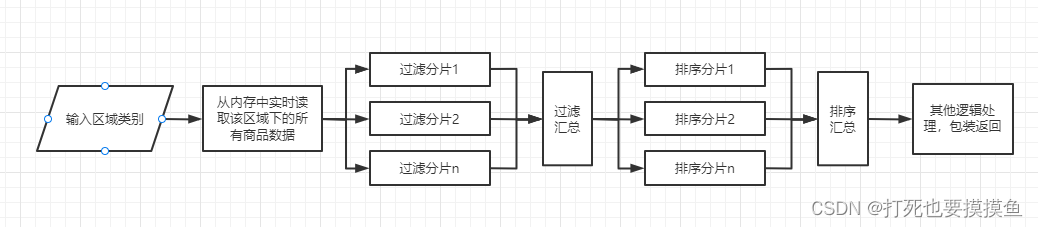
优化思路:
1、参与该业务逻辑处理的区域数量大概在5个左右,每个区域下的商品在1-400个不等。所以实时调用查询接口这一步可以优化,我们可以事先把所有区域下的所有商品在内存中进行缓存。
2、由于过滤和排序操作的耗时和数据量是成正相关的,因此我们需要对实时调用过滤、排序接口进行分片并行处理,减少接口耗时。
3、原接口使用了同步阻塞的代码,我们这次需要换成异步非阻塞的方法来执行。
二、代码实现
1、曝光过滤这一块,耗时相对较短,不需要分片,直接流处理就可以。这段耗时基本在1ms左右就能完成。
/**
* 曝光过滤
* @param mallHomeContext
* @param spuSnList
* @return
*/
public ListenableFuture<List<String>> exposeFilterAsync(MallHomeContext mallHomeContext, List<String> spuSnList){
if (CollectionUtil.isEmpty(spuSnList)) {
return Futures.immediateFuture(Collections.emptyList());
}
//布隆过滤器存储曝光过滤
BiBloomFilter biBloomFilter = mallHomeContext.getBiBloomFilter();
List<String> exposeFilterSpuSnList = spuSnList.stream()
.filter(spuSn -> !biBloomFilter.isExist(spuSn))
.collect(Collectors.toList());
return Futures.immediateFuture(exposeFilterSpuSnList);
}
2、商品状态校验,需要使用线程池对数据做分片并行处理。分片的大小,直接影响接口耗时。
/**
* 商品接口过滤(线程池分片进行)
* @param envParam
* @param spuSnList
* @return
*/
public ListenableFuture<List<String>> mallFilterAsync(EnvParam envParam, List<String> spuSnList){
if (CollectionUtil.isEmpty(spuSnList)) {
return Futures.immediateFuture(Collections.emptyList());
}
//对list进行分片,50个一片
List<List<String>> sliceList = Lists.partition(spuSnList, 50);
List<ListenableFuture<List<String>>> sliceListFuture = sliceList.stream()
.map(slice -> filter(envParam, slice))
.collect(Collectors.toList());
//对各个分片的数据进行汇总
return Futures.transform(Futures.allAsList(sliceListFuture), input -> {
if (CollectionUtil.isEmpty(input)) {
return Collections.emptyList();
}
return input.stream().flatMap(List::stream).collect(Collectors.toList());
}, ThreadPoolUtils.proxyThreadGPool);
}
/**
* 调用proxy,进行过滤
* @param envParam
* @param spuSnList
* @return
*/
public ListenableFuture<List<String>> filter(EnvParam envParam, List<String> spuSnList){
return ThreadPoolUtils.proxyThreadGPool.submit(() -> filterProxy.filter(envParam, spuSnList));
}
3、实时为用户对商品进行排序,需要使用线程池对数据做分片并行处理。分片的大小,直接影响接口耗时。
/**
* 排序(线程池分片进行)
* @param envParam
* @param spuSnList
* @return
*/
public ListenableFuture<List<RankItem>> athenaDirectRankAsync(EnvParam envParam, List<String> spuSnList){
if (CollectionUtil.isEmpty(spuSnList)) {
return Futures.immediateFuture(Collections.emptyList());
}
//对list进行分片。50个一片
List<List<String>> sliceList = Lists.partition(spuSnList, 50);
List<ListenableFuture<List<RankItem>>> sliceListFuture = sliceList.stream()
.map(slice -> rank(envParam, slice))
.collect(Collectors.toList());
//对各个分片的数据进行汇总
return Futures.transform(Futures.allAsList(sliceListFuture), input -> {
if (CollectionUtil.isEmpty(input)) {
return Collections.emptyList();
}
return input.stream().flatMap(List::stream).collect(Collectors.toList());
}, ThreadPoolUtils.proxyThreadGPool);
}
/**
* 调用proxy进行排序
* @param envParam
* @param spuSnList
* @return
*/
public ListenableFuture<List<RankItem>> rank(EnvParam envParam, List<String> spuSnList){
return ThreadPoolUtils.proxyThreadGPool.submit(() -> rankProxy.rank(envParam, spuSnList));
}
4、主方法,将这些串起来
/**
* 查询数据的方法
* @param mallHomeContext
* @return
*/
public ListenableFuture<List<String>> query(MallHomeContext mallHomeContext) {
//拿到该区域下所有橱窗中的数据包装成ListenableFuture
ListenableFuture<List<String>> windowSpuSnListFuture = windowProductCacheManager.getSpuSnByAreaId(areaId);
//对数据执行 曝光过滤
ListenableFuture<List<String>> exposeFilterFuture = Futures.transformAsync(windowSpuSnListFuture, spuSnList ->
exposeFilterAsync(mallHomeContext, spuSnList)
, ThreadPoolUtils.proxyThreadGPool);
//对数据执行 商品状态过滤
ListenableFuture<List<String>> mallFilterFuture = Futures.transformAsync(exposeFilterFuture, exposeFilterList ->
mallFilterAsync(envParam, exposeFilterList)
, ThreadPoolUtils.proxyThreadGPool);
//对数据执行 排序
ListenableFuture<List<RankItem>> rankFuture = Futures.transformAsync(mallFilterFuture, mallFilterList ->
athenaDirectRankAsync(envParam, mallFilterList)
, ThreadPoolUtils.proxyThreadGPool);
//对排序后的数据,进行最终处理返回
return Futures.transform(rankFuture, rankList -> {
if (CollectionUtil.isEmpty(rankList)) {
return Collections.emptyList();
}
return rankList.stream()
.sorted(Comparator.comparing(RankItem::getWeight).reversed())
.limit(10)
.map(RankItem::getSpuSn)
.collect(Collectors.toList());
}, ThreadPoolUtils.proxyThreadGPool);
}